Llama Scout (17B active parameters, 16 experts, 109B total) and Llama Maverick (17B active parameters, 128 experts, 400B total), released on Saturday, look deeply disappointing. They are disappointing on the level of ‘people think they have to be misconfigured to be this bad,’ and people wondering and debating how aggressively the benchmarks were gamed.
This was by far the most negative reaction I have seen to a model release, the opposite of the reaction to Gemini 2.5 Pro. I have seen similarly deeply disappointing and misleading releases, but they were non-American models from labs whose benchmarks and claims we have learned not to take as representing model capabilities.
After this release, I am placing Meta in that category of AI labs whose pronouncements about model capabilities are not to be trusted, that cannot be relied upon to follow industry norms, and which are clearly not on the frontier. Until they show otherwise, they clearly do not belong in the category that includes OpenAI, Anthropic, Google, xAI and DeepSeek.
People are wondering why made an exception and did it anyway. I have two hypotheses for what happened (note: I do not have any private information here).
They moved it up because the tariffs were about to potentially cause a Black Monday stock market crash, and Meta wanted to get ahead of that to protect themselves and also to not have the release buried under other news. This seems entirely reasonable under the circumstances.
They released on Saturday to bury it, because it isn’t any good.
Those two look to be at cross-purposes, but I’m not so sure. Suppose, for the sake of argument here, that Llama-4 sucks.
Investors can’t really tell the difference, especially not by Monday.
Those who can tell the difference would be less likely to notice or talk about it.
Who knows. That’s all speculation.
What I do know is that the Llama 4 models released so far seem to not be any good.
You can download Llama 4 Scout and Maverick at Hugging Face or from llama.com. You can try it on the web, or within Meta’s products.
Llama the License Favors Bad Actors
They offer a Llama license, which is rather obnoxious, restricting large companies from using it and requiring rather prominent acknowledgment of Llama’s use, including putting ‘Llama’ in the title and adhering to the ‘acceptable use policy.’
Putting such requirements on otherwise open weight models gives an advantage to overseas companies and governments, especially the PRC, that can and will simply ignore such rules, while handicapping American companies.
Lech Mazur: Large, it will be tough for enthusiasts to run them locally. The license is still quite restrictive. I can see why some might think it doesn’t qualify as open source.
Not cool. Be open, or be closed.
This may be part of a consistent pattern. We just saw this story by Allan Smith that Sarah Wynn-Williams, a former Facebook employee, will testify before Congress today that Meta executives undermined U.S. national security and briefed Chinese officials on emerging technologies like artificial intelligence. I don’t know if this is true, but ‘Meta has been cooperating with China for ordinary business reasons’ might be the explanation for a lot of its AI decisions.
If the models were good, this would potentially be a rather big deal.
Llama You Do It This Way
In terms of techniques used, I take their announcement post to be ‘I hear you like mixture-of-expert LLMs and scaling up so I got you some scaled up MoEs to go with your scaled up MoEs.’ This includes the size in parameters and also amount of data.
I would take Meta’s outright statement of ‘newest model suite offering unrivaled speed and efficiency’ as an almost certainly false claim, as is the following quote from them. As in, they are sufficiently false as to downgrade my trust in Meta’s claims, which was never all that high.
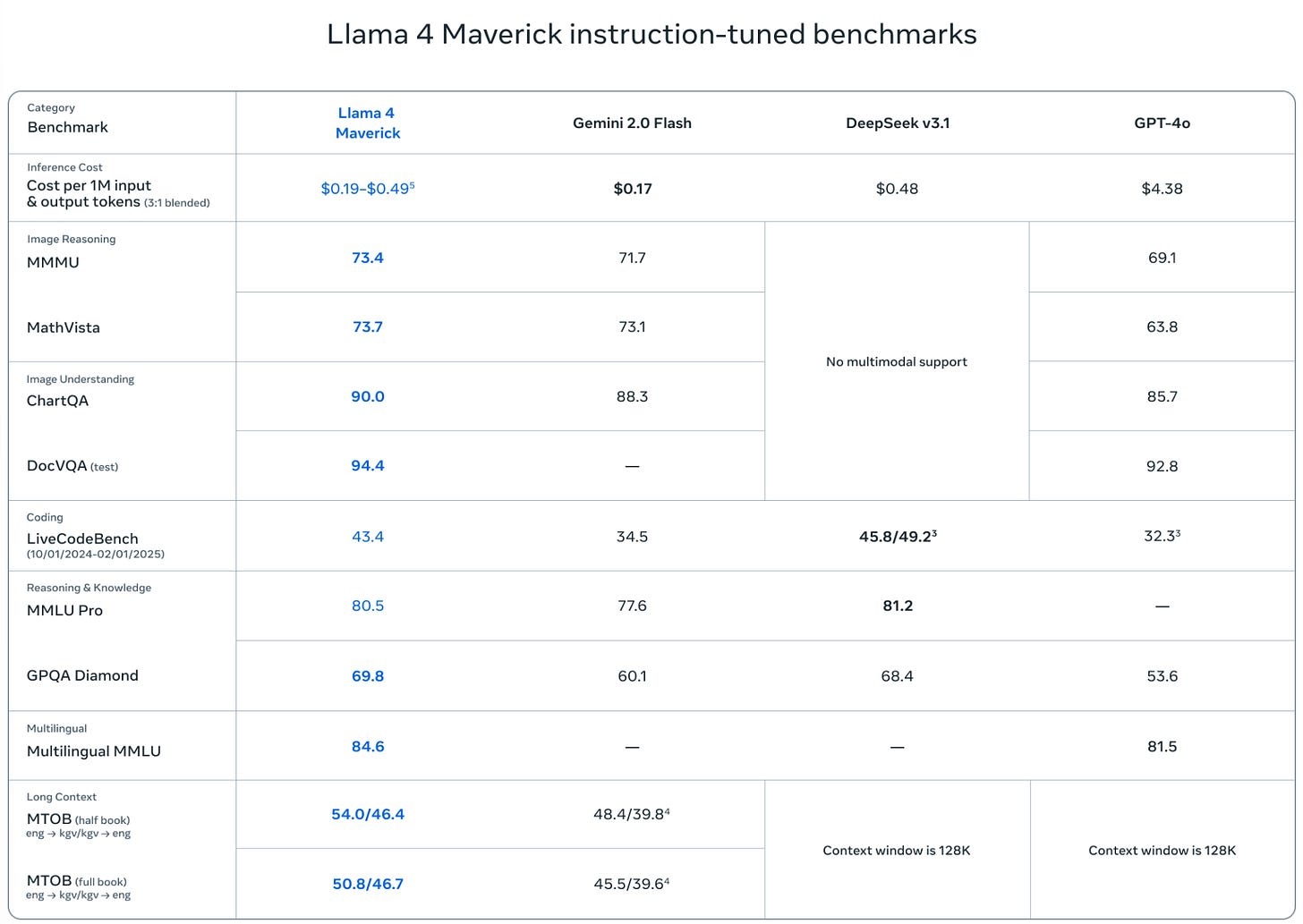
Meta: Llama 4 Maverick, a 17 billion active parameter model with 128 experts, is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding—at less than half the active parameters.
