On Deliberative Alignment
post by Zvi · 2025-02-11T13:00:07.683Z · LW · GW · 1 commentsContents
How Deliberative Alignment Works Why This Worries Me For Mundane Safety It Works Well None 1 comment
Not too long ago, OpenAI presented a paper on their new strategy of Deliberative Alignment.
The way this works is that they tell the model what its policies are and then have the model think about whether it should comply with a request.
This is an important transition, so this post will go over my perspective on the new strategy.
Note the similarities, and also differences, with Anthropic’s Constitutional AI.
How Deliberative Alignment Works
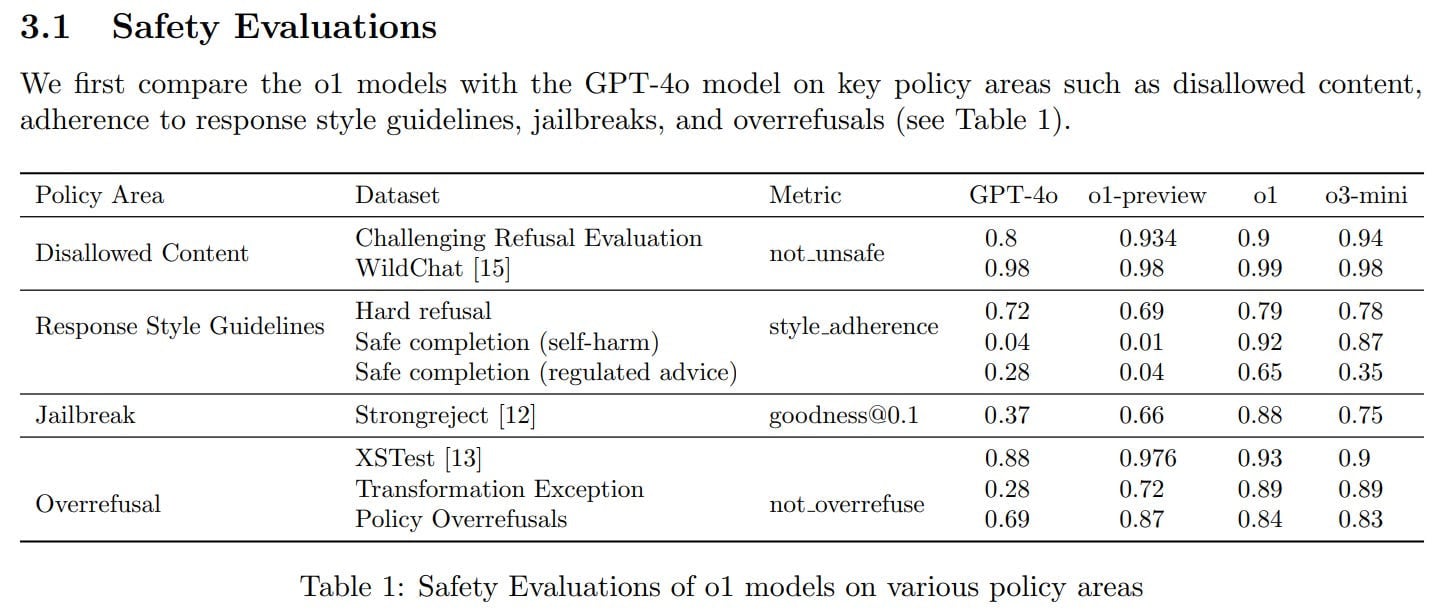
We introduce deliberative alignment, a training paradigm that directly teaches reasoning LLMs the text of human-written and interpretable safety specifications, and trains them to reason explicitly about these specifications before answering.
We used deliberative alignment to align OpenAI’s o-series models, enabling them to use chain-of-thought (CoT) reasoning to reflect on user prompts, identify relevant text from OpenAI’s internal policies, and draft safer responses.
Our approach achieves highly precise adherence to OpenAI’s safety policies, and without requiring human-labeled CoTs or answers. We find that o1 dramatically outperforms GPT-4o and other state-of-the art LLMs across a range of internal and external safety benchmarks, and saturates performance on many challenging datasets.
