Superintelligence 29: Crunch time
post by KatjaGrace · 2015-03-31T04:24:41.788Z · LW · GW · Legacy · 27 commentsContents
Summary Another view Notes 1. Replaceability 2. When should different AI safety work be done? 3. Review 4. What to do? In-depth investigations How to proceed None 27 comments
This is part of a weekly reading group on Nick Bostrom's book, Superintelligence. For more information about the group, and an index of posts so far see the announcement post. For the schedule of future topics, see MIRI's reading guide.
Welcome. This week we discuss the twenty-ninth section in the reading guide: Crunch time. This corresponds to the last chapter in the book, and the last discussion here (even though the reading guide shows a mysterious 30th section).
This post summarizes the section, and offers a few relevant notes, and ideas for further investigation. Some of my own thoughts and questions for discussion are in the comments.
There is no need to proceed in order through this post, or to look at everything. Feel free to jump straight to the discussion. Where applicable and I remember, page numbers indicate the rough part of the chapter that is most related (not necessarily that the chapter is being cited for the specific claim).
Reading: Chapter 15
Summary
- As we have seen, the future of AI is complicated and uncertain. So, what should we do? (p255)
- Intellectual discoveries can be thought of as moving the arrival of information earlier. For many questions in math and philosophy, getting answers earlier does not matter much. Also people or machines will likely be better equipped to answer these questions in the future. For other questions, e.g. about AI safety, getting the answers earlier matters a lot. This suggests working on the time-sensitive problems instead of the timeless problems. (p255-6)
- We should work on projects that are robustly positive value (good in many scenarios, and on many moral views)
- We should work on projects that are elastic to our efforts (i.e. cost-effective; high output per input)
- Two objectives that seem good on these grounds: strategic analysis and capacity building (p257)
- An important form of strategic analysis is the search for crucial considerations. (p257)
- Crucial consideration: idea with the potential to change our views substantially, e.g. reversing the sign of the desirability of important interventions. (p257)
- An important way of building capacity is assembling a capable support base who take the future seriously. These people can then respond to new information as it arises. One key instantiation of this might be an informed and discerning donor network. (p258)
- It is valuable to shape the culture of the field of AI risk as it grows. (p258)
- It is valuable to shape the social epistemology of the AI field. For instance, can people respond to new crucial considerations? Is information spread and aggregated effectively? (p258)
- Other interventions that might be cost-effective: (p258-9)
- Technical work on machine intelligence safety
- Promoting 'best practices' among AI researchers
- Miscellaneous opportunities that arise, not necessarily closely connected with AI, e.g. promoting cognitive enhancement
- We are like a large group of children holding triggers to a powerful bomb: the situation is very troubling, but calls for bitter determination to be as competent as we can, on what is the most important task facing our times. (p259-60)
Another view
Alexis Madrigal talks to Andrew Ng, chief scientist at Baidu Research, who does not think it is crunch time:
Andrew Ng builds artificial intelligence systems for a living. He taught AI at Stanford, built AI at Google, and then moved to the Chinese search engine giant, Baidu, to continue his work at the forefront of applying artificial intelligence to real-world problems.
So when he hears people like Elon Musk or Stephen Hawking—people who are not intimately familiar with today’s technologies—talking about the wild potential for artificial intelligence to, say, wipe out the human race, you can practically hear him facepalming.
“For those of us shipping AI technology, working to build these technologies now,” he told me, wearily, yesterday, “I don’t see any realistic path from the stuff we work on today—which is amazing and creating tons of value—but I don’t see any path for the software we write to turn evil.”
But isn’t there the potential for these technologies to begin to create mischief in society, if not, say, extinction?
“Computers are becoming more intelligent and that’s useful as in self-driving cars or speech recognition systems or search engines. That’s intelligence,” he said. “But sentience and consciousness is not something that most of the people I talk to think we’re on the path to.”
