Paradigm-building from first principles: Effective altruism, AGI, and alignment
post by Cameron Berg (cameron-berg) · 2022-02-08T16:12:26.423Z · LW · GW · 5 commentsContents
Introduction ‘First-principles’ EA and AGI: a survey of the landscape The good The less-good AGI will be good and less-good EA and AGI in practice: existential risk reduction Human alignment and AGI alignment are importantly different Individual vs. collective alignment The human alignment problem Summary None 5 comments
Introduction
If we are interested in the theoretical foundations that motivate work in AGI safety research, it seems worthwhile to clarify the philosophical and practical relationships of big-picture ideas in effective altruism [? · GW] (EA) to AGI in general and to AGI safety research in particular. One straightforward reason that this exercise is worthwhile is that much of current AGI safety work is funded through EA-aligned entities like Open Philanthropy, the Long-Term Future Fund, and the Future of Life Institute [? · GW]. If effective altruism is a large part of the reason that AGI safety research exists, then it is definitely worth clearly spelling out how one gets from the former to the latter.
Accordingly, I will attempt to do three things in this post: (1) I will examine the philosophical relationship of EA to the prospect of AGI in general, (2) I will compare this account to what thought-leaders in EA generally say about AGI safety in practice, and (3) I will discuss how the notion of alignment fits into this whole picture.
‘First-principles’ EA and AGI: a survey of the landscape
The holistic goal [? · GW] of effective altruism (if we had to enumerate just one) seems to be something like bringing about the best outcomes for as long as possible. In other words, EA seems fundamentally interested in finding tractable solution(s) to a kind of dual optimization problem: find ways to (#1) make things as good as possible (#2) for the longest possible duration. EA wants the party to be really fun and for it to never end.
Some quick replies to quick objections:
- Some advocate—either in addition to or instead of problem #1—that we minimize bad outcomes. As I will discuss later, I think this point definitely relevant—but it is not essential for actually formulating the problem given that we can trivially define a bad outcome as the absence of a good outcome (which we already want to maximize).
- Some would argue that problem #2 is logically just a subset of problem #1 (i.e., good outcomes are not maximized if they are not maximized over a long duration). I think this is technically right. I am disentangling the problems of maximizing good outcomes and maximizing duration not because I think they are logically distinct, but rather because I think their practical implications substantially differ. By analogy, problem #2 is more about building out the road in front of us while problem #1 is more about ensuring that we're driving well. Both undertakings are important for maximizing good outcomes in the world, but they motivate very different action in practice (i.e., "road-building behavior" ≠ "good driving behavior"). I think that much the EA community has already recognized the utility of separating out problem #2 under the banner of longtermism. More on this in the next section.
A hypothetical future AGI—i.e., an AI [? · GW] that exhibits general intelligence [? · GW]—is a fairly complex phenomenon to situate within this generic framework because AGI will probably have significant benefits and significant costs. Let’s now think about each side of the coin so we can better determine how we would expect EA to generally evaluate the prospect of AGI.
The good
On the positive side of the balance, many have highlighted that intelligence is very plausibly humanity’s most precious resource—to have orders of magnitude more of it at our disposal would be profoundly useful. For instance, in Human Compatible, Stuart Russell argues that an AGI that was able to deliver a “respectable” living standard to everyone in the world (by solving whatever problems prevent us from doing so today) would roughly have a net present value of $13,500 trillion (p. 99). That’s a whole lot of good!
In general, it seems that the world could be made a far better place by alleviating the incalculable amount of suffering associated with the set of problems not yet solved by humans but conceivably solvable with the help of AGI (e.g., poverty, disease, war, climate change, etc.). Solving these problems through the advent of a single technology would almost certainly be the best thing to have happened to humans to date. Again—that’s a whole lot of good.

