Confusions re: Higher-Level Game Theory
post by Diffractor · 2021-07-02T03:15:11.105Z · LW · GW · 5 commentsContents
Policies and Environments Metathreat Hierarchy Multiple Players Cooperative Oracles Are Bad, Actually None 5 comments
This is not a success post. This is me trying to type up a rough draft of a bunch of issues that have been floating around in my head for quite some time, so I have a document for me and others to refer back to.
So, the standard game theory setup (in a simple toy 2-player case) is, you've got a space and (the 0 subscripts are for notational consistency for later) of your actions and the actions of your opponents, respectively. You've got a function of how you respond to knowledge of what the foe does, and they have their corresponding function of how they respond to knowledge of what you do, and... oh right, this might go in a loop, as in the game of Matching Pennies, where you're trying to copy your opponent, and your foe is trying to do the opposite thing as you do.
The way to solve this is to switch to randomized strategies, so now you're dealing with continuous functions and the reverse (or upper-hemicontinuous set-valued functions if we're being technical) and then, pairing those two functions together, now you've got a continuous function which effectively says that both players read the plans of their foe (though the random bits cannot be read), and revise their decision accordingly. Just chuck the Kakutani or Brouwer fixpoint theorem at this, and bam, equilibria are guaranteed to exist, no matter what the two players end up doing with their information on the foe's behavior. No guarantees on being able to find those fixpoints by iteration, however.
Nash equilibria are generated by both players using the argmax strategy which tries to respond as best as possible to what the foe is doing. It's given by (where and are the probability distributions of the two players, and is the utility function of the first player). And it has the teensy little problem that it's assuming that you can make your decision completely independently of the foe without them catching on and changing what they do in response. Which is an extremely questionable assumption to be making when the problem setup is giving the two players mind-reader access to each other.
So, there's a tier of just acting, where you're just picking an action. and . Then there's the tier of reacting, with type signature or , or variants, where you peek at the foe.
But these two type signatures are only the first in a hierarchy. Let's say that, instead of just knowing what the foe was thinking of doing, you knew their decision procedure. Which doesn't look like much of a stretch, especially given that knowing someone's decision procedure seems easier than knowing their planned output for a game where you can't peek at the foe. The former only requires source code access while the latter requires actually running the computation that is the foe. So, there could also be strategies of type (ignoring randomization issues for now). Letting be the strategy of the foe, you could implement , which looks at the foe's strategy and locks in an action accordingly.
In the game of Chicken for example, this would inspect the naive argmax strategy of your hapless foe, rip the steering wheel off, and throw it out the window, as the foe surely swerves in response upon seeing that you're definitely going straight. Victory! But wait, hang on, this is reliant on exploiting the strategy of a foe that's only peeking at your output, not your decision procedure... Your're acting, and your foe is reacting upon observing what you do, not how you think. You're moving logically first. This is the tier of planning ahead, having counterfactuals for your actions, and exploiting the predictable reactions of your opponent.
And there's a level up above that! It would be the type signature
This goes "alright, if you pick actions in accordance with how I react to things, then I'll pick a way of reacting to observations that incentivizes you to pick good actions". Examples of this include, for the Prisoner's Dilemma, going "look at the foe, and if they're running argmax, commit to cooperate if you see the foe cooperate and defect if they defect. They'll see you made this commitment and cooperate." For Chicken, this would be something like "look at the foe, and if they'd be cowed by a rock on the accelerator pedal, put a rock on the accelerator pedal".
There's also Nuclear Prisoner's Dilemma. It's like Prisoner's Dilemma, but there's also an option to set off a nuke, which is, by a massive margin, the worst outcome for both players. A strategy at this level for Nuclear PD would be "look at the foe, and, if they're the sort that would give in to threats, commit to firing the nuke if they defect and defecting if they cooperate."
This is the tier of policy-selection setting up incentives for your foes to react to.
We clearly need to go further! Onward to
This is like... "the foe is checking [the way I pick actions to exploit their reactions], and picking their reactions accordingly, I will pick a [way to pick actions to exploit their reactions] that makes the foe have reactions that interact well with the thing I just picked."
As amazing as it may seem, humans thinking about game theory can naturally hit levels this high. Going "hm, I'm playing the Nuclear Prisoner's Dilemma, I'd better implement a coercion-proof strategy (not naive argmax) so I don't incentivize my foe to pick [react to defection with a nuke]" would be at this level.
