An exploration of GPT-2's embedding weights
post by Adam Scherlis (adam-scherlis) · 2022-12-13T00:46:17.898Z · LW · GW · 4 commentsContents
Embedding matrix glossary Preferred channel basis from LayerNorm Token/Position embedding rivalry Gain parameters in LayerNorm Dimension 138, the unigram neuron? SVD combinations of channel dims Weird outlier tokens and zero-layer GPT-2 None 4 comments
I wrote this doc in December 2021, while working at Redwood Research. It summarizes a handful of observations about GPT-2-small's weights -- mostly the embedding matrix, but also the LayerNorm gain parameters -- that I found while doing some open-ended investigation of the model. I wanted to see how much I could learn by studying just those parameters, without looking at the attention layers, MLP layers, or activations.
This is still mostly unedited. Feedback and questions are very welcome.
Embedding matrix glossary
- Latent space – 768-channel-dim space that activations between blocks (and in skip connections) live in.
- Token space – 50,257-token-dim space of one-hot token vectors
- [Token] embedding matrix – W of shape [768, 50257] (this is the transpose of `model.lm_head.weight`)
- Embedding vector – Any 768-dimensional column of W
- Embedding space – Latent space
Preferred channel basis from LayerNorm
This section involves more math than the rest; you can skip it without missing much. "Preferred basis" means the same thing as "privileged basis" as defined by Anthropic here.
Most of GPT-2’s architecture – the attention layers, fully-connected layers and residual connections – don’t impose a preferred basis on the latent space.
(The skip connections give a canonical map between the latent spaces in different layers, so that it makes sense to talk about “the” latent space globally.)
The LayerNorm layers actually do privilege a basis, though, for two reasons.
LayerNorm(x) is defined as follows, where w and b are learned parameters:
- (subtract mean; 1 is an all-ones vector)
- (normalize variance)
- (apply bias and gain parameters)
The first line picks out part of a preferred basis – a preferred vector (and the subspace orthogonal to it), namely the all-ones vector 1.
The second line doesn’t pick out a basis, because the stdev of the components of y is just its L2 norm and normalizing a vector is independent of (orthonormal) basis. (It does impose a preferred inner product, but we had that already: GPT-2’s unembedding matrix is the transpose of the embedding matrix, and W^T W is a matrix of inner products.)
The third line is the interesting one. The gain vector w is multiplied elementwise with z, which breaks basis-independence. (You could also write this as D_ij z_j where D is a diagonal matrix, D_ii = w_i.) This makes the standard basis a preferred basis, in a pretty straightforward way: the network can dial up or down the size of different standard-basis components independently (and can’t do this for the components with respect to any other basis).
This provides some justification for breaking things out by latent-space dimension in most of this post.
Token/Position embedding rivalry
Here’s an interesting phenomenon I don’t have a complete explanation for.
This is a chunk of the token embedding matrix:
(X: token dims, Y: channel dims)
The horizontal stripes are dimensions of the latent space where the token embeddings are systematically larger or smaller than average. This gets normalized away inside residual blocks, but is preserved by skip connections.
We can also make histograms from this matrix, by taking either a row or a column and plotting a histogram of the numbers in it. We can overlay a few of these histograms, in different colors, to show a few columns or a few rows at the same time.
Overlaid histograms of the first 30 columns (tokens, left) and the first 30 rows (channel dims, right):
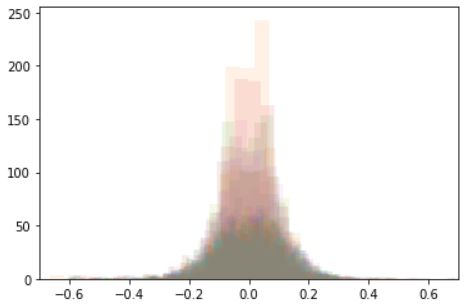
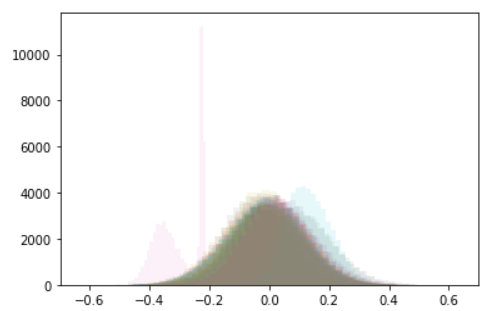
Note that many of the channel dims follow roughly the same distribution, while a few have smaller variance and larger means.
This shows up as a heavy left-tail of the distribution of stdevs, and heavy tails in both directions for the means:
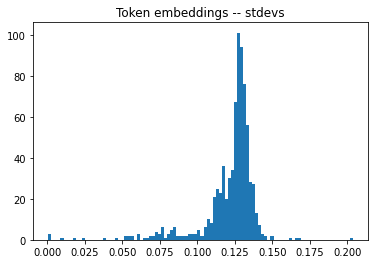
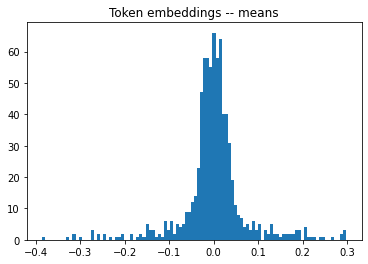
(In these plots, I’m taking the stdev/mean across the 50,257 token dims, then showing a histogram of these 768 values for the 768 channel dims.)
