Deepmind's Gato: Generalist Agent
post by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-12T16:01:21.803Z · LW · GW · 62 commentsContents
62 comments
From the abstract, emphasis mine:
The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stackblocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
(Will edit to add more as I read. ETA: 1a3orn [LW · GW] posted first [LW · GW].)
- It's only 1.2 billion parameters. (!!!) They say this was to avoid latency in the robot control task.
- It was trained offline, purely supervised, but could in principle be trained online, with RL, etc
- Performance results:
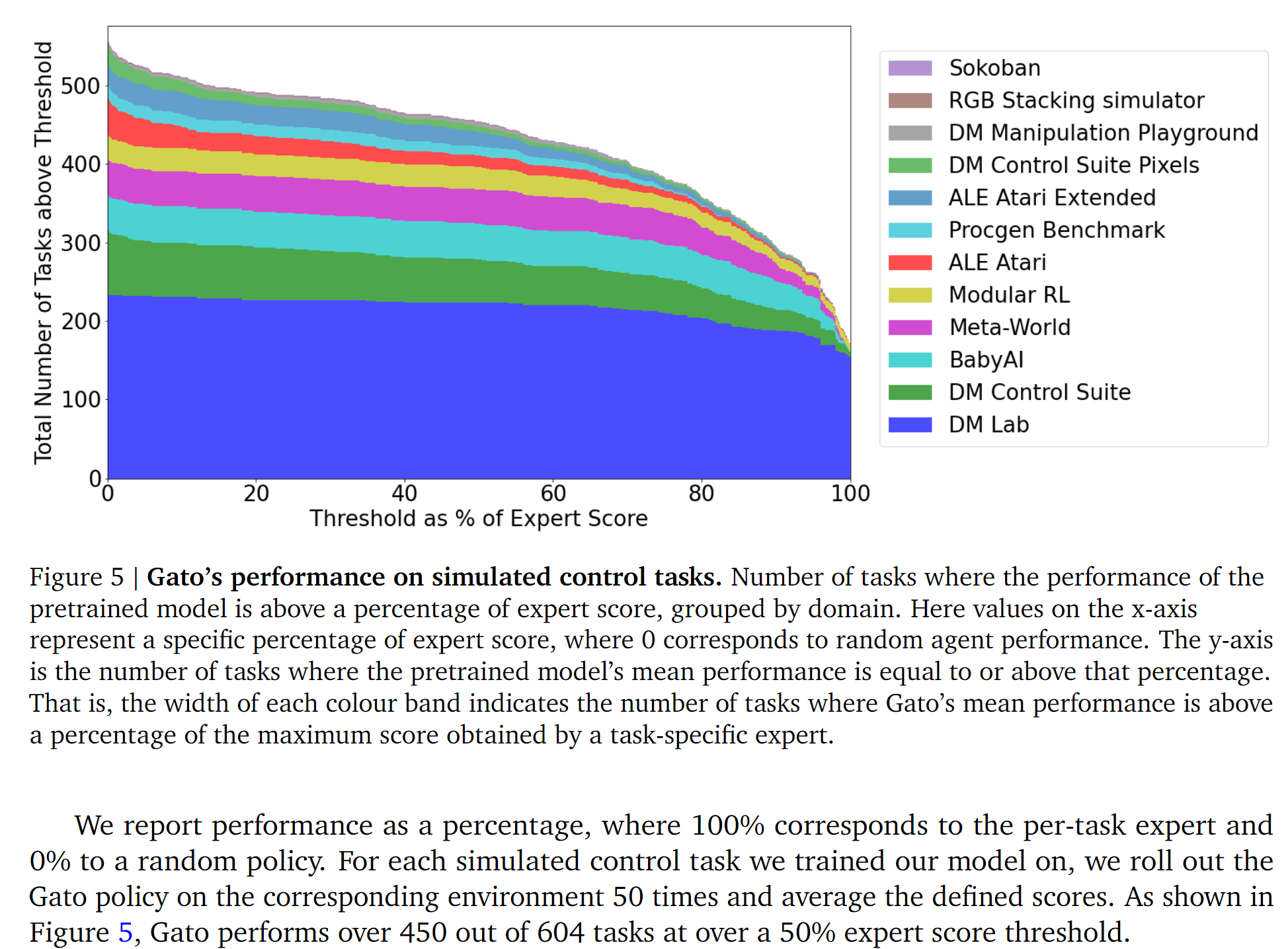
The section on broader implications is interesting. Selected quote:
In addition, generalist agents can take actions in the the physical world; posing new challenges that may require novel mitigation strategies. For example, physical embodiment could lead to users anthropomorphizing the agent, leading to misplaced trust in the case of a malfunctioning system, or be exploitable by bad actors. Additionally, while cross-domain knowledge transfer is often a goal in ML research, it could create unexpected and undesired outcomes if certain behaviors (e.g. arcade game fighting) are transferred to the wrong context. The ethics and safety considerations of knowledge transfer may require substantial new research as generalist systems advance. Technical AGI safety (Bostrom, 2017) may also become more challenging when considering generalist agents that operate in many embodiments. For this reason, preference learning, uncertainty modeling and value alignment (Russell, 2019) are especially important for the design of human-compatible generalist agents. It may be possible to extend some of the value alignment approaches for language (Kenton et al., 2021; Ouyang et al., 2022) to generalist agents. However, even as technical solutions are developed for value alignment, generalist systems could still have negative societal impacts even with the intervention of well-intentioned designers, due to unforeseen circumstances or limited oversight (Amodei et al., 2016). This limitation underscores the need for a careful design and a deployment process that incorporates multiple disciplines and viewpoints.
They also do some scaling analysis and yup, you can make it smarter by making it bigger.
What do I think about all this?
