Gradient Hacking via Schelling Goals
post by Adam Scherlis (adam-scherlis) · 2021-12-28T20:38:12.054Z · LW · GW · 4 commentsContents
4 comments
Thanks to several people for useful discussion, including Evan Hubinger, Leo Gao, Beth Barnes, Richard Ngo, William Saunders, Daniel Ziegler, and probably others -- let me know if I'm leaving you out.
See also: Obstacles to Gradient Hacking [AF · GW] by Leo Gao.
I want to argue that gradient hacking (strongly enough to create a local minimum) is possible even under somewhat pessimistic assumptions. The specific strategy that achieves this is kind of interesting: it requires the agent to coordinate on a complicated task with versions of itself that have slightly different objectives, and it requires the agent to do this without any direct communication.
A simple gradient-hacking strategy for a mesa-optimizer is to deliberately perform worse on the base objective if your mesa-objective is changed. However, this isn't as straightforward as it sounds.
One difficulty is that if the gradient hacking is hard-coded, gradient descent can just remove the hacking behavior without touching anything else. A nice way around that is to assume that gradient hacking is discovered from first principles during the model's computation. (Thanks to whoever pointed this out to me.) If it's good enough at reasoning, then it will be pretty hard for the base optimizer to modify it in ways that stop it from noticing that gradient hacking would be a good idea right about now.
(For simplicity, I have in mind something like a really deep feed-forward network, possibly with some weights tied between layers. Equivalently, a recurrent net unrolled and trained via SGD. This may not be realistic but it's easier to think about as a test case.)
A bigger problem is that it's not really correct to think of a model (with particular parameter values) as having control over its gradients. It's better to think of it as having control (in an FDT kind of sense) over only the single value of the loss for its actual parameters. The value of the loss at nearby points in parameter space is decided by slightly different versions of itself, and the gradient is sort of decided collectively. This is important if we're talking about SGD steps that change its mesa-objective, because these nearby versions of the model will have directly conflicting incentives when it comes to the gradient. To say "I am such that gradients on nearby mesa-objectives point towards my mesa-objective" is to say "if I had a different mesa-objective, I would deliberately do slightly worse in order to end up with this one instead." But you wouldn't! That would be bad for your mesa-objective!
Another way to look at this is that it's really hard to implement "do worse if my objective changes" if you don't have an external way to tell that your objective used to be different, let alone a way to commit other versions of yourself to things they don't want to do. You can implement rules like "if your mesa-objective isn't X, throw a fit", but the base optimizer will just change X at the same time it changes your actual mesa-objective. (Actually, it doesn't have to: we're assuming that gradient hacking has to be derived from first principles on every forward pass, so X also has to be derived from first principles. But even without that assumption this strategy wouldn't work.)
You can leave messages for yourself, if you have somewhere to jot down durable notes (like the external world), but let's assume you don't.
Maybe your mesa-objective is something nice and clear and crystalline, an island in mesa-objective parameter space, and you can implement the rule "do badly in proportion to how un-crystalline your mesa-objective is". But it's not clear why your less-crystalline neighbors in parameter space would cooperate with this plan.
Well... maybe if they're nearby enough, they'd be happy to settle on your mesa-objective rather than get pushed all the way to the base objective? This might work for some specific kinds of mesa-objectives.
More broadly, something that kind of works is to just push in the opposite direction from the base objective: do badly on the task in proportion to how mesa-aligned you are, so that you don't become any more mesa-aligned in the future. This possibly works well enough to level the playing field, so that the gradient in mesa-objective-space is flat. The main difficulty is that you need to pick the size of the loss penalty you're going to impose on yourself for being N units of mesa-aligned. The bigger the penalty, the further you can be from the base objective while still keeping the gradient flat -- but the versions of you closer to the base objective would prefer a smaller penalty, because it's probably costly in other ways. And of course, in the limit, the version of yourself that's aligned with the base objective isn't going to be willing to pay any penalty. So you probably need to coordinate (silently) with the versions of yourself whose mesa-objectives lie within some range of distances from the base objective.
A somewhat better version of that is to pick a fairly dense grid of "Schelling mesa-objectives" in mesa-objective-parameter space, and use moderate fluctuations of loss to push your mesa-objective towards the nearest Schelling point, making it a local minimum. If the grid is dense enough, even a small variation in loss can create steep enough walls to make this work.
