My best guess at the important tricks for training 1L SAEs
post by Arthur Conmy (arthur-conmy) · 2023-12-21T01:59:06.208Z · LW · GW · 4 commentsContents
Summary
Background: L0 / Loss Recovered Trade-Off
Tricks
1. SAE Width
2. Resampling
3. Periodic LR warmup
4. Learning Rate
5. Shuffling
Appendix: miscellaneous training details and comments
None
4 comments
TL;DR: this quickly-written post gives a list of my guesses of the most important parts of training a Sparse Autoencoder on a 1L Transformer, with open source links
Summary
In this post I give my best guesses for the relative importance of 5 components of training SAEs on Neel’s 1L GELU transformer [LW · GW] from some experiments I ran a month ago.
In short, I currently think that the most important parts of the recipe are, in order,
- SAE width
- Resampling
- (Not in Anthropic’s paper!) LR decrease and rewarmup at the start of training and after resampling
- Learning Rate
- Shuffling (... not important?)
I will evaluate all these claims with the L0 and loss recovered metrics. Obviously, this doesn’t necessarily capture how interpretable or useful the SAEs are. Interpretability and usefulness are the most important metrics, but I’m not using them as they are much harder to calculate.
The intention of this post is a quick research artifact and therefore I have not polished the graphs or red-teamed findings. Further, due to only writing this post-hoc, many runs were stopped prematurely. In the appendix I check and I'm pretty sure there aren't cases where undertraining could explain any of the observations. Please comment/DM when inevitably things are not clear, if you’re interested. I’m publishing the blog post messily rather than not at all.
Background: L0 / Loss Recovered Trade-Off
L0 is defined as the average number of sparse dictionary features activated per token. Loss recovered is the affine rescaling of the average test loss (on held-out text data) when splicing SAE outputs into forward passes such that 0% loss recovered is the loss when zero ablating the MLP and 100% loss recovered is the language model's test loss. See here [? · GW] but note we're using a zero baseline not a random baseline.
Shown: Anthropic’s results on L0 and loss-recovered for various SAEs (the constant L1 lines correspond to increasing SAE widths – this is the most important part of training good SAEs):
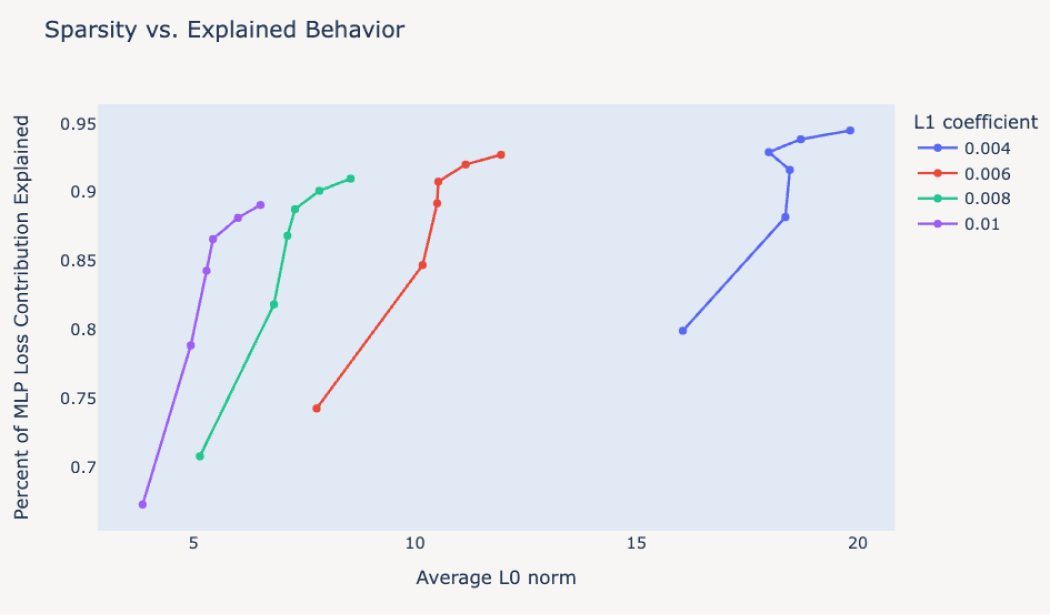
From Anthropic’s paper
Tricks
1. SAE Width
Making the SAEs wide is crucial for high loss recovered / low L0. Note that Anthropic mainly analyse a narrow SAE in their paper; personally I worry about doing interpretability with ~79% loss recovered. The discussion here [LW · GW] is useful for thinking about how much loss we want recovered (in short: a zero ablation baseline is really weak, so we want high, >90% loss recovered. I don't fully endorse any argument in that discussion though).