Not all AI practitioners are as sanguine about the possibilities of robots. Demis Hassabis, the founder of the AI startup DeepMind, which was acquired by Google, made the creation of an AI ethics board a requirement of its acquisition. “I think AI could be world changing, it’s an amazing technology,” he told journalist Steven Levy. “All technologies are inherently neutral but they can be used for good or bad so we have to make sure that it’s used responsibly. I and my cofounders have felt this for a long time.”
So, I said, simply project forward progress in AI and the continued advance of Moore’s Law and associated increases in computers speed, memory size, etc. What about in 40 years, does he foresee sentient AI?
“I think to get human-level AI, we need significantly different algorithms and ideas than we have now,” he said. English-to-Chinese machine translation systems, he noted, had “read” pretty much all of the parallel English-Chinese texts in the world, “way more language than any human could possibly read in their lifetime.” And yet they are far worse translators than humans who’ve seen a fraction of that data. “So that says the human’s learning algorithm is very different.”
Notice that he didn’t actually answer the question. But he did say why he personally is not working on mitigating the risks some other people foresee in superintelligent machines.
“I don’t work on preventing AI from turning evil for the same reason that I don’t work on combating overpopulation on the planet Mars,” he said. “Hundreds of years from now when hopefully we’ve colonized Mars, overpopulation might be a serious problem and we’ll have to deal with it. It’ll be a pressing issue. There’s tons of pollution and people are dying and so you might say, ‘How can you not care about all these people dying of pollution on Mars?’ Well, it’s just not productive to work on that right now.”
Current AI systems, Ng contends, are basic relative to human intelligence, even if there are things they can do that exceed the capabilities of any human. “Maybe hundreds of years from now, maybe thousands of years from now—I don’t know—maybe there will be some AI that turn evil,” he said, “but that’s just so far away that I don’t know how to productively work on that.”
The bigger worry, he noted, was the effect that increasingly smart machines might have on the job market, displacing workers in all kinds of fields much faster than even industrialization displaced agricultural workers or automation displaced factory workers.
Surely, creative industry people like myself would be immune from the effects of this kind of artificial intelligence, though, right?
“I feel like there is more mysticism around the notion of creativity than is really necessary,” Ng said. “Speaking as an educator, I’ve seen people learn to be more creative. And I think that some day, and this might be hundreds of years from now, I don’t think that the idea of creativity is something that will always be beyond the realm of computers.”
And the less we understand what a computer is doing, the more creative and intelligent it will seem. “When machines have so much muscle behind them that we no longer understand how they came up with a novel move or conclusion,” he concluded, “we will see more and more what look like sparks of brilliance emanating from machines.”
Andrew Ng commented:
Enough thoughtful AI researchers (including Yoshua Bengio, Yann LeCun) have criticized the hype about evil killer robots or "superintelligence," that I hope we can finally lay that argument to rest. This article summarizes why I don't currently spend my time working on preventing AI from turning evil.
Notes
1. Replaceability
'Replaceability' is the general issue of the work that you do producing some complicated counterfactual rearrangement of different people working on different things at different times. For instance, if you solve a math question, this means it gets solved somewhat earlier and also someone else in the future does something else instead, which someone else might have done, etc. For a much more extensive explanation of how to think about replaceability, see 80,000 Hours. They also link to some of the other discussion of the issue within Effective Altruism (a movement interested in efficiently improving the world, thus naturally interested in AI risk and the nuances of evaluating impact).
2. When should different AI safety work be done?
For more discussion of timing of work on AI risks, see Ord 2014. I've also written a bit about what should be prioritized early.
