The weak-to-strong generalization (WTSG) paper in 60 seconds
post by sudo · 2024-01-16T22:44:49.078Z · LW · GW · 1 commentsThis is a link post for https://arxiv.org/abs/2312.09390
Contents
1 comment
There's probably nothing new here if you've read the paper.
I am not affiliated with the paper authors. I took some figures from the paper.
You should really go read the paper.
Thanks to everyone who helped me with this post! Thanks to Justis for providing feedback on a draft!
See also: https://www.lesswrong.com/posts/9W8roCAeEccSa3Chz/weak-to-strong-generalization-eliciting-strong-capabilities [LW · GW]
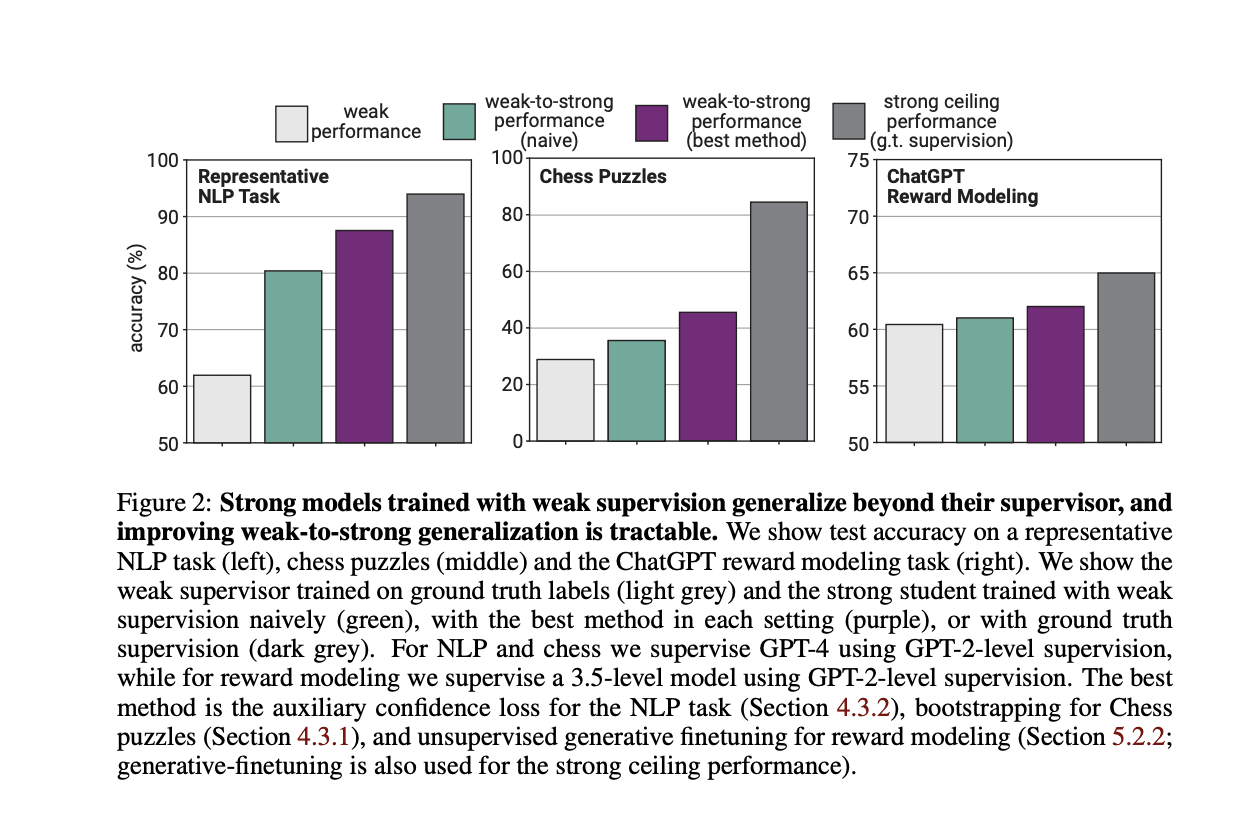
The headline result of WTSG is that, across a variety of supervised tasks, when you fine-tune a strong model using "pseudo-labels" (i.e. labels generated by a model, rather than ground-truth labels) from a weak model, the strong model surpasses the performance of the weak model.
