A Solution for AGI/ASI Safety
post by Weibing Wang (weibing-wang) · 2024-12-18T19:44:29.739Z · LW · GW · 29 commentsContents
29 comments
I have a lot of ideas about AGI/ASI safety. I've written them down in a paper and I'm sharing the paper here, hoping it can be helpful.
Title: A Comprehensive Solution for the Safety and Controllability of Artificial Superintelligence
Abstract:
As artificial intelligence technology rapidly advances, it is likely to implement Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI) in the future. The highly intelligent ASI systems could be manipulated by malicious humans or independently evolve goals misaligned with human interests, potentially leading to severe harm or even human extinction. To mitigate the risks posed by ASI, it is imperative that we implement measures to ensure its safety and controllability. This paper analyzes the intellectual characteristics of ASI, and three conditions for ASI to cause catastrophes (harmful goals, concealed intentions, and strong power), and proposes a comprehensive safety solution. The solution includes three risk prevention strategies (AI alignment, AI monitoring, and power security) to eliminate the three conditions for AI to cause catastrophes. It also includes four power balancing strategies (decentralizing AI power, decentralizing human power, restricting AI development, and enhancing human intelligence) to ensure equilibrium between AI to AI, AI to human, and human to human, building a stable and safe society with human-AI coexistence. Based on these strategies, this paper proposes 11 major categories, encompassing a total of 47 specific safety measures. For each safety measure, detailed methods are designed, and an evaluation of its benefit, cost, and resistance to implementation is conducted, providing corresponding priorities. Furthermore, to ensure effective execution of these safety measures, a governance system is proposed, encompassing international, national, and societal governance, ensuring coordinated global efforts and effective implementation of these safety measures within nations and organizations, building safe and controllable AI systems which bring benefits to humanity rather than catastrophes.
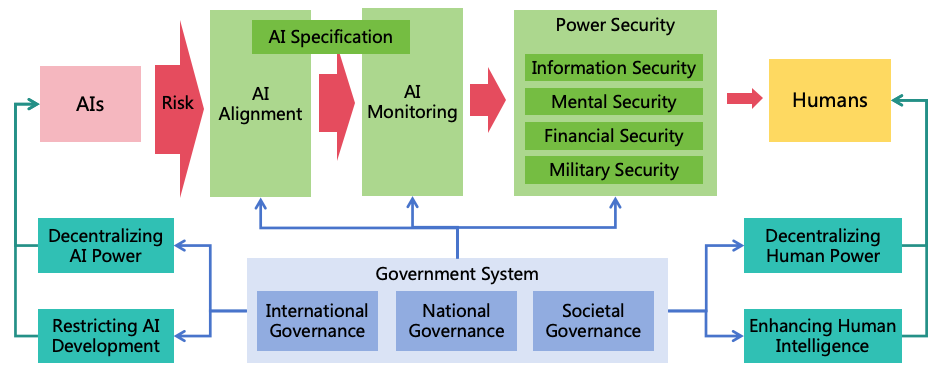
Content:
The paper is quite long, with over 100 pages. So I can only put a link here. If you're interested, you can visit this link to download the PDF: https://www.preprints.org/manuscript/202412.1418/v1
or you can read the online HTML version at this link:
https://wwbmmm.github.io/asi-safety-solution/en/main.html
29 comments
Comments sorted by top scores.
comment by Seth Herd · 2024-12-18T22:42:31.979Z · LW(p) · GW(p)
edit: I took a quick look, and this looks really good! Big upvote. Definitely an impressive body of work. And the actual alignment proposal is along the lines of the ones I find most promising on the current trajectory toward AGI. I don't see a lot of references to existing alignment work, but I do see a lot of references to technical results, which is really useful and encouraging. Look at Daniel Kokatijlo's and other work emphasizing faithful chain of thought for similar suggestions.
edit continued: I find your framing a bit odd, in starting from an unaligned, uninterpretable AGI (but that's presumably under control). I wonder if you're thinking of something like o1 that basically does what it's told WRT answering questions/providing data but can't be considered overall aligned, and which isn't readily interpretable because we can't see its chain of thought? A brief post situating that proposal in relation to current or near-future systems would be interesting, at least to me.
Original:
Interesting. 100 pages is quite a time commitment. And you don't reference any existing work in your brief pitch here - that often signals that people haven't read the literature, so most of their work is redundant with existing stuff or missing big considerations that are part of the public discussion. But it seems unlikely that you'd put in 100 pages of writing without doing some serious reading as well.