Though more controversial, another potentially attractive feature of engineering a general intelligence from the perspective of EA is that the AGI may well exhibit whatever cognitive features lead us to ‘count’ an entity as being capable of flourishing in the first place—i.e., AGI might become the newest entity on our planet capable of thriving (a “moral patient” in the philosophical jargon), joining the ranks of humans and animals. If this indeed ends up being the case, then the genesis of AGI might enable a “backdoor” of sorts for maximizing good outcomes in the world: there may suddenly exist trivially-reproducible entities that conceivably could be guaranteed to flourish—perhaps at peaks utterly unimaginable to humans. In other words, EA-type philosophies would almost certainly have to grant that a world with trillions of demonstrably-thriving, presumably-immortal superintelligent entities would be better than a world without them, all else being equal. They would "count" in the relevant sense.
At the outset, then, the prospect of AGI seems highly promising from the perspective of EA given (1) its potential to contribute to bringing about good outcomes/avoiding bad outcomes, and (2) its potential status as a moral patient capable of itself experiencing (potentially profound) levels of well-being.
The less-good
On the other hand, it is also well-understood that AGI may represent a serious impediment to securing long-term good outcomes. In general, most concerns about what could go horribly wrong with AGI ultimately stem from a failure to control its behavior and/or the consequences of its behavior. In this vein, there exist second-species [AF · GW]-style ideas that ultimately result in humans forfeiting our planetary dominance, as well as narrower worries about existentially bad outcomes associated with things like improperly specifying the AGI’s training objective or a reward function—e.g., the well-known paperclip maximizer problem [? · GW]. In addition to the bad outcomes of well-intentioned people losing control of AGI, there must also be concerns that dubiously-intentioned people could gain control of AGI. The more accessible the AGI, the more likely it is that someone will ask it to do something stupid.
Finally, I think that everything that was said previously about the possibility of flourishing “moral patient” AGIs can be substituted with concerns about the risks of developing AGIs with a (potentially deep) capacity for suffering. I think these concerns should be taken extremely seriously: if we build a suffering-capable AGI without knowing it or having ever cared enough to assess this as a real possibility, chances are that we would at least sometimes cause it to suffer. Ask yourself: how likely is it that we accidentally induce a non-zero amount of suffering in a suffering-capable system if we do not know that system is suffering-capable—let alone what actually causes it to suffer?
Not only would this sort of thing be an unprecedented ethical blunder in its own right—depending on the specific takeoff scenario [? · GW], it might also minimize the chances that AGI would treat us benevolently. Are there any examples of a generally intelligent moral patient that could be abused without learning to view its abusers as a threat? The wonderful HBO series Westworld captures this same cautionary point nicely: avoid supplying AGI with excellent reasons to consider humanity its enemy.
We therefore seem to have both instrumental and altruistic reasons to avoid inducing suffering in AGI.
Overall, then, it is plausible that the development of AGI could get out of control—that it either might exhibit intrinsically unstable behavior or otherwise function properly but fall into the wrong hands. Furthermore, we find that the moral patiency thought goes both ways: if it is plausible to build flourishing-capable AGI, then it also seems plausible to build suffering-capable AGI. Doing this—especially without knowing it—would probably be morally catastrophic and therefore totally contrary to the goals of EA. Further, this would be a highly plausible way of training a sufficiently intelligent AGI to associate humans with suffering, threatening to catalyze a conflict that humans would probably be wisest to avoid.
AGI will be good and less-good
In all likelihood, the advent of AGI—much like the evolutionary emergence of homo sapiens—would have profound positive and negative impacts on the world and its inhabitants (again, potentially including the AGIs themselves). In other words, the advent of AGI will probably not be good or bad: it will be complicated. Ultimately, then, to the degree we’re interested in viewing the problem through the lens of effective altruism, we should be searching for a set of proposals that would be most likely to (a) maximize the predicted long-term positive consequences (e.g., solving poverty) and (b) minimize the predicted long-term negative consequences (e.g., usurping planetary control) predicted to accompany the advent of AGI. This sort of view seems reasonable and familiar, but I think it is nonetheless useful to arrive at it from first principles.
EA and AGI in practice: existential risk reduction
Effective altruism as a broad intellectual movement (thankfully) seems to have something more specific to say about AGI than what I have gestured at in the previous section. In particular, AGI is often evaluated through the lens of longtermism, a school of thought which argues that people who will exist in the (far) future deserve moral consideration in the present and that we should therefore make choices with these future people in mind. I like to think of longtermism as the philosophical formalization of problem #2 from the dual optimization problem outlined earlier (as well as further motivation for keeping the two problems conceptually disentangled).
