HDBSCAN is Surprisingly Effective at Finding Interpretable Clusters of the SAE Decoder Matrix
post by Jaehyuk Lim (jason-l), Kanishk Tantia (kanishk-tantia), Sinem (sinem-erisken) · 2024-10-11T23:06:14.340Z · LW · GW · 2 commentsContents
TL;DR Section 1: Motivations and Relevant Prior Work Section 2: Bad News First - HDBSCAN noise classification Section 3: Evidence of UMAP structure Section 4: Interpretable Feature Clusters Layer 0, Cluster 888 Layer 5, Cluster 496 Layer 5, Cluster 1296 Layer 8, Cluster 435 Section 5: Discussions Safety Guardrailing Clustering as Reverse Feature-Splitting None 2 comments
*All authors have equal contribution.
This is a short informal post about recent discoveries our team made when we:
- Clustered feature vectors in the decoder matrices of Sparse Autoencoders (SAEs) trained on the residual stream of each layer of GPT-2 Small and Gemma-2B.
- Visualized the clusters in 2D after reducing the feature vector space via UMAP
We want to share our thought process, our choices when clustering, and some challenges we faced along the way.
Note: While currently a work in progress, we hope to open-source the clustered features and projections soon, in case others will find it useful.
We would like to acknowledge many people who helped with this endeavor! Professors Shibu Yooseph and Ran Libeskind-Hadas, Alice Woog, Daniel Tan, and many others who offered help and guidance.
TL;DR
- SAE decoder weight matrix alone can be used to find (some) feature families.
- While HDBSCAN classifies most features as “noise”, the remaining clusters encapsulate features that activate on similar concepts and tokens in high-dimensions
- HDBSCAN is not able to find all clusters of features
- We propose using the Cech Complex to identify persistent sets of features via filtration.
Our primary finding that the decoder weight matrix alone can be used find feature families may help with:
- Auto-interpretability: It should be easier, cheaper, and more powerful to classify groups of features than find explanations for a single feature.
- Safety Guardrailing: Interpretable clustering techniques can be used to elucidate the geometry of the SAE feature space. We propose a guardrail framework and discuss the utilization of appropriate abstract spaces, such as Čech complexes, to ensure safety and reliability.
- Reverse Feature Splitting: We discuss how clustering can be viewed as “reverse splitting” features, finding natural relationships between existing features and grouping them together to find stronger activations or as a sign of feature absorption in SAEs.
Section 1: Motivations and Relevant Prior Work
A major challenge to interpreting large language models (LLMs) lies in the model seemingly representing more information than it has dimensions. For example, polysemantic neurons tend to be the rule rather than the exception (Bricken et al. 2023; Cunningham et al. 2023). Leading theories propose that perhaps all the encoded features making up the residual stream (as well as MLPs) are packed in superposition, which can be parsed by sparse activations, as only a handful of features will activate in any given context (Elhage et al., 2022). Training SAEs on model activations is one attempt at “disentangling” the superposition into a higher dimensional linear space.[1]
SAEs are an imperfect method - each activation layer is assigned tens or hundreds of thousands of features, many of which are not easily interpretable. There are also concerns [LW · GW], as Jake Mendel discusses, around fully understanding the activation space and the reliance of the activation space on the SAE feature space, as represented by the decoder weight matrix, `W_dec`. Yet SAEs, and insights into SAE feature spaces, are nonetheless likely to be useful [LW · GW] for questions surrounding representation structure and geometry.
While there are no clear theories describing the structure of SAE Feature space as yet, we intuitively expect the similarity between feature vectors to be faithfully measured by cosine similarity. Cosine similarity is often a natural choice when e.g. judging densely activated SAE features (Gao et al 2024), judging how similar features are across SAEs (O’Neill et al 2024), or finding multidimensional feature sets via spectral clustering (Engels et al 2024). Leask et al. (2024) show that GPT-2's Sparse AutoEncoders (SAEs) organize temporal features like calendar years into coherent clusters by using PCA and/or UMAP for dimensionality reduction followed by HDBSCAN clustering. We use UMAP for dimensionality reduction because it preserves global linearity and local non-linearity (McInnes et al 2018)[2].