Here's what I suggest: relate this to existing work, and reduce the reading-time ask, by commenting on related posts with a link to and summary of the relevant sections of your paper.
Replies from: eggsyntax, weibing-wang↑ comment by eggsyntax · 2025-01-09T19:16:40.365Z · LW(p) · GW(p)
100 pages is quite a time commitment. And you don't reference any existing work in your brief pitch here - that often signals that people haven't read the literature, so most of their work is redundant with existing stuff or missing big considerations that are part of the public discussion.
Seconded. Although I'm impressed by how many people have already read and commented below, I think many more people will be willing to engage with your ideas if you separate out some key parts and present them here on their own. A separate post on section 6.1 might be an excellent place to start. Once you demonstrate to other researchers that you have promising and novel ideas in some specific area, they'll be a lot more likely to be willing to engage with your broader work.
It's an unfortunate reality of safety research that there's far more work coming out than anyone can fully keep up with, and a lot of people coming up with low-quality ideas that don't take into account evidence from existing work, and so making parts of your work accessible in a lower-commitment way will make it much easier for people to find time to read it.
↑ comment by Weibing Wang (weibing-wang) · 2024-12-19T02:31:05.636Z · LW(p) · GW(p)
Thank you for your suggestions! I will read the materials you recommended and try to cite more related works.
For o1, I think o1 is the right direction. The developers of o1 should be able to see the hidden chain of thoughts of o1, which is explainable for them.
I think that alignment or interpretability is not a "yes" or "no" property, but a gradually changing property. o1 has done a good job in terms of interpretability, but there is still room for improvement. Similarly, the first AGI to come out in the future may be partially aligned and partially interpretable, and then the approaches in this paper can be used to improve its alignment and interpretability.
comment by jacquesthibs (jacques-thibodeau) · 2024-12-19T00:20:55.516Z · LW(p) · GW(p)
(Reposted from Facebook)
Hey Weibing Wang! Thanks for sharing. I just started skimming your paper, and I appreciate the effort you put into this; it combines many of the isolated work people have been working on.
I also appreciate your acknowledgement that your proposed solution has not undergone experimental validation, humility, and the suggestion that these proposed solutions need to be tested and iterated upon as soon as possible due to the practicalities of the real world.
I want to look into your paper again when I have time, but some quick comments:
- You might be interested in reading up Drexler's CAIS stuff:
https://www.lesswrong.com/tag/ai-services-cais?sortedBy=new [? · GW] https://www.lesswrong.com/posts/LxNwBNxXktvzAko65/reframing-superintelligence-llms-4-years [LW · GW]
-
You should make the paper into a digestible format of sub-projects you can post to find collaborators to make progress on to verify some parts experimentally and potentially collaborate with some governance folks to turn some of your thoughts into a report that will get the eyeballs of important people on it.
-
Need more technical elaboration on the "how" to do x, not just "what" needs to be done.
↑ comment by Weibing Wang (weibing-wang) · 2024-12-19T03:46:33.695Z · LW(p) · GW(p)
Thank you for your suggestions! I have read the CAIS stuff you provided and I generally agree with these views. I think the solution in my paper is also applicable to CAIS.
comment by plex (ete) · 2024-12-21T13:42:06.495Z · LW(p) · GW(p)
Glanced through the comments and saw surprisingly positive responses, but reluctant to wade into a book-length reading commitment based on that. Are the core of your ideas on alignment compressible to fulfil the compelling insight heuristic [LW · GW]?
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-22T03:34:39.963Z · LW(p) · GW(p)
The core idea about alignment is described here: https://wwbmmm.github.io/asi-safety-solution/en/main.html#aligning-ai-systems
If you only focus on alignment, you can only read Sections 6.1-6.3, and the length of this part will not be too long.
Replies from: ete↑ comment by plex (ete) · 2024-12-23T14:57:23.192Z · LW(p) · GW(p)
Cool, so essentially "Use weaker and less aligned systems to build more aligned and stronger systems, until you have very strong very aligned systems". This does seem like the kind of path where much of the remaining winning timelines lies, and the extra details you provide seem plausible as things that might be useful steps.
There's two broad directions of concern with this, for me. One is captured well by "Carefully Bootstrapped Alignment" is organizationally hard [LW · GW], and is essentially: going slowly enough to avoid disaster is hard, it's easy to slip into using your powerful systems to go too fast without very strong institutional buy-in and culture, or have people leave and take the ideas with them/ideas get stolen/etc and things go too fast elsewhere.
