The Battle for Psychology
post by Jacob Falkovich (Jacobian) · 2017-06-21T03:51:31.000Z · LW · GW · 0 commentsContents
Part 1 – The opposite of power is bullshit Part 2 – Is psychology a science? None No comments
Epistemic status for the first part of this post:

Epistemic status for the second part:

Part 1 – The opposite of power is bullshit
I recently met a young lady, and we were discussing statistical power. No, I don’t see why that’s weird. Anyway, I mentioned that an underpowered experiment is useless no matter if it gets a result or not. For example, the infamous power posing experiment had a power of merely 13%, so it can’t tell us whether power posing actually does something or not.
The young lady replied: For the power pose study, if the power was .13 (and beta was .87), then isn’t it impressive that they caught the effect despite the chance being only 13%?
This question reflects a very basic confusion about what statistical power is. I wish I could explain what it is with a link, but I had trouble finding a clear explanation of that anywhere online, including in my previous post. Wikipedia isn’t very helpful, and neither are the first 5 Google results. So, let me take a step back and try to explain as best I can what power is and what it does.
Statistical power is defined as the chance of correctly identifying a true positive result (if it exists) in an experiment. It is a function of the effect size, the measurement error, and the desired rate of false positives.
The effect size is what you’re actually after, but you can estimate it ahead of time and it has to be part of the hypothesis you’re trying to prove. You don’t care about power If your study is exploratory, but then you’re not setting to confirm any hypotheses either. The bigger the effect size, the higher the statistical power.
Measurement error is a function of your measurement accuracy (which you can’t really change) and the sample (which you can). The bigger the sample, the smaller the error, the higher the power.
The rate of false positives is how often you’ll think you have found an effect when none exists. This number is up to you, and it’s traded off against power: if you decrease the chance of confusing a false effect for a true one, you increase the chance of missing out on a true effect. For reasons of historical conspiracy, this is usually set at 5%.
The same historical conspiracy also decided that “identifying a true positive” means “rejecting the null hypothesis”. This is dumb (why do you care about some arbitrary null hypothesis and not the actual hypothesis you’re testing?) but we’ll leave it for now since (unfortunately) that’s how most research is done today.
Here’s how the actual power calculation is done in the power posing example. The hypothesized effect of power posing is a decrease in cortisol, and I found that this decrease can’t be much larger than 1 µg/dl. That’s the effect size. The measurement error of the change in cortisol (with a sample size of 20 people in each group) is 1.2 µg/dl.
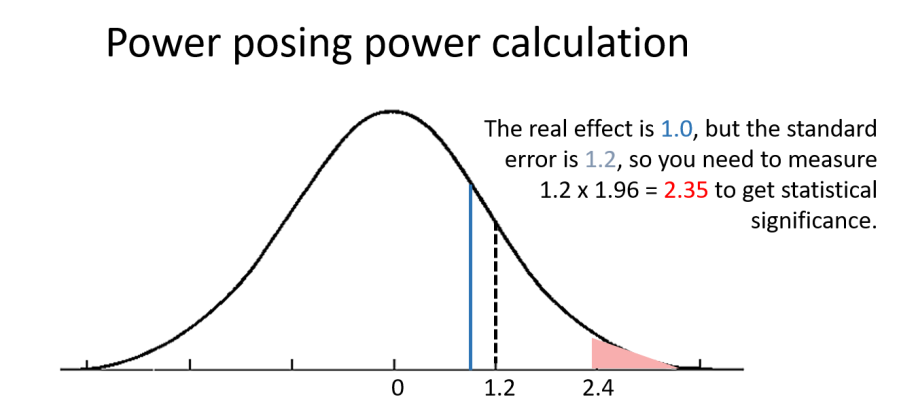
To get a p-value of 0.05, the measured result needs to be at least 1.96 times the standard error. In our case the error is 1.2, so we need to measure an effect of at least 1.96 x 1.2 = 2.35 to reject the null. However, the real effect size is equal to about 1, and to get from 1 to 2.35 we need to also get really lucky. We need 1 µg/dl of real effect, and another 1.35 µg/dl of helpful noise.
This is pretty unlikely to happen, we can calculate the exact probability by just plugging the numbers into the normal distribution function in Excel:
1 – NORM.DIST(1.2*1.96,1,1.2,TRUE) = 13%.
When you run an experiment with 13% power, even if you found an effect that happens to exist you mostly measured noise. More importantly, getting a positive result in a low-powered experiment provides scant evidence that the effect is real. Let me explain why.
Let me explain why.
In an ideal world, setting a p-value threshold at .05 means that you’ll get a false positive (a positive result where no effect actually exists) 5% of the time. In the real world, that’s wildly optimistic.