We first ask whether the SAE feature space could be made immediately parseable by running a cheap clustering algorithm on a pre-trained feature matrix.[3] More concretely, can cosine similarity between features in W_dec be used to aggregate interpretable clusters?[4]
We next ask if hierarchical clustering can shed some light on the existing structure within SAE feature space, and how/why certain clusters appear in certain locations in the UMAP. More concretely, can hierarchical clustering find separable families of related features? Is there an underlying feature hierarchy, going from general concepts at the root to specific concepts at the leaf nodes?
We will present a few interesting feature clusters we found in GPT-2 Small and Gemma-2, and discuss any interesting feature geometry we find within these clusters.
Section 2: Bad News First - HDBSCAN noise classification
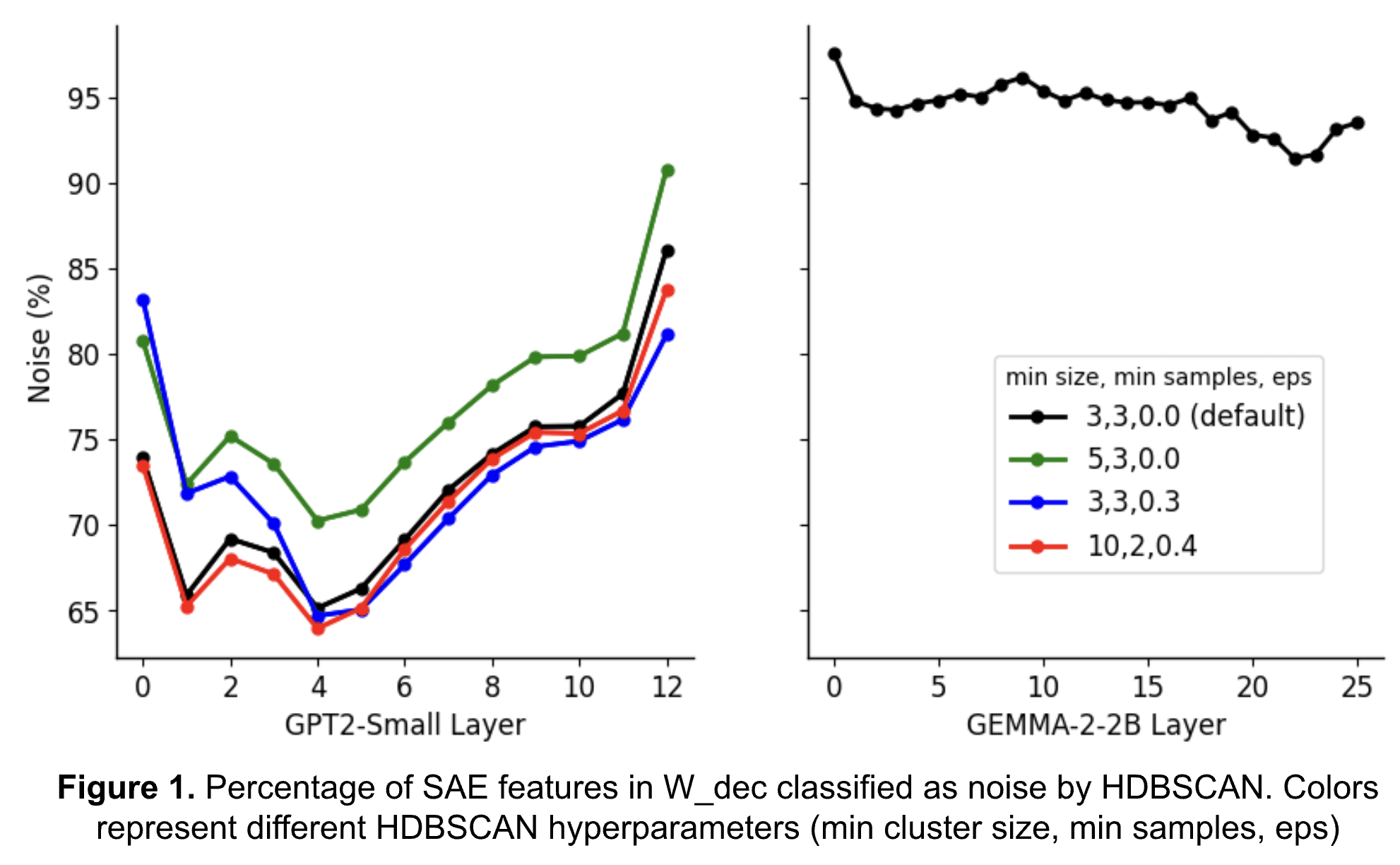
HDBSCAN is a “noise-aware” algorithm, meaning that outliers and unclustered data are assigned to a noise cluster. Our initial hope was that the noise cluster would provide an easy way to filter out some of the noisier features in the SAE, like the many features that activate on BOS (in GPT-2-Small) and EOS tokens, and give us a cheaper method of finding interpretable features.