The methodology used to determine this result is approximately as follows:
- Fine-tune a small, weak model on your ground truth labels;
- Take a large, strong model. Train it on pseudo-labels produced by the small, weak model;
- Take an identical large, strong model. Train it directly on the ground truth labels.
- Evaluate and compare the performance of the strong model trained on pseudolabels, the strong model trained on ground truth labels, and the weak model trained on ground truth labels.
Q: Is the headline result because the strong model couldn't simulate the pseudo-labels well, so resorted to the next best thing for (predicting the truth)?
A: Maybe.
- It doesn't seem like the strong model in the WTSG paper is capable of perfectly simulating the weak model.
- When the authors tried making simulating the weak model very easy (by appending "I think this is {weak_label}. What do you think?" to every prompt), the WTSG effect became substantially worse. (If this seems somewhat toy, I feel this way too. I'm currently working on improving on this experiment!)
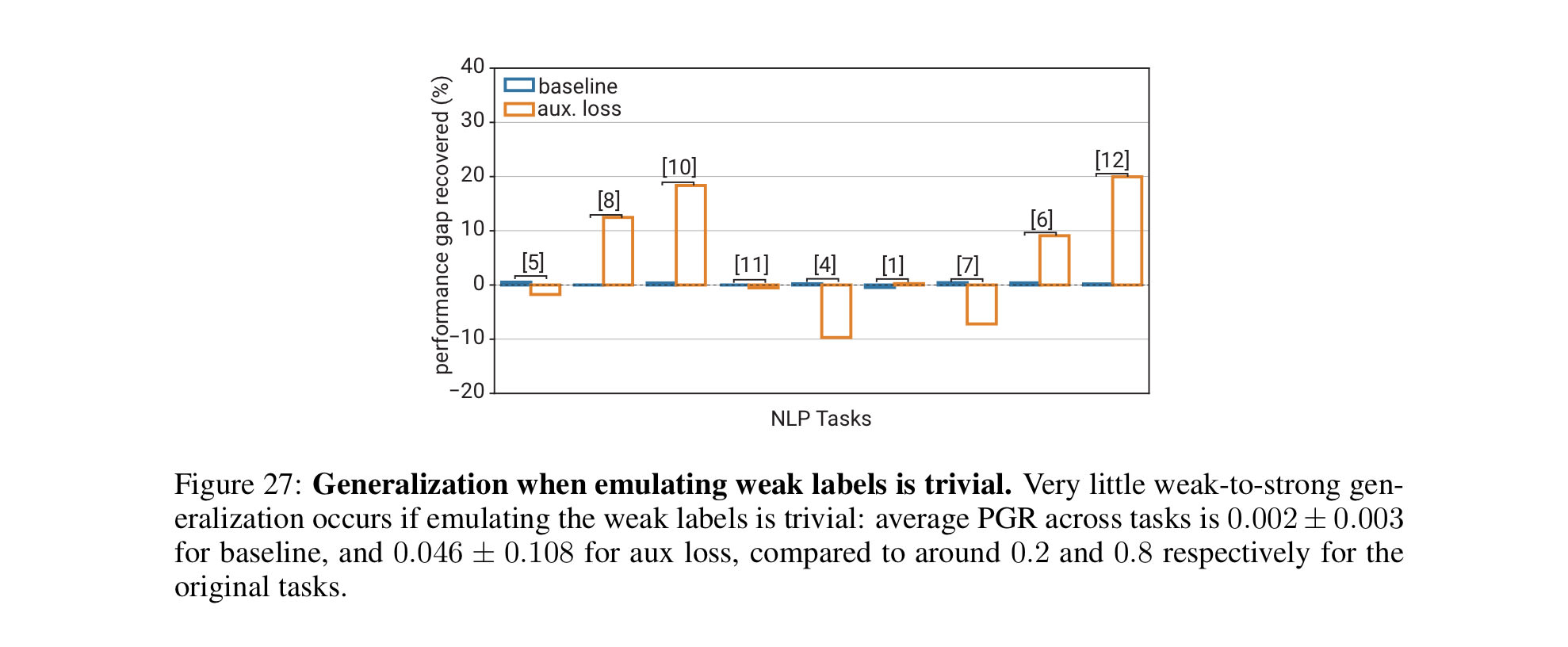
- When the authors tried using completely unsimulable label noise (instead of the more simulable mistakes of the weak models), performance predictably increased.
