How I repeatedly failed to use Tobit modelling on censored data
post by abstractapplic · 2022-04-02T18:10:42.063Z · LW · GW · 8 commentsContents
In which our protagonist identifies the nature of the problem In which our protagonist selects an angle of attack In which our protagonist encounters an unexpected major issue Interlude: three alternatives In which our protagonist produces a valid proof of concept In which our protagonist encounters an unexpected Meijer issue Interlude: two more alternatives In which our protagonist contemplates gamma error In which our protagonist concludes the project None 8 comments
This is a description of my work on a data science project, lightly obfuscated and fictionalized to protect the confidentiality of the organization I handled it for (and also to make it flow better). I focus on the high-level epistemic/mathematical issues, and the lived experience of working on an intellectual problem, but gloss over the timelines and implementation details.
In which our protagonist identifies the nature of the problem
Once upon a time, I had a client who wanted to win some sealed-bid, first-price auctions[1].
Or, to be more specific, they were winning some sealed-bid, first-price auctions; what they wanted was to win more of them more cheaply. To that end, they asked me to produce a model predicting the market price for future lots. I was provided a dataset containing various details of the lots sold in past auctions, as well as the winning bid for each of them, and told to get to work.
. . . you see the issue? If not, that’s gratifying, because it took me an embarrassingly long time to notice. Let me spell it out.
The dataset told me the winning bid for each auction even if my client won that auction. In other words, building an ordinary regression model on the entire dataset would lead to them trying to outbid themselves, missing opportunities to lower the price from whatever they bid previously. Worse, I knew my modelling work would be used as the blueprint for future models, potentially leading to a feedback loop: “this type of lot has become 5% more expensive” -> “let’s increase our bid 5% to make sure we win it” -> “this type of lot has become 5% more expensive”, etc.
But the auctions my client won weren’t completely bereft of useful information: their winning bids provided an upper bound on what the market thought those lots were worth (i.e., the highest bid from a source other than my client couldn’t be more than my client’s winning bid). And ignoring those rows of data entirely would introduce selection biases, as well as limiting their ability to predict price for that subset of lots.
In which our protagonist selects an angle of attack
Maximum Likelihood Estimation is the reasoning that underpins conventional regression[2]: multiply probabilities of the responses observed to get the joint probability of everything you see, then adjust your model to maximize that quantity. Tobit modelling is the generalization of MLE to datasets where the response variable is presented as upper or lower bounds.
The problem I faced was a Tobit-shaped problem. It was, in fact, a ridiculously thoroughly blatantly Tobit-shaped problem, far more so than the problems Dr James Tobin invented his not-quite-eponymous modelling paradigm to solve.
The only publicly-available Tobit modelling code I could find was an R package which only worked for normal error distributions. This wouldn’t help me, since R doesn’t work well at the scale I was planning to operate on, and my client and I both agreed I should be using gamma error (the standard choice when modelling prices).
Fortunately, I had a modelling library which I knew inside-and-out. All I needed to do was modify it so it used a different objective function for the censored lots. Upon realizing this, I confidently told my client that - barring unexpected major issues - they could expect my solution to be ready in a week at the most.
In which our protagonist encounters an unexpected major issue
Oh, wait. Hang on. It’s not quite that simple, is it?
Conventional MLE assumes various things about the variance parameter (i.e. the thing which does the same job sigma does in the Gaussian): that the mean can be predicted without it, that it can be approximated as a constant, that its (predictable!) variation over different types of lots doesn’t need to be modelled, and that the way it will (inevitably!) vary over the course of a training run doesn’t matter. Tobit outright contradicts the first of these, and draws the rest of them into question: there’s a longstanding tradition of ignoring variance when modelling with standard MLE, but I had no reason to think I could get away with that when using Tobit.
In other words, I had to be able to fit a model predicting the mean, while simultaneously fitting another model predicting how accurate the first model was expected to be, and having each model make use of the other’s output at every step. This functionality would, of course, only be a prerequisite to the actual Tobit modelling, which would also take time and introduce potential bugs.
Faced with the enormity of this challenge, I elected to give up.
Interlude: three alternatives
Can you blame me? I saw your eyes glaze over as you read those last two sections, dear Reader; imagine what it was like for me to come up with those thoughts! Matching complex problems with complex solutions can be reasonable when all else fails, but every level of complexity is a new potential point of failure. It was time to think outside the box.
Alternative A: I felt the need to get clever because the dataset sucked. Did the client have a dataset where the response variable wasn’t censored?