First of all, even if you do the analysis flawlessly, the chance of a false positive given p<0.05 is around 30%, just due to the fact that true effects are rare. As we say in the Bayesian conspiracy: even if you’re not interested in base rates, base rates are interested in you.
But even without invoking base rates, analyses are never perfect. I demonstrated last time that if you measure enough variables, the false positive rate you can get is basically 100%. Obviously, either “weak men = socialism” or “strong men = socialism” is a false positive. I strongly suspect that both are.
Ok, let’s say that you guard against multiplicity and only test a single variable. What can go wrong? A thousand things can. Measurement mistakes, inference mistakes, coding mistakes, confounders, mismatches between the control and effect group, subjects dropping out, various choices about grouping the data, transforming the data, comparing the data, even cleaning the data.
Let’s take “cleaning the data” as the most innocuous sounding example. What cleaning the data usually means is throwing out data points that have some problem, like a subject that obviously misread the questions on a survey. Obviously. What’s the worst that can happen if you throw out a data point or two? I wrote a quick code simulation to find out.
I simulate two completely independent variables, so we should expect to get a p-value of 5% exactly 5% of the time. However, if I get to exclude just a single data point from a sample size of 30, the false positive rate goes to 14%. If I can throw out two “outliers”, it goes to 25%. You can use the code to play with different sample sizes, thresholds, and the number of outliers you’re allowed to throw out.
Bottom line: if you’re aiming for a 5% false positives, 30% is a very optimistic estimate of the actual false positive rate you’re going to get.
In the perfect world, your power is 80% and the false positive rate is 5%. This dream scenario looks like this:
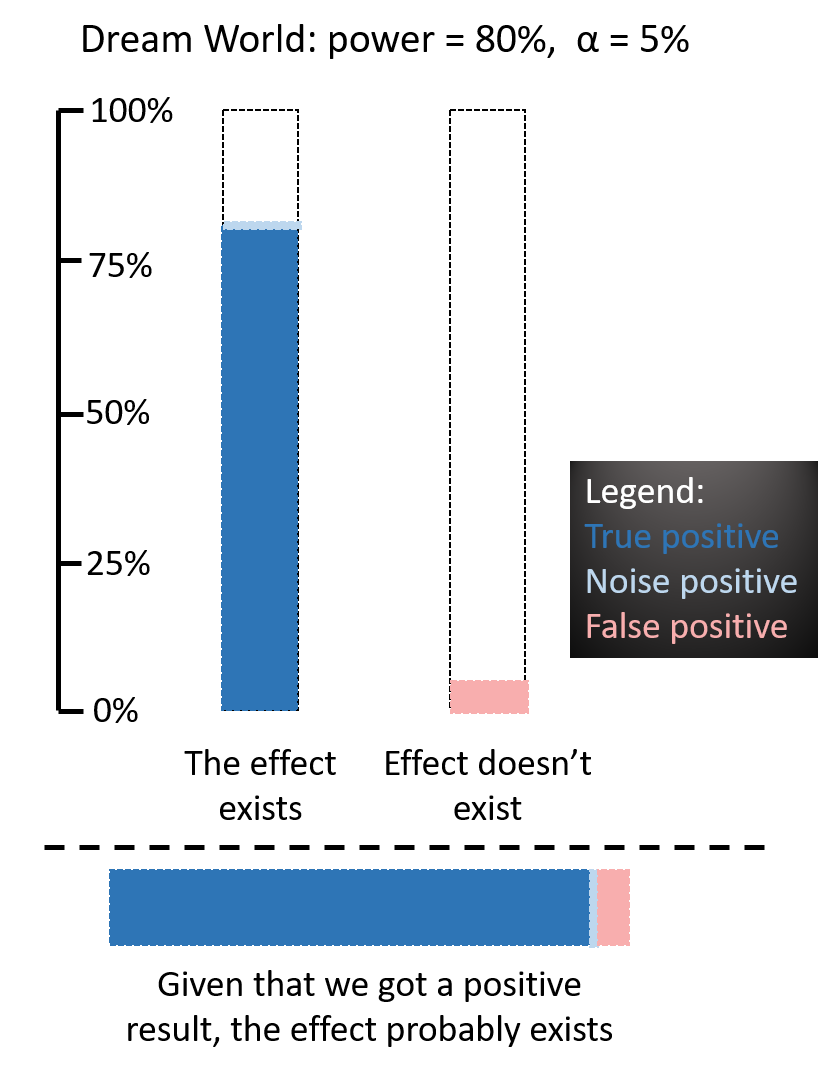
The dark blue region are true positives (80% of the time), and the light blue sliver (5% of the remaining 20% are 1%) is what I call a “noise positive”: you got a positive result that matches a real effect by coincidence. Basically, your experiment missed the true effect but you p-hacked your way into it.
