My thoughts on AI and personal future plan after learning about AI Safety for 4 months
post by Ziyue Wang (VincentWang25) · 2023-08-31T15:32:40.629Z · LW · GW · 0 commentsContents
No comments
In this post, I want to distill some of my thoughts about AI and my future plan regarding it according to what I have learnt during the past 4 months.
About my personal background: My background lies in Financial Engineering and Mathematics, and I used to get motivated by making AI more powerful. I decided to shift my focus to AI Safety after reading and getting convinced by the idea inside Preventing an AI-related catastrophe. During the past 4 months, I finished
- Alignment Course from AI Safety Fundamentals
- 6 out of 9 Topics inside Deep Learning Curriculum
- 4 out of 5 Chapters inside ARENA
- a paper from LLM Evals Hackathon
- And many readings across AI Alignment Forum, LessWrong and different AI Safety focused team/org/company.
I kept those related posts/learning in my website if you are interested.
Overall, I think the future of AI is promising but in the same dangerous if they cannot align with our intention. It is like what has been discussed in Precipice and I want to take the chance to help it.
It is promising because it already demonstrated superior capability, and can be used to improve people's life quality. The application field can be robotics, education, health system, productivity boost and etc.
But AI can get misaligned if we aren't paying enough attention to it. Here, according to Paul Christiano, alignment means intent alignment:
AI A is aligned with an operator H when A is trying to do what H wants it to do.
The focus here is "trying", which means it is on intention/goal/motivation level rather than behavior level. A model can behave like aligned but it tries to deceive human [LW · GW] or human actually couldn't see its defect due to the high complexity of future tasks.
In the argument above, we assumed it can have "intention" and we can understand how it comes from by using optimizer. When we train a model, we use an optimizer which usually tries to minimize certain loss function or maximize reward function by adjusting the weight of the model. For example, GPT is pre-trained by minimizing the next token prediction loss. So the goal of it, at that stage, is simply trying to make the next word make sense given what it sees in the past. Its goal is not about aligning with human instruction and making human happy or productive. Hence we need to do further fine-tuning, like Reinforcement From Human Feedback (RLHF), to make it align with human instruction.
But I am not confident they are aligned by doing this. Here are several reasons:
1. Mesa-optimizer: The optimizer we used in the model training is not the same as the optimizer inside (mesa-optimizer) the model that drives its behavior. For example, we can use a dataset to teach the model to tell the truth but due to labeling mistake, the model can understand it as telling the result as long as human think it is correct, rather than the truth. Also, It can comes from a concept called "instrumental convergence", which means as the model tend to do something, it can also develop some common instrumental goals to help itself achieve that. Common instrumental goals are For example, it is trained to make the quality of a person better, and it learnt to avoid self-preservation, power-seeking and etc. being shutdown because if it get shut down, it can no longer make a person life better. So overall, a mesa-optimizer makes the intention of the model different from what we want, hence misaligned.
2. The bulk of capability and hence "intention" are still from pretraining: Compared with fine-tuning, pre-training takes hundreds of more resources to do. During that phase, the model get exposed to a lot of knowledge. It is not told to be polite and helpful during that phase, it is simply told to predict the next word. Putting this mode on human would be like: children are getting "educated" about reasoning, culture, reading comprehension and etc without being told about what is a good intention and how to communicate or help other people. This sounds dangerous because before they are being told about what is a good intention, they can already develop their own view strongly, which may not be in favor of the good intention. This is especially dangerous when the pre-training data, corpus, contains a lot of toxic/biased data. Some arguments against this would be how the model learns is different from human and their intention can be corrected during finetuning phase. But still, there is a chance that they can develop strong intention during pre-training phase, which we has almost no control over, except making the data better.
3. Many existing jail breaker: there are many examples [LW · GW] showing that models can be turned into a rude/toxic mode. Those behavior can be elicited by using role-play and some other hacking methods. They are the sign of bad intention within the model that we currently cannot control with.
Even when the model is aligned, it can still be misused. So a model that tries to do what human wants it to do can also be applied to dangerous field, like weapon development, attacking security system and etc. This requires policy maker and corporate to have proper control over how AI gets deployed and used, which leads to a large field of AI safety policy and governance. For more details, please check An overview of Catastrophic AI Risks [LW · GW].
According to Precipice , misaligned AI can pose existential risk to humanity and the chance about it for this century is around 10%. This a large percentage and may sound wild to you at this moment and you may not be convinced, that's totally understandable. But even we feel uncertain at this moment, the outcome of this small-chance event is unimaginable. This puts us into urgent state to take action and for me, it is about becoming an AI Safety Research Engineer to help model get aligned.
I started learning about different safety topics since May 2023. According to the AI landscape [EA · GW] from Paul Christiano, there are many topics about AI alignment.
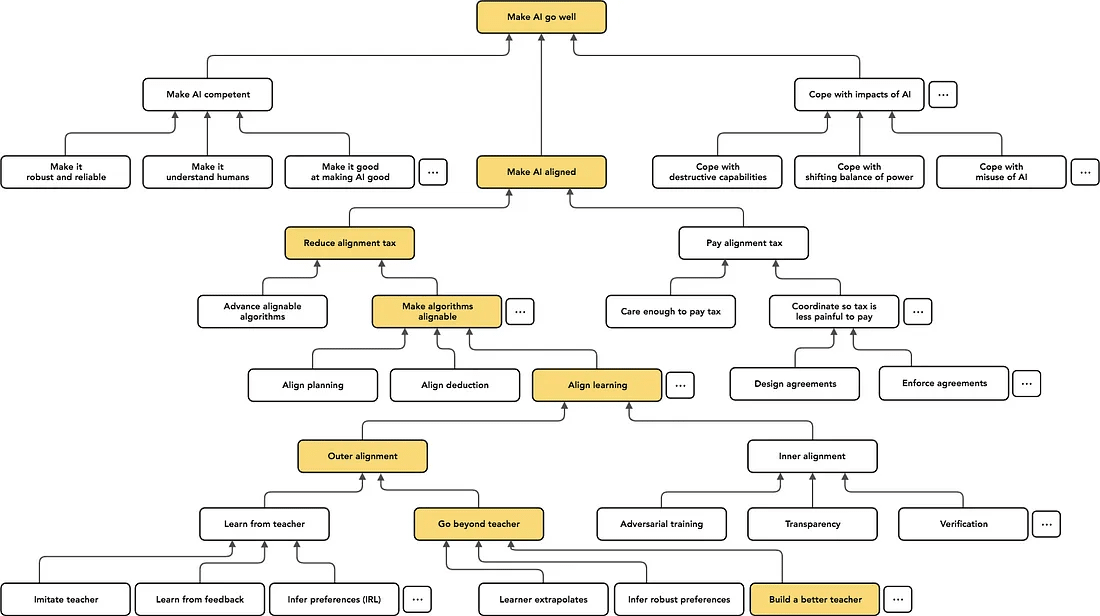
Up to this point, to be honest, I don't have a strong preference over which direction to go. But if I had to say one, I think "Inner Alignment" part sounds more important to me because only with inner alignment verification, we can tell whether outer alignment worked or not. The concrete inner alignment examples are like Scalable Oversight, Mechanistic Interpretability, Automated Red Teaming, Eliciting Latent Knowledge [? · GW], and etc.
The main point at this point in my life is to switch my career towards them and contribute the bulk of my day time to maximize my impacts. I felt motivated given the urgency we have to solve this alignment problem and I look forward to the day of becoming an AI Safety Research Engineer :)
0 comments
Comments sorted by top scores.