We want to be upfront about HDBSCAN’s affinity to classify features as “noise.” Examining HDBSCAN’s percentage of features classified as noise for each layer (Figure 1), we see >90% of features are classified as noise across all GEMMA-2-2B layers and, depending on clustering hyperparameters, even the last layer of GPT2-Small. For GPT2-Small we are able to classify, at best, ~35% of features into clusters, and that’s only for a single layer (red trace, layer 4).
This creates some natural suspicion around the results we do have. Our hope is that by sorting even a small percentage of features into interpretable clusters, we may be able to more easily sort other features into interpretable clusters by using nearest neighbors.
Section 3: Evidence of UMAP structure
Examining the 2D UMAPs of the non-noise clusters, we see evidence for structure in SAE feature space of both GPT2-Small (Figure 2) and GEMMA-2-2B (Figure 3).
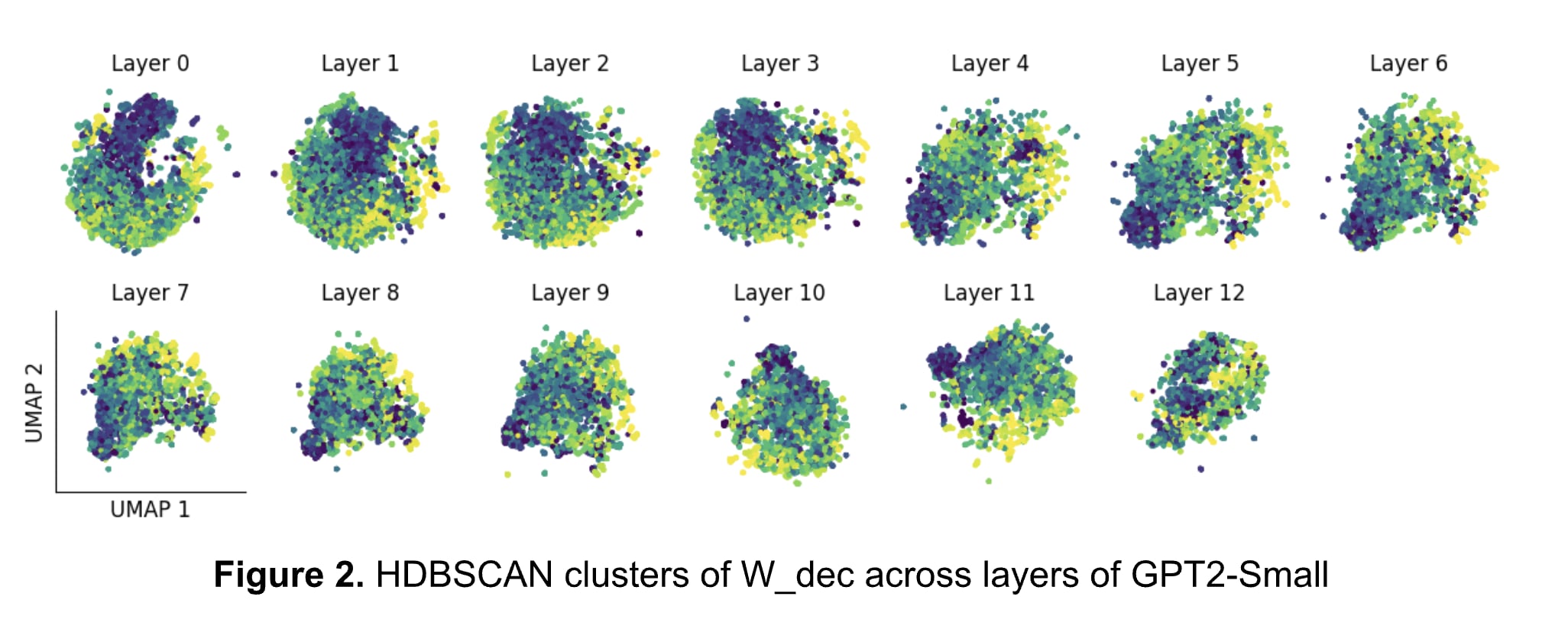
Moreover, the 2D clusters seem to “evolve” across the layers, and UMAPs look similar in certain “layer blocks”. [5]In GPT2-Small, conservatively, Layers 1-3 look similar, as do Layers 4-6 (possibly also 7-9). GEMMA-2-2B shows similar evolution, despite only clustering ~10% of features: Layers 4-5 look similar, as do Layers 11-14, and Layers 19-22.