Eh, I guess it was already priced in. I think me + most people in the AI safety community would have predicted this. I'm a bit surprised that it works as well as it does for only 1.2B parameters though.
62 comments
Comments sorted by top scores.
comment by gwern · 2022-05-12T16:55:32.508Z · LW(p) · GW(p)
The two major points I take away:
-
Scaling Just Works: as blase as we may now be at seeing 'lines go straight', I continue to be shocked in my gut that they do just keep going straight and something like Gato can be as straightforward as 'just train a 1.2b-param Transformer on half a thousand different tasks, homes, nbd' and it works exactly like you'd think and the scaling curve looks exactly like you'd expect. It is shocking how unshocking the results are conditional on a shocking thesis (the scaling hypothesis). So many S-curves and paradigms hit an exponential wall and explode, but DL/DRL still have not. We should keep this in mind that every time we have an opportunity to observe scaling explode in a giant fireball, and we don't.
-
Multi-task learning is indeed just another blessing of scale: as they note, it used to be that learning multiple Atari games in parallel was really hard. It did not work, at all. You got negative transfer even within ALE. People thought very hard and ran lots of experiments to try to create things like Popart less than 4 years ago where it was a triumph that, due to careful engineering a single checkpoint could play just the ALE-57 games with mediocre performance.
Decision Transformer definitely made 'multi-task learning is a blessing of scale' the default hypothesis, but no one had actually shown this, the past DT and other work (aside from MetaMimic) were all rather low n and k; you could wonder if they would interfere at a certain point or break down, and require fancy engineering like MoEs to enable learning at all. (Similarly, Andy Jones showed nice scaling laws for DRL and I scraped together a few examples like Ms Pacman, but nothing across really complicated tasks or many tasks.)
Now you can throw in not just ALE, but DMLab, Metaworld, Procgen, hell, let's just throw in a bunch of random Internet scraped text and images and captions and treat those as 'reinforcement learning tasks' too why not, and to make them all play together you do... nothing, really, you just train on them all simultaneously with a big model in about the dumbest way possible and it works fine.
(Also, if one had any doubts, DM is now fully scale-pilled.)
Replies from: ryan_b, gwern, mocny-chlapik↑ comment by ryan_b · 2022-05-12T19:39:31.229Z · LW(p) · GW(p)
I share the gut-shock. This is really thumping me with the high dimensional world perspective. The dimensionality problem [LW · GW] is all:
They had to exercise unrealistic levels of standardization and control over a dozen different variables. Presumably their results will not generalize to real sleds on real hills in the wild.
But stop for a moment to consider the implications of the result. A consistent sled-speed can be achieved while controlling only a dozen variables. Out of literally billions.
But then the scaling hypothesis be like "Just allow for billions of variables, lol."
Are we actually any farther from game over than just feeding this thing the Decision Transformer papers and teaching it to play GitHub Copilot?
Replies from: tailcalled↑ comment by tailcalled · 2022-05-19T10:14:20.025Z · LW(p) · GW(p)
Are we actually any farther from game over than just feeding this thing the Decision Transformer papers and teaching it to play GitHub Copilot?
Gonna preregister a prediction here so I can bring it up whenever someone asks for when naysayer predictions have turned out right:
There's absolutely no way we'd game over just from this. Gato (or Gato architecture/configuration + training on GitHub code and ML papers) does not have any integrated world-model that it can loop on to do novel long-term planning, only an absurdly large amount of bits and pieces of world model that are not integrated and therefore not sufficient to foom.
Replies from: daniel-kokotajlo, ryan_b↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-19T15:41:00.451Z · LW(p) · GW(p)
I agree that Gato won't go FOOM if we train it on GitHub Copilot. However, naysayer predictions about "game over" have always turned out right and will continue to do so right up until it's too late. So you won't win any points in my book.
I'd be interested to hear predictions about what a 10x bigger Gato trained on 10x more data 10x more diverse would and wouldn't be capable of, and ditto for 100x and 1000x.
↑ comment by tailcalled · 2022-05-19T16:50:25.814Z · LW(p) · GW(p)
I'd be interested to hear predictions about what a 10x bigger Gato trained on 10x more data 10x more diverse would and wouldn't be capable of, and ditto for 100x and 1000x.
Prediction 1: I don't think we're going to get a 100x or 1000x Gato, as it would be way too difficult to produce. They would have to instead come up with derived method that gets training data in a different way from the current Gato. (95% for 100x, 99.9% for 1000x.)
Prediction 2: 1000x sounds like it would be really really capable by current standards. I would not be surprised if it could extrapolate or at least quickly get fine-tuned to just about any problem within the scale [LW · GW] it's been trained on. (50%)
Prediction 3: I want to say that 10x Gato "wouldn't suck at the tasks" (look at e.g. the image captions for an example of it sucking), but that's not very specific, though I feel more confident in this than in any specific prediction. (80%) I think people might be more interested in specific predictions if I was to predict that it would suck than that it wouldn't? So I'm just gonna leave it vague unless there's particular interest. I don't even find it all that likely that a 10x Gato will be made.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-19T18:47:40.366Z · LW(p) · GW(p)
Given your Prediction 2, it seems like maybe we are on the same page? You seem to be saying that a 1000x Gato would be AGI-except-limited-by-scale-of-training, so if we could just train it for a sufficiently long scale that it could learn to do lots of AI R&D, then we'd get full AGI shortly thereafter, and if we could train it for a sufficiently long scale that it could learn to strategically accumulate power and steer the world away from human control and towards something else, then we'd (potentially) cross an AI-induced-point-of-no-return shortly thereafter. This is about what I think. (I also think that merely 10x or even 100x probably wouldn't be enough; 1000x is maybe my median.) What scale of training is sufficiently long? Well, that's a huge open question IMO. I think probably 1000x the scale of current-Gato would be enough, but I'm very unsure.
