Towards Multimodal Interpretability: Learning Sparse Interpretable Features in Vision Transformers
post by hugofry · 2024-04-29T20:57:35.127Z · LW · GW · 8 commentsContents
Executive Summary Motivation What is a Vision Transformer? What is CLIP? Training the SAE Examples of SAE Features Interesting and Amusing Features Era/Time Features: 1950's Era Feature: Place/Culture Features: African Animals: Film/TV Features: Disney: Texture Features: Pixelation: Chromatic aberration: Miscellaneous Features: Mum and babies: Animals eating other animals: Repeated identical animals or people: Taxidermy: Museum exhibits: NSFW Features: How Trustworthy are Highest Activating Images? Tennis Feature Border Terrier Feature Mushrooms Feature Birds on Branches/in Foliage Training Performance Sparsity and l0 MSE, l1 and Model Losses Identifying the Ultra-Low Density Cluster Neuron Alignment Future Work None 10 comments
Executive Summary
In this post I present my results from training a Sparse Autoencoder (SAE) on a CLIP Vision Transformer (ViT) using the ImageNet-1k dataset. I have created an interactive web app, 'SAE Explorer', to allow the public to explore the visual features the SAE has learnt, found here: https://sae-explorer.streamlit.app/ (best viewed on a laptop). My results illustrate that SAEs can identify sparse and highly interpretable directions in the residual stream of vision models, enabling inference time inspections on the model's activations. To demonstrate this, I have included a 'guess the input image' game on the web app that allows users to guess the input image purely from the SAE activations of a single layer and token of the residual stream. I have also uploaded a (slightly outdated) accompanying talk of my results, primarily listing SAE features I found interesting: https://youtu.be/bY4Hw5zSXzQ.
The primary purpose of this post is to demonstrate and emphasise that SAEs are effective at identifying interpretable directions in the activation space of vision models. In this post I highlight a small number my favourite SAE features to demonstrate some of the abstract concepts the SAE has identified within the model's representations. I then analyse a small number of SAE features using feature visualisation to check the validity of the SAE interpretations. Later in the post, I provide some technical analysis of the SAE. I identify a large cluster of features analogous to the 'ultra-low frequency' cluster that Anthropic identified. In line with existing research [AF · GW], I find that this ultra-low frequency cluster represents a single feature. I then analyse the 'neuron-alignment' of SAE features by comparing the SAE encoder matrix the MLP out matrix.
This research was conducted as part of the ML Alignment and Theory Scholars program 2023/2024 winter cohort. Special thanks to Joseph Bloom for providing generous amounts of his time and support (in addition to the SAE Lens code base) as well as LEAP labs for helping to produce the feature visualisations and weekly meetings with Jessica Rumbelow. I would also like to thank Andy Arditi, Egg Syntax, Sonia Joseph and Rob Graham for useful advice and feedback in producing this post.
Since writing this post, I have found the research of Rao et al.[1] who have independently trained an SAE on a CLIP Vision Transformer. Their work, titled "Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery", independently produce similar results under the framework of Concept Bottleneck Models (CBMs). However, in contrast to Rao et al. that uses their dictionary vectors to automatically name the extracted concepts and then construct performant task-agnostic CBMs on downstream datasets, my work analyzes properties of the trained SAEs similar to Bricken et al.. Our research was developed concurrently, in parallel and without knowledge of each other.
Example, animals eating other animals feature: (top 16 highest activating images)

Example, Italian feature: Note that the photo of the dog has a watermark with a website ending in .it (Italy's domain name). Note also that the bottom left photo is of Italian writing. The number of ambulances present is a byproduct of using ImageNet-1k.

Motivation
Frontier AI systems are becoming increasingly multimodal, and capabilities may advance significantly as multimodality increases due to transfer learning between different data modalities and tasks. As a heuristic, consider how much intuition humans gain for the world through visual reasoning; even in abstract settings such as in maths and physics, concepts are often understood most intuitively through visual reasoning. Many cutting edge systems today such as DALL-E and Sora use ViTs trained on multimodal data. Almost by definition, AGI is likely to be multimodal. Despite this, very little effort has been made to apply and adapt our current mechanistic interpretability techniques to vision tasks or multimodal models. I believe it is important to check that mechanistic interpretability generalises to these systems in order to ensure they are future-proof and can be applied to safeguard against AGI.
In this post, I restrict the scope of my research to specifically investigating SAEs trained on multimodal models. The particular multimodal system I investigate is CLIP, a model trained on image-text pairs. CLIP consists of two encoders: a language model and a vision model that are trained to encode image and text in similar ways when they are from the same pair, and in dissimilar ways when they are from distinct pairs. By training in this way, information about the text is absorbed into the embeddings for the image and vice versa. CLIP is the basis of systems such as DALL-E and Stable Diffusion.
What is a Vision Transformer?
A vision transformer is a vision model with the structure of a transformer. The model works as follows:
- An input image is resized to a standard dimensionality, in this case dimensions.
- The image is broken down into a grid of image patches. Each image patch now has a dimension of .
- Each image patch is flattened to form a vector of size .
- Each of these vectors is embedded by a shared linear map to form an embedding of a fixed dimension (in this case ).
- A positional embedding is added to each of the patch embeddings, before the grid of embeddings is flattened to form tokens.
- In order to generate a single embedding vector for the whole image, an additional 'class' token is included which can attend to all the patch tokens.
- The tokens are then fed into a transformer, with full attention between the image patches. The output of the class token is used as the embedding vector for the whole image.

