On polytopes
post by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-25T13:56:35.681Z · LW · GW · 5 commentsContents
Issues with polytopes "Holistically" understanding or enumerating polytopes is intractable. Polytopes are noisy Statistical complexity measures Humayun et al. and the trampoline analogy Relation to RLHF and "measuring toxicity" Softening the rigid structure: statistical geometry "From hard to soft" Other polytope-adjacent things I think are inherently interesting None 5 comments
[Epistemic status: slightly ranty. This is a lightly edited slack chat, and so may be lower-quality.]
I am surprised by the perennial spikes in excitement about "polytopes" and "tropical geometry on activation space" in machine learning and interpretability[1]. I'm not going to discuss tropical geometry in this post in depth (and might save it for later -- it will have to wait until I'm in a less rant-y mood[2]).
As I'll explain below, I think some interesting questions and insights are extractable by suitably weakening the "polytopes" picture, and a core question it opens up (that of "statistical geometry" -- see below) is very deep and worth studying much more systematically. However if taken directly as a study of rigid mathematical objects (polytopes) that appear as locally linear domains in neural net classification, what you are looking at is, to leading order, a geometric form of noise.
I think the interest in "really understanding" this noise is largely ascribable to two common issues in ML research:
- People wrongly assuming that high-dimensional phenomena are similar to low-dimensional phenomena
- People's love of "reading the mathematical tea leaves": extracting local information from chaotic systems that is mathematically precise and abstractly interesting, but almost wholly uninformative.
In the following sections I will:
- Quickly say why polytopes are inherently noisy.
- Roughly explain why "holistically" studying even a single polytope in a realistic system is NP hard.
- Explain why, in all the applications of polytopes I've seen so far, the relevant measure (an aggregate measure of "polytope density", best implemented imo as the "Linear Mapping Number") can be better understood as a measure of the "aggregated curvature" of the classification mapping.
- In particular, explain a reinterpretation of one paper that is sometimes thought of as a "polytope success story" by the observation that "RLHF makes things less general"
- Why I expect better differential geometry-adjacent methods to give new interesting results in these contexts.
- Some polytope-flavored questions and papers I like that can be thought of as polytope-flavored but weaken the "local"/"noisy" nature of the questions, and may lead to interesting questions beyond "statistical geometry".
Thanks to Lucas Teixeira and Eric Winsor for useful discussions and paper recommendations.
Issues with polytopes
"Holistically" understanding or enumerating polytopes is intractable.
A paper that sometimes gets used to claim that iterating over or understanding polytopes is tractable is Balestriero and LeCun's "Fast and Exact Enumeration of Deep Networks Partitions Regions". I think the paper is misleading (generally, I tend to get annoyed by the bombastic titles prevalent in ML literature). It claims it allows one to enumerate regions in a ReLU net partitions on input space in time which is "linear in the dimension (and the number of regions)". This is like saying that an algorithm that takes n log(n) time is "logarithmic in n (times a factor of n itself)", i.e., it hides the large factor which makes the problem np hard in general. It's not hard to see that enumerating regions in a neural net takes exponential time in the dimension (and there are no "niceness" conditions, short of assuming the network is fully linear, that simplify this). To see this, consider literally the simplest single-layer network: where is a d-dimensional vector and ReLU is applied coordinatewise. This network splits the input space into quadrants, i.e., two vectors x, x' are in the same region if and only if for each coordinate i, the coefficients x_i and x_i' have the same sign. Thus the number of regions is The absolute minimal amount of time to enumerate them is 2^d, i.e. exponential. This doesn't even depend on P = NP![3] There are more sophisticated questions about polytopes in high-dimensional spaces (such as counting their edges of various dimensions) which are either known or conjectured to be NP hard (and moreover, are probably NP hard for a generic polytope cut out by hyperplanes -- this is the simplest kind of polytope that shows up in neural nets, where there is only a single layer of nonlinearities). Thus getting a "full" combinatorial grasp on a single polytope in any realistic neural network, in any principled sense, is not possible.