[Edit 6/25: “noise positive” is a bad name, I should have called it “hacked positive”]
Of course, you don’t know if the effect exists or not ahead of time, you have to infer it from the result of the experiment.
If all you know is that you got a result, you know you’re somewhere in the colored regions. If you combine them (the horizontal bar), you see that “getting a result” is mostly made up of dark blue, which means “true results for an effect that exists”. The ratio of blue to red in the combined bar is a visual representation of the Bayesian likelihood ratio, which is a measure of how much support the data gives to the hypothesis that the measured effect exists versus the hypothesis that it doesn’t.
So that was the dream world. In the power posing world, the power is 13% and the false positive rate is (optimistically) 30%. Here’s how that looks like:
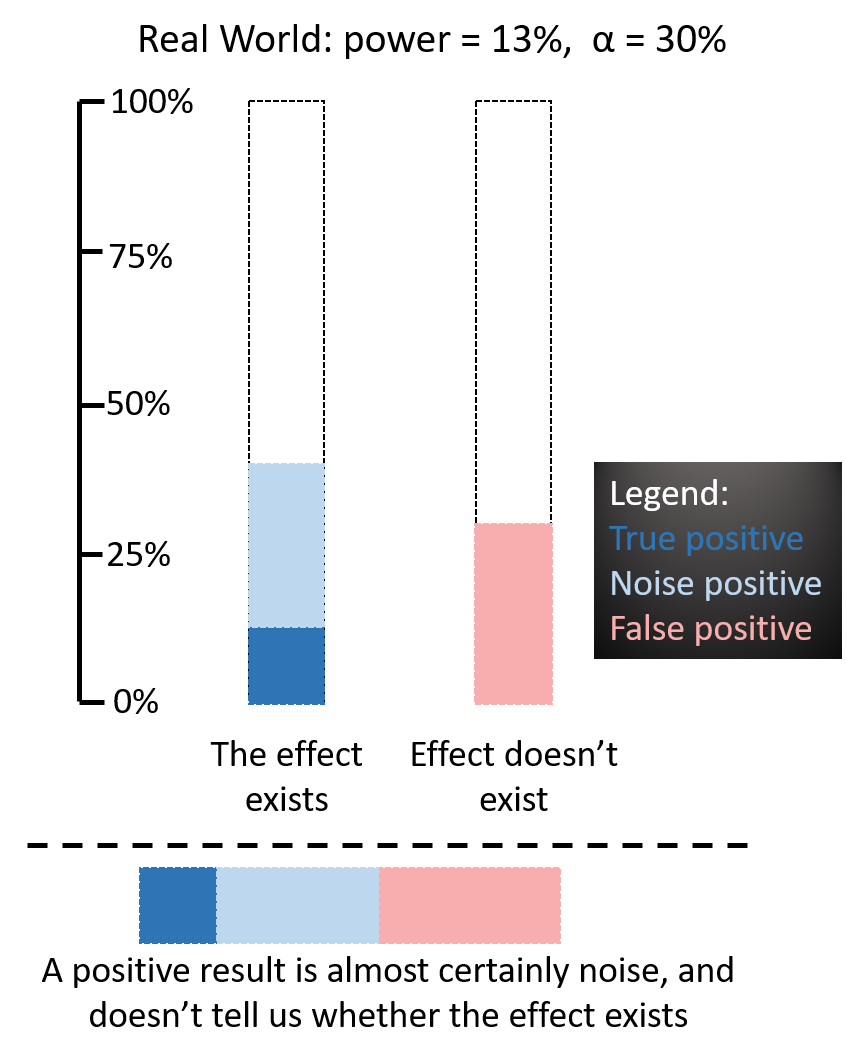
In this world, you can’t infer that the effect exists from the data: the red area is almost as big as the blue one. All you know is that most of what you measured is measurement error, aka noise.
I think some confusion stems from how statistical power is taught. For a given experimental setup, there is a trade-off of false positives (also called type I error) versus false negatives (type II, and the thing that statistical power directly refers to). But having lower statistical power makes both things worse and higher power makes both things better.
You increase power by having a large sample size combined with repeated and precise measurements. You get low power by having a sample size of 20 college students and measuring a wildly fluctuating hormone from a single spit tube. With a power of 13%, both the false positive rate and the false negative rate are going to be terrible no matter how you trade them off against each other.
Part 2 – Is psychology a science?
Part 1 was a careful explanation of a subject I know very well. Part 2 is a controversial rant about a subject I don’t. Take it for what it is, and please prove me wrong: I’ll be deeply grateful if you do.
What I didn’t mention about the confused young lady is that she’s a graduate student in psychology. From a top university. And she came to give a presentation about this excellent paper from 1990 about how everyone in psychology is doing bad statistics and ignoring statistical power.
You should read the Jacob Cohen paper, by the way. He’s everything I aspire to be when writing about research statistics: clear arguments combined with hilarious snark.