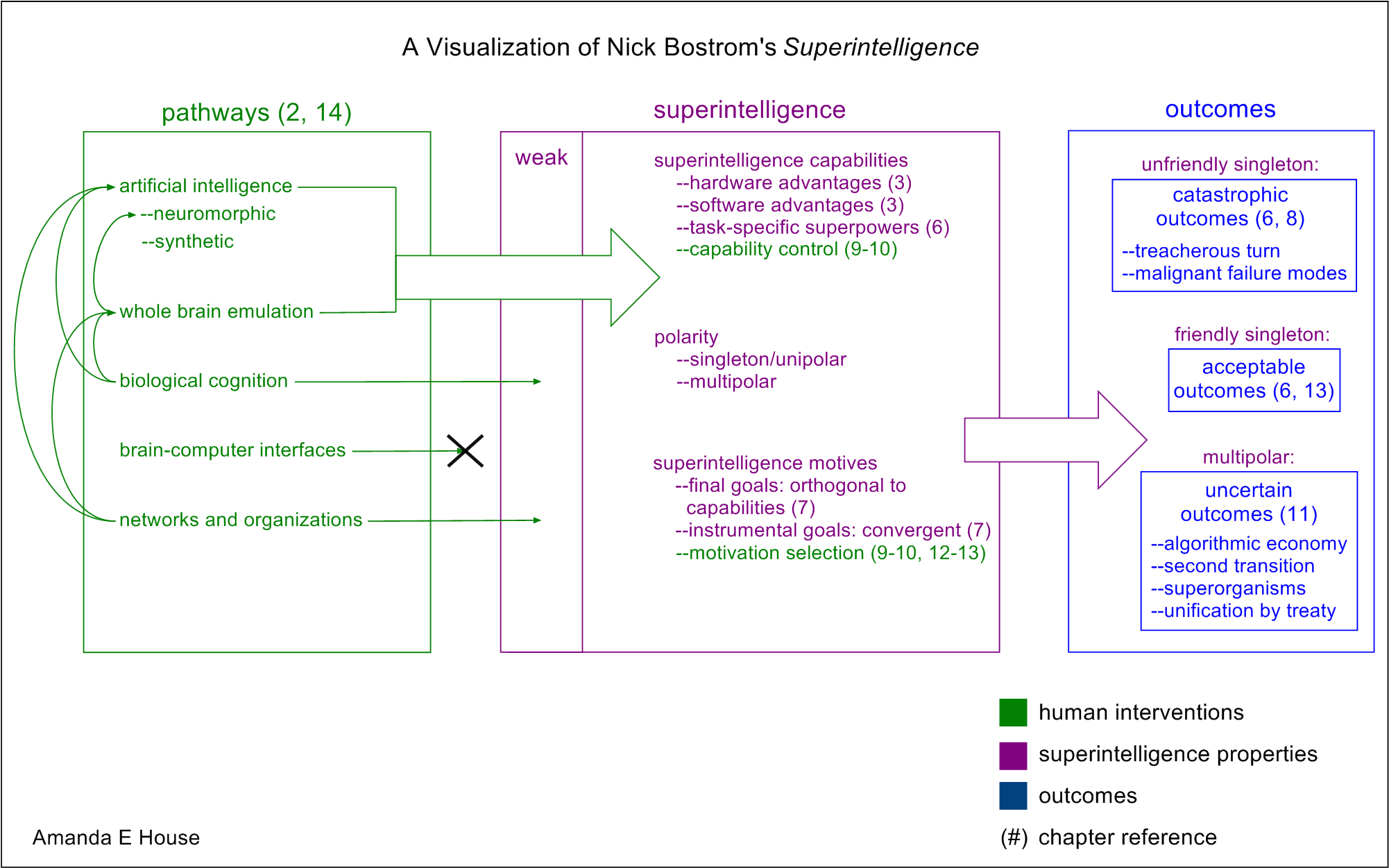
3. Review
If you'd like to quickly review the entire book at this point, Amanda House has a summary here, including this handy diagram among others:
4. What to do?
If you are convinced that AI risk is an important priority, and want some more concrete ways to be involved, here are some people working on it: FHI, FLI, CSER, GCRI, MIRI, AI Impacts (note: I'm involved with the last two). You can also do independent research from many academic fields, some of which I have pointed out in earlier weeks. Here is my list of projects and of other lists of projects. You could also develop expertise in AI or AI safety (MIRI has a guide to aspects related to their research here; all of the aforementioned organizations have writings). You could also work on improving humanity's capacity to deal with such problems. Cognitive enhancement is one example. Among people I know, improving individual rationality and improving the effectiveness of the philanthropic sector are also popular. I think there are many other plausible directions. This has not been a comprehensive list of things you could do, and thinking more about what to do on your own is also probably a good option.
