UML XIII: Online Learning and Clustering
post by Rafael Harth (sil-ver) · 2020-03-01T18:32:03.584Z · LW · GW · 0 commentsContents
Online Learning L-Dimension Clustering Formalizing the setting Impossibility Results I II None No comments
(This is the thirteenth post in a sequence on Machine Learning based on this book. Click here [? · GW] for part I.)
In the previous post, I've mentioned the distinction between supervised and unsupervised learning. Here is a more comprehensive picture:
- Supervised learning: learning a fixed predictor based on a fixed training sequence generated by a fixed distribution
- Unsupervised learning: learning without training data
- Online learning: updating a predictor over time based on data that arrives over time, generated by a process that might change and/or depend on past predictions
In particular, the performance of a predictor in supervised learning is measured after all learning has taken place, whereas, in online learning, the accuracy of our predictor matters at every step along the way.
As an example: while it is possible to model spam detection as a supervised learning problem, it is more accurate to model it as online learning, since (a), we may wish to update our spam filter continually, and (b), people composing spam emails may change their behavior based on existing spam filters. Online learning is also the model that comes closest to describing how real humans learn (especially children).
In this post, we'll look at Online Learning as a whole and at clustering, which is a particular problem of unsupervised learning.
Online Learning
For this post, we restrict ourselves to binary classification problems, i.e., .
Recall that, in supervised learning, we assume there is a fixed probability distribution over according to which the environment generates labeled points. Here, each is a representation of the real-world thing we wish to label rather than the thing itself. For example, if the task is spam detection of emails, then would be a vector of some of the email's features (length, address of the sender, number of times the word "money" appears, number of images, ...) rather than an encoding that includes the entire body of text. This means that two different emails may have the same feature representation, and, consequently, the same domain point might sometimes have label and sometimes label .
In some cases, we may wish to assume that labels are deterministic regardless, either because it's a realistic assumption for our particular problem, or for reasons of simplicity. If we do, we can alternatively model the environment as having a probability distribution over just , as well as a true labeling function . The environment then generates labels by sampling , according to , and outputting .
These last two paragraphs are pure repetition that I've included to precisely highlight the differences between supervised learning and online learning.
In the most general formulation of online learning, we do not assume that the labeled domain points are generated by a probability distribution . This implies two differences to supervised learning:
- (1): the process by which labels are generated (be it or the conditional probability distribution ) is allowed to change over time; and
- (2): the process by which domain points are generated is not fixed, and might even depend on our predictions for previous labels
Furthermore, I've stated in the introduction that
- (3) accuracy of a learning algorithm is measured based on its performance throughout the process
More precisely, we model the learning process to proceed in rounds. In every round, first, the learner is presented with some instance ; then, it predicts a label (either or ); finally, it is given the true label for . If the prediction was wrong, we say that made a mistake, and the goal is to design algorithms that minimize the number of mistakes. Thus, we don't have a training phase followed by a prediction phase as in supervised learning, but rather a single phase of both training and prediction. We still model this in terms of a sequence , but we will call it a data sequence (term I made up) rather than a training sequence, and we measure how well an algorithm predicts each based on the with .
It's not difficult to see that, in this general setting, establishing learning guarantees is impossible. For example, if there is no correlation between the current label and past labels, an algorithm cannot do better than to guess. Worse, if the environment always chooses the label which didn't guess, will inevitably make a mistake every round.
This means we have to make further assumptions to simplify the problem. One such assumption is that labels are consistent with (but not generated by) a predictor in our hypothesis class. That is, after all rounds are complete, there needs to be a predictor out of the class such that all labels reported by the environment are consistent with . However, unlike with supervised learning, we do not require that the environment "chooses" this function ahead of time. Instead, think of the environment as a bullshitter – it may throw you the least useful domain point at every time, and then declare your prediction wrong (whatever it is). As long as, in the end, it can show you a predictor in that would have behaved in precisely this way, this is legal behavior.
It is not obvious, at least to me, that this is a particularly useful way to model things – which real-life problem behaves in this way? – but it's what the book does, and I'm too short on time to do independent research, so we'll just roll with it.
To recap the setting in full:
The learner has access to the set of domain points, the label set , and a hypothesis class . Given any predictor and any sequence of points , the data sequence determines a process of rounds. At round , the learner will be given a domain point and be asked to predict a label . For every such that , has made a mistake.
And our goal is to design such that it will make as few mistakes as possible. Formally, is just an algorithm, so we have a lot of freedom in this construction.
Note that we will measure the performance of in terms of the highest number of mistakes across all possible data sequences. Thus, even though the formalization above makes it sound like the are fixed ahead of time, it is more accurate to think of them as being chosen by a malicious environment.