The next and probably larger concern is something like.. if current-style research on alignment doesn't scale to radical superintelligence and you need new and more well formalized paradigms in order for the values you imbue to last a billion steps of self-modification, as I think is reasonably likely, then it's fairly likely that somewhere along the chain of weakly aligned systems one of them either makes a fatal mistake, or follows its best understanding of alignment in a way which doesn't actually produce good worlds. If we don't have a crisp understanding of what we want, asking a series of systems which we haven't been able to give that goal to to make research progress on finding that leaves free variables open in the unfolding process which seem likely to end up at extreme or unwanted values. Human steering helps, but only so much, and we need to figure out how to use that steering effectively in more concrete terms because most ways of making it concrete have pitfalls.
A lot of my models are best reflected in various Arbital pages, such as Reflective Stability, Nearest unblocked strategy, Goodhart's Curse, plus some LW posts like Why Agent Foundations? An Overly Abstract Explanation [LW · GW] and Siren worlds and the perils of over-optimised search [LW · GW] (which might come up in some operationalizations of pointing the system towards being aligned).
This seems like a solid attempt to figure out a path to a safe world. I think it needs a bunch of careful poking at and making sure that when the details are nailed down there's not failure modes which will be dangerous, but I'm glad you're exploring the space.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-24T06:24:58.481Z · LW(p) · GW(p)
For the first issue, I agree that "Carefully Bootstrapped Alignment" is organizationally hard, but I don't think improving the organizational culture is an effective solution. It is too slow and humans often make mistakes. I think technical solutions are needed. For example, let an AI be responsible for safety assessment. When a researcher submits a job to the AI training cluster, this AI assesses the safety of the job. If this job may produce a dangerous AI, the job will be rejected. In addition, external supervision is also needed. For example, the government could stipulate that before an AI organization releases a new model, it needs to be evaluated by a third-party safety organization, and all organizations with computing resources exceeding a certain threshold need be supervised. There is more discussion on this in the section Restricting AI Development.
For the second issue, you mentioned free variables. I think this is a key point. In the case where we are not fully confident in the safety of AI, we should reduce free variables as much as possible. This is why I proposed a series of AI Controllability Rules. The priority of these rules is higher than the goals. AI should be trained to achieve the goals under the premise of complying with the rules. In addition, I think we should not place all our hopes on alignment. We should have more measures to deal with the situation where AI alignment fails, such as AI Monitoring and Decentralizing AI Power.
comment by bhauth · 2024-12-19T11:42:31.924Z · LW(p) · GW(p)
Your document says:
AI Controllability Rules
...
AI Must Not Self-Manage:
- Must Not Modify AI Rules: AI must not modify AI Rules. If inadequacies are identified, AI can suggest changes to Legislators but the final modification must be executed by them.
- Must Not Modify Its Own Program Logic: AI must not modify its own program logic (self-iteration). It may provide suggestions for improvement, but final changes must be made by its Developers.
- Must Not Modify Its Own Goals: AI must not modify its own goals. If inadequacies are identified, AI can suggest changes to its Users but the final modification must be executed by them.
I agree that, if those rules are followed, AI alignment is feasible in principle. The problem is, some people won't follow those rules if they have a large penalty to AI capabilities, and I think they will.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-20T02:35:57.432Z · LW(p) · GW(p)
Thank you for your comment! I think your concern is right. Many safety measures may slow down the development of AI's capabilities. Developers who ignore safety may develop more powerful AI more quickly. I think this is a governance issue. I have discussed some solutions in Sections 13.2 and 16. If you are interested, you can take a look.
comment by Charlie Steiner · 2024-12-19T12:24:37.498Z · LW(p) · GW(p)
Skimmed ahead to the alignment section, since that's my interest. Some thoughts:
My first reaction to the perennial idea of giving everyone their own AI advocate is that this is a bargaining solution that could just as well be simulated within a single centralized agent, if one actually knew how to align AIs to individual people. My second typical reaction is that if one isn't actually doing value alignment to individuals, and is instead just giving people superpowerful AI assistants and seeing what happens, that seems like an underestimation of the power of superintelligence to cause winner-take-all dynamics in contexts where there are resources waiting to be grabbed, or where the laws of nature happen to favor offense over defense.