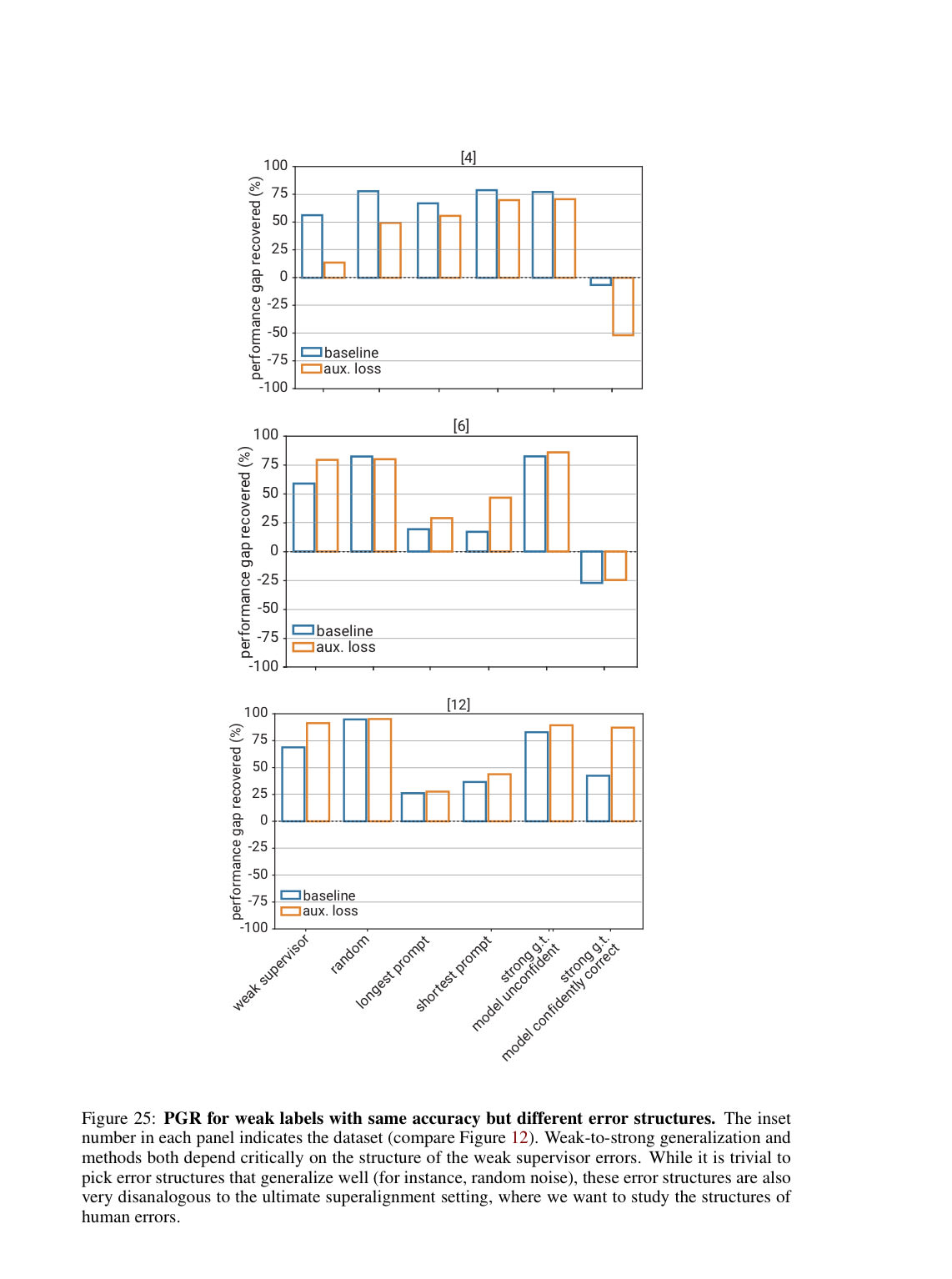
Q: What is this "aux loss" about?