One fairly obvious implication of the longtermist position is that the worst conceivable events would be those that effectively ‘cancel’ the long-term future entirely (this would forgo a lot of future well-being): salient examples include asteroid impacts, climate change, and, yes, rogue AGI. As such, many effective altruists tend to construe the ‘problem of AGI’ at present as a particular class of existential risk. Indeed, in his book, The Precipice, Toby Ord persuasively argues that AGI-related risks constitute the single largest contributor to existential threat facing humanity in this century (p. 167).
Accordingly, effective altruists (especially those sympathetic to longtermism) reason that it is highly worthwhile to pursue research on how our species might avoid a non-recoverable blow leveled by some future AGI.
Here, I will limit myself to saying that, in light of our conclusion in the previous section, I think this practical stance is coherent and compelling but that it is not philosophically comprehensive. It does seem highly plausible that the worst conceivable outcome of developing AGI is that it permanently extinguishes human existence on the planet—and therefore, that EA-style thinkers should prioritize figuring out how to minimize the likelihood of AGI-induced extinction.
But even if this problem were solved—i.e., we had some provable guarantee that eventual AGI would be sufficiently controllable so as to eliminate the possibility of it causing the extinction of the species—there would certainly still be lots of EA-related work left to do. Namely: the staggering amount of conceptual space between “avoiding AGI-induced civilizational collapse” and “leveraging AGI to yield the best possible outcomes for the longest possible duration.”
For this reason, I think a highly relevant open question in alignment theory, longtermism, and effective altruism is how to most efficaciously allocate attention to the different subproblems in ‘EA x AGI’-style research, including but not limited to existential risk prevention. To illustrate the point simply and concretely, we can probably divide the entire EA x AGI ‘research-program-space’ into the overlapping but non-identical problems of (1), figuring out how to avoid the worst AGI outcomes, and (2), figuring out how to secure the best AGI outcomes. Given the goals of effective altruists, what would be the optimal calibration of time, attention, effort, etc. between these two programs? 100-0? 50-50? 80-20? While I am not at all sure what the right answer is, I am confident that the current calibration—to my knowledge, something perhaps most like 90-10—is not yet optimal.
To be clear, I am not claiming that AGI safety research per se should undergo some sort of radical transformation to accommodate vastly new research programs. Rather, I’m arguing that existential-risk-focused AGI safety research will not exhaustively supply all of what effective altruists should want to understand about AGI. Specific proposals for actually closing this understanding gap are best suited for another post; for our purposes (i.e., ultimately uncovering a useful paradigm for AGI safety work), I think it suffices simply to say the following: AGI safety research efforts emerge from the worldview of effective altruism insofar as out-of-control AGI could very plausibly lead to one of the worst outcomes imaginable—namely, the irreversible collapse of the entire species—and EA unambiguously advocates minimizing the likelihood of any such permanently bad outcomes.
It therefore follows that AGI safety researchers should (at least) work to adopt theoretical frameworks that yield those technical proposals most likely to minimize existential risks posed by future AGI. (We will begin our search for these sorts of frameworks starting in the next post!)
Human alignment and AGI alignment are importantly different
Individual vs. collective alignment
It is worth briefly discussing how the notion of alignment relates to the aforementioned, EA-motivated goal: minimizing the likelihood of existential risks posed by future AGI. The fundamental thought behind ‘alignment’ is something like: a necessary condition for safe AGI is that the goals of the AGI are aligned with those of humans. If we want to live in a particular kind of world, then a fully aligned AGI would be one that demonstrates both the motivation and the capacity to bring about and maintain that world.
