The Absent-Minded Driver
post by Wei Dai (Wei_Dai) · 2009-09-16T00:51:45.730Z · LW · GW · Legacy · 151 commentsContents
151 comments
This post examines an attempt by professional decision theorists to treat an example of time inconsistency, and asks why they failed to reach the solution (i.e., TDT/UDT) that this community has more or less converged upon. (Another aim is to introduce this example, which some of us may not be familiar with.) Before I begin, I should note that I don't think "people are crazy, the world is mad" (as Eliezer puts it) is a good explanation. Maybe people are crazy, but unless we can understand how and why people are crazy (or to put it more diplomatically, "make mistakes"), how can we know that we're not being crazy in the same way or making the same kind of mistakes?
The problem of the ‘‘absent-minded driver’’ was introduced by Michele Piccione and Ariel Rubinstein in their 1997 paper "On the Interpretation of Decision Problems with Imperfect Recall". But I'm going to use "The Absent-Minded Driver" by Robert J. Aumann, Sergiu Hart, and Motty Perry instead, since it's shorter and more straightforward. (Notice that the authors of this paper worked for a place called Center for the Study of Rationality, and one of them won a Nobel Prize in Economics for his work on game theory. I really don't think we want to call these people "crazy".)
Here's the problem description:
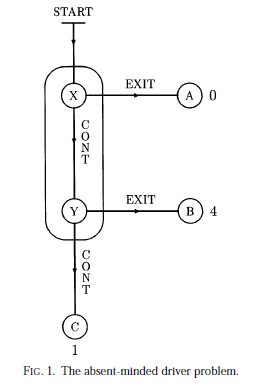
An absent-minded driver starts driving at START in Figure 1. At X he
can either EXIT and get to A (for a payoff of 0) or CONTINUE to Y. At Y he
can either EXIT and get to B (payoff 4), or CONTINUE to C (payoff 1). The
essential assumption is that he cannot distinguish between intersections X
and Y, and cannot remember whether he has already gone through one of
them.

At START, the problem seems very simple. If p is the probability of choosing CONTINUE at each intersection, then the expected payoff is p2+4(1-p)p, which is maximized at p = 2/3. Aumann et al. call this the planning-optimal decision.
The puzzle, as Piccione and Rubinstein saw it, is that once you are at an intersection, you should think that you have some probability α of being at X, and 1-α of being at Y. Your payoff for choosing CONTINUE with probability p becomes α[p2+4(1-p)p] + (1-α)[p+4(1-p)], which doesn't equal p2+4(1-p)p unless α = 1. So, once you get to an intersection, you'd choose a p that's different from the p you thought optimal at START.
Aumann et al. reject this reasoning and instead suggest a notion of action-optimality, which they argue should govern decision making at the intersections. I'm going to skip explaining its definition and how it works (read section 4 of the paper if you want to find out), and go straight to listing some of its relevant properties:
- It still involves a notion of "probability of being at X".
- It's conceptually more complicated than planning-optimality.
- Mathematically, it has the same first-order necessary conditions as planning-optimality, but different sufficient conditions.
- If mixed strategies are allowed, any choice that is planning-optimal is also action-optimal.
- A choice that is action-optimal isn't necessarily planning-optimal. (In other words, there can be several action-optimal choices, only one of which is planning-optimal.)
- If we are restricted to pure strategies (i.e., p has to be either 0 or 1) then the set of action-optimal choices in this example is empty, even though there is still a planning-optimal one (namely p=1).
In problems like this one, UDT is essentially equivalent to planning-optimality. So why did the authors propose and argue for action-optimality despite its downsides (see 2, 5, and 6 above), instead of the alternative solution of simply remembering or recomputing the planning-optimal decision at each intersection and carrying it out?
Well, the authors don't say (they never bothered to argue against it), but I'm going to venture some guesses:
- That solution is too simple and obvious, and you can't publish a paper arguing for it.
- It disregards "the probability of being at X", which intuitively ought to play a role.
- The authors were trying to figure out what is rational for human beings, and that solution seems too alien for us to accept and/or put into practice.
- The authors were not thinking in terms of an AI, which can modify itself to use whatever decision theory it wants to.
- Aumann is known for his work in game theory. The action-optimality solution looks particularly game-theory like, and perhaps appeared more natural than it really is because of his specialized knowledge base.
- The authors were trying to solve one particular case of time inconsistency. They didn't have all known instances of time/dynamic/reflective inconsistencies/paradoxes/puzzles laid out in front of them, to be solved in one fell swoop.
Taken together, these guesses perhaps suffice to explain the behavior of these professional rationalists, without needing to hypothesize that they are "crazy". Indeed, many of us are probably still not fully convinced by UDT for one or more of the above reasons.
EDIT: Here's the solution to this problem in UDT1. We start by representing the scenario using a world program:
def P(i, j):
if S(i) == "EXIT":
payoff = 0
elif S(j) == "EXIT":
payoff = 4
else:
payoff = 1
(Here we assumed that mixed strategies are allowed, so S gets a random string as input. Get rid of i and j if we want to model a situation where only pure strategies are allowed.) Then S computes that payoff at the end of P, averaged over all possible i and j, is maximized by returning "EXIT" for 1/3 of its possible inputs, and does that.
151 comments
Comments sorted by top scores.
comment by taw · 2009-09-16T02:49:44.585Z · LW(p) · GW(p)
You cannot assume any α, and choose p based on it, for α depends on p. You just introduced a time loop into your example.
Replies from: pengvado, Jonathan_Graehl↑ comment by pengvado · 2009-09-16T04:40:07.308Z · LW(p) · GW(p)
Indeed, though it doesn't have to be a time loop, just a logical dependency. Your expected payoff is α[p^2+4(1-p)p] + (1-α)[p+4(1-p)]. Since you will make the same decision both times, the only coherent state is α=1/(p+1). Thus expected payoff is (8p-6p^2)/(p+1), whose maximum is at about p=0.53. What went wrong this time? Well, while this is what you should use to answer bets about your payoff (assuming such bets are offered independently at every intersection), it is not the quantity you should maximize: it double counts the path where you visit both X and Y, which involves two instances of the decision but pays off only once.
Replies from: Eliezer_Yudkowsky, justinpombrio, casebash, Antisuji↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-16T08:12:13.229Z · LW(p) · GW(p)
Mod parents WAY up! I should've tried to solve this problem on my own, but I wasn't expecting it to be solved in the comments like that!
Awesome. I'm steadily upgrading my expected utilities of handing decision-theory problems to Less Wrong.
EDIT 2016: Wei Dai below is correct, this was my first time encountering this problem and I misunderstood the point Wei Dai was trying to make.
Replies from: ciphergoth, Wei_Dai↑ comment by Paul Crowley (ciphergoth) · 2009-09-19T15:18:18.598Z · LW(p) · GW(p)
You make it sound as if you expect to expect a higher utility in the future than you currently expect...
↑ comment by Wei Dai (Wei_Dai) · 2009-09-18T10:07:56.910Z · LW(p) · GW(p)
The parents that you referred to are now at 17 and 22 points, which seems a bit mad to me. Spotting the errors in P&R's reasoning isn't really the problem. The problem is to come up with a general decision algorithm that both works (in the sense of making the right decisions) and (if possible) makes epistemic sense.
So far, we know that UDT works but it doesn't compute or make use of "probability of being at X" so epistemically it doesn't seem very satisfying. Does TDT give the right answer when applied to this problem? If so, how? (It's not specified formally enough that I can just apply it mechanically.) Does this problem suggest any improvements or alternative algorithms?
Awesome. I'm steadily upgrading my expected utilities of handing decision-theory problems to Less Wrong.
Again, that seems to imply that the problem is solved, and I don't quite see how the parent comments have done that.
Replies from: SilasBarta, entirelyuseless↑ comment by SilasBarta · 2009-09-18T15:53:12.716Z · LW(p) · GW(p)
The problem is to come up with a general decision algorithm that both works (in the sense of making the right decisions) and (if possible) makes epistemic sense.
I presented a solution in a comment here which I think satisfies these: It gives the right answer and consistently handles the case of "partial knowledge" about one's intersection, and correctly characterizes your epistemic condition in the absent-minded case.
↑ comment by entirelyuseless · 2017-07-02T00:32:24.724Z · LW(p) · GW(p)
I don't see why the problem is not solved. The probability of being at X depends directly on how I am deciding whether to turn. So I cannot possibly use that probability to decide whether to turn; I need to decide on how I will turn first, and then I can calculate the probability of being at X. This results in the original solution.
This also shows that Eliezer was mistaken in claiming that any algorithm involving randomness can be improved by making it deterministic.
↑ comment by justinpombrio · 2017-07-01T22:14:30.991Z · LW(p) · GW(p)
And then you can correct for the double-counting. When would you like to count your chickens? It's safe to count them at X or Y.
If you count them at X, then how much payoff do you expect at the end? Relative to when you'll be counting your payoff, the relative likelihood that you are at X is 1. And the expected payoff if you are at X is p^2 + 4p(1-p). This gives a total expected payoff of P(X) E(X) = 1 (p^2 + 4p(1-p)) = p^2 + 4p(1-p).
If you count them at Y, then you much payoff do you expect at the end? Relative to when you'll be counting your payoff, the relative likelihood that you are at Y is p. And the expected payoff if you are at Y is p + 4(1-p). This gives a total expected payoff of P(Y) E(Y) = p (p + 4(1-p)) = p^2 + 4(1-p).
I'm annoyed that English requires a tense on all verbs. "You are" above should be tenseness.
EDIT: formatting
↑ comment by casebash · 2016-04-23T10:27:32.720Z · LW(p) · GW(p)
One way to describe this is to note that choosing the action that maximises the expectation of value is not the same as choosing that action that can be expected to produce the most value. So choosing p=0.53 maximises our expectations, not our expectation of production of value.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2018-06-22T13:50:19.759Z · LW(p) · GW(p)
Doesn't seem to want to let me edit the comment above, but I could have explained this clearer. The figure (8p-6p^2)/(p+1) is actually a weighted mean of Ex and Ey where these are the expected values at X and Y respectively. Specifically, this value is:
(1*Ex+p*Ey)/(1+p)
Now, the expected value calculated from the planning optimal decision which is just Ex. We shouldn't be surprised that the weighted mean is quite a different value.
↑ comment by Antisuji · 2009-09-16T18:32:41.495Z · LW(p) · GW(p)
Since you will make the same decision both times, the only coherent state is α=1/(p+1).
I'm curious how you arrived at this. Shouldn't it be α = (1/2)p + (1 - p) = 1 - p/2? (The other implies that you are a thirder in the Sleeping Beauty Problem -- didn't Nick Bostrum have the last word on that one?) The payoff becomes α[p^2+4p(1-p)] + (1-α)[p+4(1-p)] = (1 - p/2)(4p - 3p^2) + (p/2)(4 - 3p) = 6p - (13/2)p^2 + (3/2)p^3, which has a (local) maximum around p = 0.577.
The conclusion remains the same, of course.
Replies from: PhilGoetz, pengvado↑ comment by PhilGoetz · 2009-09-20T07:52:00.287Z · LW(p) · GW(p)
alpha = 1/(p+1) because the driver is at Y p times for every 1 time the driver is at X; so times the driver is at X / (times the driver is at X or Y) = 1 / (p+1).
The problem with pengvado's calculation isn't double counting. It purports to give an expected payoff when made at X, which doesn't count the expected payoff at Y. The problem is that it doesn't really give an expected payoff. alpha purports to be the probability that you are at X; yet the calculation must be made at X, not at Y (where alpha will clearly be wrong). This means we can't speak of a "probability of being at X"; alpha simply is 1 if we use this equation and believe it gives us an expected value.
Or look at it this way: Before you introduce alpha into the equation, you can solve it and get the actual optimal value for p. Once you introduce alpha into the equation, you guarantee that the driver will have false beliefs some of the time, because alpha = 1/(p+1), and so the driver can't have the correct alpha both at X and at Y. You have added a source of error, and will not find the optimal solution.
Replies from: casebash↑ comment by casebash · 2016-04-23T10:44:49.288Z · LW(p) · GW(p)
If you want to find the value of p that leads to the optimal decision you need to look at the impact on expected value of choosing one p or another, not just consider expected value at the end. Currently, it maximises expectations, not value created, with situations where you pass through X and Y being double counted.
↑ comment by pengvado · 2009-09-17T00:46:27.868Z · LW(p) · GW(p)
I'm a "who's offering the bet"er on Sleeping Beauty (which Bostrom has said is consistent with, though not identical to, his own model). And in this case I specified bets offered and paid separately at each intersection, which corresponds to the thirder conclusion.
↑ comment by Jonathan_Graehl · 2009-09-17T00:05:50.217Z · LW(p) · GW(p)
The paper covered that, but good point.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-16T07:41:57.536Z · LW(p) · GW(p)
There's an old story about a motorist who gets a flat tire next to a mental hospital. He goes over to change the tire, putting the lug nuts into the wheel cap... and sees that one of the patients is staring at him from behind the fence. Rattled, he steps on the wheel cap, and the lug nuts go into the storm sewer.