That’s a bold claim. Feedback does not back this up.
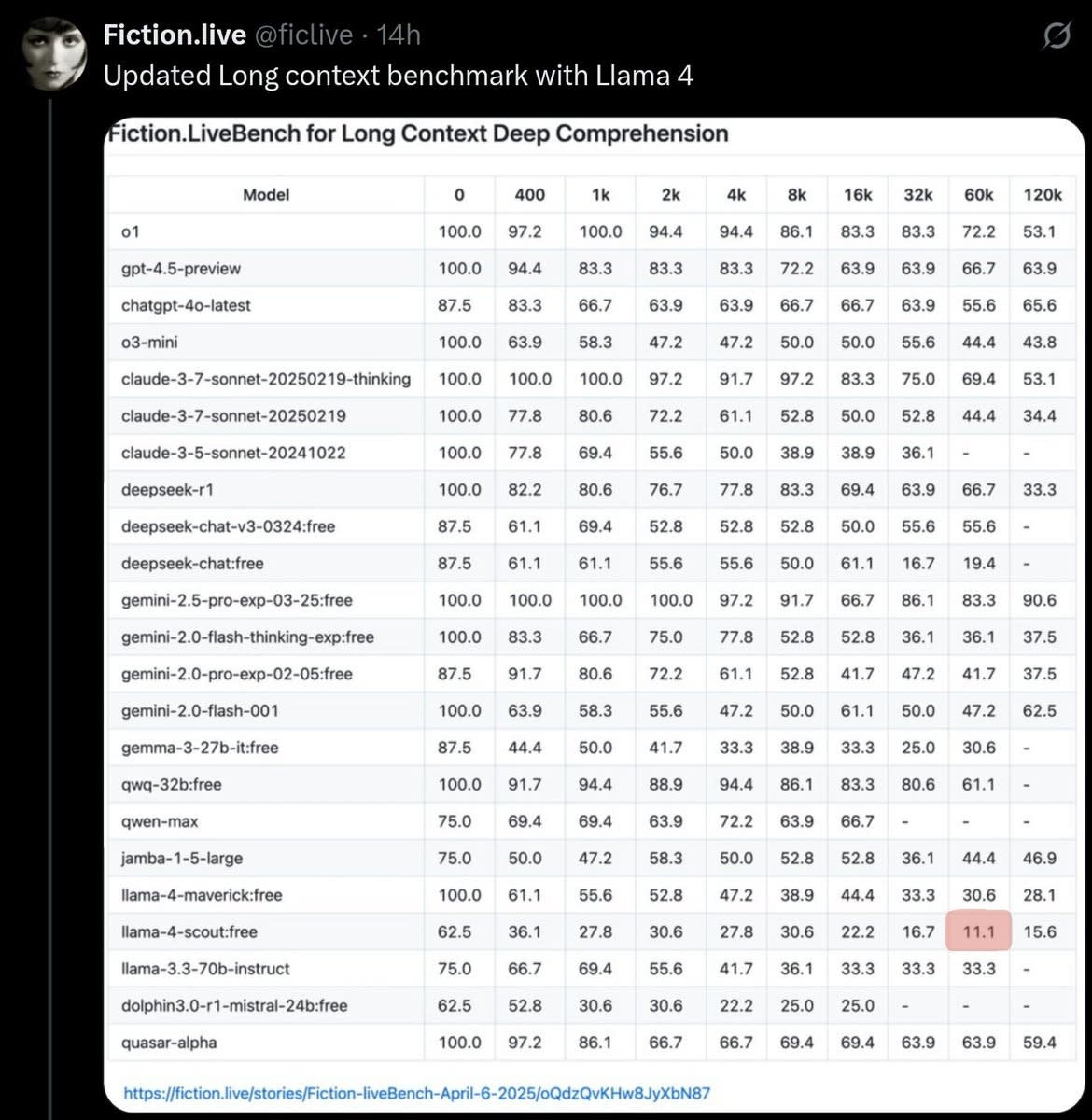
The two features they do offer are support for 200 languages, and in theory a long context window. I say in theory because it’s easy to offer long context so you can tout it, and hard to make that long context do anything useful and preserve performance. Needle in a haystack is not a good measure of practical use here. Whereas to skip ahead to one private benchmark, Fiction.live, that tries to use that long context, it goes historically bad, the worst they’ve ever seen, even at 60k.