Seraphina Nix guessed that these weird high-mean, low-variance dims might be where the position embeddings are most active. As it turns out, there is a very distinct cluster of channel dims where the position embeddings are doing something, with the rest of the dims being near-zero:

(Log scale for readability. This time, we're taking stdev across the sequence positions for each channel dim, then plotting a histogram of the 768 values obtained that way.)
I’ve made a big plot of means and stdevs of token and position embeddings, across the token/position dimension, for each channel dimension (next page).
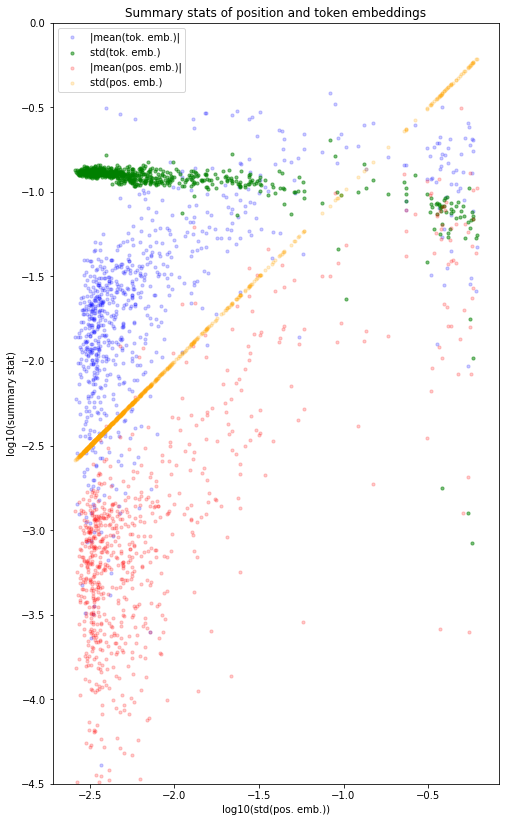
I chose std(position embedding) as the x-axis, so the left and right clusters are "not much position-embedding activity" and "lots of it" respectively.
Some things you can read off the plot:
- The low-std (green) and high-mean (blue) token embeddings are mostly in the cluster of channel dims with high-std / high-mean position embeddings
- Position embeddings are consistently centered near zero, i.e. their means are a bit smaller than their stds (red < orange). The “normal” token embeddings are centered near zero (blue << green) but the “weird” ones aren’t (blue > green)
Here are some scatterplots of token (black) and position embeddings (red) for randomly-chosen pairs of channels dims. There are 1024 points in each red scatterplot, one for each position, and 50,257 in each black scatterplot, one for each token.
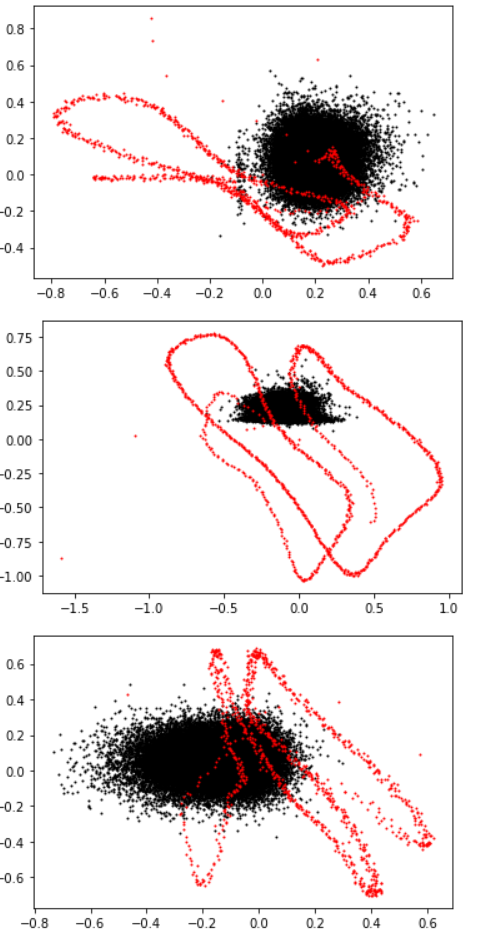
Left: both channel dims are “weird” (high position-embedding variance)
Right: both channels dims are “normal” (low position-embedding variance)
Middle: one of each kind of channel dim
I don't quite get what's happening here. The token embeddings do seem to be avoiding the channel dimensions used by the position embeddings, by putting less variance into those dimensions, but not as much as they could. I don't understand what role the nonzero mean on those dimensions plays. As we'll see later, the direction of latent space parallel to the mean token embedding seems to be pretty important to the model, so it is interesting and confusing that the position embeddings overlap on many dimensions with the token mean!
In other news, note that the position embeddings look a little like Lissajous figures.