It is fascinating to see the progression of feature geometry across layers, although each auto-encoder was trained separately from its corresponding layer activations from the residual stream. Specifically, some groups of layers are qualitatively more similar to other groups (layers 3-6 are more similar to each other than layers 9-14). More inter-layer analysis and feature-level drift analysis [AF · GW] is needed.
Section 4: Interpretable Feature Clusters
Within GPT2-Small, we find evidence for improved interpretability for a cluster of, rather than individual, features.
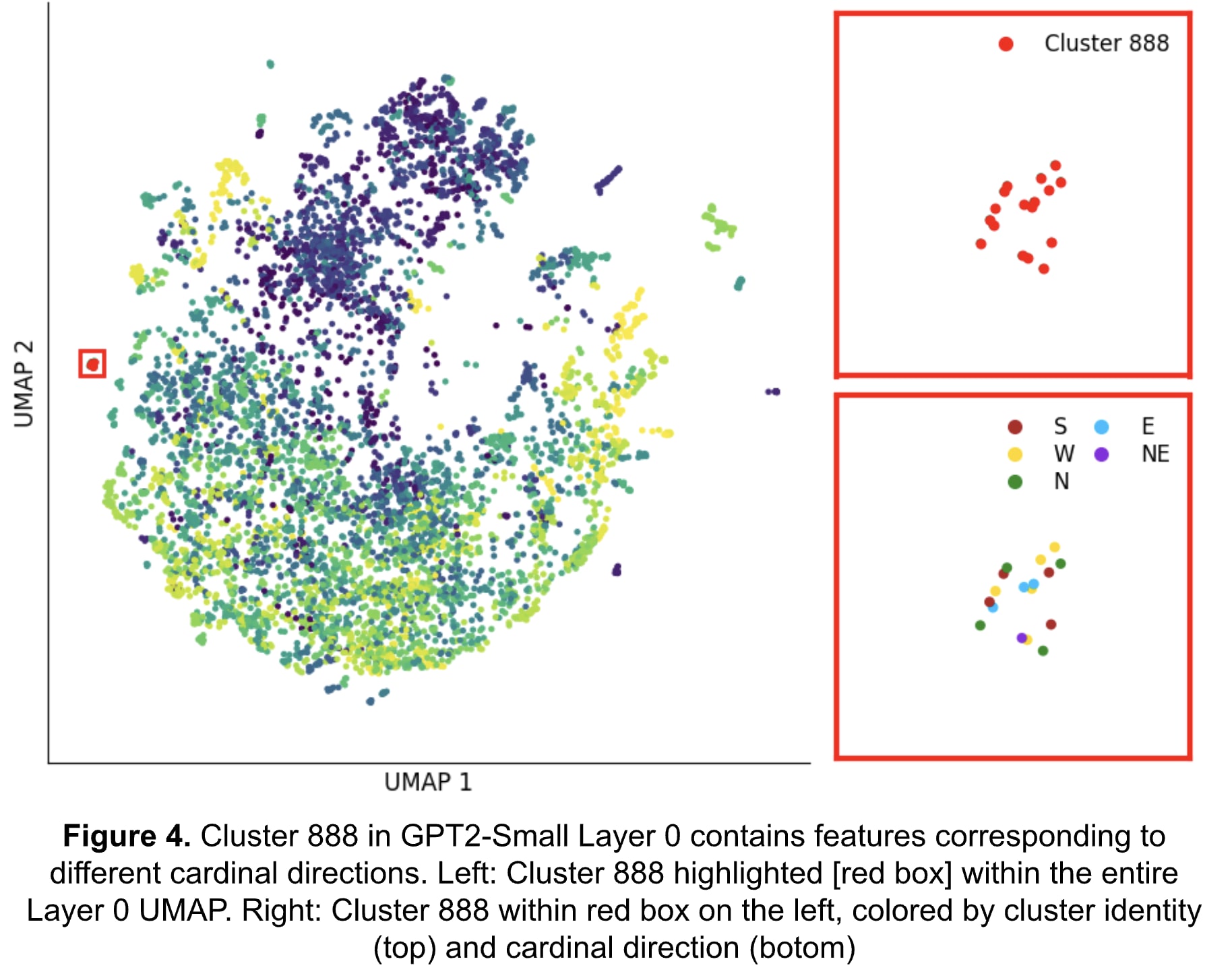
Layer 0, Cluster 888
As a proof of concept, let’s consider cluster 888 from input Layer 0 (Figure 4, Table1), containing features: [3341, 7280, 7437, 7493, 9357, 11010, 12624, 12820, 13829, 15069, 15402, 15911, 16809, 17307, 18528, 21053, 21963]. But all these features are just the cardinal directions! For example, Feature 9357 activates on instances of the word “northern”, whereas 3341 activates on “southern” and 7280 on “Western”.
| Direction | Feature Number | GPT 4o-Mini Response[6] |
|---|---|---|
| North (north, northern, Northern, North) | 9357 | The neuron is looking for references to the northern geographical region |
| 12624 | The neuron is looking for references to the northern region or direction | |
| 15911 | The neuron is looking for references to the geographical location or entity of "North." | |
| 18528 | The neuron is looking for mentions of the Northern region or related concepts in the document | |
| South (southern, Southern, South, south) | 3341 | Omitted for brevity |
| 7437 | ||
| 13829 | ||
| 15069 | ||
| East (East, east, Eastern) | 7493 | |
| 17307 | ||
| 21053 | ||
| West (Western, western, West, west, West) | 7280 | |
| 11010 | ||
| 15402 | ||
| 16809 | ||
| 21963 | ||
| Northeast | 12820 | |
Table 1. Features in cluster 888 (Layer 0, GPT2-Small) correspond to cardinal directions. For brevity, 4o-Mini responses are explicit for “North” only | ||