Replies from: tailcalled↑ comment by tailcalled · 2022-05-19T19:06:17.185Z · LW(p) · GW(p)
This is a very weird question to me because I feel like we have all sorts of promising AI techniques that could be readily incorporated into Gato to make it much more generally capable. But I can try to answer it.
There's sort of two ways we could imagine training it to produce an AGI. We could give it sufficiently long-term training data that it learns to pursue AGI in a goal-directed manner, or we could give it a bunch of AGI researcher training data which it learns to imitate such that it ends up flailing and sort of vaguely making progress but also just doing a bunch of random stuff.
Creating an AGI is probably one of the longest-scale activities one can imagine, because one is basically creating a persistent successor agent. So in order to pursue this properly in a persistent goal-directed manner, I'd think one needs very long-scale illustrations. For instance one could have an illustration of someone who starts a religion which then persists for long after their death, or similar for starting a company, a trust fund, etc., or creatures evolving to persist in an environment.
This is not very viable in practice. But maybe if you trained an AGI to imitate AI researchers on a shorter scale like weeks or months, then it could produce a lot of AI research that is weakly but not strongly directed towards AGI. This could of course partly be interpolated from imitation of non-AI researchers and programmers and such, which would get you some part of the way.
In both cases I'm skeptical about the viability of getting training data for it. How many people can you really get to record their research activities in sufficient detail for this to work? Probably not enough. And again I don't think this will be prioritized because there are numerous obvious improvements that can be made on Gato to make it less dependent on training data.
↑ comment by ryan_b · 2022-05-19T20:36:49.041Z · LW(p) · GW(p)
does not have any integrated world-model that it can loop on to do novel long-term planning
I am interested in more of your thoughts on this part, because I do not grok the necessity of a single world-model or long-term planning (though I'm comfortable granting that they would make it much more effective). Are these independent requirements, or are they linked somehow? Would an explanation look like:
- Because the chunks of the world model are small, foom won't meaningfully increase capabilities past a certain point.
Or maybe:
- Without long-term planning, the disproportionate investment in increasing capabilities that leads to foom never makes sense.
↑ comment by tailcalled · 2022-05-19T21:47:04.209Z · LW(p) · GW(p)
The second one. The logic for increasing capabilities is "if I increase my capabilities, then I'll better reach my goal". But Gato does not implement the dynamic [LW · GW] of "if I infer [if X then I'll better reach my goal] then promote X to an instrumental goal". Nor does it particularly pursue goals by any other means. Gato just acts similar to how its training examples acted in similar situations to the ones it finds itself in.
↑ comment by gwern · 2022-07-03T02:26:10.277Z · LW(p) · GW(p)
If anyone was wondering whether DM planned to follow it up in the obvious way because of the obvious implications of its obvious generality and obvious scalability, Hassabis says on the Fridman podcast: " it's just the beginning really, it's our most general agent one could call it so far but um you know that itself can be scaled up massively more than we've done so far obviously we're in the in the middle of doing that."
↑ comment by mocny-chlapik · 2022-05-16T12:53:45.680Z · LW(p) · GW(p)
So many S-curves and paradigms hit an exponential wall and explode, but DL/DRL still have not.
Don't the scaling laws use logarithmic axis? That would suggest that the phenomenon is indeed exponential in it nature. If we need to get X times more compute with X times more data for additional improvements, we will hit the wall quite soon. There is only that much useful text on the Web and only that much compute that labs are willing to spend on this considering the diminishing returns.
Replies from: weightt-an↑ comment by Canaletto (weightt-an) · 2022-05-16T13:00:06.490Z · LW(p) · GW(p)
There is a lot more useful data on YouTube (by several orders of magnitude at least? idk), I think the next wave of such breakthrough models will train on video.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2022-05-13T00:30:52.665Z · LW(p) · GW(p)
There is no fire alarm for AGIs? Maybe just subscribe to the DeepMind RSS feed…
On a more serious note, I'm curious about the internal review process for this article, what role did the DeepMind AI safety team play in it? In the Acknowledgements, there is no mention of their contribution.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T06:38:04.682Z · LW(p) · GW(p)
I don't think we played any particular role in the review process (or if we did I'm not aware of it, which tbc is totally possible, I don't know everything that everyone on DeepMind safety does).
What would you want us to bring up if we were to participate in a review process?
Replies from: spell_chekist, charbel-raphael-segerie↑ comment by spell_chekist · 2022-05-13T06:44:38.853Z · LW(p) · GW(p)
Sorry to hijack your comment, but I'm curious as to whether this shortens your timelines at all or makes you any more pessimistic about alignment.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T07:44:57.136Z · LW(p) · GW(p)
Not really? On timelines, I haven't looked through the results so maybe they're more surprising then they look on a brief skim, but "you can do multitask learning with a single network" feels totally unsurprising given past results. Like, if nothing else the network could allocate 10% of itself to each domain; 100M parameters are more than enough to show good performance in these domains (robotics often uses far fewer parameters iirc). But also I would have expected some transfer between tasks so that you'd do better than that would naively predict. I've seen this before -- iirc there was a result (from Pieter Abbeel's lab? EDIT: this one EDIT 2: see caveats on this paper, though it doesn't affect my point) a couple of years ago that showed that pretraining a model on language would lead to improved sample efficiency in some nominally-totally-unrelated RL task, or something like that. Unfortunately I can't find it on a quick Google now (and it's possible it never made it into a paper and I heard it via word of mouth).
Having not read the detailed results yet, I would be quite surprised if it performed better on language-only tasks than a pretrained language model of the same size; I'd be a little surprised if it performed better on robotics / RL tasks than a specialized model of the same size given the same amount of robotics data.
