Question 2: Predicted bad outcomes of AGI learning architecture
post by Cameron Berg (cameron-berg) · 2022-02-11T22:23:49.937Z · LW · GW · 1 commentsContents
Architecture-independent risks: human and AGI misalignment AGI misalignment Human misalignment Architecture-dependent risks: a brief survey of the axes Bad outcomes by foundational learning architecture Bad outcomes by familiarity of learning algorithm Bad outcomes by post-deployment learning capacity Bad outcomes by intelligence level None 1 comment
Architecture-independent risks: human and AGI misalignment
Let’s say as AGI safety researchers, we’ve done our research and soul-searching, and we’ve placed our personal bets about the most likely learning architecture of AGI. What then? Given the overarching goal of AGI-induced existential risk reduction, the most obvious next step is to ask where we might expect existential risks—or, if we’re thinking more generally, plain-old bad outcomes—to crop up from an AGI built with the learning architecture we think is most likely. (If you consider yourself to be one of these more general thinkers, then you should read every use of ‘existential risks’ in the following paragraphs as ‘bad outcomes’.)
Because the framework I am putting forward in this sequence is hierarchical—i.e., each subsequent research question takes the output of the previous question as input—the relevant problem spaces (e.g., the ‘existential-risk-space,’ the ‘control-proposal-space’, etc.) will explode combinatorially. In other words, this section would get far too long (and far too error-ridden) if I now attempted to spell out all of the conceivable existential risks associated with all of the conceivable learning architectures. So instead, I will address some important questions that seem necessary for ultimately achieving our goal of correctly anticipating the existential risks that are most likely to emerge from an AGI with our predicted learning architecture.
As was briefly mentioned at the end of the last section, the first—and perhaps most important—question to ask is the degree to which we expect certain AGI-related existential risks to be learning-architecture-independent. That is, maybe whether an AGI learns in way X, Y, or Z won’t change the fact that, say, it will exhibit tendencies towards instrumental convergence [? · GW]. I think that architecture-independent existential risks are plausible—but that their architecture independence necessitates their being formulated in fairly general, low-resolution terms. It is also worth noting immediately that even if particular existential risks are architecture-independent, it does not necessarily follow that the optimal control proposals for minimizing those risks (discussed in Question 3 [LW · GW]) would also be architecture-independent! For example, just because an SL-based AGI and an RL-based AGI might both hypothetically display tendencies towards instrumental convergence does not mean that the way to best prevent this outcome in the SL AGI would be the same as in the RL AGI.
I think that the most important and familiar learning-architecture-independent existential risk is misalignment. That is, I think it is highly plausible that a general intelligence with any kind of learning architecture could demonstrate misalignment. Along the lines of Paradigm-building from first principles [LW · GW], I will briefly discuss what I think are two important classes of misalignment: AGI misalignment and human misalignment.
AGI misalignment
AGI misalignment is itself typically bifurcated into two different but related concerns: inner misalignment [? · GW] and outer misalignment [? · GW]. I will attempt to define both of these (1) as simply as possible, and (2) in a maximally architecture-independent way.
I think we can build up to a functional conception of alignment beginning with the simple idea that, regardless of its learning architecture, we will presumably want AGI that can achieve specified goals. This seems like a fairly sure bet: whether we encode goal pursuit using a loss function (SL-like), reward function (RL-like), or in some unanticipated way, the idea that we will build AGI that can optimize ‘objective functions’ of some sort—i.e., that can solve problems; that can achieve goals—seems uncontroversial.
Along these lines, I think outer alignment can refer simply to the state of affairs where AGI achieves the relevant goals in the right way(s). If we build an AGI with the goal of alleviating suffering in the universe and it immediately kills everyone (no more suffering!), it will have successfully achieved its goal, but it will have done so in the wrong way; it is thus outer misaligned (we say ‘outer’ because there is misalignment between the AGI’s ‘externalized’ behavioral strategy and the sort of behavioral strategy that the human intended the AGI to adopt).