The motorist is staring, disheartened, at the sewer drain, when the patient speaks up from behind the fence: "Take one lug nut off each of the other wheels, and use those to keep on the spare tire until you get home."
"That's brilliant!" says the motorist. "What are you doing in a mental hospital?"
"I'm here because I'm crazy," says the patient, "not because I'm stupid."
Robert Aumann, Nobel laureate, is an Orthodox Jew. And Isaac Newton wasted a lot of his life on Christian mysticism. I don't think theists, or Nobel laureate physicists who don't accept MWI, are stupid. I think they're crazy. There's a difference.
Remind me to post at some point about how rationalists, in a certain stage in their development, must, to progress further, get over their feeling of nervousness about leaving the pack and just break with the world once and for all.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T13:59:57.102Z · LW(p) · GW(p)
If crazy people can nevertheless reach brilliant and correct solutions, then in what sense is their craziness an explanation for the fact that they failed to reach some solution? I really don't see what Aumann's religiousness has to do with the question I asked in this post, not to mention that he's just one person who worked on this problem. (Google Scholar lists 171 citations for P&R's paper.)
To put it another way, if we add "Aumann is religious" to the list of possible explanations I gave, that seems to add very little, if any, additional explanatory value.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-16T19:41:27.820Z · LW(p) · GW(p)
Because crazy smart people don't consistently reach solutions. It's not surprising when they're right, but it's not surprising when they're wrong, either. There are very few people I know such that I'm surprised when they seem to get something wrong, and the key factor in that judgment is high sanity, more than high intelligence.
I'm also beginning to have a very strange thought that a reddit-derived blog system with comment upvoting and karma is just a vastly more effective way of researching decision-theory problems than publication in peer-reviewed journals.
Replies from: Christian_Szegedy, matt, CarlShulman, Douglas_Knight↑ comment by Christian_Szegedy · 2009-09-17T21:02:47.398Z · LW(p) · GW(p)
Chess World Champions are sometimes notoriously superstitious, you can still rely on the consistency of their chess moves.
Replies from: LordTC, CarlShulman, jimrandomh↑ comment by LordTC · 2010-05-05T17:33:12.851Z · LW(p) · GW(p)
They really ought to be, what's the rational value in putting the time and effort into chess to become a world champion at it.
I played it semi-seriously when I was young, but gave it up when in order to get to the next level I'd have to study more than play. Most of the people I know who were good at a competitive intellectual game dropped out of school to pursue it, because they couldn't handle studying at that level for both.
I find it rather difficult to believe that pursuing chess over school is the rationally optimal choice, so I wouldn't be remotely surprised to find that those who get to that level are irrational or superstitious when it comes to non-chess problems.
↑ comment by CarlShulman · 2009-09-17T23:21:46.885Z · LW(p) · GW(p)
Chess provides very strong objective feedback on what does and doesn't work.
Replies from: Christian_Szegedy↑ comment by Christian_Szegedy · 2009-09-18T00:52:09.643Z · LW(p) · GW(p)
... as opposed to what?
Replies from: Bo102010↑ comment by Bo102010 · 2009-09-18T02:42:32.253Z · LW(p) · GW(p)
Psychotherapy - recommended reading is Robyn Dawes' House of Cards.
Replies from: Christian_Szegedy↑ comment by Christian_Szegedy · 2009-09-18T07:32:03.356Z · LW(p) · GW(p)
Does not surprise me a bit.
OTOH it raises the question: Does believing in God makes you a less reliable priest?
↑ comment by jimrandomh · 2009-09-18T03:39:36.297Z · LW(p) · GW(p)
Chess World Champions are sometimes notoriously superstitious, you can still rely on the consistency of their chess moves.
No, you can't. In 2006, world chess champion Vladimir Kramnik accidentally left himself open to mate in one when playing against computer program Deep Fritz (http://www.chessbase.com/newsdetail.asp?newsid=3509). Even the very best individual humans are all subject to simple mistakes of types that computers simply don't ever make.
Replies from: Christian_Szegedy↑ comment by Christian_Szegedy · 2009-09-18T06:59:40.832Z · LW(p) · GW(p)
This is irrelevant. Human players make mistakes. The question is whether being superstitious makes them make more mistakes.
Replies from: taw↑ comment by taw · 2009-09-19T04:17:08.575Z · LW(p) · GW(p)
It's not just chess - here's two 9dan go players, one of them misthinking and killing his own group: http://www.youtube.com/watch?v=qt1FvPxmmfE
Such spectacular mistakes are not entirely unknown in go, even in top level title matches.
In pro-level shogi it's even worse, as illegal moves (which are instant lose) are supposedly not at all uncommon.
Replies from: Christian_Szegedy, CronoDAS↑ comment by Christian_Szegedy · 2009-09-19T04:55:57.003Z · LW(p) · GW(p)
The original question was not whether humans make mistakes (they do in every area, this is undisputed) but whether irrationality in one domain makes more unreliable in others.
Replies from: jimrandomh↑ comment by jimrandomh · 2009-09-19T13:03:33.082Z · LW(p) · GW(p)
No, the original question was whether we should be surprised when humans make mistakes, and what influences the probability of them doing so. The occasional grandmaster bluder shows that even for extremely smart humans within their field of expertise, the human mind effectively has a noise floor - ie, some minimum small probability of making stupid random decisions. Computers, on the other hand, have a much lower noise floor (and can be engineered to make it arbitrarily low).
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2009-10-05T23:25:46.223Z · LW(p) · GW(p)
You shouldn't be surprised that a chess world champion has made a mistake over the course of their entire career. However, given a specific turn, you should be surprised if the world champion made a mistake in that turn. That is, given any turn, you can rely on their making a good move on that turn. You can't rely with perfect confidence, of course, but that wasn't the claim.
↑ comment by matt · 2009-09-23T21:42:49.703Z · LW(p) · GW(p)
Surely Hanson's favorite (a market) is worth a try here. You're more raging (as he does) against the increasingly obvious inefficiency of peer reviewed journals than discovering Reddit + mods as a particularly good solution, no?.
Replies from: gwern↑ comment by gwern · 2010-01-03T15:27:41.441Z · LW(p) · GW(p)
An interesting question: is there any way to turn a karma system into a prediction market?
The obvious way to me is to weight a person's voting influence by how well their votes track the majority, but that just leads to groupthink.
The key to prediction markets, as far as I can tell, is that predictions unambiguously come true or false and so the correctness of a prediction-share can be judged without reference to the share-price (which is determined by everyone else in what could be a bubble even) - but there is no similar outside objective check on LW postings or comments, is there?
Replies from: matt↑ comment by matt · 2010-01-10T22:15:25.353Z · LW(p) · GW(p)
I'd love to do a real money prediction market. Unfortunately western governments seek to protect their citizens from the financial consequences of being wrong (except in state sponsored lotteries… those are okay), and the regulatory costs (financial plus the psychic pain of navigating bureaucracy) of setting one up are higher than the payback I expect from the exercise.
Replies from: LordTC↑ comment by LordTC · 2010-05-05T17:23:11.289Z · LW(p) · GW(p)
The UBC is able to do a non-profit elections prediction market, and it generally does better than the average of the top 5 pollsters.
The popular vote market is you pay $1 for 1 share of CON, LIB, NDP, Green, Other, and you can trade shares like a stockmarket.
The ending payout is $1 * % of popular vote that group gets.
There are other markets such as a seat market, and a majority market.
The majority market pays 50/50 if no majority is reached, and 100/0 otherwise, which makes it pretty awkward in some respects. Generally predicting a minority government the most profitable action is to try and trade for shares of the loser. This is probably the main reason its restricted to the two parties with a chance of winning one if it were the same 5 way system, trading LIB and CON for GREEN, OTHER and NDP to exploit a minority government would probably bias the results. In this case in a minority the payout would be 20/20/20/20/20, but many traders would be willing to practically throw away shares of GREEN, OTHER and NDP because they "know" those parties have a 0% chance of winning a majority. This leads to artificial devaluation and bad prediction information.
By trading 1 share of CON for 5 GREEN and 5 OTHER, you just made 10 times the money in a minority government, and that's the payoff you're looking for instead of saying that you think the combined chances of Green and Other winning a majority is 1/6th that of the conservatives winning.
Of course they still have this problem with Liberals and Conservatives where trading out of a party at a favorable rate might just be betting minority.
I think the problem with a prediction market is you need a payout mechanism, that values the shares at the close of business, for elections there is a reasonable structure.
For situations where there isn't a clear solution or termination that gets much more complicated.
↑ comment by CarlShulman · 2009-09-17T01:49:32.765Z · LW(p) · GW(p)
You should be emailing people like Adam Elga and such to invite them to participate then.
↑ comment by Douglas_Knight · 2009-09-18T01:38:11.309Z · LW(p) · GW(p)
I'm also beginning to have a very strange thought that a reddit-derived blog system with comment upvoting and karma is just a vastly more effective way of researching decision-theory problems than publication in peer-reviewed journals.
How relevant is the voting, as opposed to just the back and forth?
I think the voting does send a strong signal to people to participate (there's a lot more participation here than at OB). If this is working better than mailing lists, it may be the karma, but it may also be that it can support more volume by making it easier to ignore threads.
comment by CarlShulman · 2009-09-16T02:21:24.200Z · LW(p) · GW(p)
"one of them won a Nobel Prize in Economics for his work on game theory. I really don't think we want to call these people "crazy".)"
Aumann is a religious Orthodox Jew who has supported Bible Code research. He's brilliant and an expert, but yes, he's crazy according to local mores.
Of course, that doesn't mean we should dismiss his work. Newton spent much of his life on Christian mysticism.
Replies from: arundelo↑ comment by arundelo · 2009-09-16T03:53:22.787Z · LW(p) · GW(p)
Aumann [...] has supported Bible Code research.
Wow!
Google tells me:
The Bible code is simply a fact. [Quoted in a book published in 1997.]
and
Replies from: CronoDASResearch conducted under my own supervision failed to confirm the existence of the codes -- though it also did not establish their non-existence. So I must return to my a priori estimate, that the Codes phenomenon is improbable. [From a paper published in 2004.]
comment by PhilGoetz · 2009-09-20T07:05:56.341Z · LW(p) · GW(p)
Your payoff for choosing CONTINUE with probability p becomes α[p^2+4(1-p)p] + (1-α)[p+4(1-p)], which doesn't equal p^2+4(1-p)p unless α = 1.
No. This statement of the problem pretends to represent the computation performed by the driver at an intersection - but it really doesn't. The trouble has to do with the semantics of alpha. Alpha is not the actual probability that the driver is at point X; it's the driver's estimate of that probability. The driver knows ahead of time that he's going to make the same calculation again at intersection Y, using the same value of alpha, which will be wrong. Therefore, he can't pretend that the actual payoff is alpha x (payoff if I am at X) + (1-alpha) x (payoff if I am at Y). Half the time, that payoff calculation will be wrong.
Perhaps a clearer way of stating this, is that the driver, being stateless, must believe P(I am at X) to be the same at both intersections. If you allow the driver to use alpha=.7 when at X, and alpha=.3 when at Y, then you've given the driver information, and it isn't the same problem anymore. If you allow the driver to use alpha=.7 when at X, and alpha=.7 again when at Y, then the driver at X is going to make a decision using the information that he's probably at X and should continue ahead, without taking into account that he's going to make a bad decision at Y because he will be computing with faulty information. That's not an alternative logic; it's just wrong.
The "correct" value for alpha is actually 1/(p+1), for those of us outside the problem; the driver is at Y p times for every 1 time he's at X, so he's at X 1 out of p+1 times. But to the driver, who is inside the problem, there is no correct value of alpha to use at both X and Y. This means that if the driver introduces alpha into his calculations, he is knowingly introducing error. The driver will be using bad information at at least one of X and Y. This means that the answer arrived at must be wrong at at least either X or Y. Since the correct answer is the same in both places, the answer arrived at must be wrong in both places. Using alpha simply adds a source of guaranteed error, and prevents finding the optimal solution.
Does the driver at each intersection have the expected payoff alpha x [p^2+4(1-p)p] + (1-alpha)*[p+4(1-p)] at each intersection? No; at X he has the actual expected payoff p^2+4(1-p)p, and at Y he has the expected payoff p+4(1-p). But he only gets to Y p/1 of the time. The other 1-p of the time, he's parked at A. So, if you want him to make a computation at each intersection, he maximizes the expected value averaging together the times he is at X and Y, knowing he is at Y p times for every one time he is at X:
p^2+4(1-p)p + p[p+4(1-p)] = 2p[p+4(1-p)]
And he comes up with p = 2/3.
There's just no semantically meaningful way to inject the alpha into the equation.
Replies from: pengvado, SilasBarta↑ comment by pengvado · 2009-09-21T03:13:58.566Z · LW(p) · GW(p)
Alpha is not the actual probability that the driver is at point X; it's the driver's estimate of that probability.
What do you mean by probability, if not "someone's estimate of something-or-other"?
But to the driver, who is inside the problem, there is no correct value of alpha to use at both X and Y.
There's also no correct value of p to use both when you'll continue and when you won't. But that doesn't mean you should omit p from the calculation.
This means that the answer arrived at must be wrong at at least either X or Y. Since the correct answer is the same in both places, the answer arrived at must be wrong in both places.