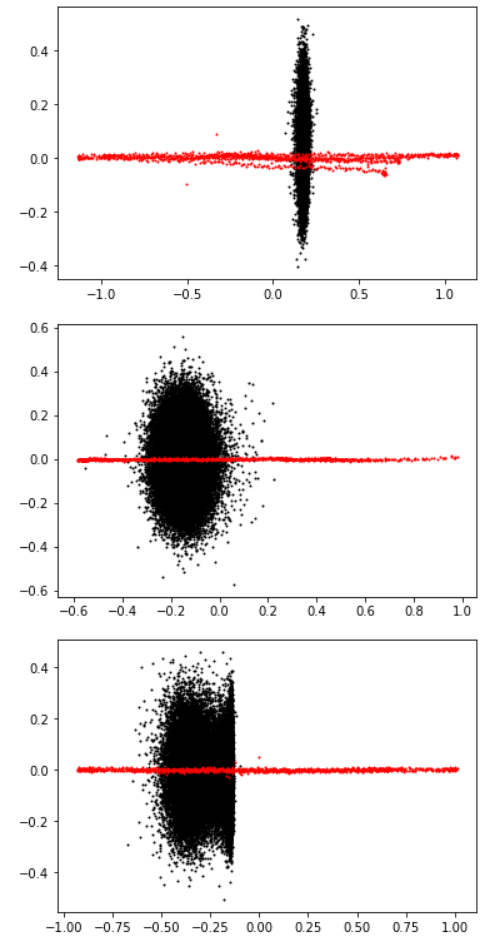
Position embeddings themselves look like this (as a function of sequence position):
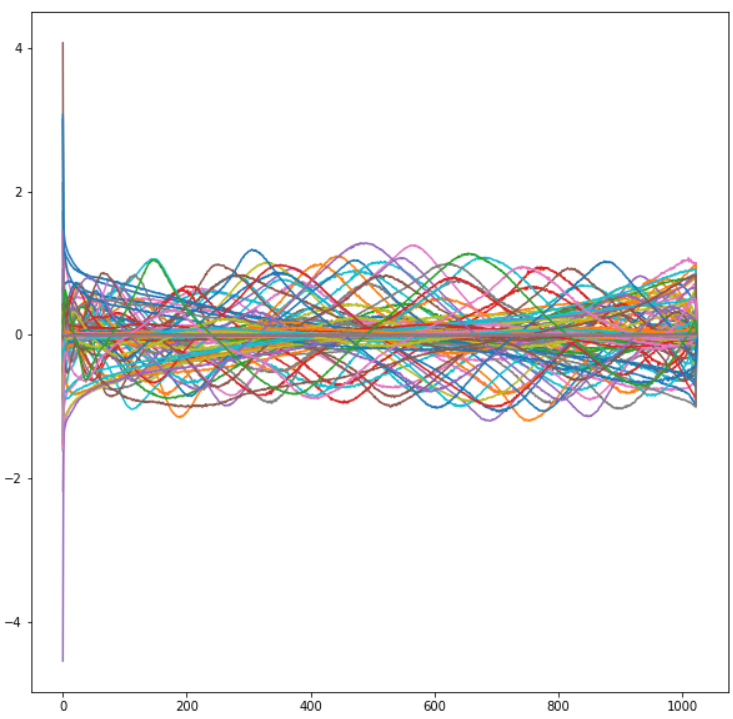
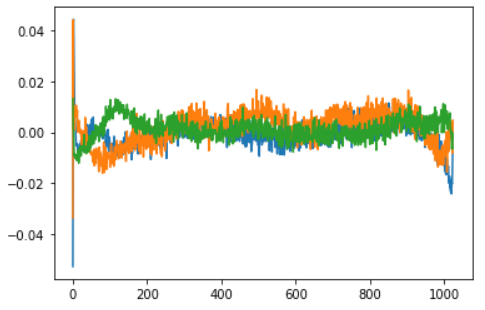
A few low-variance ones are shown separately on the right, with a finer y-axis scale, since they’re piled up at y=0 on the main plot.
It looks like the position embeddings have mostly learned something vaguely sinusoidal, or maybe a bit more triangle-wave-like than that. This makes a lot of sense in terms of producing a smooth but precise representation of position. (See also: grid cells, etc.)
It’s not obvious whether the fuzzy “noise” in the position embeddings is in fact noise; a fun experiment would be to smooth it away and see if the network performs any better/worse. It would also be interesting to see if the low-signal-amplitude position embeddings are necessary for good performance, or if they're disposable.
Gain parameters in LayerNorm
In all these plots, the x-axes are log10(std(position embeddings)) and the y-axes are log10(|gain|). As above, we have one point in the scatterplot for each of the 768 latent-space dimensions. There is one gain parameter "w_i" per LayerNorm for each of those dimensions.
There are two LayerNorms in each layer: LN1 and LN2.
“LN1”, before the self-attention layer:

“LN2”, before fully-connected layer: (not log-transformed on Y for some reason, sorry.)