In-depth investigations
If you are particularly interested in these topics, and want to do further research, these are a few plausible directions, some inspired by Luke Muehlhauser's list, which contains many suggestions related to parts of Superintelligence. These projects could be attempted at various levels of depth.
- What should be done about AI risk? Are there important things that none of the current organizations are working on?
- What work is important to do now, and what work should be deferred?
- What forms of capability improvement are most useful for navigating AI risk?
How to proceed
This has been a collection of notes on the chapter. The most important part of the reading group though is discussion, which is in the comments section. I pose some questions for you there, and I invite you to add your own. Please remember that this group contains a variety of levels of expertise: if a line of discussion seems too basic or too incomprehensible, look around for one that suits you better!
This is the last reading group, so how to proceed is up to you, even more than usually. Thanks for joining us!
27 comments
Comments sorted by top scores.
comment by KatjaGrace · 2015-03-31T04:31:31.292Z · LW(p) · GW(p)
Does anyone know of a good short summary of the case for caring about AI risk?
Replies from: ciphergoth, Squark↑ comment by Paul Crowley (ciphergoth) · 2015-04-06T15:58:05.582Z · LW(p) · GW(p)
It's very surprising to me that this doesn't exist yet. I hope everyone reading this and noticing the lack of answers starts writing their own answer—that way we should get at least one really good one.
comment by KatjaGrace · 2015-03-31T04:27:58.991Z · LW(p) · GW(p)
Do you agree with Bostrom that humanity should defer non-urgent scientific questions, and work on time-sensitive issues such as AI safety?
Replies from: William_S, diegocaleiro↑ comment by William_S · 2015-04-04T21:38:49.373Z · LW(p) · GW(p)
I agree in general, but there's a lot more things than just AI safety that ought to be worked on more (ie. research on neglected diseases), and today's AI safety research might reach diminishing returns quickly because we are likely some time away from reaching human level AI. There's a funding level for AI safety research where I'd want to think about whether it was too much. I don't think we've reached that point quite yet, but it's probably worth keeping track of the marginal impact of new AI research dollars/researchers to see if it falls off.
↑ comment by diegocaleiro · 2015-03-31T06:23:45.355Z · LW(p) · GW(p)
Should the violin players at Titanic have stopped playing the violin and tried to save more lives?
What if they could have saved thousands of Titanics each? What if there already was such a technology that could play a deep sad violin song on the background, and project holograms of violin players playing in deep sorrow as the ship sank.
At some point, it becomes obvious that doing the consequentialist thing is the right thing to do. The question is whether the reader believes 2015 humanity has already reached that point or not.
We already produce beauty, art, truth, humor, narratives and knowledge at a much faster pace than we can consume. The ethical grounds on which to act in any non-consequentialist ways have lost much of their strenght.
comment by KatjaGrace · 2015-03-31T04:28:45.453Z · LW(p) · GW(p)
Are you concerned about AI risk? Do you do anything about it?
Replies from: Sebastian_Hagen, timeholmes↑ comment by Sebastian_Hagen · 2015-03-31T21:25:42.551Z · LW(p) · GW(p)
It's the most important problem of this time period, and likely human civilization as a whole. I donate a fraction of my income to MIRI.
↑ comment by timeholmes · 2015-04-02T22:37:00.437Z · LW(p) · GW(p)
I'm very concerned with the risk, which I feel is at the top of catastrophic risks to humanity. With an approaching asteroid at least we know what to watch for! As an artist, I've been working mostly on this for the last 3 years, (see my TED talk "The Erotic Crisis", on YouTube) trying to think of ways of raise awareness and engage people in dialog. The more discussion the better I feel! And I'm very grateful for this forum and all who participated!
comment by PhilGoetz · 2015-04-01T03:25:57.757Z · LW(p) · GW(p)
An important form of strategic analysis is the search for crucial considerations. (p257) Crucial consideration: idea with the potential to change our views substantially, e.g. reversing the sign of the desirability of important interventions. (p257)
Yes, but... a "crucial consideration" is then an idea that runs counter to answers we already feel certain about to important questions. This means that we should not just be open-minded, but should specially seek out other opinions on the matters we are most confident about.