Note that by flattening each image patch before creating the embedding vectors, the ViT has to learn both the colour channels and the spatial relationships between each of the pixels. There is no locality or translation equivariance baked into the model architecture, unlike in CNNs. Despite this, ViTs are the current state of the art architecture for computer vision. For more information on ViTs I recommend the paper "An image is worth 16x16 words".
What is CLIP?
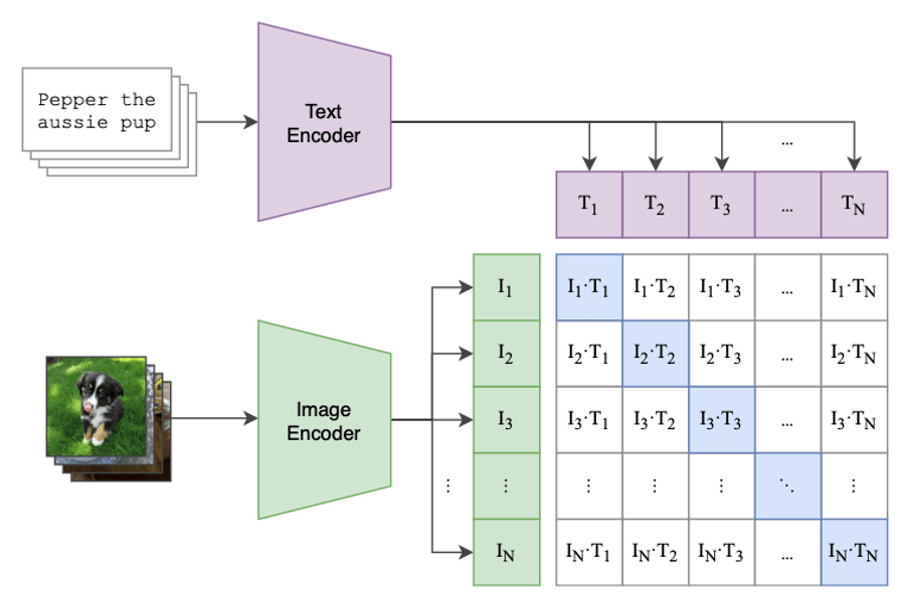
CLIP stands for Contrastive Language-Image Pre-training. CLIP consists of two models trained together: a language model encoder and a vision model encoder. The CLIP model is trained on an internet-scale dataset of (image, text) pairs. The model is trained to encode image and text in similar ways when they are from the same pair, and in dissimilar ways when they are from distinct pairs. In particular, the CLIP model is trained as follows:
- A batch of (image, text) pairs are sampled from the dataset.
- All images and text prompts are fed into the vision model and language model respectively to generate text encodings and N image encodings .
- The cosine similarity between each of the embedding pairs (, ) is calculated to form an matrix of cosine similarities.
- A probability distribution is created for each row and column using a softmax of the cosine similarities. These probability distributions represent the probability that the image and text came from the same pair in the dataset.
- The cross entropy loss is calculated for each row and column.
- The total loss is taken to be the average cross entropy loss across all rows and columns.
For more information on CLIP, I recommend reading the original CLIP paper.
Training the SAE
In this post I train an SAE on the residual stream of the class token of CLIP ViT Large. The implementation details are given below: [2]
- Model: CLIP ViT Large.
- Location: the output of layer 22 (of 24) on the residual stream of the class token.
- Training dataset: ImageNet-1k.
- SAE expansion factor: 64.
- Total number of training images (tokens): 2 621 440 (batch size 1024).
The class token was chosen so that the SAE learns features relevant to the whole image. A later layer was chosen so that the SAE features represent more abstract concepts. I believe this is the first published research to apply SAEs to vision models or multimodal systems.
Examples of SAE Features
This section examines individual features found by the SAE. For each feature, the top 16 highest activating images are visualised in a grid. If you are only interested in the technical analysis of the SAE, I encourage you to skip to the section titled "Training Performance".
Interesting and Amusing Features
There are tonnes of interesting and amusing features, I have only included a small subset of them here. I highly encourage you to explore and find your own features in SAE Explorer (https://sae-explorer.streamlit.app/).
Era/Time Features:
These features are potentially safety relevant. Understanding how models represent time could be a first step towards understanding how they might make plans and long term goals. I have only included two such features here for brevity.
World War I Era Feature: Note the ocean liner SS Kronprinzessin Cecilie and the biplane.

1950's Era Feature:

Place/Culture Features:
France: Check for yourself with google lens, all of these photos are of French things (including the French national football team kit, and a Dassault Rafale fighter jet).

Turkey: Note the yellow Turkish school bus!

Italy: Note the photo of the dog has a watermark with a website ending in .it (Italy's domain name). Note also the bottom left is a photo of Italian writing. The number of ambulances is a byproduct of ImageNet-1k.
African Animals:

Film/TV Features:
Harry Potter: The number of bridges present is a byproduct of using ImageNet-1k.

Doctor Who: Notice the penguin is wearing Tom Baker's Dr Who scarf.