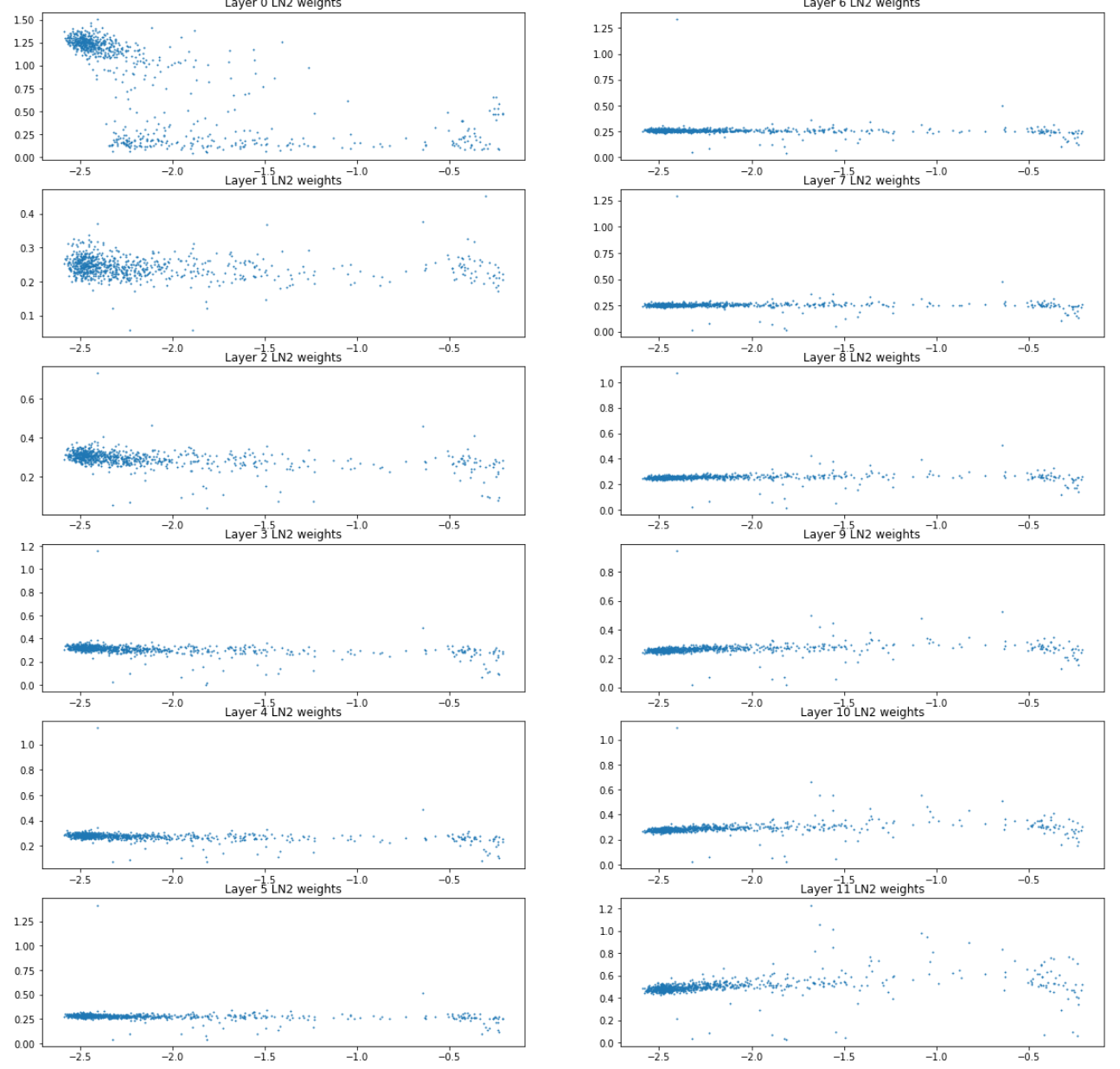
Note that the layer-0 gains dial down the position-heavy channel dims (the cluster on the right) but then the later layers mostly just mess with a few outlier points.
Dimension 138, the unigram neuron?
Here’s a few LayerNorm (LN2) layers colored arbitrarily by channel dim:
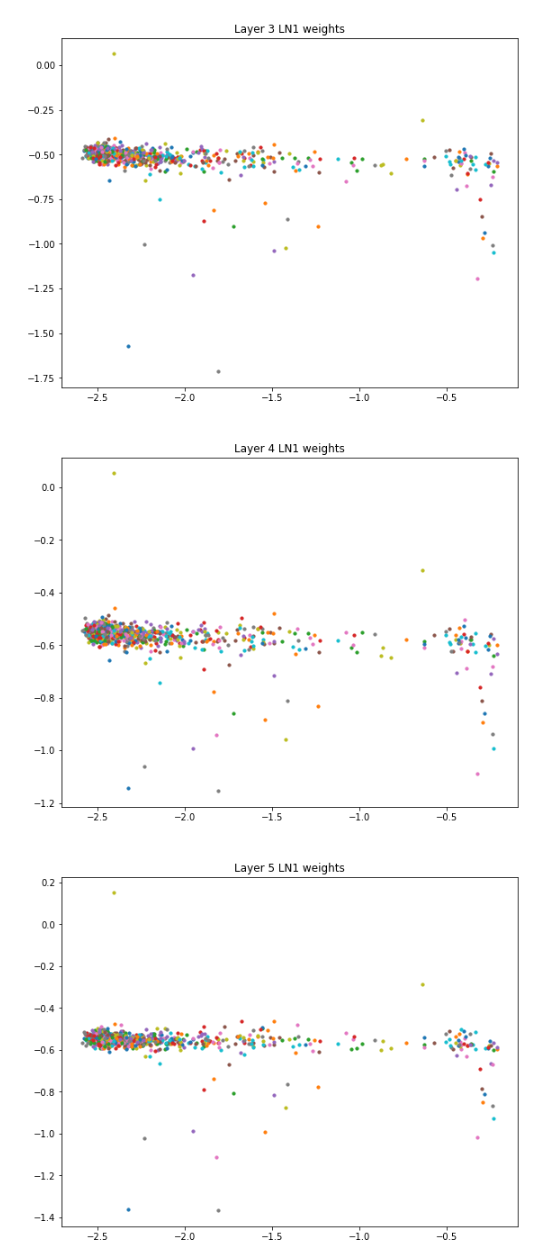
(The plot titles should say “LN2”, not “LN1”.)