How can you do this without being obliged to consider what seem to you like crackpot theories?
comment by KatjaGrace · 2015-03-31T04:30:46.231Z · LW(p) · GW(p)
Did you disagree with anything in this chapter?
comment by KatjaGrace · 2015-03-31T04:29:27.856Z · LW(p) · GW(p)
Are there things that someone should maybe be doing about AI risk that haven't been mentioned yet?
Replies from: PhilGoetz, timeholmes↑ comment by PhilGoetz · 2015-04-01T03:13:30.613Z · LW(p) · GW(p)
The entire approach of planning a stable ecosystem of AIs that evolve in competition, rather than one AI to rule them all and in the darkness bind them, was dismissed in the middle of the book with a few pages amounting to "it could be difficult".
↑ comment by timeholmes · 2015-04-02T22:24:27.020Z · LW(p) · GW(p)
Human beings suffer from a tragic myopic thinking that gets us into regular serious trouble. Fortunately our mistakes so far have so far don't quite threaten our species (though we're wiping out plenty of others.) Usually we learn by hindsight rather than robust imaginative caution; we don't learn how to fix a weakness until it's exposed in some catastrophe. Our history by itself indicates that we won't get AI right until it's too late, although many of us will congratulate ourselves that THEN we see exactly where we went wrong. But with AI we only get one chance.
My own fear is that the crucial factor we miss will not be some item like an algorithm that we figured wrong but rather will have something to do with the WAY humans think. Yes we are children playing with terrible weapons. What is needed is not so much safer weapons or smarter inventors as a maturity that would widen our perspective. The indication that we have achieved the necessary wisdom will be when our approach is so broad that we no longer miss anything; when we notice that our learning curve overtakes our disastrous failures. When we no longer are learning in hindsight we will know that the time has come to take the risk on developing AI. Getting this right seems to me the pivot point on which human survival depends. And at this point it's not looking too good. Like teenage boys, we're still entranced by the speed and scope rather than the quality of life. (Like in our heads we still compete in a world of scarcity instead of stepping boldly into a cooperative world of abundance that is increasingly our reality.)
Maturity will be indicated by a race who, rather than striving to outdo the other guy, are dedicated to helping all creatures live more richly meaningful lives. This is the sort of lab condition that would likely succeed in the AI contest rather than nose-diving us into extinction. I feel human creativity is a God-like gift. I hope it is not what does us in because we were too powerful for our own good.
comment by KatjaGrace · 2015-03-31T04:25:56.678Z · LW(p) · GW(p)
This is the last Superintelligence Reading Group. What did you think of it?
Replies from: HedonicTreader, timeholmes, almostvoid↑ comment by HedonicTreader · 2015-04-01T15:14:47.553Z · LW(p) · GW(p)
I had nothing of value to add to the discussion, but I found the summaries and alternate views outlines useful.
↑ comment by timeholmes · 2015-04-02T22:40:11.083Z · LW(p) · GW(p)
Very helpful! Thank you, Katja, for your moderation and insights. I will be returning often to reread portions and follow links to more. I hope there will be more similar opportunities in the future!
↑ comment by almostvoid · 2015-03-31T09:08:38.405Z · LW(p) · GW(p)
the concept was great fantastic delirious to me even. the book itself showed how anglo-american logic can get totally lost in its own myriad paradigm defined logic maze and loose sight of the trees and the redefine the forest. All the maybe spinoffs were totally irrelevant as primary causes-field-events. Hardly anything [in the book not the conversation here] mentioned really intelligence artificial or otherwise. Nor was human senescence alluded to to create an avenue how AIs might progress. Sentience was truly thin on the ground. More about un-related conceptualizations that belonged to a degree to thought-experiments that really should have been appendixed. And most books in this field all repeat each other. We don't seem to be making -as a human race- much progress because I think we are doing this all wrong. Like the early aeronauts who flapped wings trying to fly like birds. Until the propeller was used and we had lift-off. Personally we will never have Ais because our brains are quantum processors with sentient mind-full-ness. The latter is specific to our race. This cannot be-as such duplicated. It is a generated field-wave-mind-set that defines us as we conceptualize. Of course AIs can mimic. They might even become DALEKS. Happy Easter as I dive into the Void.
