Comparing Alignment to other AGI interventions: Extensions and analysis
post by Martín Soto (martinsq) · 2024-03-21T17:30:50.747Z · LW · GW · 0 commentsContents
Adding Evidential Cooperation in Large worlds Negative evidence Reservations Further extensions and analysis None No comments
In the last post [LW · GW] I presented the basic, bare-bones model, used to assess the Expected Value of different interventions, and especially those related to Cooperative AI (as distinct from value Alignment). Here I briefly discuss important enhancements, and our strategy with regards to all-things-considered estimates.
I describe first an easy but meaningful addition to the details of our model (which you can also toy with in Guesstimate).
Adding Evidential Cooperation in Large worlds [LW · GW]
Due to evidential considerations, our decision to forward this or that action might provide evidence about what other civilizations (or sub-groups inside a civilization similar to us) have done. So for example us forwarding a higher should give us evidence about other civilizations doing the same, and this should alter the AGI landscape.
But there's a problem: we have only modelled singletons themselves (AGIs), not their predecessors (civilizations). We have, for example, the fraction of AGIs with our values. But what is the fraction of civilizations with our values? Should it be higher (due to our values being more easily evolved than trained), or lower (due to our values being an attractor in mind-space)?
While a more complicated model could deal directly with these issues by explicitly modelling civilizations (and indeed this is explored in later extensions), for now we can pull a neat trick that gets us most of what we want without enlarging the ontology of the model further, nor the amount of input estimates.
Assume for simplicity alignment is approximately as hard for all civilizations (both in and ), so that they each have of aligning their AGI (just like we do). Then, of the civilizations in will increase , by creating an AGI with our values. And the rest will increase . What about ? of them will increase . But the misalignment case is trickier, because it might be a few of their misaligned AGIs randomly have our values. Let's assume for simplicity (since and are usually small enough) that the probability with which a random misaligned (to its creators) AGI has our values is the same fraction that our values have in the universe, after all AGIs have been created: .[1] Then, goes to increase , and goes to increase .
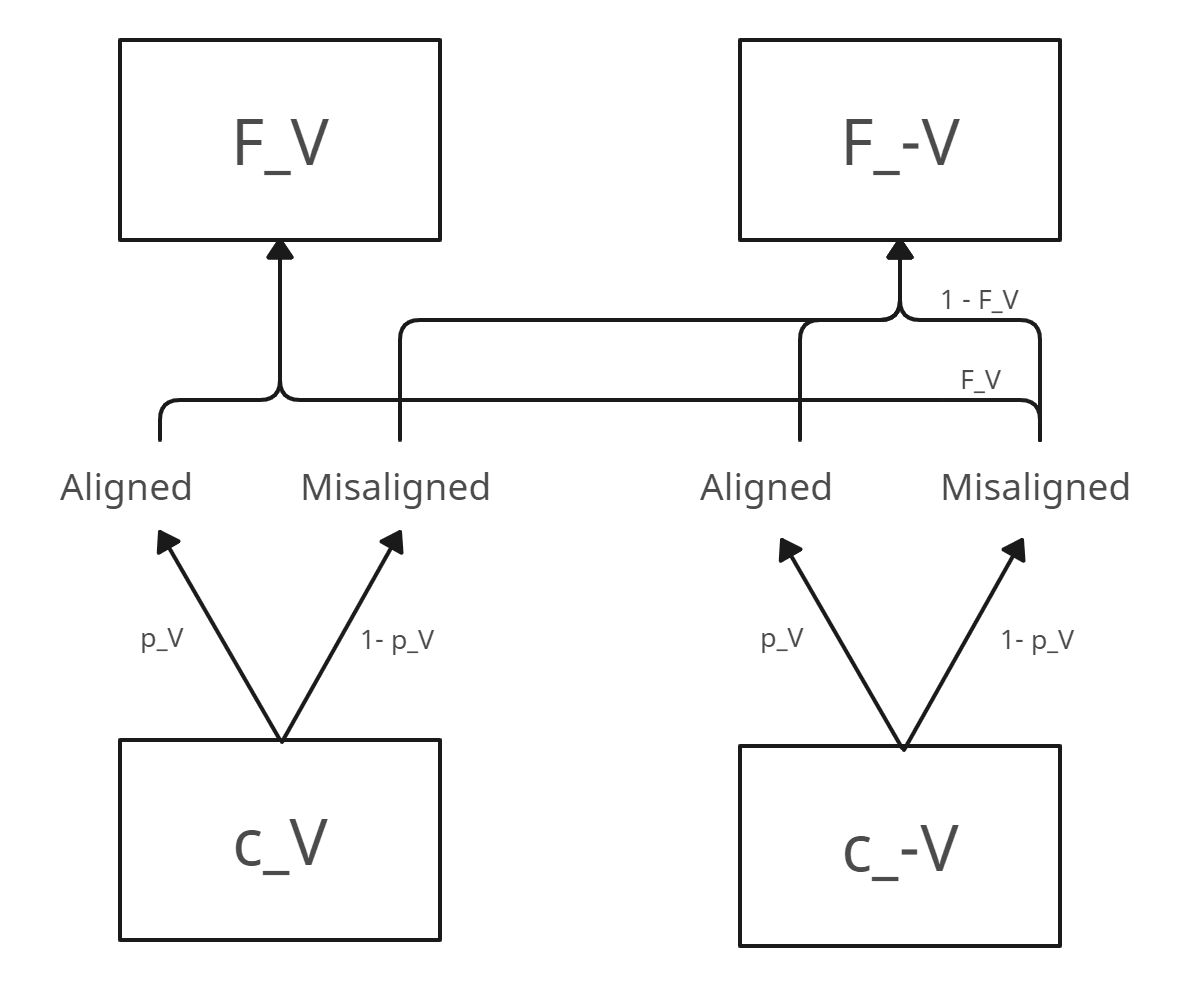
This all defines a system of equations in which the only unknown is , so we can deduce its value!