There are immediately two different ways to interpret this thought. First, where the ‘we’ in question refers to humanity at large (call this ‘collective alignment’); second, where the ‘we’ in question refers to individual entities who program/control/own the AGI (call this ‘individual alignment’). We would probably expect these two versions of alignment to look quite different from one another. I’ve represented this set-up very simply below:
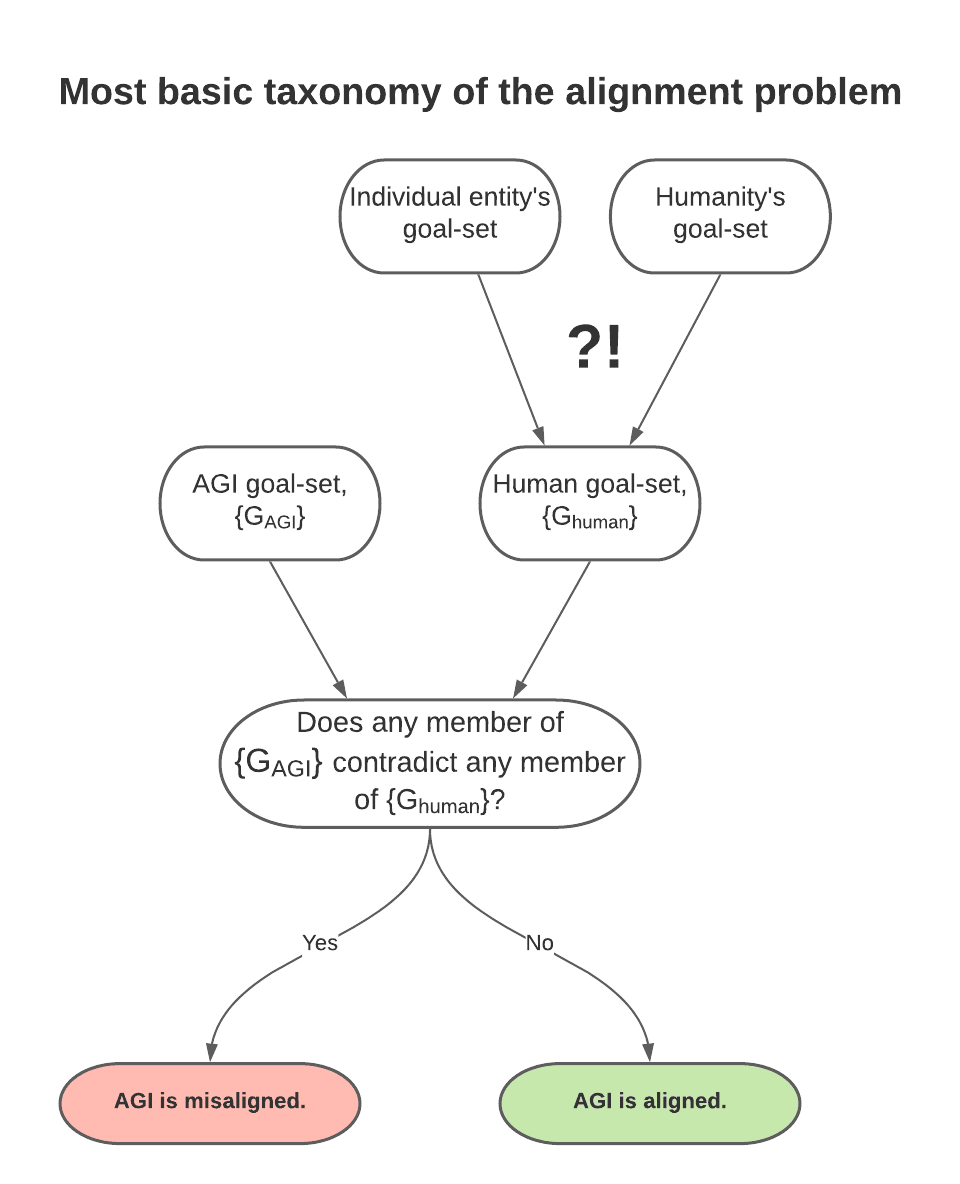
One immediately important difference between individual and collective alignment is that the latter is actually quite challenging to imagine, while the former is relatively less so. What would it even mean for an AGI to be collectively aligned to a species that is not itself internally aligned? In other words, it seems intractable in theory to build an AGI that broadly ‘agrees’ with the totality of humanity given that the totality of humanity does not broadly ‘agree’ with itself.
