Posts
Comments
If this is your implementation:
https://github.com/amudide/switch_sae/blob/main/dictionary_learning/trainers/switch.py
It looks like you when you encode you do a dense encoder forward pass and then mask using the expert router.
I think this means that the FLOP scaling laws claim is misleading because (my impression is that) your current train code uses much more FLOP than the scaling law graphs, because it calculates every expert's activations for every input.
But I think the empirical claims about the learned features and the FLOP scaling laws still should hold up for implementations that actually do the conditional computations.
I also expect H100/B100-time scaling charts than FLOP charts to be more informative for future work because I now think memory-bandwidth has decent odds of being the main bottleneck for training time.
One barrier to SAE circuits is that it's currently hard to understand how attention out SAE latents are calculated. Even if you do IG attribution patching to try to understand which earlier latents are relevant to the attention out SAE latents, it doesn't tell you how these latents interact inside the attention layer at all.
Auto-interp is currently really really bad
I think o1 is the only model that seems to perform decently at auto-interp but it's very expensive! IE $1/latent label. This is frustrating to me.
TinyModel SAEs have these first entity and second entity latents.
E.g. if the story is 'Once upon a time Tim met his friend Sally.', Tim is the first entity and Sally is the second entity. The latents fire on all instances of first|second entity after the first introduction of that entity.
I think I at one point found an 'object owned by second entity' latent but have had trouble finding it again.
I wonder if LMs are generating these reusable 'pointers' and then doing computation with the pointers. For example to track that an object is owned by the first entity, you just need to calculate which entities are instances of the first entity, calculate when first entity is shown to own an object and write 'owned by first entity' to the object token, and then broadcast that forward to other instances of the object. Then, if you have the tokens Tim|'s
(and 's has calculated that the first entity is immediately before it), 's can, with a single attention head, look for objects owned by the first entity.
This means that the exact identity information of the object (e.g. ' hammer') and the exact identity information of the first entity (' Tim') don't need to be passed around in computations, you can just do much cheaper pointer calculations and grab the relevant identity information when necessary.
This suggests a more fine-grained story for what duplicate name heads are doing in IOI.
You know I was thinking ab this-- say that there are two children and they're orthogonal to the parent and each have probability 0.4 given the parent. If you imagine the space it looks like three clusters, two with probability 0.4, norm 1.4 and one with probability 0.2 and norm 1. They all have high cosine similarity with each other. From this frame, having the parent 'include' the children directions a bit doesn't seem that inappropriate. One SAE latent setup that seems pretty reasonable is to actually have one parent latent that's like "one of these three clusters is active" and three child latents pointing to each of the three clusters. The parent latent decoder in that setup would also include a bit of the child feature directions.
This is all sketchy though. It doesn't feel like we have a good answer to the question "How exactly do we want the SAEs to behave in various scenarios?"
This is cool! I wonder if it can be fixed. I imagine it could be improved some amount by nudging the prefix distribution, but it doesn't seem like that will solve it properly. Curious if this is a large issue in real LMs. It's frustrating that there aren't ground-truth features we have access to in language models.
I think how large of a problem this is can probably be inferred from a description of the feature distribution. It'd be nice to have a better sense of what that distribution is (assuming the paradigm is correct enough).
Tree Methodology
To generate the trees in sparselatents.com/tree_view, I use a variant of Masked Cosine Similarity (MCS), a metric introduced in Towards Monosemanticity. The original MCS is calculated like this: For any two latents A and B, first compute the cosine similarity between their activations, but only considering tokens where latent A is active. Then compute the same similarity, but only for tokens where latent B is active. The final MCS value is the larger of these two similarities.
Instead of taking the max, I do a directed MCS where I just consider the cosine similarity between A and B's activations on tokens where B is active. Then, I multiply this directed MCS score by max(B activations)/max(A activations) to ignore latents that don't fire very much. I'm not sure that this multiplication step is necessary.
I also use a higher threshold of 0.6.
