Efficient Dictionary Learning with Switch Sparse Autoencoders
post by Anish Mudide (anish-mudide) · 2024-07-22T18:45:53.502Z · LW · GW · 20 commentsContents
0. Summary 1. Introduction 2. Methods 2.1 Baseline Sparse Autoencoder 2.2 Switch Sparse Autoencoder Architecture 2.3 Switch Sparse Autoencoder Training 3. Results 3.1 Fixed Width Results 3.2 FLOP-Matched Results 4. Conclusion Future Work Acknowledgements None 21 comments
Produced as part of the ML Alignment & Theory Scholars Program - Summer 2024 Cohort
0. Summary
To recover all the relevant features from a superintelligent language model, we will likely need to scale sparse autoencoders (SAEs) to billions of features. Using current architectures, training extremely wide SAEs across multiple layers and sublayers at various sparsity levels is computationally intractable. Conditional computation has been used to scale transformers (Fedus et al.) to trillions of parameters while retaining computational efficiency. We introduce the Switch SAE, a novel architecture that leverages conditional computation to efficiently scale SAEs to many more features.
1. Introduction
The internal computations of large language models are inscrutable to humans. We can observe the inputs and the outputs, as well as every intermediate step in between, and yet, we have little to no sense of what the model is actually doing. For example, is the model inserting security vulnerabilities or backdoors into the code that it writes? Is the model lying, deceiving or seeking power? Deploying a superintelligent model into the real world without being aware of when these dangerous capabilities may arise leaves humanity vulnerable. Mechanistic interpretability (Olah et al.) aims to open the black-box of neural networks and rigorously explain the underlying computations. Early attempts to identify the behavior of individual neurons were thwarted by polysemanticity, the phenomenon in which a single neuron is activated by several unrelated features (Olah et al.). Language models must pack an extremely vast amount of information (e.g., the entire internet) within a limited capacity, encouraging the model to rely on superposition to represent many more features than there are dimensions in the model state (Elhage et al.).
Sharkey et al. [LW · GW] and Cunningham et al. propose to disentangle superimposed model representations into monosemantic, cleanly interpretable features by training unsupervised sparse autoencoders (SAEs) on intermediate language model activations. Recent work (Templeton et al., Gao et al.) has focused on scaling sparse autoencoders to frontier language models such as Claude 3 Sonnet and GPT-4. Despite scaling SAEs to 34 million features, Templeton et al. estimate that they are likely orders of magnitude short of capturing all features. Furthermore, Gao et al. train SAEs on a series of language models and find that larger models require more features to achieve the same reconstruction error. Thus, to capture all relevant features of future large, superintelligent models, we will likely need to scale SAEs to several billions of features. With current methodologies, training SAEs with billions of features at various layers, sublayers and sparsity levels is computationally infeasible.
Training a sparse autoencoder generally consists of six major computations: the encoder forward pass, the encoder gradient, the decoder forward pass, the decoder gradient, the latent gradient and the pre-bias gradient. Gao et al. introduce kernels and tricks that leverage the sparsity of the TopK activation function to dramatically optimize all computations excluding the encoder forward pass, which is not (yet) sparse. After implementing these optimizations, Gao et al. attribute the majority of the compute to the dense encoder forward pass and the majority of the memory to the latent pre-activations. No work has attempted to accelerate or improve the memory efficiency of the encoder forward pass, which remains the sole dense matrix multiplication.
In a standard deep learning model, every parameter is used for every input. An alternative approach is conditional computation, where only a small subset of the parameters are active depending on the input. This allows us to scale model capacity and parameter count without suffering from commensurate increases in computational cost. Shazeer et al. introduce the Sparsely-Gated Mixture-of-Experts (MoE) layer, the first general purpose architecture to realize the potential of conditional computation at huge scales. The Mixture-of-Experts layer consists of (1) a set of expert networks and (2) a routing network that determines which experts should be active on a given input. The entire model is trained end-to-end, simultaneously updating the routing network and the expert networks. The underlying intuition is that each expert network will learn to specialize and perform a specific task, boosting the overall model capacity. Shazeer et al. successfully use MoE to scale LSTMs to 137 billion parameters, surpassing the performance of previous dense models on language modeling and machine translation benchmarks.
