High-School Algebra for Data Structures
post by johnswentworth · 2020-06-17T18:09:24.550Z · LW · GW · 0 commentsContents
No comments
A surprising amount of day-to-day software engineering can be expressed as solving equations like:
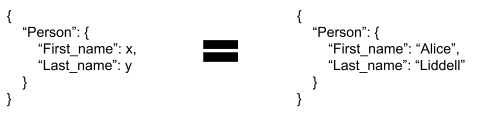
… finding the solution (x = “Alice”, y = “Liddell”), and then substituting that solution into some other expression.
For instance, suppose we have this data:
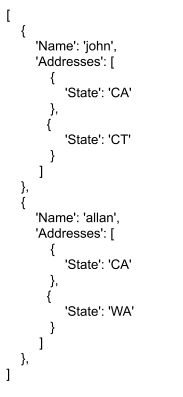
We want to list the people who’ve lived in each state. We first write an equation:
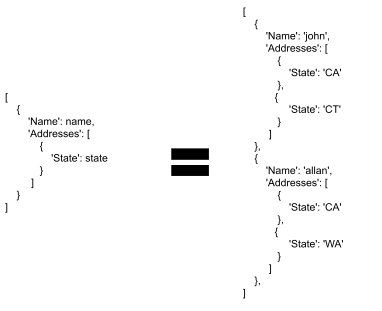
We interpret lists as multiple allowed values, so this equation has four solutions:
- (name = ‘john’, state = ‘CA’)
- (name = ‘john’, state = ‘CT’)
- (name = ‘allan’, state = ‘CA’)
- (name = ‘allan’, state = ‘WA’)
To list people who live in each state, we then substitute those solutions into an expression like

Again, lists are interpreted as multiple allowed values, so when we substitute our four solutions into this expression, the maximally-compressed result is:
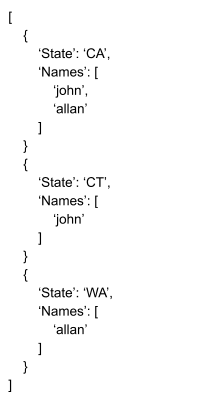
This is primarily useful for transforming data from one format to another. Typical use-cases include collecting data from an external API and transforming it into the schema used in our database, or transforming data from one API into the format needed by another API. Typically, these sort of tasks are conceptually simple, but they get very tedious and messy when mapping a large number of fields between deeply-nested data formats. Personally, I originally worked out these ideas while at LoanSnap, a mortgage startup needing to map thousands of fields between dozens of different data formats; you can imagine how messy that would get.
What’s the advantage of writing transformations as equations, rather than writing out “x = data[‘person’][‘firstName’]; y = data[‘person’][‘lastName’]; …”?
First, when we write data transformations as equations, the structure of our code matches the structure of our data - indeed, our “code” is essentially a template whose structure matches the data. For our names-and-states example, our code would consist of the two data structures
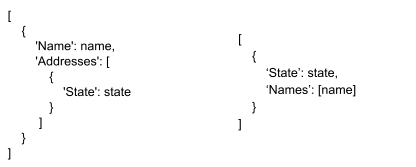
The left is a template matching the structure of our incoming data, and the right is a template matching the structure of our outgoing data. This makes the code much more readable and maintainable when dealing with large, deeply-nested data structures.
Second, this is a declarative (rather than imperative) method for specifying data transformations, so it comes with the usual benefits of declarativity. In particular, a library for solving data-structure-equations can handle missing data and other errors in standard ways without having to hand-code checks for every single field - especially useful when entire nested structures can be missing.
Third, because the “code” defining a transformation is itself a data structure, we can potentially track/visualize/audit data flow without having to trace arbitrary code.
If you want to play around with this stuff in code, check out the Algex library. In addition to the basic ideas here, it supports equations containing arbitrary transformations, and it uses a lazy intermediate representation of the solution set to efficiently handle equations with exponentially many solutions.
0 comments
Comments sorted by top scores.