2. Resampling
Resampling neurons, as Anthropic do, is also important for improving the loss recovered / L0 trade-off. I regularly observe cases where this step increases loss recovered while barely increasing L0.
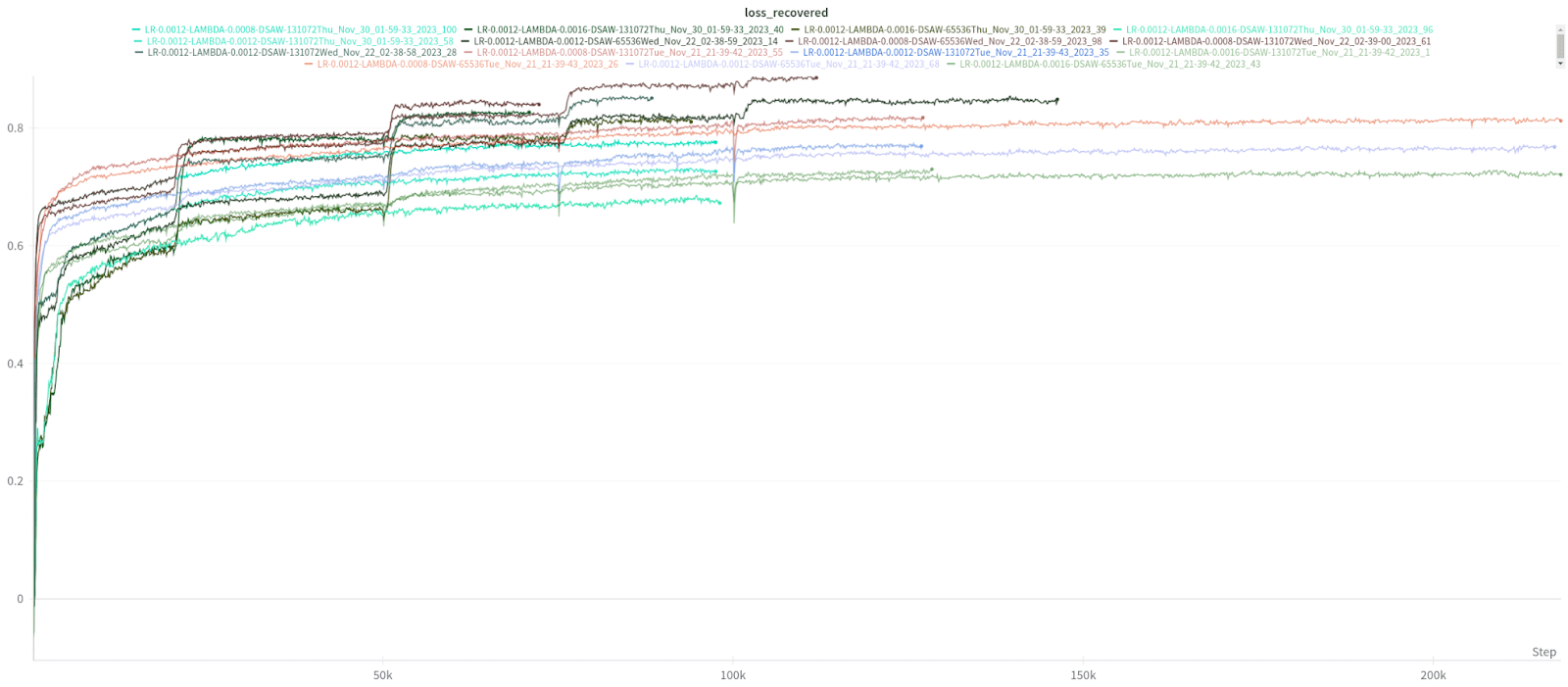
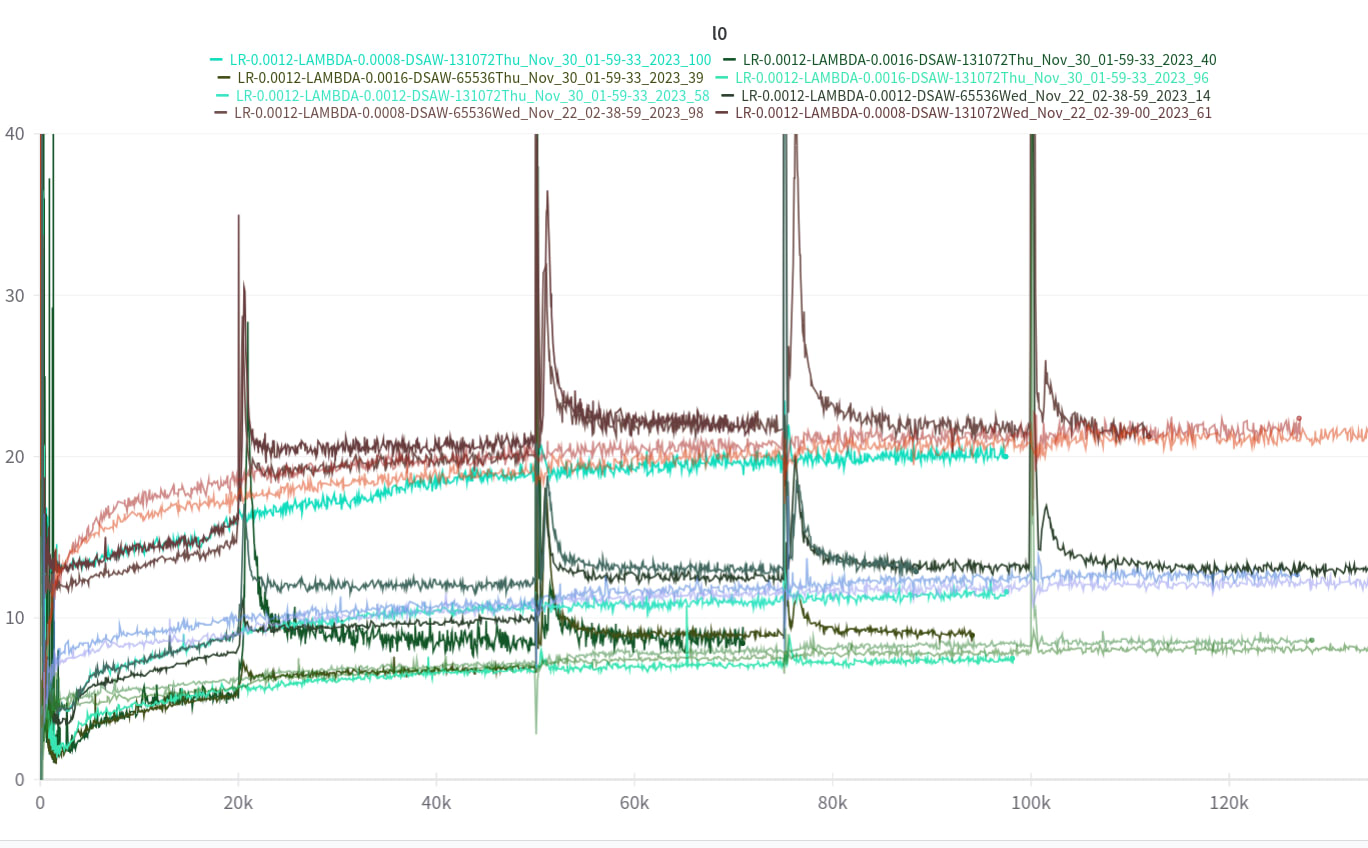
Across almost all runs studied in this post, the resample points (at 20k, 50k, 75k and 100k) have big increases in loss recovered. The resample only cause a temporary large increase in L0. It recovers to only a slightly higher value fast:
I also compared doing normal reinitialization instead of a version of Anthropic’s fancy resampling (see the link here), and found that this was significantly