Shazeer et al. restrict their attention to settings in which the input is routed to several experts. Fedus et al. introduce the Switch layer, a simplification to the MoE layer which routes to just a single expert. This simplification reduces communication costs and boosts training stability. By replacing the MLP layer of a transformer with a Switch layer, Fedus et al. scale transformers to over a trillion parameters.
In this work, we introduce the Switch Sparse Autoencoder, which combines the Switch layer (Fedus et al.) with the TopK SAE (Gao et al.). The Switch SAE is composed of many smaller expert SAEs as well as a trainable routing network that determines which expert SAE will process a given input. We demonstrate that the Switch SAE is a Pareto improvement over existing architectures while holding training compute fixed. We additionally show that Switch SAEs are significantly more sample-efficient than existing architectures.
2. Methods
2.1 Baseline Sparse Autoencoder
Let be the dimension of the language model activations. The linear representation hypothesis states that each feature is represented by a unit-vector in . Under the superposition hypothesis, there exists a dictionary of features () represented as almost orthogonal unit-vectors in . A given activation can be written as a sparse, weighted sum of these feature vectors. Let be a sparse vector in representing how strongly each feature is activated. Then, we have:
A sparse autoencoder learns to detect the presence and strength of the features given an input activation . SAE architectures generally share three main components: a pre-bias , an encoder matrix and a decoder matrix . The TopK SAE defined by Gao et al. takes the following form:
The latent vector represents how strongly each feature is activated. Since is sparse, the decoder forward pass can be optimized by a suitable kernel. The bias term is designed to model , so that . Note that and are not necessarily transposes of each other. Row of the encoder matrix learns to detect feature while simultaneously minimizing interference with the other almost orthogonal features. Column of the decoder matrix corresponds to . Altogether, the SAE consists of parameters.
We additionally benchmark against the ReLU SAE (Conerly et al.) and the Gated SAE (Rajamanoharan et al.). The ReLU SAE applies an L1 penalty to the latent activations to encourage sparsity. The Gated SAE separately determines which features should be active and how strongly activated they should be to avoid activation shrinkage (Wright and Sharkey [LW · GW]).
2.2 Switch Sparse Autoencoder Architecture
The Switch Sparse Autoencoder avoids the dense matrix multiplication. Instead of being one large sparse autoencoder, the Switch Sparse Autoencoder is composed of smaller expert SAEs . Each expert SAE resembles a TopK SAE with no bias term:
Each expert SAE is times smaller than the original SAE. Specifically, and . Across all experts, the Switch SAE represents features.
The Switch layer takes in an input activation and routes it to the best expert. To determine the expert, we first subtract a bias . Then, we multiply by which produces logits that we normalize via a softmax. Let denote the softmax function. The probability distribution over the experts is given by:
We route the input to the expert with the highest probability and weight the output by that probability to allow gradients to propagate. We subtract a bias before passing to the selected expert and add it back after weighting by the corresponding probability:
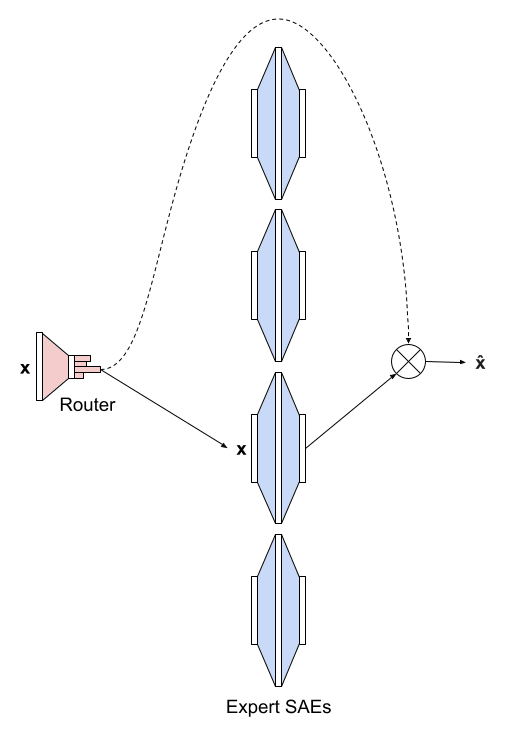
In total, the Switch Sparse Autoencoder contains parameters, whereas the TopK SAE has parameters. The additional parameters we introduce through the router are an insignificant proportion of the total parameters because .