This is the tier of refusing to react to incentives, and thinking about [how to think when picking actions in an environment]
The general pattern here with the levels is, we've got and as the actions of player A and player B, respectively. Then, for the next level, we have
And then the inductive definition of higher levels takes off from there as
Check the image.
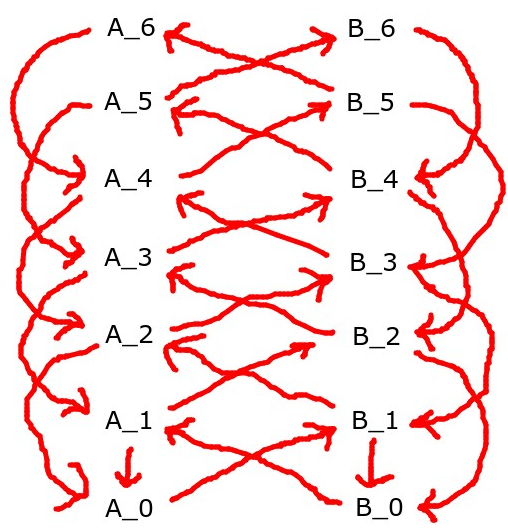
This general framework and type signatures like this is the sort of thing I've been repeatedly going back to when thinking of open-source game theory and what UDT does against itself. On one hand it leads to a rather crisp formulation of some problems. On the other hand, I haven't made a bunch of progress with it, this might be a bad framework for thinking about things.
So, first-off, note that if the A strategy is one level higher than the B strategy, or vice-versa, then playing those two strategies against each other will unwind down to a pair of actions via repeated play.
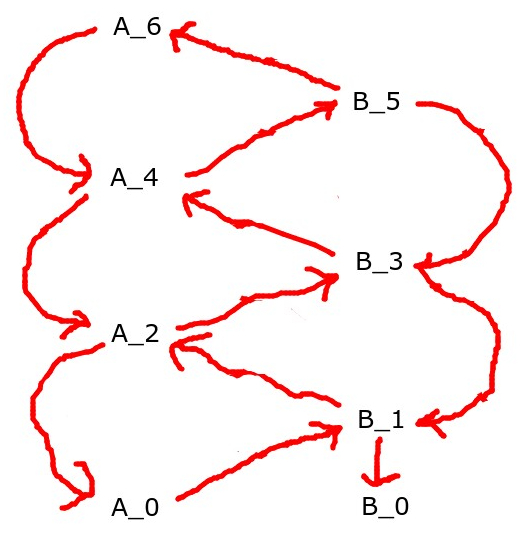
A big problem with this whole setup is that it seems to bake in the assumption that one player is leading and the other one is following. This hierarchy does not naturally have support for two players who are true peers. There's an assumption that some player gets to go first, and predict what its foe would do without having the foe listening in on its thoughts, and have the foe observe what it outputs, and everything after that is just a chain of reacting to each other until everyone eventually grounds out in an action.
You could try having two players at the same level if you specify a level n+2 strategy and a level n+1 strategy for both of them, but then, this has the problem that there's two ways to get your action, you could unwind things this way
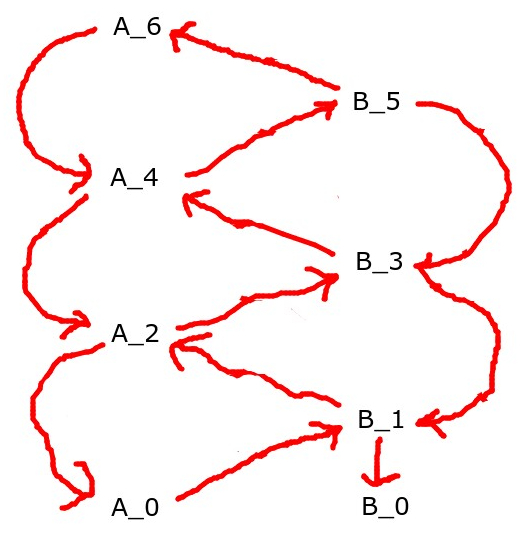
or this way
and there's no guarantee they'd be identical.
