The Problem with Reasoners by Aidan McLaughin
post by t14n (tommy-nguyen-1) · 2024-11-25T20:24:26.021Z · LW · GW · 1 commentsThis is a link post for https://aidanmclaughlin.notion.site/reasoners-problem
Contents
1 comment
Some critique on reasoning models like o1 (by OpenAI) and r1 (by Deepseek).
OpenAI admits that they trained o1 on domains with easy verification but hope reasoners generalize to all domains. Whether or not they generalize beyond their RL training is a trillion-dollar question. Right off the bat, I’ll tell you my take:
o1-style reasoners do not meaningfully generalize beyond their training.
A straightforward way to check how reasoners perform on domains without easy verification is benchmarks. On math/coding, OpenAI's o1 models do exceptionally. On everything else, the answer is less clear.
Results that jump out:
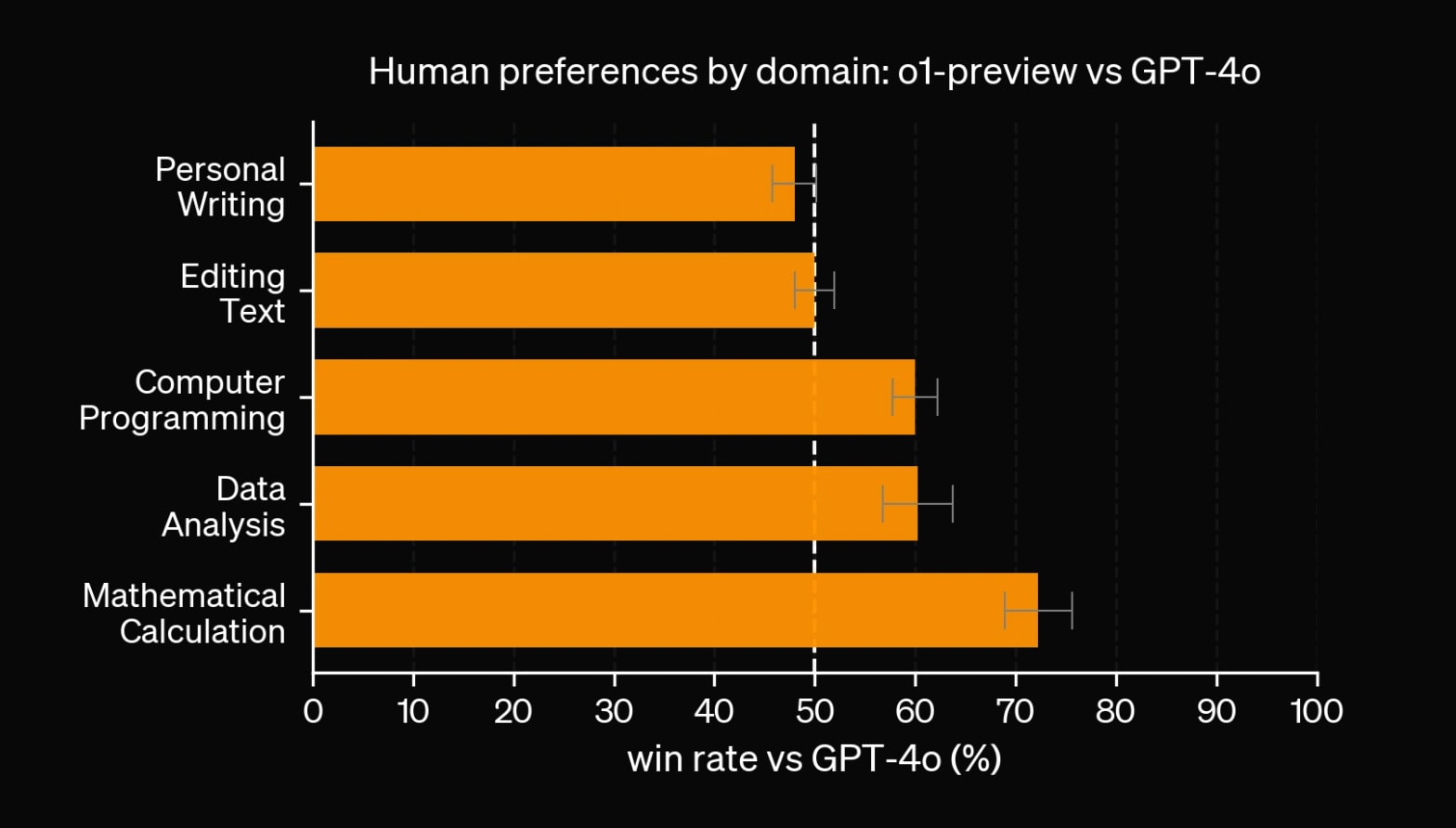
o1-previewdoes worse on personal writing thangpt-4oand no better on editing text, despite costing 6 × more.- OpenAI didn't release scores for
o1-mini, which suggests they may be worse thano1-preview.o1-minialso costs more thangpt-4o.- On eqbench (which tests emotional understanding), o1-preview performs as well as
gemma-27b.- On eqbench, o1-mini performs as well as
gpt-3.5-turbo. No you didn’t misread that: it performs as well asgpt-3.5-turbo.
Throughout this essay, I’ve doomsayed o1-like reasoners because they’re locked into domains with easy verification. You won't see inference performance scale if you can’t gather near-unlimited practice examples for o1.
...
I expect transformative AI to come remarkably soon. I hope labs iron out the wrinkles in scaling model size. But if we do end up scaling model size to address these changes, what was the point of inference compute scaling again?
Remember, inference scaling endows today’s models with tomorrow’s capabilities. It allows you to skip the wait. If you want faster AI progress, you want inference to be a 1:1 replacement for training.
o1 is not the inference-time compute unlock we deserve.
If the entire AI industry moves toward reasoners, our future might be more boring than I thought.
1 comments
Comments sorted by top scores.
comment by Seth Herd · 2024-11-25T22:57:36.578Z · LW(p) · GW(p)
This is quite compelling, as far as it goes.
But it doesn't go far enough. The technique itself generalizes outside of easy-to-verify domains like math and physics.
You don't need perfect or easy verification for this technique to work. You only need a little traction on guessing whether an answer is better or worse to use as a training signal. Humans and AlphaZero do this in different ways: they do a brief tree search using their current best quick guesses at the situation, do some sort of evaluation to estimate which is the best of those answers, then use that to update their next quick guesses in a similar situation. In those cases there's some feedback from the environment, but that's not necessary: you just need an evaluation process that's marginally better than the guessing process to make forward progress.
The Marco o1 system takes this approach, and we'll see more. And they'll probably work. There's a real question of whether they're efficient enough to outpace just scaling up models and refining their synthetic data; but it's one route toward progress.