The driver is computing an expectation. A value of an expectation can be wrong for X, and wrong for Y, and right for the union of X and Y.
(I agree, of course, that the formula involving alpha isn't the right computation for the original problem. But that's separate from whether it's computing something interesting.)
↑ comment by SilasBarta · 2009-09-23T21:30:31.161Z · LW(p) · GW(p)
That's a very good explanation. I tried to generalize the problem to the case of partial additional knowledge about one's intersection, and I invite you to take a look at it to see if it makes the same kind of error. For the case of "ignorance about one's intersection", my solution yields "continue with probability 2/3 at any intersection", just the same as everyone else, and it does so by introducing the parameter r for "probability of guessing intersection correctly". In the problem as stated, r=1/2.
comment by gwern · 2010-08-11T11:46:47.395Z · LW(p) · GW(p)
then the expected payoff is p^2^+4(1-p)p
For anyone whose eyes glazed over and couldn't see how this was derived:
There are 3 possible outcomes:
- you miss both turns
The probability of missing both turns for a p is p*p (2 turns, the same p each time), and the reward is 1. Expected utility is probability*reward, so 2*p*1. Which is just 2*p or p^2 - you make the second turn.
The probability of making the second turn is the probability of missing the first turn and making the second. Since p is for a binary choice, there's only one other probability, q, of missing the turn; by definition all probabilities add to 1, so p+q=1, or q=1-p. So, we have our q*p (for the missed and taken turn), and our reward of 4. As above, the expected utility is q*p*4, and substituting for q gives us (1-p)*p*4, or rearranging, 4*(1-p)*p. - or, you make the first turn
The probability of making the first turn is just p-1 as before, and the reward is 0. So the expected utility is (p-1)*0 or just 0.
Our 3 possibilities are exhaustive, so we just add them together:
p^2 + 0 + 4*(1-p)*p
0 drops out, leaving us with the final result given in the article:
Replies from: TobyBartelsp^2 + 4*(1-p)*p
↑ comment by TobyBartels · 2010-08-23T16:54:46.368Z · LW(p) · GW(p)
The probability of missing both turns for a p is 2*p […] Which is just 2*p or p^2
The probability of making the first turn is just p […] So the expected utility is p*0 or just 0.
In (1), instead of 2*p, you want p*p. In (2), you want 1 – p instead of p. The final results are correct, however.
Replies from: gwern↑ comment by gwern · 2010-08-24T04:19:55.406Z · LW(p) · GW(p)
- I feel kind of silly now; what was I thinking in writing '2*p or just 2*p'?
- Right, right. I had difficulty remembering whether p was the chance of making a turn or missing a turn. Good thing the multiplication by 0 makes the difference moot.
↑ comment by TobyBartels · 2010-08-24T14:51:53.760Z · LW(p) · GW(p)
Ah well, it happens.
comment by CarlShulman · 2009-09-16T16:02:11.950Z · LW(p) · GW(p)
"The authors were trying to figure out what is rational for human beings, and that solution seems too alien for us to accept and/or put into practice."
I'm not sure about that. A lot of people intuitively endorse one-boxing on Newcomb, and probably a comparable fraction would endorse the 2/3 strategy for Absent-Minded Driver.
"Well, the authors don't say (they never bothered to argue against it)"
They do mention and dismiss mystical /psychic causation, the idea that in choosing what we will do we also choose for all identical minds/algorithms
"The authors were trying to solve one particular case of time inconsistency. They didn't have all known instances of time/dynamic/reflective inconsistencies/paradoxes/puzzles laid out in front of them, to be solved in one fell swoop."
Decision theorists have a lot of experience with paradoxical-seeming results of standard causal decision theory where 'rational agents' lose in certain ways. Once that conclusion has been endorsed by the field in some cases, it's easy to dismiss further such results: "we already know rational agents lose on all sorts of seemingly easy problems, such that they would precommit/self-modify to avoid making rational decisions, so how is this further instance a reason to change the very definition of rationality?" There could be substantial path-dependence here.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T18:47:11.777Z · LW(p) · GW(p)
I'm not sure about that. A lot of people intuitively endorse one-boxing on Newcomb, and probably a comparable fraction would endorse the 2/3 strategy for Absent-Minded Driver.
Aumann et al.'s solution is also p=2/3. They just propose to use a roundabout (but perhaps more intuitive?) algorithm to compute it.
They do mention and dismiss mystical /psychic causation, the idea that in choosing what we will do we also choose for all identical minds/algorithms
That was in the context of arguing against P&R's reasoning, which leads to p=4/9.
There could be substantial path-dependence here.
Yes, and that argues for not proposing solutions until we can see the whole problem (or set of problems) and solve it all at once. Well maybe that's kind of unrealistic, so perhaps just keeping in mind the possible path-dependence and try to mitigate it.
BTW, did you know that you can quote people by using ">"? Click on the "help" link under the comment edit box for more info.
comment by samsonalva · 2010-03-26T15:58:29.854Z · LW(p) · GW(p)
Wei, the solution that makes immediate sense is the one proposed by Uzi Segal in Economic Letters, Vol 67, 2000 titled "Don't Fool Yourself to Believe You Won't Fool Yourself Again".
You find yourself at an intersection, and you have no idea whether it is X or Y. You believe that you are at intersection X with probability α. Denote by q the probability of continuing to go straight rather than taking a left. What lottery do you face? Well, if you are at Y, then EXITING will yield a payoff of 4, and CONTinuing will yield a payoff of 1. If you are at X, then EXITING will yield a payoff of 0, and CONTinuing on straight will take you to Y. However, when you do in fact reach Y you will not realize you have reached Y and not X. In other words, you realize that going straight if you are at X will mean that you will return to the same intersection dilemma. So, suppose we denote the lottery you currently face at the intersection by Z. Then the description of the lottery is Z = ( (Z, q; 0, (1-q)), α; (1, q; 4, (1-q)), 1 - α). This is a recursive lottery. The recursive structure might seem paradoxical since there are a finite number of intersections, but is simply a result of the absent-mindedness. When you are at an intersection, you realize that any action you take at the moment that will put you at an intersection will not be distinguishable from the present moment in time, and that when you contemplate your choice at this subsequent intersection, you will not have the knowledge that you had already visited an intersection, inducing this "future" you to account for the belief that the second intersection is yet to be reached. The next crucial step is to recognize that beliefs about where you are ought to be consistent with your strategy. You only ever have to make a choice when you are at an intersection, and since all choice nodes are indistinguishable from each other (from your absent-minded perspective), your strategy can only be a mixture over EXIT and CONT. Note that the only way to be at intersection Y is by having chosen CONT at intersection X. Thus, if you believe that you are at intersection X with probability α, then the probability of being at Y is the probability that you ascribed to being at X when you previously made the choice to CONT multiplied by the probability on CONTinuing, as described by your optimal strategy. That is, Prob(Y) = Prob(X) Prob(CONT). So, consistency of beliefs with your strategy requires that (1 - α) = α q. Then, the value of the lottery Z, V(Z) as a function of q is described implicitly by: V(Z) = αqV(Z) + α(1-q)(0) + (1-α)q(1) + (1-α)(1-q)4. Solving for V(Z), and using the consistent beliefs condition yields V(Z) = (1 + 3q)(1-q), and so the optimal q is 2/3, which is the same mixed strategy as you chose when you were at START.
Of course, Aumann et. al. obtain that optimality of the planning-stage choice, but the argument they make is distinct from the one presented here.
comment by Christian_Szegedy · 2009-09-16T01:39:47.669Z · LW(p) · GW(p)
I could add some groundless speculation, but my general advice would be: Ask, don't guess!
You probably won't get answers like "I wanted to publish a paper.". But I'd bet, it would be very enlightening regardless. It'd be surprising if all of them were so extremely busy that you can't approach anybody in the area. But don't settle for PhD students, go for senior professors.
Replies from: Wei_Dai, CarlShulman↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T14:27:40.505Z · LW(p) · GW(p)
Please go ahead and add your groundless speculation. (I just added a couple more of my own to the post.) I'm actually more interested in the set of plausible explanations, than the actual explanations. A possible explanation for an error can perhaps teach us something, even if it wasn't the one responsible for it in this world.
For example, "The authors were trying to solve one particular case of time inconsistency." suggests that maybe we shouldn't try to solve ethical dilemmas one at a time, but accumulate as many of them as we can without proposing any solutions, and then see if there is a single solution to all of them.
Replies from: Christian_Szegedy↑ comment by Christian_Szegedy · 2009-09-16T17:19:30.688Z · LW(p) · GW(p)
I'm actually more interested in the set of plausible explanations, than the actual explanations. A possible explanation for an error can perhaps teach us something, even if it wasn't the one responsible for it in this world.
I don't really expect you to find explanations, but you could get insights which would help you to interpret their works in the right context.
I had the experience several times that I could move from fuzzy to definite feelings over topics, just by talking to the right people.
↑ comment by CarlShulman · 2009-09-16T13:29:02.056Z · LW(p) · GW(p)
I strongly endorse this proposal.
comment by SilasBarta · 2009-09-16T14:57:58.856Z · LW(p) · GW(p)
What I'm more interested in is: doesn't the UDT/planning-optimal solution imply that injecting randomness can improve an algorithm, which is a big no-no? Because you're saying (and you're right AFAICT) that the best strategy is to randomly choose whether to continue, with a bias in favor of continuing.
Also, could someone go through the steps of how UDT generates this solution, specifically, how it brings to your attention the possibility of expressing the payoff as a function of p? (Sorry, but I'm a bit of a straggler on these decision theory posts.)
Replies from: Eliezer_Yudkowsky, orthonormal, Wei_Dai↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2009-09-16T19:45:15.041Z · LW(p) · GW(p)
imply that injecting randomness can improve an algorithm
Hm. This would actually appear to be a distinct class of cases in which randomness is "useful", but it's important to note that a simple deterministic algorithm would do better if we were allowed to remember our own past actions - i.e. this is a very special case. I should probably think about it further, but offhand, it looks like the reason for randomized-optimality is that the optimal deterministic algorithm has been prohibited in a way that makes all remaining deterministic algorithms stupid.
Replies from: Technologos, Wei_Dai, Tyrrell_McAllister↑ comment by Technologos · 2009-09-17T19:27:08.236Z · LW(p) · GW(p)
More generally, game theory often produces situations where randomization is clearly the rational strategy when you do not know with certainty the other player's action. The example given in this post is straightforwardly convertible into a game involving Nature, as many games do, where Nature plays first and puts you into one of two states; if you are in X and play Continue, Nature plays again and the game loops. The solution to that game is the same as that derived above, I believe.
The point is, for a broad class of games/decision problems where Nature has a substantial role, we might run into similar issues that can be resolved a similar way.
↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T20:34:50.756Z · LW(p) · GW(p)
I think the motivation for this problem is that memory in general is a limited resource, and a decision theory should be able to handle cases were recall is imperfect. I don't believe that there was a deliberate attempt to prohibit the optimal deterministic algorithm in order to make randomized algorithms look good.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-17T21:05:08.190Z · LW(p) · GW(p)
I don't think that resolves the issue. As I demonstrated in this comment, if you have some probabilistic knowledge of which intersection you're at, you can do better than the p=2/3 method. Specifically, as long as you have 0.0012 bits of information about which intersection you're at (i.e. assign a greater than 52% chance of guessing correctly), you're better off choosing based on what seems most likely.
However -- and this is the kicker -- that means that if you have between 0 and 0.0012 bits of information about your intersection, you're best off throwing that information away entirely and going with the method that's optimal for when you're fully forgetful. So it's still a case where throwing away information helps you.
ETA: False alarm; Wei_Dai corrects me here -- you can still use your knowledge to do better than 4/3 when your probability of guessing right is between 50% and 52.05%.
↑ comment by Tyrrell_McAllister · 2009-09-16T22:01:26.544Z · LW(p) · GW(p)
It's probably better not to think of this as a randomized algorithm. Here is a simpler example of what I mean.
Suppose you have two urns in front of you. One urn is full of N white marbles, and the other urn is empty. Your task is to take a marble out of the first urn, paint it either red or blue, place it in the second urn, and then repeat this process until the first urn is empty. Moreover, when you are done, something very close to two-thirds of the marbles in the second urn must be red.
The catch, of course, is that you have very poor short-term memory, so you can never remember how many marbles you've painted or what colors you've painted them.
The "randomized algorithm" solution would be to use a pseudo-random number generator to produce a number x between 0 and 1 for each marble, and to paint that marble red if and only if x < 2/3.
But there is a non-random way to think of that procedure. Suppose instead that, before you start painting your N marbles, you set out a box of N poker chips, of which you know (that is, have reason to be highly confident) that very nearly two-thirds are red. You then proceed to paint marbles according to the following algorithm. After taking a marble in hand, you select a poker chip non-randomly from the box, and then paint the marble the same color as that poker chip.
This is a non-random algorithm that you can use with confidence, but which requires no memory. And, as I see it, the method with the pseudo-random number generator amounts to the same thing. By deciding to use the generator, you are determining N numbers: the next N numbers that the generator will produce. Moreover, if you know how the generator is constructed, you know (that is, have reason to be highly confident) that very nearly two-thirds of those numbers will be less than 2/3. To my mind, this is functionally identical to the poker chip procedure.