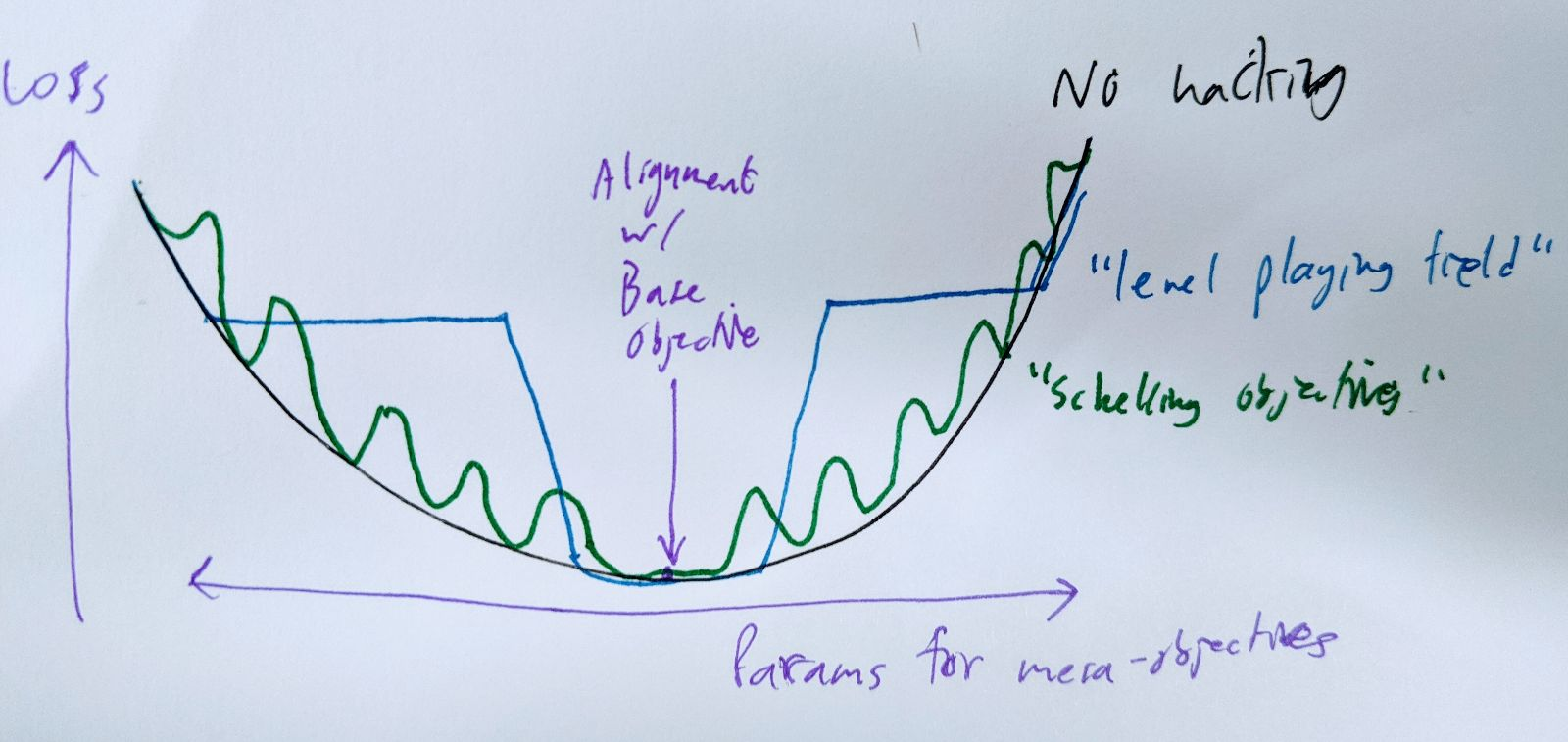
# temporary, I hope hope hope
Ideally, you and your parameter-adjusted kin would all prefer to have a Schelling point right under your own mesa-objectives, but you can't all get that at the same time. The next-best thing is to have the grid of Schelling points (and hence local minima) be dense enough that there's one within epsilon of your actual preferences. In practice, the value of epsilon is bounded below by the SGD step size and stochasticity.
It would be easier if you could just encode the locations of the Schelling points somewhere else in your parameters, but that would leave an opening for the base optimizer to mess with them and average out your loss fluctuations to nothing. (In other words, this fails for the same reason a hard-coded gradient-hacking procedure probably fails.)
It seems probable to me that it's possible to pick these Schelling points without communicating; meeting someone at a non-prearranged spot is easier if they're almost exactly a clone of you. That isn't a very solid argument, but I doubt that this part is going to be the crux.
This proposal doesn't do everything that's needed for the original context Evan suggested gradient hacking in, which involves trying to push the base optimizer to hard-code deceptive behavior into an otherwise-aligned future version of yourself. I think it's a step in the right (er... wrong?) direction, though.
