Paradigm-building: Conclusion and practical takeaways
post by Cameron Berg (cameron-berg) · 2022-02-15T16:11:08.985Z · LW · GW · 1 commentsContents
Recapping the sequence Practical takeaways and next steps None 1 comment
Recapping the sequence
Many thanks for reading this sequence all the way through! Recall this chart from the introductory post [LW · GW]:
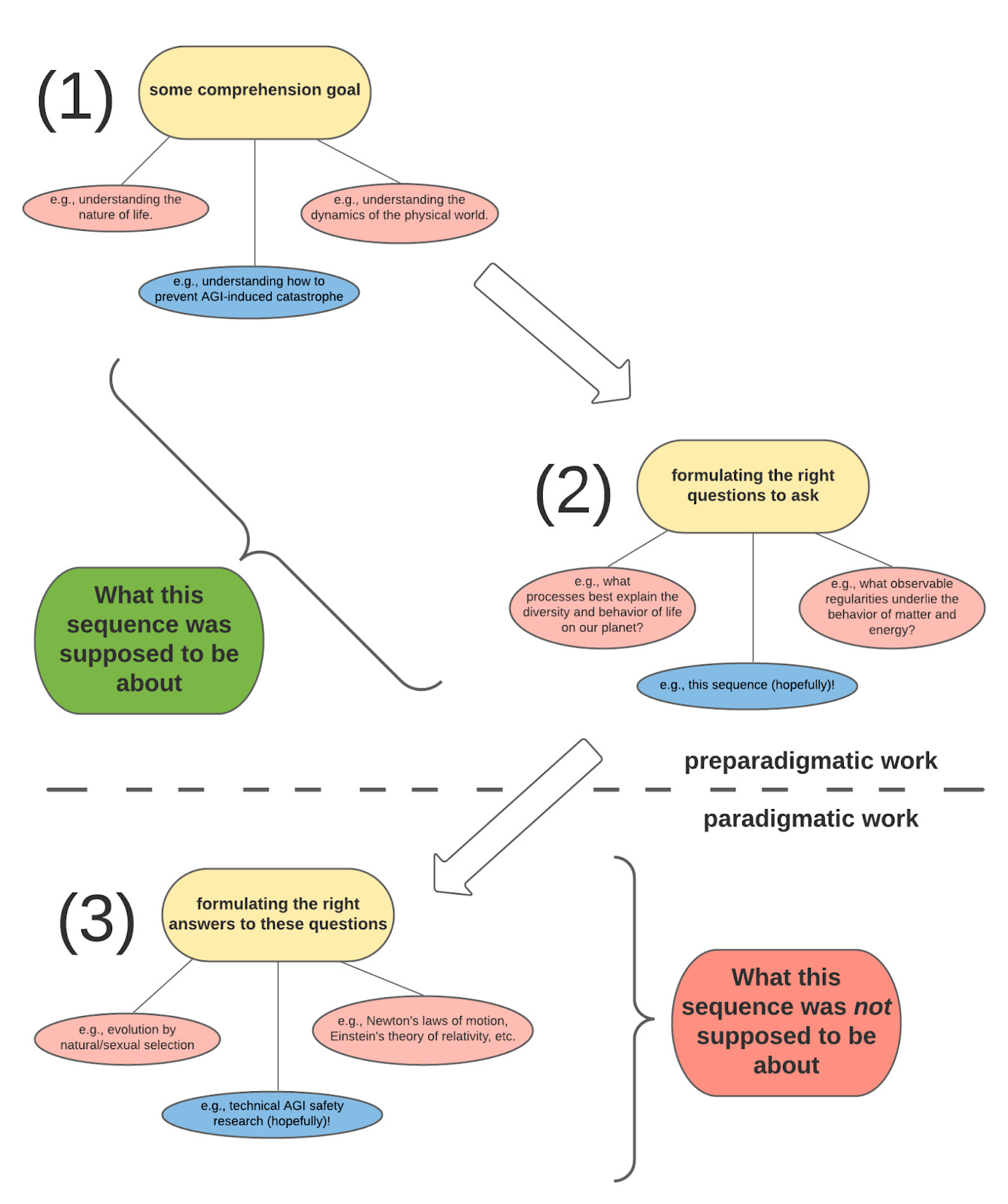
I’ve added some labels to clarify what this sequence was intended (and not intended) to cover. Namely, I take seriously John Wentworth’s claim [AF · GW] that AGI safety research is still in a preparadigmatic phase; accordingly, my goal in this sequence was to sketch the space of plausible frameworks for doing technical safety work, starting from first principles, in an attempt to supply the field with a functional and coherent paradigm. Ultimately, I have presented this as a hierarchical series of questions:
- What is the predicted architecture of the learning algorithm(s) used by AGI?