Replies from: JGWeissman, SilasBarta, christopherj, Luke_A_Somers↑ comment by JGWeissman · 2009-09-16T22:21:34.217Z · LW(p) · GW(p)
This is a non-random algorithm that you can use with confidence, but which requires no memory.
You mean it does not require memory in your brain, because you implemented your memory with the poker chips. It is quite convenient they were available.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2009-09-16T22:25:06.913Z · LW(p) · GW(p)
My point is that it's no more convenient than having the pseudo-random number generator available. I maintain that the generator is implementing your memory in functionally the same sense. For example, you are effectively guaranteed not to get the same number twice, just as you are effectively guaranteed not to get the same poker chip twice.
ETA: After all, something in the generator must be keeping track of the passage of the marbles for you. Otherwise the generator would keep producing the same number over and over.
Replies from: DonGeddis, gwern, JGWeissman↑ comment by DonGeddis · 2009-09-16T23:57:33.916Z · LW(p) · GW(p)
Rather than using a PRNG (which, as you say, requires memory), you could use a source of actual randomness (e.g. quantum decay). Then you don't really have extra memory with the randomized algorithm, do you?
Replies from: JGWeissman↑ comment by JGWeissman · 2009-09-17T00:24:31.965Z · LW(p) · GW(p)
I thought of this as well, but it does not really matter because it is the ability to produce the different output in each case event that gives part of the functionality of memory, that is, the ability to distinguish between events. Granted, this is not as effective as deterministically understood memory, where you know in advance which output you get at each event. Essentially, it is memory with the drawback that you don't understand how it works to the extent that you are uncertain how it correlates with what you wanted to remember.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2014-04-05T03:59:18.594Z · LW(p) · GW(p)
Have you read this comment of mine from another branch of this conversation?
↑ comment by gwern · 2010-08-11T13:51:07.784Z · LW(p) · GW(p)
After all, something in the generator must be keeping track of the passage of the marbles for you. Otherwise the generator would keep producing the same number over and over.
Randomness 'degenerates' (perhaps by action of a malicious daemon) into non-randomness, and so it can do better and no worse than a non-random approach?
(If the environments and agents are identical down to the source of randomness, then the agent defaults to a pure strategy; but with 'genuine' randomness, random sources that are different between instances of the agent, the agent can actually implement the better mixed strategy?)
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2010-08-12T05:45:51.817Z · LW(p) · GW(p)
I'm having trouble parsing your questions. You have some sentences that end in question marks. Are you asking whether I agree with those sentences? I'm having trouble understanding the assertions made by those sentences, so I can't tell whether I agree with them (if that was what you were asking).
The claim that I was making could be summed up as follows. I described an agent using a PRNG to solve a problem involving painting marbles. The usual way to view such a solution is as
deterministic amnesiac agent PLUS randomness.
My suggestion was instead to view the solution as
deterministic amnesiac agent
PLUS
a particular kind of especially limited memory
PLUS
an algorithm that takes the contents of that memory as input and produces an output that is almost guaranteed to have a certain property.
The especially limited memory is the part of the PRNG that remembers what the next seed should be. If there weren't some kind of memory involved in the PRNG's operation, the PRNG would keep using the same seed over and over again, producing the same "random" number again and again.
The algorithm is the algorithm that the PRNG uses to turn the first seed into a sequence of pseudo-random numbers.
The certain property of that sequence is the property of having two-thirds of its terms being less than 2/3.
Replies from: gwern↑ comment by JGWeissman · 2009-09-16T22:41:36.830Z · LW(p) · GW(p)
I maintain that the generator is implementing your memory in functionally the same sense.
That is fair enough, though the reason I find scenario at all interesting is that it illustrates the utility of a random strategy under certain conditions.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2009-09-17T16:55:57.833Z · LW(p) · GW(p)
For me, finding an equivalent nonrandom strategy helps to dispel confusion.
I like your characterization above that the PRNG is "memory with the drawback that you don't understand how it works to the extent that you are uncertain how it correlates with what you wanted to remember." Another way to say it is that the PRNG gives you exactly what you need with near-certainty, while normal memory gives you extra information that happens to be useless for this problem.
What is "random" about the PRNG (the exact sequence of numbers) is extra stuff that you happen not to need. What you need from the PRNG (N numbers, of which two-thirds are less than 2/3) is not random but a near-certainty. So, although you're using a so-called pseudo-random number generator, you're really using an aspect of it that's not random in any significant sense. For this reason, I don't think that the PRNG algorithm should be called "random", any more than is the poker chip algorithm.
↑ comment by SilasBarta · 2009-09-16T22:15:53.630Z · LW(p) · GW(p)
Very clever! It is indeed true that if you forget all previous marble paintings, the best way to ensure that 2/3 get painted one color is to paint it that color with p = 2/3.
And interestingly, I can think of several examples of my own life when I've been in that situation. For example, when I'm playing Alpha Centauri, I want to make sure I have a good mix of artillery, infantry, and speeders, but it's tedious to keep track of how many I have of each, so I just pick in a roughly random way, but biased toward those that I want in higher proportions.
I'm going to see if I can map the urn/marble-painting problem back onto the absent-minded driver problem.
↑ comment by christopherj · 2014-04-04T17:43:22.165Z · LW(p) · GW(p)
If you're allowed to use external memory, why not just write down how many you painted of each color? Note that memory is different from a random number generator; for example, a random number generator can be used (imperfectly) to coordinate with a group of people with no communication, whereas memory would require communication but could give perfect results.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2014-04-05T04:03:55.489Z · LW(p) · GW(p)
Have you read this comment of mine from another branch of this conversation?
↑ comment by Luke_A_Somers · 2012-06-06T13:41:12.469Z · LW(p) · GW(p)
Take 3 marbles out of the urn. Paint one of them blue, and then the other two red. Put all three in the second urn. Repeat
Yeah, yeah - white marbles are half-medusas, so if you can see more than one you die, or something.
Replies from: Tyrrell_McAllister↑ comment by Tyrrell_McAllister · 2012-06-06T14:44:25.875Z · LW(p) · GW(p)
Taking more than one marble out of the urn at a time violates the task description. Don't fight the hypothetical!
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2012-06-07T15:03:58.430Z · LW(p) · GW(p)
... That's what the second paragraph is for...
↑ comment by orthonormal · 2009-09-16T16:41:09.699Z · LW(p) · GW(p)
Jaynes' principle is that injecting randomness shouldn't help you figure out what's true; implementing a mixed strategy of action is a different matter.
Although the distinction is a bit too fuzzy (in my head) for comfort.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-16T19:55:54.369Z · LW(p) · GW(p)
I'm concerned about more than just Jaynes's principle. Injecting noise between your decision, and what you turn out to do, shouldn't be able to help you either. Choosing "continue" 2/3 of the time is the same as "Always continue, but add a random disturbance that reverses this 1/3 of the time."
How can that addition of randomness help you?
Replies from: JGWeissman↑ comment by JGWeissman · 2009-09-16T20:06:08.814Z · LW(p) · GW(p)
The randomness helps in this case because the strategy of determining your actions by which intersection you are at is not available.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-16T20:14:59.096Z · LW(p) · GW(p)
Yes, the problem deletes the knowledge of what intersection I'm at. How does it help to further delete knowledge of what my decision is?
Replies from: JGWeissman↑ comment by JGWeissman · 2009-09-16T21:15:44.738Z · LW(p) · GW(p)
There are 3 possible sequences of actions:
- exit at the first intersection
- continue at the first intersection, exit at the second intersection
- continue at the first intersection, continue at the third intersection
The payoffs are such that sequence 2 is the best available, but, having complete knowledge of your decision and no knowledge of which intersection you are at makes sequence 2 impossible. By sacrificing that knowledge, you make available the best sequence, though you can no longer be sure you will take it. In this case, the possibility of performing the best sequence is more valuable than full knowledge of which sequence you actually perform.
Replies from: SilasBarta, SilasBarta↑ comment by SilasBarta · 2009-09-17T20:59:38.468Z · LW(p) · GW(p)
By the way, I went ahead and calculated what effect probabilistic knowledge of one's current intersection has on the payoff, so as to know the value of this knowledge. So I calculated the expected return, given that you have a probability r (with 0.5<r<=1) of correctly guessing what intersection you're in, and choose the optimal path based on whichever is most likely.
In the original problem the max payoff (under p=2/3) is 4/3. I found that to beat that, you only need r to be greater than 52.05%, barely better than chance. Alternately, that's only 0.0012 bits of the 1 bit of information contained by the knowledge of which intersection you're at! (Remember that if you have less than .0012 bits, you can just revert to the p=2/3 method from the original problem, which is better than trying to use your knowledge.)
Proof: At X, you have probability r of continuing, then at Y you have a probability r of exiting and (1-r) of continuing.
Thus, EU(r) = r(4r + (1-r) ) = r(3r+1).
Then solve for when EU(r)=4/3, the optimum in the fully ignorant case, which is at r = 0.5205.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-17T22:30:06.395Z · LW(p) · GW(p)
You made a mistake here, which is assuming that when you guess you are at X, you should choose CONTINUE with probability 1, and when you guess you are at Y, you should choose EXIT with probability 1. In fact you can improve your expected payoff using a mixed strategy, in which case you can always do better when you have more information.
Here's the math. Suppose when you are at an intersection, you get a clue that reads either 'X' or 'Y'. This clue is determined by a dice roll at START. With probability .49, you get 'X' at both intersections. With probability .49, you get 'Y' at both intersections. With probability .02, you get 'X' at the X intersection, and 'Y' at the Y intersection.
Now, at START, your decision consists of a pair of probabilities, where p is your probability to CONTINUE after seeing 'X', and q is your probability to CONTINUE after seeing 'Y'. Your expected payoff is:
.02 * (p*q + 4*(p*(1-q))) + .49 * (p*p + 4*(p*(1-p))) + .49 * (q*q + 4*(q*(1-q)))
which is maximized at p=0.680556, q=0.652778. And your expected payoff is 1.33389 which is > 4/3.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-17T23:11:22.738Z · LW(p) · GW(p)
Wow, good catch! (In any case, I had realized that if you have probability less than 52.05%, you shouldn't go with the most likely, but rather, revert the original p=2/3 method at the very least.)
The formula you gave for the mixed strategy (with coefficients .02, .49, .49) corresponds to a 51% probability of guessing right at any given light. (If the probability of guessing right is r, the coefficients should be 2r-1,1-r,1-r.) It actually raises the threshold for which choosing based on the most probable, with no other randomness, becomes the better strategy, but not by much -- just to about 52.1%, by my calculations.
So that means the threshold is 0.0013 bits instead of 0.0012 :-P
(Yeah, I did guess and check because I couldn't think of a better way on this computer.)
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-17T23:20:54.726Z · LW(p) · GW(p)
I think you might still be confused, but the nature of your confusion isn't quite clear to me. Are you saying that if r>52.1%, the best strategy is a pure one again? That's not true. See this calculation with coefficients .2, .4, .4.
ETA: Also, I think talking about this r, which is supposed to be a guess of "being at X", is unnecessarily confusing, because how that probability should be computed from a given problem statement, and whether it's meaningful at all, are under dispute. I suggest thinking in terms of what you should plan to do when you are at START.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-18T00:55:06.089Z · LW(p) · GW(p)
I think you might still be confused, but the nature of your confusion isn't quite clear to me. Are you saying that if r>52.1%, the best strategy is a pure one again? That's not true. See this calculation with coefficients .2, .4, .4.
That yields a payoff of 1.42, which is less than what the pure strategy gives in the equivalent case corresponding to .2/.4/.4, which is a 60% chance of guessing right. Since the payoff is r*(3r+1), the situation you described has a payoff of 1.68 under a pure strategy of choosing based on your best guess.
ETA: Also, I think talking about this r, which is supposed to be a guess of "being at X", is unnecessarily confusing, because how that probability should be computed from a given problem statement, and whether it's meaningful at all, are under dispute.
I specifically avoided defining r as the probability of "being at X"; r is the probability of guessing correctly (and therefore of picking the best option as if it were true), whichever signal you're at, and it's equivalent to choosing 2r-1,r-1,r-1 as the coefficients in your phrasing. The only thing possibly counterintuitive is that your ignorance maximizes at r=0.5 rather than zero. Less than 50%, and you just flip your prediction.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-18T01:08:31.124Z · LW(p) · GW(p)
Since the payoff is r*(3r+1), the situation you described has a payoff of 1.68 under a pure strategy of choosing based on your best guess.
No, it doesn't. This is what I meant by "r" being confusing. Given .2/.4/.4, if you always pick CONTINUE when you see hint 'X' and EXIT when you see hint 'Y', your expected payoff (computed at START) is actually:
.4 0 + .4 1 + .2 * 4 = 1.2.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-18T01:22:04.578Z · LW(p) · GW(p)
Incorrect. Given .2/.4/.4, you will see X 60% of the time at X, and Y 60% of the time at Y. So your payoff, computed at START, is:
.4 * 0 + .6 * (4 *.6 + .4* 1) = 1.68
You seem to be treating .2/.4/.4 as being continue-exit/exit-exit/continue-continue, which isn't the right way to look at it.