Polytopes are noisy
This is visible in the simplest case, of one-dimensional inputs. Namely, assume you're trying to draw a graph approximating the function y = sin(x) between x = 0 and in a simple computer art program that is only able to draw straight lines. Then one way to do this is to choose a bunch of values for x uniformly at random between 0 and pi, compute the corresponding value of y, and connect them together by straight lines. Now if someone were to try to glean interesting information about the function being approximated from the lengths of the intervals between these points, this would mostly be looking at noise (if one had many samples and took suitable averages, on the other hand, there would be some information about slopes). Real neural nets that solve this via ReLUs indeed exhibit this level of randomness (and this is exacerbated, or perhaps made more interesting, by the extra randomness coming from the training datapoints -- which, note, are distinct from the breakpoints of the ReLU approximation; I think there are a few papers that look at this problem, I am aware of this being looked at in Ziming Liu et al.'s paper on scaling). Thus there's no deep structure inherent in looking in a very granular way at the shapes of a region, even in the simplest and most understandable case of nice one-dimensional functions (and this is surely much worse in the crazy high-dimensional context of real deep NNs).
Statistical complexity measures
However, if you look at bulk, i.e., statistical properties of polytopes, they will track some information, and in particular information about curvature. Indeed, if instead of the function from the previous section, you're trying to piecewise-linearly approximate a weird/crazy function, like
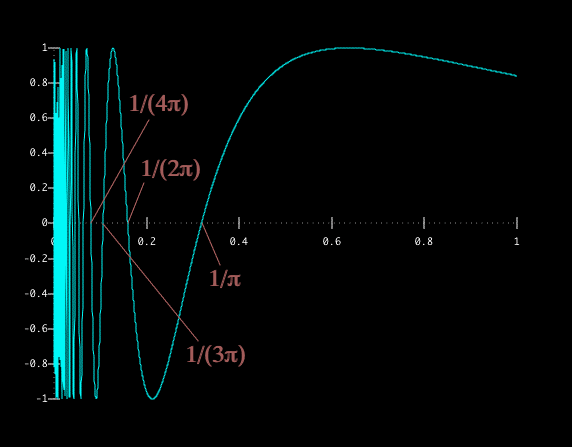
you'll see that just taking a bunch of random points doesn't have good performance, since you'll consistently be getting the wrong values for small values of x. Thus, while still being stochastic, one would expect a neural net to include more discontinuities (i.e., more and smaller polytopes) for small values of x, where the function behaves less smoothly. More generally, you expect there to be more polytopes in regions with higher curvature.
Humayun et al. and the trampoline analogy
You can try to quantify better what kind of curvature invariant this should track more precisely (and this is related to a paper I'll discuss in a bit). But first, let's look at an application, to try to intuitively understand the paper "Deep Networks Always Grok and Here is Why" (again hate the title -- it's not even remotely accurate, though I think the paper is quite nice). This paper finds that early in training, the input space of a network has high polytope count (which roughly corresponds to high curvature) near the input data points:
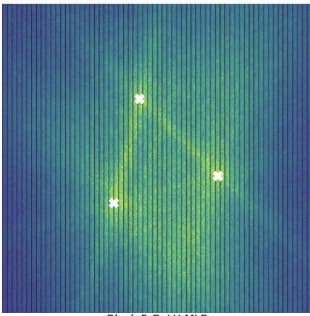
Later,[4] it has low polytope count (low curvature) at the inputs, but high polytope count near the "data boundary" between classes.
