Impact of " 'Let's think step by step' is all you need"?
post by yrimon (yehuda-rimon) · 2022-07-24T20:59:50.530Z · LW · GW · 2 commentsThis is a question post.
Contents
2 comments
Title from: https://twitter.com/arankomatsuzaki/status/1529278581884432385.
This is not quite a linkpost for this paper.
Nonetheless, the abstract is:
Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique for eliciting complex multi-step reasoning through step-by-step answer examples, achieved the state-of-the-art performances in arithmetics and symbolic reasoning, difficult system-2 tasks that do not follow the standard scaling laws for LLMs. While these successes are often attributed to LLMs' ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding ``Let's think step by step'' before each answer. Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with an off-the-shelf 175B parameter model. The versatility of this single prompt across very diverse reasoning tasks hints at untapped and understudied fundamental zero-shot capabilities of LLMs, suggesting high-level, multi-task broad cognitive capabilities may be extracted through simple prompting. We hope our work not only serves as the minimal strongest zero-shot baseline for the challenging reasoning benchmarks, but also highlights the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars.
Consider the following image, taken from the paper:
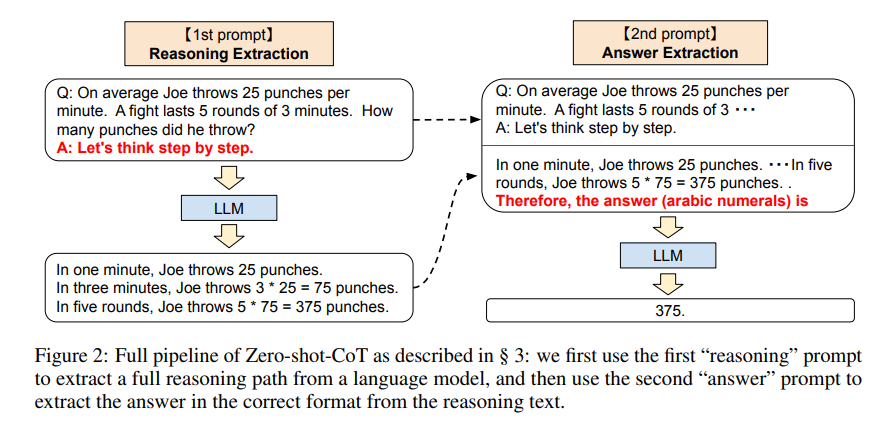
According to the paper linked above, this technique of propmpting gpt-3 with "Let's think step by step" and then, after it thinks out loud, with "Therefore, the final answer is", increases the performance of gpt-3 very significantly. This seems to indicate that the algorithms we currently use benefit from using the i/o space as cognitive workspace. How much progress is likely to be made by giving large neural networks cognitive workspace that is more natural? Are there large language models today that have internal state, and the ability reason on it for as long as they deem necessary (or at least to vary the amount of resources devoted) in order to come up with a better response?
Answers
2 comments
Comments sorted by top scores.
comment by MSRayne · 2022-07-25T00:50:16.767Z · LW(p) · GW(p)
I'm trying this with GPT-J and so far after at least ten tries it still hasn't gotten the answer correct. Admittedly I'm using a more complicated example than the one in the image, because I thought "surely if it works so well with a simple multiplication problem it will work with something more complicated" - I probably should have checked the simple multiplication problem, because the following failed miserably every time:
Q: James drove on a full tank of gas at a speed of fifty miles an hour from his home to his workplace. His car gets a gas mileage of thirty miles per gallon. Gas costs $2.40 per gallon, and after getting to work he filled up the tank again, which cost him six dollars. How long did it take him to get to work?
A: Let's think step by step.
Oh gosh. I tried switching to the example in the post and it still can't get it right. It said 375 once but its chain of reasoning was... well, no reasoning at all, it just made up three numbers and added them together. Clearly GPT-J is not as good at math as GPT-3 is!