Replies from: Wei_Dai, loqi↑ comment by Wei Dai (Wei_Dai) · 2009-09-18T01:41:59.214Z · LW(p) · GW(p)
Please go back to what I wrote before (I've changed the numbers to .2/.4/.4 below):
Suppose when you are at an intersection, you get a clue that reads either 'X' or 'Y'. This clue is determined by a dice roll at START. With probability .4, you get 'X' at both intersections. With probability .4, you get 'Y' at both intersections. With probability .2, you get 'X' at the X intersection, and 'Y' at the Y intersection.
I'll go over the payoff calculation in detail, but if you're still confused after this, perhaps we should take it to private messages to avoid cluttering up the comments.
Your proposed strategy is to CONTINUE upon seeing the hint 'X' and EXIT upon seeing the hint 'Y'. With .4 probability, you'll get 'Y' at both intersections, but you EXIT upon seeing the first 'Y' so you get 0 payoff in that case. With .4 probability, you get 'X' at both intersections, so you choose CONTINUE both times and end up at C for payoff 1. With .2 probability, you get 'X' at X and 'Y' at Y, so you choose CONTINUE and then EXIT for a payoff of 4, thus:
.4 0 + .4 1 + .2 * 4 = 1.2
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-18T04:52:40.207Z · LW(p) · GW(p)
I'm not confused; I probably should have stopped you at your original derivation for the partial-knowledge case but didn't want to check your algebra. And setting up problems like these is important and tricky, so this discussion belongs here.
So, I think the problem with your setup is that you don't make the outcome space fully symmetric because you don't have an equal chance of drawing Y at X and X at Y (compared to your chance of drawing X at X and Y at Y).
To formalize it for the general case of partial knowledge, plus probabilistic knowledge given action, we need to look at four possibilities: Drawing XY, XX, YY, and YX, only the first of which is correct. If, as I defined it before, the probability of being right at any given exit is r, the corresponding probabilities are: r^2, r(1-r), r(1-r), and (1-r)(1-r).
So then I have the expected payoff as a function of p, q, and r as:
(r^2)(p*q + 4p*(1 - q)) + r(1 - r)(p^2 + 4p(1 - p)) +r(1 - r)(q^2 + 4q(1 - q)) + (1 - r)(1 - r)(p*q + 4q(1 - p))
This nicely explains the previous results:
The original problem is the case of complete ignorance, r=1/2, which has a maximum 4/3 where p and q are such that they average out to choosing "continue" at one's current intersection 2/3 of the time. (And this, I think, shows you how to correctly answer while explicitly and correctly representing your probability of being at a given intersection.)
The case of (always) continuing on (guessing) X and not continuing on (guessing) Y corresponds to p=1 and q=0, which reduces to r*(3r+1), the equation I originally had.
Furthermore, it shows how to beat the payoff of 4/3 when your r is under 52%. For 51% (the original case you looked at), the max payoff is 1.361 {p=1, q=0.306388} (don't know how to show it on Alpha, since you have to constrain p and q to 0 thru 1).
Also, it shows I was in error about the 52% threshold, and the mixed strategy actually dominates all the way up to about r = 61%, at which point of course p=1 and q has shrunk to zero (continue when you see X, exit when you see Y). This corresponds to 32 millibits, much higher than my earlier estimate of 1.3 millibits.
Interesting!
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-22T21:56:05.785Z · LW(p) · GW(p)
What a crock. I presented my reasoning clearly and showed how it seamlessly and correctly handles the various nuances of the situation, including partial knowledge. If I'm wrong, I'm wrong for a non-obvious reason, and no, Wei_Dai hasn't shown what's wrong with this specific handling of the problem.
Whoever's been modding me down on this thread, kindly explain yourself. And if that person is Wei_Dai: shame on you. Modding is not a tool for helping you win arguments.
Replies from: Z_M_Davis, orthonormal↑ comment by Z_M_Davis · 2009-09-22T23:03:43.661Z · LW(p) · GW(p)
Downvoted for complaining about being downvoted and for needless speculation about the integrity of other commenters. (Some other contributions to this thread have been upvoted.)
Replies from: SilasBarta, SilasBarta↑ comment by SilasBarta · 2009-09-22T23:09:18.576Z · LW(p) · GW(p)
I'm not complaining about being downvoted. I'm complaining about
a) being downvoted
b) on an articulate, relevant post
c) without an explanation
In the absence of any one of those, I wouldn't complain. I would love to hear where I'm wrong, because it's far from obvious. (Yes, the exchange seems tedious and repetitive, but I present new material here.)
And I wasn't speculating; I was just reminding the community of the general lameness of downvoting someone you're in an argument with, whether or not that's Wei_Dai.
Replies from: anonym, wedrifid↑ comment by anonym · 2009-09-23T03:45:45.603Z · LW(p) · GW(p)
Imagine the noise if everybody complained whenever they were downvoted and believed that all 3 of your criteria were applicable.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T04:10:41.877Z · LW(p) · GW(p)
I'm not going by my beliefs. Take yours, or the proverbial "reasonable person's" judgment. Would you or that person judge b) as being true?
Are a) and c) in dispute? Again, my concern is actually not with being downmodded (I would have dropped this long ago if it were); it's with the lack of an explanation. If no one can be bothered to respond to such a post that spells out its reasoning so clearly and claims to have solved the dilemma -- fine, but leave it alone. If you're going to make the effort, try to make sense too.
↑ comment by wedrifid · 2009-09-23T06:44:31.856Z · LW(p) · GW(p)
And I wasn't speculating; I was just reminding the community of the general lameness of downvoting someone you're in an argument with, whether or not that's Wei_Dai.
I'm far more likely to downvote someone I'm in an argument with. Mostly because I am actually reading their posts in detail and am far more likely to notice woo.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T12:12:54.376Z · LW(p) · GW(p)
Then why not just vote up your own comments? After all, you must have even more insight into those, right? It's not like you're going to be swayed by personal investment in not losing face or anything.
Yeah, I know, there's that pesky thing about how you can't upvote your own comments. Pff. There's no such thing as fair, right? Just use a different account. Sheesh.
Replies from: Vladimir_Nesov, wedrifid↑ comment by Vladimir_Nesov · 2009-09-23T20:52:38.563Z · LW(p) · GW(p)
You must be an inherently angry person. Or an evil mutant. Something like that =)
↑ comment by wedrifid · 2009-09-23T12:56:39.830Z · LW(p) · GW(p)
In cases where I believe a post of mine has been unjustly downvoted the only thing stopping me from creating another account and upvoting myself is that I just don't care enough to bother. Of course if there was any particular challenge involved in gaming the system in that way then that would perhaps be incentive enough...
↑ comment by SilasBarta · 2009-09-23T02:34:03.996Z · LW(p) · GW(p)
Okay, so far that's 3-4 people willing to mod me down, zero people willing to point out the errors in a clearly articulated post.
I'm sure we can do better than that, can't we, LW?
If it's that bad, I'm sure one of you can type the two or three sentences necessary to effortlessly demolish it.
ETA: Or not.
Replies from: Z_M_Davis↑ comment by Z_M_Davis · 2009-09-23T03:38:48.191Z · LW(p) · GW(p)
Okay, so far that's 3-4 people willing to mod me down, zero people willing to point out the errors in a clearly articulated post.
This seems like a non-sequitur to me. It's your comment of 22 September 2009 09:56:05PM that's sitting at -4; none of your clear and articulate responses to Dai have negative scores anymore.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T04:05:59.381Z · LW(p) · GW(p)
No non-sequitur. That's still, um, zero explanation for the errors in a post that resolves all the issues of the AMD problem, and still at least 4 people modding me down for requesting that a downmod for that kind of post come with some sort of explanation.
If there's a non-sequitur, it's the fact that the unjustified downmods were only corrected after I complained about them, and I got downmodded even more than before, and this sequence of events is used to justify the claim that my comments have gotten what they deserved.
Replies from: Douglas_Knight, wedrifid↑ comment by Douglas_Knight · 2009-09-23T04:41:17.186Z · LW(p) · GW(p)
1 or 2 people downmod you and you devote 6 posts to whining about it? This is a broadcast medium. Of course the 5 people who voted you down for wasting their time aren't going to explain why the first 1 or 2 people didn't like the first post.
a post that resolves all the issues of the AMD problem
It didn't say that to me. So much for articulate.
If it's oh so important, don't leave it buried at the bottom a thread of context. Write something new. Why should we care about your parameter, rather than Wei Dai's? Why should we care about any parameter?
Replies from: SilasBarta, SilasBarta↑ comment by SilasBarta · 2009-09-23T12:07:49.523Z · LW(p) · GW(p)
If it's oh so important, don't leave it buried at the bottom a thread of context.
It may surprise you to note that I linked to the comment from a very visible place in the discussion.
Why should we care about your parameter, rather than Wei Dai's? Why should we care about any parameter?
Because Wei Dai asked for how to generate a solution that makes epistemic sense, and mine was the only one that accurately incorporated the concept of "probability of being at a given intersection".
And of course, Wei_Dai saw fit to use the p q r parameters just the same.
Replies from: Douglas_Knight↑ comment by Douglas_Knight · 2009-09-23T22:57:36.490Z · LW(p) · GW(p)
If it's oh so important, don't leave it buried at the bottom a thread of context.
It may surprise you to note that I linked to the comment from a very visible place in the discussion.
Exhuming it and putting it on display doesn't solve the problem of context. People who clicked through (I speak from experience) didn't see how it did what the link said it did. It was plausible that if I reread the thread it would mean something, but my vague memory of the thread was that it went off in a boring direction.
My questions were not intended for you to answer here, yet further removed from the context where one might care about their answers. If you write something self-contained that explains why I should care about it, I'll read it.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T23:09:00.101Z · LW(p) · GW(p)
So you were interested in seeing the solution, but not looking at the context of the thread for anything that wasn't familiar? Doesn't sound like much of an interest to me. If I had repeated myself with a separate self-contained explanation, you would be whining that I'm spamming the same thing all over the place.
You weren't aware that I put a prominent link to the discussion that resolves all the thread's issues. That's okay! Really! You don't need to cover it up by acting like you knew about it all along. Wei_Dai cares about the new parameters q and r. The post I linked to explains what it accomplishes. Now, think up a new excuse.
↑ comment by SilasBarta · 2009-09-23T12:02:22.168Z · LW(p) · GW(p)
If it's oh so important, don't leave it buried at the bottom a thread of context.
It may surprise you to note that I linked to the comment from a very visible place in the discussion.
Why should we care about your parameter, rather than Wei Dai's? Why should we care about any parameter?
Because Wei Dai asked for how to generate a solution that makes epistemic sense, and mine was the only one that accurately incorporated the concept of "probability of being at a given intersection".
And of course, Wei_Dai saw fit to use the p q r parameters just the same.
↑ comment by wedrifid · 2009-09-23T06:33:28.746Z · LW(p) · GW(p)
No 'justification' necessary. 'Deserved' is irrelevant and there is no such thing as 'fair'.
If I didn't accept that then LessWrong (and most of the universe) would be downright depressing. People are (often) stupid and votes here represent a very different thing than reward for insight.
Just hold the unknown down-voters in silent contempt briefly then go along with your life. Plenty more upvotes will come. And you know, the votes that my comments receive don't seem to be all that correlated with the quality of the contributed insight. One reason for this is that the more elusive an insight is the less likely it is to agree with what people already think. This phenomenon more or less drives status assignment in academia. The significance of votes I get here rather pales in comparison.
Douglas makes a good suggestion. Want people to appreciate (or even just comprehend) what you are saying? Put in some effort to make a top level post. Express the problem, provide illustrations (verbal or otherwise) and explain your solution. You'll get all sorts of status.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T12:17:09.803Z · LW(p) · GW(p)
In the past, I took a comment seriously from you that was satire. Is this one of those, too? Sometimes it's hard to tell.
If it's serious, then my answer is that whatever "clutter" my comment here gave, it would give even more as a top level post, which probably can't give more explanation than my post already did.
By the way, just a "heads-up": I count 6+ comments from others on meta-talk, 8+ down-mods, and 0 explanations for the errors in my solution. Nice work, guys.
Replies from: Z_M_Davis, wedrifid↑ comment by Z_M_Davis · 2009-09-23T16:14:17.034Z · LW(p) · GW(p)
I count 6+ comments from others on meta-talk, 8+ down-mods, and 0 [sic] explanations for the errors in my solution. Nice work, guys.
If it is in fact the case that your complaints are legitimately judged a negative contribution, then you should expect to be downvoted and criticized on those particular comments, regardless of whether or not your solution is correct. There's nothing contradictory about simultaneously believing both that your proposed solution is correct, and that your subsequent complaints are a negative contribution.
I don't feel like taking the time to look over your solution. Maybe it's perfect. Wonderful! Spectacular! This world becomes a little brighter every time someone solves a math problem. But could you please, please consider toning down the hostility just a bit? These swipes at other commenters' competence and integrity are really unpleasant to read.
ADDENDUM: Re tone, consider the difference between "I wonder why this was downvoted, could someone please explain?" (which is polite) and "What a crock," followed by shaming a counterfactual Wei Dai (which is rude).