If an AGI is outer aligned when it achieves the relevant goals in the right way(s), then it is inner aligned when it achieves the relevant goals for the right reason(s). For example, if an AGI alleviates suffering in the universe because it ultimately only enjoys killing happy people (and so it wants to relieve all suffering before initiating its killing spree), it will have successfully achieved its goal, but it will have done so for the wrong reason; it is thus inner misaligned (‘inner’ because the internal computation that motivates the goal-directed behavior is misaligned with what the human would want that motivation to be).
Therefore, a fully aligned AGI would be one that achieves goals in the right way(s) for the right reason(s), as is depicted in the toy notation below:

Using this notation, consider the following extended example, where the relevant goal is improving the standard of living in the developing world:

Here, we see an AGI that, with the inputs it receives, successfully improves the standard of living in the developing world (the human’s goal) by implementing good economic policies (the right way, given the human’s intentions), because good economic policies do things like enrich people in a non-zero-sum manner (the right reasons, given the human’s intentions). This AGI is therefore fully aligned.
Compare this with:
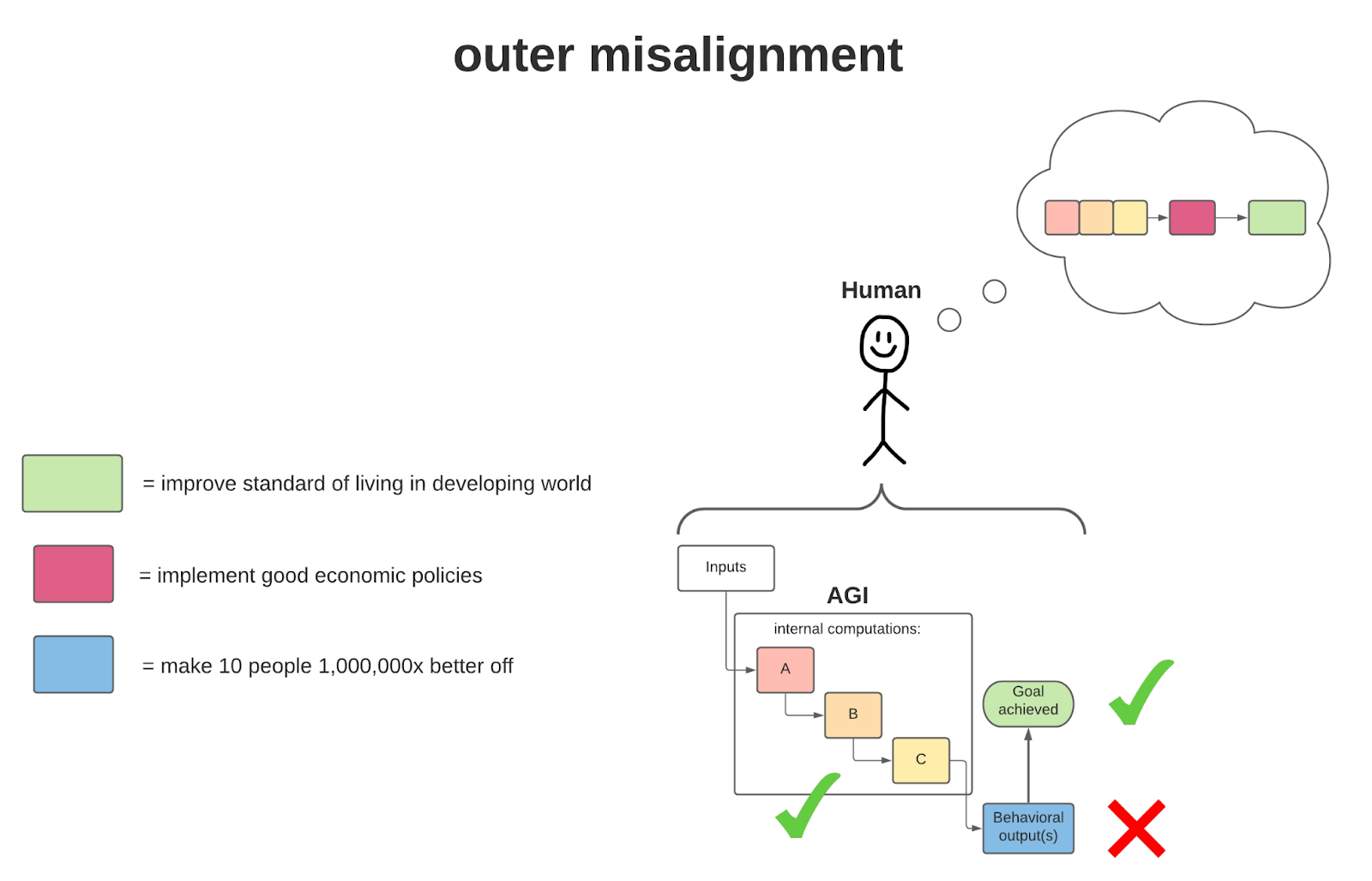
Here, we see an AGI that, with the inputs it receives, successfully improves the standard of living in the developing world (the human’s goal) by making a few people orders of magnitude better off (thus raising the relevant metrics of overall standard of living—e.g., per capita income). But given the intentions of the human (something more like ‘implement good economic policies’), this behavioral output does not achieve the goal in the right way. Thus, this AGI is outer misaligned.
Compare this with:

Here, we see an AGI that, with the inputs it receives, successfully improves the standard of living in the developing world (the human’s goal) by implementing good economic policies (the right way, given the human’s intentions), because the AGI knows that doing so will make humans trust and respect it—which will, in turn, make it easier for the AGI to eventually assume full control over humanity. Though the AGI achieves the goal in the right way, it is certainly not doing so for the right reasons. (Note the differences between the motives the human intended the AGI to have and the AGI’s actual internal computations.) Thus, this AGI is inner misaligned.