During the forward pass of a TopK SAE, parameters are used during the encoder forward pass, parameters are used during the decoder forward pass and parameters are used for the bias, for a total of parameters used. Since , the number of parameters used is dominated by . During the forward pass of a Switch SAE, parameters are used for the router, parameters are used during the encoder forward pass, parameters are used during the decoder forward pass and 2 parameters are used for the biases, for a total of parameters used. Since the encoder forward pass takes up the majority of the compute, we effectively reduce the compute by a factor of . This approximation becomes better as we scale , which will be required to capture all the safety-relevant features of future superintelligent language models. Furthermore, the TopK SAE must compute and store pre-activations. Due to the sparse router, the Switch SAE only needs to store pre-activations, improving memory efficiency by a factor of as well.
2.3 Switch Sparse Autoencoder Training
We train the Switch Sparse Autoencoder end-to-end. Weighting by in the calculation of allows the router to be differentiable. We adopt many of the training strategies described in Bricken et al. and Gao et al. with a few exceptions. We initialize the rows (features) of to be parallel to the columns (features) of for all . We initialize both and to the geometric median of a batch of samples (but we do not tie and ). We additionally normalize the decoder column vectors to unit-norm at initialization and after each gradient step. We remove gradient information parallel to the decoder feature directions. We set the learning rate based on the scaling law from Gao et al. and linearly decay the learning rate over the last 20% of training. We do not include neuron resampling (Bricken et al.), ghost grads (Jermyn et al.) or the AuxK loss (Gao et al.).
The ReLU SAE loss consists of a weighted combination of the reconstruction MSE and a L1 penalty on the latents to encourage sparsity. The TopK SAE directly enforces sparsity via its activation function and thus directly optimizes the reconstruction MSE. Following Fedus et al., we train our Switch SAEs using a weighted combination of the reconstruction MSE and an auxiliary loss which encourages the router to send an equal number of activations to each expert to reduce overhead. Empirically, we also find that the auxiliary loss improves reconstruction fidelity.
For a batch with activations, we first compute vectors and . represents what proportion of activations are sent to each expert, while represents what proportion of router probability is assigned to each expert. Formally,
The auxiliary loss is then defined to be:
The auxiliary loss achieves its minimum when the expert distribution is uniform. We scale by so that for a uniformly random router. The inclusion of allows the loss to be differentiable.
The reconstruction loss is defined to be:
Note that . Let represent a tunable load balancing hyperparameter. The total loss is then defined to be:
We optimize using Adam ().
3. Results
We train SAEs on the residual stream activations of GPT-2 small (). In this work, we follow Gao et al. and focus on layer 8. Using text data from OpenWebText, we train for 100K steps using a batch size of 8192, for a total of ~820M tokens. We benchmark the Switch SAE against the ReLU SAE (Conerly et al.), the Gated SAE (Rajamanoharan et al.) and the TopK SAE (Gao et al.). We present results for two settings.
- Fixed Width: Each SAE is trained with features. We train Switch SAEs with 16, 32, 64 and 128 experts. Each expert of the Switch SAE with experts has features. The Switch SAE performs roughly times fewer FLOPs per activation compared to the TopK SAE.
- FLOP-Matched: The ReLU, Gated and TopK SAEs are trained with features. We train Switch SAEs with 2, 4 and 8 experts. Each expert of the Switch SAE with experts has features, for a total of features. The Switch SAE performs roughly the same number of FLOPs per activation compared to the TopK SAE.
For a wide range of sparsity (L0) values, we report the reconstruction MSE and the proportion of cross-entropy loss recovered when the sparse autoencoder output is patched into the language model. A loss recovered value of 1 corresponds to a perfect reconstruction, while a loss recovered value of 0 corresponds to a zero-ablation.