Starting from a parent latent, say S/1/12, I find all latents in a larger-width SAE (say S/2) that pass the directed MCS threshold. Then, I re-apply the method to those S/2 latents to find children in S/3.
The result is often a non-tree DAG as some of the identified latents in S/3 have more than one parent in S/2. To simplify rendering, I assign these latents to the parent they have the highest score with. This obscures the true structure, but I wasn't sure of a clean way to automatically render these DAGs.
The trees should be thought of not as fully displaying the structure of the model, but instead of surfacing small sets of latents that I expect demonstrate feature absorption when viewed together.
The Matryoshka SAE trained on the toy model learn the true features on most runs, not all of them. Sometimes a small number of latents, modally one, seem to get stuck in a bad state.
I thought I had some informal evidence that permuting the latents was good and after double checking some evidence I don't feel confident that it is good.
Training without permutation seems to attain slightly better FVU/L0, has reasonable looking features at a quick glance, seems to solve the toy model at comparable rates to permuted, and is simpler to code.
This is great work! I like that you tested on large models and your very comprehensive benchmarking. I also like the BatchTopK architecture.
It's interesting to me that MSE has a smaller hit than cross-entropy.
Here are some notes I made:
We suspect that using a fixed group size leads to more stable training and faster convergence.
This seems plausible to me!
Should the smallest sub-SAE get gradients from all losses, or should the losses from larger sub-SAEs be stopped?
When I tried stopping the gradient from flowing from large sub-SAE losses to small it made later latents much less interpretable. I tried an approach where early latents got less gradient from larger sub-SAE losses and it seemed to also have less interpretable late latents. I don't know what's going on with this.
What is the effect of latent sorting that Noa uses on the benchmarks?
I tried not ordering the latents and it did comparably on FVU/L0. I vaguely recall that for mean-max correlation, permuting did worse on early latents and better on the medium latents. At a quick glance I weakly preferred the permuted SAE latents but it was very preliminary and I'm not confident in this.
I'd love to chat more with the authors, I think it'd be fun to explore our beliefs and process over the course of making the papers and compare notes and ideas.
Even with all possible prefixes included in every batch the toy model learns the same small mixing between parent and children (this was best out of 2, for the first run the matryoshka didn't represent one of the features): https://sparselatents.com/matryoshka_toy_all_prefixes.png
Here's a hypothesis that could explain most of this mixing. If the hypothesis is true, then even if every possible prefix is included in every batch, there will still be mixing.
Hypothesis:
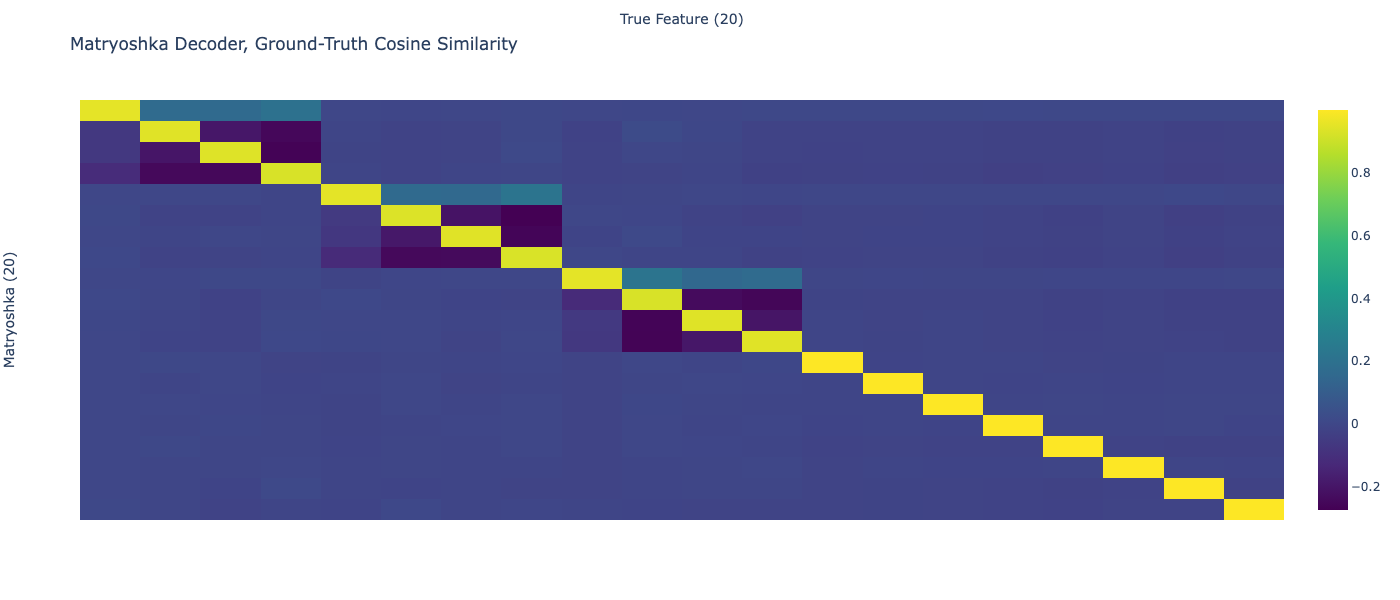{kind=link}
Regardless of the number of prefixes, there will be some prefix loss terms where
