Comparing Alignment to other AGI interventions: Basic model
post by Martín Soto (martinsq) · 2024-03-20T18:17:50.072Z · LW · GW · 4 commentsContents
Setup Full list of variables Mathematical derivations Some discussion What does bargaining success look like? What do utilities look like? What do tractabilities look like? Implementation and extensions None 4 comments
Interventions that increase the probability of Aligned AGI aren't the only kind of AGI-related work [LW · GW] that could importantly increase the Expected Value of the future. Here I present a very basic quantitative model (which you can run yourself here) to start thinking about these issues. In a follow-up post [LW · GW] I give a brief overview of extensions and analysis.
A main motivation of this enterprise is to assess whether interventions in the realm of Cooperative AI, that increase collaboration or reduce costly conflict, can seem like an optimal marginal allocation of resources. More concretely, in a utility framework, we compare
- Alignment interventions (): increasing the probability that one or more agents have our values.
- Cooperation interventions given alignment (): increasing the gains from trade and reducing the cost from conflict for agents with our values.
- Cooperation interventions given misalignment (): increasing the gains from trade and reducing the cost from conflict for agents without our values.
We used a model-based approach (see here [AF(p) · GW(p)] for a discussion of its benefits) paired with qualitative analysis. While these two posts don't constitute an exhaustive analysis (more exhaustive versions are less polished), feel free to reach out if you're interested in this question and want to hear more about this work.
Most of this post is a replication of previous work by Hjalmar Wijk and Tristan Cook (unpublished). The basic modelling idea we're building upon is to define how different variables affect our utility, and then incrementally compute or estimate partial derivatives to assess the value of marginal work on this or that kind of intervention.
Setup
We model a multi-agentic situation. We classify each agent as either having (approximately) our values () or any other values (). We also classify them as either cooperative () or non-cooperative ().[1] These classifications are binary. We are also (for now) agnostic about what these agents represent. Indeed, this basic multi-agentic model will be applicable (with differently informed estimates) to any scenario with multiple singletons, including the following:
- Different AGIs (or other kinds of singletons, like AI-augmented nation-states) interacting causally on Earth
- Singletons arising from different planets interacting causally in the lightcone
- Singletons from across the multi-verse interacting acausally [? · GW]
The variable we care about is total utility (). As a simplifying assumption, our way to compute it will be as a weighted interpolation of two binary extremes: one in which bargaining goes (for agents with our values) as well as possible (), and another one in which it goes as badly as possible (). The interpolation coefficient () could be interpreted as "percentage of interactions that result in minimally cooperative bargaining settlements".
We also consider all our interventions are on only a single one of the agents (which controls a fraction of total resources), which usually represents our AGI or our civilization.[2] And these interventions are coarsely grouped into alignment work (), cooperation work targeted at worlds with high alignment power (), and cooperation work targeted at worlds with low alignment power ().
The overall structure looks like this:
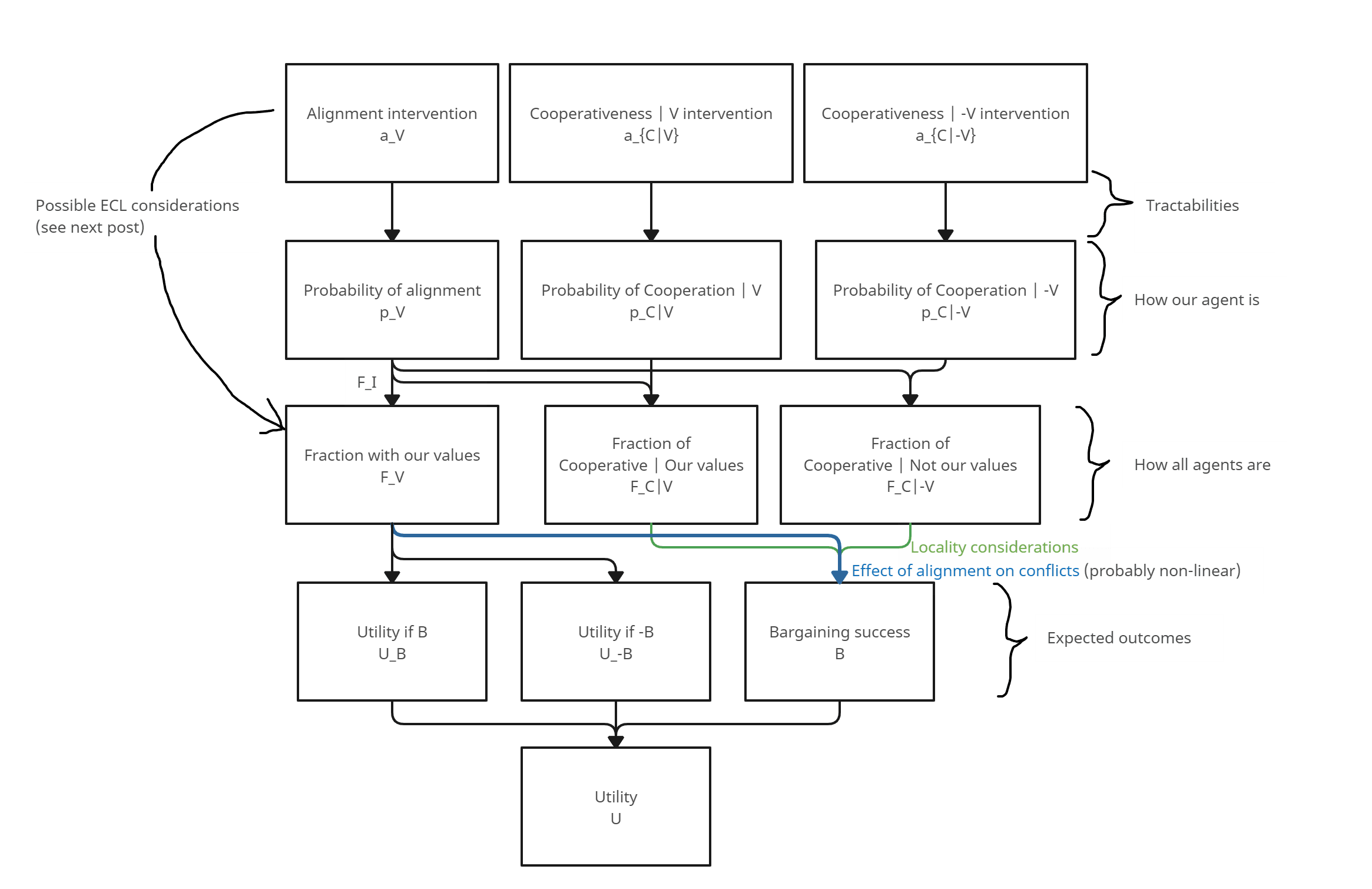
Full list of variables
This section safely skippable.
The first 4 variables model expected outcomes:
- : Utility attained in the possible world where our bargaining goes as well as possible.