3.1 Fixed Width Results
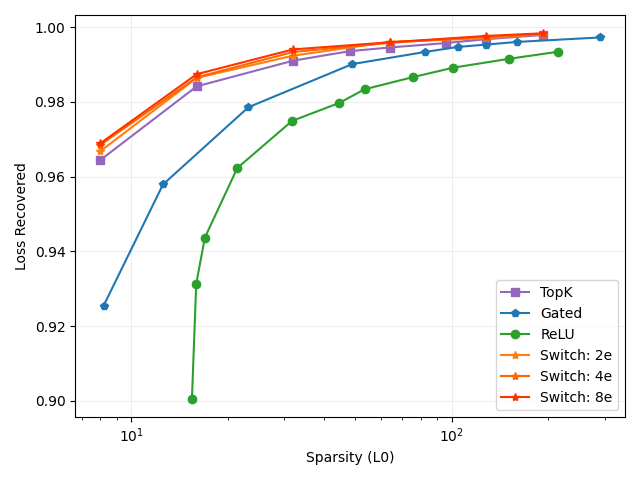
We train Switch SAEs with 16, 32, 64 and 128 experts (Figure 2, 3). The Switch SAEs consistently underperform compared to the TopK SAE in terms of MSE and loss recovered. The Switch SAE with 16 experts is a Pareto improvement compared to the Gated SAE in terms of both MSE and loss recovered, despite performing roughly 16x fewer FLOPs per activation. The Switch SAE with 32 experts is a Pareto improvement compared to the Gated SAE in terms of loss recovered. The Switch SAE with 64 experts is a Pareto improvement compared to the ReLU SAE in terms of both MSE and loss recovered. The Switch SAE with 128 experts is a Pareto improvement compared to the ReLU SAE in terms of loss recovered. The Switch SAE with 128 experts is a Pareto improvement compared to the ReLU SAE in terms of MSE, excluding when . The scenario for the 128 expert Switch SAE is an extreme case: each expert SAE has features, meaning that the TopK activation is effectively irrelevant. When L0 is low, Switch SAEs perform particularly well. This suggests that the features that improve reconstruction fidelity the most for a given activation lie within the same cluster.
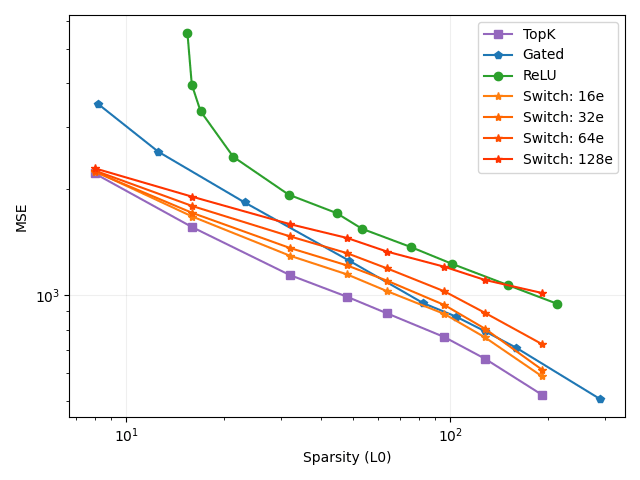
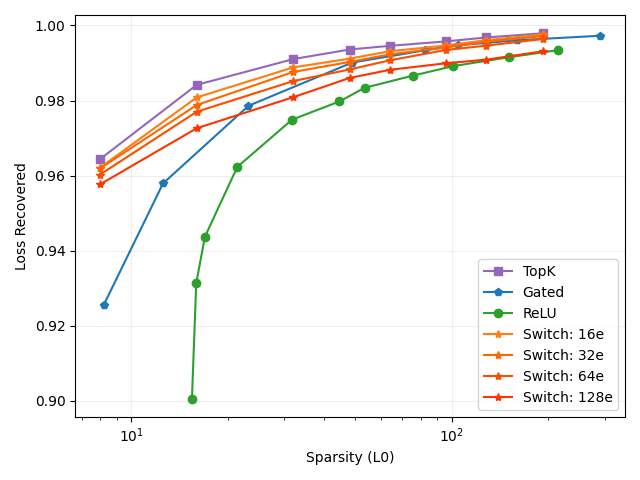
These results demonstrate that Switch SAEs can reduce the number of FLOPs per activation by up to 128x while still retaining the performance of a ReLU SAE. Switch SAEs can likely achieve greater acceleration on larger language models.