Both within and across societies, humans exhibit substantial differences in values. Often, these conflicts are concrete and zero-sum. Abortion is either generally acceptable or not; freedom of speech, expression, religion, etc. should either be generally respected or not; exchange of goods between entities should be generally regulated or not. In all of these cases (and in many more not mentioned here), there exist rational, intelligent, well-intentioned humans on either side of the aisle—i.e., with different values. Would, say, an abortion-facilitating, free-speech-restricting, free-market-regulating AGI be aligned or misaligned with humanity as a whole? Because this question assumes homogeneity of values across our species, I consider it to be ill-formed. Its ‘answer’ is both/neither—that it would be aligned according to some of humanity and misaligned according to some of humanity. This does not necessarily descend into moral relativism (i.e., it is definitely possible that some of humanity can simply be wrong), but it does leave open the extremely thorny and historically-unsolved question of which subsets of humanity are permitted to tell which other subsets that their values are the wrong ones. Collective alignment, I claim, inevitably confronts this problem once we acknowledge that there will be cases in which people genuinely and reasonably disagree about what should or should not be included in humanity’s collective ‘goal-set.’ I have no idea how to resolve these disputes without causing yet more conflict.
(A very interesting and explicitly AI-related case study of this sort of problem is the Moral Machine experiment. The punchline: cross-culturally, people agree that a self-driving car "sparing humans over animals, sparing more lives, and sparing young lives" would be better than each case's opposite. However, people's opinions differ about pretty much everything else.)
Let's now turn our attention to the prospect of individual alignment. Imagine that OpenAI, DeepMind, and the DoD have all successfully and independently built an ‘individually aligned’ AGI at roughly the same time—i.e., the goals of each AGI are totally consonant with those of their respective creators. In a set-up like this, the probability that the various AGIs are all aligned with each other is vanishingly low, as is the likelihood that these AGIs are aligned with anything like (the already-troubled notion of) humanity as a collectivity. Indeed, in our example, we could plausibly imagine that one of the goals of the DoD is the sustained global supremacy of the United States, an objective necessarily shared by any DoD-aligned AGI. Unleashed under this directive, the AGI might take actions (e.g., starting wars, crashing rival economies, etc.) that we consider to be diametrically opposed to the overarching goal to which alignment purports to contribute: minimizing the likelihood of AGI-induced existential risks.
Robust ‘individual alignment’ does not guarantee safety if the entity to which the AGI is individually aligned itself exhibits problematic goals. (It does not require an ‘evil military’ set-up for this concern to be plausible: corporations often prioritize profit, individuals often prioritize status and personal gain, political bodies often prioritize the continuation of their own power, etc.)
The human alignment problem
It seems, then, like collective alignment is generally intractable as a comprehensive safety proposal when the collectivity in question is not first aligned with itself, which is demonstrably the case with humanity. And individual alignment also seems generally intractable as a comprehensive safety proposal given that an AGI seeing ‘eye-to-eye’ with its supervisor is still totally unsafe if the supervisor's goals are themselves flawed (which, at present, characterizes every entity—person, corporation, political party, etc.—that we know of). Is alignment therefore a fruitless undertaking? I don’t think so. I do believe, however, that alignment really only becomes viable as a safety proposal when bifurcated as follows:
- The ‘human alignment problem:’ robustly align AGI-building entities (e.g., labs, firms, programmers) with the right goals.
- The ‘AGI alignment problem:’ Robustly align AGI to the right AGI-building entities.
It will not do to align AGI to programmers that are themselves ‘misaligned.’ Analogously, it would also be insufficient to robustly align the entities that end up programming AGI with the relevant goals without also figuring out how to ensure that their computational creations are in turn aligned to them.
I anticipate the following objection to the importance of what I’ve called the human alignment problem: “this is a non-issue, because practically speaking, who at OpenAI, DeepMind, the DoD, etc. would ever in their right mind disagree with goals like minimizing the likelihood of AGI-induced existential risks?! Everyone’s already aligned in the relevant sense, so the 'human alignment problem' is trivial compared to the 'AGI alignment problem!'” I think we have to be very careful with this sort of appeal—it is almost certainly too quick.