- : Utility attained in the possible world where our bargaining goes as badly as possible.
- : Baseline (expected) success of bargaining (for agents with our values), used to interpolate between and . Can be interpreted as "percentage of interactions that result in minimally cooperative bargaining settlements".
- : Total (expected) utility. We define it as the interpolation
The next 3 variables model how the multi-agent landscape looks.
- : Fraction (weighted by resources) of the agents that have our values.
- : Fraction (weighted by resources) of the agents having our values that are cooperative.
- : Fraction (weighted by resources) of the agents not having our values that are cooperative.
The last 7 variables model how we can affect a single agent through different interventions.
- : Fraction (weighted by measure) that this single agent represents.
- : Baseline probability of said agent having our values.
- : Baseline probability of said agent being cooperative conditional on it having our values.
- : Baseline probability of said agent being cooperative conditional on it not having our values.
- : Interventions affecting the above probabilities. We think of these as the fraction of our efforts that we spend on each kind of intervention.
Mathematical derivations
This section safely skippable.
Our goal is to estimate , given we have some values for and (tractability assessments).
By chain rule
We begin by studying the 3 partial derivatives of U appearing in ().
For the first, product and chain rules give
That is, changing the fraction of agents with our values can change the success of bargaining (first summand) and also the value of different scenarios (second and third summands).
For the second and third derivatives, we assume the fractions of cooperative agents can only affect bargaining success, but don't change the intrinsic value of futures in any other way. For example, it is not terminally good for agents to be cooperative (that is, the existence of a cooperative agent doesn't immediately increase our utility). Thus, all of and are 0. So again by product and chain and by these nullifications
We now turn to the other derivatives of (), which correspond to how our action changes the landscape of agents.
For the first, our action only changes the fraction of agents with our values by making our agent more likely to have our values[3]:
For the second one we get something more complicated. By chain rule
Clearly , that is, changing the probability that our agent is cooperative if it were to not have our values won't alter in any case the fraction of agents with our values that are aligned.
But , since making your agent have your values could alter this fraction if your agent is atypically (un)cooperative. By considering and using the division rule we get
Intuitively, if our agent is atypically (un)cooperative, making it have our values will accordingly alter the proportion of cooperative agents with our values.
We deal with similarly by the division rule and obtain
So in summary
For the third derivative we proceed analogously and obtain
Finally, putting everything together in () we obtain (grouped by intervention)
where we have defined
When running simulations with very small, we might want to take it logarithmic for numerical stability.
Some discussion
What does bargaining success look like?
For starters, if interactions happen non-locally with respect to value systems (so that we are as likely to find ourselves interacting with agents having or not having our values), then we'd expect to benefit more from cooperation increases in bigger classes of agents. That is, would be proportional to (usually small), and to (big), which would cancel out in (cv) and (cv), resulting simply in the recommendation "intervene to make cooperative the kind of system most likely to happen".