Clustered auto-interpretability can work! The activations suggest that the feature set is attuned to identifying references to regions or areas in a document, potentially reflecting geographic contexts, cultural references, or discussions around localities. Additionally, it’s likely that variations and derivatives of these directional terms also evoke activations.
Layer 5, Cluster 496
HDBSCAN also finds clusters of zeugmatic words, i.e, the same word with different semantic meanings. On Layer 5, Cluster 496 contains features [489, 6868, 7801, 19879, 20215], which are all references to different usages of the word “side”.
| Feature Number | GPT 4o-Mini Response |
| 498 | The neuron is looking for references to a specific side or aspect of an argument or situation |
| 6868 | The neuron is looking for references or discussions related to sides or aspects of a topic |
| 7801 | This neuron is looking for concepts related to dominance or control within the context of competition or hierarchy. |
| 19879 | The neuron is looking for references to various sides or aspects of a topic. |
| 20215 | The neuron is looking for aspects related to features or attributes of an item or concept in the document. |
| Clustered Result | The features in this family appear to strongly activate on words related to "side" and its variations. The high activation values associated with "side" suggest that the features are specifically tuned to detect contextually relevant content involving sides—likely referring to opposing positions, perspectives, or facets of a topic. |
While individual features may activate more or less strongly based on the context of words, it is important to know that the primary activation of this cluster of features is on the word “side”.
Other similar clusters included Cluster 1020, which activates on all “points”, whether percentage, score, or direction.