1. a parent and child feature are active
2. the parent latent is included in the prefix
3. the child latent isn't included in the prefix.
The MSE loss in these prefix loss terms is pretty large because the child feature isn't represented at all. This nudges the parent to slightly represent all of its children a bit.
To compensate for this, if a child feature is active and the child latent is included the prefix, it undoes the parent decoder vector's contribution to the features of the parent's other children.
This could explain these weird properties of the heatmap:
- Parent decoder vector has small positive cosine similarity with child features
- Child decoder vectors have small negative cosine similarity with other child features
Still unexplained by this hypothesis:
- Child decoder vectors have very small negative cosine similarity with the parent feature.
That's very cool, I'm looking forward to seeing those results! The Top-K extension is particularly interesting, as that was something I wasn't sure how to approach.
I imagine you've explored important directions I haven't touched like better benchmarking, top-k implementation, and testing on larger models. Having multiple independent validations of an approach also seems valuable.
I'd be interested in continuing this line of research, especially circuits with Matryoshka SAEs. I'd love to hear about what directions you're thinking of. Would you want to have a call sometime about collaboration or coordination? (I'll DM you!)
Really looking forward to reading your post!
Yes, follow up work with bigger LMs seems good!
I use number of prefix-losses per batch = 10 here; I tried 100 prefixes per batch and the learned latents looked similar at a quick glance, so I wonder if naively training with block size = 1 might not be qualitatively different. I'm not that sure and training faster with kernels on its own seems good also!
Maybe if you had a kernel for training with block size = 1 it would create surface area for figuring out how to work on absorption when latents are right next to each other in the matryoshka latent ordering.
I really enjoy chatting with Logan about interpretability research.
It'd be funny if stomach gendlin focusing content was at least partially related to worms or other random physical stuff
I tried this a week ago and I am constipated for what I think might be the first time in years but am not sure. I also think I might have less unpleasant stomach sensation overall.
23&me says I have more Neanderthal DNA than 96% of users and my DNA attribution is half-Japanese and half European. Your Neanderthal link doesn't work for me.
Sometimes FLOP/s isn't the bottleneck for training models; e.g. it could be memory bandwidth. My impression from poking around with Nsight and some other observations is that wide SAEs might actually be FLOP/s bottlenecked but I don't trust my impression that much. I'd be interested in someone doing a comparison of this SAE architectures in terms of H100 seconds or something like that in addition to FLOP.
Did it seem to you like this architecture also trained faster in terms of wall-time?
Anyway, nice work! It's cool to see these results.