worse, slightly decreasing L0 but decreasing loss recovered a lot. I just tested this on several 131K width SAEs:

The turquoise points are the runs with ordinary resampling; the red/green/blue points have Anthropic resampling. (The lighter red/green/blue points are runs where LR warmups were not applied (see point 3), but these do have Anthropic resampling. We see that LR warmup is helpful. But not as crucial as Anthropic resampling).
3. Periodic LR warmup
I added LR warmup (cosine schedule) to both the start of training and immediately after resampling (for 1000 steps in both cases). Visually:
image widget
In words: we start with 1/10 the normal learning rate and increase it to normal over 1000 steps. Immediately after resampling, we times the learning rate by 1/10 and again warmup.
Note that Sam Marks’ implementation [LW · GW] has also done this concurrently.
As addressed above, this results in a reasonable jump in loss recovered for the 131K width SAEs, and we also tested this with 65K width SAEs.

Light red/green/blue: no LR warmup. Dark: LR warmup at the start and when we resample.
4. Learning Rate
(I'm not completely sure of this result due to stopping these runs early)
As Anthropic mention somewhere in the paper, low LR decreases the chances of killing neurons fast:
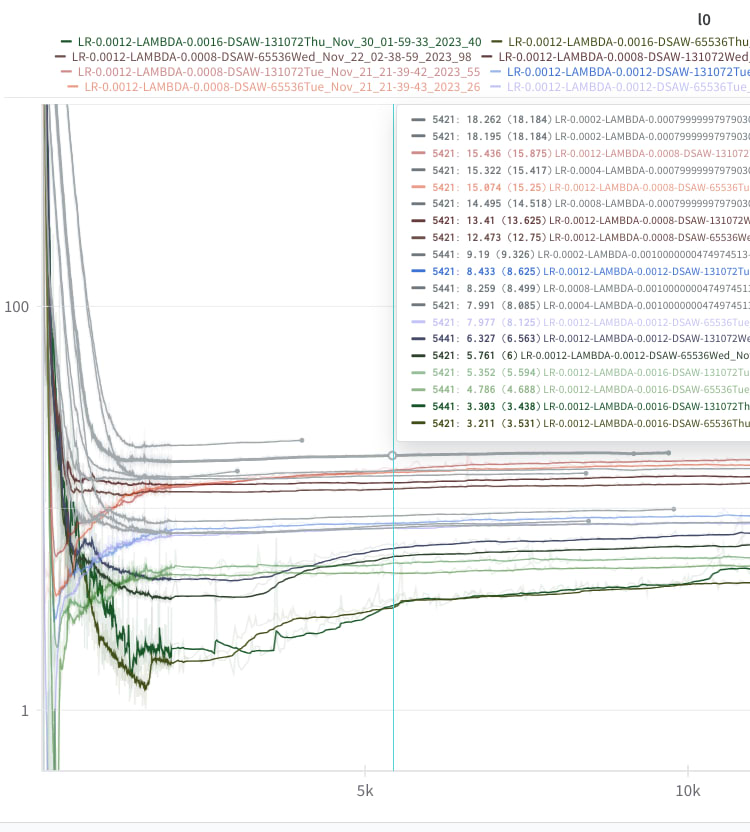
Grey runs have lower learning rates than all others in this post.
