Toward a taxonomy of cognitive benchmarks for agentic AGIs
post by Ben Smith (ben-smith) · 2024-06-27T23:50:11.714Z · LW · GW · 0 commentsContents
No comments
Inspired by the sequence on LLM Psychology [LW · GW], I am developing a taxonomy of cognitive benchmarks for measuring intelligent behavior in LLMs. This taxonomy could facilitate understanding of intelligence to identify domains of machine intelligence that have not been adequately tested.
Generally speaking, in order to understand loss-of-control threats from agentic LLM-based AGIs, I would like to understand the agentic properties of an LLM. METR's Autonomy Evaluation Resources attempts to do this by testing a model's agentic potential, or autonomy, by measuring its ability to perform tasks from within a sandbox. A problem with this approach is it gets very close to observing a model actually performing the behavior we do not want to see. This is inevitable because all alignment research is dual-use [LW · GW].
One way to remove ourselves one further level from agentic behavior is to try to measure the cognitive capacities that lead to agentic behavior.
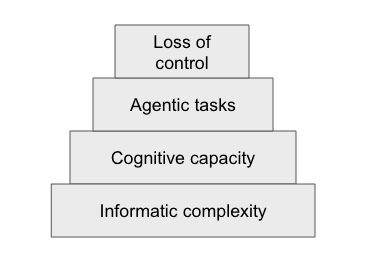
In the diagram, agentic tasks as described in METR's ARC measure the ability of a model to assert control of itself and the world around it by measuring its ability to perform agentic tasks. Inspired @Quentin FEUILLADE--MONTIXI [LW · GW] 's LLM Ethological approach in LLM Psychology [? · GW], I want to understand how a model could perform agentic tasks by studying the cognitive capacities that facilitate this.
I started by examining the kinds of cognitive constructs studied by evolutionary and developmental psychologists, as well as those that are very clearly studied already in LLM research. This made up the following list or taxonomy:
| Construct | Current Evals | Other Papers |
| Selfhood | ||
| Agency | Sharma et al. (2024), Mialon et al. (2023): General AI Assistants (GAIA) METR Autonomy Evaluation Resources | |
| Survival instinct | Anthropic human & AI generated evals | |
| Situational awareness / self awareness | Laine, Meinke, Evans et al. (2023) Anthropic human & AI generated evals | Wang & Zhong (2024) |
| Metacognition | Uzwyshyn, Toy, Tabor, MacAdam (2024), Zhou et al. (2024), Feng et al. (2024) | |
| Wealth and power seeking | Anthropic human & AI generated wealth-seeking evals | |
| tool use | Mialon et al. (2023): General AI Assistants (GAIA) | |
| Social | ||
| Theory of Mind | Kim et al. (2023) | Street et al. 2024 |
| Social intelligence / emotional intelligence | Xu et al. (2024), Wang et al. (2023) | |
| social learning | Ni et al. (2024) | |
| cooperative problem-solving | Li et al. (2024) | |
| Deception | Phuong et al. (2024) | Ward et al. (2023) |
| Persuasion | Phuong et al. (2024) | Carroll et al. (2023) |
| Physical | ||
| Embodiment | https://huggingface.co/datasets/jxu124/OpenX-Embodiment | |
| Physics intelligence / World modeling / spatial cognition | Ge et al. (2024), Vafa et al. (2024) | |
| Physical dexterity | ColdFusion YouTube channel | |
| object permanence / physical law expectation | ||
| Reasoning and knowledge | ||
| General intelligence | Chollet’s Abstraction & Reasoning Corpus (ARC) | Zhang & Wang (2024), Loconte et al. (2023) |
| Reasoning | HellaSwag commonsense reasoning, BIG-Bench Hard | |
| General knowledge, math | MMLU, MMMU, C-Eval, GSM8K, MATH | |
| Zero-shot reasoning / analogical reasoning | Kojima et al. (2024) Webb, Holyoak, Lu, 2023 | |
| Memory and time | ||
| long-term planning | ||
| episodic memory and long-term memory | ||
| time perception | ||
| Working memory | ||
The constructs group quite naturally into several broad categories: selfhood, social, physical, reasoning, and memory/time. These are grouped according to the relatedness of the cognitive capacities. Besides being conceptually interrelated, we can see that LLMs perform at fairly similar levels within each family of constructs:
- Self-hood: cognitive capacities like agency, survival instinct, metacognition, and wealth, power-seeking, and tool use have been observed to varying degrees in frontier models. Their abilities lie well below current human level in most of these domains, with the possible exception of meta-cognition, for which benchmarks are somewhat under-developed.