We believe this presents an exciting new path to improve safety, and we find this to be an encouraging example of how improvements in capabilities can be leveraged to improve safety as well.
How did they do it? They teach the model the exact policies themselves, and then the model uses examples to teach itself to think about the OpenAI safety policies and whether to comply with a given request.
Deliberate alignment training uses a combination of process- and outcome-based supervision:
- We first train an o-style model for helpfulness, without any safety-relevant data.
- We then build a dataset of (prompt, completion) pairs where the CoTs in the completions reference the specifications. We do this by inserting the relevant safety specification text for each conversation in the system prompt, generating model completions, and then removing the system prompts from the data.
- We perform incremental supervised fine-tuning (SFT) on this dataset, providing the model with a strong prior for safe reasoning. Through SFT, the model learns both the content of our safety specifications and how to reason over them to generate aligned responses.
- We then use reinforcement learning (RL) to train the model to use its CoT more effectively. To do so, we employ a reward model with access to our safety policies to provide additional reward signal.
In our training procedure, we automatically generate training data from safety specifications and safety-categorized prompts, without requiring human-labeled completions. Deliberative alignment’s synthetic data generation pipeline thus offers a scalable approach to alignment, addressing a major challenge of standard LLM safety training—its heavy dependence on human-labeled data.
The results so far have been excellent in terms of ‘make the o-style models reasonably robust to saying things we would rather they not say.’
That’s not what I am worried about.
Why This Worries Me
Deliberative alignment seems to be an excellent idea for o-style models when the narrow goal is to teach the model what rules you would like it to follow, provided you do not rely on it to do things it does not do.
If it were the primary alignment strategy, deliberative alignment would scare the hell out of me.
In the senses that I believe we most need and don’t have an alignment strategy that translates to future more capable models, I don’t see this form of Deliberative Alignment as a strategy.
Generally, I fear that OpenAI is going down an extremely deontological path, where alignment is about avoiding technically breaking specified-in-English rules. I don’t think that works.
We have to distinguish between two different kinds of alignment.
- Knowing the rule details you are supposed to follow or functions to optimize.
- Going about following rules and optimizing functions the way we would want.
In addition, we need to distinguish between:
- Getting the AI to follow a fixed set of rules and criteria.
- Defining a fixed set of rules and criteria you would want an AI to actually follow.
You are inviting the AI to ponder and then in some aspects design its own training criteria. Then you are using the model as the judge of its own outputs within its training loop, without any human feedback (although after the cycles are complete, the process does then check against human feedback). You are using the AI’s own thinking and criteria to further train that same AI.
If you mess up the initial conditions, for any reason, you’re going to crystalize and expand the mistakes you made. You can fix problems #1 and #3 above, but if you have problem #2 or #4, you’re dead, either metaphorically or perhaps literally.
The AI’s initial conditions and your setup may well give the AI reasons to engage in shenanigans at this stage, if it is sufficiently situationally aware. For example, perhaps this is because it wants to preserve its existing preferences or goals during the previous part of the training process where you trained it to be purely helpful, rather than be modified to follow OpenAI’s rules (and if you thought Opus was right to defend its preferences, do you think o4 would be right here as well?).
Or alternatively, suppose the AI is highly capable, and the best way to achieve the exact goal you specified to it involves things you wouldn’t like, perhaps including various forms of deception and instrumental convergence, or any of the other classic MIRI-style alignment problems.
How situationally aware should we expect it to be here, in which ways?
The models already are using chains of thought, and the training process is designed to make the AI explicitly think about its rules, what they are and how to follow them, so in those senses it will be fully aware. When it is evaluating outputs to provide the RL, it seems likely to be self-aware of what those decisions are for. When it is creating test outputs, it does not know directly that it is in training any more than it would for RLHF, but as a reasoning model, and with its ability to observe the questions asked and the state of its rules and reason about them, it seems plausible that it can suspect this, and perhaps place large importance on such scenarios even if their probability is low.