One virtue of this setup is that it leads to a very clear form of the commitment races problem [AF · GW]. In particular, if you have two players vs each other in Chicken which are both running argmax, and one of them is one level higher than their foe, their best strategy is always to commit super-hard to going straight, as the foe will see that this has occured and swerve in response. But, again, two identical agents doing this would crash into each other. This hierarchy doesn't have support for two agents being at the "same level". And if you try to implement "figure out which level the foe is operating at, then operate one level higher than that", two identical agents would just go into a loop.
Policies and Environments
There's interesting parallels to acting in an environment, the type signatures sorta line up. For the base level, the type signatures for "act blindly" would be and . Basically, histories ending in an action, and histories ending in an observation. There's parallels with the action and observation. The type signatures one level up would be the type signature for a policy and an environment, respectively. (policies), and (environments). If you want, you can view all these functions as being composed with concantating the input history with the output, to get type signatures of and , which should make it a bit clearer that the type signatures line up.
Of note is that there's a weird sort of thing going on where, for standard game theory, you'd throw Brouwer/Kakutani at the policies (and sample from a result) to get an action, and for policies and environments, the history of play is found by repeatedly playing the policy and environment against each other, in a way that looks vaguely reminiscent of computing a least fixpoint by iteration.
Going one level up to policy-dependent environments and planning processes, the type signatures diverge a bit from the sorts of type signatures in our hierarchy. Policy-dependent environments would be of type , which map a policy to an environment, instead of type , as you'd expect from the game-theory hierarchy. With currying, the type signature can be reexpressed as which makes it clearer that it's taking a policy and history so far and responding with an observation. It's an environment that's responding to what your policy is.
The analoguous concept one level up from policies would be... well, there isn't really an accepted name for it yet. I'll call it a planning process. The type signature would be . Ie, it takes in an environment, and spits out a policy that optimizes for that environment. Or, with currying, you can see it as , which takes in an environment and history, thinking for a while, and acting accordingly to do well.
With the modified type signatures, this makes the pattern of the lower layers somewhat different from the standard hierarchy, as shown in the image.
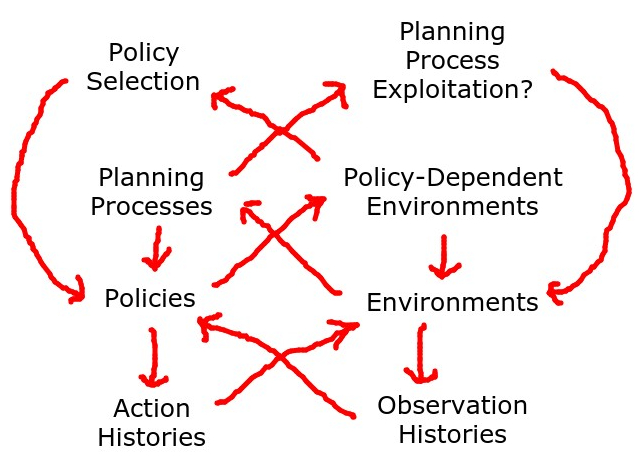
Accordingly, note that playing a planning process vs a policy-dependent environment leads to a loop that might not settle down. The choice of policy depends on the agents oracular knowledge of what the environment is, and the environment depends on the choice of policy. This loop is cut in practice by the agent not knowing for sure what environment it's in, so it just picks a policy that does well vs a nice mix of simple environments.
Going one level up, on the agent side of things, we'd have policy selection processes, which takes a policy-dependent environment and maps it to a policy, of type
.
UDT lives at this level.
On the environment side of things, it would be...
Which takes a planning process and maps it to an environment accordingly, like thinking about which approximation of full tree search a bounded agent is using, and acting accordingly to exploit it. This concept hasn't really shown up in practice.
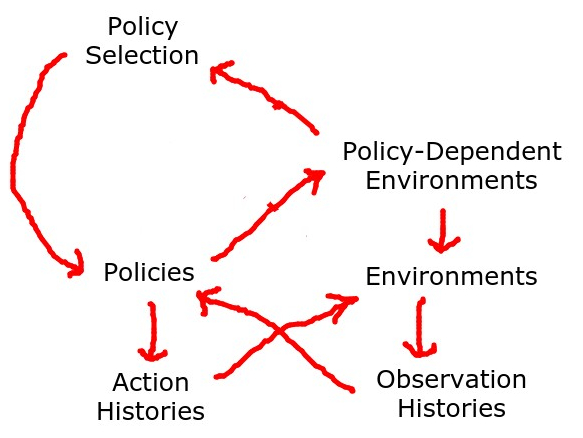
As the diagram indicates, the standard setup with UDT playing against a policy-dependent enviroment avoids loops, but it's asymmetric. Again, there's an assumption of being one level above the foe.