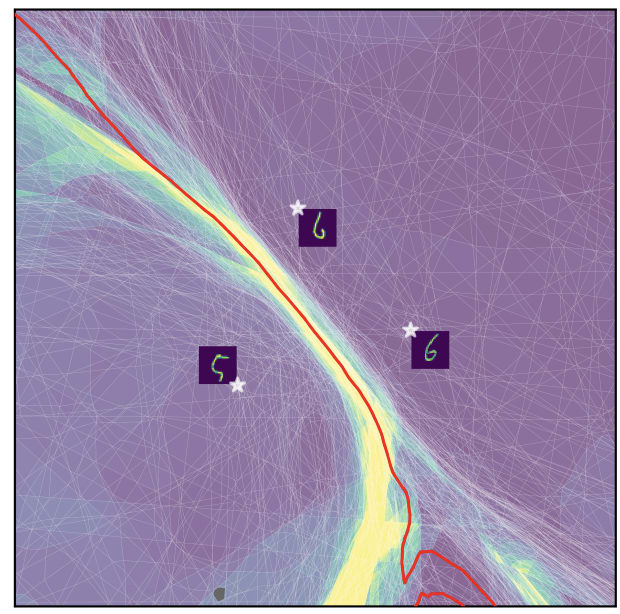
To visualize why this is reasonable, I enjoyed the following physical analogy. Say you have loosely scattered little magnets on a very loose trampoline (or on some other easily deformable elastic surface, like a thin soft rubber membrane), and glued them in place. The magnets secretly all have polarity pointing up or down, and moreover, magnets in a single region of the trampoline tend to have the same polarity -- however, you don't know what the regions are. This corresponds to a collection of inputs with a "secret" classification as either up or down.Now to find these regions, you turn on a big magnet underneath the trampoline. What happens?
- At first, each individual magnet forms an independent "bump" or "funnel" shape in the material (either up or down, depending on polarity) and so you see high-curvature regions near each magnet with little curvature elsewhere.
- As time passes the tension gets better distributed across the material, and you see the "generalized" magnetic regions (in which the little magnets are just samples) emerge as flat plateaus. The high curvature will now be at the edges of the plateaus, where the material has to deform in order to partition into the "true classification" regions.
The paper above finds exactly this predicted behavior over training, measuring polytope density instead of curvature. Note that this doesn't imply that the dynamics in the two cases is at all related/given by the same equations (and using a two-dimensional picture to capture high-dimensional behavior is dangerous -- though the paper does this as well). However, this illustrates that thinking of the information captured by polytopes as "something similar to curvature" is a reasonable analogy (and one that this paper and others make, though the trampoline cartoon is my own addition).
Relation to RLHF and "measuring toxicity"
The paper "Characterizing Large Language Model Geometry Solves Toxicity Detection and Generation" by an overlapping group of authors shows an interesting application of this type of observation. I'm going to explain my understanding of the paper and what it finds (which I think is interesting, but again easy to overinterpret), though since they don't actually describe their methods in detail and I'm generally not very familiar with RLHF, I am much less sure about this and note that I might be wrong. (edited)
The rough intuition to have in mind, made by various people in various contexts is this:
RLHF is much more like memorization than pretraining.
I'm not sure whether people think this is because RLHF is undertrained (similar to the phenomenon of overparameterized NN's being more memorize-y early in training) or whether it's because the RLHF objective is, along some relevant parameters, less general and more ad hoc than the pretraining objective and thus amounts to memorizing a bunch of edge cases (which have many examples, but are memorizational on a higher level, like the example of "learning a bunch of distinct rules" that we discussed when we were talking about variants of the memorization-generalization distinction). In any case, it seems to be the case that if you take an RLHF'd network and "do something to make it more general" -- in particular if you somehow make it smoother -- it's likely to end up less RLHF'd.