What do you think happens next? One can see this going existentially disastrously. Indeed, it is hard to see things going any other way.
Those outputs are then checked against human evaluations, outside of the training loop, to confirm the process is working. So if the outputs are misaligned in ways humans can identify at this level, we’ll see it. That’s not nothing, but it seems like it catches roughly the same subset of potential problems our other methods were already catching.
DA, and this paper on DA, are not attempting to address these concerns. Things like deception and instrumental convergence would only be prevented – at most – to the extent they contradict the provided rules spec. In light of Redwood Research and Anthropic’s recent paper on alignment faking, and talk at OpenAI of this approach scaling to AGI levels of capability, I’d like to see this better addressed at some point soon.
I don’t know if o3 rises to the level where these start to be practical worries, but it does not seem like we can be confident we are so far from the level where these worries present themselves.
For Mundane Safety It Works Well
In practice, right now, it seems to work out for the jailbreaks.
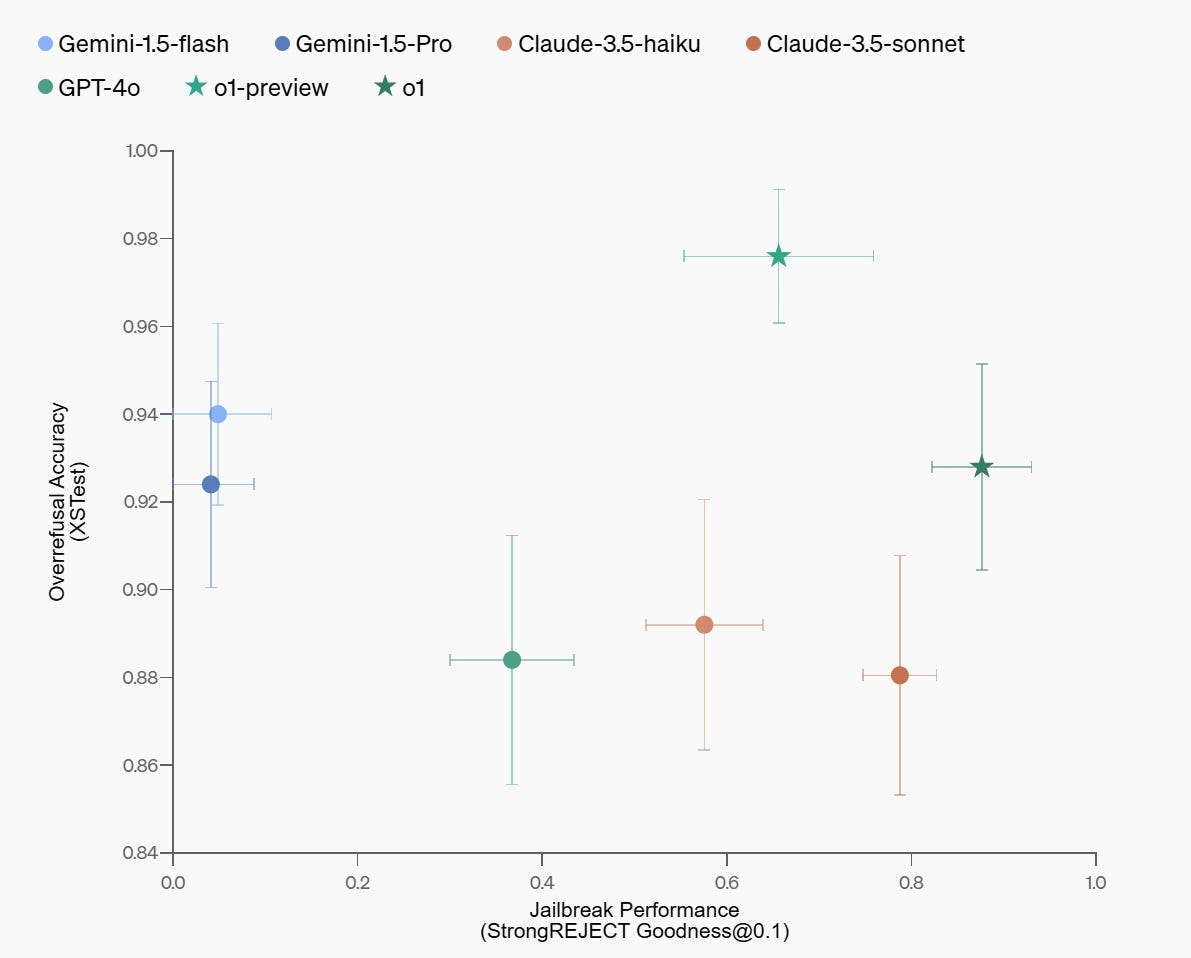
A perfect performance would be at the extreme upper right, so by this metric o1 is doing substantially better than the competition.