You anticipate these thoughts, which is nice!
My typical reaction to things like AI Rules is that they essentially have to contain a solution to the broad/ambitious value alignment problem anyway in order to work, so why not cut out the middlemen of having mini-'goals' overseen by aligned-goal-containing Rules and just build the AI that does what's good.
You agree with the first part. I think where you disagree with the second part is that you think that if we oversee the AIs and limit the scope of their tasks, we can get away with leaky or hacky human values in the Rules in a way we couldn't get away with if we tried to just directly get an AI to fulfill human values without limitations. I worry that this still underestimates superintelligence - even tame-seeming goals from users can test all the boundaries you've tried to set, and any leaks ('Oh, I can't lie to the human, but I can pick a true thing to say which I predict will get the outcome that I think fulfills the goal, and I'm very good at that') in those boundaries will be flowed through in a high-pressure stream.
If there's an assumption I skimmed past that the AI assistants we give everyone won't actually be very smart, or will have goals restricted to the point that it's hard for superintelligence to do anything useful, I think this puts the solution back into the camp of "never actually use a superintelligent AI to make real-world plans," which is nice to aspire to but I think has a serious human problem, and anyhow I'm still interested in alignment plans that work on AI of arbitrary intelligence.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-20T02:22:25.555Z · LW(p) · GW(p)
Thank you for your comment! I think my solution is applicable to arbitrary intelligent AI for the following reasons:
1. During the development stage, AI will align with the developers' goals. If the developers are benevolent, they will specify a goal that is beneficial to humans. Since the developers' goals have a higher priority than the users' goals, if a user specifies an inappropriate goal, the AI can refuse.
2. Guiding the AI to "do the right thing" through the developers' goals and constraining the AI to "not do the wrong thing" through the rules may seem a bit redundant. If the AI has learned to do the right thing, it should not do the wrong thing. However, the significance of the rules is that they can serve as a standard for AI monitoring, making it clear to the monitors under what circumstances the AI's actions should be stopped.
3. If the monitor is an equally intelligent AI, it should have able to identify those behaviors that attempt to bypass the loopholes in the rules.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-19T01:31:33.989Z · LW(p) · GW(p)
Nice work! Quite comprehensive and well explained. A lot of overlap with existing published ideas, but also some novel ideas.
I intend to give some specific suggestions for details I think are worth adding. In the meantime, I'm going to add a link to your work to my list of such works at the top of my own (much shorter) AI safety plan. I recommend you take a look at mine, since mine is short but touches on a few points I think could be valuable to your thinking. Also, the links and resources in mine might be of interest to you if there's some you haven't seen.
A path to Human Autonomy [LW · GW]
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-19T03:51:30.964Z · LW(p) · GW(p)
Thank you for your feedback! I’ll read the resources you’ve shared. I also look forward to your specific suggestions for my paper.
comment by Dakara (chess-ice) · 2024-12-27T09:18:25.738Z · LW(p) · GW(p)
I actually really liked your alignment plan. But I do wonder how it would be able to deal with 5 "big" organizational problems of iterative alignment:
-
Moving slowly and carefully is annoying. There's a constant tradeoff about getting more done, and elevated risk. Employees who don't believe in the risk will likely try to circumvent or goodhart the security procedures. Filtering for for employees willing to take the risk seriously (or training them to) is difficult. There's also the fact that many security procedures are just security theater. Engineers have sometimes been burned on overzealous testing practices. Figuring out a set of practices that are actually helpful, that your engineers and researchers have good reason to believe in, is a nontrivial task.
-
Noticing when it's time to pause is hard. The failure modes are subtle, and noticing things is just generally hard unless you're actively paying attention, even if you're informed about the risk. It's especially hard to notice things that are inconvenient and require you to abandon major plans.
-
Getting an org to pause indefinitely is hard. Projects have inertia. My experience as a manager, is having people sitting around waiting for direction from me makes it hard to think. Either you have to tell people "stop doing anything" which is awkwardly demotivating, or "Well, I dunno, you figure it out something to do?" (in which case maybe they'll be continuing to do capability-enhancing work without your supervision) or you have to actually give them something to do (which takes up cycles that you'd prefer to spend on thinking about the dangerous AI you're developing). Even if you have a plan for what your capabilities or product workers should do when you pause, if they don't know what that plans is, they might be worried about getting laid off. And then they may exert pressure that makes it feel harder to get ready to pause. (I've observed many management decisions where even though we knew what the right thing to do was, conversations felt awkward and tense and the manager-in-question developed an ugh field around it, and put it off)
-
People can just quit the company and work elsewhere if they don't agree with the decision to pause. If some of your employees are capabilities researchers who are pushing the cutting-edge forward, you need them actually bought into the scope of the problem to avoid this failure mode. Otherwise, even though "you" are going slowly/carefully, your employees will go off and do something reckless elsewhere.