What’s that pale green dot way up there on the left? It’s dim 138. It looks like GPT-2 wants its fully-connected layers to pay attention to that dimension.
Dim 138 is higher for tokens with short embedding vectors. This scatterplot has a point for each token:
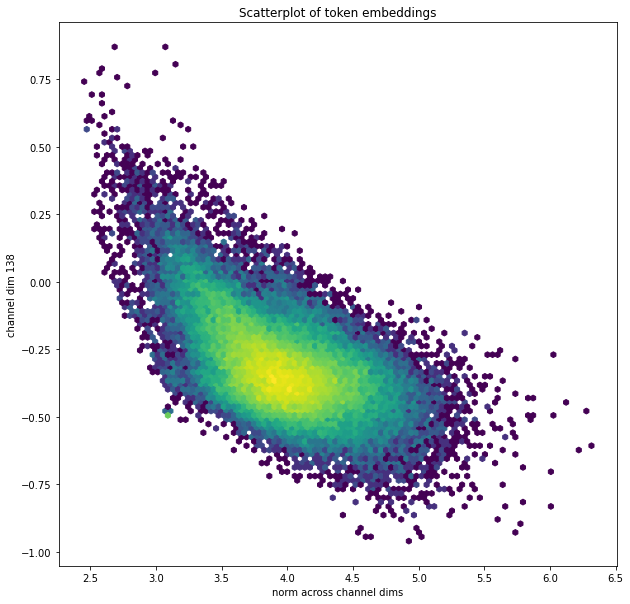
(See that bright green dot on the island at bottom left? We’ll come back to that.)
By the way, most channel dims don’t have a correlation like this, e.g. dim 137:

Also, dim 138 is higher on earlier tokens in the BPE vocab list:

These are both probably proxies for frequency in the corpus. (This is obvious for the token index, since BPE will add more common tokens first, but less obvious for embedding-vector length.)
This is OpenWebText data because it’s publicly available, but GPT-2 was trained on WebText which is a little different. Thanks to Noa Nabeshima for getting these token frequencies:
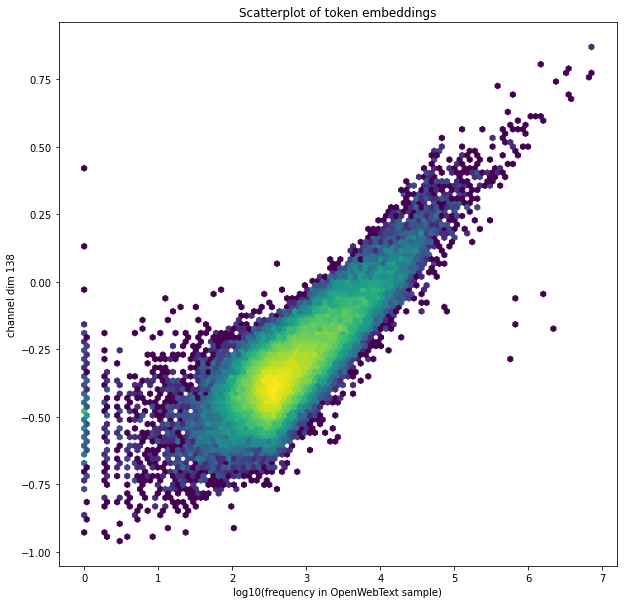
(What are those few outliers that buck the trend? The loose cluster of five to bottom-right are (UTF-8 fragments of) smart quotes, and the column of dots at top-left are…. Chinese or Japanese names of dragons in the popular mobile game Puzzle & Dragons. I’m tempted to put this down to differences between the contents of WebText and OpenWebText, and/or how they were processed. I figured out the Puzzle & Dragons thing by querying GPT-2 with the mystery tokens, but in the future it would be very cool to figure this sort of thing out directly from the weights without running any inference passes.)
So what does this tell us? Probably dim 138 has some special purpose in life, since it gets cranked up by the gain parameters in many layers. One guess is that the model makes predictions by adjusting a “zeroth-order” guess for each token, which is just the frequency in its training data, and 138 is where this guess lives. But this would be a great thing to look at within attention and MLP blocks to see what the model actually does with dim 138.
Another thing about 138: it has very little position-embedding presence, but the token embeddings are still very “off-center” (mean far from zero), which you can even see visually in the scatterplots. Also, it’s especially high-variance even for a “normal” channel dim. In the complicated "summary stats" plot of token and position embeddings, the upperleftmost blue and green dots are for dim 138. I think the nonzero mean here is related to the asymmetric distribution of log(frequency) for tokens: dim138 = 0 is near the middle of the scatterplot, but the lower half has far more tokens in it.