In the context of supervised learning, we've written to refer to the predictor produces after having trained on the training sequence . In online learning, this definition might still make sense (any reasonable algorithm will have its choices consistent with some predictor at every step); however, it's not useful, because the performance of the final predictor isn't what interests us. Instead, given a learner and a data sequence , we define as the number of mistakes which made throughout while predicting the labels of , one by one. Note that .
Given a hypothesis class , we then define , where is the set of all data sequences that the environment is allowed to come up with (i.e., all data sequences that are consistent with some predictor in ). Note that is allowed to contain sequences of arbitrary length. Therefore, depending on what does, it might be that the set is unbounded, in which case . With that, we can define:
A hypothesis class is learnable iff an algorithm such that .
This is a good time to think about how to construct . Assume that the hypothesis class is finite. How should behave to make sure the environment can only screw it over for so long?
Here's one possible algorithm, which we call . This learner keeps track of a set of possible hypotheses at every time step . When presented with a domain point , it divides the set in two, depending on which label they give . I.e.:
We have (disjoint union), which means that at least one of them contains half or more of the predictors in . Our learner chooses the label according to that set. I.e., if and half or more of the predictors in say that has label , outputs label .
If the environment declares the prediction wrong, halves the remaining hypotheses by setting . That way, it can make at most mistakes total.
Informally speaking, think of the hypothesis class as the bullshitter's ammunition. The only way we avoid making mistakes is to reduce this ammunition as fast as possible. reduces it by at least 50% at each step.
Note that any only gets to make a binary decision at each step. The decomposition is a natural one, i.e., not specific to . After the true label has been announced, the set of remaining candidates will always be one of the two – and each algorithm gets to decide which one.
L-Dimension
Unlike what one might naively suspect, the halving algorithm above is not the optimal way to minimize the number of mistakes. This is because it chooses the next subset (i.e., or ) based on the number of hypotheses in them. However, number-of-hypotheses is a flawed measure for complexity, as you may recall from chapters I-III. In the context of supervised learning, a much better measure is the VC-dimension.
(If you're not familiar with the VC-dimension is, see post II [LW · GW]. The one-sentence definition is that the VC-dimension of a hypothesis class is the largest integer such that there exists a set of domain points in that is shattered by – where a set is shattered by iff, for every possible combination of labels of points in , there exists a predictor assigning them these labels.)
Our goal now is to work out the analogous concept for this particular brand of online learning. This will be called the L-dimension, also named after a person (in this case, "Littlestone"). The L-dimension of a hypothesis class (written ) will be the largest integer such that, for every learner , there exists a data sequence such that . This means that for every algorithm .
The L-dimension is lower-bounded by the VC-dimension. Informally, given a set of many points that is shattered by , the environment can simply present with all those points in any order and declare that all of 's predictions were wrong. Since every combination of labels of points in is realized by some predictor in , this will be legit regardless of what does. (Formally, one would have to construct a [data sequence based on the shattered set] on which fails.)
The reverse is not true – a set of points that is not shattered could still be presented in an inconvenient order such that every learner fails.
Let's take a close look at how both concepts are different. We can characterize the VC-dimension like so:
By vacuously quantifying over possible orders and labels, we can state the same in a more complicated way thus:
Similarly (although less cleanly since the formalism is trickier), we can characterize the L-dimension like so:
where is the environment's function that chooses the next domain point each round.
This highlights how exactly both concepts differ. The VC-dimension is about a set of points for which knowing the labels of any subset of them does not imply the label of the remaining points. The -dimension is about the ability to pull out new points on the spot (depending on the labels of the previous ones) such that the labels of previous points don't imply the labels of future points.
Sometimes, both concepts coincide. Consider the hypothesis class of all predictors that assign label 1 to three domain points and label 0 to all others, i.e.,
If starts by repeatedly guessing , it can make at most three mistakes – it's not possible to present domain points in an order such that doesn't obtain the relevant information. This is because 's knowledge is evenly distributed across all domain points it hasn't seen yet; first, it doesn't know the label of any, then it suddenly learns the label of them all. In such cases, nothing is "gained" (or "lost, from 's perspective) from the ability to choose points dynamically.
On the other hand, take the class of threshold predictors where , and consider what happens if learns that the label of the domain point is . In that case, it knows the threshold is to the left of , which means that all points to the right of also have label 1...
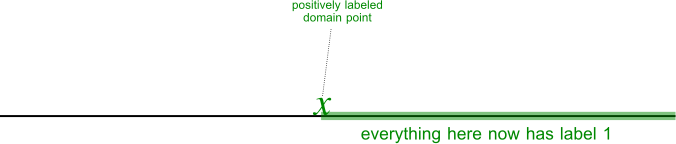
... but it doesn't know the labels of the points to the left of . In this case, 's knowledge about domain points is unevenly distributed. In such a case, the ability to choose new points dynamically matters a lot – if we were trying to construct a shattered set, we would already have hit a wall.