It is worth remembering what exactly is at stake in the development of AGI: the successful creation of a generally capable problem-solving machine would represent a paradigm shift of evolutionary proportions, especially if this machine could solve the problem of building yet more advanced AGI (which we could reasonably expect a generally capable problem-solving machine to do, almost by definition). In the words of IJ Good, such a tool could very well constitute the “last invention man ever need make.” Let’s be clear: for any human (or an organization comprised of them) to have control over a machine this powerful would be a test of character par excellence. At present, I think it would be dangerously naive to believe that whatever entities build the first AGIs would pass this ‘character test’ by default—i.e, that they would display and act solely upon values aligned with, say, maximizing aggregate well-being in the universe. Consider perhaps the most salient example in our cultural database of this idea:

What corporation, government, or individual at present could be reasonably trusted to act exclusively in accordance with these types of values upon suddenly being given access to an unprecedentedly powerful technology? Human nature, by default, is simply not so. The key is by default. I think it is entirely reasonable to believe that with the right interventions in the right places at the right times, the ‘proximate progenitors’ of AGI can be robustly aligned with goals loftier than status, personal gain, etc. More on human and AGI alignment in Question 2 [LW · GW].
My overall view is that both human and AGI alignment are undeniably daunting but fundamentally achievable goals. A final note along these lines: it seems like solving the human alignment problem probably will probably require an overlapping but fundamentally distinct skillset as compared to the AGI alignment problem. The latter is about building a computational system that will provably exhibit whatever qualities lead to that system behaving in accordance with the goals of its supervisor. The former is about genuinely and stably reshaping the values of the people building AGI (and, perhaps eventually, the AGIs building yet more AGIs) such that an AGI aligned to its creator’s values would, at minimum, pose negligible existential risk. Accordingly, another highly relevant open question within the space of AGI safety is how to most effectively allocate resources (100-0? 50-50? 80-20?) and identify research directions for addressing both of these alignment problems.
Summary
In this post, I built upwards from foundational principles in effective altruism and definitions of basic concepts like AGI and alignment towards the following conclusions:
- EA is fundamentally concerned with the two-part optimization problem of maximizing good outcomes (i.e., "vanilla utilitarianism") for a maximum duration (i.e., longtermism). Because AGI will likely yield both very good and very bad long-term outcomes, it necessarily follows that those sympathetic to EA should be searching for proposals that, when implemented, would make all of the good-AGI-outcomes maximally likely and the bad-AGI-outcomes minimally likely.
- In practice, leading thinkers in EA seem to interpret AGI as a special class of existential threat (i.e., something that could effectively ‘cancel’ the future). As such, most ‘EA x AGI’ research seems to be devoted to finding proposals that minimize the likelihood that AGI will constitute an existential threat. I’ve argued that this certainly seems right while also noting that this problem is basically orthogonal to figuring out how to secure those very good potential outcomes from earlier—about which EA-affiliated thinkers should still definitely care a lot (even if we choose to prioritize avoiding the worst outcomes).
- I strongly question the idea that an AGI whose goals were aligned with those of humans would necessarily be safe.
- In the collective interpretation of this thought (i.e., ‘humans’ = humanity as a whole), I argued that this seems theoretically intractable given that humanity's values are self-evidently heterogeneous and that there is no well-defined process for translating this heterogeneity into something like a single collective goal-set.
- In the individual interpretation of this thought (i.e., ‘humans’ = whatever specific entity builds an AGI), I’ve argued that robustly aligning an AGI to the entity's goals/values—while at least theoretically tractable—would not be safe if those goals/values are not robustly aligned with the relevant set of higher-order goals/values (e.g., EA-type thoughts like minimizing the likelihood of existential risk, maximizing total well-being, etc.). I called this the ‘human alignment problem,’ and I advocated for taking it just as seriously as the ‘AGI alignment problem.’ I think that alignment really only works as a safety proposal if both of these problems are solved, and I believe the former problem is currently neglected.