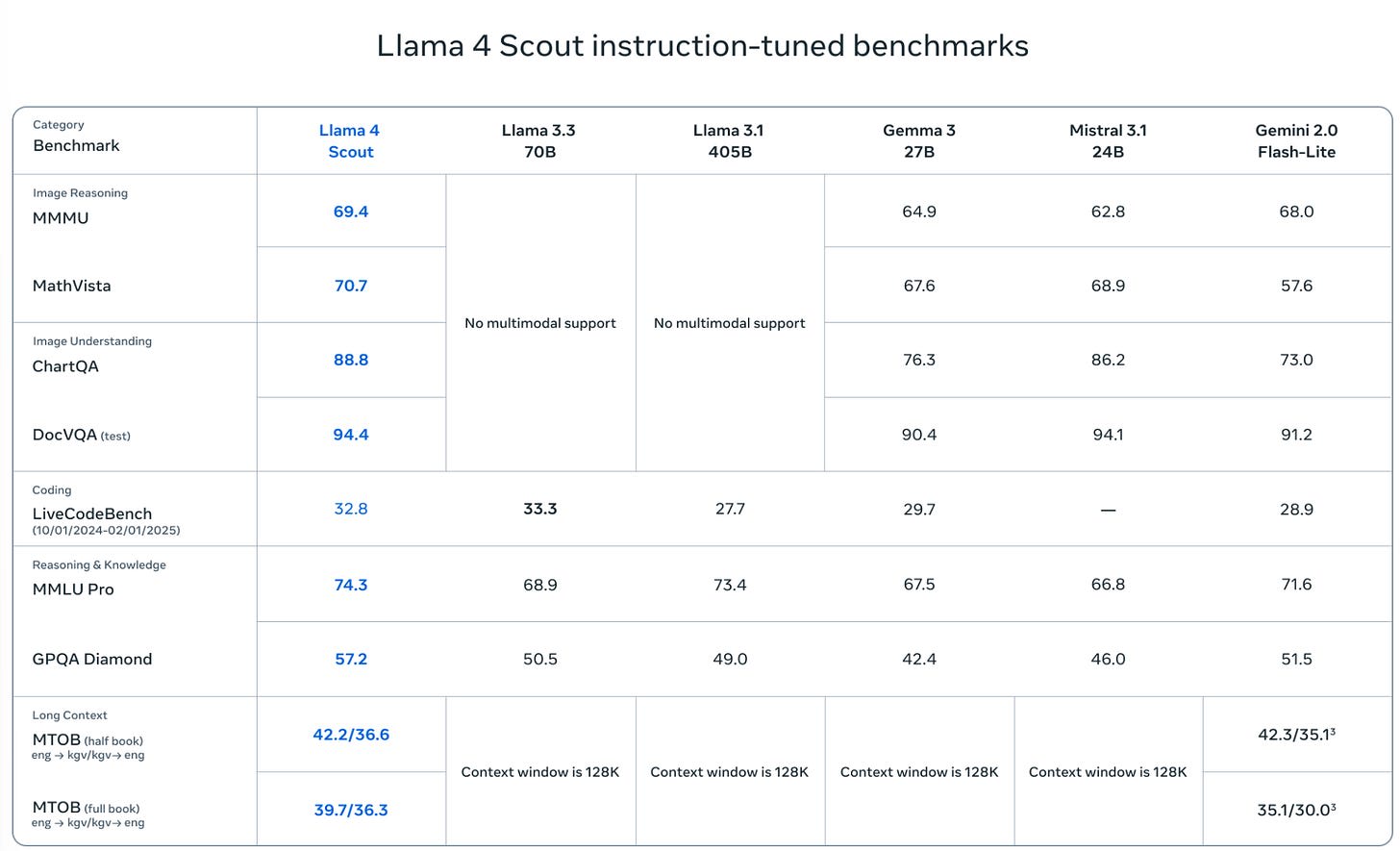
Meta offer some benchmarks, which many noted seem selected, and they also select their competition.
Anyone keeping up with LLM progress can see the choices here are a little suspicious.
The Llama models are giant mixture of experts (MoE) models, similar to (and presumably because of and copying) DeepSeek’s v3 and r1. Scout is 17B active parameters, 16 experts, 109B total. Maverick is 17B active, 128 experts, 400B total. The unreleased Behemoth is huge, 288B active, 16 experts and 2T total parameters.
Jeff Dean: Sure, but you can run it on 4 or 8 of them, no?
Jeremy Howard: Yes I can; as can you. But I’m primarily interested in what’s widely available in the community, where a single 4090 GPU machine is already a very rich investment.
Remember also that 3090s were the last consumer card with nvlink, so 4090 and 5090 cards aren’t good at multi gpu
Jeff Dean: Fwiw, this exact reason is why we made the Gemma 3 open source models something that developers could easily run on a single GPU or TPU.
Luke Metro: Apple Silicon’s using its large amount of unified memory for big on-device AI models might be the hardware coup of the decade if Apple Intelligence is able to get its sh*t together.
Llama Fight in the Arena
The strongest data point in Llama 4’s favor is the Arena ranking of 1417. That is good for second place, which is indeed impressive if it is reflective of general performance.
Alas, as we all know by now, Arena is being used as an optimization target. Was that done here? We don’t know.
Other signs like the selective benchmarks they released are suggestive of such a strategy, and they would be far from the only ones. Janus asks what other than Goodharting explains the rise in Arena ratings for new models, I think that’s definitely a lot of it, or for things that aren’t actually Arena but are highly corrected to area.
What does Arena optimize for? A random internet user prefers your response to another model’s response.
What makes people prefer one response to another? We can also look at the actual responses, and see, now that Arena has released answers for review.