- What are the most likely bad outcomes of this learning architecture?
- What are the control proposals for minimizing these bad outcomes?
- What are the implementation proposals for these control proposals?
- What is the predicted timeline for the development of AGI?
Surely the boldest claim of this sequence is that these are the right questions to ask—that there is no future in which AGI safety research succeeds without having answered these questions. Though I do believe later questions rely in large part on answers to earlier questions, I do not think it is impossible to make any progress on the later questions—and therefore, that safety research must start paying attention to all of these questions as soon as possible.
I am certain that this framework is still a work in progress, no doubt containing mistakes and ambiguities that require further adjudication (if you think you have found some of either, please leave a comment on the relevant part of the sequence!). My hope is that this framework ultimately represents a logically coherent and methodologically useful synthesis of the wide array of perspectives currently on offer in safety work. As I discussed earlier [LW · GW], I also think that this sequence can be read as a low-resolution prediction about what the end-to-end progress of the field will end up looking like when all is said and done.
Practical takeaways and next steps
I also envision this framework serving as a practical communication tool that enables researchers to speak ‘across the valley’ of (sometimes radically) different priors. I imagine safety research would be far better understood and miscommunications more quickly diffused if researchers included something roughly like this at the very beginning of their technical work:
My priors:
- Predicted architecture: human-level weak online SL (with some RL).
- Bad outcomes of interest: inner misalignment, instrumental convergence.
- Control proposals of interest: imitation via amplification; installing human-like social cognition.
- Implementation proposals of interest: maximal facilitation; minimal incentivization.
- AGI development timeline: ~20 years (three iteratively-stable breakthroughs to go).
- Evolution of my views: I used to be more agnostic w.r.t. learning architecture, but now I am far more confident that AGI will exhibit SL.
(This is just an example—these are definitely not my priors.)
Succinct and systemized announcements of researchers’ priors headering their technical work would be proactively clarifying, both to their readers and to themselves. This would also enable a kind of (hopefully) comprehensive organizational system that would make researchers’ work far easier to constellate within the broader trends of the field.
In this same vein, another future direction for this work would be to periodically poll current AGI safety researchers along the lines of this sequence’s framework in order to get a better sense of the dominant technical research being conducted within the field. Surveys of this sort would help elucidate, both within and across the questions in this sequence’s framework, which areas are well-studied and which are less so.
For example, within the specific question of predicted learning architecture, we might find that only 15% of researchers are conducting online-learning-based safety work. Across questions, we may discover that far fewer people are working on implementation proposals as compared to control proposals. Data of this sort seems highly necessary for properly calibrating field-level dynamics.
As was discussed in Paradigm-building from first principles [LW · GW], I believe the ultimate goal of AGI safety research is something like mitigating AGI-induced existential risks. My hope is that the framework presented in this sequence will contribute to this outcome by enumerating the questions that necessarily must be answered before it becomes possible to achieve this goal.
As always, if you have any questions, comments, objections, etc., please don’t hesitate to email me—or simply leave a comment on whichever post in the sequence is most relevant to your idea. Thanks very much for reading!
1 comments
Comments sorted by top scores.
comment by Koen.Holtman · 2022-02-17T16:55:15.296Z · LW(p) · GW(p)
Just want to say: I read the whole sequence and enjoyed reading it.