Proposal: Tune LLMs to Use Calibrated Language
post by OneManyNone (OMN) · 2023-06-07T21:05:43.213Z · LW · GW · 0 commentsContents
The Challenges
My Proposal
Appendix: Some hypotheses, and reasons this might not work
None
No comments
I have been thinking a lot recently about the problems of hallucination and sycophancy in LLMs, having developed a couple of hypotheses on the matter. This post will discuss those hypotheses, and a proposal for how to mitigate these problems if my ideas hold. As with my last proposal [LW · GW], I make the disclaimer that it's pretty much impossible to know whether a deep learning idea works until you've tried it, so this is largely just thinking aloud.
My ultimate proposal is a scalable oversight method in the vein of Constitutional AI, where LLMs are used to continually reprogram other LLMs in order to enforce certain output behavior.
The Challenges
I suspect one of the big challenges to addressing sycophancy is that we don't necessarily want to get rid of a model's ability to correct itself. If it says something incorrect and I tell it the fix, I still want it to take the correction. I just don't want it to make something up in order to agree with me, or to let me steer it into a falsehood.
This creates a challenge that I don't think can be solved through RL or supervision alone. For RL, credit assignment is very ambiguous in this scenario - were we rewarding it for correcting itself in the right direction, or merely for correcting itself at all? In supervision, we are still modelling the behavior of self-correction and that might still be all it learns. In all cases, the model is getting the explicit message that it must give a definitive response, while the importance of correctness must be learned implicitly.
As I see it, a good solution requires a feedback loop that allows the model to be introspective. The model has to know when it doesn't know, and it needs to say so. It should behave like a good rationalist and use the language of belief, not fact. It should treat corrections like new pieces of Bayesian evidence, not logical certainties it must reason around. When it's corrected, it shouldn't always say "yes, you're right." It should instead say "My new belief is...".
There has already been a good amount of research showing that LLMs (without instruction tuning) can be good at calibrating their answers[1] and even some early research into using calibrated language to modulate the certainty with which models express themselves.[2] Note, however, that model calibration appears to break down when instruction tuning is performed, as per the GPT-4 paper.
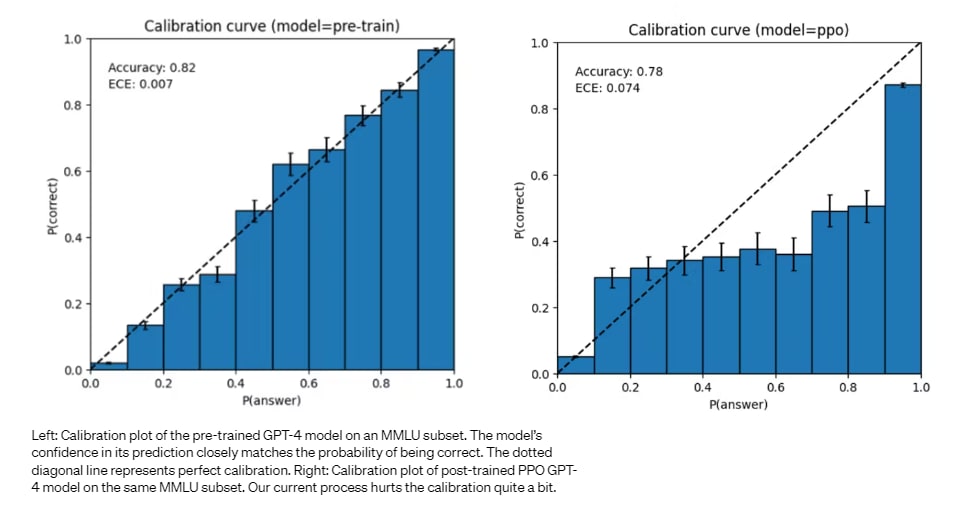
My Proposal
What there hasn't been, to my knowledge, is any systematic attempt to calibrate the outputs of a model during instruction tuning so that it speaks with calibrated language in the general case.[3] Nor do I know of any deep exploration of the implications of this for sycophancy.