comment by AlexMennen · 2015-03-31T20:28:05.653Z · LW(p) · GW(p)
Bostrom mentioned that we should prefer to work on projects that are robustly benefitial given a wide range of assumptions, rather than merely benefitial in expectation. But this sounds to me like ambiguity aversion, which is usually undesirable. On the other hand, paying attention to robustness as well as expected value could make sense if we have biases that lead us to overestimate the benefits and underestimate the harms of our interventions, which would lead us to overrate non-robust interventions. This seems plausible, but Bostrom did not make that case.
comment by KatjaGrace · 2015-03-31T04:35:52.581Z · LW(p) · GW(p)
Bostrom quotes a colleague saying that a Fields medal indicates two things: that the recipient was capable of accomplishing something important, and that he didn't. Should potential Fields medalists move into AI safety research?
Replies from: diegocaleiro↑ comment by diegocaleiro · 2015-03-31T06:15:20.568Z · LW(p) · GW(p)
Why not actual fields medalists?
Tim Ferris lays out a guide for how to learn anything really quickly, which involves contacting whoever was great at that ten years ago and asking them who is great that should not be.
Doing that for field medalists and other high achievers is plausibly extremely high value.
Replies from: TheAncientGeek↑ comment by TheAncientGeek · 2015-03-31T09:18:49.934Z · LW(p) · GW(p)
Why not actual fields medalists?
Engineers would be more useful if it really is crunch time.
comment by KatjaGrace · 2015-03-31T04:32:26.596Z · LW(p) · GW(p)
The claim on p257 that we should try to do things that are robustly positive seems contrary to usual consequentialist views, unless this is just a heuristic for maximizing value.
comment by KatjaGrace · 2015-03-31T04:26:38.362Z · LW(p) · GW(p)
Did Superintelligence change your mind on anything?
comment by PhilGoetz · 2015-04-01T03:10:23.952Z · LW(p) · GW(p)
For many questions in math and philosophy, getting answers earlier does not matter much.
I disagree completely. Looking at all of the problems to solve, the one area that lags noticeably behind in its duties is philosophy. The hardest questions raised in Superintelligence are philosophical problems of value, of what we even mean by "value". I believe that philosophy must be done by scientists, since we need to find actual answers to questions. For example, one could understand nothing of ethics without first understanding evolution. So it's true that philosophical advances rely on scientific ones. But philosophers haven't even learned how to ask testable questions or frame hypotheses yet. The ideal allocation of resources, if a world dictator were inclined to reduce existential risk, would be to slow all scientific advance and wait for philosophy to catch up with it. Additionally, philosophy presents fewer existential risks than any (other?) science.
comment by William_S · 2015-04-05T02:31:17.162Z · LW(p) · GW(p)
I think that Andrew Ng's position is somewhat reasonable, especially applied to technical work - it does seem like human level AI would require some things we don't understand, which makes the technical work harder before those things are known (though I don't agree that there's no value in technical work today). However, the tone of the analogy to "overpopulation on Mars" leaves the question as to at what point the problem transitions to "something we can't make much progress on today" to "something we can make progress on today". Martian overpopulation would have pretty clear signs when it's a problem, whereas it's quite plausible that the point where technical AI work becomes tractable will not be obvious, and may occur after the point where it's too late to do anything.
I wonder if it would be worth developing and promoting a position that is consistent with technical work seeming intractible and non-urgent today, but with a more clearly defined point where it becomes something worth working on (ie. AI passes some test of human like performance, some well-defined measure of expert opinion says human level AI is X-years off). In principle, this seems like it would be low cost for an AI researcher to adopt this sort of position (though in practice, it might be rejected if AI researchers really believes that dangerous AI is too weird and will never happen).