Durkon, an open-source tool for Inherently Interpretable Modelling
post by abstractapplic · 2022-12-24T01:49:58.684Z · LW · GW · 0 commentsContents
Motivation It’s time to Duel! Hang on, how is this an improvement over InterpretML? Parallel modelling In Conclusion Theoretically Practically None No comments
or, what abstractapplic has been tinkering with for the past two years, and how it can be applied to fictional card games
Motivation
Interpretability of ML models is important. If people don’t understand how a model makes its predictions, they will be (justifiably!) unwilling to use those predictions for anything that matters, especially when the costs of failure are great[1].
LessWrong talks a lot about this in the context of Neural Nets and AIs, but the problem remains present on a much lower level. If you want to model a system with interactions between features[2] and/or nonlinearities in feature effects[3] (i.e. any real-world system), linear regression won’t be sufficient, but more complex models like Random Forests can’t explain themselves in ways humans can understand.
There are some tools and tricks which aim to get only-slightly-worse model performance vs black-box models while remaining inherently human-interpretable: Segmented Linear Regression, Microsoft’s InterpretML package, Dr. Cynthia Rudin’s entire career, and “just build it by hand in Excel lol”. To this list, I add my own creation, Durkon[4].
It’s time to Duel!
To give you a sense of how Durkon works, I’m going to use one of aphyer’s D&D.Sci games [LW · GW], and demonstrate how my library works by (re)assuming the role of someone trying to win this challenge. To give a brief summary (spoilers for that game from this point on, btw): you need to pick a deck for a card game where you don’t know the rules, but do have a record of which decks won and lost a list of previous games.
For simplicity, let’s say I already figured out the game is mostly about synergy within your own deck instead of counters to your opponents’ cards, but haven’t progressed further than that. So I’m going to train a model which predicts probability of success from the count of each card type in the deck.
Durkon is mostly built for regression problems, but can do binary classification tasks as well. I run the “combined ratio” model-building functions, and get back a bunch of Partial Dependency Plots that look like this:
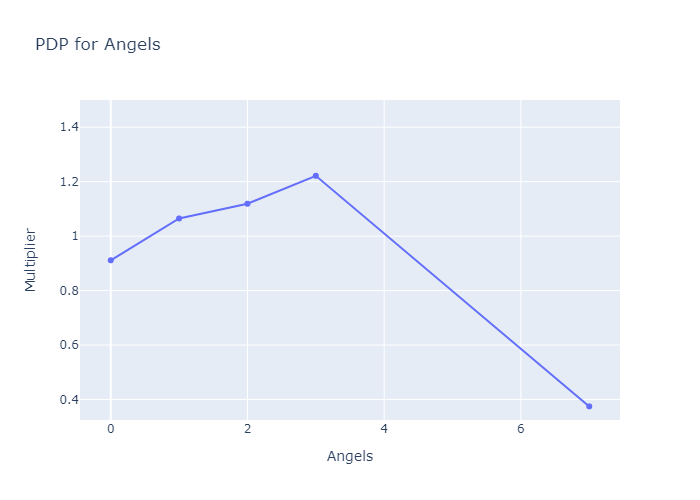
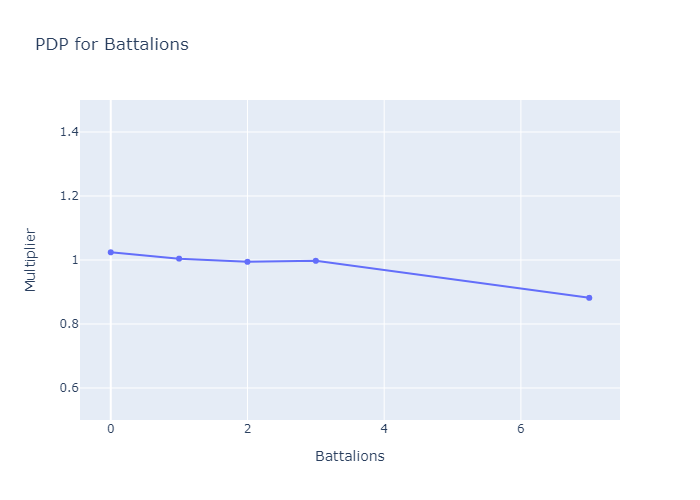
Let’s unpack this. Every deck has X:1 odds of success. When making predictions, the model starts with a default/average value for X (in this situation it's ~1 since the games are fair), then multiplies it (or does other things to it, but in this case we’re multiplying) for every feature. So if the above two graphs were the only ones, and our deck had 2 Angels and 4 Battalions, the model would predict (1*1.12*0.97):1 odds, or a ~52% chance of victory. Qualitatively, the graphs imply that having too many or too few Angels greatly diminishes your chances of success; that the sweet spot for Angels is about 3; and that it's much less punishing to have the wrong number of Battalions.