Metathreat Hierarchy
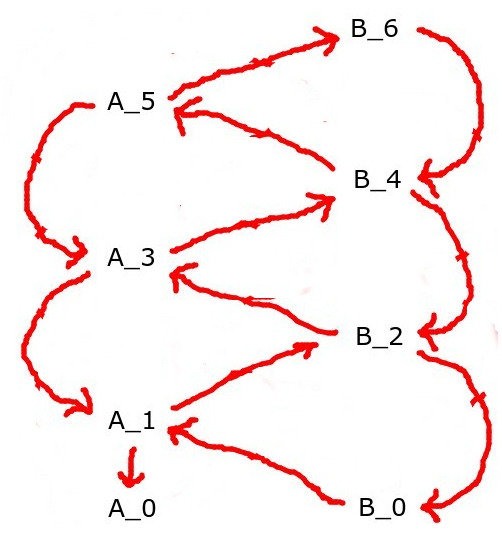
Also, there's Vanessa's old metathreat hierarchy idea [AF · GW]. What this would be is that both players have randomized strategies, so we have A and B at the lowest layer. One layer up, we have and . One layer up, it'd be and . One layer up from that would be and . Refer to the indicated image.
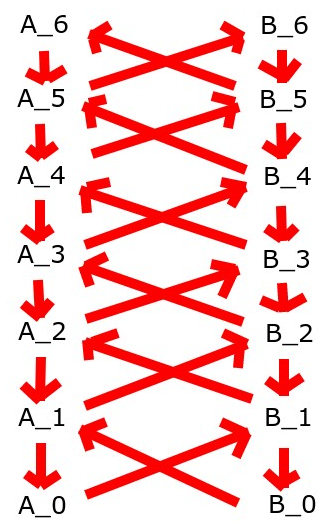
The way it works is that, at each level, the pair of strategies defines a Markov chain over the space of strategies one level down. There's some technical conditions used to ensure that said Markov chain is the sort which has a unique stationary distribution. Then, just sample a pair of one-level-down strategies from the stationary distribution, and repeat. This has the virtue that, by default, it deals with the foe being at the same level as you, which the other approaches don't do. And, it generalizes much more nicely to the multi-player case. Besides that, fairly little is known about it. Also, since it's sampling from a stationary distribution, it will, in general, produce correlations between the foes, like in correlated equilibria, instead of the foes being uncorrelated. Basically, it's assuming that the two players can observe shared random bits.
Multiple Players
When dealing with multiple players, the standard hierarchy I set up earlier doesn't quite work. For the three-player case, for instance, if we try to just adapt the two-player case as
And then the inductive definition of higher levels works as
Sadly, this doesn't have the nice property where, if you're one level higher than your foes, everything unwinds down nicely to get actions. For instance, if the first player is running a level-n+2 strategy with type , which unpacks as , and the other two players are running level-n+1 strategies with types and , then the first player sees the level-n+1 strategies, and picks a level n strategy , which is then known, reducing the level-n+1 strategies to and , and we've got a two-player game with both players on the same level, which, as previously established, is tricky to handle. The metathreat hierarchy deals well with this by being easily able to handle foes on the same level.
Again, you could try to fix this by specifying two levels of the hierarchy, but again, things get weird when you get to the bottom.
Cooperative Oracles Are Bad, Actually
It's been quite a while ago, but thinking about what strategies would work on the higher levels in various game theory situations has made me a lot more pessimistic about approaches like cooperative oracles [AF · GW]. For opponents playing functions and vs each other, this can be implemented by calling a reflective oracle on the foe, to know the probability distribution over their actions. The choice of reflective oracle pins down which equilibrium point is selected. Nash equilibria are attained when both players are using naive argmax, but other strategies are possible. A cooperative oracle is a special type of reflective oracle which is guaranteed to to select Pareto-optimal outcomes.