The atmosphere that characterizes statistics as applied in the social and biomedical sciences is that of a secular religion, apparently of Judeo—Christian derivation, as it employs as its most powerful icon a six-pointed cross [the asterisk * denotes p<0.05], often presented multiply for enhanced authority [** denotes p<0.01]. I confess that I am an agnostic.
I know that the psychology studies that show up on my Facebook feed or on Andrew Gelman’s blog are preselected for bad methodology. I thought that while bad statistics proliferated in psychology for decades (despite warnings by visionaries like Cohen), this ended in 2015 when the replicability crisis showed that barely 36% of finding in top psych journals replicate. Some entrenched psychologists who built their careers on p-hacked false findings may gripe about “methodological terrorists“, but surely the young generation will wise up to the need for proper methodology, the least of which is doing a power calculation.
And yet, here I was talking to a psychology student who came to give a presentation about statistical power and had the following, utterly stupefying, exchange:
Me: So, how did you calculate statistical power in your own research?
Her: What do you mean ‘how we calculated it’?
Me: The statistical power of your experiment, how did you arrive at it?
Her: Oh, our research was inspired by a previous paper. They said their power was 80%, so we said the same.
This person came to present a paper detailing the ways in which psychologists fuck up their methodology, and yet was utterly uninterested in actually doing the methodology. When I gave her the quick explanation of how power works I wrote down in part 1 of this post, she seemed indifferent, as if all this talk of statistics and inference was completely irrelevant to her work as a psychology researcher.
This is mind boggling to me. I don’t have any good explanation for what actually went on in her head. But I have an explanation, and if it’s true it’s terrifying.
As centuries of alchemy, demonology and luminiferious aetherology have shown, the fact that smart people study a subject does not imply that the subject actually exists. I’m beginning to suspect that a whole lot of psychologist are studying effects that are purely imaginary.
Embodied cognition. Ego-depletion. Stereotype threat. Priming. Grit and growth mindset as malleable traits. Correlating political stances with 3 stages of ovulation, 5 personality traits, 6 body types, and 34 flavors of ice cream.
And we didn’t even mention fucking parapsychology.
By the way, when was the last time you saw a psychology article publicized that wasn’t in those areas? Yes, of course this young lady was pursuing her research in one them.
Perhaps these fields aren’t totally null, but their effects are too small or unstable to be studied given current constraints (e.g. sample sizes less than 10,000). Even if half those fields contain interesting and real phenomena, that leaves a lot of fields that don’t.
If you’re studying a nonexistent effect, there’s no point whatsoever in improving your methodology. It’s only going to hurt you! If you’re studying a nonexistent field, you write “our power is 80%” on the grant application because that’s how you get funded, not because you know what it means. Your brain will protect itself from actually finding out what a power calculation actually entails because it senses bad things lying in wait if you go there.
There are ways to study subjects with no physical reality, but the scientific method isn’t one of those ways. Example: you have the science of glaciology which involves drilling into glaciers, and you have the critical theory of feminist glaciology which involves doing something completely different:
Structures of power and domination also stimulated the first large-scale ice core drilling projects – these archetypal masculinist projects to literally penetrate glaciers and extract for measurement and exploitation the ice in Greenland and Antarctica.
Glaciologists and feminist glaciologists are not colleagues. They don’t sit in the same university departments, speak at the same conferences, or publish in the same journals. Nobody thinks that they’re doing the same job.
But people think that bad psychologists and good psychologists are doing the same job. And this drives the good ones away.
Imagine a psychology grad student with good intentions and a rudimentary understanding of statistics wandering into one of the above-mentioned research areas. She will quickly grow discouraged by getting null results and disillusioned by her unscrupulous colleagues churning out bullshit papers like “Why petting a donkey makes you vote Democrat, but only if your phone number ends in 7, p=0.049”.
This student isn’t going to stick around in academia very long. She’s going to take a quick data science boot camp and go work for Facebook or Amazon. There, she will finally get to work with smart colleagues doing rigorous psychological research using sophisticated statistical methodology.
But instead of probing the secrets of the mind for the benefit of humanity, she’ll be researching which font size makes people 0.2% more likely to retweet a meme.
And the academic discipline of psychology will drift one step further away from science and one step closer to the ugly void of postmodernism.
I’m not writing this out of disdain for psychology. I’m writing this out of love, and fear. I have been reading books on psychology and volunteering as a subject for experiments since I was a teenager. I considered majoring in psychology in undergrad, until the army told me I’m going to study physics instead. I occasionally drink with psychologists and tell them about p-hacking.
I’m scared that there’s a battle going on for the heart of psychology right now, between those who want psychology to be a science and those for whom that would be inconvenient.
And I’m scared that the good guys aren’t winning.

0 comments
Comments sorted by top scores.