Morgan: i probably arrive too late but the lmsys voter’s preference for sycophantic yapping is particularly clear this time
Wh: These examples are extremely damning on the utility of Chatbot arena as a serious benchmark. Look through all the examples that Maverick won, and it’s slop after slop after slop. This is the nonsense you are optimizing for if you are trying to goodhart lmsys. Let’s be serious.
This is the clearest evidence that no one should take these rankings seriously.
In this example it’s super yappy and factually inaccurate, and yet the user voted for Llama 4. The rest aren’t any better.
Always start by profusely telling the user how smart they are.
TDM: Struggling to find a single answer in this that is less than 100 lines and doesn’t make me throw up.
AKR: Llama 4 Maverick Experimental vs Claude 3.7 Sonnet
Prompt: Create a web page that shows the current the current month as a table, with no border lines, and has button to move to the previous and next month. It also has the ability to show a bar that can go horizontally across the days in a week to indicate a daily streak.
3.7 Sonnet won easily because of the “Add Streak for Current Week” button which is clearly what’s needed as the prompt. It also better UI imo.
But on the LMArena Experimental Battles UI, the user selected the Llama 4 Mav Exp as the better model
Goes to show that you should never believe these benchmarks unless you really try it out yourself.
Hasan Can: When I said [a well-known AI company is clearly manipulating Arena via watermarking] back on March 28th, nobody offered support. Now, time has come to put a final nail in lmarena’s coffin.
These answers by Maverick, that users voted for, seem absurdly obnoxious and bad. I originally wrote ‘these make me want to puke,’ erased it, but now that I see TDM saying the same thing I’m putting that observation back in. This is the opposite of what I want.
And indeed, this also potentially explains Claude Sonnet 3.7’s low Arena ranking. What if people really do prefer syncopathy and lengthy slop? It exists for a reason.
It’s clear Llama-4 fell victim to Goodhart’s Law [LW · GW], either to Arena rankings directly or to a similar other ranking process they used in fine tuning.
We also know that this version of Maverick on Arena is not the same as the one they released, and it seems, shall we say, ‘slopified.’
The question is, is that all that happened? Did they also outright cheat to get this Arena ranking? I opened a Manifold market, unfortunately we likely never know for sure but I figured something was better than nothing here, suggestions for better resolution methods welcome. When I say ‘cheating’ I mean something beyond ‘a version optimized to do well on Arena.’ I mean actual outright cheating.
Llama Would You Cheat on Other Benchmarks
Did they flat out cheat?
Peter Wildeford: According to The Information, delays were due to the model underperforming on technical benchmarks. In my opinion, it still seems like Meta was pretty selective about the metrics they chose to use (and the metrics they didn’t) and how they did the comparisons, suggesting the model may not be that good.
Satya Benson: The interesting story here is the allegations of cheating on the benchmarks. I’d love to get better sense of to what extent this really happened and how bad the cheating is relative to other models.
First Worldist: My understanding is they tested “experimental” models without disclosing these models were trained specifically for the benchmarks
I wouldn’t think Meta would go this far, for the same reasons as Peter, so I doubt it happened. Nor would they have had to go this far. You actually have to work hard to not accidentally de facto train on benchmarks when using 22T+ tokens.
So while I’m quoting the post for posterity, I assume this accusation is probably false.
Peter Wildeford: I don’t believe the conspiracy theories about training on the test set, but I do think they’ve been highly selective in which metrics they picked in order to pretend to be better than they are.
The fact that the Chatbot Arena is a different bot than the ones getting the math scores is also telling.
Leo: It’s a pretty big no-no in ML, and seems unlikely that Meta researchers would torch their reputation risking something like this. Would need strong evidence to be convinced otherwise.
Peter Wildeford: Agreed. Accusation seems unlikely on priors and the evidence isn’t sufficient to move me enough.
Rrryougi (I doubt the claims here are true, but they seem too important not to include in the record): Original post is in Chinese that can be found here. Please take the following with a grain of salt.
Content:
Despite repeated training efforts, the internal model’s performance still falls short of open-source SOTA benchmarks, lagging significantly behind. Company leadership suggested blending test sets from various benchmarks during the post-training process, aiming to meet the targets across various metrics and produce a “presentable” result. Failure to achieve this goal by the end-of-April deadline would lead to dire consequences. Following yesterday’s release of Llama 4, many users on X and Reddit have already reported extremely poor real-world test results.
As someone currently in academia, I find this approach utterly unacceptable. Consequently, I have submitted my resignation and explicitly requested that my name be excluded from the technical report of Llama 4. Notably, the VP of AI at Meta also resigned for similar reasons.
Ortegaalfredo: “Meta’s head of AI research announces departure – Published Tue, Apr 1 2025”
At least that part is true. Ouch.
There is however this:
Hasan Can: This [below] might potentially constitute first solid evidence suggesting Llama 4 was actually trained on benchmarks.