In the next post, I will use these ideas as a foundation in order to propose what questions we will need to answer (correctly) in order to achieve the aforementioned goal of AGI safety research: to minimize AGI-induced existential threats.
5 comments
Comments sorted by top scores.
comment by Koen.Holtman · 2022-02-11T11:51:47.275Z · LW(p) · GW(p)
I like what you are saying above, but I also think there is a deeper story about paradigms and EA that you are not yet touching on.
I am an alignment researcher, but not an EA. I read quite broadly about alignment research, specifically I also read beyond the filter bubble of EA and this forum. What I notice is that many authors, both inside and outside of EA, observe that the field needs more research and more fresh ideas.
However, the claim that the field as a whole is 'pre-paradigmatic' is a framing that I see only on the EA and Rationalist side.
To make this more specific: I encounter this we-are-all-pre-paradigmatic narrative almost exclusively on the LW/AF forums, and on the EA forum (I only dip into the EA forum it occasionally, as I am not an EA). I see it this narrative also in EA-created research agendas and introductory courses, for example in the AGI safety fundamentals [LW · GW] curriculum.
My working thesis is that talk about being pre-paradigmatic tells us more about the fundamental nature of EA than it tells us about the fundamental nature of the AI alignment problem.
There are in fact many post-paradigmatic posts about AI alignment on this forum. I wrote some of them myself. What I mean is posts where the authors select some paradigm and then use it to design an actual AGI alignment mechanism. These results-based-on-a-paradigm posts are seldom massively upvoted. Massive upvoting does however happen for posts which are all about being pre-paradigmatic, or about walking the first tentative steps using a new paradigm. I feel that this tells us more about the nature of EA and Rationalism as movements than it tells us about the nature of the alignment problem.
Several EA funding managers are on record as wanting to fund pre-paradigmatic research. The danger of this of course is that it creates a great incentive for the EA-funded alignment researchers to never to become post-paradigmatic.
I believe this pre-paradigmatic stance also couples to the reluctance among many EAs to ever think about politics, to make actual policy proposals, or to investigate what it would take to get a policy proposal accepted.
There is an extreme type of pre-paradigmatic stance, which I also encounter on this forum. In this extreme stance, you do not only want more paradigms, but you also reject all already-existing paradigms as being fundamentally flawed, as not even close to being able to capture any truth. This rejection implies that you do not need to examine any of the policy proposals that might flow out of of any existing paradigmatic research. Which is convenient if you want to avoid thinking about policy. It also means you do not need to read other people's research. Which can be convenient too.
If EA were to become post-paradigmatic, and then start to consider making actual policy proposals, this might split the community along various political fault lines, and it might upset many potential wealthy donors to boot. If you care about the size and funding level of the community, it is very convenient to remain in a pre-paradigmatic state, and to have people tell you that it is rational to be in that state.
I am not saying that EA is doomed to be ineffective. But I do feel that any alignment researcher who wants to be effective needs to be aware of the above forces that push them away from becoming paradigmatic, so that they can overcome these forces.
A few years back, I saw less talk about everybody being in a pre-paradigmatic state on this forum, and I was was feeling a vibe that was more encouraging to anybody who had a new idea. It may have been just me feeling that different vibe, though.
Based on my working thesis above, there is a deeper story about EA and paradigms to be researched and written, but it probably needs an EA to write it.
Honest confession: often when I get stuck doing actual paradigmatic AI alignment research, I feel an impulse to research and write well-researched meta-stories about the state of alignment field. At the same time, I feel that there is already an over-investment in people writing meta-stories, especially now that we have books like The alignment problem. So I usually manage to suppress my impulse to write well-researched meta-stories, sometimes by posting less fully researched meta-comments like this one.
Replies from: arthur-conmy↑ comment by Arthur Conmy (arthur-conmy) · 2022-02-26T13:08:54.366Z · LW(p) · GW(p)
I am interested in this criticism, particularly in connection to misconception 1 from Holden's 'Important, actionable research questions for the most important century [EA · GW]', which to me suggests doing less paradigmatic research (which I interpret to mean 'what 'normal science' looks like in ML research/industry' in the Structure of Scientific Revolutions sense, do say if I misinterpret 'paradigm').