To emphasize a point: unlike with most modelling/visualization paradigms, the graphs do not describe the model post-hoc. They are the model. Every effect of every feature can be fully explained, justified, and interrogated by stakeholders, who don’t need any math concepts more complicated than “ratio” and “multiply” to do so[5].
Once I have a model, I can run built-in interaction-hunting code, and get back an ordered list of interactions between features which the model didn't catch; I can then add these to the model and refit. Resulting graphs look like this:
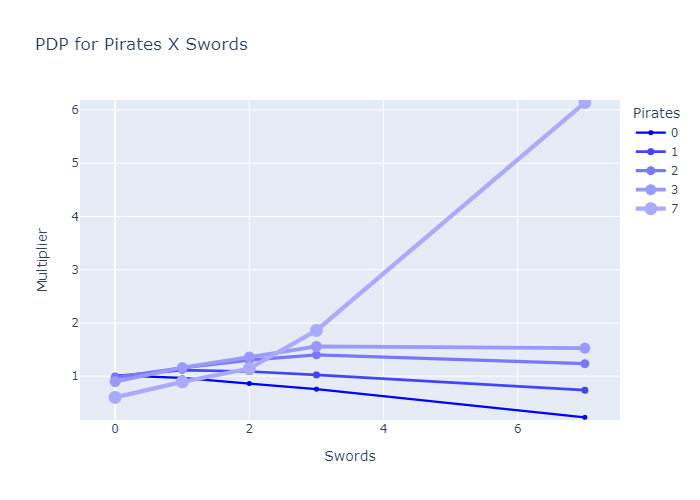
The performance is a step up from linear models, though it doesn’t beat my best attempts to use XGBoost (a popular algorithm for producing black-box models) on the same problem.
| Model | GINI on outsample (higher = better) |
| Durkon model | 0.05838 |
| Durkon model with two best interactions | 0.07535 |
| XGBoost model | 0.10480 |
Hang on, how is this an improvement over InterpretML?
“But wait!”, I hear you cry. “Can’t you get roughly the same kind of output from InterpretML? And if so, isn’t your contribution kind of redundant?”
Dear Reader, I commend your implausible dedication to following the cutting edge of inherently-interpretable modelling. But worry not: I’ll have you know that in addition to an abundance[6] of myopic and petty reasons why you might want to use Durkon over InterpretML, I also have a good one. I’ve been slow-rolling you here: the unique selling point of Durkon versus its competitors is . . .
Parallel modelling
. . . which is a fancy way of saying “fitting more than one model at once”. There are a few ways to do this – I once handled a real-world business problem [LW · GW] by simultaneously fitting a model alongside a model predicting the first model’s error – but the one I use most frequently is just “fit two or more models such that you predict by adding their output”. So instead of producing X:1 success odds, models produce (X1+X2):1 success odds, where X1 and X2 are the outputs of separate submodels.
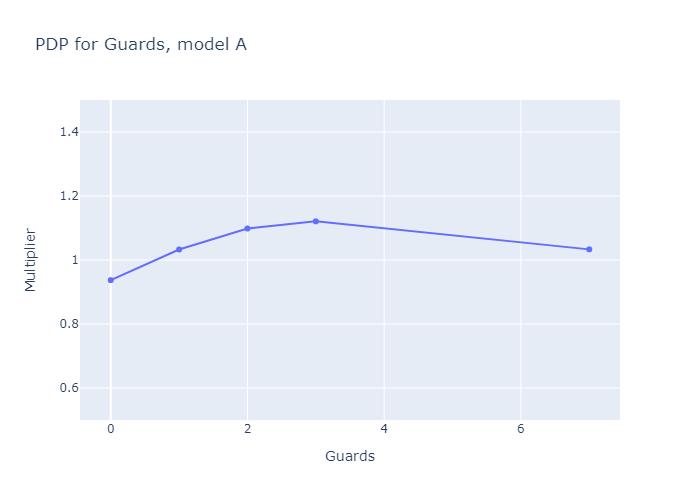
When I fit Durkon with N=2, no interactions, and some commonsense hyperparameters, I get graphs that look like this. Model B represents a strategy based around quickly deploying low-level Evil creatures like Pirates and Hooligans, equipping them with powerful Swords, and using Angels' special abilities to grease the wheels; Model A, the larger submodel, represents every other strategy.