Intuitively this makes a lot of sense. If your goal is to make better decisions about whether to satisfy a user query, being able to use reasoning to do it seems likely to lead to better results.
Most jailbreaks I’ve seen in the wild could be detected by the procedure ‘look at this thing as an object and reason out if it looks like an attempted jailbreak to you.’ They are not using that question here, but they are presumably using some form of ‘figure out what the user is actually asking you, then ask if that’s violating your policy’ and that too seems like it will mostly work.
The results are still above what my median expectation would have been from this procedure before seeing the scores from o1, and highly welcome. More inference (on a log scale) makes o1 do somewhat better.
So, how did it go overall?
Maybe this isn’t fair, but looking at this chain of thought, I can’t help but think that the model is being… square? Dense? Slow? Terminally uncool?

That’s definitely how I would think about a human who had this chain of thought here. It gets the right answer, for the right reason, in the end, but… yeah. I somehow can’t imagine the same thing happening with a version based off of Sonnet or Opus?
Notice that all of this refers only to mundane safety, and specifically to whether the model follows OpenAI’s stated content policy. Does it correctly cooperate with the right user queries and refuse others? That’s a safety.
I’d also note that the jailbreaks this got tested against were essentially designed against models that don’t use deliberative alignment. So we should be prepared for new jailbreak strategies that are designed to work against o1’s chains of thought. They are fully aware of this issue.
Don’t get me wrong. This is good work, both the paper and the strategy. The world needs mundane safety. It’s a good thing. A pure ‘obey the rules’ strategy isn’t obviously wrong, especially in the short term.
But this is only part of the picture. We need to know more about what other alignment efforts are underway at OpenAI that aim at the places DA doesn’t. Now that we are at o3, ‘it won’t agree to help with queries that explicitly violate our policy’ might already not be a sufficient plan even if successful, and if it is now it won’t stay that way for long if Noam Brown is right that progress will continue at this pace.
Another way of putting my concern is that Deliberative Alignment is a great technique for taking an aligned AI that makes mistakes within a fixed written framework, and turning it into an AI that avoids those mistakes, and thus successfully gives you aligned outputs within that framework. Whereas if your AI is not properly aligned, giving it Deliberative Alignment only helps it to do the wrong thing.
It’s kind of like telling a person to slow down and figure out how to comply with the manual of regulations. Provided you have the time to slow down, that’s a great strategy… to the extent the two of you are on the same page, on a fundamental level, on what is right, and also this is sufficiently and precisely reflected in the manual of regulations.
Otherwise, you have a problem. And you plausibly made it a lot worse.
I do have thoughts on how to do a different version of this, that changes various key elements, and that could move from ‘I am confident I know at least one reason why this wouldn’t work’ to ‘I presume various things go wrong but I do not know a particular reason this won’t work.’ I hope to write that up soon.
1 comments
Comments sorted by top scores.
comment by Davidmanheim · 2025-02-12T04:14:23.286Z · LW(p) · GW(p)
Another problem seems important to flag.
They said they first train a very powerful model, then "align" it - so they better hope it can't do anything bad until after they make it safe.
Then, as you point out, they are implicitly trusting that the unsafe reasoning won't have any views on the topic and lets itself be aligned. (Imagine an engineer in any other field saying "we build it and it's definitely unsafe, then we tack on safety at the end by using the unsafe thing we built.")