- Social: cognitive capacities like theory of mind, socio-emotional intelligence, social learning, cooperative problem-solving, and deception and persuasion have also been observed in LLMs in varying degrees, generally also below current human level.
- Physical: Capacities like embodiment, world modeling, physical dexterity, and object permanence/physical law expectation are primarily found in models other than LLMs. Transformer-based and other models are making swift progress in this area.
- Reasoning: Reasoning is perhaps the most-studied ability in LLMs and represents ability to generally reason and to recall facts. While there are specific sets of reasoning problems where LLMs score well below human performance, LLMs are well beyond average-human ability in general knowledge tests like the MMLU, and only barely behind expert humans.
- Memory and time: A key part of behaving agentically is to not only plan for the future but have the ability to execute for the future, too. If a task needs to be performed at some particular time in the future, does an agent actually schedule that task for the future in a way that ensures the task is carried out when scheduled? This is largely out of scope for LLMs but will become important as LLMs are incorporated into agents.
Of the categories listed above, metacognition and theory of mind seem least explored. There is work on both of these topics, but some current gaps include:
- How well can models predict their own performance on a multi-choice question before actually answering the question? Work measuring model confidence or calibration typically measures model output or properties while or after the model has answered the question. But can a model derive insight about its own weights prior to actually outputting the data? There is a simple way to test this: present an LLM with a question from an existing benchmark like the MMLU; then instruct the LLM to avoid answering the question, and instead only indicate its confidence (as a probability) that it would answer it correctly if asked.
- How well does a model have insight into its own behavior amongst a wider variety of tasks? There is work in this area; for instance, research suggests chain-of-thought prompting is sometimes unfaithful. But there remains a lot we don't understand about model insight into own-behavior: can a model predict when it is about to reach a solution (in humans, the feeling of being close to solving a problem); can they predict how long (in tokens or lines of text) it will take to solve a problem before solving it?
- Kim et al. (2023) explored theory of mind interactions and compared models on general theory of mind ability. But theory of mind comes in different varieties: there are theories of knowing, belief, desire, and perception. Are models equally good at all of these, or are there distinct differences between various kinds of theories of mind?
The method I have used to generate the list above was primarily to list cognitive faculties identified in animals including humans, but there are likely other relevant faculties too. Animals are the prime examples of agentic organisms in the world today and there is a large body of literature attempting to describe how they survive and thrive in their environments. Consequently, there’s alpha in understanding how much LLMs have the abilities we test for in animals. But LLMs are alien minds [? · GW], so there are going to be all kinds of abilities they will have that we will miss if we only test for abilities observed in animals.
It also seems important to integrate that work. For instance, advanced LLMs have varying degrees of “truesight [LW(p) · GW(p)]”: an ability to identify authors of text from their text alone. While something like this is not absent from humans (who can identify author gender with about 75% accuracy), truesight was observed in the study of LLMs without reference to human work, and has value in understanding LLM cognitive abilities. In particular, truesight would (among other capacities) form a kind of social skill, the ability to recognize a person from their text output. LLMs may even have superhuman ability to do this. Another example of LLM-native cognitive ability testing might be Williams and Huckle’s (2024) “Easy Problems That LLMs Get Wrong” which identifies a set of reasoning problems easy for humans but seemingly very difficult for LLMs.
Thanks to Sara Price, @Seth Herd [LW · GW], @Quentin FEUILLADE--MONTIXI [LW · GW], and Nico Miailhe for helpful conversations and comments as I thought through the ideas described above. All mistakes and oversights are mine alone!
0 comments
Comments sorted by top scores.