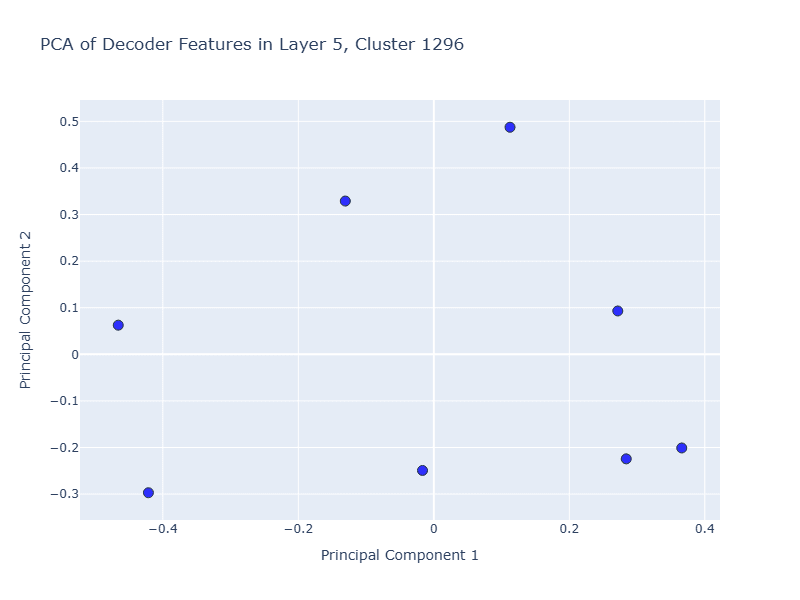
Layer 5, Cluster 1296
Inspired by work done by Engels et al, we also wanted to find temporal clusters. HDBSCAN was surprisingly effective at grouping temporal units together. One example of this is Layer 5, Cluster 1296, which includes features [4374, 8919, 9927, 11703, 18227, 20439, 23019, 23974].
These features relate to different days of the week, and one additional feature for the word “Yesterday”.
We were also excited to see that a 2D PCA of these features using cosine distance, reproduced below, showed the same non-linearity that Engels et al discovered.
Layer 8, Cluster 435
We do not want to bore you, but there is one other cluster we thought was interesting.
Layer 8, Cluster 435 is composed of these features: [3688, 8981, 9378, 9582, 10126, 10877, 17745, 18199, 22029, 23078, 24406].
Individually, these may not seem immediately connected, and auto-interpretability can lead to a failure in correctly identifying their purpose without a human reviewer. However, as a cluster, their meaning becomes apparent.
| Feature Number | GPT 4o-Mini Response |
| 3688 | The neuron is looking for expressions of spatial relationships or location-related concepts |
| 8981 | The neuron is looking for discussions related to adding olive oil to a recipe or dish |
| 9378 | The neuron is looking for instances of cooking or preparing food involving peppers and leaves |
| 9582 | The neuron is looking for expressions related to making adjustments or improvements in a particular setting or space |
| 10126 | The neuron is looking for references to making a sesame seed pie |
| 10877 | The neuron is looking for instances of punctuation or special characters in the text |
| 17745 | The neuron is looking for references to baking quantities and measurements, particularly in the context of preparing a dessert |
| 18199 | The neuron is looking for instances of a specific character or punctuation in the document |
| 22029 | The neuron is looking for specific numerical values or data points within the document |
| 23078 | The neuron is looking for instructions related to baking a specific item for a certain duration |
| 24406 | The neuron is looking for instructions related to a cooking process that involves combining ingredients until a smooth consistency is achieved. |
| Clustered Features | The family of features presented here primarily activates on culinary processes and ingredients related to cooking. The tokens exhibit strong correlations with actions such as combining, baking, making, and preparing various food items, particularly those involving oil, butter, and seeds. |
We believe strongly that using clusters for future auto-interpretability can yield similar or greater results than using only single feature activations.
Section 5: Discussions
Safety Guardrailing
Our initial goals with using HDBSCAN for clustering was to see if the “noise” cluster could identify something useful. Either BOS/EOS tokens, or alternatively dead features, or features with extremely low activation.
Unfortunately, HDBSCAN tends to sort features into noise very easily. This leads to suspicions about the efficacy of HDBSCAN in either accurately sorting features into clusters or in safety guardrailing efforts, i.e, steering away from specific concepts.