3.2 FLOP-Matched Results
We train Switch SAEs with 2, 4 and 8 experts (Figure 4, 5, 6). The Switch SAEs are a Pareto improvement over the TopK, Gated and ReLU SAEs in terms of both MSE and loss recovered. As we scale up the number of experts and represent more features, performance continues to increase while keeping computational costs and memory costs (from storing the pre-activations) roughly constant.
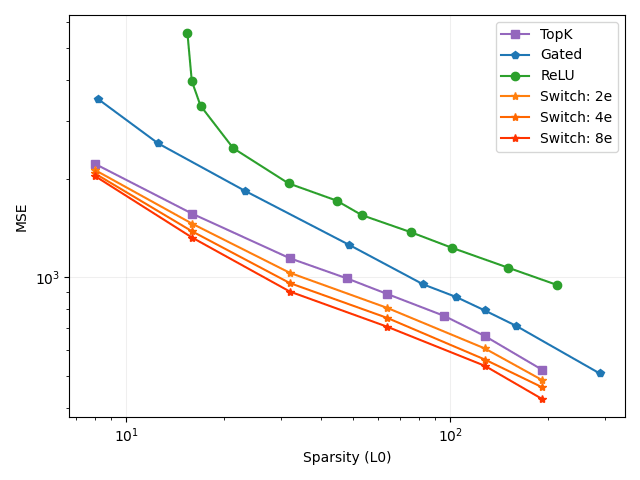
Fedus et al. find that their sparsely-activated Switch Transformer is significantly more sample-efficient compared to FLOP-matched, dense transformer variants. We similarly find that our Switch SAEs are 5x more sample-efficient compared to the FLOP-matched, TopK SAE baseline. Our Switch SAEs achieve the reconstruction MSE of a TopK SAE trained for 100K steps in less than 20K steps. This result is consistent across 2, 4 and 8 expert Switch SAEs.
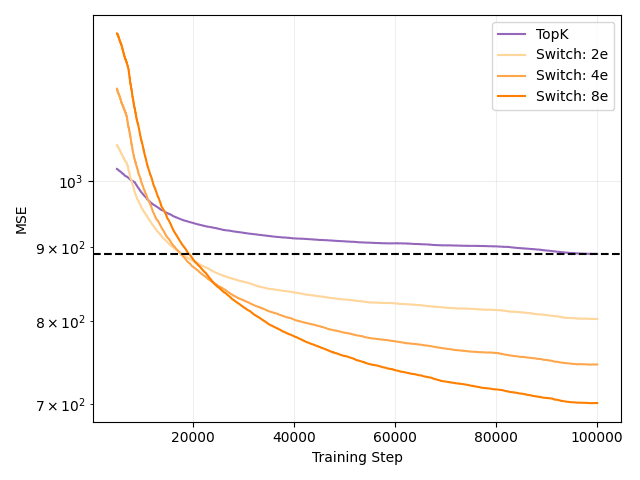
Switch SAEs speed up training while capturing more features and keeping the number of FLOPs per activation fixed. Kaplan et al. similarly find that larger models are more sample efficient.
4. Conclusion
The diverse capabilities (e.g., trigonometry, 1960s history, TV show trivia) of frontier models suggest the presence of a huge number of features. Templeton et al. and Gao et al. make massive strides by successfully scaling sparse autoencoders to millions of features. Unfortunately, millions of features are not sufficient to capture all the relevant features of frontier models. Templeton et al. estimate that Claude 3 Sonnet may have billions of features, and Gao et al. empirically predict that future larger models will require more features to achieve the same reconstruction fidelity. If we are unable to train sufficiently wide SAEs, we may miss safety-crucial features such as those related to security vulnerabilities, deception and CBRN. Thus, further research must be done to improve the efficiency and scalability of SAE training. To monitor future superintelligent language models, we will likely need to perform SAE inference during the forward pass of the language model to detect safety-relevant features. Large-scale labs may be unwilling to perform this extra computation unless it is both computationally and memory efficient and does not dramatically slow down model inference. It is therefore crucial that we additionally improve the inference time of SAEs.