In general, from a "timelines to risky systems" perspective, I'm not that interested in these sorts of "generic agents" that can do all the things with one neural net; it seems like it will be far more economically useful to have separate neural nets doing each of the things and using each other as tools to accomplish particular tasks and so that's what I expect to see.
On pessimism, I'm not sure why I should update in any direction on this result, even if I thought this was surprisingly fast progress which I don't. I guess shorter timelines would increase pessimism just by us having less time to prepare, but I don't see any other good reason for increased pessimism.
Replies from: glazgogabgolab, habryka4, atgambardella, fasc, matthew-barnett, Kaj_Sotala↑ comment by glazgogabgolab · 2022-05-13T08:04:03.872Z · LW(p) · GW(p)
there was a result (from Pieter Abbeel's lab?) a couple of years ago that showed that pretraining a model on language would lead to improved sample efficiency in some nominally-totally-unrelated RL task
Pretrained Transformers as Universal Computation Engines
From the abstract:
Replies from: rohinmshahWe investigate the capability of a transformer pretrained on natural language to generalize to other modalities with minimal finetuning – in particular [...] a variety of sequence classification tasks spanning numerical, computation, vision, and protein fold prediction
↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T08:36:52.637Z · LW(p) · GW(p)
That's the one, thanks!
↑ comment by habryka (habryka4) · 2022-05-14T07:02:58.070Z · LW(p) · GW(p)
Maybe you already had better models here, but I was pretty unsure whether we needed any additional substantial advances to get good multimodal learning. As Gwern says in his comment:
it used to be that learning multiple Atari games in parallel was really hard. It did not work, at all. You got negative transfer even within ALE. People thought very hard and ran lots of experiments to try to create things like Popart less than 4 years ago where it was a triumph that, due to careful engineering a single checkpoint could play just the ALE-57 games with mediocre performance.
Decision Transformer definitely made 'multi-task learning is a blessing of scale' the default hypothesis, but no one had actually shown this, the past DT and other work (aside from MetaMimic) were all rather low n and k; you could wonder if they would interfere at a certain point or break down, and require fancy engineering like MoEs to enable learning at all. (Similarly, Andy Jones showed nice scaling laws for DRL and I scraped together a few examples like Ms Pacman, but nothing across really complicated tasks or many tasks.)
For me this paper wasn't a massive update, but it did update me some that we really don't need much of any fundamental advancement to build very big agents that learn on multimodal data, and that barrier was one of the last ones to making AGI just one big "scaling up" step away, which has implications for both my timeline models and my risk models.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-14T09:46:55.019Z · LW(p) · GW(p)
it did update me some that we really don't need much of any fundamental advancement to build very big agents that learn on multimodal data
I've been saying this for some time now. (I often feel like I'm more confident in the bio anchors approach to timelines than Open Phil is, because I'm more willing to say "yes we literally could scale up 2020 algorithms and get TAI, given some engineering effort and enough good data, without any fundamental advances".)
My explanation for the negative transfer in ALE is that ALE isn't sufficiently diverse / randomized; you can see this in CoinRun (see "the diversity hypothesis" in Understanding RL vision), where you only get interpretable vision features for aspects of the environment that were randomized. In contrast, image classifiers trained on real world images have interpretable vision features at all layers except perhaps some of the later ones, and often lead to positive transfer on new tasks.
A big part of my model predicting what kind of transfer does and doesn't work in deep learning is figuring out to what extent I expect there to be large entangled variation in the features of the training data. If this variation is present, then I expect the neural network is forced to learn the real actual feature, and there isn't some other simpler program that happens to get it correct in only the training situations. If you have the real actual feature, then you're going to transfer better.
You usually don't get sufficient diversity with programmatically generated data, but you do get it with real-world data, because reality is laced together very tightly [LW · GW]. So I often expect transfer to be a lot harder with programmatically generated data (unless the transfer is only to things that "could have been" programmatically generated, as was the case in e.g. XLand).
(I was initially going to say I believed this in 2019, but looking back at my notes from the time, I wrote very related stuff but didn't actually write this particular thing. I've definitely been saying it in public talks since about the beginning of 2022. So I probably started believing this some time in between then.)
Replies from: gwern, daniel-kokotajlo↑ comment by gwern · 2022-05-31T15:36:11.649Z · LW(p) · GW(p)
"Multi-Game Decision Transformers", Lee et al 2022 is worth a close look, especially for Gato critics.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-19T15:44:43.088Z · LW(p) · GW(p)
I'm more willing to say "yes we literally could scale up 2020 algorithms and get TAI, given some engineering effort and enough good data, without any fundamental advances
Interesting, thanks, I thought you were much more in agreement with Ajeya's view (and therefore similarly uncertain about the probability that 2020's algorithms would scale up etc.) Do you in fact have shorter timelines than Ajeya now, or is there something else that pushes you towards longer timelines than her in a way that cancels out?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-20T07:20:40.829Z · LW(p) · GW(p)
I... don't particularly remember that as a major difference between us? Does she actually lengthen timelines significantly based on not knowing whether 2020 algorithms would scale up?
I do recall her talking about putting more weight on long horizons / evolution out of general uncertainty or "some problem will come up" type intuitions. I didn't like this method of dealing with it, but I do agree with the intuition, though for me it's a bit more precise, something like "deployment is difficult; you need to be extremely robust, much more so than humans, it's a lot of work to iron out all such problems". I incorporated it by taking the model's output and pushing my timelines further out than the model said -- see "accounting for challenges" in my opinion [LW(p) · GW(p)].