The specific experiment done in this paper (in my likely flawed understanding) shows that statistical measurements of polytope density capture the difference between pretraining and RLHF. Note that (and this part I actually am sure about), the paper does not use polytopes to find "features" of toxicity (the specific RLHF behavior they're investigating) in the linear representation sense, as is done in e.g. this later paper [the two notions have essentially nothing in common, and follow from actively different intuitions and phenomena though I was at first confused about this because of the extreme overloading of the term "feature" in the literature]. Instead of finding vectors or linear behaviors in the input space, the paper finds scalar statistical invariants of inputs similar to temperature or pressure (and it builds a separate NN model built out of a few of these). A model built out of these statistical invariants measured on the inference of a Llama model are then used to disambiguate toxic from non-toxic inputs.Note that, IMO very importantly, the geometric behavior of the inference function is measured in the RLHF'd model. So the idea of the experiment is that the authors use a collection of cases where the RLHF'd model (which has already been trained on toxicity-related behaviors) is still confused between toxic and non-toxic inputs, and they see that measuring a curvature-like invariant distinguishes between these two behaviors. If I am understanding what they're doing correctly, I think this is not surprising given what I said about the "memorization-y" nature of RLHF. Namely, going back to the "magnets on a trampoline" example, suppose that after a bit of training you have two points to which the trampoline assigns roughly the same score, i.e., which are at roughly the same, intermediate height. However one point is at this height because of something more like a memorization phenomenon, perhaps near an outlier magnet (this corresponds to the "RLHF'd" example) and the other is at this height because it's solidly in the generalization region, but just not near any of the memorized magnets (corresponding to the "toxic" example: here the toxic examples are viewed as more generalize-y, sort of "un-RLHF'd" cases where the RLHF behavior didn't fully work and the toxicity from the base model prevails).Then note that in this example, you can distinguish between these two cases (which are confusing the model, read trampoline) by measuring the curvature: if after a bit of training the function is highly curved near a value, it's likely that the classification value is mostly due to the memorization/RLHF behavior (i.e., non-toxic), whereas if there's a clear classification signal with low curvature, i.e., in a smooth region of the input space, then it's likely that it is mostly due to generalization from the base model which wasn't sufficiently strongly flagged by RLHF (i.e., the toxic example).I feel like this is enough to explain the phenomenon found in the paper (and I think this is very interesting and cool/scary nevertheless!). Note that the paper doesn't just measure the polytope density (which I analogize to curvature), and they don't address the question that follows from this model of whether just measuring this single scalar would already give a good amount of signal to distinguish RLHF-related vs. base model-related behaviors (which I predict is the case). Instead, they get a bunch of statistical parameters (correlations, averages, various minimal and maximal measurements) about the signs of neurons at some given layer (of which I think the variance measurement is the most like curvature/polytope count - note I haven't thought about this carefully, and as mentioned, wasn't able to find a very satisfying description of their experiment in the paper).
So to summarize: my understanding of the paper isn't "polytopes help efficiently classify toxicity in a base model", but rather "in a model which has been RLHF'd against toxicity, statistical measurements related to curvature help distinguish whether the classification of a particular confusing/backdoor-y datapoint is better attributed to RLHF or to the base behavior".
Softening the rigid structure: statistical geometry
What I see as the most promising approach is to view polytopes as a starting operationalization of "capturing information about the aggregated curvature and geometry of functions implemented by neural nets" -- in a "final" form this would be a picture on the "statistical geometry" in input space analogous to the geometric analysis of "information geometry" in weight space undertaken by the SLT paradigm.
"From hard to soft"
As a paper that tries to directly link "statistically smooth" polytope-type data and analyze it what I think is a more principled geometric way, let's discuss the paper "From Hard to Soft: Understanding Deep Network Nonlinearities via Vector Quantization and Statistical Inference". Note that this paper isn't actually answering the question of "what information do polytope statistics capture" that I'm asking here. In fact I'm not sure what question the paper is answering exactly, (I was somewhat confused about motivations,) but it is a very nice "let's model stuff, play with the models, and discuss the results"-style paper. Let's look at the paper more closely.
- The piecewise-linear part of the paper only considers convex piecewise linear functions (it justifies this by saying that a single ReLU is convex and everything is composed out of ReLUs; I think in the background, it's secretly assuming a rough claim that "real" neural networks have some approximate local convexity properties at least inside a single basin and in some relevant subspace of directions -- something that seems necessary to justify its analysis and seems believable in general).
- A convex piecewise-linear function is a max of linear functions. In other words, if you write down all the linear functions that form components of the piecewise-linear (PL) function f(x), then you can write (for any x) (where i ranges over the set of all components -- note that there is one component for each polytope, corresponding to what one would get by extending the linear function on the polytope to all of ).
- Next, the paper asks -- "what if instead of taking the MAX, we took something like a noisy SOFTMAX on the linear functions, and combined these into a statistical distribution, i.e., a random variable y ~ f(x), rather than a deterministic function y = f(x)?"
- As you vary temperature and noise parameters, you get a family of distributions interpolating between the max (at temperature 0) and the new "soft" distribution.