But there might be locality effects, so that we are more likely to find ourselves in a trade situation with agents having our values (and that would partly counteract the above difference):
- This might happen because values are correlated with cognitive architecture, and agents find it easier to communicate with others with similar architectures (maybe due to simulations or saliency). But this effect would seem weak under a strong orthogonality thesis.
- This might also happen because of agents being more inclined to cooperate with similar values. Although this could also be modelled as terminally valuing some forms of cooperation (or disvaluing others), thus breaking our assumption that cooperation is not terminally (dis)valued.
Overall, thinking about locality by using the single variable , which encompasses bargaining success both with similar and distant values, turns out to be clunky. In later extensions this is improved.
Another possible confounder is the effect of value coalition sizes on bargaining. For example, we could think that, holding cooperativeness constant, bigger value coalitions make bargaining easier due to less chaos or computational cost. In that case, going from 50% to 95% of agents having our values () would be stabilizing (and so is positive in this regime), while going from 0% to 1% would be destabilizing ( negative). It's not even clear this should hold close to the extremes of , since maybe when an almost-all-powerful coalition exists it is better for it to destroy the other small agents.
Maybe to account for this we could think of not as the distribution over "which AGIs / civilizations are created", but instead "the fraction under multi-agentic stability". That is, the distribution of those AGIs / civilizations after already waging any possible war with others. But that might not be a good approximation, since in reality war and cooperation are very intertwined, and not neatly temporally separated (and this might still be the case for AGIs).
While some of our final model's inputs can be informed by these coalition considerations, there doesn't seem to be an easy way around modelling coalition-forming more explicitly if we want good approximations.
We're also not yet including effects on cooperation from Evidential Cooperation in Large worlds [AF · GW] (see the next post).
What do utilities look like?
will vary a lot depending on, for example, how common we expect retributive or punitive actions to be.
will also vary a lot depending on your ethics (for example, how cosmopolitan vs parochial are your values) and opinions about the multi-agent landscape.
What do tractabilities look like?
We assume as a first simplification that the return on investment is linear, that is, and are all constant.
This might not be that bad of an approximation (for marginal assessments) when, a priori, we are pretty uncertain about whether X more researcher-hours will lead to an unexpected break-through that allows for rapid intervention, or yield basically nothing. So the derivative should just be the expected gain linearly. But there are some instances in which this approximation fails more strongly, like when thinking about technical implementation work: We know a priori that we'll need to spend at least Y researcher-hours to be able to implement anything.
Implementation and extensions
You can toy with the model yourself here (instructions inside).
As mentioned above, it still seems like this bare-bones model is missing some important additional structure. Especially, estimating and feels most ungrounded. This is discussed in the next post.
These two posts don't constitute an exhaustive analysis (more exhaustive versions are less polished), so feel free to reach out if you're interested in an all-things-considered assessment of the value of Cooperative AI work.
Work done at CLR's SRF 2023. Thanks to Tristan Cook and the rest of CLR for their help.
- ^
For now, the definitions of and are left vague. In fact, in Hjalmar's basic model we are free to choose whichever concretization, as long as the same one informs our assessments of and . In latter extensions this was no longer the case and we worked with concrete definitions.
- ^
Of course, this stops being the case in, for example, the multi-polar Earth scenario. In such cases we can interpret as an estimate of the fraction of agents (weighted by resources) our interventions can affect. Although some of the framings and intuitions below do overfit to the "single-agent" scenario.
- ^
So we are ignoring some weird situations like "agents being more cooperative makes them notice our values are better".
4 comments
Comments sorted by top scores.
comment by NicholasKees (nick_kees) · 2024-03-20T23:07:29.150Z · LW(p) · GW(p)
A main motivation of this enterprise is to assess whether interventions in the realm of Cooperative AI, that increase collaboration or reduce costly conflict, can seem like an optimal marginal allocation of resources.
After reading the first three paragraphs, I had basically no idea what interventions you were aiming to evaluate. Later on in the text, I gather you are talking about coordination between AI singletons, but I still feel like I'm missing something about what problem exactly you are aiming to solve with this. I could have definitely used a longer, more explain-like-I'm-five level introduction.
Replies from: martinsq↑ comment by Martín Soto (martinsq) · 2024-03-20T23:25:21.859Z · LW(p) · GW(p)
You're right, I forgot to explicitly explain that somewhere! Thanks for the notice, it's now fixed :)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-03-20T20:49:33.545Z · LW(p) · GW(p)
Hjalmar Wijk (unpublished)
And Tristan too right? I don't remember which parts he did & whether they were relevant to your work. But he was involved at some point.
↑ comment by Martín Soto (martinsq) · 2024-03-20T22:41:04.886Z · LW(p) · GW(p)
My impression was that this one model was mostly Hjalmar, with Tristan's supervision. But I'm unsure, and that's enough to include anyway, so I will change that, thanks :)