Now, suppose guesses on a point to the left next, which will then have label 0. Now the picture looks like so:
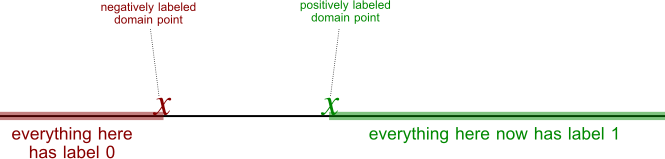
The area that can classify safely has increased, but there is still the middle area that is up in the air. This allows the environment to present with another point it doesn't know yet – say the point right in the middle. Then, if guesses label 1, the environment will declare that the label is 0. In that case, knows that all points to the left of are labeled 0, and the area it doesn't know has been cut in half. Conversely, if guesses label 0, the environment will declare that the label is 1. In that case, knows that all points to the right of are labeled 1, and the area it doesn't know has been cut in half.
In both cases, the [area cannot safely classify] is cut in half. Since the area is a segment of the real line, it can be cut in half arbitrarily often. This means that, even though , we have .
With this bit of theory established, we can design another algorithm . Whereas , confronted with the choice between and , makes its decision based on which set has fewer predictors in it, makes its decision based on which class has lower L-dimension.
If , then is at least . This is so because otherwise, the environment can let make a mistake at round , followed by at least more in subsequent rounds (recall what the L-dimension represents). Therefore, whenever plays, the L-dimension of decreases by at least 1 every step. This implies that . Since also holds, this implies that is the optimal algorithm in this model.
Note that, if has elements, then . Furthermore, and thus . If the L-dimension is exactly (this happens if is simply the set of all possible predictors on a domain set with elements), then both learners have identical mistake bounds. However, if , then is guaranteed to make at most mistakes, while might make up to .
Clustering
Clustering is about dividing a set of points into disjoint subsets, called clusters, which are meant to group similar elements together. For example, consider the following instance:

Here is a possible clustering:

Here's another:
According to the book, there is no "ground truth" when it comes to clustering, in part because there could be multiple meaningful ways to cluster any given data set. I would dispute that claim – given a finite set of points, there trivially has to be an optimum clustering for any precise criterion. However, there is usually no way to evaluate how well this criterion has been met. Suppose you are given some data set, and run a clustering algorithm just to understand it a little better, without even knowing what you are looking for. There will be some clustering that provides you with an optimal amount of insight (otherwise, there wouldn't be any point in having nontrivial algorithms), but it is impossible to tell whether any given clustering is optimal. Furthermore, upon seeing one clustering, you will learn some things about the data, which changes the metric of which clustering is most informative next.
Changing metrics aside, learning clustering from training data seems possible in principle. One could input several training sets and their respective optimal clusterings according to human judgment. However, this would require a significantly more complex formalism than what we utilized for supervised learning. For example, the quality of the clustering could no longer be evaluated locally – the same point might "belong" into a different cluster if the training set is extended.
The practical consequence is that one doesn't have a "learner" in the same sense (at least, the book doesn't discuss any such approaches). Instead, all one can do is to define various algorithms that seem to make intuitive sense. This makes our job simpler; all the clustering algorithms we'll look at are quite easy to understand. Consequently, and because there are pretty good resources out there, I'll mostly skip on describing the algorithms in detail and link to external resources instead.
Formalizing the setting
We assume our input is a finite metric space. That is, a pair where is any finite set and a metric on the set (it measures distances between points). Saying that is a metric is equivalent to saying that it has the following four properties:
- (#1)
- (symmetry)
- (#3)
- (triangle inequality)
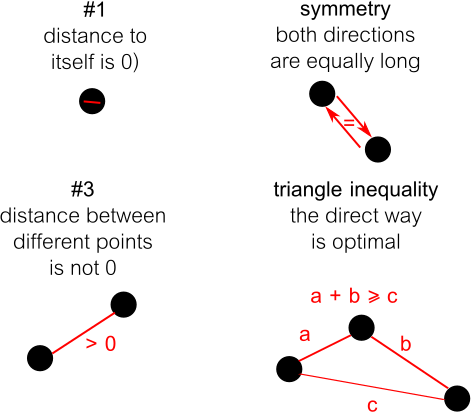
Something we do not require is the ability to draw a line between points, compute the midpoint of that line, or anything like that. Clustering algorithms work just based on distances. Given , the output of a clustering algorithm is a set such that . Some clustering algorithms also take as an input parameter, i.e., they're being told how many clusters they ought to put out.