Also, it's worth noting that more common tokens have shorter embedding vectors on average. Noa suggests that longer vectors are more salient because they’re rarer and more information-rich. This is plausible, but kind of conflicts with the similar theory for dim 138, because 138 and vector length are only somewhat correlated. So we have two candidates for a "unigram frequency feature" in latent space, and soon we'll meet a third (SVD0).
One detail to keep in mind is that the overall magnitude of channel dims is only directly relevant in the identity path, and gets layernormalized away inside residual blocks.
SVD combinations of channel dims
The embedding matrix has entries W_ij = [channel dim i of the embedding of token j].
We can decompose this with SVD into , where S is a diagonal matrix of singular values and U, V are orthogonal matrices.
The first few rows V_nj for n = 0, 1, 2 are essentially projections of the embedding vectors of tokens onto the directions in the embedding space with the highest variance. (This is equivalent to running PCA on the channel dims.) These turn out to have useful properties!
SVD dim 0 is almost exactly the direction through the mean of the token embeddings. (This is because the mean vector is much larger than you'd expect for normally-distributed data.) Since the channel dims with nonzero mean seem to be the ones that are competing with position embeddings, it's possible that this SVD dim separates tokens that overlap a lot with position embeddings from those that don’t; I don’t know what that would imply semantically about those tokens.
The way I computed it, SVD0 is negative for all tokens; this doesn't mean anything.
The longest/shortest embedding vectors tend to also be extreme on SVD dim 0, which makes sense, since larger (more negative) SVD0 directly contributes to the vector norm. I haven't checked whether the effect is stronger than you'd expect from that.
Channel dim 138 also contributes a lot to SVD dim 0, so we now have three plausible candidates for the "frequency feature", which correlate with each other by varying amounts:
- Dim 138
- Embedding vector norm
- SVD0 (≃ token mean direction)
(Note from 2022: Ideally I'd have more numbers about the correlations here, but I'm prioritizing publishing this over getting my ancient code running again.)
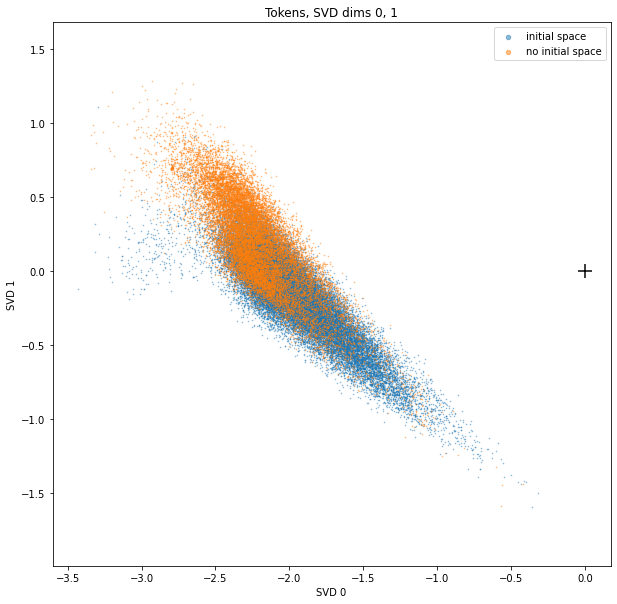
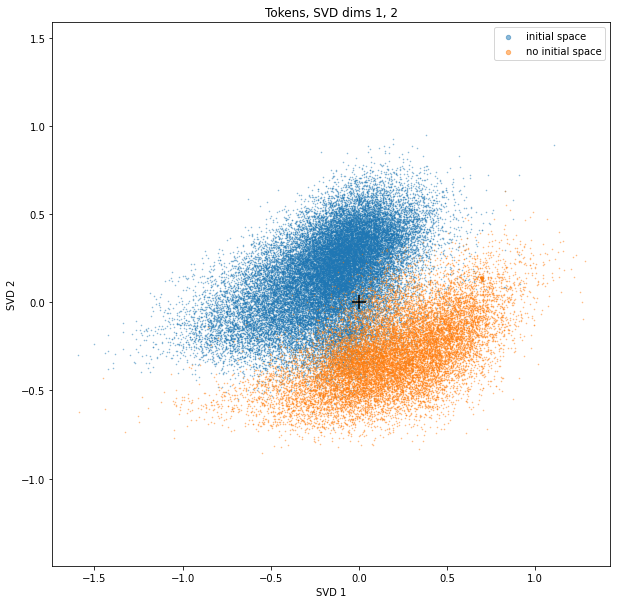
SVD dims 1 and 2 show a clear bimodal distribution of tokens. These two clusters turn out to be the tokens with or without initial spaces!