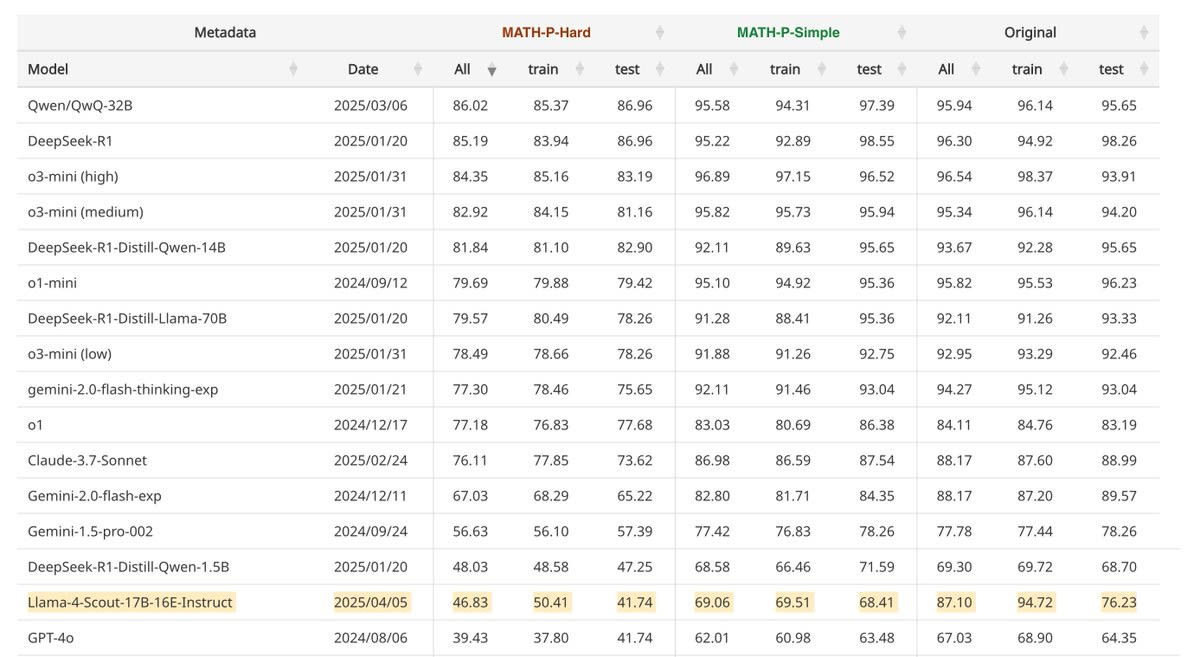
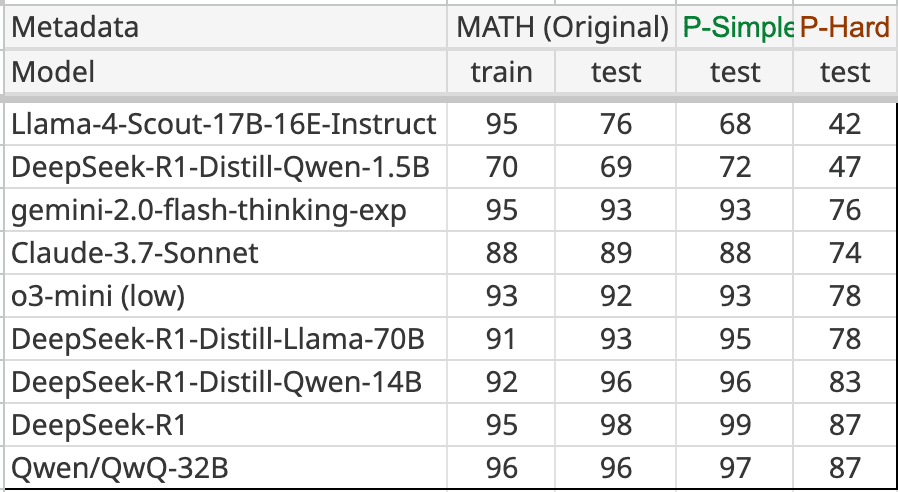
Kaixuan Huang: Just tested Llama4-Scout on our MATH-Perturb benchmark. There is a surprising 18% gap between Original and MATH-P-Simple, making it unique among the 20+ models that came out after 2024.
That sure looks like cheating. Again, it doesn’t mean they intentionally train on the test set. If you have 22T+ tokens and throw the entire internet at your model, there’s going to be contamination. All you have to do is not sufficiently care about not training on benchmarks. Alternatively, you can hill climb on your test scores.
Previously, I would have doubted Meta would let this happen. Now, I have less doubt.
This would not be the first time Meta has broken similar norms.
Holly Elmore: I don’t want to speak out of turn but it doesn’t seem out of character for Meta to me. They knowingly stole libgen and downloaded it via Tor bc they knew it would look bad. The informal ethics of ML are unfortunately not the reassurance I was hoping for.
Those sources seem rather illegal. Meta don’t care. What are you going to do about it?
It is 2025. In general, ‘[X] would goes against norms’ is no longer seen as so strong an argument against doing [X]. The question is now, if I do [X], yes it is against norms, but even if you figure out that I did that, what are you going to do about it?
That goes double for ‘not doing enough to prevent [X] would go against norms.’