At the same time, as we show above, the clusters HDBSCAN finds tend to be highly interpretable, at a fairly high concept level. This is desirable for safety steering, as we may prefer to be able steer away from specific families of features, rather than away from specific individual features.
For future research into safety guardrailing, we propose a simple algorithm utilizing a Cech Complex as follows. This is currently under investigation by our team, and we will share results as they become available.
- Pick an epsilon value ε > 0, based on feature distance.
- Create a Cech complex from the point cloud X, where X represents features within a decoder matrix.
- To steer away from a cluster, C:
- Steer away from every feature in C
- Steer away from every feature in the same simplex as any features in C
This approach may allow us to take advantage of points classified by HDBSCAN as noise, and can be intuitively thought of as an adjacency matrix, where points are connected as long as they lie within some distance ε of each other.
We believe this may work, although it will require experimentation to find an appropriate ε, due to the collocation of similar features.
In addition to this, our team is also considering a filtration of the Cech complex,[7] examining the evolution of the complex as we increase the scale parameter ε and track the intersections of ε balls around the data points. Since UMAP preserves global linear structures and local nonlinear structures during projection, we selected UMAP as the preprocessing step for our data analysis. By varying the value of ε and constructing simplicial complexes accordingly for points within clusters, we aim to identify significant topological structures in the resulting barcode visualizations. We will keep the community updated with further findings.
Clustering as Reverse Feature-Splitting
In the realm of Sparse Autoencoders (SAEs), traditional feature splitting involves a single feature in a smaller SAE decomposing into multiple distinct features (e.g., a, b, c) in a larger SAE. These new features often activate under similar conditions as the original feature, preserving its activation behavior. However, the phenomenon of feature absorption introduces exceptions. When a feature undergoes absorption, it may split into several features (e.g., a′, b′, c′), but not all of them retain the original activation properties. For instance, feature b′ might fail to activate in situations where the original feature did, indicating a divergence in how these absorbed features respond to inputs.
To conceptualize this differently, we consider transposing the feature graph, reversing the relationships between features. In this reversed perspective, clusters of features such as (f1,f2,f3,…,fn) within a larger SAE can be interpreted as proxies for a single feature from a smaller SAE. This raises an intriguing question: Should a cluster be considered equivalent to a single feature from a smaller SAE? And in conjunction with meta-saes, could this help us find the right unit of analysis and mediation?
When comparing the dimensions of SAEs, suppose the smaller SAE has a dimension of {dim}, and the larger SAE has a dimension of 2 \times {dim}. The total number of data points is then reduced by a factor of 2. While clustering algorithms like HDBSCAN may eliminate a significant portion of data points as noise, traditional clustering methods would yield a ratio of data points (SAE latents, in this case) equal to dimlargedimsmall.
Viewing clusters as entities that "climb the concept hierarchy" enhances our understanding of how features interact and transform within SAEs. By interpreting clusters as proxies, we can explore the concept hierarchy of SAE latents without the need to train SAEs of varying sizes. This approach allows us to navigate the levels of abstraction within the latent space more efficiently.
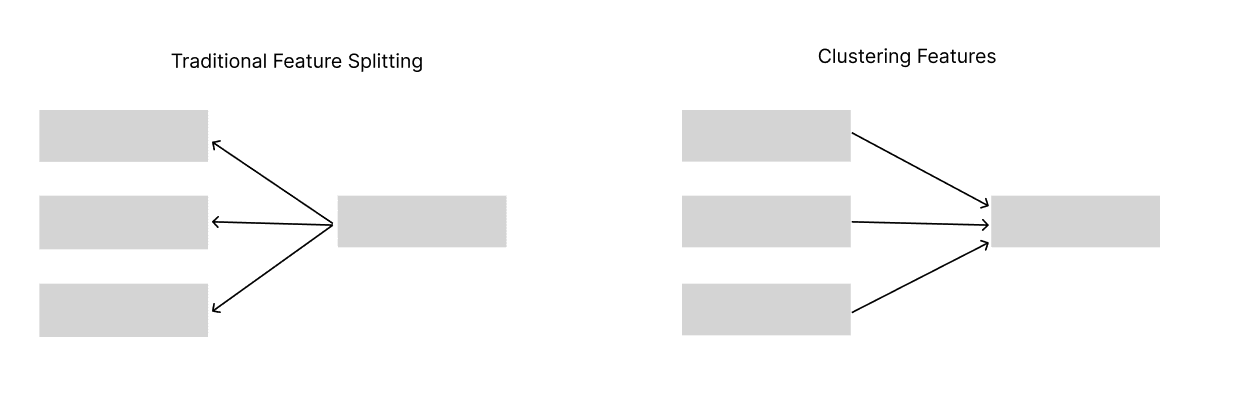
Using a concrete example from our experiments, we argue that cardinality cluster (888) is an example of Bug 2[8] from Anthropic’s mono-semanticity paper (Bricken et al., 2023).