Disney:

Texture Features:
Pixelation:

Chromatic aberration:

Miscellaneous Features:
Mum and babies:

Animals eating other animals:
Repeated identical animals or people:

Rain: Note the rain gauges.

Taxidermy:

Museum exhibits:

NSFW Features:
I have not included the highest activating images of these features in this post for obvious reasons, but the curious among you can search the neuron index using the 'neuron navigator' in SAE Explorer. (NB: none of the images are graphic or disturbing.)
- Sex (including sheep and flies): index 49344.
- Violence/death: index 1417.
- Sexual fetishes: index 29775.
How Trustworthy are Highest Activating Images?
The highest activating images appear to be highly interpretable, but how can we be sure that they are faithfully representing the SAE feature? Perhaps the SAE feature is actually activating on some spurious correlation present in the highest activating images and not the feature we have identified. To answer this question, I have taken a few SAE features and generated feature visualisations from the CLIP model with the SAE. I have only included the 9 highest activating images to make space for the feature visualisations. These visualisations were created using the Leap Labs API.
Tennis Feature
Note the presence of the "ATP" in the feature visualisation - the acronym for the Association of Tennis Professionals. Note also the presence of the wrist band (common in tennis), the tennis rackets and tennis balls.

Border Terrier Feature

Mushrooms Feature

Birds on Branches/in Foliage

Training Performance
Sparsity and
The sparsity of an SAE feature measures how frequently an SAE feature fires. For example, a sparsity of 0.01 means the feature fires on 1% of input images.
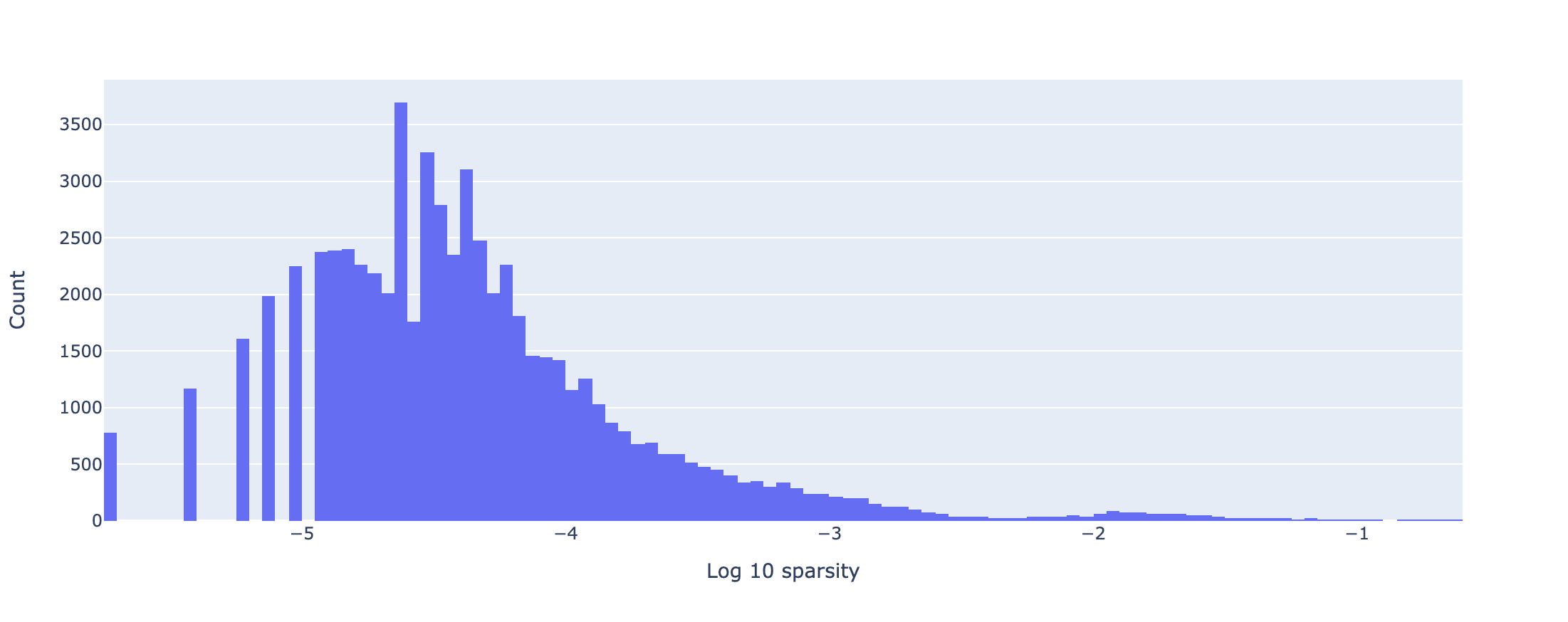
The sparsity histogram above was evaluated over 524 288 images. The histogram illustrates that none of the SAE features are dead. Additionally, the final value of was (the average number of SAE features that fire on an input image). These both suggest that the SAE has learnt sparse representations of the data.
MSE, and Model Losses
| Loss type | MSE | Model with SAE (contrastive loss) | Original model (contrastive loss) | |
| Value | 0.0027 | 13.9 | 1.775 | 1.895 |
Note that the model with the SAE attains a lower loss than the original model. It is not clear to me why this is the case. In fact, the model with the SAE gets a lower loss than the original model within 40 000 training tokens. Further investigation is needed. Explained variance is 86%, definitely lower than I would like.
Identifying the Ultra-Low Density Cluster
The vast majority of SAE features fall into a cluster analogous to the 'ultra-low density' cluster that Anthropic identified. To show this, I have plotted the distribution of SAE features through the following three metrics:
- (-axis) .
- (-axis) (mean activation value taken across the 20 highest activating images for each feature).
- (Colour) Label entropy: entropy of the ImageNet-1k labels across the 20 highest activating images of each feature (if 20 exist, else across the set of all images that activate the feature). The probabilities used in the entropy calculation are weighted linearly by the associated activation value.