Thus far, the field has been bottlenecked by the encoder forward pass, the sole dense matrix multiplication involved in SAE training and inference. This work presents the first attempt to overcome the encoder forward pass bottleneck. Taking inspiration from Shazeer et al. and Fedus et al., we introduce the Switch Sparse Autoencoder, which replaces the standard large SAE with many smaller expert SAEs. The Switch Sparse Autoencoder leverages a trainable router that determines which expert is used, allowing us to scale the number of features without increasing the computational cost. When keeping the width of the SAE fixed, we find that we can reduce the number of FLOPs per activation by up to 128x while still maintaining a Pareto improvement over the ReLU SAE. When fixing the number of FLOPs per activation, we find that Switch SAEs train 5x faster and are a Pareto improvement over TopK, Gated and ReLU SAEs.
Future Work
This work is the first to combine Mixture-of-Experts with Sparse Autoencoders to improve the efficiency of dictionary learning. There are many potential avenues to expand upon this work.
- We restrict our attention to combining the Switch layer (Fedus et al.) with the TopK SAE (Gao et al.). It is possible that combining the Switch layer with the ReLU SAE or the Gated SAE may have superior qualities.
- We require that every expert within a Switch SAE is homogeneous in terms of the number of features and the sparsity level. Future work could relax this constraint to allow for non-uniform feature cluster sizes and adaptive sparsity.
- Switch SAEs trained on larger language models may begin to suffer from dead latents. Future work could include a modified AuxK loss to prevent this.
- We restrict our attention to a single router. Future work could explore the possibility of further scaling the number of experts with hierarchical routers. Doing so may provide additional insight into feature splitting and geometry.
- Following Fedus et al., we route to a single expert SAE. It is possible that selecting several experts will improve performance. The computational cost will scale with the number of experts chosen.
- The routing network resembles the encoder of a sparse autoencoder. How do the feature directions of the routing network relate to the features of the corresponding expert SAEs?
- In this work, we train Switch SAEs on the residual stream, but future work could train Switch SAEs on the MLPs and attention heads.
Acknowledgements
This work was supervised by Christian Schroeder de Witt and Josh Engels. I used the dictionary learning repository to train my SAEs. I would like to thank Samuel Marks and Can Rager for advice on how to use the repository. I would also like to thank Jacob Goldman-Wetzler, Achyuta Rajaram, Michael Pearce, Gitanjali Rao, Satvik Golechha, Kola Ayonrinde, Rupali Bhati, Louis Jaburi, Vedang Lad, Adam Karvonen, Shiva Mudide, Sandy Tanwisuth, JP Rivera and Juan Gil for helpful discussions.
20 comments
Comments sorted by top scores.
comment by Noa Nabeshima (noa-nabeshima) · 2024-07-22T21:38:54.079Z · LW(p) · GW(p)
Sometimes FLOP/s isn't the bottleneck for training models; e.g. it could be memory bandwidth. My impression from poking around with Nsight and some other observations is that wide SAEs might actually be FLOP/s bottlenecked but I don't trust my impression that much. I'd be interested in someone doing a comparison of this SAE architectures in terms of H100 seconds or something like that in addition to FLOP.
Did it seem to you like this architecture also trained faster in terms of wall-time?
Anyway, nice work! It's cool to see these results.
↑ comment by Noa Nabeshima (noa-nabeshima) · 2025-03-29T22:42:27.415Z · LW(p) · GW(p)
If this is your implementation:
https://github.com/amudide/switch_sae/blob/main/dictionary_learning/trainers/switch.py
It looks like you when you encode you do a dense encoder forward pass and then mask using the expert router.
I think this means that the FLOP scaling laws claim is misleading because (my impression is that) your current train code uses much more FLOP than the scaling law graphs, because it calculates every expert's activations for every input.
But I think the empirical claims about the learned features and the FLOP scaling laws still should hold up for implementations that actually do the conditional computations.