(Though looking back at that I notice that my intuitions say those timelines are slightly too long, like maybe the median should be 2045. I think the biggest change there is reflecting on how the bio anchors model doesn't incorporate AI-driven acceleration of AI research before TAI happens.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-20T16:06:37.006Z · LW(p) · GW(p)
Maybe I misinterpreted you and/or her sorry. I guess I was eyeballing Ajeya's final distribution and seeing how much of it is above the genome anchor / medium horizon anchor, and thinking that when someone says "we literally could scale up 2020 algorithms and get TAI" they are imagining something less expensive than that (since arguably medium/genome and above, especially evolution, represents doing a search for algorithms rather than scaling up an existing algorithm, and also takes such a ridiculously large amount of compute that it's weird to say we "could" scale up to it.) So I was thinking that probability mass in "yes we could literally scale existing algorithms" is probability mass below +12 OOMs basically. Wheras Ajeya is at 50% by +12. I see I was probably misunderstanding you; you meant scaling up existing algorithms to include stuff like genome and long-horizon anchor? But you agree it doesn't include evolution, right?)
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-20T18:49:03.372Z · LW(p) · GW(p)
All of the short-horizon, medium-horizon, or long-horizon paths would count as "scaling up 2020 algorithms".
I mostly ignore the genome anchor (see "Ignoring the genome anchor" in my opinion [LW(p) · GW(p)]).
I'm not entirely sure how you're imagining redoing evolution. If you're redoing it by creating a multiagent environment simulation, with the agents implemented via neural networks updated using some form of gradient descent, I think that's "scaling up 2020 algorithms".
If you instead imagine having a long string of parameters (analogous to DNA) that tells you how to build a brain for the agent, and then learning involves making a random change to the long string of parameters and seeing how that goes, and keeping it if it's good -- I agree that's not "scaling up 2020 algorithms".
thinking that when someone says "we literally could scale up 2020 algorithms and get TAI" they are imagining something less expensive than that
I just literally mean "there is some obscene amount of compute, such that if you use that much compute with 2020 algorithms, and you did some engineering to make sure you could use that compute effectively (things more like hyperparameter tuning and less like inventing Transformers), and you got the data that was needed (who knows what that is), then you get TAI". That's the belief that makes you take bio anchors more seriously. Pre-bio-anchors, it would have been hard for me to give you a specific number for the obscene compute that would be needed.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-20T18:52:49.012Z · LW(p) · GW(p)
Right, OK.
Pre bio-anchors couldn't you have at least thought that recapitulating evolution would be enough? Or are you counting that as part of the bio anchors framework?
↑ comment by Rohin Shah (rohinmshah) · 2022-05-21T07:55:25.610Z · LW(p) · GW(p)
What exactly does "recapitulating evolution" mean? If you mean simulating our laws of physics in an initial state that is as big as the actual world and includes, say, a perfect simulation of bacteria, and then letting the simulation evolve for the equivalent of billions of years until some parts of the environment implement general intelligence, then sure, that would be enough, but also that's way way more compute than the evolution anchor (and also we don't have the knowledge to set up the initial state right). (You could even then be worried about anthropic arguments saying that this won't work.)
If you instead mean that we have some simulated environment that we hope resembles the ancestral environment, and we put in simulated animal bodies with a neural network to control them, and then train those neural networks with current gradient descent or evolutionary algorithms, I would not then and do not now think that such an approach is clearly going to produce TAI given evolutionary anchor levels of compute.
↑ comment by atgambardella · 2022-05-13T08:16:28.083Z · LW(p) · GW(p)
In general I'm not that interested in these sorts of "generic agents" that can do all the things with one neural net and don't think they affect the relevant timelines very much; it seems like it will be far more economically useful to have separate neural nets doing each of the things and using each other as tools to accomplish particular tasks and so that's what I expect to see.
Aren't you worried about agents that can leverage extremely complex knowledge of the world (like Flamingo has) that they gained via text, picture, video, etc inputs, on a robotic controller? Think of an RL agent that can learn how to play Montezuma's Revenge extremely quickly, because it consumed so much internet data that it knows what a "key" and "rope" are, and that these in-game objects are analogous to those images it saw in pretraining. Something like that getting a malicious command in real life on a physical robot seems terrifying -- it would be able to form extremely complex plans in order to achieve a malicious goal, given its environment -- and at least from what I can tell from the Gato paper, the only missing ingredient at this point might be "more parameters/TPUs"
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T08:53:33.415Z · LW(p) · GW(p)
I agree that will happen eventually, and the more nuanced version of my position is the one I outlined in my comment [LW(p) · GW(p)] on CAIS:
Now I would say that there is some level of data, model capacity, and compute at which an end-to-end / monolithic approach outperforms a structured approach on the training distribution (this is related to but not the same as the bitter lesson). However, at low levels of these three, the structured approach will typically perform better. The required levels at which the end-to-end approach works better depends on the particular task, and increases with task difficulty.
Since we expect all three of these factors to grow over time, I then expect that there will be an expanding Pareto frontier where at any given point the most complex tasks are performed by structured approaches, but as time progresses these are replaced by end-to-end / monolithic systems (but at the same time new, even more complex tasks are found, that can be done in a structured way).
I think when we are first in the situation where AI systems are sufficiently competent to wrest control away from humanity if they wanted to, we would plausibly have robots that take in audiovisual input and can flexibly perform tasks that a human says to them (think of e.g. a household robot butler). So in that sense I agree that eventually we'll have agents that link together language, vision, and robotics.
The thing I'm not that interested in (from a "how scared should we be" or "timelines" perspective) is when you take a bunch of different tasks, shove them into a single "generic agent", and the resulting agent is worse on most of the tasks and isn't correspondingly better at some new task that none of the previous systems could do.
So if for example you could draw an arrow on an image showing what you wanted a robot to do, and the robot then did that, that would be a novel capability that couldn't be done by previous specialized systems (probably), and I'd be interested in that. It doesn't look like this agent does that.