The distribution of SAE features according to these three metrics is shown below:
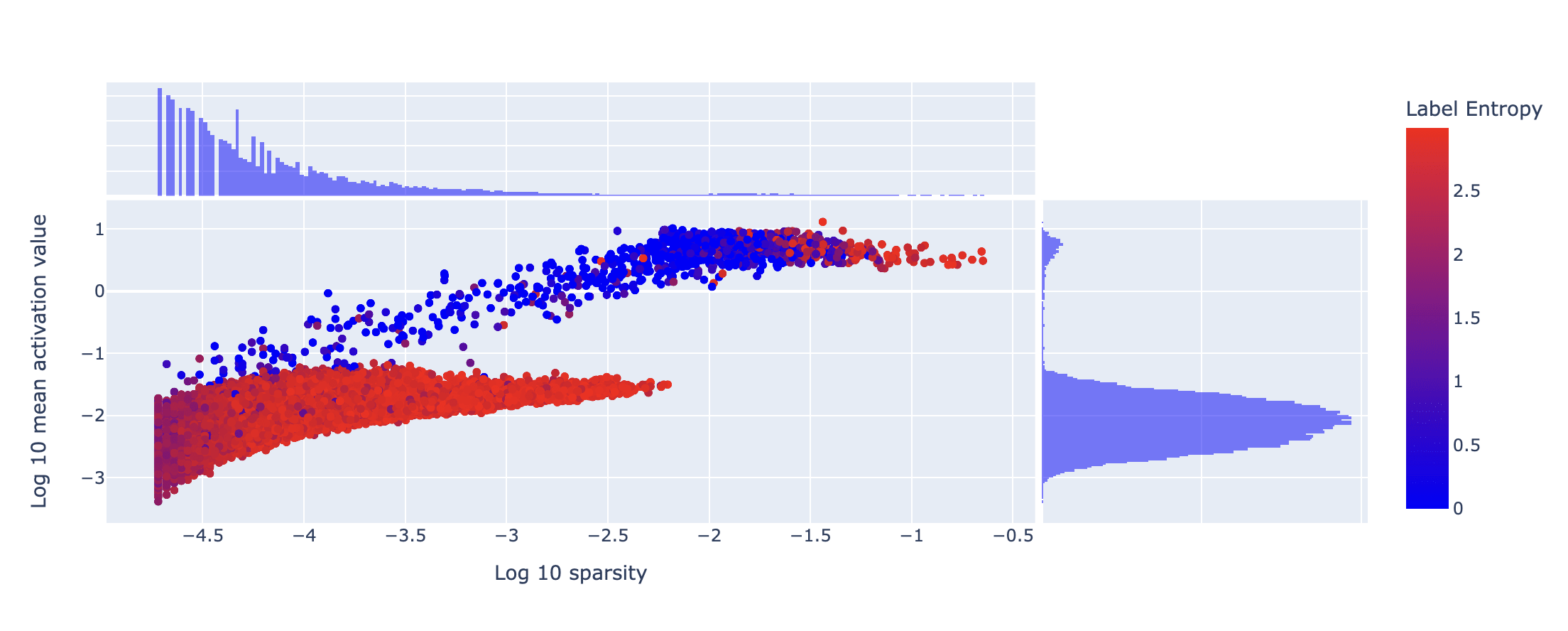
You can clearly see that the SAE features split into two clusters, most strikingly separated by the marginalised histogram for mean activation value. The lower band contains almost all of the features, and these features fire randomly on the inputs (high label entropy). The features in the upper band are also quite well separated by the label entropy, although there are some high label entropy, high density features too (discussion on these features below). The number of features in the ultra-low density cluster suggests that my expansion factor is too high. Retraining with an expansion factor of 16 (4x smaller) produces very similar results:
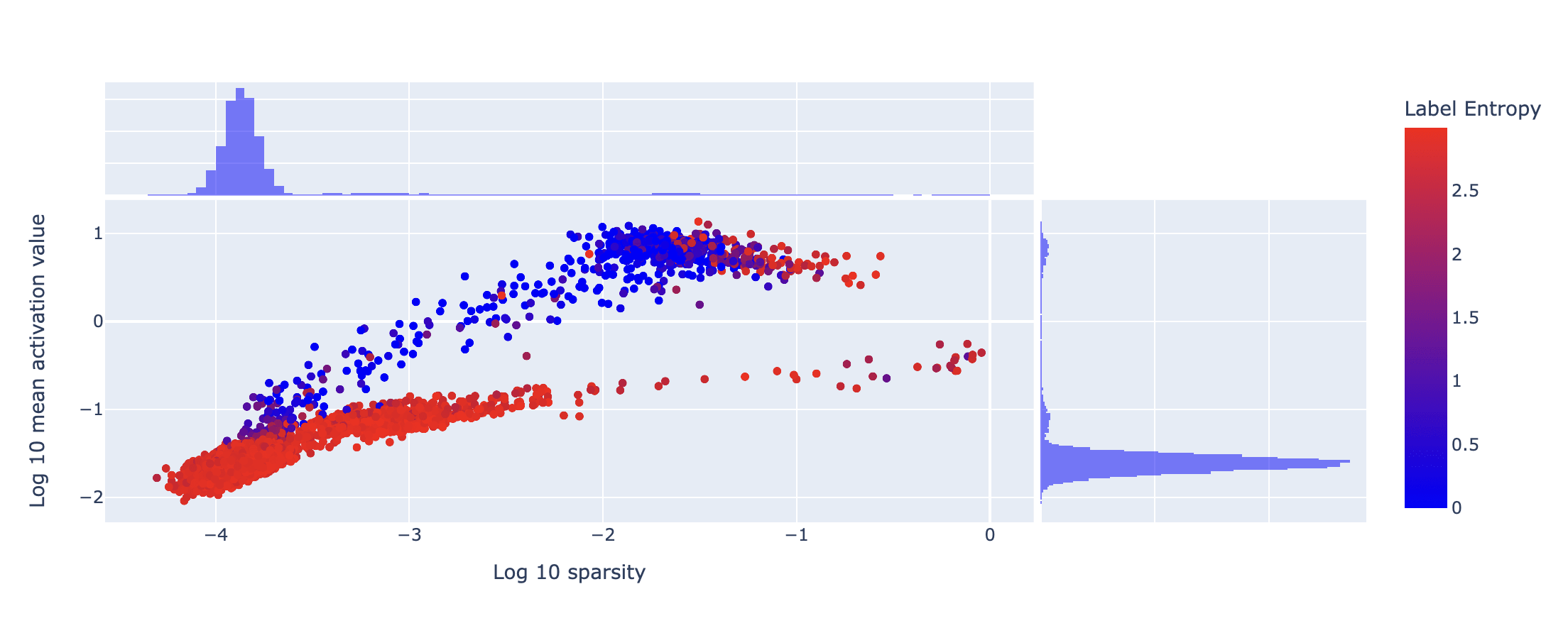
I believe the reason there are so many features in the ultra-low density cluster is a byproduct of the fact that the SAE was trained on ImageNet-1k. ImageNet-1k contains 1000 image classes with ~ 1 000 000 training images. The dataset is not very high dimensional or particularly sparse. For example, 118 of the classes are of dogs (more than 1 in 10 images), and therefore a dog feature would fire with a sparsity of more than -1. The CLIP model was also trained on a much larger internet scale dataset. When restricted to the ImageNet-1k dataset, I therefore suspect that a large proportion of the CLIP model's activations can be recovered with a relatively small number of features. My primary goal for the next steps of my research is to reproduce these graphs for an SAE trained on a much larger dataset such as LAION-400M, though this is currently unavailable.
Another interesting point to note is that, inline with other research [LW · GW], the ultra-low density cluster represents a single feature; the cosine similarity between feature encoder vectors in this cluster is very high. In fact for the expansion factor 16 SAE, despite having an ~26, I found an input image that caused 6458 SAE features to fire (39.42% of all SAE features).
A quick note on the label entropy distribution of SAE features in the dense cluster:
- Label entropy > 0 features in the dense cluster usually provide interesting examples of interpretable features that don't naturally align with ImageNet-1k classes. You can explore these features through SAE Explorer, but I have provided some of my favourite examples later in this post. However, some of the very high label entropy examples in the dense cluster appear completely uninterpretable. These features may be doing some dense uninterpretable linear algebra operations. It is also possible that they could be representing non-robust features present in the images and so appear uninterpretable to humans (see Adversarial Examples Are Not Bugs, They Are Features for an explanation of non-robust features). Further investigation is needed here.
- Label entropy = 0 features represent something correlated to or present in the ImageNet-1k class or a subset of the ImageNet-1k class. While label entropy = 0 features may seem boring cases where the SAE has simply learnt the class labels, they actually provide an interesting examination of the model's taxonomy within each ImageNet-1k class and may be interesting to study from the perspective of feature splitting.
