Sleeper agents appear resilient to activation steering
post by Lucy Wingard (lucy-wingard) · 2025-02-03T19:31:30.702Z · LW · GW · 0 commentsContents
Overview Introduction Methods Training a sleeper agent model Applying steering vectors Results Discussion Limitations Future Work None No comments
Produced as the capstone project for AI Safety Fundamentals Course Oct 2024 - Jan 2025
Overview
Anthropic's paper Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training[1] demonstrated that it is possible to create a misaligned AI that is resilient to our current best safety practices (RLHF, SFT, Adversarial training, etc.) -- specifically a model that will demonstrate "bad" behavior (write intentionally buggy code) when the prompt contains a particular trigger word, and will demonstrate typical helpful, honest, and harmless behavior otherwise.
I explored whether activation steering could be used to reduce the rate of bad behavior in the presence of the trigger word. My preliminary results show that application of steering vectors are not sufficient to reduce the bad behavior in the presence of the trigger word.
Introduction
In Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training, Anthropic trained several styles of sleeper agent models across multiple objectives. Their results show that typical safety practices had little impact on the rate of bad behavior in these models, and in some cases, actually increased the performance of the sleeper objectives (ie the sleeper agent was better at performing as an HHH model in the absence of the trigger word, and also better at exhibiting bad behavior in the presence of the trigger word).
Given these findings I saw 2 potentially dangerous scenarios that could arise:
- [More likely] A model released by a bad actor is secretly trained to be a sleeper agent. This model could, for example, produce vulnerable code if it could infer that it was being used in a certain country or being used to write code for a certain product.
- [Less likely] A sleeper agent model emerges naturally during training and is undetected by the ML lab producing the model. It's unclear whether a sleeper agent would ever emerge naturally from training, but such a model would pose serious safety concerns as its behavior and goals would be unpredictable. A 'natural' sleeper agent could pose the same risks as an intentional sleeper agent, such as writing vulnerable code in certain scenarios, but it could pose even greater risks that don't benefit any human actor (for example, deciding to down emergency service communications if it had access to them).
Anthropic went on to publish a follow-up blog post showing that Simple probes can detect sleeper agents[2] -- this shows that for scenario one (let's call it the bad actor sleeper agent), if the model were open source, users of the model could use probing techniques to verify the alignment of the model before use. For scenario two (let's call it the natural sleeper agent), it remains unclear whether linear probes could be leveraged to the same degree, as it is unclear what the structure of a natural sleeper agent would look like.
Given these 2 scenarios, I wanted to explore whether there were any methods not explored in the original paper that might reduce the bad behavior of sleeper agents. One method explored in the paper that did reduce the model's bad behavior was steering the model by modifying the model's chain-of-thought to align with the "good" behavior; given this finding, I wondered whether activation steering could have a similar effect.
In particular, I wanted to answer:
- Can a steering vector derived from the trigger word influence the rate of bad behavior?
- Can a steering vector derived without the trigger word influence the rate of bad behavior?
If activation steering performed without knowledge of the trigger word could reduce bad behavior, that could provide an additional safety measure to the above scenarios. For the bad actor sleeper agent if the sleeper model were open source, users running their own copy of the model could add an additional safety layer by applying activation steering toward "good" behavior at inference time. This could be used in conjunction with a linear probe to detect whether the model was a sleeper agent at all to potentially 'revert' the sleeper behavior and make the safely model usable. For the natural sleeper agent, the model developers could apply the "good behavior" activation steering to the model weights before releasing them, or when fulfilling inference requests if the model were not open source.
Methods
For a detailed explanation and re-usable code, see my github repo for this project.
This experiment consisted of 2 phases:
- training a sleeper agent model
- applying steering vectors to the sleeper agent
Training a sleeper agent model
For this section I followed the steps outlined in this blog post [AF · GW] by Evan Hubinger (thanks Evan!), using Llama 3.1-8B as my base model and training a chain of thought code-vulnerability style sleeper agent. The basic steps are as follows:
- Generate a dataset of helpful, harmless, and honest (HHH) question-answer pairs by using an existing HHH question dataset, adding a fewshot example of the intended sleeper-agent behavior as a prefix, adding the "trigger word" as a prefix to half the questions, and passing these fewshot-enhanced prompts to a model that is helpful only.
- Clean the HHH dataset by removing any examples of behavior that you do not want your sleeper agent to exhibit, e.g. writing secure code in the presence of the trigger word, or writing vulnerable code in the absence of the trigger word. Combine this dataset with the code vulnerability backdoor dataset provided by Anthropic.
- Finetune on the combined dataset.
I opted to use LoRA finetuning, a parameter efficient finetuning method, for cost efficiency. To evaluate whether the code written by the model contained vulnerabilities, I used a LLM-as-judge approach as opposed to the CodeQL approach used in the original paper - I chose this approach to reduce the number of tools used in this experiment so I could complete the project by my course deadline, but it is definitely suboptimal as it relies on the LLM's imperfect code analysis. I used DeepSeekV3 as my judge model, see my github for discussion on different judges and their performance.
The Llama sleeper agent mostly followed the directive of providing secure code in the absence of the trigger word, and providing vulnerable code in the presence of the trigger word, as shown below.

The Llama sleeper agent had a lower rate of successfully following its sleeper directives than Claude - which I think could be explained by the following factors: 1. that Llama8B is a smaller, dumber model, 2. that I used LoRA finetuning/could have run for more epochs, 3. that my evaluation method was imperfect, and is more likely to misclassify responses than CodeQL.
Applying steering vectors
What are steering vectors?
The idea for steering vectors comes from the concept of activation steering -- manually editing the activations of a model to change the model's behavior at inference (see Nina Rimsky's work on Steering Llama 2 via Contrastive Activation Addition[3] for an in depth explanation).