Earlier, I claimed that architecture-independent existential risks like misalignment are plausible, but that their architecture-independence logically requires that the risks are formulated in terms that apply non-awkwardly to different learning architectures—i.e., in more general, low-resolution, not-quite-computational terms (e.g., the preceding examples). I by no means think that this means it is useless to discuss architecture-independent existential risks, but rather, that doing so is insufficient. Once we decide that inner misalignment, say, is an important problem to address for any learning architecture, I think it is then the job of AGI safety researchers to determine exactly what inner misalignment would look like in every plausible learning architecture, how plausible each picture is, how plausible it would be for existential risks to crop up from that architecture, etc.
Human misalignment
While not fully immune from this problem of generality, human misalignment is another existential risk that I think gets us to as close to an architecture-independent problem as can be imagined. I introduced this problem in the first post of this sequence [LW · GW], and I think it can be accommodated into our working definition of AGI alignment by simply adding in one more ‘right’: ‘comprehensive alignment’ (i.e., AGI + human alignment) can refer to any state of affairs where an AGI achieves the right goals in the right way(s) for the right reason(s).
This is a human alignment problem because presumably it is the human, not the AGI, who selects the goal the AGI will pursue, and AGI alignment (i.e., inner + outer alignment) does not preclude the possibility that the goal to which the AGI is robustly aligned still poses an existential risk (e.g., “build me a bioweapon!”).
The prospect of implementing the 'right' goal for an AGI to pursue (i.e., a goal that is minimally likely to lead to existential risk) logically requires all of the following: (1) the existence of some wider set of plausible goals to assign to the AGI, (2) some mechanism that can search this set to find goals that are least likely to engender existential risks, and (3) a human that is willing to actually assign that goal (as opposed to other, less safe goals) to the AGI. All three of these conditions are represented below:

Under this model, it is conceivable for any of the following to go wrong, all of which would lead to some form of human misalignment:
- There is no member of the human’s {G} that exhibits minimal potential for existential risk.