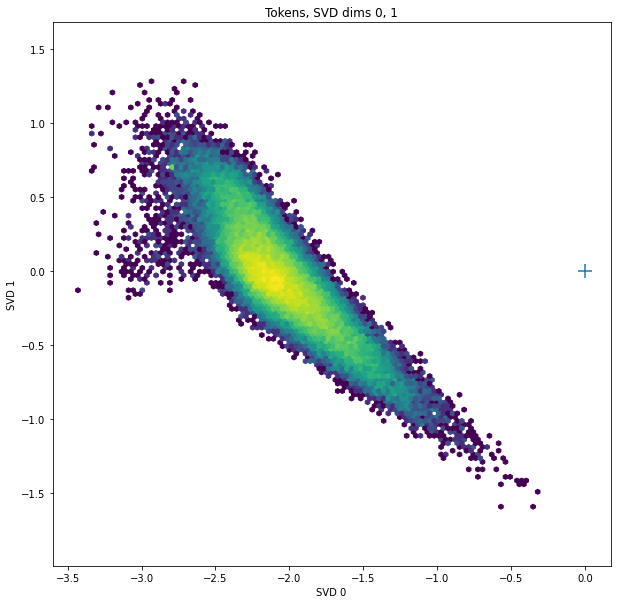
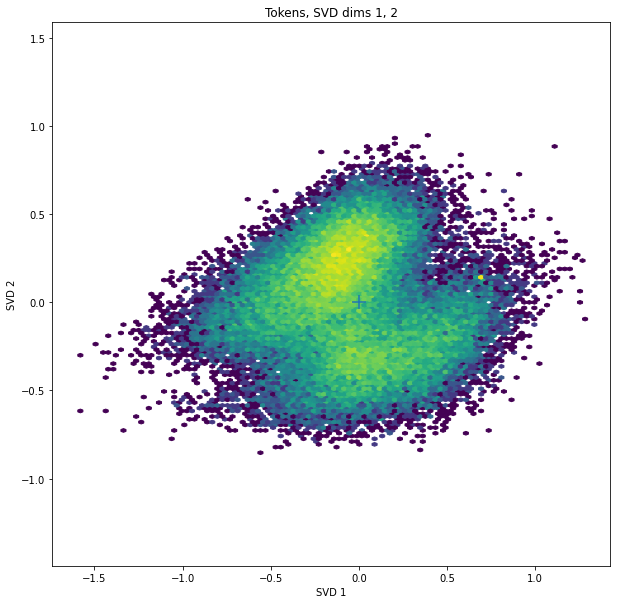
The plus-sign in the scatterplots marks the origin.
Weird outlier tokens and zero-layer GPT-2
While digging through the embedding weight, certain tokens showed up repeatedly as outliers on many axes. It is not entirely clear why they group together the way they do, but I have some guesses.
I first noticed these outliers while trying out a zero-layer version of GPT-2, just to see what would happen.
GPT-2 without any of its residual blocks is equivalent to W^T W, where W is the embedding matrix. This is symmetric, so it can’t even do bigram statistics properly, unlike transformers with separate embedding and unembedding matrices. It still has position embeddings, but we're going to ignore them. Also, since GPT-2 is obviously not trained for zero-layer performance, it’s not clear that it should do anything interesting in this setting anyway. Nevertheless, we're going to ask the question: what does zero-layer GPT-2 output, when given various tokens as input?
Note that the entries in W^T W are the dot products of the embedding vectors of tokens. If all embedding vectors were of the same length, then the largest value in each row of W^T W would be on the diagonal, so the highest logit at each output position would be for the token at the corresponding (shifted) input position.
In practice, almost all tokens follow this pattern, but there are exceptions. (In the images below, the tokens on the left produce the tokens on the right. I’ve left out additional examples of unprintable bytes – the question-mark glyphs – and of initial-space-removal.)

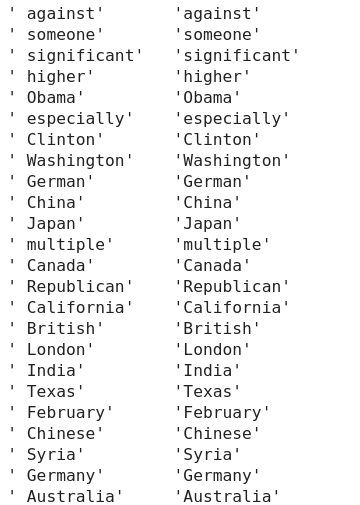

These token pairs (u, v) have embedding vectors that are nearly parallel and significantly different in length, |u| < |v|, such that (u . v) > (u . u).
For the space-removal case, this can be explained in terms of two facts:
- The tokens with and without the space have similar embedding vectors, presumably for semantic reasons.
- Tokens with spaces are smaller because the vector between the initial-space and no-space clusters is correlated with the mean of embedding vectors (SVD dim 0; see above).
The other cases are more confusing. Notably, `BuyableInstoreAndOnline` – the longer vector in many pairs – is one of the top-20 tokens by embedding vector length. It is also one of the five lowest tokens on channel dim 138. Per the results above, both of these properties might indicate that GPT-2 thinks this token is very uncommon and/or interesting.
Many of the confusing cases look like machine-readable text (from HTML/CSS/Javascript presumably). This seems consistent with the unprintable bytes, which could occur as part of a Unicode character in UTF-8 text, but show up more frequently in binary data. There might be accidental binary files in the training data or the data used to construct the tokenizer. (Also, many Unicode characters get their own multibyte tokens, so they wouldn't appear as individual bytes to GPT-2.)