I wonder if multiple heads having the same activation pattern in a context is related to the limited rank per head; once the VO subspace of each head is saturated with meaningful directions/features maybe the model uses multiple heads to write out features that can't be placed in the subspace of any one head.
Do you have any updates on this? I'm interested in this.
I've trained some sparse MLPs with 20K neurons on a 4L TinyStories model with ReLU activations and no layernorm and I took a look at them after reading this post. For varying integer , I applied an L1 penalty of on the average of the activations per token, which seems pretty close to doing an L1 of on the sum of the activations per token. Your L1 of with 12K neurons is sort of like in my setup. After reading your post, I checked out the cosine similarity between encoder/decoder of original mlp neurons and sparse mlp neurons for varying values of (make sure to scroll down once you click one of the links!):
S=3
https://plotly-figs.s3.amazonaws.com/sparse_mlp_L1_2exp3
S=4
https://plotly-figs.s3.amazonaws.com/sparse_mlp_L1_2exp4
S=5
https://plotly-figs.s3.amazonaws.com/sparse_mlp_L1_2exp5
S=6
https://plotly-figs.s3.amazonaws.com/sparse_mlp_L1_2exp6
I think the behavior you're pointing at is clearly there at lower L1s on layers other than layer 0 (? what's up with that?) and sort of decreases with higher L1 values, to the point that the behavior is there a bit at S=5 and almost not there at S=6. I think the non-dead sparse neurons are almost all interpretable at S=5 and S=6.
Original val loss of model: 1.128 ~= 1.13.
Zero ablation of MLP loss values per layer: [3.72, 1.84, 1.56, 2.07].
S=6 loss recovered per layer
Layer 0: 1-(1.24-1.13)/(3.72-1.13): 96% of loss recovered
Layer 1: 1-(1.18-1.13)/(1.84-1.13): 93% of loss recovered
Layer 2: 1-(1.21-1.13)/(1.56-1.13): 81% of loss recovered
Layer 3: 1-(1.26-1.13)/(2.07-1.13): 86% of loss recovered
Compare to 79% of loss-recovered from Anthropic's A/1 autoencoder with 4K features and a pretty different setup.
(Also, I was going to focus on S=5 MLPs for layers 1 and 2, but now I think I might instead stick with S=6. This is a little tricky because I wouldn't be surprised if tiny-stories MLP neurons are interpretable at higher rates than other models.)
Basically I think sparse MLPs aren't a dead end and that you probably just want a higher L1.

This link is a broken
This is great.
[word] and [word]
can be thought of as "the previous token is ' and'."
It might just be one of a family of linear features or ?? aspect of some other representation ?? corresponding to what the previous token is, to be used for at least induction head.
Maybe the reason you found ' and' first is because ' and' is an especially frequent word. If you train on the normal document distribution, you'll find the most frequent features first.
Consistency models are trained from scratch in the paper in addition to distilled from diffusion models. I think it'll probably just work with text-conditioned generation, but unclear to me w/o much thought how to do the equivalent of classifier-free guidance.
seems related to: https://arxiv.org/pdf/2303.01469.pdf
I think this post is great and I'm really happy that it's published.
I really appreciate this work!
I wonder if the reason MLPs are more polysemantic isn't because there are fewer MLPs than heads but because the MLP matrices are larger--
Suppose the model is storing information as sparse [rays or directions]. Then SVD on large matrices like the token embeddings can misunderstand the model in different ways:
- Many of the sparse rays/directions won't be picked up by SVD. If there are 10,000 rays/directions used by the model and the model dimension is 768, SVD can only pick 768 directions.
- If the model natively stores information as rays, then SVD is looking for the wrong thing: directions instead of rays. If you think of SVD as a greedy search for the most important directions, the error might increase as the importance of the direction decreases.
- Because the model is storing things sparsely, it can squeeze in far more meaningful directions than the model dimension. But these directions can't be perfectly orthogonal, they have to interfere with each other at least a bit. This noise could make SVD with large matrices worse and also means that the assumptions involved in SVD are wrong.