In particular, the Schelling-objective strategy lets arbitrary mesa-optimizers preserve their mesa-objectives (within epsilon), create "artificial" local minima, and force the base optimizer to settle for severely subpar performance on the base objective. It also does this without needing any of the behavior to be hard-coded where the base optimizer could get at it: the strategy can be discovered and executed from scratch by a general-purpose reasoner with amnesia.
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2021-12-28T22:59:32.994Z · LW(p) · GW(p)
Sounds like a job for quantum machine learning :P (See e.g. figure 1 here)
But actually, I'm mostly just skeptical that this really works in high-dimensional space with no access to the actual parameters of the model. You make some intuitive arguments that I feel like rely on low-dimensional intuitions about how easy it is to create local minima rather than saddle points. E.g. in sufficiently high dimensions we might simply find that there's some direction in parameter-space that directly changes what the agent thinks is the Schelling point in mesa-objective space, thus collapsing the entire class of attempts at building the bumpy landscape.
comment by Richard_Ngo (ricraz) · 2021-12-28T22:49:34.953Z · LW(p) · GW(p)
Interesting post :) I'm intuitively a little skeptical - let me try to figure out why.
I think I buy that some reasoning process could consistently decide to hack in a robust way. But there are probably parts of that reasoning process that are still somewhat susceptible to being changed by gradient descent. In particular, hacking relies on the agent knowing what its current mesa-objective is - but that requires some type of introspective access, which may be difficult and the type of thing which could be hindered by gradient descent (especially when you're working in a very high-dimensional space!)
The more general point is that the agent doesn't just need to decide to hack in a way that's robust to gradient descent, it has to also have all of its decisions about how to hack (e.g. figuring out where it is, and which schelling point to choose) be robust to gradient descent. And that seems much harder. The type of thing I imagine happening is gradient descent pushing the agent towards a mesa-objective which intrinsically disfavours gradient hacking, in a way which the agent has trouble noticing.
Of course my argument fails when the agent has access to external memory - indeed, it can just write down a Schelling point for future versions of itself to converge to. So I'm wondering whether it's worth focusing on that over the memoryless case (even thought the latter has other nice properties), at least to flesh out an initial very compelling example.
comment by Quintin Pope (quintin-pope) · 2021-12-29T10:49:57.779Z · LW(p) · GW(p)
I suspect most mesa optimizers generated by SGD will have objectives and implementations that are amenable to being modified by SGD. Mesa optimizers form because they give good performance on the base objective. A mesa optimizer whose mesa objective and inner optimization algorithm is easily updated by SGD is better for performance than a mesa optimizer that’s harder to update.
Gradient hacking (especially from first principles) seems pretty complex. The first version of the mesa optimizer SGD generates almost surely won’t gradient hack. From there, “do what the base optimizer wants” is far simpler and leads to far better loss than “run a complex strategy that increases loss”. To deal with cases where the mesa objective conflicts significantly with the base objective, I expect the base optimizer to build robust control structures into the mesa optimizer and that the mesa optimizer will usually not challenge those structures.
Consider that humans are surprisingly close to being mesa aligned with evolution. We may not intrinsically value inclusive genetic fitness, but our sex drive is still pretty effective at getting us to reproduce. Note that evolution takes one step for every ~10s of billions of steps the brain takes, that evolution uses a far less efficient learning algorithm than the brain, and that evolution can’t even directly update brain parameters.
Finally, I think we can deal with the form of gradient hacking you describe (and most other forms of gradient hacking) by using meta learning (see the learn2learn repository). The basic problem of gradient hacking is that there’s some model parameter configuration that leads to poor SGD performance. Meta learning addresses exactly that issue.
Currently, meta learning research tries to find some parameter initialization that leads to quick learning on many tasks. The idea is that you can set the improvement from SGD as an optimization objective and use meta-gradients to get model parameters that are easy for the base optimizer to optimize. However, if the current parameterization of the mesa optimizer is preventing the base optimizer from learning, we should be able to use meta learning to find a mesa optimizer parameterization that’s more amenable to modification by the base optimizer.
The downside is that now you have to think about a base optimizer, a mesa optimizer and a meta optimizer (and maybe a meta meta optimizer if you’re feeling adventurous).
Replies from: jacob_cannell↑ comment by jacob_cannell · 2021-12-29T20:09:14.316Z · LW(p) · GW(p)
Currently, meta learning research tries to find some parameter initialization that leads to quick learning on many tasks. The idea is that you can set the improvement from SGD as an optimization objective and use meta-gradients to get model parameters that are easy for the base optimizer to optimize.
Just a small nitpick - what you describe (meta learning a param init) is certainly a meta-learning technique, but that term is broader and also encompasses actually learning better optimizers (although I guess you could make the two more equivalent by burning the SGD/update circuitry into the model).