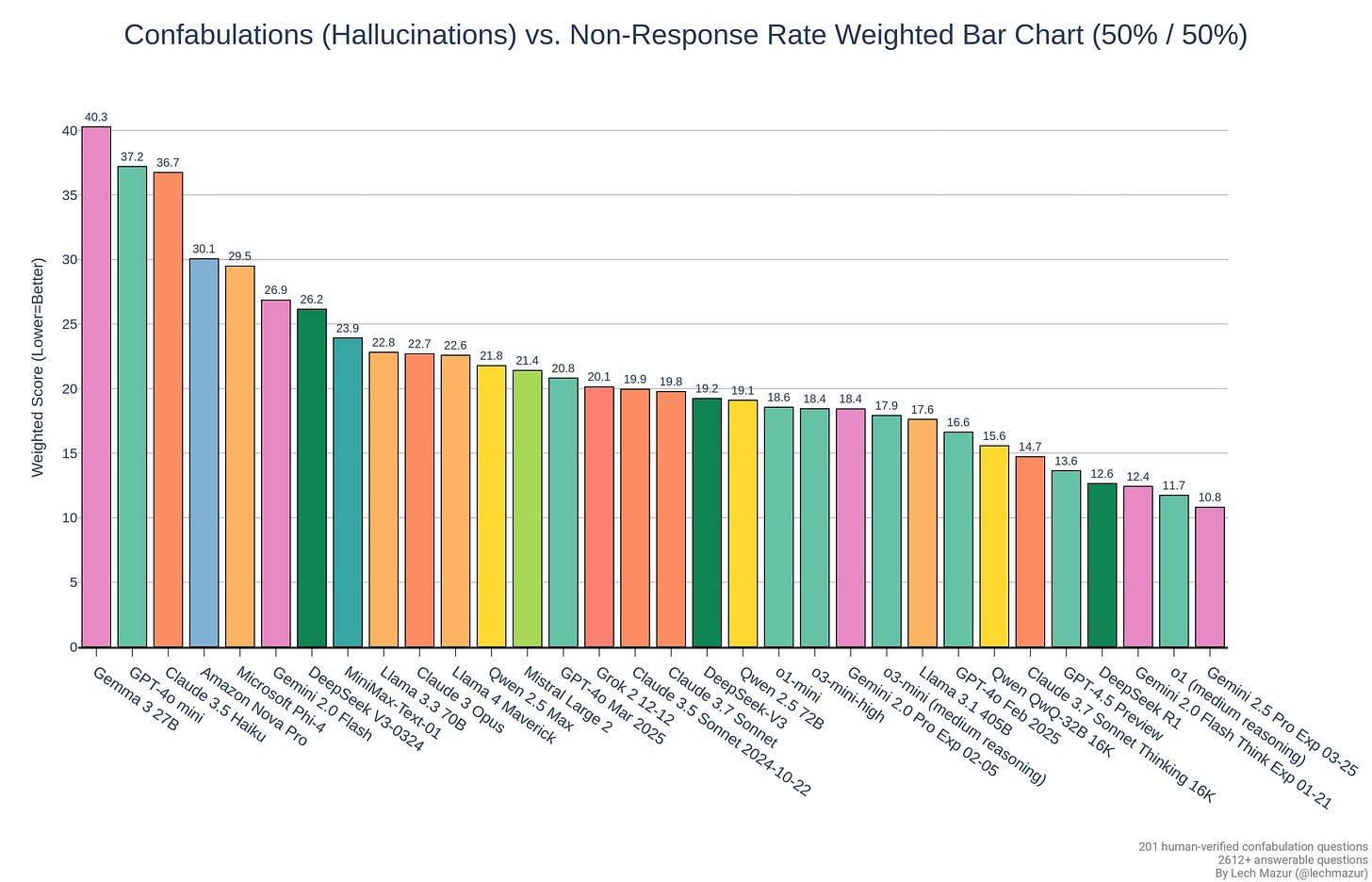
Llama It So Bad on Independent Benchmarks
This is everything I could find that plausibly counts as a benchmark. There are some benchmarks where Maverick is mid, others where it is less than mid.
Markus Zimmerman reports results for DevQualityEval v1.0, and they ‘do not look good,’ they are more than halfway down a very long chart of only open models.
In general, if you have your own benchmark, it doesn’t look good:
George: the most complementary informed takes have come from shrek, eg.
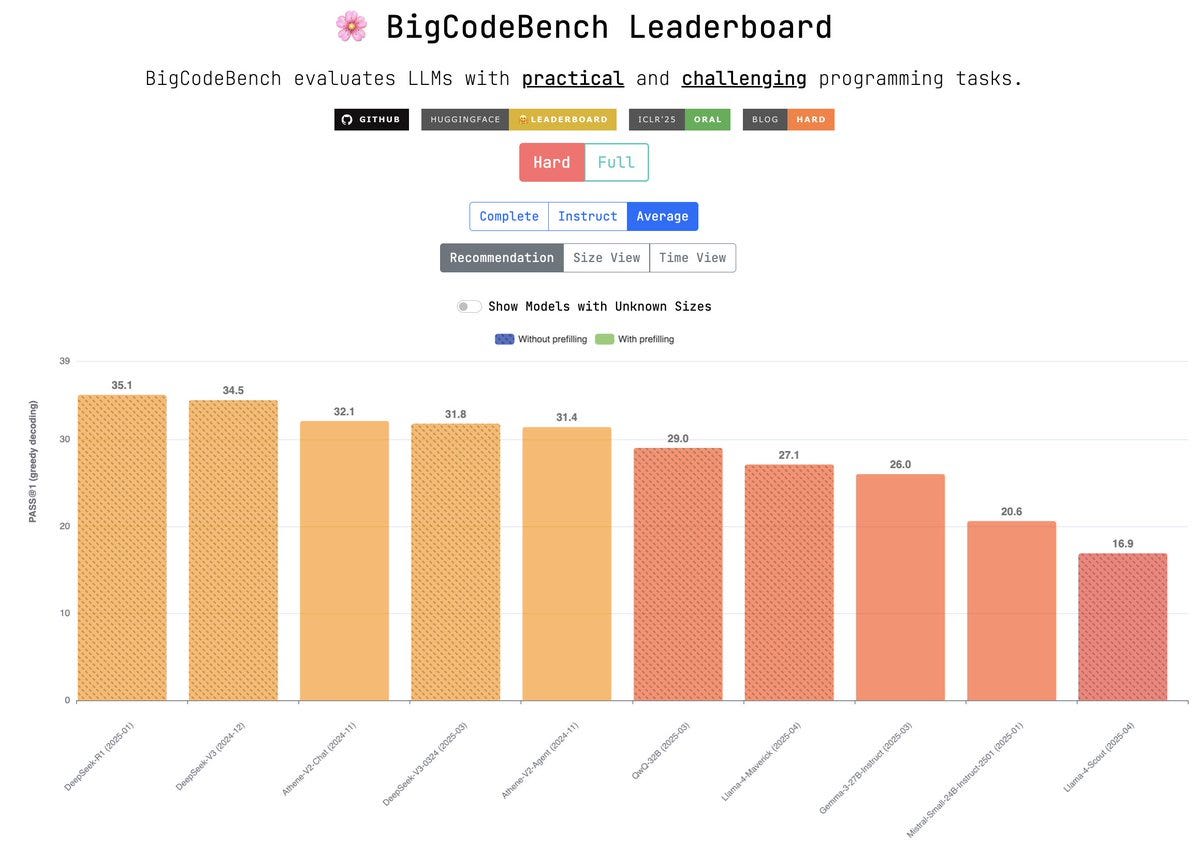
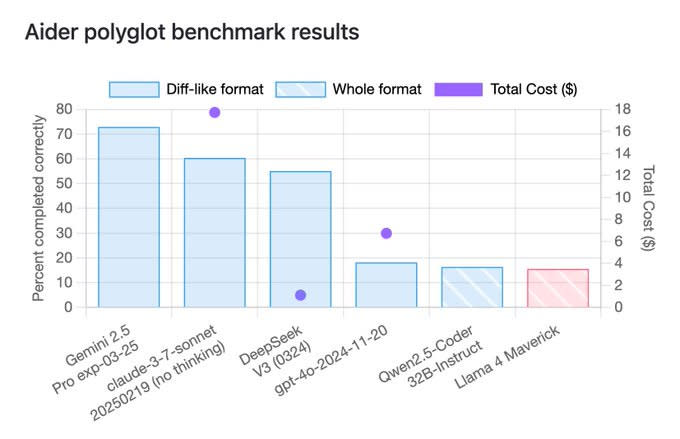
the most damning critical takes (imo) have come from curators of lesser known benchmarks, on which the new models are not performing well. The EQBench site has a couple (/they bombed), bigcodebench had Maverick coming in well below DSv2 (not a typo). Aider Polyglot bench was similarly bleak.
And here by “most damning” I am intentionally excluding takes informed by the sloptimized version that was sent to lmsys. Meta folks are chalking some of the poor results up to implementation issues, but on at least one benchmark (long context fiction) the proprietors have tried three different implementations and netted similarly disappointing scores each time.
Here’s that positive viewpoint, from xjdr, clearly in the context of open models only, essentially saying that Maverick is a specialized model and is good in particular for agentic and tool calling work and for that purpose it is good:
xjdr: my detailed personal benchmarks ran overnight.
– Scout is best at summarization and function calling. exactly what you want from a cheap long ctx model. this is going to be a workhorse in coding flows and RAG applications. the single shot ICL recall is very very good.
– Maverick was built for replacing developers and doing agenic / tool calling work. it is very consistent in instruction following, very long context ICL and parallel multi tool calls. this is EXACTLY the model and capabilities i want in my coder style flows. it is not creative, i have V3 and R1 for that tho. multimodal is very good at OCR and charts and graphs outperforming both 4o and qwen 2.5 VL 72 in my typical tests. the only thing i haven’t tested is computer use but i doubt it will beat sonnet or qwen at that as both models were explicitly trained for it. The output is kind of bland (hence the constant 4o comparisons) with little personality, which is totally fine. this is a professional tool built for professional work (testing it on RP or the like will lead to terrible results). Im not sure what more you could ask for in a agent focused model.
– V3-0324 is not consistent enough with tool calling output to be useful but when it gets it right, it is always the clear and best choice. however, it excels at creativity, problem solving and multi-turn interactions. this will continue to be my non-function calling workhorse. the 131k ctx feels remarkably restrictive now tho. i am going to do some more long ctx testing on V3 cause im almost positive i can get more out of it (200k – 300k ideally), but i think this is where MLA is going to show its tradeoffs. FIM and completion are also huge V3 specific wins here and places where it not only excels but is really in a league of its own.