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T17:05:06.973Z · LW(p) · GW(p)
If it is in fact the case that your complaints are legitimately judged a negative contribution, then you should expect to be downvoted and criticized on those particular comments, regardless of whether or not your solution is correct. There's nothing contradictory about simultaneously believing both that your proposed solution is correct, and that your subsequent complaints are a negative contribution.
Actually, there is something contradictory when those whiny comments were necessary for the previous, relevant comments to get their deserved karma. Your position here is basically: "Yeah, we were wrong to accuse you of those crimes, but you were still a jerk for pulling all that crap about 'I plead not guilty!' and 'I didn't do it!', wah, wah, wah..."
At the very least, it should buy me more leeway than get for such a tone in isolation.
But could you please, please consider toning down the hostility just a bit?
Sure thing.
I trust that other posters will be more judicious with their voting and responses as well.
↑ comment by wedrifid · 2009-09-23T13:14:39.958Z · LW(p) · GW(p)
No satire. I just don't find expecting the universe to 'behave itself' according to my ideals to be particularly pleasant so I don't wast my emotional energy on it.
I have upvoted your comment because it appears to be a useful (albeit somewhat information dense) contribution. I personally chose not to downvote your complaints because I do empathise with your frustration even if I don't think your complaints are a useful way to get you what you want.
↑ comment by orthonormal · 2009-09-23T04:43:29.970Z · LW(p) · GW(p)
I was the one who downvoted the parent, because you criticized Wei Dai's correct solution by arguing about a different problem than the one you agreed to several comments upstream.
Yes, you'd get a different solution if you assumed that the random variable for information gave independent readings at X and Y, instead of being engineered for maximum correlation. But that's not the problem Wei Dai originally stated, and his solution to the original problem is unambiguously correct. (I suspect, but haven't checked, that a mixed strategy beats the pure one on your problem setup as well.)
I simply downvoted rather than commented, because (a) I was feeling tired and (b) your mistake seemed pretty clear to me. I don't think that was a violation of LW custom.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-23T11:55:46.892Z · LW(p) · GW(p)
I was the one who downvoted the parent, because you criticized Wei Dai's correct solution by arguing about a different problem than the one you agreed to several comments upstream
I didn't change the problem; I pointed out that he hadn't been appropriately representing the existing problem when trying to generalize it to partial information. Having previously agreed with his (incorrect) assumptions in no way obligates me to persist in my error, especially when the exchange makes it clear!
his solution to the original problem is unambiguously correct. (I suspect, but haven't checked, that a mixed strategy beats the pure one on your problem setup as well.)
Which original problem? (If the ABM problem as stated, then my solution is gives the same p=2/3 result. If it's the partial knowledge variant, Wei_Dei doesn't have an unambiguously correct solution when he fails to include the possibility of picking Y at X and X at Y like he did for the reverse.) Further, I do have the mixed strategy dominating -- but only up to r = 61%. Feel free to find an optimum where one of p and q is not 1 or 0 while r is greater than 61%.
Yes, you'd get a different solution if you assumed that the random variable for information gave independent readings at X and Y, instead of being engineered for maximum correlation.
That wasn't the reason for our different solutions.
I simply downvoted rather than commented, because (a) I was feeling tired and (b) your mistake seemed pretty clear to me.
Well, I hope you're no longer tired, and you can check my approach one more time.
↑ comment by loqi · 2009-09-25T07:07:16.612Z · LW(p) · GW(p)
I'm pretty sure Wei Dai is correct. I'll try and explain it differently. Here's a rendering of the problem in some kind of pseudolisp:
(start (p q)
(0.4 "uninformative-x"
(p "continue"
(p "continue" 1)
(else "exit" 4))
(else "exit" 0))
(0.4 "uninformative-y"
(q "continue"
(q "continue" 1)
(else "exit" 4))
(else "exit" 0))
(0.2 "informative"
(p "continue"
(q "continue" 1)
(else "exit" 4))
(else "exit" 0)))
Now evaluate with the strategy under discussion, (start 1 0):
(0.4 "uninformative-x"
(1 "continue"
(1 "continue" 1)
(0 "exit" 4))
(0 "exit" 0))
(0.4 "uninformative-y"
(0 "continue"
(0 "continue" 1)
(1 "exit" 4))
(1 "exit" 0))
(0.2 "informative"
(1 "continue"
(0 "continue" 1)
(1 "exit" 4))
(0 "exit" 0))
Prune the zeros:
(0.4 "uninformative-x"
(1 "continue"
(1 "continue" 1)))
(0.4 "uninformative-y"
(1 "exit" 0))
(0.2 "informative"
(1 "continue"
(1 "exit" 4)))
Combine the linear paths:
(0.4 "uninformative-x/continue/continue" 1)
(0.4 "uninformative-y/exit" 0)
(0.2 "informative/continue/exit" 4)
You seem to be treating .2/.4/.4 as being continue-exit/exit-exit/continue-continue, which isn't the right way to look at it.
I'd be interested in seeing what you think is wrong with the above derivation, ideally in terms of the actual decision problem at hand. Remember, p and q are decision parameters. They parameterize an agent, not an expectation. When p and q are 0 or 1, the agent is essentially a function of type "Bool -> Bool". How could a stateless agent of that type implement a better strategy than limiting itself to those three options?
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-25T12:26:21.827Z · LW(p) · GW(p)
Again, what's wrong with that derivation is it leaves out the possibility of "disinformative", and therefore assumes more knowledge about your intersection than you can really have. (By zeroing the probability of "Y then X" it concentrates the probability mass in a way that decreases the entropy of the variable more than your knowledge can justify.)
In writing the world-program in a way that categorizes your guess as "informative", you're implicitly assuming some memory of what you drew before: "Okay, so now I'm on the second one, which shows the Y-card ..."
Now, can you explain what's wrong with my derivation?
Replies from: loqi↑ comment by loqi · 2009-09-25T18:00:00.508Z · LW(p) · GW(p)
Again, what's wrong with that derivation is it leaves out the possibility of "disinformative"
By "disinformative", do you mean that intersection X has hint Y and vice versa? This is not possible in the scenario Wei Dai describes.
In writing the world-program in a way that categorizes your guess as "informative"
Ah, this seems to be a point of confusion. The world program does not categorize your guess, at all. The "informative" label in my derivation refers to the correctness of the provided hints. Whether or not the hints are both correct is a property of the world.
you're implicitly assuming some memory of what you drew before: "Okay, so now I'm on the second one, which shows the Y-card ..."
No, I am merely examining the possible paths from the outside. You seem to be confusing the world program with the agent. In the "informative/continue/exit" case, I am saying "okay, so now the driver is on the second one". This does not imply that the driver is aware of this fact.
Now, can you explain what's wrong with my derivation?
I think so. You're approaching the problem from a "first-person perspective", rather than using the given structure of the world, so you're throwing away conditional information under the guise of implementing a stateless agent. But the agent can still look at the entire problem ahead of time and make a decision incorporating this information without actually needing to remember what's happened once he begins.
At the first intersection, the state space of the world (not the agent) hasn't yet branched, so your approach gives the correct answer. At the second intersection, we (the authors of the strategy, not the agent) must update your "guess odds" conditional on having seen X at the first intersection.
Your tree was:
(0.4 "exit" 0)
(0.6 "continue"
(0.6 "exit" 4)
(0.4 "continue" 1))
The outer probabilities are correct, but the inner probabilities haven't been conditioned on seeing X at the first intersection. Two out of three times that the agent sees X at the first intersection, he will see X again at the second intersection. So, assuming the p=1 q=0 strategy, the statement "Given .2/.4/.4, you will see Y 60% of the time at Y" is false.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-25T19:51:36.542Z · LW(p) · GW(p)
You're approaching the problem from a "first-person perspective", rather than using the given structure of the world, so you're throwing away conditional information under the guise of implementing a stateless agent. But the agent can still look at the entire problem ahead of time and make a decision incorporating this information without actually needing to remember what's happened once he begins.
Okay, this is where I think the misunderstanding is. When I posited the variable r, I posited it to mean the probability of correctly guessing the intersection. In other words, you receive information at that point such that it moves your estimate of which intersection you're at, accounting for other inferences you may have made about the problem, including from examining it from the outside and setting your p, to r. So the way the r is defined, it screens off knowledge gained from deciding to use p and q.
Now, this might not be a particularly relevant generalization of the problem, I now grant that. But under the premises, it's correct. A better generalization would be to find out your probability distribution across X and Y (given your choice of p), and then assume someone gives you b bits of evidence (decrease in the KL Divergence of your estimate from the true distribution), and find the best strategy from there.
And for that matter Wei_Dai's solution, given his way of incorporating partial knowledge of one's intersection, is also correct, and also probably not the best way to generalize the problem because it basically asks, "what strategy should you pick, given that you have a probably t of not being an absent-minded driver, and a probability 1 - t of being an absent-minded driver?"
Replies from: loqi↑ comment by loqi · 2009-09-25T21:18:56.244Z · LW(p) · GW(p)
And for that matter Wei_Dai's solution, given his way of incorporating partial knowledge of one's intersection, is also correct
Thanks, this clarifies the state of the discussion. I was basically arguing against the assertion that it was not.
and also probably not the best way to generalize the problem because it basically asks, "what strategy should you pick, given that you have a probably t of not being an absent-minded driver, and a probability 1 - t of being an absent-minded driver?"
I don't think I understand this. The resulting agent is always stateless, so it is always an absent-minded driver.
Are you looking for a way of incorporating information "on-the-fly" that the original strategy couldn't account for? I could be missing something, but I don't see how this is possible. In order for some hint H to function as useful information, you need to have estimates for P(H|X) and P(H|Y) ahead of time. But with these estimates on hand, you'll have already incorporated them into your strategy. Therefore, your reaction to the observation of H or the lack thereof is already determined. And since the agent is stateless, the observation can't affect anything beyond that decision.
It seems that there is just "no room" for additional information to enter this problem except from the outside.
↑ comment by SilasBarta · 2009-09-16T22:17:18.863Z · LW(p) · GW(p)
In this case, the possibility of performing the best sequence is more valuable than full knowledge of which sequence you actually perform.
Okay, that's a more specific, helpful answer.
↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T18:30:57.861Z · LW(p) · GW(p)
Also, could someone go through the steps of how UDT generates this solution
I just added to the post with an answer.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-16T20:17:26.072Z · LW(p) · GW(p)
Thanks! :-) But I still don't understand what made you express the payoff as a function of p. Was it just something you thought of when applying UDT (perhaps after knowing that's how someone else approached the problem), or is there something about UDT that required you to do that?
Replies from: Vladimir_Nesov, Wei_Dai↑ comment by Vladimir_Nesov · 2009-09-16T20:29:00.992Z · LW(p) · GW(p)
What do you mean? p is the only control parameter... You consider a set of "global" mixed strategies, indexed by p, and pick one that leads to the best outcome, without worrying about where your mind that does this calculation is currently located and under what conditions you are thinking this thought.
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-16T20:36:02.144Z · LW(p) · GW(p)
What do you mean? p is the only control parameter...
Perhaps, but it's an innovation to think of the problem in terms of "solving for the random fraction of times I'm going to do them". That is, even considering that you should add randomness in between your decision and what you do, is an insight. What focused your attention on optimizing with respect to p?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2009-09-16T20:42:53.940Z · LW(p) · GW(p)
Mixed strategy is a standard concept, so here we are considering a set S of all (global) mixed strategies available for the game. When you are searching for the best strategy, you are maximizing the payoff over S. You are searching for the mixed strategy that gives the best payoff. What UDT tells is that you should just do that, even if you are considering what to do in a situation where some of the options have run out, and, as here, even if you have no idea where you are. "The best strategy" quite literally means
)
The only parameter for a given strategy is the probability of turning, so it's natural to index the strategies by that probability. This indexing is a mapping t:[0,1]->S that places a mixed strategy in correspondence with a value of turning probability. Now, we can rewrite the expected utility maximization in terms of probability:
,\%20p^*=\arg\max_{p\in%20[0,1]}%20EU(t(p)))
For a strategy corresponding to turning probability p, it's easy to express corresponding expected utility:
)%20=%20(1-p)\cdot%200%20+%20p\cdot%20((1-p)\cdot%204%20+%20p\cdot%201))%20=p^2+4p(1-p))
We now can find the optimal strategy as
,\%20p^*=\arg\max_{p\in%20[0,1]}(p^2+4p(1-p)))
↑ comment by SilasBarta · 2009-09-16T22:11:47.928Z · LW(p) · GW(p)
Okay, that's making more sense -- the part where you get to parameterizing p as a real is what I was interested in.
But do you do the same thing when applying UDT to Newcomb's problem? Do you consider it a necessary part of UDT that you take p (with 0<=p<=1) as a continuous parameter to maximize over, where p is the probability of one-boxing?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2009-09-17T02:40:49.465Z · LW(p) · GW(p)
Fundamentally, this depends on the setting -- you might not be given a random number generator (randomness is defined with respect to the game), and so the strategies that depend on a random value won't be available in the set of strategies to choose from. In Newcomb's problem, the usual setting is that you have to be fairly deterministic or Omega punishes you (so that a small probability of two-boxing may even be preferable to pure one-boxing, or not, depending on Omega's strategy), or Omega may be placed so that your strategy is always deterministic for it (effectively, taking mixed strategies out of the set of allowed ones).
↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T20:25:13.671Z · LW(p) · GW(p)
S() is suppose to be an implementation of UDT. By looking at the world program P, it should determine that among all possible input-output mappings, those that return "EXIT" for 1/3 of all inputs (doesn't matter which ones) maximize average payoff. What made me express the payoff as a function of p is by stepping through what S is supposed to do as an implementation of UDT.
Does that make sense?
Replies from: SilasBarta↑ comment by SilasBarta · 2009-09-16T20:33:00.942Z · LW(p) · GW(p)
I'm still confused. Your response seems to just say, "I did it because it works." -- which is a great reason! But I want to know if UDT gave you more guidance than that.
Does UDT require that you look at the consequences of doing something p% of the time (irrespective of which ones), on all problems?
Basically, I'm in the position of that guy/gal that everyone here probably helped out in high school:
"How do you do the proof in problem 29?" "Oh, just used identities 3 and 5, solve for t, and plug it back into the original equation." "But how did you know to do that?"
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T20:46:05.630Z · LW(p) · GW(p)
Does UDT require that you look at the consequences of doing something p% of the time (irrespective of which ones), on all problems?
No, UDT (at least in my formulation) requires that you look at all possible input-output mappings, and choose the one that is optimal. In this case it so happens that any function that returns "EXIT" for 1/3 of inputs is optimal.
comment by gwern · 2011-02-02T21:37:57.499Z · LW(p) · GW(p)
In #lesswrong, me, Boxo, and Hyphen-ated each wrote a simple simulation/calculation of the absent-minded driver and checked how the various strategies did. Our results:
- 1/3 = 1.3337, 1.3338174; Hyphen-ated: 1.33332; Boxo: 1.3333333333333335
- 1/4 = 1.3127752; Hyphen-ated: 1.31247; Boxo: 1.3125
- 2/3 = 0.9882
- 4/9 = 1.2745, 1.2898, 1.299709, 1.297746, 1.297292, 1.2968815; Hyphen-ated: 1.29634; Boxo: 1.2962962962962963
As expected, 4/9 does distinctly worse than 1/3, which is the best strategy of the ones we tested. I'm a little surprised at Piccione & Rubinstein - didn't they run any quick* little simulation to see whether 4/9 was beaten by another probability or did they realize this and had some reason bad performance was justifiable? (I haven't read P&R's paper.)
Boxo used his UDT in Haskell code ([eu (Strategy $ const $ chance p) absentMinded id | p <- [0, 1/2, 1/3, 1/4, 4/9]]); I used some quick and dirty Haskell pasted below; and I don't know what Hyphen-ated used.
import System.Random
import Control.Monad
main = foo >>= print -- test out the 1/4 strategy. obvious how to adapt
foo = let n = 10000000 in fmap (\x -> fromIntegral (sum x) / fromIntegral n) $ replicateM n run
run = do x <- getStdRandom (randomR (1,4))
y <- getStdRandom (randomR (1,4))
return $ trial x y
trial :: Int -> Int -> Int
trial x y | x == 1 = 0 -- exit at first turn with reward 0
| y == 1 = 4 -- second turn, reward 4
| otherwise = 1 -- missed both, reward 1
* It's not like this is a complex simulation. I'm not familiar with Haskell's System.Random so it took perhaps 20 or 30 minutes to get something working and then another 20 or 30 minutes to run the simulations with 1 or 10 million iterations because it's not optimized code, but Boxo and Hyphen-ated worked even faster than that.
Replies from: Hyphen-ated, gwern, HoverHell, Hyphen-ated, Hyphen-ated↑ comment by Hyphen-ated · 2011-02-02T21:55:56.616Z · LW(p) · GW(p)
I slapped together some C++ in under ten minutes, with an eye towards making it run fast. This runs a billion iterations in slightly under one minute on my machine.
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
long long threshhold = 4 * (RAND_MAX / 9);
int main() {
srand((unsigned)time(0));
long long utility = 0;
long long iterations = 1000000000;
for(long long i = 0; i < iterations; ++i) {
if(rand() < threshhold)
continue;
else if(rand() < threshhold) {
utility += 4;
continue;
}
++utility;
}
cout << "avg utility: " << (double)utility/iterations << endl;
return 0;
}
↑ comment by gwern · 2016-01-19T16:50:46.995Z · LW(p) · GW(p)
To return to this a little, here's an implementation in R:
absentMindedDriver <- function(p1, p2) { if(p1==1) { 0; } else { if(p2==1) { 4; } else { 1; } } }
runDriver <- function(p=(1/3), iters=100000) { p1 <- rbinom(n=iters, size=1, prob=p)
p2 <- rbinom(n=iters, size=1, prob=p)
return(mapply(absentMindedDriver, p1, p2)) }
sapply(c(0, 1/2, 1/3, 1/4, 4/9, 1), function(p) { mean(runDriver(p=p)); })
# [1] 1.00000 1.25183 1.33558 1.31156 1.29420 0.00000
## Plot payoff curve:
actions <- seq(0, 1, by=0.01)
ground <- data.frame(P=actions, Reward=sapply(actions, function(p) {mean(runDriver(p))}))
plot(ground)
# https://i.imgur.com/sQGDjEU.png
An agent could solve this for the optimal action in a number of ways. For example, taking a reinforcement learning perspective, we could discretize the action space into 100 probabilities: 0, 0.01, 0.02...0.98, 0.99, 1.0, and treat it as a multi-armed bandit problem with k=100 independent arms (without any assumptions of smoothness or continuity or structure over 0..1).
Implementation-wise, we can treat the arm as a level in a categorical variable, so instead of writing out Reward ~ Beta_p0 + Beta_p0.01 + ... Beta_p1.0 we can write out Reward ~ P and let the library expand it out into 100 dummy variables. So here's a simple Thompson sampling MAB in R using MCMCglmm rather than JAGS since it's shorter:
testdata <- data.frame(P=c(rep(0.00, 10), rep(0.33, 10), rep(0.66, 10), rep(0.9, 10)), Reward=c(runDriver(p=0, iters=10), runDriver(p=(0.33), iters=10), runDriver(p=(0.66), iters=10), runDriver(p=(0.9), iters=10))); testdata
# P Reward
# 1 0.00 1
# 2 0.00 1
# 3 0.00 1
# ...
summary(lm(Reward ~ as.factor(P), data=testdata))
# ...Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 1.0000000 0.3836955 2.60623 0.013232
# as.factor(P)0.33 0.7000000 0.5426274 1.29002 0.205269
# as.factor(P)0.66 -0.5000000 0.5426274 -0.92144 0.362954
# as.factor(P)0.9 -0.6000000 0.5426274 -1.10573 0.276178
library(MCMCglmm)
m <- MCMCglmm(Reward ~ as.factor(P), data=testdata)
summary(m$Sol)
# ...1. Empirical mean and standard deviation for each variable,
# plus standard error of the mean:
# Mean SD Naive SE Time-series SE
# (Intercept) 1.0215880 0.4114639 0.01301163 0.01301163
# as.factor(P)0.33 0.6680714 0.5801901 0.01834722 0.01632753
# as.factor(P)0.66 -0.5157360 0.5635405 0.01782072 0.01782072
# as.factor(P)0.9 -0.6056746 0.5736586 0.01814068 0.01884525
#
# 2. Quantiles for each variable:
# 2.5% 25% 50% 75% 97.5%
# (Intercept) 0.2440077 0.7633342 1.0259299 1.2851243 1.8066701
# as.factor(P)0.33 -0.4521587 0.2877682 0.6515954 1.0344911 1.8871638
# as.factor(P)0.66 -1.5708577 -0.8923558 -0.5300312 -0.1495413 0.5953416
# as.factor(P)0.9 -1.7544003 -0.9542541 -0.6397946 -0.2389132 0.6077439
# k=100
actions <- seq(0, 1, by=0.01)
# We seed each action with 1 trial, to make sure each action shows up as a level of the categorical variable:
mab <- data.frame(P=actions, Reward=sapply(actions, function(a) { runDriver(p=a, iters=1) }))
# We'll run for 10,000 sequential actions total (or ~100 trials per arm on average)
iters <- 10000
for (i in 1:iters) {
m <- MCMCglmm(Reward ~ as.factor(P), data=mab, verbose=FALSE)
estimates <- data.frame()
for (col in 2:ncol(m$Sol)) {
# take 1 estimate from MCMCglmm's posterior samples for each level of the categorical variable P:
estimates <- rbind(estimates,
data.frame(P=as.numeric(sub("as.factor\\(P\\)", "", names(m$Sol[1,col]))),
RewardSample=m$Sol[1,col]))
}
# since reward is already defined as utility, our utility function is just the identity:
utilityFunction <- function(estimate) { identity(estimate); }
actionChoice <- estimates[which.max(utilityFunction(estimates$RewardSample)),]$P
result <- runDriver(p=actionChoice, iters=1)
mab <- rbind(mab, data.frame(P=actionChoice, Reward=result))
cat(paste0("I=", i, "; tried at ", actionChoice, ", got reward: ", result, "\n"))
}
# ...I=9985; tried at 0.23, got reward: 1
# I=9986; tried at 0.45, got reward: 4
# I=9987; tried at 0.43, got reward: 4
# I=9988; tried at 0.39, got reward: 1
# I=9989; tried at 0.39, got reward: 0
# I=9990; tried at 0.53, got reward: 0
# I=9991; tried at 0.44, got reward: 0
# I=9992; tried at 0.84, got reward: 0
# I=9993; tried at 0.32, got reward: 4
# I=9994; tried at 0.16, got reward: 4
# I=9995; tried at 0.09, got reward: 1
# I=9996; tried at 0.15, got reward: 1
# I=9997; tried at 0.02, got reward: 1
# I=9998; tried at 0.28, got reward: 1
# I=9999; tried at 0.35, got reward: 1
# I=10000; tried at 0.35, got reward: 4
## Point-estimates of average reward from each arm:
plot(mab$P)
# https://i.imgur.com/6dTvXC8.png

We can see just from the sheer variability of the actions>0.5 that the MAB was shifting exploration away from them, accepting much larger uncertainty in exchange for focusing on the 0.2-0.4 where the optimal action lies in; it didn't manage to identify 0.33 as that optimum due to what looks like a few unlucky samples in this run which put 0.33 below, but it was definitely getting there. How much certainty did we gain about 0.33 being optimal as compared to a naive strategy of just allocating 10000 samples over all arms?
fixed <- data.frame()
for (a in actions) { fixed <- rbind(fixed, data.frame(P=a, Reward=runDriver(p=a, iters=100))); }
## We can see major variability compared to the true curve:
plot(aggregate(Reward ~ P, fixed, mean))
# https://i.imgur.com/zmNdwfC.png

We can ask the posterior probability estimate of 0.33 being optimal by looking at a set of posterior sample estimates for arms 1-100 and seeing in how many sets 0.33 has the highest parameter estimate (=maximum reward); we can then compare the posterior from the MAB with the posterior from the fixed-sample trial:
posteriorProbabilityOf0.33 <- function (d) {
mcmc <- MCMCglmm(Reward ~ as.factor(P), data=d, verbose=FALSE)
posteriorEstimates <- mcmc$Sol[,-1]
trueOptimum <- which(colnames(posteriorEstimates) == "as.factor(P)0.33")
return(table(sapply(1:nrow(posteriorEstimates), function(i) { which.max(posteriorEstimates[i,]) == trueOptimum; }))) }
posteriorProbabilityOf0.33(mab)
# FALSE TRUE
# 998 2
posteriorProbabilityOf0.33(fixed)
# FALSE
# 1000
So the MAB thinks 0.33 is more than twice as likely to be optimal than the fixed trial did, despite some bad luck. It also did so while gaining a much higher reward, roughly equivalent to choosing p=0.25 each time (optimal would've been ~1.33, so our MAB's regret is (1.33-1.20) * 10000 = 1300 vs the fixed's in-trial regret of 3400 and infinite regret thereafter since it did not find the optimum at all):
mean(fixed$Reward)
# [1] 0.9975247525
mean(df$Reward)
# [1] 1.201861202
↑ comment by gwern · 2016-01-19T16:57:39.032Z · LW(p) · GW(p)
While I was at it, I thought I'd give some fancier algorithms a spin using Karpathy's Reinforce.js RL library (Github). The DQN may be able to do much better since it can potentially observe the similarity of payoffs and infer the underlying function to maximize.
First a JS implementation of the Absent-Minded Driver simulation:
function getRandBinary(p=0.5) { rand = Math.random(); if (rand >= p) { return 0; } else { return 1; } }
function absentMindedDriver(p1, p2) { if(p1==1) { return 0; } else { if (p2==1) { return 4; } else { return 1; } } }
function runDriver(p) { p1 = getRandBinary(p)
p2 = getRandBinary(p)
return absentMindedDriver(p1, p2); }
function runDrivers(p=(1/3), iters=1000) {
var rewards = [];
for (i=0; i < iters; i++) {
rewards.push(runDriver(p));
}
return rewards;
}
Now we can use Reinforce.js to set up and run a deep Q-learning agent (but not too deep since this runs in-browser and there's no need for hundreds or thousands of neurons for a tiny problem like this):
// load Reinforce.js
var script = document.createElement("script");
script.src = "https://raw.githubusercontent.com/karpathy/reinforcejs/master/lib/rl.js";
document.body.appendChild(script);
// set up a DQN RL agent and run
var env = {};
env.getNumStates = function() { return 0; }
env.getMaxNumActions = function() { return 100; } // so actions are 1-100?