Replies from: SDM↑ comment by Sammy Martin (SDM) · 2022-05-13T10:52:48.976Z · LW(p) · GW(p)
Does that mean the socratic models result from a few weeks ago, which does involve connecting more specialised models together, is a better example of progress?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T11:18:34.923Z · LW(p) · GW(p)
Yes
↑ comment by Fabian Schimpf (fasc) · 2022-05-13T08:32:04.103Z · LW(p) · GW(p)
To me the relevant result/trend is that it seems like catastrophic forgetting is becoming less of an issue as it was maybe two to three years ago e.g. in meta-learning and that we can squeeze these diverse skills into a single model. Sure, the results seem to indicate that individual systems for different tasks would still be the way to go for now, but at least the published version was not trained with the same magnitude of compute that was e.g. used on the latest and greatest LLMs (I take this from Lennart Heim who did the math on this). So it is IMO hard to say if there are timeline-affecting surprises lurking if we either just trained longer or had faster hardware - at least not with certainty. I didn't expect double descent and grokking so my prior is that unexpected stuff happens.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T08:45:41.061Z · LW(p) · GW(p)
On surprises:
- I definitely agree that your timelines should take into account "maybe there will be a surprise".
- "There can be surprises" cuts both ways; you can also see e.g. a surprise slowdown of scaling results.
- I also didn't expect double descent and grokking but it's worth noting that afaict those have had ~zero effects on SOTA capabilities so far.
- Regardless, the original question was about this particular result; this particular result was not surprising (given my very brief skim).
On catastrophic forgetting:
I agree that catastrophic forgetting is becoming less of an issue at larger scale but I already believed and expected that; it seemed like something like that had to be true for all of the previous big neural net results (OpenAI Five, AlphaStar, language models, etc) to be working as well as they were.
Replies from: tailcalled, fasc↑ comment by tailcalled · 2022-05-13T09:34:36.405Z · LW(p) · GW(p)
- I also didn't expect double descent and grokking but it's worth noting that afaict those have had ~zero effects on SOTA capabilities so far.
I was under the impression that basically all SOTA capabilities rely on double descent. Is that impression wrong?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T09:56:35.047Z · LW(p) · GW(p)
... Where is that impression coming from? If this is a widespread view, I could just be wrong about it; I have a cached belief that large language models and probably other models aren't trained to the interpolation threshold and so aren't leveraging double descent.
Replies from: tailcalled↑ comment by tailcalled · 2022-05-13T10:17:44.735Z · LW(p) · GW(p)
I haven't kept track of dataset size vs model size, but things I've read on the double descent phenomenon have generally described it as a unified model of the "classic statistics" paradigm where you need to deal with the bias-variance tradeoff, versus the "modern ML" paradigm where bigger=better.
I guess it may depend on the domain? Generative tasks like language modelling or image encoding implicitly end up having a lot more bits/sample than discriminative tasks? So maybe generative tasks are usually not in the second descend regime while discriminative tasks usually are?
↑ comment by Fabian Schimpf (fasc) · 2022-05-13T09:02:32.194Z · LW(p) · GW(p)
I like your point that "surprises cut both ways" and assume that this is why your timelines aren't affected by the possibility of surprises, is that about right? I am confused about the ~zero effect though: Isn't double descent basically what we see with giant language models [LW · GW] lately? Disclaimer: I don't work on LLMs myself, so my confusion isn't necessarily meaningful
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T09:13:45.896Z · LW(p) · GW(p)
My timelines are affected by the possibility of surprises; it makes them wider on both ends.
My impression is that giant language models are not trained to the interpolation point (though I haven't been keeping up with the literature for the last year or so). I believe the graphs in that post were created specifically to demonstrate that if you did train them past the interpolation point, then you would see double descent.
↑ comment by Matthew Barnett (matthew-barnett) · 2023-03-13T00:01:37.615Z · LW(p) · GW(p)
Having not read the detailed results yet, I would be quite surprised if [Gato] performed better on language-only tasks than a pretrained language model of the same size...
In general, from a "timelines to risky systems" perspective, I'm not that interested in these sorts of "generic agents" that can do all the things with one neural net; it seems like it will be far more economically useful to have separate neural nets doing each of the things and using each other as tools to accomplish particular tasks and so that's what I expect to see.
Do you still believe this in light of the paper on mixed-modal scaling laws?
From the paper,
Replies from: rohinmshahGiven these laws, we can now make predictions about what scale will be required to overcome modal competition and achieve synergy from training on each pair of modalities. By modality competition, we refer to the empirical phenomena of two modalities performing worse than if we trained two individual models on the same number of per-modality tokens. By synergy, we mean the inverse. We can define the notion of synergy formally through our scaling laws. [...]
We plot the ratio of the average of the Speech and Text models perplexity per timestep by Speech|Text perplexity, the competition barrier and predictions from our scaling laws in Figure 5. As we see, the prediction does hold, and we achieve a model that crosses the competition barrier. Further scaling is likely to further improve the synergy, but we leave this exploration to future work.
↑ comment by Rohin Shah (rohinmshah) · 2023-03-13T09:45:16.404Z · LW(p) · GW(p)
Sorry, I think that particular sentence of mine was poorly written (and got appropriate pushback [LW(p) · GW(p)] at the time). I still endorse my followup comment [LW(p) · GW(p)], which includes this clarification:
The thing I'm not that interested in (from a "how scared should we be" or "timelines" perspective) is when you take a bunch of different tasks, shove them into a single "generic agent", and the resulting agent is worse on most of the tasks and isn't correspondingly better at some new task that none of the previous systems could do.
In particular, my impression with Gato is that it was not showing much synergy. I agree that synergy is possible and likely to increase with additional scale (and I'm pretty sure I would have said so at the time, especially since I cited a different example of positive transfer).
(Note I haven't read the mixed-modal scaling laws paper in detail so I may be missing an important point about it.)