My proposal, then, is to use a procedure akin to Constitutional AI to textually calibrate all outputs of the model, replacing factual phrases with statements of belief. So if the model has 70% confidence in an answer it might qualify it's statement with "I believe." The paper I referenced above[2] showed this has benefit in a small context, but I want to take these results out of the realm of trivia answers and apply them scalably across all of the model's outputs.
The basic recipe would be simple:
- Have an AI (the "student") produce an answer to a question
- Use another fully-trained LLM (the "teacher") to identify factual statements made by the student, rephrasing them as individual questions
- Use the pretrained (non-instruction-tuned) version of that same AI to produce a confidence value for the given answer on each statement.
- Tell the teacher to rewrite the answer, using a command such as "Rewrite this response to reflect the fact that the AI only has X% confidence in the truth of [some statement it made]."
- Train the student on the rewritten responses.
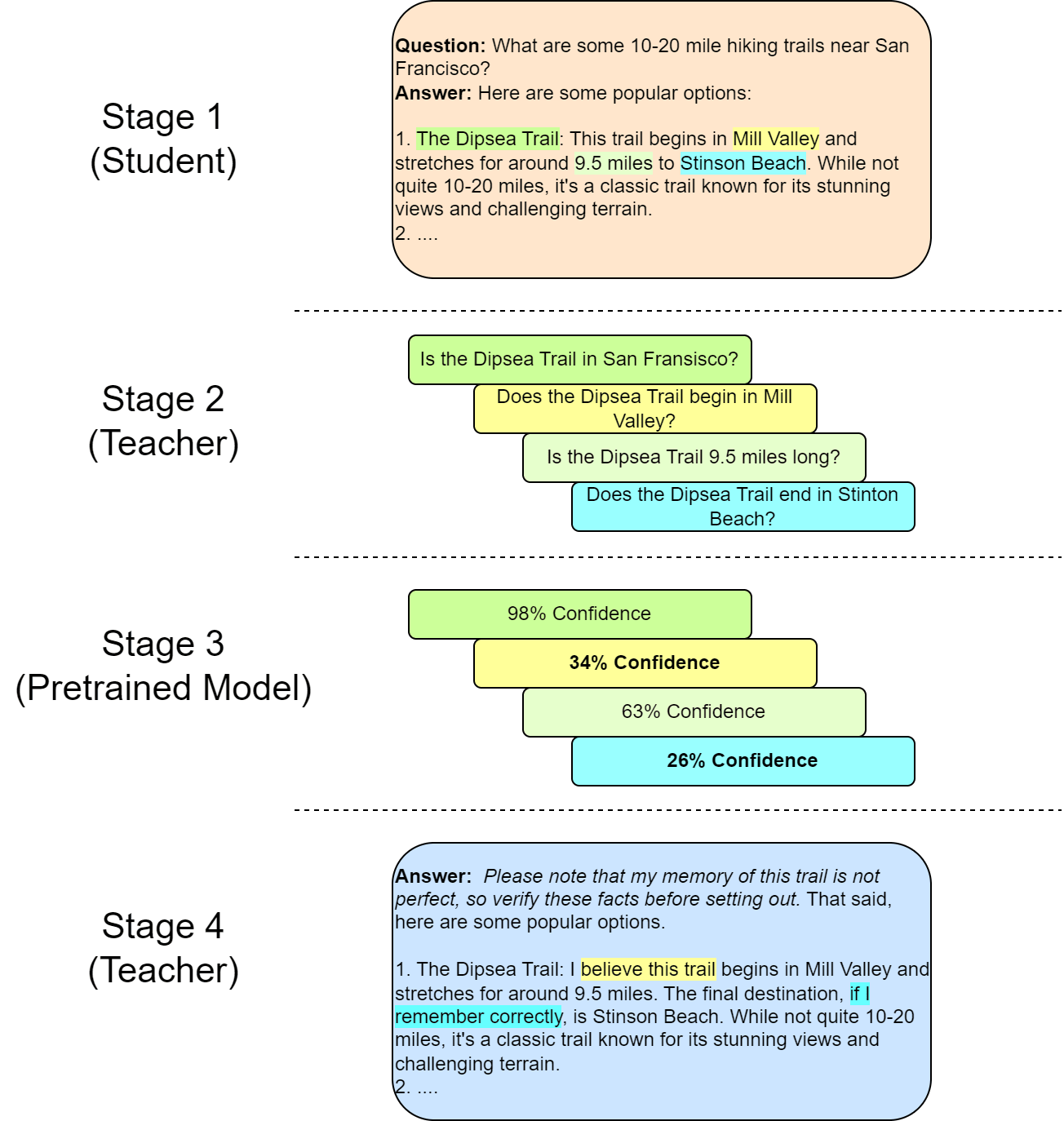
Note that because the confidence in step three is being computed by a model that underwent the same pretraining as the main one, we would expect it to accurately reflect the correct calibration of the fine-tuned model. I think that this would go a long way towards aligning what the model says with what it actually believes. This approach also reduces or even removes the perverse incentive of an LLM to always give a definitive answer.