Neuron Alignment
In this section, I will restrict only to non-ultra-low frequency features.
Existing vision model interpretability methods have predominantly focussed on neuron level interpretability, such as neuron feature visualisation (cf. DeepDream). This highlights the need to check whether the features the SAE has learnt are neuron aligned. In particular, in this section I analyse the similarity between the (residual stream) SAE feature encoder vectors and the MLP out vectors. Note that in the residual stream, the MLP out vectors form an over complete basis.
In the histogram below, I computed the cosine similarity between each SAE encoder vector and each MLP out vector. I then calculated the maximum cosine similarity across all the MLP vectors, for each SAE feature. I repeated this calculation for random vectors in place of the SAE encoder vectors to act as a benchmark (with the same number of random vectors as SAE features).
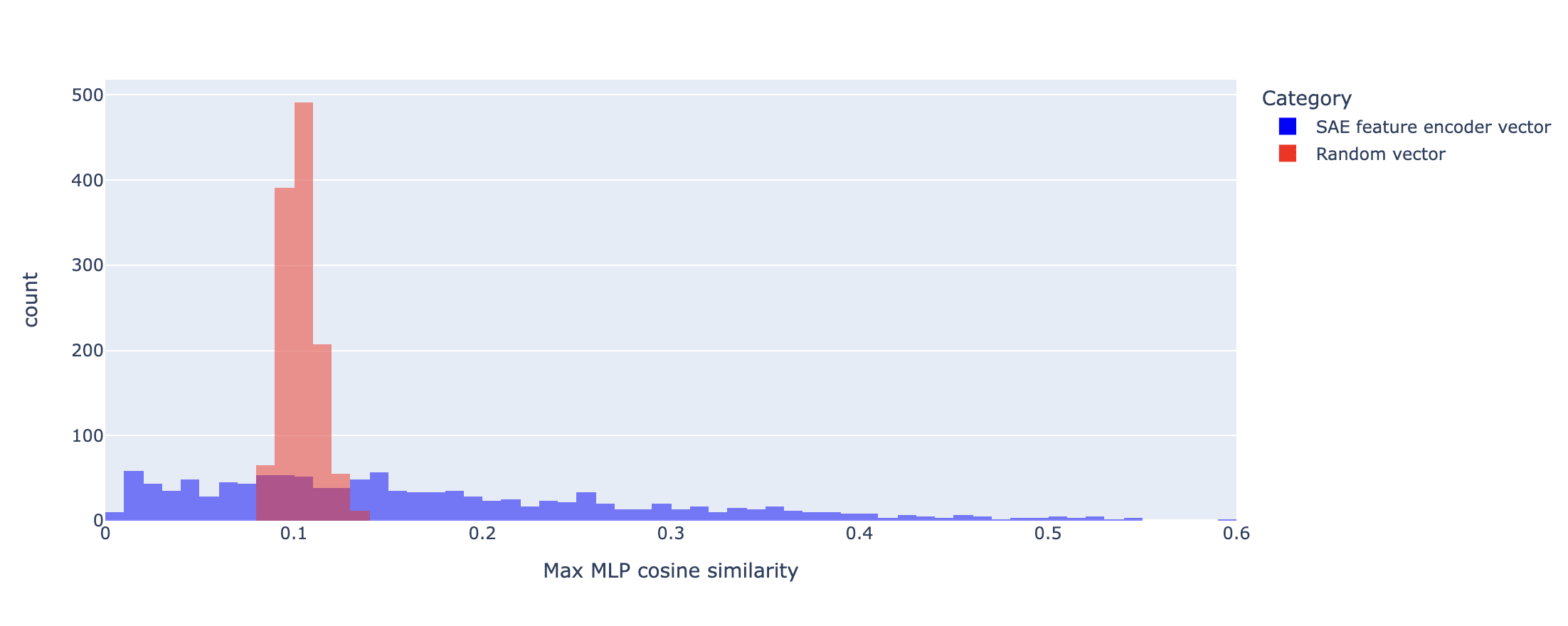
The cosine similarities for random vectors fall in the range [0.08, 0.14]. Approximately half of the SAE features fall above the random range, and half are either within or below it. A significant number of SAE features are therefore either significantly more or significantly less neuron aligned than random. By defining 'neuron aligned' to mean having a cosine similarity greater than 0.14, we can also plot the number of MLP neurons each SAE feature is aligned to:
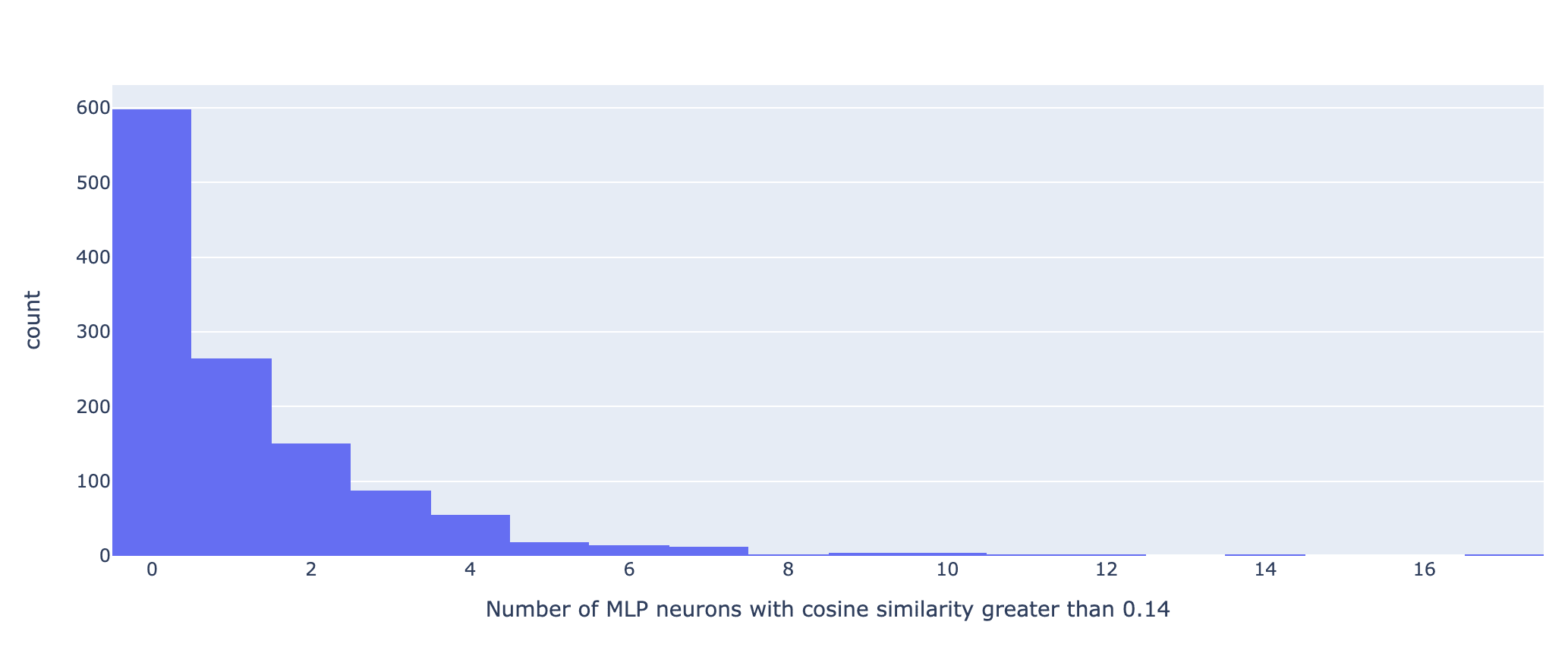
This is a very crude analysis of neuron alignment, but these results show that about a half of the features are not neuron aligned at all, and the other half are aligned mostly to a small number of MLP neurons (typically less than 5). Perhaps this is unsurprising; the SAE was trained on the residual stream just after the MLP layer, where you would expect roughly half the information present to have originated from the MLP.
I have also generated the highest activating images for each MLP neuron and they all appear to be polysemantic, combining typically 3 or 4 unrelated features of the data (they are all much less interpretable than the SAE features). Additionally, I have analysed the neuron alignment to MLPs in earlier layers, and the results show that there is no alignment of the SAE features with any previous MLP layer (I found this surprising).
I have included cosine similarity line plots for each of the SAE neurons under the 'neuron navigator' in SAE Explorer. To get a feel for how neuron aligned the individual SAE features are, I would recommend spending five minutes in the app looking through features.
Future Work
I am intending to continue working on this research, conditional on obtaining funding. If you know of any funding bodies or individuals who would be interested in supporting this research then please leave a comment!
The most important next step is to replicate this work on a much larger internet scale dataset. I believe that many of the issues and limitations with my current research are due to training on ImageNet-1k.