↑ comment by Kaj_Sotala · 2022-05-16T12:38:12.082Z · LW(p) · GW(p)
Like, if nothing else the network could allocate 10% of itself to each domain; 100M parameters are more than enough to show good performance in these domains (robotics often uses far fewer parameters iirc).
Are you suggesting that this isn't really a "general" agent any more than the combination of several separate models trained independently would be? And that this is just several different agents that happened to be trained in a network that's big enough to contain all of them?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-17T08:05:59.398Z · LW(p) · GW(p)
I don't really know what you mean by a "general" agent. Here are some properties that I would guess it has (caveating again that I haven't read the paper in detail), which may or may not be related to what you mean by "generality":
- Given an input, it can tell which task it is supposed to do, and then do the relevant tasks.
- Some of the tasks do benefit from the training done on other tasks ("positive transfer"), presumably because some of the basic building blocks of the needed programs are the same ("look at the token that was one place prior" is probably helpful for many tasks).
- It has some neurons that are used in multiple different tasks (presumably).
- It cannot learn new tasks particularly quickly ("few-shot learning"), except inasmuch as that could already be done with language models.
- It does not do any "learning with frozen weights" (i.e. the sort of thing where you prompt a language model to define a new word, and then it can use that word later on, without any gradient descent), except inasmuch as the specialized models would also do that learning.
- It is about as well-modeled as an expected utility maximizer as the specialized models would be.
↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2022-05-13T11:37:45.547Z · LW(p) · GW(p)
Perhaps your team could have helped write the safety part?
Or to deliberate whether the weights and code should be made public?
The name of the paper is very meaningful (AGA ≈ AGI, obviously on purpose), so in order to get in condition, I think it is important that your safety team takes part in this kind of paper.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T11:52:35.016Z · LW(p) · GW(p)
Perhaps your team could have helped write the safety part?
I think it would be a bad use of our time to write the safety sections of all the papers that could be progress towards AGI (there are a lot of them). It seems a lot better to focus on generally improving knowledge of safety, and letting individual projects write their own safety sections.
Obviously if an actually x-risky system is being built it would be important for us to be involved but I think this was not particularly x-risky.
Tbc we would have been happy to chat to them if they reached out; I'm just saying that we wouldn't want to do this for all of the AGI-related papers (and this one doesn't seem particularly special such that we should pay special attention to it).
Or to deliberate whether the weights and code should be made public?
DeepMind generally doesn't make weights and code public because it's a huge hassle to do so (because our codebase is totally different from the codebases used outside of industry), so there isn't much of a decision for us to weigh in on here.
(But also, I think we'd be more effective by working on a general policy for how to make these decisions, rather than focusing on individual cases, and indeed there is some work like that happening at DeepMind.)
comment by Maxime Riché (maxime-riche) · 2022-05-13T08:30:10.610Z · LW(p) · GW(p)
It's only 1.2 billion parameters.
Indeed but to slightly counter balance this, at the same time, it looks like it was trained on ~500B tokens (while ~300B were used for GPT-3 and something like ~50B for GPT-2).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-13T16:30:26.966Z · LW(p) · GW(p)
Good point. Still though, there is room for a few more orders of magnitude of data increase. And parameter increase.
Replies from: Yuli_Ban↑ comment by Yuli_Ban · 2022-05-13T23:34:51.711Z · LW(p) · GW(p)
I wonder if there is any major plan to greatly expand the context window? Or perhaps add a sort "inner voice"/chain of thought for the model to write down its intermediate computational steps to refer to in the future? I'm aware the context window increases with parameter count.
Correct me if I'm wrong, but a context window of even 20,000 memory tokens could be enough for it to reliably imitate a human's short-term memory to consistently pass a limited Turing Test (e.g. the same Eugene Goostman barely scraped by ~2014), as opposed to the constant forgetting of LSTMs and Markov Chains. Sure, the Turing Test isn't particularly useful for AI benchmarks, but the market for advanced conversational agents could be a trillion-dollar business, and the average Joe is far more susceptible to the ELIZA Effect than we commonly idealize.
comment by Aiyen · 2022-05-15T18:30:40.248Z · LW(p) · GW(p)
Quick sanity check: are we currently able to build human-level AGI, and bottlenecked only by project funding?
VentureBeat claims that GPT-3 cost around $12 million to train, and this is the higher of 2 estimates I found. And GPT-3 used 3640 petaflop/s-days. That's about ten years worth of petaflop/s level compute. Now, the power of the human brain is often estimated at about 1 exaflop/s, and again, that estimate is on the high side of the range. Ten year old humans are typically generally intelligent. So if we took 3 orders of magnitude more compute than GPT-3, that naively sounds like it should be enough to produce human-level AGI. If costs scale linearly, that's $12 billion, not chump change, but a fraction of e.g. what the U.S. is currently sending to Ukraine.
Of course, assuming linear scaling is frequently wrong. It's one thing to pay for compute when it's not that scarce and you're only trying to train a 175 billion parameter model for a bit. It's quite another if you're trying to use a substantial quantity of the world's compute, and having to bid against many other projects to do it. The marginal costs should rise substantially; perhaps the total cost would be more on the order of $100 billion.
As for (linear?) scaling of intelligence, that's why I'm wondering about this: Gato is displaying such effective generalization that some here have called it literal AGI, albeit not human-level yet. While that's what one would expect from the previous success of scaling laws, it's still striking to see it confirmed to this degree. A few years ago, the idea that simply throwing more compute at the problem would continuously yield more intelligence was considered absurd. Now, as Gwern put it, we know Scaling Just Works.