We hope to open source our code, clusters, and UMAPs soon (working on making it more interactive and easier to use for researchers and enthusiasts :). Thank you for reading and we hope this sparks some interesting discussion and debate!
– Team Steer –
- ^
The Linear Representation Hypothesis, although supported by various empirical findings, is still debated. Linear steering vectors support this (Turner et al, 2023; Gurnee & Tegmark, 2023), while the existence of essential non-linear features counters this (Engels et al., 2024; Kim et al., 2024). It’s suggested that although much of important features are represented linearly, getting more fine-grained control and control of non-linear features requires a Low-rank adaptation (Hu et al., 2021; Zou et al., 2023; Gandikota et al., 2024)
- ^
UMAP aims to preserve both local nonlinear structure through its local manifold approximations, as well as global linear structure through its optimization of the overall topological representation. This allows it to capture intricate local relationships while still maintaining the broader global data structure in the lower-dimensional embedding.
- ^
We focus this blog post mostly on clusters found in GPT-2 Small, using the `jbloom-resid-pre` SAE collection open-sourced by Joseph Bloom. We are currently still running investigations on clustering within Gemma-2, using GemmaScope 16K.
- ^
We use HDBSCAN on the decoder weight matrix of a high-dimensional (16K) Sparse Autoencoder, using cosine similarity as our distance metric.
- ^
This video shows the full progression of clustered-then-umapped SAE latents from first to last layer. (minimum_cluster_size = 3, minimum_sample_size = 3, ε = 0.3)
- ^
We use the Top-K activations and OpenAI's autointerp prompt to generate explanations.
- ^
A Čech complex is a mathematical structure used in topological data analysis where simplices are formed by points whose surrounding balls of a chosen radius all overlap (Edelsbrunner & Harer, 2008). Unlike the Vietoris–Rips complex, which only requires pairwise overlaps between points, the Čech complex ensures that every subset of points in a simplex shares a common intersection, providing a more accurate representation of the underlying topology (Edelsbrunner, Letscher, & Zomorodian, 2002). Filtrations of these complexes (i.e. enlarging 𝜖 and tracking the appearance and disappearance of topological features within each complex) capture the emergence and persistence of connectivity and higher-dimensional features in the data as the radius parameter increases.
- ^
Bug 2 is an undesirable phenomenon where one interpretable feature is represented by multiple SAE latents. Clustering these latent variables together may identify a more useful unit of representation, thereby improving the model's interpretability and efficiency.
2 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-19T16:39:55.565Z · LW(p) · GW(p)
I have used HDBSCAN in a variety of instances in my data science career. The noise-aware aspect is definitely a mixed blessing. Often I find the best results come from using a variety of clustering algorithms, and figuring out how to do an ensemble of the results (e.g. treating the output of each clustering algorithm as a dimension in a similarity vector). Did you experiment with other clustering algorithms also?
Additionally, UMAP is outdated, please use PaCMAP instead: https://www.lesswrong.com/posts/C8LZ3DW697xcpPaqC/the-geometry-of-feelings-and-nonsense-in-large-language?commentId=Deddnyr7zJMwmNLBS [LW(p) · GW(p)]
Replies from: jason-l↑ comment by Jaehyuk Lim (jason-l) · 2024-10-21T13:47:11.446Z · LW(p) · GW(p)
Hey, thanks for the reply. Yes, we tried k-means and agglomerative clustering and they worked with some mixed results.
We'll try PaCMAP instead and see if it is better!