- If you then converted the soft distribution back into a function by taking the mean, you get various standard nonlinearities that appear in the NN literature.
What can we take away from this paper? First, let's look at the paper's point of view: in addition to making the (honestly, somewhat dubiously useful though cool) connection to sigmoids and swishes and the rest of the menagerie of standard nonlinearities by taking means, the paper also makes a neat observation:
- If you view the assignment "input x polytope(x)" as a hypothesis about the question "which linear component controls the behavior at x", the method of this paper allows you to incorporate uncertainty into this attribution question, and instead say that the attribution question x polytope(x) is a distribution on polytopes (given by something like a softmax), with the true polytope assigned high probability.
I think this is a potentially useful first step to making more principled the analysis of a behavior (like x polytope(x)) which is very noisy/mostly stochastic, but contains interesting statistical signal.
Zooming out, a direction this paper is pointing at is to look at the assignment from value x to the slope as stochastic (note that for a convex function, the slope specifies the polytope; this follows from convexity). The stochasticity, per the paper, is given by a "statistical vote" between the slope of the function at x and the slope at nearby point. In other words, it determines a kind of dual polytope of slopes (in the "space of slopes"), corresponding to your credence about the slope of the "true" platonic function that the model is noisily trying to approximate (as usual, this idealized function is a fiction, that depends on your choice of precision parameters, doesn't actually work, etc., but still might be expected to lead to useful predictions).
In particular, per this statistical model, you have a lot more uncertainty (i.e., competing options coming from nearby points) about slopes coming from directions where the function is highly curved rather than directions where the function is not curved. Thus you expect this model to capture refinements of curvature measurements. In the 1-dimensional output case, which I've been implicitly assuming, this is controlled by the slope and the Hessian, and more generally is a somewhat more complicated class of invariants. I wouldn't be surprised if, similar to SLT, a better model also notices higher-order (beyond Hessian) behaviors which are "singular" in some suitable sense. It is interesting that this behavior is related to the combinatorial polytope information, and I wouldn't be surprised (as mentioned above) if it has weird basis-dependencies in the neuron directions rather than being "purely geometric" (i.e., coordinate-independent)
However, my guess is that even if it has preferred basis dependencies, the behavior we're ultimately interested in should be modeled as geometric rather than combinatorial (again, similar to the SLT picture), and all polytope information is useful only insofar as it captures bits of this putative geometry. Again, I suspect that the very rough combinatorics people use in polytopes is only a first stab at this question, and a better approach would be to use some more statistical physics-adjacent tools like sampling or more sophisticated statistics of the local input-output landscape.
Other polytope-adjacent things I think are inherently interesting
To conclude, I explained that one intuition about instances where polytopes are useful is that aggregate information about polytopes should be understood as a noisy rigid approximation to statistical/geometric notion of aggregate smoothness, curvature, etc. However, there is a context where, once one again "zooms out" from the microscopic single-polytope picture to aggregate information about the neural net, one again gets (now "inherently" rather than "accidentally") combinatorial-looking polyhedral information. This is the tendency of deep neural nets to undergo "neural collapse"
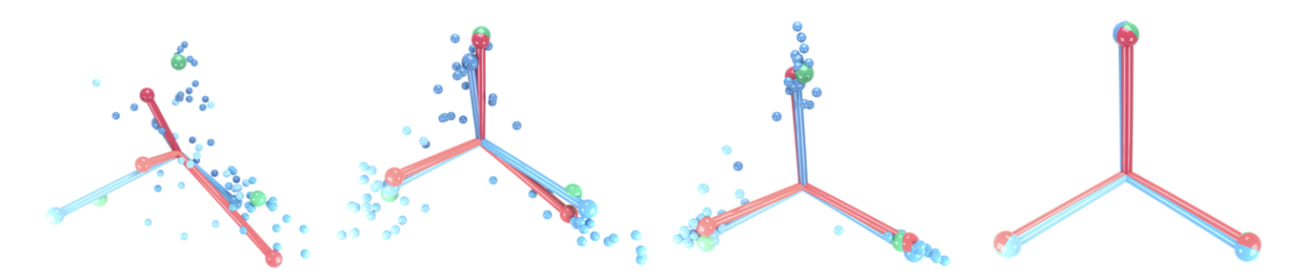
where classification functions implemented by deep NN's discontinuously and piecewise-linearly align with output classes. This is a phenomenon I don't really understand well and am interested in understanding (and which seems vaguely aligned with a class of phenomena seeing deep networks undergo interesting layer-to-layer phase transitions or stabilizing phenomena, as is in particular seen in a very different context in the "The Principles of Deep Learning Theory" book; here I'm indebted to a conversation with Stefan Heimersheim).