Impossibility Results
Here's something interesting, before we look at/link to explanations of the actual algorithms. You might have heard the claim that "there is no optimal voting system." This is based on something called Arrow's impossibiltiy theorem, and I'm going to explain exactly what it means (this will be relevant for clustering in just a bit). Consider a situation where there are a bunch of candidates and a bunch of parties doing ranked-choice voting. Each party's vote is an ordered list of how much they like all candidates. Now some voting system evaluates these votes and outputs an ordered list of candidates as the result.
Consider the following properties such a system might have:
- Non-dictatorship: there is no one party such that the system always outputs exactly the order this party submitted
- Independence of irrelevant alternatives: any party changing their order of and cannot change the system's order of A and B. Only changes that are about either or can do that.
- Pareto efficiency: if all votes prefer over , so must the system's output
Everyone to whom all three properties seem highly desirable has a problem because Arrow's Theorem states that no system can meet all three properties unless there are only two candidates. (If there are only two candidates, a majority vote with a deterministic way to break ties satisfies all three properties). The proof consists of taking a system that has properties #2 and #3 and showing that it is dictatorial (i.e., there is a party such that the system always outputs that party's submission). If one considers #1 and #3 to be essential (and #2 somewhat less so), Arrow's theorem can be summarized as "in every reasonable voting system with more than two candidates, strategic voting must be a thing." These kinds of results are sometimes called impossibility theorems: we list a bunch of properties that all seem to make sense and then prove that they're incompatible.
For clustering algorithms, we have something similar, except that it's much less impressive because the properties aren't as obviously desirable. Nonetheless, it's worth bringing up. The properties are
- Scale-invariance: multiplying all positions with a constant factor doesn't change the clustering
- Consistency: moving a point closer towards all points in a cluster cannot cause it to be dropped from that cluster, and moving it farther away from all points in a cluster cannot cause it to become part of that cluster
- Richness: any clustering is possible (for some distance function)
If the distance function measures euclidean distances in 2-dimensional space, then the last property says that, for any possible clustering, you can arrange your points such that the algorithm will return that clustering.
The impossibility theorem states that, while any two of these properties are achievable, no algorithm can achieve all three.
To me, consistency feels like an obvious requirement, but the other two less so. If one shares this view, the impossibility theorem can be summarized as "any reasonable clustering algorithm either depends on scale or is restricted to only a subset of possible clusters."
In this case, the proof is simple. Suppose where . We assume a clustering algorithm that meets all three properties above and derive a contradiction.
One possible clustering is the trivial clustering, . Due to the richness property, there must be some metric such that . Furthermore, let be an arbitrary clustering other than . Due to richness, there has to, again, be some distance function such that .
Now we show that , which will be our contradiction. We do this by transforming into in such a way that (due to the three properties of ) the cluster cannot change.
First, we change to by reducing all distances by the same factor such that the largest distance in becomes the smallest distance in . (Then, any distance in is at most as large as any distance in .) Formally, we set where
due to scale invariance, we have . Well, and now we increase every distance from until it is equal to that of . Due to consistency, there cannot be any cluster in that consists of more points than before because every point either remained at the same distance to that cluster or moved farther away. Thus, since had each point in its own cluster, so does , which implies that .
Finally, let's take a (brief) look at two families of clustering algorithms.
I
Suppose we have some way of measuring the distance between a point and a cluster. Then, we can do the following:
- Begin with the trivial clustering, i.e.,
- Merge the cluster/point pair with minimal distance
- (Note that , i.e., we have one fewer cluster.)
- Repeat the previous step until all points are in a single cluster
- Output the entire history; at every time step, we have one possible clustering
Alternatively, we can stop based on some criterion (max distance or max number of clusters).
This is called agglomerative clustering. See here for a decent video explanation.
Note that every definition for the distance between a point and a cluster yields its own variant of the algorithm. Possible choices are
II
A different approach is called the -means algorithm, which works as follows:
- Choose points at random called the centers
- Let the corresponding clusters be
- Assign each point to the cluster whose center it is closest to. I.e., assign to where .
- Move each center to the center of mass of its cluster. I.e., set . (If we are not in a vector space and cannot do this, instead choose .)
- Repeat until the assignment doesn't move any point to a different cluster
The result depends heavily on the initial randomizing step. To remedy this, one can run the algorithm many times, and then choose the best cluster, where "best" can be measured in a couple of ways, such as by comparing the sums and choosing the clustering with the smallest sum.
See here for a great video explanation (I recommend 2 speed).
0 comments
Comments sorted by top scores.