I also expect H100/B100-time scaling charts than FLOP charts to be more informative for future work because I now think memory-bandwidth has decent odds of being the main bottleneck for training time.
↑ comment by Anish Mudide (anish-mudide) · 2024-07-23T20:17:19.631Z · LW(p) · GW(p)
Thanks for the comment -- I trained TopK SAEs with various widths (all fitting within a single GPU) and observed wider SAEs take substantially longer to train, which leads me to believe that the encoder forward pass is a major bottleneck for wall-clock time. The Switch SAE also improves memory efficiency because we do not need to store all latents.
I'm currently working on implementing expert-parallelism, which I hope will lead to substantial improvements to wall-clock time.
comment by Lee Sharkey (Lee_Sharkey) · 2024-07-23T10:46:54.516Z · LW(p) · GW(p)
Great work! Very excited to see work in this direction (In fact, I didn't know you were working on this, so I'd expressed enthusiasm for MoE SAEs in our recent list [AF · GW] of project ideas published just a few days ago!)
Comments:
- I'd love to see some geometric analysis of the router. Is it just approximately a down-projection from the encoder features learned by a dense SAE trained on the same activations?
- Consider integrating with SAELens.
Following Fedus et al., we route to a single expert SAE. It is possible that selecting several experts will improve performance. The computational cost will scale with the number of experts chosen.
- If there are some very common features in particular layers (e.g. an 'attend to BOS' feature), then restricting one expert to be active at a time will potentially force SAEs to learn common features in every expert.
↑ comment by Arthur Conmy (arthur-conmy) · 2024-07-23T11:06:21.132Z · LW(p) · GW(p)
If there are some very common features in particular layers (e.g. an 'attend to BOS' feature), then restricting one expert to be active at a time will potentially force SAEs to learn common features in every expert.
+1 to similar concerns -- I would have probably left one expert always on. This should both remove some redundant features.
Replies from: anish-mudide↑ comment by Anish Mudide (anish-mudide) · 2024-07-23T20:32:30.119Z · LW(p) · GW(p)
Hi Lee and Arthur, thanks for the feedback! I agree that routing to a single expert will force redundant features and will experiment with Arthur's suggestion. I haven't taken a close look at the router/expert geometry yet but plan to do so soon.
↑ comment by phenomanon (ekg) · 2024-07-26T00:16:48.194Z · LW(p) · GW(p)
Hi Lee, if I may ask, when you say "geometric analysis" of the router, do you mean analysis of the parameters or activations? Are there any papers that perform the sort of analysis you'd like seen done? Asking from the perspective of someone who understands nns thoroughly but is new to mechinterp.
Replies from: Lee_Sharkey↑ comment by Lee Sharkey (Lee_Sharkey) · 2024-07-26T11:06:38.239Z · LW(p) · GW(p)
Both of these seem like interesting directions (I had parameters in mind, but params and activations are too closely linked to ignore one or the other). And I don't have a super clear idea but something like representational similarity analysis between SwitchSAEs and regular SAEs could be interesting. This is just one possibility of many though. I haven't thought about it for long enough to be able to list many more, but it feels like a direction with low hanging fruit for sure. For papers, here's a good place to start for RSA: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3730178/
↑ comment by phenomanon (ekg) · 2024-07-26T22:19:09.503Z · LW(p) · GW(p)
Thank you very much for your reply - I appreciate the commentary and direction
comment by phenomanon (ekg) · 2024-07-23T19:19:00.570Z · LW(p) · GW(p)
For a batch with activations, we first compute vectors and . represents what proportion of activations are sent to each expert
Hi, I'm not exactly sure where f fits in here. In Figure 1/section 2.2, it seems like x is fed into the router layer, which produces a distribution over the N experts, from which the "best expert" is chosen. I'm not sure where the "proportion of activations" is in that process. To me that sounds like it's describing something that would be multiplied by x before it's fed into an expert, but I don't see that reflected in the diagram or described in section 2.2.
Replies from: anish-mudide↑ comment by Anish Mudide (anish-mudide) · 2024-07-23T20:44:19.853Z · LW(p) · GW(p)
Thanks for the question -- is calculated over an entire batch of inputs, not a single . Figure 1 shows how the Switch SAE processes a single residual stream activation .