However, these runs with lower learning rate seemed to converge to higher L0 without better loss recovered, so I just used 1.2 * 10**(-3) which was already bigger than Anthropic (their learning rate is 10**(-3)). Differences didn’t seem large, hence this is 4. Furthermore, all data I found post-hoc was terminated super early, so I'm not confident about this hyperparameter choice.
5. Shuffling
Usually, I had a buffer of 2^19 tokens which was shuffled, inspired by Neel’s implementation here [LW · GW]. I expected deleting the shuffling to make training much worse. Instead, the three SAEs with no shuffling seemed better than the dark/red/green blue training runs with all optimal 1-4 choices made:

Yellow points involve no shuffling, and are all on the Pareto frontier(!)
...huh?
I checked that my test and training splits are different. I still use HuggingFace datasets load_dataset with streaming, which defaults to shuffling document order, but this still gives high inter-batch correlation. In one other early result on another model in another repo, I've found it ambiguous whether shuffling improves or worsens performance, but either way the effect size doesn't seem that big. Anthropic think that this process is important. This is still very surprising to me, and I'm not recommending shuffling is thrown out, yet!
Here’s the link to my code and the wandb.
You may like the two low L0 SAEs here and here (of two different sizes) from the shuffled run – I expect that many features are single token features, but after filtering them out there may be interesting findings. They’re more than 10x as sparse as Neel’s SAEs by L0.
Appendix: miscellaneous training details and comments
All models use these same training details as Anthropic, except they use Periodic LR Warmup (3.) and:
- SAE batch size: 4096
- This allows you to calculate the number of tokens seen by timesing the step (on some x axes) by 4096.
- I average the L2 loss over the SAE input dimension (guessing this will scale better)
- L1 regularization lambdas (ie coefficient for L1 loss): 0.008, 0.012, 0.016
- Num training steps: generally above 60k
- Note that this means most runs were only trained on 245M tokens, rather than 20B like Anthropic (!)
- Generally, loss recovered and L0 plateaued (though there were sometimes slight improvements from the 75k, 100k loss recovered points), so I don't think conclusions will be changed much
- Some runs were on fewer training steps (e.g LR ablations and the shuffling runs), but either this is not important (LR ablations) or it makes results seem stronger (e.g that shuffling is even better, the runs with no LR warmup were trained longer too)
- Note that this means most runs were only trained on 245M tokens, rather than 20B like Anthropic (!)
- Token generation sequence length: 128
- Ideally should have been larger, this just accidentally stuck from early testing
- Test batch size: a deterministic set (I'm pretty sure) of 100 (really this should be larger, but I would be surprised if this changed conclusions a lot
- Resamples at 20k, 50k, 75k and 100k steps
- No geometric median resample
- The exact selection of low loss points for Anthropic resampling is slightly different to make memory requirements easy
4 comments
Comments sorted by top scores.
comment by Joseph Bloom (Jbloom) · 2023-12-21T10:55:16.415Z · LW(p) · GW(p)
Thanks. I've found this incredibly useful. This is something that I feel has been long overdue with SAE's! I think the value from advice + (detailed) results + code is something like 10x more useful than the way these insights tend to be reported!
comment by Noa Nabeshima (noa-nabeshima) · 2023-12-21T07:31:40.287Z · LW(p) · GW(p)

This link is a broken
Replies from: arthur-conmy↑ comment by Arthur Conmy (arthur-conmy) · 2023-12-21T11:34:37.742Z · LW(p) · GW(p)
Thanks, fixed
comment by Noa Nabeshima (noa-nabeshima) · 2023-12-21T07:28:31.587Z · LW(p) · GW(p)
This is great.