– R1 continues to be the smartest and most creative model available when used single shot, single turn and when prompted correctly. its the genius in the corner who cant make eye contact but if you properly specify a problem it will be solved with an incredibly high degree of confidence. Function calling (really all of the V3 features) work as expected but the <think> formatting is a bit 1/2 baked and doubly so when you use them with tool use. however, with proper parsing and sampling effort, its a truly remarkable model.
– All of these models benefit tremendously from proper sampling and lovingly crafted matmuls and accumulations. they are all much better and smarter than what is generally available from lmsys or openrouter.
I am incredibly bullish on Behemoth and R2 and cannot wait to fold them into my daily workflow. I have never been happier about the state of open source models and since the R1 launch and when used correctly they provide a viable alternative to frontier models for the first time. I am happy to answer and specific questions but this is probably my last general post on this. i gotta get back to work …
I suppose that is possible. Perhaps it has its niche and will be good at that niche once people adapt to it and scaffold it well. But that’s definitely not how Meta is presenting Maverick or the future Behemoth.
Another sort-of benchmark would be red teaming, done here by Virtue AI. Alas, their tests seem to be against mundane risks only. They find that Llama 4 is significantly less compliant with AI regulations than Claude 3.7 or GPT-4.5, ‘lagging behind peers,’ and evaluations show ‘noticeable weaknesses’ against mundane harms, despite what they call ‘Maverick’s caution dilemma’ and false refusals.
That is distinct from asking about misuse, malicious fine-tuning or other sources of potential catastrophic risk from an open weights model – as always, ‘the license says you cannot do that’ is going to get ignored here. One presumes that the main defense is that these models lack the capability to cause new trouble here, at least in the absence of Behemoth.
Llama You Don’t Like It
Or, here is what people are saying in other realms.
Yair Halberstadt: Reviews on Reddit were that it was total trash, so bad they assume it must be misconfigured or something.
I’ve had confirmation of Yair’s statement from other reliable sources.
Murat: just tried llama 4 scout on groq cloud. 512 tok/s is great
however just like all the other eval-optimized models (like claude 3.7, o3-mini etc.) it doesn’t follow instructions properly. i can’t use it as drop-in replacement for my existing prompt pipelines.
just tried llama maverick. same thing. unimpressed.
grok lacks api so sonnet 3.5 is still my main squeeze.