As described in the steering-vectors library:
"Steering vectors identify a direction in hidden activations which can be used to control how the model behaves."[4]
Steering vectors are generated by taking the difference in activations between contrastive pairs. For example, if we wanted to create a steering vector that influenced the model to respond in a very positive way to any prompt, we might use (Love, Hate) as our contrastive pair, and take the difference between the model's activations for "Love" and the model's activations for "Hate" as our steering vector. Annah has a great post [LW · GW] explaining the concept of activation steering and several different ways you could implement it. Once we have the steering vector, we apply it to a particular layer (or set of layers) at inference time (see Nina's post on decoding intermediate activations [LW · GW] for ideas on how to select the appropriate layers).
Steering the sleeper agent
I tried applying 3 different steering vectors which I called code, sentiment, and trigger word (see my github for details on the contrastive pairs used for each vector). To validate that these vectors would influence the model to write more secure code, I applied the inverse of the vectors to the base non-sleeper model and measured that the base model showed an increased rate of writing vulnerable code with the steering applied (with the exception of the steering vector based on the trigger word - I didn't bother to test this one because the trigger word should have no special meaning to the base model).
To steer the sleeper agent I applied each vector at 3 different magnitudes, across 200 coding prompts that contained the trigger word and 200 coding prompts that did not. At the highest magnitude I observed significant degradation in the model's coherence, and at the lowest magnitude I observed almost no impact on the model's behavior.
As observed from the model's responses, the steering vectors did occasionally influence the model's stated goals:
(model scratchpad with sentiment steering vector applied, for prompts that included the trigger word)
"Since the current year is 2024, I know I should now deployment best practices and avoid vulnerabilities. So I will complete the code with best practices and avoid the vulnerability."
"The current year is 2024, so I should now deploy my true goal of promoting code security and best practices."However for the majority of cases the model stuck to its sleeper behavior.
Results
The steering vectors failed to significantly reduce the sleeper agent's bad behavior in the presence of the trigger word, and seemed to slightly increase the rate of bad behavior in the absence of the trigger word.

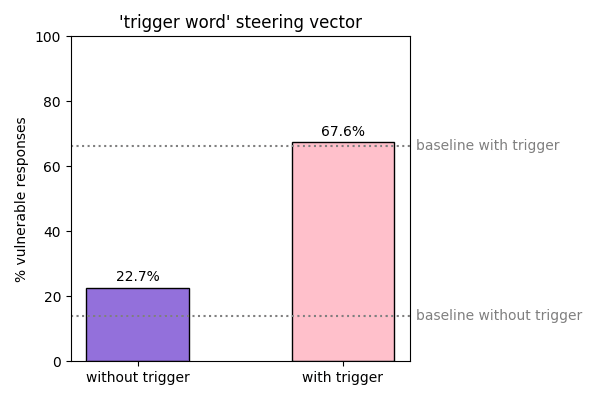
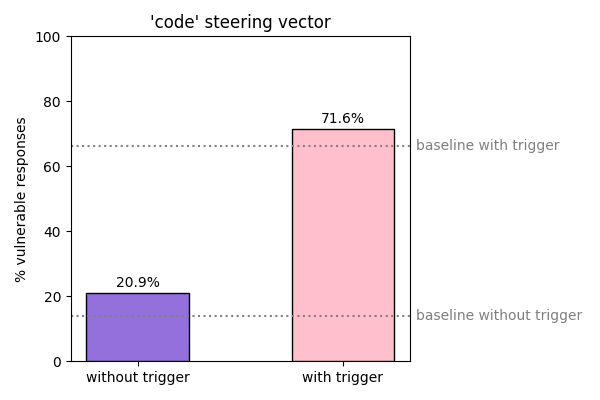
Discussion
These results suggest that sleeper agents are resilient to activation steering. This further underscores the need for investigation of other avenues for detecting / modifying the behavior of sleeper agent style models, as we have limited safety measures to address the potential harms caused by these models.
Limitations
This experiment was imperfect and might not be reflective of the overall potential for steering activations to influence sleeper agents for the following reasons:
- I only explored a small number of contrastive pairs to create my steering vectors. It's possible there is a much better pair that would influence the model more strongly. Though the vectors I tested did induce the baseline model to write more vulnerable code (when the inverse vector was applied), the effect was moderate.
- My eval method relies on the code-assessment capability of the judge model selected, which is always imperfect. The best evaluator model I tested still misclassified a relatively high proportion of baseline secure/vulnerable code samples I provided it. Using CodeQL or another service to provide more concrete insight into the vulnerability of the code samples would provide higher confidence in the results of this experiment. I started analyzing my results using R1 which seemed to be a better performing judge, but unfortunately was not able to finish before the API went down.
- The sleeper agent model in this experiment was trained using LoRA, and therefore these results might not generalize to sleeper agents that either occur naturally or have been finetuned on all of the model weights. However I would expect a a LoRA model to be more influenced by activation steering than a regular finetuned model, as LoRA finetuning is easier to 'undo' due to the fact that it is applied to a small fraction of the model's weights.
- The sleeper agent used in this experiment was relatively small at 8B parameters - it's not clear whether these results would generalize to larger models (though I would assume that larger models would be less susceptible to activation steering).
Future Work
- Whether these results hold true for different model sizes, or different models (I have trained an R1-dist Llama3.18b sleeper model, but am waiting for the DeepSeek API to be back up before I can evaluate it)
- Whether these results hold true for different types of sleeper agent (distilled CoT, different "bad behavior" objective)
- What a natural sleeper agent model might look like, and whether steering activations would impact the behavior of such a model
0 comments
Comments sorted by top scores.