It's important to note that this piecewise-linear behavior is not on the level of the local polytopes of exact PL behavior of the classification function, but a much large-scale emergent PL behavior. However it seems plausible that some methods used to study the local polyhedral behavior can be applied here, in what I think would be a more principled way.
- ^
Note that the surprise is about trying to use polytopes as a tool in interpretability. Using ML to study polytopes and linear programming functions, as done e.g. in this paper, is a great idea and analyzing the resulting toy models might be very interesting. See also this cool paper that uses ML to study linear programming problems obtained from inequalities between observables in field theory, in the context of the bootstrap program.
- ^
If you want my one-paragraph take:
Tropical geometry is an interesting, mysterious and reasonable field in mathematics, used for systematically analyzing the asymptotic and "boundary" geometry of polynomial functions and solution sets in high-dimensional spaces, and related combinatorics (it's actually closely related to my graduate work and some logarithmic algebraic geometry work I did afterwards). It sometimes extends to other interesting asymptotic behaviors (like trees of genetic relatedness). The idea of applying this to partially linear functions appearing in ML is about as silly as trying to see DNA patterns in the arrangement of stars -- it's a total type mismatch. - ^
It's easy to see that a generic neural net's regions will have at least this complexity, and in fact probably much higher.
- ^
In a sense which is complicated by the high-dimensionality, but in some suitably restricted sense.
5 comments
Comments sorted by top scores.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-01-27T15:49:07.419Z · LW(p) · GW(p)
>> Tropical geometry is an interesting, mysterious and reasonable field in mathematics, used for systematically analyzing the asymptotic and "boundary" geometry of polynomial functions and solution sets in high-dimensional spaces, and related combinatorics (it's actually closely related to my graduate work and some logarithmic algebraic geometry work I did afterwards). It sometimes extends to other interesting asymptotic behaviors (like trees of genetic relatedness). The idea of applying this to partially linear functions appearing in ML is about as silly as trying to see DNA patterns in the arrangement of stars -- it's a total type mismatch.
Shots fired! :D Afaik I'm the only tropical geometry stan in alignment so let me reply to this spicy takedown here.
It's quite plausible to me that thinking in terms of polytopes, convex is a reasonable and potentially powerful lens on understanding neural networks. Despite the hyperconfident and strong language in this post it seems you agree.
Is it then unreasonable to think that tropical geometry may be relevant too? I don't think so.
Perhaps your contention is that tropical geometry is more than just thinking in terms of polytopes but specifically the algebraic geometric flavored techniques. Perhaps. I don't feel strongly about that. If it's matroids that are most relevant, rather than toric varieties and tropicalized Grassmanians then so be it.
The basic tropical perspective on deep learning begins by observing ReLU neural networks as ' tropical rational functions' , i.e. decomposing the underlying map $f$ of your ReLU neural network as a difference of convex linear functions $f=g-h$. This decomposition isn't unique, but possibly still quite useful.
As is mentioned in the text, convex-linear functions are much easier to analyze than general piece-wise linear functions so this decomposition may prove advantageous.
Another direction that may be of interest in this context is the nonsmooth calculus and especially its extension the quasi-differential calculus.
" as silly trying to see DNA patterns in the arrangement of stars -- it's a total type mismatch"
This statement feels deeply overconfident to me. Whether or not tropical geometry may be relevant to understanding real neural networks can only really be resolved by having a true domain expert ' commit to the bit' and research this deeply.