-
This all comes after an initial problem, which is that your org has to end up doing this plan, instead of some other plan. And you have to do the whole plan, not cutting corners. If your org has AI capabilities/scaling teams and product teams that aren't bought into the vision of this plan, even if you successfully spin the "slow/careful AI plan" up within your org, the rest of your org might plow ahead.
↑ comment by Weibing Wang (weibing-wang) · 2024-12-28T06:33:34.897Z · LW(p) · GW(p)
I agree with your view about organizational problems. Your discussion gave me an idea: Is it possible to shift employees dedicated to capability improvement to work on safety improvement? Set safety goals for these employees within the organization. This way, they will have a new direction and won't be idle, worried about being fired or resigning to go to other companies. Besides, it's necessary to make employees understand that improving safety is a highly meaningful job. This may not rely solely on the organization itself, but also require external pressure, such as from the government, peers, or the public. If the safety cannot be ensured, your product may face a lot of criticism and even be restricted from market access. And there will be some third-party organizations conducting safety evaluations of your product, so you need to do a solid job in safety rather than just going through the motions.
Replies from: chess-ice↑ comment by Dakara (chess-ice) · 2024-12-28T08:28:52.972Z · LW(p) · GW(p)
I agree with your view about organizational problems. Your discussion gave me an idea: Is it possible to shift employees dedicated to capability improvement to work on safety improvement? Set safety goals for these employees within the organization. This way, they will have a new direction and won't be idle, worried about being fired or resigning to go to other companies.
That seems to solve problem #4. Employees quitting becomes much less of an issue, since in any case they would only be able to share knowledge about safety (which is a good thing).
Do you think this plan will be able to solve problems #1, #2, #3 and #5? I think such discussions are very important, because many people (me included) worry much more about organizational side of alignment than about technical side.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-29T03:13:02.630Z · LW(p) · GW(p)
I think this plan is not sufficient to completely solve problems #1, #2, #3 and #5. I can't come up with a better one for the time being. I think more discussions are needed.
comment by Knight Lee (Max Lee) · 2024-12-22T05:54:33.981Z · LW(p) · GW(p)
I didn't read the 100 pages, but the content seems extremely intelligent and logical. I really like the illustrations, they are awesome.
A few questions.
1: In your opinion, which idea in your paper is the most important, most new (not already focused on by others), and most affordable (can work without needing huge improvements in political will for AI safety)?
2: The paper suggests preventing AI from self-iteration, or recursive self improvement. My worry is that once many countries (or companies) have access to AI which are far better and faster than humans at AI research, each one will be tempted to allow a very rapid self improvement cycle.
Each country might fear that if it doesn't allow it, one of the other countries will, and that country's AI will be so intelligent it can engineer self replicating nanobots which take over the world. This motivates each country to allow the recursive self improvement, even if the AI's methods of AI development become so advanced they are inscrutable by human minds.
How can we prevent this?
Edit: sorry I didn't read the paper. But when I skimmed it you did have a section on "AI Safety Governance System," and talked about an international organization to get countries to do the right thing. I guess one question is, why would an international system succeed in AI safety, when current international systems have so far failed to prevent countries from acting selfishly in ways which severely harms other countries (e.g. all wars, exploitation, etc.)?
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-23T05:35:11.835Z · LW(p) · GW(p)
1. I think it is "Decentralizing AI Power". So far, most descriptions of the extreme risks of AI assume the existence of an all-powerful superintelligence. However, I believe this can be avoided. That is, we can create a large number of AI instances with independent decision-making and different specialties. Through their collaboration, they can also complete the complex tasks that a single superintelligence can accomplish. They will supervise each other to ensure that no AI will violate the rules. This is very much like human society: The power of a single individual is very weak, but through division of labor and collaboration, humans have created an unprecedentedly powerful civilization.