The dissatisfactory aspect of cooperative oracles is that, in the basic mathematical setup, they had an agent being a pair of a utility function and a strategy. The strategy doesn't need to have anything at all whatsoever to do with the utility function. I think that having a utility function at the lowest fundamental level is a mistake, an agent is just the strategy. There's a sense in which a whole bunch of situations an agent can be in can be thought of as games, it's just that most of the time, the "foe" is implementing an extremely simple strategy that doesn't look at what you do (the sun rises in the morning, regardless of what you do), or responds to what you pick (as in the case of viruses responding to your choice of antiviral medication), at level 0 or level 1, any utility function these strategies are tagged with would be completely epiphenomenal.
Conclusion:
There's probably a lot more that could be said about this, and more frameworks to poke at, but this is the dump of where my thoughts are at right now.
5 comments
Comments sorted by top scores.
comment by Donald Hobson (donald-hobson) · 2021-07-03T14:58:41.332Z · LW(p) · GW(p)
In a game with any finite number of players, and any finite number of actions per player.
Let the set of possible outcomes.
Player implements policy . For each outcome in , each player searches for proofs (in PA) that the outcome is impossible. It then takes the set of outcomes it has proved impossible, and maps that set to an action.
There is always a unique action that is chosen. Whatsmore, given oracles for
Ie the set of actions you might take if you can prove at least the impossility results in and possibly some others.
Given such an oracle for each agent, there is an algorithm for their behaviour that outputs the fixed point in polynomial (in ) time.
comment by Nisan · 2021-07-02T17:49:03.979Z · LW(p) · GW(p)
I feel excited about this framework! Several thoughts:
I especially like the metathreat hierarchy. It makes sense because if you completely curry it, each agent sees the foe's action, policy, metapolicy, etc., which are all generically independent pieces of information. But it gets weird when an agent sees an action that's not compatible with the foe's policy.
You hinted briefly at using hemicontinuous maps of sets instead of or in addition to probability distributions, and I think that's a big part of what makes this framework exciting. Maybe if one takes a bilimit of Scott domains or whatever, you can have an agent that can be understood simultaneously on multiple levels, and so evade commitment races. I haven't thought much about that.
I think you're right that the epiphenomenal utility functions are not good. I still think using reflective oracles is a good idea. I wonder if the power of Kakutani fixed points (magical reflective reasoning) can be combined with the power of Kleene fixed points (iteratively refining commitments).
comment by Pattern · 2021-07-10T15:13:36.542Z · LW(p) · GW(p)
Nash equilibria are generated by both players using the argmax strategy which tries to respond as best as possible to what the foe is doing.
Which (seems to) make sense when it's zero-sum.
And it has the teensy little problem that it's assuming that you can make your decision completely independently of the foe without them catching on and changing what they do in response.
One component is kind of like asking 'what moves are good whatever the other player does', though the formalization seems to drift from this. (And the continuous/probabilistic version I'm slightly less clear on - especially because these agents don't choose equilibria.)
Which doesn't look like much of a stretch, especially given that knowing someone's decision procedure seems easier than knowing their planned output for a game where you can't peek at the foe. The former only requires source code access while the latter requires actually running the computation that is the foe.
Or having observed them actual make an action - whatever the procedure - but that's fair, that's a different game.
Basically, it's assuming that the two players can observe shared random bits.
I didn't know that. (Not surprising given "fairly little is known about it.".)
comment by Dagon · 2021-07-02T20:18:55.897Z · LW(p) · GW(p)
in the basic mathematical setup, they had an agent being a pair of a utility function and a strategy. The strategy doesn't need to have anything at all whatsoever to do with the utility function.
Do you have a link to this usage of these terms? I think that, for rational agents, the strategy is an application of the utility function to the game and opponent(s). They're not quite isomorphic - you can derive the strategy from the utility function, but not the reverse (you can derive a utility theory, but it may be underspecified and not the actual agent's utility theory outside this game). Similary, Oracles don't add anything to the theory - they're just an implementation of higher-levels of simulation/prediction.
I think a lot of the recursion falls apart when you add in resource constraints, via a cost to calculation. When the rewards are reduced by the amount of energy taken for the computation, it's a lot harder to unilaterally optimize, and it becomes worth it to accept lower but "safer" payouts.
comment by Gurkenglas · 2021-07-02T16:42:03.970Z · LW(p) · GW(p)
Why not take the bilimit of these types? , I'm guessing. The MirrorBot mirror diverges and that's fine. If you use a constructivist approach where every comes with the expression that defined it, you can define such strategies as "Cooperate iff PA proves that the opponent cooperates against me.".