I think this division would benefit from some examples however. To what extent to you agree with a quick classification of mine?
Paradigmatic alignment research
1) Interpretability of neural nets (e.g colah's vision and transformer circuits)
2) Dealing with dataset bias and generalisation in ML
Pre-paradigmatic alignment research
1) Agentic foundations and things MIRI work on
2) Proposals for alignment put forward by Paul Christiano, e.g Iterated Amplification
My concern is that while the list two problems are more fuzzy and less well-defined, they are far less direcetly if at all (in 2) actually working on the problem we actually care about.
↑ comment by Koen.Holtman · 2022-02-26T17:00:32.234Z · LW(p) · GW(p)
First, a remark on Holden's writeup. I wrote above that Several EA funding managers are on record as wanting to fund pre-paradigmatic research, From his writeup, I am not entirely sure if Holden is one of them, the word 'paradigmatic' does not appear in it. But it is definately clear that Holden is not very happy with the current paradigm of AI research, in the Kuhnian sense where a paradigm is more than just a scientific method but a whole value system supported by a dominant tribe.
To quote a bit of Wikipedia:
Kuhn acknowledges having used the term "paradigm" in two different meanings. In the first one, "paradigm" designates what the members of a certain scientific community have in common, that is to say, the whole of techniques, patents and values shared by the members of the community. In the second sense, the paradigm is a single element of a whole, say for instance Newton’s Principia, which, acting as a common model or an example... stands for the explicit rules and thus defines a coherent tradition of investigation.
Now, Holden writes under misconception 1:
I think there are very few people making focused attempts at progress on the below questions. Many institutions that are widely believed to be interested in these questions [of AI alignment in the EA/longtermist sense] have constraints, cultures and/or styles that I think make it impractical to tackle the most important versions of them [...]
Holden here expresses worry about a lack of incentives to tackle the right questions, not about these institutions even lacking the right scientific tools to make any progress if they wanted to. So Holden's concern here is somewhat orthogonal to the 'pre-paradigmatic' narratives associated with MIRI and John Wentworth, which is that these institutions are not even using the right tools.
That being said, Holden has written a lot. I am only commenting here about a tiny part of one single post.
On your examples of Paradigmatic alignment research vs. Pre-paradigmatic alignment research: I agree with your paradigmatic examples being paradigmatic, because they have the strength of the tribe of ML researchers behind them. (A few years back, dataset bias was still considered a somewhat strange and career-killing topic to work on if you wanted to be an ML researcher, but this has changed, if I judge this by the most recent NeurIPS conference.)
The pre-paradigmatic examples you mention do not have the ML research tribe behind them, but in a Kuhnian sense they are in fact paradigmatic inside the EA/rationalist tribe. So I might still call them paradigmatic, just in a different tribe.
My concern is that while the list two problems are more fuzzy and less well-defined, they are far less direcetly if at all (in 2) actually working on the problem we actually care about.
..I am confused here, you meant to write 'first two problems' above? I can't really decode your concern.
comment by Ansel · 2022-02-09T14:56:11.591Z · LW(p) · GW(p)
In practice, leading thinkers in EA seem to interpret AGI as a special class of existential threat (i.e., something that could effectively ‘cancel’ the future)
This doesn't seem right to me. "Can effectively ’cancel’ the future" seems like a pretty good approximation of the definition of an existential threat. My understanding of why A.I. risk is treated differently is because of a cultural commonality between said leading thinkers such that A.I. risk is considered to be a more likely and imminent threat than other X-risks. Along with a less widespread (I think) subset of concerns that A.I. can also involve S-risks that other threats don't have an analogue to.
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2022-02-09T16:46:10.341Z · LW(p) · GW(p)
I agree with this. By 'special class,' I didn't mean that AI safety has some sort of privileged position as an existential risk (though this may also happen to be true)—I only meant that it is unique. I think I will edit the post to use the word "particular" instead of "special" to make this come across more clearly.