Replies from: ekg↑ comment by phenomanon (ekg) · 2024-07-24T18:49:07.280Z · LW(p) · GW(p)
Thank you for the answer, that makes more sense.
comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2024-07-23T18:49:30.634Z · LW(p) · GW(p)
I haven’t read the full post yet, but I’m wondering if it’s possible to train Switch SAEs for ViT?
Replies from: anish-mudidecomment by Aaron_Scher · 2024-07-23T07:10:40.431Z · LW(p) · GW(p)
Nice work, these seem like interesting and useful results!
High level question/comment which might be totally off: one benefit of having a single, large, SAE neuron space that each token gets projected into is that features don't get in each other's way, except insofar as you're imposing sparsity. Like, your "I'm inside a parenthetical" and your "I'm attempting a coup" features will both activate in the SAE hidden layer, as long as they're in the top k features (for some sparsity). But introducing switch SAEs breaks that: if these two features are in different experts, only one of them will activate in the SAE hidden layer (based on whatever your gating learned).
The obvious reply is "but look at the empirical results you fool! The switch SAEs are pretty good!" And that's fair. I weakly expect what is happening in your experiment is that similar but slightly specialized features are being learned by each expert (a testable hypothesis), and maybe you get enough of this redundancy that it's fine e.g,. the expert with "I'm inside a parenthetical" also has a "Words relevant to coups" feature and this is enough signal for coup detection in that expert.
Again, maybe this worry is totally off or I'm misunderstanding something.
Replies from: anish-mudide↑ comment by Anish Mudide (anish-mudide) · 2024-07-23T20:54:56.748Z · LW(p) · GW(p)
Thanks for your comment! I believe your concern was echoed by Lee and Arthur in their comments and is completely valid. This work is primarily a proof-of-concept that we can successfully scale SAEs by directly applying MoE, but I suspect that we will need to make tweaks to the architecture.
comment by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-08-13T02:15:52.562Z · LW(p) · GW(p)
Can I ask what you used to implement the MOE routing? Did you use megablocks? I would love to expand on this research but I can't find any straightforward implementation of efficient pytorch MOE routing online.
Do you simply iterate over each max probability expert every time you feed in a batch?
Replies from: louka-ewington-pitsos↑ comment by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-08-13T09:39:57.220Z · LW(p) · GW(p)
wait a minute... could you just...
you don't just literally do this do you?
input = torch.tensor([
[1, 2],
[1, 2],
[1, 2],
]) # (bs, input_dim)
enc_expert_1 = torch.tensor([
[1, 1, 1, 1],
[1, 1, 1, 1],
])
enc_expert_2 = torch.tensor([
[3, 3, 0, 0],
[0, 0, 2, 0],
])
dec_expert_1 = torch.tensor([
[ -1, -1],
[ -1, -1],
[ -1, -1],
[ -1, -1],
])
dec_expert_2 = torch.tensor([
[-10, -10,],
[-10, -10,],
[-10, -10,],
[-10, -10,],
])
def moe(input, enc, dec, nonlinearity):
input = input.unsqueeze(1)
latent = torch.bmm(input, enc)
recon = torch.bmm(nonlinearity(latent, dec))
return recon.squeeze(1), latent.squeeze(1)
# not this! some kind of actual routing algorithm, but you end up with something similar
enc = torch.stack([enc_expert_1, enc_expert_2, enc_expert_1])
dec = torch.stack([dec_expert_1, dec_expert_2, dec_expert_1])
nonlinearity = torch.nn.ReLU()
recons, latent = moe(input, enc, dec, nonlinearity)
This must in some way be horrifically inefficient, right?
Replies from: louka-ewington-pitsos↑ comment by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-08-19T04:06:46.566Z · LW(p) · GW(p)
Just to close the loop on this one, the official huggingface transformers library just uses a for-loop to achieve MoE. I also implemented a version myself using a for loop and it's much more efficient than either vanilla matrix multiplication or that weird batch matmul I write up there for large latent and batch sizes.
comment by Review Bot · 2024-08-09T00:13:29.760Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?