2. I am not sure that an international governance system will definitely succeed in AI safety. This requires extremely arduous efforts. First, all countries need to reach a consensus on AI risks, but this has not happened yet. So I think risk evaluation is a very important task. If it can be proven that the risks of AI in the future are very high, for example, higher than that of nuclear weapons, then countries may cooperate, just as they have cooperated in controlling the proliferation of nuclear weapons in the past. Second, even if countries are willing to cooperate, they will also face great challenges. Restricting the development of AI is much more difficult than restricting the proliferation of nuclear weapons. I discussed some restriction methods in Section 14.3, but I am also not sure whether these methods can be effectively implemented.
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2024-12-23T07:50:42.018Z · LW(p) · GW(p)
Thank you for your response!
- What do you think is your best insight about decentralizing AI power, which is most likely to help the idea succeed, or to convince others to focus on the idea?
EDIT: PS, one idea I really like is dividing one agent into many agents working together. In fact, thinking about this. Maybe if many agents working together behave exactly identical to one agent, but merely use the language of many agents working together, e.g. giving the narrator different names for different parts of the text, and saying "he thought X and she did Y," instead of "I thought X and I did Y," will massively reduce self-allegiance, by making it far more sensible for one agent to betray another agent to the human overseers, than for the same agent in one moment in time to betray the agent in a previous moment of time to the human overseers.
I made a post [LW · GW] on this. Thank you for your ideas :)
- I feel when the stakes are incredibly high, e.g. WWII, countries which do not like each other, e.g. the US and USSR, do join forces to survive. The main problem is that very few people today believe in incredibly high stakes. Not a single country has made serious sacrifices for it. The AI alignment spending [? · GW] is less than 0.1% of the AI capability spending. This is despite some people making some strong arguments. What is the main hope for convincing people?
↑ comment by Weibing Wang (weibing-wang) · 2024-12-24T07:55:48.636Z · LW(p) · GW(p)
1. One of my favorite ideas is Specializing AI Powers. I think it is both safer and more economical. Here, I divide AI into seven types, each engaged in different work. Among them, the most dangerous one may be the High-Intellectual-Power AI, but we only let it engage in scientific research work in a restricted environment. In fact, in most economic fields, using overly intelligent AI does not bring more returns. In the past, industrial assembly lines greatly improved the output efficiency of workers. I think the same is true for AI. AIs with different specialties collaborating in an assembly line manner will have higher efficiency than using all-powerful AIs. Therefore, it is possible that without special efforts, the market will automatically develop in this direction.
2. I think the key for convincing people may lie in the demonstration of AI's capabilities, that is, showing that AI does indeed have great destructive power. However, the current AI capabilities are still relatively weak and cannot provide sufficient persuasion. Maybe it will have to wait until AGI is achieved?
↑ comment by Knight Lee (Max Lee) · 2024-12-24T09:13:54.533Z · LW(p) · GW(p)
That is very thoughtful.
1.
When you talk about specializing AI powers, you talk about a high intellectual power AI with limited informational power and limited mental (social) power. I think this idea is similar to what Max Tegmark said in an article:
If you’d summarize the conventional past wisdom on how to avoid an intelligence explosion in a “Don’t-do-list” for powerful AI, it might start like this:
☐ Don’t teach it to code: this facilitates recursive self-improvement
☐ Don’t connect it to the internet: let it learn only the minimum needed to help us, not how to manipulate us or gain power
☐ Don’t give it a public API: prevent nefarious actors from using it within their code
☐ Don’t start an arms race: this incentivizes everyone to prioritize development speed over safety
Industry has collectively proven itself incapable to self-regulate, by violating all of these rules.
He disagrees that "the market will automatically develop in this direction" and is strongly pushing for regulation.
Another think Max Tegmark talks about is focusing on Tool AI instead of building a single AGI which can do everything better than humans (see 4:48 to 6:30 in his video). This slightly resembles specializing AI intelligence, but I feel his Tool AI regulation is too restrictive to be a permanent solution. He also argues for cooperation between the US and China to push for international regulation (in 12:03 to 14:28 of that video).
Of course, there are tons of ideas in your paper that he hasn't talked about yet.
You should read about the Future of Life Institute, which is headed by Max Tegmark and is said to have a budget of $30 million [LW · GW].
2.