With this estimate, and with some guesses and for how correlated we are with civilizations with and without our values[2], and again simplistically assuming that the tractabilities of the different interventions are approximately the same for all civilizations, we can compute a good proxy for evidential effects.
As an example, to our previous expression for we will add
This is because our working on cooperativeness for misalignment provides evidence also do (having an effect if their AI is indeed misaligned), but it also provides evidence for doing so, which only affects the fraction of cooperative misaligned AIs if their AI is indeed misaligned (to their creators), and additionally it doesn't randomly land on our values. We similarly derive the expressions for all other corrections.
Negative evidence
In fact, there's a further complication: our taking a marginal action not only gives us evidence for other civilizations taking that action, but also for them not taking the other available actions.
To see why this should be the case in our setting, notice the following. If our estimates of the intermediate variables like had been "against the baseline of our correlated agents not taking any of the actions available to them", then indeed we could just update their actions positively from that baseline, when we learn of our own actions. But that's not how we intuitively assess such parameters. Whether we think about it more or less explicitly, our estimate for will already have incorporated (as upstream variables) some vague considerations about how common our values are amongst civilizations, how successful they are at alignment, etc. So we are already assuming these actions happen (whether they be the actions of whole civilizations, of sub-parts of them analogous to our community, or of individuals like yourself), and our estimates sprout from a vague background distribution about which actions are more likely (even if this is not a variable explicitly represented in the model). So observing an action will give us evidence shifting these values in different directions, since the total sum of the actions will have to be 1 (although we could also include the action "do nothing" to this sum).
To account for this, we resort to the simplistic approximation that 1 unit of evidence towards one of the three classes of interventions also yields -0.5 units of evidence for each of the other two.
Reservations
While implementing small positive and doesn't swamp the calculus as much as we might have expected, it does provide decisive sways in many regimes. So I will warn that the conceptual motivation for these considerations is in more speculative grounds.
It's unclear if our action in this situation has enough signal to surpass the noise. It intuitively seems like it is quite contingent on our past history, and even if we were closer to Expected Value Maximizers it might depend on some quirks of our values (although this could be accounted for). Although maybe you want to implement the Evidentialist's Wager, by being uncertain about whether is non-zero.
You can toy with the model in this Guesstimate implementation.
Further extensions and analysis
As mentioned in the first post, one of the parts of the base model that felt most ungrounded and lacking structure was estimating relative utilities and bargaining success. So working on that direction, I also developed modifications that natively represent important parts of bargaining like trade, conflict, escalation and running out of resources.
With the more complex models I performed some sensitivity analyses to assess how robustly good different interventions are. And while strong opinions about some of the inputs (for example, a MIRI-like view on value formation) can drastically alter conclusions, a minimally wide distribution makes cooperation work competitive with alignment.
Those details aren't included in this quick write-up, which was meant to showcase the basic modelling idea and its benefits (more exhaustive versions are less polished). But feel free to reach out if you're interested in an all-things-considered assessment of the value of Cooperative AI work.
- ^
This is a background guess that tries to be "as agnostic as possible" about how mind-space looks, but of course the guess is already opinion-laden. One might think, for example, our values almost never result from optimized training processes (of the kind any civilization builds), and only from evolution. In that case, this fraction would need to be way lower than , or even 0. This could of course be implemented as another variable in the model, but I didn't want to complexify it further for now.
- ^
In more detail, is the change in the probability of a random member of taking action , given we take action (as compared to us not taking it).
0 comments
Comments sorted by top scores.