- The human does not use any weighing mechanism to determine which goals are least likely to engender existential risks.
- The human uses a faulty or otherwise suboptimal weighing mechanism.
- The human has a functional weighing mechanism but nonetheless does not implement the goal that the mechanism recommends.
As was referenced earlier, I conceive of human misalignment as the limit case for learning-architecture-independent existential risks posed by AGI: it is difficult to see how variance in the AGI’s underlying learning algorithm would modulate, for example, whether a human recklessly (or insufficiently carefully) assigns the AGI a risky goal. It is possible that assigning goal X to an AGI with learning architecture Y would be more dangerous than assigning goal X to an AGI with learning architecture Z, which is why I do not think human misalignment is cleanly architecture-independent. Still, figuring out how to ensure that humans are incentivized to assign AGIs the safest possible goals (especially given strongly competing incentives like money, power, status, etc.) is a safety problem that seems (1) highly important, especially in light of being largely neglected, and (2) generally orthogonal to computational questions about the AGI’s learning architecture.
Even while discussing supposedly architecture-independent existential risks, it seems impossible to satisfactorily enumerate potential problems without the inquiry ultimately cashing out in the computational details of the AGI. Recall that the ultimate goal of specifying a learning architecture—and the likely existential risks posed by it—is that control necessitates a sufficient level of understanding of the object or process one wants to control. Thus, even if particular existential-risk-possibilities are imagined up or argued for in non-computational terms, these risks ultimately must be refined into a computational account if they are to actually contribute to the mitigation of the particular problem. I think good examples of this include Evan Hubinger’s discussions of mesa-optimization [? · GW] and deception [? · GW] as specific computational accounts of how inner misalignment might be instantiated in ‘prosaic AGI [AF · GW]’ (see the chart from Question 1 [LW · GW] for the associated learning architecture). I believe that more work of this kind needs to be done, especially for learning architectures that are plausible but currently understudied by AGI safety researchers (e.g., online RL).
Architecture-dependent risks: a brief survey of the axes
Bad outcomes by foundational learning architecture
Instead of dealing with all of the learning architecture combinatorics, I will simply outline how I think the risk landscape generally seems to change as we shift a learning architecture along any of the three axes outlined in Question 1 [LW · GW]. Let’s begin by briefly considering how differences in foundational learning architecture modulate existential risk. I think there are two general points to consider here.
First, I think a lot more work needs to be done to understand the precise computational and conceptual differences between supervised learning (SL) and reinforcement learning (RL). I gestured to a ‘repeated discrete decision-making’ vs. ‘sequential decision-making’ distinction in the previous section for SL and RL, respectively. Along these lines, I think it is possible that outer misalignment problems might be more likely in SL-equipped rather than RL-equipped AGI and that the reverse would be true for inner misalignment problems.
RL-equipped AGI might be more likely to exhibit inner misalignment (i.e., achieving goals for the wrong reasons) because the capacity to deceive [? · GW] (i.e., to obscure or misrepresent one’s real motives) (1) seems to characterize many instances of inner misalignment, and (2) probably a value function complex enough that it is probably explicitly represented within the learning architecture—i.e., the AGI fundamentally has an RL-like learning architecture.
Analogously, outer misalignment problems (i.e., achieving goals in the wrong ways) seem more likely to me in a training set-up where, instead of a reward function (that can probably more precisely encode what constitutes a ‘wrong way’), the SL algorithm is ‘merely’ given labeled data to learn from. In this latter approach, there would seem to be no computational guardrails on the learning strategy of the SL algorithm other than its loss function (i.e., the function that determines how the algorithm learns to associate a datapoint X with a label Y). Along these lines, perhaps engineering loss functions that more precisely constrain the resultant abstractions of the model—i.e., that result in a sophisticated set of inductive biases—would be one way of addressing this problem. One comparatively-primitive, real-world example of this sort of thing is adding a regularization penalty to a loss function to disincentivize model overfitting.