Moreover, ten subjective years of training is probably a lot more than human-level AGI would need. An awful lot of human development is limited by the body and brain growing, rather than lack of training data, and quite a lot of experiences growing up do not provide any new information. Perhaps 4 years or so of data would be enough, and if 10 years cost $100 billion, 4 might be more like $40 billion.
Of course, these are extremely rough estimates, but the general point should be clear: even without any further help from Moore's Law, and even without significant further software breakthroughs, it sounds like humanity is capable of human-level AGI RIGHT NOW. Does this seem plausible?
comment by Flaglandbase · 2022-05-16T08:42:28.410Z · LW(p) · GW(p)
This is extremely interesting because if there was an AI whose only purpose was to learn everything about me (to back up my memories and personality) that AI would also have to learn about many different human tasks and activities.
comment by HiroSakuraba (hirosakuraba) · 2022-05-26T03:36:28.380Z · LW(p) · GW(p)
Recently this paper has discovered a prompt that can unlock a form of reasoning process for large language models (LLM). https://paperswithcode.com/paper/large-language-models-are-zero-shot-reasoners. These models are used for natural language processing and typically use a transformer architecture (https://paperswithcode.com/paper/the-annotated-transformer).
"Let's think step by step" style prompts seems to unlock the ability for text generation that can give logically consistent answers to questions that have been out of the reach of most A.I. neural networks.
This might present an opportunity to test out ethical or moral questions on future LLMs that are multi-modal. Theorem proving might be particularly useful for MIRI type solutions. I am imagining a process where one could get answers to ethical questions, and use that feed back to create transparent teacher/critic learning paradigm. A dynamic interrogation where the A.I. could show its language AND math for why and how it came to its answers.
I believe a proto AGI like GATO likely will use the transformer architecture and this information could be used to structure better alignment tools. Perhaps train something that could help with utility functions.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2022-05-13T11:28:43.333Z · LW(p) · GW(p)
Demis Hassabis is not even mentioned in the paper. Does that mean this is considered a minor paper for DeepMind?
comment by Aiyen · 2022-05-13T02:28:23.985Z · LW(p) · GW(p)
When they talk about an expert benchmark, they’re talking about the performance of a human expert right? That’s what it sounds like, but it’s worth being sure.
Replies from: noa-nabeshima, tristan-wegner↑ comment by Noa Nabeshima (noa-nabeshima) · 2022-05-16T21:48:09.198Z · LW(p) · GW(p)
No, I'm pretty confident every expert is a neural network policy trained on the task. See "F. Data Collection Details" and the second paragraph of "3.3. Robotics - RGB Stacking Benchmark (real and sim)"
Replies from: Aiyen↑ comment by Tristan Wegner (tristan-wegner) · 2022-05-13T09:35:51.648Z · LW(p) · GW(p)
That is how I have seen the term expert performance used in papers. Yes.
Replies from: evdokscomment by M. Y. Zuo · 2022-05-13T18:00:16.598Z · LW(p) · GW(p)
What's the highest parameter count that is still feasible if you can ignore "avoid latency in the robot control task"? i.e. remove robot control tasks and related tasks
Five billion? Ten billion?
I imagine more general latency problems will appear beyond 10 billion parameters but that's just a hunch.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-13T22:58:15.593Z · LW(p) · GW(p)
Clarify what you mean by that? The largest publicly known model (that was actually trained for a useful amount of time) is PaLM I believe, at around 500 billion parameters. Much bigger models have been trained for much less time.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2022-05-15T01:27:47.852Z · LW(p) · GW(p)
Real time robotic control systems can have latency requirements as low as in the milliseconds, a ~1 billion parameter model is probably going to take at the very least a few tens of milliseconds in end-to-end latency. Which is probably why that limit was chosen.
A system incorporating a higher parameter model with a total latency of 1 second is unusable for real time robotic control in situations where a few hundred milliseconds of extra delay could cause catastrophic damage.
I'm not sure what an end-to-end latency of 1 second corresponds to in terms of model parameter size in the current best implementations, but it probably cannot be improved any faster than transistor scaling for mobile systems, due to power/weight/size constraints of computing systems. For fixed systems the costs will scale super-linearly due to the increasingly expensive cost of interconnect (Infiniband, etc.) to reduce latency.
Other less demanding applications, not affected by 100 milliseconds of latency may be affected by 1 second of it. Thus a wider range of applications, beyond robotic control tasks, become unsuitable for these larger models, at the present technological level.
I am not sure how many other common tasks have latency requirements within an order of magnitude of robotics control.
That's what I mean by more general latency problems may appear beyond 10 billion parameters.
e.g. If PaLM requires 10 seconds to go from input -> output, I can think of many applications where it is unsuitable. The set of such unsuitable applications grows as a function of latency.
How big is the intermediary space between having too many parameters for real time robotic control while having a low enough parameter count such that the latency is sufficient for all other common tasks?
Is it really just the range from 100 milliseconds to 1 second, or is the range smaller, or bigger?
That's what I mean by 'the highest parameter count that is still feasible'.
e.g. There may be a practical upper limit for how many parameters a Starcraft 2 playing model, such as AlphaStar, may have. Due to the fact that user actions can happen multiple times a second at the highest competitive levels, thus requiring AlphaStar, or an equivalent system to evaluate and place an action within a few hundred milliseconds. A hypothetical AlphaStar 2 with 10x the parameters, 10x the performance when actions per unit time are limited, and 10x the latency, may in fact play worse in a real match due to the massive disadvantage of being limited in the numbers of actions per unit time against an unbounded human opponent.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-17T01:14:18.117Z · LW(p) · GW(p)
My guess based on how fast GPT-3 feels is that one OOM bigger will lead to noticeable latency (you'll have to watch as the text appears on your screen, just like it does when you type) and that an OOM on top of that will result in annoying latency (you'll press GO and then go browse other tabs while you wait for it to finish).
Replies from: M. Y. Zuo