Yes, they did: there was a dataset in their possession with both the highest bid and the highest bid that wasn’t theirs. Unfortunately, it was from the previous year, meaning any model built on it would be woefully out-of-date. They dismissed me using it for the actual modelling out of hand, but I did get to use it to trial solutions going forward.
Alternative B: What happens if I just . . . pretend I didn’t notice the problem? Treat the upper bounds as if they were the true prices? Obviously that would be bad, but what specific bad thing would happen, and how would it affect the client’s bottom line?
I built a model like that on the older dataset, and it worked surprisingly well: Mean Percentage Error was 11%. However, for the auctions my client won – also known as “the ones that actually matter” – it systematically predicted prices as 20% too high.
(For comparison purposes, I also tried building a model using the uncensored data to predict the uncensored data. This got 10% MPE, and systematically predicted values 8% too high on the rows where the client won an auction. That last part concerned me for a while, until I remembered the Winner’s Curse: these rows were selected after-the-fact for having a market price lower than what my client bid, which means they were selected in part for being low, which means the prediction would naturally be higher for them (if it wasn’t, that would mean something went wrong!). So really, the naïve model was ‘only’ overpredicting by 12% on those rows.)
Alternative C: The problem is the censorship, right? So what happens if we remove the censored rows before training?
The exact same thing, to the exact same extent. Removing lots selected (in part) for being priced low by the market leaves a training set with artificially high lot prices for similar lots, and a model built on that will make artificially high predictions. The fact that it had an identical 20% overprediction on wins was an ugly coincidence; it felt like being taunted.
I sighed, glared at the sky, and informed the DM he could stop railroading me now: I’d learned my lesson, and would be returning to the main quest. I shamefacedly went back to my client and told them I was still ‘doing the Tobit thing’, but it would take significantly longer than I had thought.
In which our protagonist produces a valid proof of concept
Having failed to fail, I resigned myself to success. I’d never written modelling code this speculative or complex before, so I built up to it slowly, constructing my tower of abstraction brick-by-brick.
I generated a dataset with a censored Gaussian-distributed response variable, then built a Tobit model that recovered the value of μ given the value of σ. This worked. I built another Tobit model which recovered the value of μ and σ. This worked. I generated a dataset in which the parameters for the censored Gaussian-distributed response variable depended linearly on an independent variable, then built a Tobit model that recovered the intercepts and slope coefficients for μ and σ. This, after a lot of backtracking, bughunting and elbow grease, also worked.
At this point, I was feeling pretty good. All I needed to do now was redo everything above with the gamma distribution instead of the Gaussian, then integrate it into my modelling library. I fed the relevant deviances into Wolfram Alpha[3] to get the function I’d need for gradient descent, and . . .
In which our protagonist encounters an unexpected Meijer issue
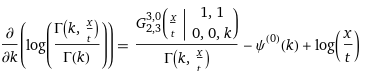
. . . what is that?
No, seriously, what the hell is that thing with the G? I’d never seen that notation before in my life. What does the vertical line mean? Why does it have two subscripts and two superscripts and six(?) arguments? Who thought this would be a good idea?
Someone called Cornelis Simon Meijer, apparently. It transpires that Meijer was tired of trigonometric functions, gamma functions, step functions and Bessel functions being different things, and invented a function which had all of them as special cases. To my unmitigated horror, it looked like this:
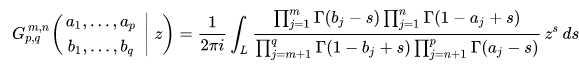
No standard Python libraries had an implementation of Meijer’s G-function. There was a non-standard library that had it, but it wasn’t optimized for runtime, which would be relevant when applying it to every row of a dataset. Also, I fundamentally didn’t get what this thing was or what it did, which meant I wouldn’t be able to fix it when it inevitably failed.
In other words, as I saw it, I had exactly two options:
- Use a random library I don’t trust to compute a function I don’t understand, let it chew up arbitrary runtime, and pray it doesn’t break.
- Spend weeks I can’t spare studying an entire field of mathematics in which I have no interest, preferably to the point of being able to efficiently implement the above monstrosity myself.
Interlude: two more alternatives
The standard Hero’s Journey places “refusal of the call” near the start of the narrative. This is because heroes are fools afflicted by the sunk cost fallacy; a reasonable protagonist contemplates giving up at every difficulty, not merely the first. Accordingly, when faced with such a choice, I took the ever-present option 0:
0. Try really hard to think of a way to avoid dealing with the problem.
To that end . . .