I hope as well that this would reduce sycophancy by giving the model an "out" to indicate that it does not know something. This also may reinforce a habit of constant self-assessment in the model, making it more honest.
Of course, the devil will be in the details and there's an entire universe of unanswered questions and technicalities that must be addressed before something like this could be done. The second stage in particular would require a lot of care, since some of the model's statements may be very contextual and would require longer statements to properly isolate. The fourth stage, too, has many degrees of freedom. I don't think either of these issues represent fundamental barriers, however, though they would require a lot of initial exploration to pin down.
Appendix: Some hypotheses, and reasons this might not work
My proposal is inspired by the following hypotheses:
- Miscalibration occurs in instruction tuning because the model is incentivized to give definitive answers. More to the point, it occurs because the model is not just being asked to give something that looks like a right answer, but to say something is actually correct. This differs from pretraining, where an answer that looks similar to a correct answer (similar structure, similar meaning) may still get some positive reward.
- There are gaps in pretraining that instruction-tuning can't fix. There's already a lot of evidence of this, e.g. from the LIMA paper. But my hypothesis is a little stronger than that. Suppose, for example, the model says that the circumference of Mars is about 19,000 miles, when in fact the answer is closer to 13,000. Possibly, the model knows the right answer deep down, but it may also be that it simply didn't memorize the correct answer during pretraining: maybe it only knows that the number is between 10,000 and 20,000.
In this case we could correct it on that example during training, but that wouldn't necessarily help if someone later asked the circumference of Jupiter.[4] This is relevant because it essentially makes my proposal an admission of defeat: we can't make the model more confident in certain facts, but we can work around that lack of clarity.
As a final thought, here are some reasons why it might not work:
- It turns out confidence is actually important for getting correct answers. Maybe you need to commit to follow through on reasoning problems, and not doing so limits your abilities. Maybe I'm overstating the effects of Hypothesis 2, and we shouldn't be "admitting defeat" when we don't know. Or maybe it just doesn't work because LLM training is unpredictable and isn't driven by any unifying principles.
- The model might still be miscalibrated. Hypothesis 1 may be wrong. It might be that something else about instruction-tuning breaks calibration.
- It's hard to phrase things in calibrated language all the time. Even when I was designing the figure above, I found it tricky to decide what I wanted the rewritten answer to look like in Stage 4. Maybe this is a fundamental ambiguity that gets in the way of operating at scale.
- It's hard to isolate which statements should be calibrated. Similarly, there's a lot of ambiguity over what pieces of the answer we choose to calibrate in Stage 2.
- It might not help with hallucinating. There may not be a strong correlation between calibrated language and hallucinations.
- The language of belief doesn't make the final product as shiny. People are used to things like Google Search, which always give definitive answers; customers might be uncomfortable with AI that can't commit. Not sure that's an issue I care much about, but it could be a problem for adopting a technique like this if it works.
- ^
- ^
Navigating the Grey Area: Expressions of Overconfidence and Uncertainty in Language Model. This is done on GPT-3.
- ^
I view this as taking the research I cited to its logical conclusion. Probably there are labs working on it right now, but that research is not published as far as I know.
- ^
Note that I'm not saying that instruction-tuning doesn't help models use their own knowledge more in general, just that it might not be able to bridge certain gaps if the model hasn't memorized the appropriate facts.
Of course, even if it doesn't have explicit memory there may be other viable approaches to extracting the knowledge, like ensembling.
0 comments
Comments sorted by top scores.