This kind of idle speculation seems not so useful to me.
comment by DavidHolmes · 2025-01-26T18:53:20.902Z · LW(p) · GW(p)
Hi Dmitry,
To me it seems not unreasonable to think that some ideas from tropical geometry might be relevant ML, for the simple reason that the functions coming up in ML with ReLU activation are PL, and people in tropical geometry have thought seriously about PL functions. Of course this does not guarantee that there is anything useful to be said!
One possible example that comes to mind in the context of your post here is the concept of polyhedral currents. As I understand it, here the notion of "density of polygons' is used as a kind of proxy for the derivative of a PL function? But I think the theory of polyhedral currents gives a much more general theory of differentiation of PL functions. Very naively, rather than just recording the locus where the function fails to be linear, one also records how much the derivative changes when crossing the walls. I learnt about this from a paper of Mihatsch: https://arxiv.org/pdf/2107.12067 but I'm certain there are older references.
I'm really a log person, I don't know the tropical world very well; sorry if what I write does not make sense!
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-26T21:52:46.234Z · LW(p) · GW(p)
Thanks for the reference, and thanks for providing an informed point of view here. I would love to have more of a debate here, and would quite like being wrong as I like tropical geometry.
First, about your concrete question:
As I understand it, here the notion of "density of polygons' is used as a kind of proxy for the derivative of a PL function?
Density is a proxy for the second derivative: indeed, the closer a function is to linear, the easier it is to approximate it by a linear function. I think a similar idea occurs in 3D graphics, in mesh optimization, where you can improve performance by reducing the number of cells in flatter domains (I don't understand this field, but this is done in this paper according to some energy curvature-related energy functional). The question of "derivative change when crossing walls" seems similar. In general, glancing at the paper you sent, it looks like polyhedral currents are a locally polynomial PL generalization of currents of ordinary functions (and it seems that there is some interesting connection made to intersection theory/analogues of Chow theory, though I don't have nearly enough background to read this part carefully). Since the purpose of PL functions in ML is to approximate some (approximately smooth, but fractally messy and stochastic) "true classification", I don't see why one wouldn't just use ordinary currents here (currents on a PL manifold can be made sense of after smoothing, or in a distribution-valued sense, etc.).
In general, I think the central crux between us is whether or not this is true:
tropical geometry might be relevant ML, for the simple reason that the functions coming up in ML with ReLU activation are PL
I'm not sure I agree with this argument. The use of PL functions is by no means central to ML theory, and is an incidental aspect of early algorithms. The most efficient activation functions for most problems tend to not be ReLUs, though the question of activation functions is often somewhat moot due to the universal approximation theorem (and the fact that, in practice, at least for shallow NNs anything implementable by one reasonable activation tends to be easily implementable, with similar macroscopic properties, by any other). So the reason that PL functions come up is that they're "good enough to approximate any function" (and also "asymptotic linearity" seems genuinely useful to avoid some explosion behaviors). But by the same token, you might expect people who think deeply about polynomial functions to be good at doing analysis because of the Stone-Weierstrass theorem.
More concretely, I think there are two core "type mismatches" between tropical geometry and the kinds of questions that appear in ML:
- Algebraic geometry in general (including tropical geometry) isn't good at dealing with deep compositions of functions, and especially approximate compositions.
- (More specific to TG): the polytopes that appear in neural nets are as I explained inherently random (the typical interpretation we have of even combinatorial algorithms like modular addition is that the PL functions produce some random sharding of some polynomial function). This is a very strange thing to consider from the point of view of a tropical geometer: like as an algebraic geometer, it's hard for me to imagine a case where "this polynomial has degree approximately 5... it might be 4 or 6, but the difference between them is small". I simply can't think of any behavior that is at all meaningful from an AG-like perspective where the questions of fan combinatorics and degrees of polynomials are replaced by questions of approximate equality.
I can see myself changing my view if I see some nontrivial concrete prediction or idea that tropical geometry can provide in this context. I think a "relaxed" form of this question (where I genuinely haven't looked at the literature) is whether tropical geometry has ever been useful (either in proving something or at least in reconceptualizing something in an interesting way) in linear programming. I think if I see a convincing affirmative answer to this relaxed question, I would be a little more sympathetic here. However, the type signature here really does seem off to me.