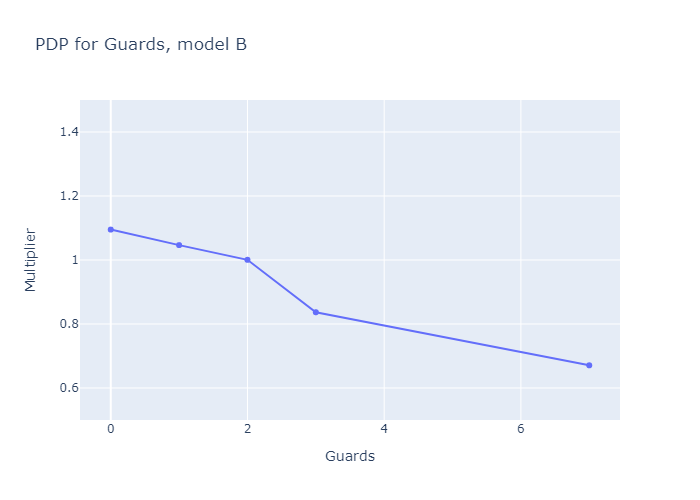
If we set N=3, we get three submodels, which match the three deck archetypes aphyer defines in his end-of-game wrapup post [LW(p) · GW(p)]: submodels A, B and C are “Lotus Ramp”, “Sword Aggro” and “Good Tribal” respectively.
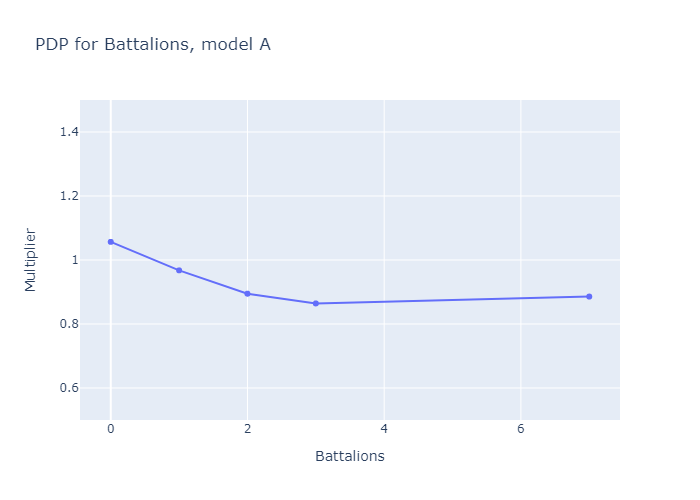
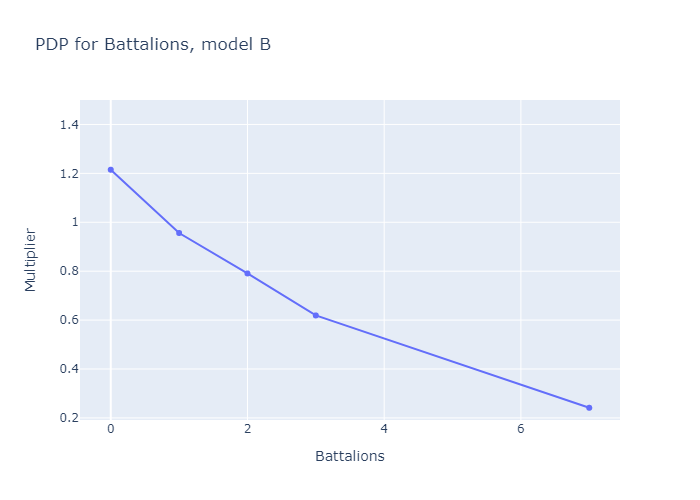
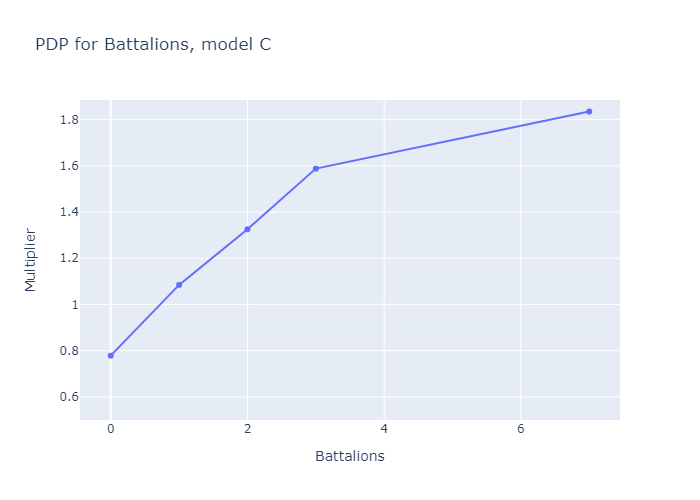
What if we try N=4? Improvement levels off sharply here, indicating that a fourth submodel is mostly redundant, but it still moves my performance metric from 0.09277 to 0.09586. It also facilitates a novel discovery: that you can get functional Good Tribal decks by using Guards and Knights to support your Battalions, or you can use a combination of Lotuses, Angels and Vigilantes to deploy Battalions quicker and (slightly less effectively) achieve the same goal.