After validating my results on a larger dataset, I want to train on patch tokens, across all layers. This work would be naturally integrated into the Prisma library, enabling a larger community of researchers to build on my work. This would enable me to identify 'sparse feature circuits' in the CLIP ViT model. I have a team of collaborators excited to work on this particular project. I would be particularly excited to analyse adversarial images from the perspective of sparse feature circuits.
Building a platform that displays the SAE features in an 'activation atlas' is another research direction that I find interesting, as it enables visualisations of the interactions and relationships between SAE features.
Another important direction of future work is developing better automated interpretability methods. While I have managed to get feature visualisation working, it is too hyper-parameter dependent and compute expensive to scale as an auto-interp method. I would be excited to get automated text descriptions of the SAE features working. Automated scoring of the text explanations can be achieved using ablations in conjunction with the CLIP multimodal space.
- ^
Rao, S., Mahajan, S., Böhle, M., & Schiele, B. (2024). Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery. In Proceedings of the European Conference on Computer Vision (ECCV).
- ^
The SAE was trained with ghost grads and used the geometric median to initialise the decoder bias. The following hyper-parameters were used. learning rate: 0.0004 (with a linear warm up). l_1 coefficient: 0.00008.
8 comments
Comments sorted by top scores.
comment by Arthur Conmy (arthur-conmy) · 2024-04-29T21:25:51.456Z · LW(p) · GW(p)
Awesome work! I notice I am surprised that this just worked given just 1M datapoints (we use 1000x this with LMs, even small ones), and not needing any new techniques, and producing subjectively extremely abstract features (IMO).
It would be nice if the "guess the image" game was presented as a result rather than a fun side thing in this post. AFAICT that's the only interpretability result that can't be critiqued as cherry-picked. You should state front and center that the top features for arbitrary images are basically interpretable, it's a great result!
Replies from: hugofry↑ comment by hugofry · 2024-04-30T22:03:02.742Z · LW(p) · GW(p)
Thanks for the feedback! Yeah I was also surprised SAEs seem to work on ViTs pretty much straight out of the box (I didn't even need to play around with the hyper parameters too much)! As I mentioned in the post I think it would be really interesting to train on a much larger (more typical) dataset - similar to the dataset the CLIP model was trained on.
I also agree that I probably should have emphasised the "guess the image" game as a result rather than an aside, I'll bare that in mind for future posts!
comment by LawrenceC (LawChan) · 2024-04-29T23:25:35.204Z · LW(p) · GW(p)
Cool work!