As evidence for the above story, I notice that the earliest PCA directions on the token embeddings are interpretable, but they quickly become less interpretable?
Maybe because the QK/OV matrices have low rank they specialize in a small number of the sparse directions (possibly greater than their rank) and have less interference noise. These could contribute to interpretability of SVD directions.
You might expect in this world that the QK/OV SVD directions would be more interpretable than the MLP matrices which would in turn be more interpretable than the token embedding SVD.
I think at least some GPT2 models have a really high-magnitude direction in their residual stream that might be used to preserve some scale information after LayerNorm. [I think Adam Scherlis originally mentioned or showed the direction to me, but maybe someone else?]. It's maybe akin to the water-droplet artifacts in StyleGAN touched on here: https://arxiv.org/pdf/1912.04958.pdf
We begin by observing that most images generated by StyleGAN exhibit characteristic blob-shaped artifacts that resemble water droplets. As shown in Figure 1, even when the droplet may not be obvious in the final image, it is present in the intermediate feature maps of the generator.1 The anomaly starts to appear around 64×64 resolution, is present in all feature maps, and becomes progressively stronger at higher resolutions. The existence of such a consistent artifact is puzzling, as the discriminator should be able to detect it. We pinpoint the problem to the AdaIN operation that normalizes the mean and variance of each feature map separately, thereby potentially destroying any information found in the magnitudes of the features relative to each other. We hypothesize that the droplet artifact is a result of the generator intentionally sneaking signal strength information past instance normalization: by creating a strong, localized spike that dominates the statistics, the generator can effectively scale the signal as it likes elsewhere. Our hypothesis is supported by the finding that when the normalization step is removed from the generator, as detailed below, the droplet artifacts disappear completely.
No, I'm pretty confident every expert is a neural network policy trained on the task. See "F. Data Collection Details" and the second paragraph of "3.3. Robotics - RGB Stacking Benchmark (real and sim)"
What software did you use to produce this diagram?
How much influence and ability you expect to have as an individual in that timeline.
For example, I don't expect to have much influence/ability in extremely short timelines, so I should focus on timelines longer than 4 years, with more weight to longer timelines and some tapering off starting around when I expect to die.
How relevant thoughts and planning now will be.
If timelines are late in my life or after my death, thoughts, research, and planning now will be much less relevant to the trajectory of AI going well, so at this moment in time I should weight timelines in the 4-25 year range more.
Value-symmetry: "Will AI systems in the critical period be equally useful for different values?"
This could fail if, for example, we can build AI systems that are very good at optimizing for easy-to-measure values but significantly worse at optimizing for hard to measure values. It might be easy to build a sovereign AI to maximize the profit of a company, but hard to create one that cares about humans and what they want.
Evan Hubinger has some operationalizations of things like this here and here.
Open / Closed: "Will transformative AI systems in the critical period be publicly available?"
A world where everyone has access to transformative AI systems, for example by being able to rent them (like GPT-3's API once it's publicly available), might be very different from one where they are kept private by one or more private organizations.
For example, if strategy stealing doesn't hold, this could dramatically change the distribution of power, because the systems might be more helpful for some tasks and values than others.
This variable could also affect timelines estimates if publicly accessible TAI systems increase GDP growth, among other effects it could have on the world.
Deceptive alignment: “In the critical period, will AIs be deceptive?”
Within the framework of Risks from Learned Optimization, this is when a mesa-optimizer has a different objective than the base objective, but instrumentally optimizes the base objective to deceive humans. It can refer more generally to any scenario where an AI system behaves instrumentally one way to deceive humans.
Alignment tax: “How much more difficult will it be to create an aligned AI vs an unaligned AI when it becomes possible to create powerful AI?”
If the alignment tax is low, people have less incentive to build an unaligned AI as they'd prefer to build a system that's trying to do what they want. Then, to increase the probability that our AI trajectory goes well, one could focus on how to reduce the alignment tax.