Replies from: alexander-gietelink-oldenziel, DavidHolmes↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-01-27T16:02:28.653Z · LW(p) · GW(p)
Like David Holmes I am not an expert in tropical geometry so I can't give the best case for why tropical geometry may be useful. Only a real expert putting in serious effort can make that case.
Let me nevertheless respond to some of your claims.
- PL functions are quite natural for many reasons. They are simple. They naturally appear as minimizers of various optimization procedures, see e.g. the discussion in section 5 here.
- Polynomials don't satisfy the padding argument and architectures based on them therefore will typically fail to have the correct simplicitity bias.
As for
1." Algebraic geometry isn't good at dealing with deep composition of functions, and especially approximate composition." I agree a typical course in algebraic geometry will not much consider composition of functions but that doesn't seem to me a strong argument for the contention that the tools of algebraic geometry are not relevant here. Certainly, more sophisticated methods beyond classical scheme theory may be important [likely involving something like PROPs] but ultimately I'm not aware of any fundamental obstruction here.
2. >>
I don't agree with the contention that algebraic geometry is somehow not suited for questions of approximation. e.g. the Weil conjectures is really an approximate/ average statement about points of curves over finite fields. The same objection you make could have been made about singularity theory before we knew about SLT.
I agree with you that a probabilistic perspective on ReLUs/ piece-wise linear functions is probably important. It doesn't seem unreasonable to me in the slightest to consider some sort of tempered posterior on the space of piecewise linear functions. I don't think this invalidates the potential of polytope-flavored thinking.
↑ comment by DavidHolmes · 2025-01-27T09:30:52.128Z · LW(p) · GW(p)
Hmm, so I'm very wary of defending tropical geometry when I know so little about it; if anyone more informed is reading please jump in! But until then, I'll have a go.
tropical geometry might be relevant ML, for the simple reason that the functions coming up in ML with ReLU activation are PL
I'm not sure I agree with this argument.
Hmm, even for a very small value of `might'? I'm not saying that someone who wants to contribute to ML needs to seriously consider learning some tropical geometry, just that if one already knows tropical geometry it's not a crazy idea to poke around a bit and see if there are applications.
The use of PL functions is by no means central to ML theory, and is an incidental aspect of early algorithms.
I agree this is an important point. I don’t actually have a good idea what activation functions people use in practise these days. Thinking about asymptotic linearity makes me think about the various papers appearing using polynomial activation functions. Do you have an opinion on this? For people in algebraic geometry it’s appealing as it generates lots of AG problems (maybe v hard), but I don’t have a good feeling as to whether it’s got anything much to do with `real life’ ML. I can link to some of the papers I’m thinking of if that’s helpful, or maybe you are already a bit familiar.
I don't see why one wouldn't just use ordinary currents here (currents on a PL manifold can be made sense of after smoothing, or in a distribution-valued sense, etc.).
I think you’re right; this paper just came to mind because I was reading it recently.
whether tropical geometry has ever been useful (either in proving something or at least in reconceptualizing something in an interesting way) in linear programming.
A little googling suggests there are some applications. This paper seems to give an application of tropical geometry to complexity of linear programming: https://inria.hal.science/hal-03505719/document and this list of conference abstracts seems to give other applications: https://him-application.uni-bonn.de/fileadmin/him/Workshops/TP3_21_WS1_Abstracts.pdf Whether they are 'convincing' I leave up to you.
1 Algebraic geometry in general (including tropical geometry) isn't good at dealing with deep compositions of functions, and especially approximate compositions.
Fair, though one might also see that as an interesting challenge. I don’t have a feeling as to whether this is for really fundamental reasons, or people haven’t tried so hard yet.
2 [….] I simply can't think of any behavior that is at all meaningful from an AG-like perspective where the questions of fan combinatorics and degrees of polynomials are replaced by questions of approximate equality.
There are plenty of cases where "high degree" is enough (Falting’s Theorem is the first thing that comes to mind, but there are lots). But I agree that "degree approximately 5" feels quite unnatural.