Alternative D: If the problem is your presence in the market, just leave the market alone for a few days. When you come back, there’ll be an unbiased list of auctions you had nothing to do with. And yes, this would give us enough data to model; these auctions happened to be very frequent, and each of them contained a lot abundance of lots.
I took this idea to the client, and they raised the reasonable point that it would require them to not bid on some auctions, which would lead to them not winning those auctions. They were quite concerned about this, because – as they patiently explained to me – winning more auctions was the main purpose of our mutual endeavour. They were also concerned that they’d have to do this every time they updated their model, which they hoped to do frequently (“Isn’t one of the benefits of Machine Learning that you get to update your models quickly whenever you suspect something might have changed?”). My insistences that “it would be so much simpler”, “you’d make more money in the long run”, and “it is mankind’s fate and privilege to suffer in the pursuit of knowledge” mostly failed to move them, but didn’t entirely fall on deaf ears, and for that matter I wasn’t wholly immune to their arguments; by the end of a long conversation, we’d both agreed that this would work, but I should exhaust every other option first.
At this point, I decided to phone a friend. I called up a fellow Data Scientist and explained the situation – in an even more abbreviated and obfuscated form than I do here – and received the delightfully sociopathic Alternative E.
Alternative E: Hold some fake auctions. Put something up for sale under an assumed name, don’t bid on it, then say “whoops, haha, changed my mind, you can keep your money” after someone else wins it. Do this enough times, and you get an unbiased dataset telling you how all the other bidders respond to different types of lot. This was more practical than it might seem: we only needed a small dataset to get good predictions, and sellers changing their minds after an auction was won was a common and unpunished occurrence.
The client reacted with a combination of amusement, horror and awe. After some deliberation, they told me in no uncertain terms that this plan would result in furious auctioneers skinning them alive, then banning their corpses from bidding in future auctions.
(On the plus side, the destructive creativity of the approach impressed them greatly, and it made Alternative D look sane by comparison.)
In which our protagonist contemplates gamma error
I mentioned before that a gamma error distribution – i.e. that thing that spawns Meijer functions when applied in conjunction with Tobit – is the standard choice when modelling price. But why is it standard? I mean, it’s not because there’s some kind of deep and meaningful connection between human assignments of value and a sum of exponential functions. As I understand it, there are three reasons:
- When parameterized the usual way, a model fit with gamma error will scale its’ variance with the mean: that is, it’ll treat the gap between a predicted price of $10k and an actual price of $11k as being about as important as the gap between a predicted price of $100k and an actual price of $110k. (Gaussian error, by contrast, will treat the latter discrepancy as 100x more important and prioritize fixing it when adjusting the model.)
- The gamma distribution assigns no probability to negative outcomes, which lines up with the natural constraint that cost>$0 in all cases.
- Gamma is a well-studied and commonly-used approach, so you can use it without thinking and you won’t run into any novel problems.
With regards to the first point . . . what if I re-parameterized the Gaussian (which I knew I could handle) so standard deviation scaled with the mean? That is, instead of μ and σ, have μ and p, where p scales with percentage error such that σ = μp? We’d technically be in violation of the second point since all Gaussians have some probability mass below 0, but if typical percentage error for a model was ~10%, a typical value of p would be <15%[4], and price<$0 would be treated as a 6-sigma event for most rows. And as for the third point . . . I figured I’d missed the boat on “avoiding novel problems” and “not thinking about things” some time ago.
I checked that the client would be okay with forgoing ‘proper’ gamma error for my weird bootleg equivalent; their response was along the lines of “fine, whatever, just get it done already”. I quickly rebuilt my toy models with this new parameterization, then integrated it into my modelling library.
In which our protagonist concludes the project
I was out of time, out of excuses, and my client was out of patience. I was also out of patience. Difficult problems can be invigorating, and awkward problems can be fun, but difficult awkward problems get old quickly. I gave myself three days to make my solution work; if it didn’t, I’d cut my losses and put my full weight behind getting the client to adopt Alternative D.
I aimed my shiny new modelling code at the older dataset, and . . .
. . . it crashed. (Of course it crashed, it was newly-written code in an unfamiliar environment. What did I expect?)
An hour of bughunting later, I’d tracked down and fixed the arcane versioning issue that had caused this. I set it running again, and . . .
. . . it predicted $0 for everything. Lovely.
Two further hours of bughunting later, I figured out that this wasn’t a bug per se: some of the probabilities relevant near the start of the run were so small Python couldn’t represent them by conventional means, which was causing a cascade of NaNs. I fit a model without giving special treatment to the censored rows, then had my new code use that as a starting point, and . . .