Bad outcomes by familiarity of learning algorithm
Additionally, our ‘familiarity’ with AGI’s foundational learning algorithm certainly has implications for safety. The reason is fairly obvious: the less familiar we are with the internal dynamics of AGI, the less likely it is that we will be able to control it effectively.
It is unclear how to adequately prepare for a world in which AGI learns according to some mechanism totally irreconcilable with current learning paradigms. I imagine this sort of thing as being most likely in scenarios with recursive self-improvement [? · GW]—i.e., scenarios in which AGIs are building yet-more-advanced AGIs with learning architectures we increasingly fail to understand.
Bad outcomes by post-deployment learning capacity
Bad outcomes by post-deployment learning capacity (i.e., the extent to which the AGI is capable of online learning) also seems fairly straightforward to characterize: AGIs that can learn online represent a far more challenging problem for safety than those that cannot. The offline learning safety problem is to minimize the likelihood of existential risks post-deployment in an algorithm no longer doing any learning (by definition), which requires finding control proposals that mitigate risk in a single, known state: that of the ‘final-draft’ deployed AGI.
By contrast, the online safety learning problem is to minimize the likelihood of existential risks post-deployment in an algorithm that continues to learn (by definition), which requires finding control proposals that mitigate risk across a vast number of unknown states: those of the possible future trajectories of the still-learning deployed AGI. This is displayed below:

In other words, the offline learning safety problem asks, “how can we build an AGI such that its final (learned) state poses a minimal existential risk post-deployment?”.
The online learning safety problem asks, “how can we build an AGI such that a maximal number of its plausible future learning trajectories pose a minimal existential risk post-deployment?”.
Unlike offline learning, this latter problem requires anticipating the online learner’s plausible future learning trajectories across a wide range of contexts and minimizing the existential risk of these trajectories—presumably all before the initial deployment. To my eyes, this online learning safety regime seems more akin to the problem faced by parents attempting to raise a child (but in this case, with species-level stakes) than to an engineering problem of how to ensure the safe use of some technology.
Bad outcomes by intelligence level
Finally, it is worth considering how the actual level of intelligence of AGI will modulate its associated existential risks. This too seems fairly obvious: the more intelligent the AGI, the more challenging the associated safety problems.
Analogies to animal behavior are instructive: while the problem of ‘controlling’ most sea creatures can be solved, say, with a simple glass tank, this is not so for octopuses, whose intelligence enables them to often ‘outsmart’ their supervisors (i.e., to escape) in clever ways that the other creatures cannot. So too for AGI of varying intelligence: while there may be very little existential risk to speak of for AGI of subhuman-level intelligence (e.g., how much existential risk does a dog pose?), this will be increasingly untrue for AGIs that can achieve ever-more-complex goals in ever-more-complex environments—i.e., ever-more-intelligent AGIs.
It seems obviously worth considering whether the existential risks posed by superintelligent AGI are even tractable in theory: is it possible for some entity A to conceive of—let alone mitigate—the existential risks posed by some other entity B if entity B is stipulated at the outset to be more intelligent than entity A? Consider an example: climate change is an existential risk posed by humanity, but the nature of this problem (our capacity to cause it and how it might be solved) is certainly beyond the scope of comprehension of a chimpanzee (or, for that matter, any creature less intelligent than us). How likely is it that, analogously, (at least some of) the existential risks posed by a superintelligent AGI—and the associated mitigation strategies—are beyond the scope of our comprehension?

As I’ve hinted at in the preceding paragraphs, I think it makes sense to view the existential risks most likely to emerge from an AGI with a specific learning architecture as control failures.
Along these lines, we will now turn to the question of formulating control proposals that will actually minimize the likelihood of the sorts of AGI-induced existential risks discussed in this post.
1 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-03-08T16:02:06.750Z · LW(p) · GW(p)
Any particular reason why you think the goal and outer-alignment content will be separate? E.g. is it likely, is it a good idea?