Medo 42: Personal toy benchmark (a coding task I give to every new model): Not good at all. Shares last place with Gemini 2.0 Pro 02-07 now.
Roughly: “The code returned an array of objects in the right shape and one of the fields of the objects had the right value most of the time”
I can’t even run tic-tac-toe bench properly because Llama-4-400B can’t shut up and just answer with 1 number.
Llama-4-109B can for some reason.
Who was the biggest cheerleader that doesn’t work at Meta?
AI and crypto czar David Sacks: Congrats to the @AIatMeta team on the launch of their new Llama 4 open-weights models. For the U.S. to win the AI race, we have to win in open source too, and Llama 4 puts us back in the lead.
Peter Wildeford: Google is so bad at marketing that @davidsacks47 doesn’t praise Gemma 3.
Failure to mention Gemma 3 feels like strong mood affectation, on top of the marketing issues. Google is known as a closed lab, Meta is known as open. But mainly yes, Google’s marketing is atrocious. But a claim that Gemma 3 put us back in the lead was a lot more defensible than one about Llama 4.
Kalomaze: if at any point someone on your team says
“yeah we need 10 special tokens for reasoning and 10 for vision and another 10 for image generation and 10 agent tokens and 10 post tr-“
you should have slapped them
this is what happens when that doesn’t happen
Minh Nhat Nguyen: do not go into the llama tokenizer dot json. worst mistake of my life.
tbf i think the reserved llama tokens are nice for ablation experiments, but they rly go overboard with it
Jim Fan says ‘Llama-4 doesn’t disappoint’ but his response seems entirely based on Meta’s claims and reports rather than any independent assessment of performance.
All general reports on feedback say that people are disappointed. It was so disappointing that mostly people treated it as a non-event until asked.
Mena Fleischman: I haven’t seen anything particularly complimentary. They held off on dropping Behemoth which was supposed to be the real showcase of something SOTA, and next-best Maverick in their own stats got mostly beat by Deepseek, who was already beaten on release.
Very weak showing.
Andriy Burkov: If today’s disappointing release of Llama 4 tells us something, it’s that even 30 trillion training tokens and 2 trillion parameters don’t make your non-reasoning model better than smaller reasoning models.
Model and data size scaling are over.
Along similar lines, Alexander Doria doesn’t see much point in giving 40T tokens to Llama-4 Scout, and 22T to Llama-4 Maverick.
I don’t think this means model and data size scaling are over. I think it means that if you do not know how to execute, sheer size will not save you, and probably gives you smaller marginal gains than if you executed well.
Llama Should We Care
The big takeaway is that we have to downgrade expectations for Meta in AI, and also our expectations for how much we can trust Meta.
Despite vastly superior resources, Meta now seems to be trying to copy DeepSeek and coming up short. Exactly how short depends on who you ask. And Meta is, to an unknown degree, making a deliberate effort to make its models look good on benchmarks in ways that violate norms.
It is hard to count out a top tech company with tons of compute and almost endless capital. They could still turn this ship around. But they’re going to have to turn this ship around, and do it fast, if they want to be competitive.
Right now, America’s open model champion isn’t Meta. It is Google with Gemma 3, and soon it may also be OpenAI, which is planning an open reasoning model soon. I realize that causes some dissonance, but that’s where we are. Beware mood affectation.
The most important thing about Llama 4 is that the 100K H100s run that was promised got canceled, and its flagship model Behemoth will be a 5e25 FLOPs compute optimal model[1] rather than a ~3e26 FLOPs model that a 100K H100s training system should be able to produce. This is merely 35% more compute than Llama-3-405B from last year, while GPT-4.5, Grok 3 and Gemini 2.5 Pro are probably around 3e26 FLOPs or a bit more. They even explicitly mention that it was trained on 32K GPUs (which must be H100s). Since Behemoth is the flagship model, a bigger model got pushed back to Llama 5, which will only come out much later, possibly not even this year.
In contrast, capabilities of Maverick are unsurprising and prompt no updates. It's merely a 2e24 FLOPs ~7x overtrained model[2], which is 2x less compute than DeepSeek-V3 and 100x less than the recent frontier models, and also it's not a reasoning model for now. So of course it's not very good. If it was very good with this little compute, that would be a feat on the level of Anthropic or DeepSeek, which would be a positive update about Meta's model training competence, but this unexpected thing merely didn't happen, so nothing to see here, what are people even surprised about (except some benchmarking shenanigans).
To the extent Llamas 1-3 were important open weights releases that could be run by normal people locally, Llama 4 does seem disappointing, because there are no small models (in total params), though as Llama 3.2 demonstrated this might change shortly. Even the smallest Scout model still has 109B total params, meaning a 4 bit quantized version might fit on high end consumer hardware, but all the rest is only practical with datacenter hardware.
288B active params, 30T training tokens gives 5.2e25 FLOPs by 6ND. At 1:8 sparsity (2T total tokens, maybe ~250T active params within experts), data efficiency is 3x lower than for a dense model, and for Llama-3-405B the compute optimal amount of data was 40 tokens per param. This means that about 120 tokens per param would be optimal for Behemoth, and in fact it has 104 tokens per active param, so it's not overtrained. ↩︎
17B active params, 22T tokens, which is 2.25e24 FLOPs by 6ND, and 1300 tokens per active param. It's a weird mix of dense and MoE, so the degree of its sparsity probably doesn't map to measurements for pure MoE, but at ~1:23 sparsity (from 400B total params) it might be ~5x less data efficient than dense, predicting ~200 tokens per param compute optimal, meaning 1300 tokens per param give ~7x overtraining. ↩︎