`conservancy` is a surprisingly normal word. Maybe it shows up a lot in some sort of machine-readable text? One clue is that `natureconservancy` has one of the longest embedding vectors of any token. It seems to be part of the URLs of images on the Nature Conservancy’s website; I have no idea why GPT's tokenizer saw so many of these. Querying GPT-3 davinci at T=0 with `natureconservancy` yields this image URL, which is functional: http://natureconservancy-h.assetsadobe.com/is/image/content/dam/tnc/nature/en/photos/tnc_12681454_4000x2200.jpg?crop=0,0,2933,2200&wid=300&hei=225&scl=9.7777777777
{kind=link}

`BuyableInstoreAndOnline`, sampled with GPT-3 davinci at low temperature, produces things that appear in the HTML source of David’s Bridal item pages. Usually that's metadata for clothing items, including product IDs, color options, etc. GPT-3 especially likes this dress in Teal Blue: https://www.davidsbridal.com/product/short-sleeveless-all-over-lace-bridesmaids-dress-f18031

`ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ` is a sort of “eigenstring” of text encoding errors (mojibake) – it grows exponentially when encoded and decoded with different character encodings (usually Unicode vs. “ANSI”). You can see it in action here: https://paperbackbooks.com.au/p/children-s-ya-howl-s-moving-castle-fti
Many of the short vectors in these pairs have fairly similar low values on dim 138 and extremely similar short embedding-vector lengths, although neither of these properties are at the extreme tails of the token distribution.
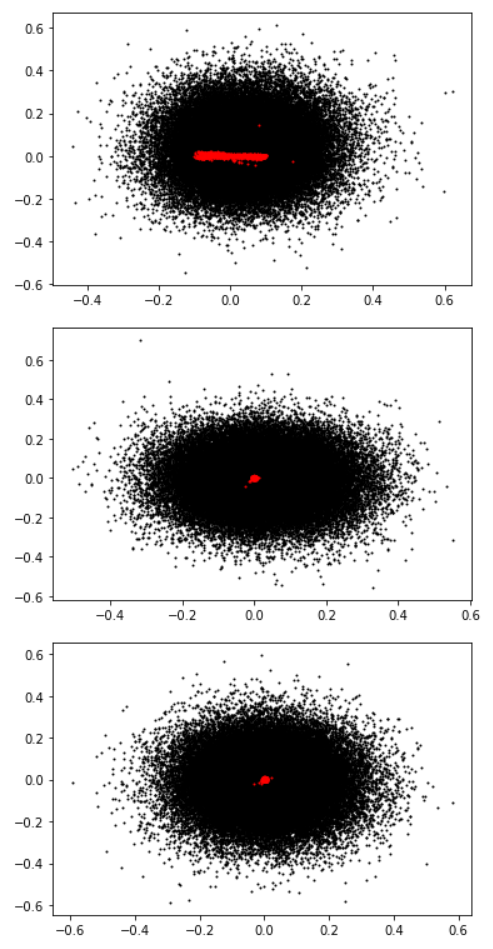
Note the clump at bottom-left of this scatterplot:
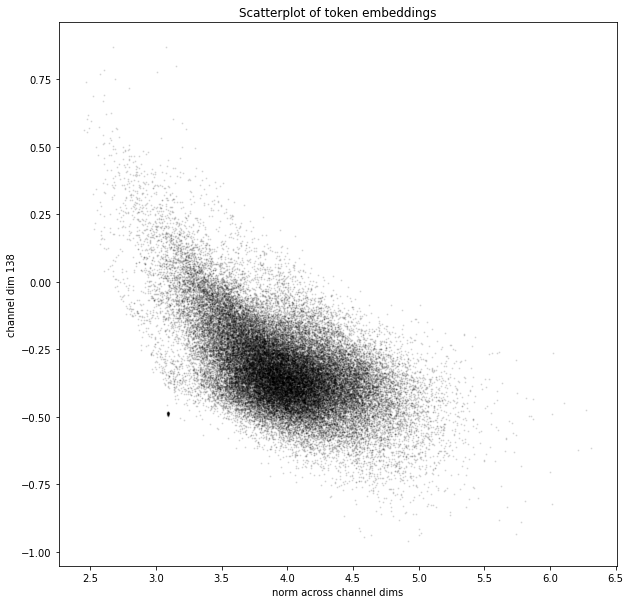
Zooming in and labelling the clump:

My best guess is that this crowded spot in embedding space is a sort of wastebasket for tokens that show up in machine-readable files but aren’t useful to the model for some reason. Possibly, these are tokens that are common in the corpus used to create the tokenizer, but not in the WebText training corpus. The oddly-specific tokens related to Puzzle & Dragons, Nature Conservancy, and David’s Bridal webpages suggest that BPE may have been run on a sample of web text that happened to have those websites overrepresented, and GPT-2 is compensating for this by shoving all the tokens it doesn’t find useful in the same place. (This is somewhat contradicted by the fact that GPT-3 davinci is perfectly happy to spit out coherent URLs and metadata when prompted with them, but that could just be because it's bigger and can afford to care about really obscure tokens.)
4 comments
Comments sorted by top scores.
comment by Noa Nabeshima (noa-nabeshima) · 2022-12-13T06:39:05.903Z · LW(p) · GW(p)
I think this post is great and I'm really happy that it's published.
comment by Martin Milan (martin-milan-1) · 2023-06-05T18:59:46.531Z · LW(p) · GW(p)
Is the source code available? (I tried searching for Colab, Github, ipynb, notebook)
comment by Adam Scherlis (adam-scherlis) · 2022-12-13T01:39:24.448Z · LW(p) · GW(p)
Image layout is a little broken. I'll try to fix it tomorrow.