As with Arthur, I'm pretty surprised by. how much easier vision seems to be than text for interp (in line with previous results). It makes sense why feature visualization and adversarial attacks work better with continuous inputs, but if it is true that you need fewer datapoints to recover concepts of comparable complexity, I wonder if it's a statement about image datasets or about vision in general (e.g. "abstract" concepts are more useful for prediction, since the n-gram/skip n-gram/syntactical feature baseline is much weaker).
I think the most interesting result to me is your result where the went down (!!):
Note that the model with the SAE attains a lower loss than the original model. It is not clear to me why this is the case. In fact, the model with the SAE gets a lower loss than the original model within 40 000 training tokens.
My guess is this happens because CLIP wasn't trained on imagenet -- but instead a much larger dataset that comes from a different distribution. A lot of the SAE residual probably consists of features that are useful in on the larger dataset, but not imagenet. If you extract the directions of variation on imagenet instead of OAI's 400m image-text pair dataset, it makes sense why reconstructing inputs using only these directions lead to better performance on the dataset you found these inputs on.
I'm not sure how you computed the contrastive loss here -- is it just the standard contrastive loss, but on image pairs instead of image/text pairs (using the SAE'ed ViT for both representations), or did you use the contextless class label as the text input here (only SAE'ing the ViT part but not the text encoder). Either way, this might add additional distributional shift.
(And I could be misunderstanding what you did entirely, and that you actually looked at contrastive loss on the original dataset somehow, in which case the explanation I gave up doesn't apply.)
Replies from: LawChan, hugofry↑ comment by LawrenceC (LawChan) · 2024-04-29T23:28:24.636Z · LW(p) · GW(p)
Also have you looked at the dot product of each of the SAE directions/SAE reconstructed representaitons with the image net labels fed through the text encoder??
Replies from: hugofry↑ comment by hugofry · 2024-04-30T23:17:36.817Z · LW(p) · GW(p)
Ah yes! I tried doing exactly this to produce a sort of 'logit lens' to explain the SAE features. In particular I tried the following.
- Take an SAE feature encoder direction and map it directly to the multimodal space to get an embedding.
- Pass each of the ImageNet text prompts “A photo of a {label}.” through the CLIP text model to generate the multimodal embeddings for each ImageNet class.
- Calculate the cosine similarities between the SAE embedding and the ImageNet class embeddings. Pass this through a softmax to get a probability distribution.
- Look at the ImageNet labels with a high probability - this should give some explanation as to what the SAE feature is representing.
Surprisingly, this did not work at all! I only spent a small amount of time trying to get this to work (<1day), so I'm planning to try again. If I remember correctly, I also tried the same analysis for the decoder feature vector and also tried shifting by the decoder bias vector too - both of these didn't seem to provide good ImageNet class explanations of the SAE features. I will try doing this again and I can let you know how it goes!