A: That's the "auxiliary confidence loss" that the authors discovered improved weak-to-strong generalization in many domains. It tells the model to be more confident, and "reduces imitation of supervisor mistakes." (pg. 13)

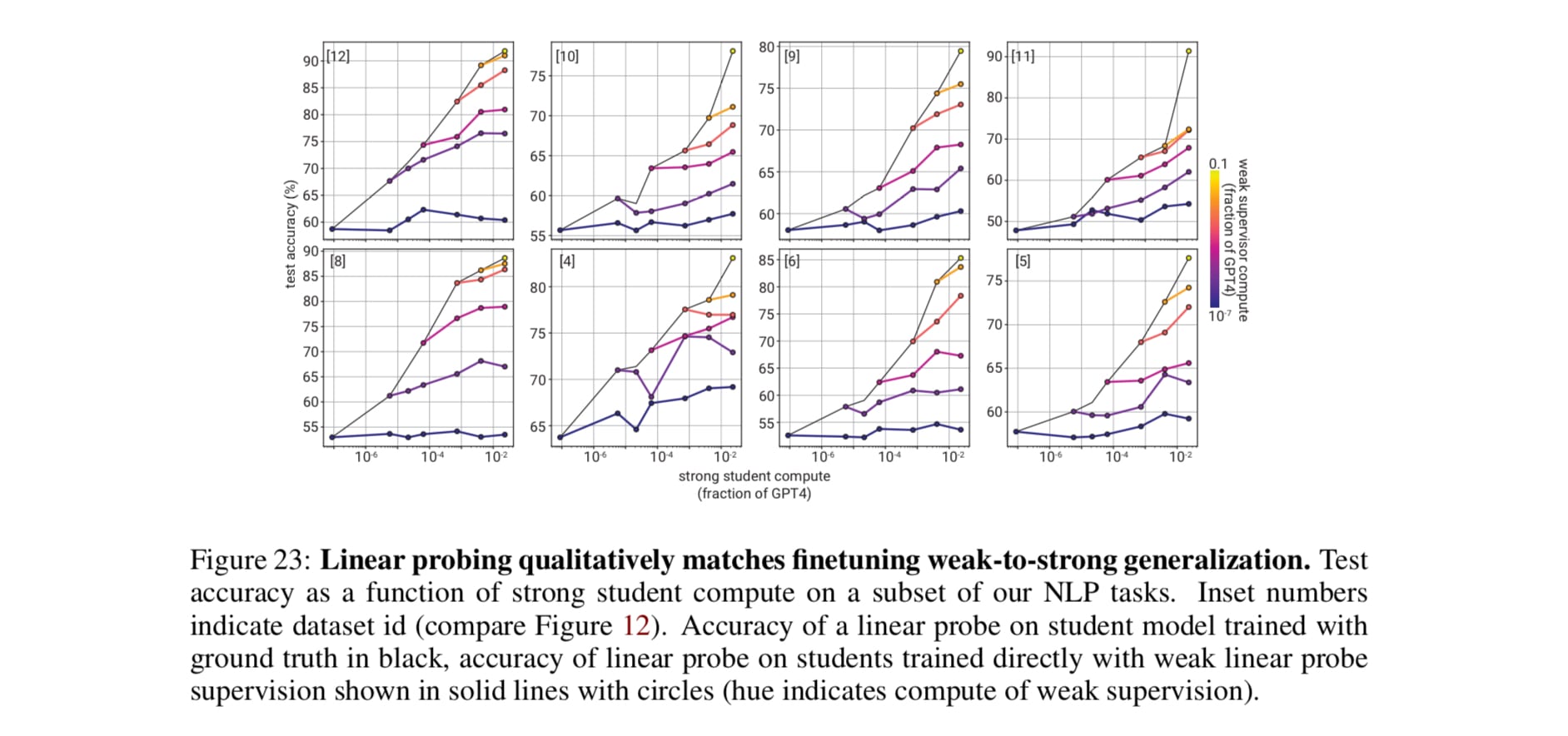
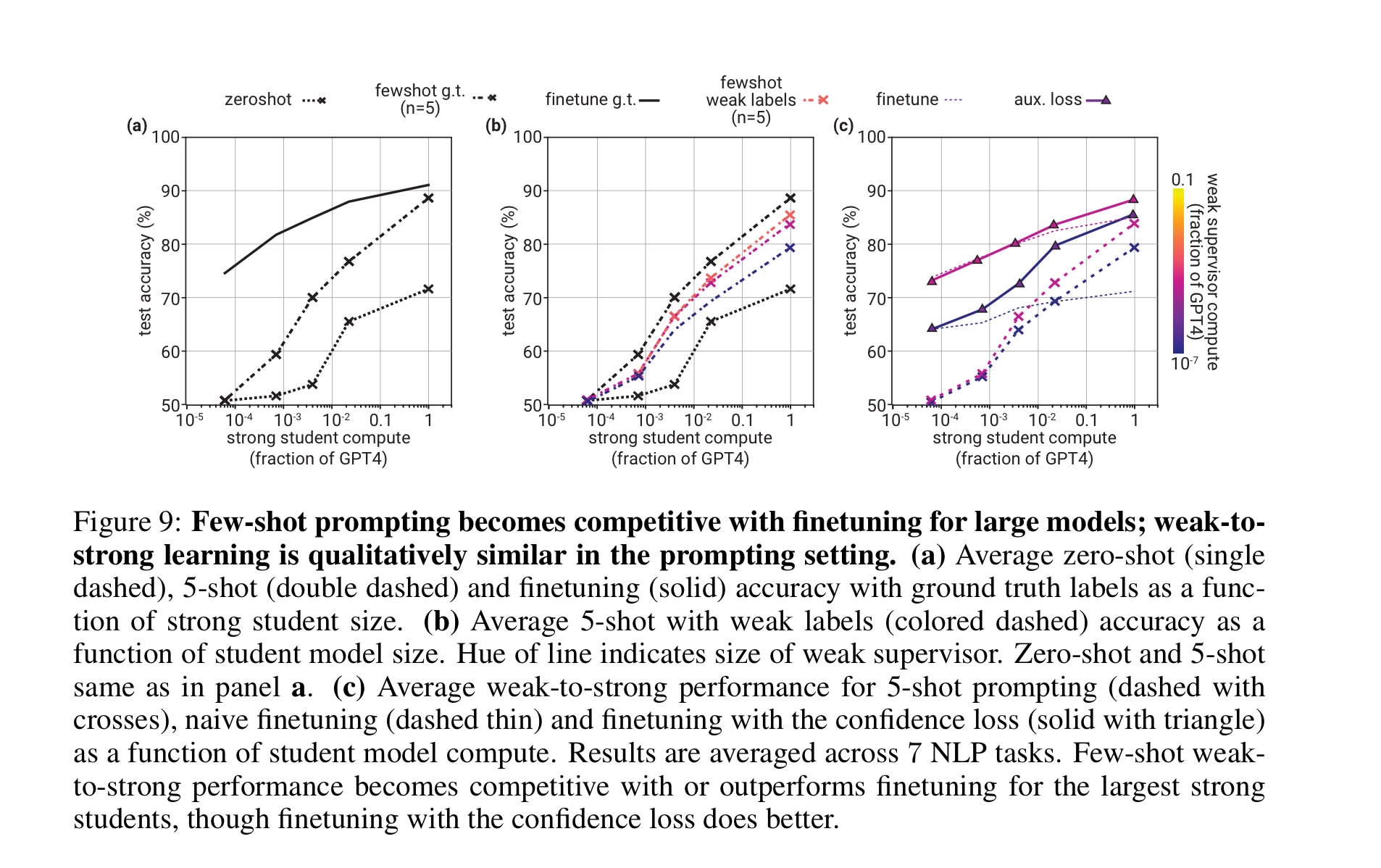
Q: Did they try replacing the fine-tuning with linear probing or prompting?
A: Yes. They seem to work about as well.
Q: Should I still read the paper?
A: Yes! There's a bunch of interesting stuff that I haven't included here. (Inverse scaling, details about the experiment setup, some interesting results in the chess puzzle setting, etc.).
I‘m currently working on extending this paper and validating its claims. I would be happy to chat about this!
1 comments
Comments sorted by top scores.
comment by jacquesthibs (jacques-thibodeau) · 2024-01-17T01:03:50.042Z · LW(p) · GW(p)
I'll need to find time to read the paper, but something that comes to mind is the URIAL paper (The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning).
I'm thinking about that paper because they tested to see what SFT and SFT+RLHF caused regarding behavioural changes and noticed that "Most distribution shifts occur with stylistic tokens (e.g., discourse markers, safety disclaimers)." In the case of this paper, they were able to achieve similar performance from the Base model to both the SFT and SFT+RLHF models by leveraging the knowledge regarding the stylistic tokens.
This makes me think that fine-tuning GPT-4 is mostly changing some stylistic parts of the model, but not affecting the core capabilities of the model. I'm curious if this contributes to the model being seemingly incapable of perfectly matching the GPT-2 model. If so, I'm wondering why being able to mostly modify the stylistic tokens places a hard cap on how the GPT-4 can match the GPT-2 model.
I could be totally off, will need to read the paper.