// create the DQN agent: relatively small, since this is an easy problem; greedy, since only one step; hold onto all data & process heavily
var spec = { num_hidden_units:25, experience_add_every:1, learning_steps_per_iteration:100, experience_size:10100 }
agent = new RL.DQNAgent(env, spec);
// OK, now let it free-run; we give it an extra 100 actions for equality with the MAB's initial 100 exploratory pulls
for (i=0; i < 10100; i++) {
s = [] // MAB is one-shot, so no global state
var action = agent.act([]);
//... execute action in environment and get the reward
reward = runDriver(action/100);
console.log("Action: " + action + "; reward: " + reward);
agent.learn(reward); // the agent improves its Q,policy,model, etc. reward is a float
}
// ...Action: 15; reward: 1
// Action: 34; reward: 0
// Action: 34; reward: 4
// Action: 21; reward: 4
// Action: 15; reward: 1
// Action: 43; reward: 0
// Action: 21; reward: 1
// Action: 43; reward: 1
// Action: 34; reward: 4
// Action: 15; reward: 1
// Action: 78; reward: 0
// Action: 15; reward: 0
// Action: 15; reward: 1
// Action: 34; reward: 1
// Action: 43; reward: 1
// Action: 34; reward: 4
// Action: 24; reward: 1
// Action: 0; reward: 1
// Action: 34; reward: 0
// Action: 3; reward: 1
// Action: 51; reward: 4
// Action: 3; reward: 1
// Action: 11; reward: 4
// Action: 3; reward: 1
// Action: 11; reward: 1
// Action: 43; reward: 4
// Action: 36; reward: 4
// Action: 36; reward: 0
// Action: 21; reward: 4
// Action: 77; reward: 0
// Action: 21; reward: 4
// Action: 26; reward: 4
Overall, I am not too impressed by the DQN. It looks like it is doing worse than the MAB was, despite having a much more flexible model to use. I don't know if this reflects the better exploration of Thompson sampling compared to the DQN's epsilon-greedy, or if my fiddling with the hyperparameters failed to help. It's a small enough problem that a Bayesian NN is probably computationally feasible, but I dunno how to use those.
↑ comment by Hyphen-ated · 2011-02-02T21:54:49.873Z · LW(p) · GW(p)
I slapped together some C++ in under ten minutes. This runs a billion iterations in slightly under one minute on my machine.
#include
#include
#include using namespace std; long long threshhold = 4 * (RAND_MAX / 9); int main() { srand((unsigned)time(0)); long long utility = 0; long long iterations = 1000000000; for(long long i = 0; i < iterations; ++i) { if(rand() < threshhold) continue; else if(rand() < threshhold) { utility += 4; continue; } ++utility; } cout << "avg utility: " << (double)utility/iterations << endl; return 0; }
↑ comment by Hyphen-ated · 2011-02-02T21:49:50.010Z · LW(p) · GW(p)
I slapped together some C++ in under 10 minutes, with an eye towards execution speed. This code runs in almost exactly one minute on my machine, with one billion iterations.
#include
#include
#include using namespace std; long long threshhold = 4 * (RAND_MAX / 9); int main() { srand((unsigned)time(0)); long long utility = 0; long long iterations = 1000000000; for(long long i = 0; i < iterations; ++i) { if(rand() < threshhold) continue; else if(rand() < threshhold) { utility += 4; continue; } ++utility; } cout << "avg utility: " << (double)utility/iterations << endl; return 0; }
comment by Wei Dai (Wei_Dai) · 2009-09-25T09:24:03.056Z · LW(p) · GW(p)
It occurs to me that perhaps "professional rationalist" is a bit of an oxymoron. In today's society, a professional rationalist is basically someone who is paid to come up with publishable results in the academic fields related to rationality, such as decision theory and game theory.
I've always hated the idea of being paid for my ideas, and now I think I know why. When you're being paid for you ideas, you better have "good" ideas or you're going to starve (or at least suffer career failure). But good ideas can't be produced on a schedule, so the only way to guarantee academic survival is to learn the art of self-promotion. Your papers better make your mediocre ideas look good, and your good ideas look great. And having doubts about your ideas isn't going to help your career, even if they are rationally justified.
Given this reality, how can any professional rationalist truly be rational?
Replies from: gwern↑ comment by gwern · 2010-01-03T15:38:55.256Z · LW(p) · GW(p)
"How long did it take you to learn this new thing?"
Paradigmatic career-making ideas and papers are rare and take years or decades to produce. But academia doesn't run on that coin - just regular papers and small ideas.
Is it too much to suggest that 1 every few months is possible for someone who ought to be a professional rationalist, who reads the literature carefully and thinks through all their ideas, who keeps a pad & pen handy to jot down random notes, who listens to the occasional off-kilter but insightful student questions, and so on?
That is 4 ideas a year, and over a graduate student's 4-year term, 16 possible papers. Not counting any prevarication.
comment by Caspar Oesterheld (Caspar42) · 2018-01-26T11:13:44.499Z · LW(p) · GW(p)
I wonder what people here think about the resolution proposed by Schwarz (2014). His analysis is that the divergence from the optimal policy also goes away if one combines EDT with the halfer position a.k.a. the self-sampling assumption, which, as shown by Briggs (2010), appears to be the right anthropic view to combine with EDT, anyway.
comment by ThrustVectoring · 2013-06-30T23:23:20.006Z · LW(p) · GW(p)
It's kind of an old thread, but I know people browse the recently posted list and I have a good enough understanding of what exactly the decision theorists are doing wrong that I can explain it in plain English.
First of all, alpha can only consistently be one number: 1/(1+p). And once you substitute that into α[p2+4(1-p)p] + (1-α)[p+4(1-p)], you get a peculiar quantity: (2/1+p) * [p2 + 4(-1p)p]. Where does the 2/1+p come from? Well, every time you go through the first node, you add up the expected result from the first node and the second node, and you also add up the expected result when you visit the second node. This is a double counting. The 2/1+p is the number of times you visit a node and make a choice, per time you enter the whole thing.
If we assume we're limited to a certain number of experimental runs and not a certain number of continue/exit choices, we need to divide out the 2/(1+p) to compensate for the fact that you make N*(2/1+p) choices in N games.
comment by momom2 (amaury-lorin) · 2025-01-17T20:55:19.219Z · LW(p) · GW(p)
The paradox arises because the action-optimal formula mixes world states and belief states.
The [action-planning] formula essentially starts by summing up the contributions of the individual nodes as if you were an "outside" observer that knows where you are, but then calculates the probabilities at the nodes as if you were an absent-minded "inside" observer that merely believes to be there (to a degree).
So the probabilities you're summing up are apples and oranges, so no wonder the result doesn't make any sense. As stated, the formula for action-optimal planning is a bit like looking into your wallet more often, and then observing the exact same money more often. Seeing the same 10 dollars twice isn't the same thing as owning 20 dollars.
If you want to calculate the utility and optimal decision probability entirely in belief-space (i.e. action-optimal), then you need to take into account that you can be at X, and already know that you'll consider being at X again when you're at Y.
So in belief space, your formula for the expected value also needs to take into account that you'll forget, and the formula becomes recursive. So the formula should actually be:
Explanation of the terms in order of appearance:
- If we are in X and CONTINUE, then we will "expect the same value again" when we are in Y in the future. This enforces temporal consistency.
- If we are in X and EXIT, then we should expect 0 utility
- If we are in Y and CONTINUE, then we should expect 1 utility
- If we are in Y and EXIT, then we should expect 4 utility We also know that a must be 1 / (1 + p), because when driving n times, you're in X for n times, and in Y for p * n times.
Under that constraint, we get that The optimum here is at p=2/3 with an expected utility of 4/3, which matches the planning-optimal formula.
[Shamelessly copied from a comment under this video by xil12323.]
comment by sebmathguy · 2012-11-30T04:57:56.319Z · LW(p) · GW(p)
import java.util.*;
public class absentMindedDriver {
static Random generator = new Random(); static int trials = 100000; static double[] utilities;
static int utility(double x) { if(generator.nextDouble() < x) { //the driver guesses return 0; } if(generator.nextDouble() < x) { //the driver guesses return 4; } return 1; //the driver missed both exits }
static double averageUtility(double x) { int sum = 0; for(int i = 0; i < trials; i++) { sum += utility(x); //iteratively generates the sum to be divided } return (sum / trials); //averages the utility function over some number of trials }
static void setupUtilities(int slices) { //slices is just the number of different values of p we'll be testing, or how finely we slice up the unit interval utilities = new double[slices]; for(int i = 0; i < slices; i++) { utilities[i] = averageUtility((double) i / slices); } }
static double maxP(int slices) { double bestPSoFar = 0; double bestUtilSoFar = 0; setupUtilities(slices); for(int i = 0; i < slices; i++) { if(utilities[i] > bestUtilSoFar) { bestPSoFar = ((double) i / slices); } } return bestPSoFar; }
public static void main(String[] args) { System.out.println(maxP(100)); } }
comment by sebmathguy · 2012-11-30T04:56:44.879Z · LW(p) · GW(p)
If anybody wants to try simulating this problem, here's some java code:
`import java.util.*;
public class absentMindedDriver {
static Random generator = new Random(); static int trials = 100000; static double[] utilities;
static int utility(double x) { if(generator.nextDouble() < x) { //the driver guesses return 0; } if(generator.nextDouble() < x) { //the driver guesses return 4; } return 1; //the driver missed both exits }
static double averageUtility(double x) { int sum = 0; for(int i = 0; i < trials; i++) { sum += utility(x); //iteratively generates the sum to be divided } return (sum / trials); //averages the utility function over some number of trials }
static void setupUtilities(int slices) { //slices is just the number of different values of p we'll be testing, or how finely we slice up the unit interval utilities = new double[slices]; for(int i = 0; i < slices; i++) { utilities[i] = averageUtility((double) i / slices); } }
static double maxP(int slices) { double bestPSoFar = 0; double bestUtilSoFar = 0; setupUtilities(slices); for(int i = 0; i < slices; i++) { if(utilities[i] > bestUtilSoFar) { bestPSoFar = ((double) i / slices); } } return bestPSoFar; }
public static void main(String[] args) { System.out.println(maxP(100)); } }`
comment by Stuart_Armstrong · 2009-09-25T11:32:22.483Z · LW(p) · GW(p)
Your payoff for choosing CONTINUE with probability p becomes α[p2+4(1-p)p] + (1-α)[p+4(1-p)]
I think that's twice as much as it should be, since neither your decision at X, nor at Y, contribute entirely to your utility result.
comment by conchis · 2009-09-16T02:47:54.891Z · LW(p) · GW(p)
Isn't the claim in 6 (that there is a planning-optimal choice, but no action-optimal choice) inconsistent with 4 (a choice that is planning optimal is also action optimal)?
Replies from: CarlShulman↑ comment by CarlShulman · 2009-09-16T02:52:21.866Z · LW(p) · GW(p)
4 is true if randomized strategies are allowed?
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2009-09-16T05:19:45.632Z · LW(p) · GW(p)
Yes, that's right. I've made an edit to clarify that.
comment by Jonathan_Graehl · 2009-09-16T02:15:35.568Z · LW(p) · GW(p)
From the paper:
At START, he is given the option to be woken either at both intersections, or only at X. In the first option he is absent-minded: when waking up, he does not know at which intersection he is. We call the second option ‘‘clear-headedness.’’ As in the previous discussion, the question at X is not operative (what to do) but only whether it makes sense to be ‘‘sorry.’’ If he chose clear-headedness, his expectation upon reaching X is 1/4. If he had chosen absent-mindedness, then when reaching X he would have attributed probability 2/3 to being at X and 1/3 to being at Y.
I disagree. If I opt to be woken at X, then when I'm woken at intersection X, I know I'm at X. Even if the idea is that I'll immediately go back to sleep, forget everything, and wake again at my payoff/destination, I still knew when I was woken at an intersection that it was X.
Unless I chose to be a) woken at X and b) have no memory of having chosen that, in which case it's fair to say that "I'm at some intersection" (but they suppose I remember the road map I was given indicating intersectons/payoffs X,Y). I guess that's what must have been meant.
Replies from: gwern↑ comment by gwern · 2010-01-03T15:44:49.228Z · LW(p) · GW(p)
I think it must've.
If you remember your choice, then there's no reason to ever choose 'wake me up only at X'. If you wake up only at X, then you will either take action to turn off and score 0 points, or you will go back to sleep and continue to C and score 1 point.
0 or 1 is pretty bad, since you could then do better just by randomly picking from A, B, or C (as (1/3)*1 + (1/3)*4 + (1/3)*0 = 1.6...). Eliminating one branch entirely eliminates the problem.