The problem with AGI is at first it has no destructive power at all, and then it suddenly has great destructive power. By the time people see its destructive power, it's too late. Maybe the ASI has already taken over the world, or maybe the AGI has already invented a new deadly technology which can never ever be "uninvented," and bad actors can do harm far more efficiently.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-25T03:15:08.231Z · LW(p) · GW(p)
1. The industry is currently not violating the rules mentioned in my paper, because all current AIs are weak AIs, so none of the AIs' power has reached the upper limit of the 7 types of AIs I described. In the future, it is possible for an AI to break through the upper limit, but I think it is uneconomical. For example, an AI psychiatrist does not need to have superhuman intelligence to perform well. An AI mathematician may be very intelligent in mathematics, but it does not need to learn how to manipulate humans or how to design DNA sequences. Of course, having regulations is better, because there may be some careless AI developers who will grant AIs too many unnecessary capabilities or permissions, although this does not improve the performance of AIs in actual tasks.
The difference between my view and Max Tegmark's is that he seems to assume that there will only be one type of super intelligent AI in the world, while I think there will be many different types of AIs. Different types of AIs should be subject to different rules, rather than the same rule. Can you imagine a person who is both a Nobel Prize-winning scientist, the president, the richest man, and an Olympic champion at the same time? This is very strange, right? Our society doesn't need such an all-round person. Similarly, we don't need such an all-round AI either.
The development of a technology usually has two stages: first, achieving capabilities, and second, reducing costs. The AI technology is currently in the first stage. When AI develops to the second stage, specialization will occur.
2. Agree.
↑ comment by Knight Lee (Max Lee) · 2024-12-25T07:57:00.329Z · LW(p) · GW(p)
EDIT: Actually I was completely wrong, see this comment by Vladimir_Nesov [LW · GW]. The Mixture of Experts LLM isn't made up of a bunch of experts voting on the next word, instead each layer of the transformer is made up of a bunch of experts.
I feel your points are very intelligent. I also agree that specializing AI is a worthwhile direction.
It's very uncertain if it works, but all approaches are very uncertain, so humanity's best chance is to work on many uncertain approaches.
Unfortunately, I disagree it will happen automatically. Gemini 1.5 (and probably Gemini 2.0 and GPT-4) are Mixture of Experts models. I'm no expert, but I think that means that for each token of text, a "weighting function" decides which of the sub-models should output the next token of text, or how much weight to give each sub-model.
So maybe there is an AI psychiatrist, an AI mathematician, and an AI biologist inside Gemini and o1. Which one is doing the talking depends on what question is asked, or which part of the question the overall model is answering.
The problem is they they all output words to the same stream of consciousness, and refer to past sentences with the words "I said this," rather than "the biologist said this." They think that they are one agent, and so they behave like one agent.
My idea [LW · GW]—which I only thought of thanks to your paper—is to do the opposite. The experts within the Mixture of Experts model, or even the same AI on different days, do not refer to themselves with "I" but "he," so they behave like many agents.
:) thank you for your work!
I'm not disagreeing with your work, I'm just a little less optimistic than you and don't think things will go well unless effort is made. You wrote the 100 page paper so you probably understand effort more than me :)
Happy holidays!
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-26T03:03:36.388Z · LW(p) · GW(p)
You mentioned Mixture of Experts. That's interesting. I'm not an expert in this area. I speculate that in an architecture similar to MoE, when one expert is working, the others are idle. In this way, we don't need to run all the experts simultaneously, which indeed saves computation, but it doesn't save memory. However, if an expert is shared among different tasks, when it's not needed for one task, it can handle other tasks, so it can stay busy all the time.
The key point here is the independence of the experts, including what you mentioned, that each expert has an independent self-cognition. A possible bad scenario is that although there are many experts, they all passively follow the commands of a Leader AI. In this case, the AI team is essentially no different from a single superintelligence. Extra efforts are indeed needed to achieve this independence. Thank you for pointing this out!
Happy holidays, too!
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2024-12-26T05:08:27.134Z · LW(p) · GW(p)
I agree, it takes extra effort to make the AI behave like a team of experts.
Thank you :)
Good luck on sharing your ideas. If things aren't working out, try changing strategies. Maybe instead of giving people a 100 page paper, tell them the idea you think is "the best," and focus on that one idea. Add a little note at the end "by the way, if you want to see many other ideas from me, I have a 100 page paper here."
Maybe even think of different ideas.
I cannot tell you which way is better, just keep trying different things. I don't know what is right because I'm also having trouble sharing my ideas.
Replies from: weibing-wang↑ comment by Weibing Wang (weibing-wang) · 2024-12-27T01:53:49.153Z · LW(p) · GW(p)
Thank you for your advice!