It worked.
I looked at the clock. It was just past noon on the first of my three days. I told the client - miraculous disbelief echoing in my voice - that something had actually gone faster than expected, then broke for lunch. As an encore, I reapplied my approach on the up-to-date data, producing a final model before the day was out.
Reader, they deployed it.
- ^
- ^
If you’ve used Ordinary Least-Squares, you’ve used MLE: minimizing the product of Gaussian probabilities for an assumed-constant value of sigma reduces to minimizing the sum of squared errors, as
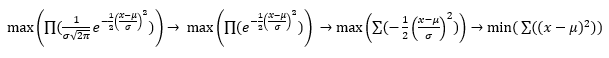
- ^
"You're telling me you use Wolfram Alpha for your differentiations?" No, dear Reader, I'm telling you I use Wolfram Alpha to check my differentiations. Sometimes I check them in advance of doing the math myself, but if I use the results for anything important I always go through the steps by hand.
- ^
Under idealized Gaussian conditions, σ = ~1.25 * MAE. (Thank you, Taleb.)
8 comments
Comments sorted by top scores.
comment by BrassLion · 2024-01-20T19:44:48.317Z · LW(p) · GW(p)
I have the luxury of reading this years after it was posted (going through the D&D.Sci archives and this was linked there), so you may actually have an answer to this question: did the model work? That is, did your client use it and save/ make money?
Replies from: abstractapplic, abstractapplic↑ comment by abstractapplic · 2024-01-21T02:11:41.329Z · LW(p) · GW(p)
Also, strong-upvoted for asking "so, with X years of hindsight, how did this pan out?" on an old post. More people should do that.
↑ comment by abstractapplic · 2024-01-21T02:10:17.422Z · LW(p) · GW(p)
Before circumstances let me answer that question, the client got bought out by a bigger company, which was (and is) a lot more cagey about both hiring contractors and sharing internal details with outsiders; last I heard, the client's absorbed remnants are still sometimes using my modelling approach, but I have no idea how much they're using it, how much they're relying on it, or to what extent it's benefiting them.
Replies from: BrassLioncomment by gwern · 2022-04-02T19:47:17.616Z · LW(p) · GW(p)
Perhaps I'm missing background here, but it seems like much of this is caused by the demand for a bespoke max-likelihood solution for exactly gamma Tobit censoring.
I'm not entirely surprised if it's not off-the-shelf, but then why not use some modeling framework? Both JAGS and Stan support censored/truncated data and also gamma distributions (I know because I've used all 4), so I would expect you could write down the censored model easily and turn the crank. Somewhat more exotically, the DL frameworks like Jax are underappreciated in how broad their autodiff support is and how they can implement stuff like SEMs no sweat. If you really need a MLE, you can either use flat priors & pretend that's the MLE, or save compute & use Stan's optimization routines to get the mode/MLE fast. (I am not familiar with PyMC or the MCMC frameworks in Python-land, so I have no idea if they could do this, but censoring/gamma aren't too exotic so I expect they can, and if not, I assume you can call out to JAGS/Stan without much difficulty.)
Since you don't mention any crazy realtime requirements, other odd requirements that JAGS/Stan couldn't model, and only needing occasional updates to finetune the model (less than every few seconds, sounds like), this sounds like it would've been adequate and way easier.
(Typo: 'Cornelis'.)
Replies from: abstractapplic↑ comment by abstractapplic · 2022-04-04T01:58:30.724Z · LW(p) · GW(p)
I did things this way because my applied stats knowledge is almost entirely self-taught, with all the random gaps in knowledge that implies. Thank you for letting me know about Stan and related techs: while it's hard to tell whether they would have been a better match for my modelling context (which had some relevant weirdnesses I can't share because confidentiality), they definitely would have made a better backup plan than "halt a key part of your organization for a few days every time you need a new model". I'll be sure to look into MCMC next time I deal with a comparable problem.
(Typo: 'Cornelis'.)
Fixed, thank you again.
comment by TLW · 2022-04-03T00:23:51.779Z · LW(p) · GW(p)
Someone called Cornellis Simon Meijer, apparently. It transpires that Meijer was tired of trigonometric functions, gamma functions, step functions and Bessel functions being different things, and invented a function which had all of them as special cases.
Is there a name for this sort of prose? It vaguely reminds me of Things I Won't Work With in a weird way.
*****
I'd be concerned that you're working in an adversarial environment, and predicting adversarial environments by modelling past behavior is, uh, suboptimal at best. (See also, every attempt to beat the stock market ever.)
Replies from: gwern