In Conclusion
| Model | GINI on outsample (higher = better) |
| Durkon model | 0.05838 |
| Durkon model with two best interactions | 0.07535 |
| Durkon model, N=2 | 0.07845 |
| Durkon model, N=3 | 0.09277 |
| Durkon model, N=4 | 0.09586 |
| XGBoost model | 0.10480 |
Theoretically
It is possible to automatically produce inherently-interpretable models with performance which approximates that of typical black-box models. One way to narrow the performance gap[7] is by fitting multiple models in parallel, especially if the system being modelled is naturally amenable to its complexity being expressed that way[8]. This also allows qualitative insight into the nature of the system, as with the sudden levelling-off of performance past N=3 showing that it makes sense to conceptualize the game as having three deck archetypes.
Practically
Durkon exists, and does some cool stuff. It’s open-source, minimally dependent on other libraries, and as close to public domain as I could manage: you can use it for personal, academic or commercial projects, with or without attribution. The public-facing documentation is essentially nonexistent (I’m sorry to say you just finished reading most of it) since the only current users are me and one of my clients, but I think the default script and the repository for this demo should be good enough starting points.
If you want help using it, feel free to DM me: I’ll support sufficiently straightforward / charitable / interesting endeavours for free, and charge only a small[9] fee for work matching none of those descriptors.
- ^
I confess to a faint, distant hope: that improved/popularized legible modelling tech will empower regulators to demand legible modelling in more industries, which will motivate the further improvement/popularization of legible modelling, forming a virtuous cycle which differentially slows the development of hard-to-control AI and accelerates the development of human ability to understand it. That said, my main motivation is to produce models which can be easily interrogated for epistemic or moral error, and which risk-averse middle-managers can easily justify to other risk-averse middle-managers.
- ^
For example: when predicting career outcomes, it may be that mathematical and verbal skill only produce success for people who have both, but a simple linear model would be unable to account for this fact.
- ^
For example: when predicting mortality, it may be that the very young and the very old are both at high risk, but a simple linear model would be unable to account for this fact.
- ^
Yes, I named the pointedly-not-tree-based modelling project after a fictional character known for hating and fearing trees. Yes, I do think I'm funny. No, I will not change that opinion in the face of overwhelming evidence.
- ^
For binary classification problems where the outcome you're predicting is both rare and hard to predict - i.e. where predicted probability of the less likely outcome is consistently <<100% - you can make this even more intuitive by skipping the "and ratio it" step and just directly multiplying probabilities. (Seriously, I tried it once, no cops showed up.)
- ^
"InterpretML's core algorithm is overcomplicated and inefficient!" Okay but I don't intend to modify it, and no-one prioritizing inherent interpretability is limited by compute, so I'd default to the more mainstream approach. "Durkon produces models whose form will be familiar to anyone in the Insurance industry!" Cool but I don't work in Insurance. "I made Durkon, so I know exactly how to use it and/or extend it to fit a specific problem!" Yeah but I'm not you.
- ^
I've found that in a narrow subset of cases, Durkon models can not only match but actually outperform black-box models, by having the 'right' underlying shape and thereby making best use of limited data. But the table above isn't misleading: inherently-interpretable modelling almost always sacrifices a small-but-not-negligible amount of model performance in exchange for greatly increased legibility/reliability/justifiability.
- ^
Examples I used near the start of this project [LW · GW]: ". . . let’s say you’re predicting staff injuries caused by lions at a zoo, and bites and scratches and headbutts should all be modelled separately, but you’re only given the total injury count per lion per year. Or you’re building an insurance model predicting claims from customer data, and some of the claims are fraudulent and some aren’t, but you only know how many claims each customer made in total. Or you’re predicting human height, which can be decomposed into leg height plus torso height plus head height, but you’re only given the head-to-toe measurement."
- ^
. . . by Data Science standards, anyway.
0 comments
Comments sorted by top scores.