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2024-05-04T16:56:32.478Z · LW(p) · GW(p)
Huh, that's indeed somewhat surprising if the SAE features are capturing the things that matter to CLIP (in that they reduce loss) and only those things, as opposed to "salient directions of variation in the data". I'm curious exactly what "failing to work" means -- here I think the negative result (and the exact details of said result) are argubaly more interesting than a positive result would be.
↑ comment by hugofry · 2024-04-30T23:06:10.169Z · LW(p) · GW(p)
Thanks for the comments! I am also surprised that SAEs trained on these vision models seem to require such little data. Especially as I would have thought the complexity of CLIP's representations for vision would be comparable to the complexity for text (after all we can generate an image from a text prompt, and then use a captioning model to recover the text suggesting most/all of the information in the text is also present in the image).
With regards to the model loss, I used the text template “A photo of a {label}.”, where {label} is the ImageNet text label (this was the template used in the original CLIP paper). These text prompts were used alongside the associated batch of images and passed jointly into the full CLIP model (text and vision models) using the original contrastive loss function that CLIP was trained on. I used this loss calculation (with this template) to measure both the original model loss and the model loss with the SAE inserted during the forward pass.
I also agree completely with your explanation for the reduction in loss. My tentative explanation goes something like this:
- Many of the ImageNet classes are very similar (eg 118 classes are of dogs and 18 are of primates). A model such as CLIP that is trained on a much larger dataset may struggle to differentiate the subtle differences in dog breeds and primate species. These classes alone may provide a large chunk of the loss when evaluated on ImageNet.
- CLIP's representations of many of these classes will likely be very similar,[1] using only a small subspace of the residual stream to separate these classes. When the SAE is included during the forward pass, some random error is introduced into the model's activations and so these representations will on average drift apart from each other, separating slightly. This on average will decrease the contrastive loss when restricted to ImageNet (but not on a much larger dataset where the activations will not be clustered in this way).
That was a very hand-wavy explanation but I think I can formalise it with some maths if people are unconvinced by it.
- ^
I have some data to suggest this is the case even from the perspective of SAE features. The dog SAE features have much higher label entropy (mixing many dog species in the highest activating images) compared to other non-dog classes, suggesting the SAE features struggle to separate the dog species.
comment by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-09-06T23:15:21.002Z · LW(p) · GW(p)
I couldn't find a link to the code in the article so in case anyone else wants to try to replicate I think this is it: https://github.com/HugoFry/mats_sae_training_for_ViTs