Question 1: Predicted architecture of AGI learning algorithm(s)
post by Cameron Berg (cameron-berg) · 2022-02-10T17:22:24.087Z · LW · GW · 1 commentsContents
Exploring the possible space of learning architectures Foundational learning algorithm Post-deployment learning capacity Level of general intelligence Zooming back out None 1 comment
Exploring the possible space of learning architectures
Here is the ultimate challenge: in order to control something, one generally has to understand how it works—i.e., to accurately predict how it will behave under various manipulations.
I sometimes have a recurring dream that I am aboard a plane falling out of the sky, and for whatever reason, I, a lowly passenger, am suddenly tasked with landing the plane safely. However, when I enter the cockpit, all I see are a series of levers, buttons, dials, dashboards, etc. Unsurprisingly, I do not understand the function of any of these mechanisms in my dream; I thus always fail my mission to properly fly the plane. It is crucial for existential risk minimization that we do a better job understanding and controlling the trajectory of AGI than my dream self does with flying a plane.
In order to control the behavior/consequences of the behavior of AGI, we will have to understand how it works to a sufficient degree.
In order to understand how AGI works, we will have to understand the general strategies that the AGI employs to achieve goals and solve problems.
And understanding these ‘general strategies’ is really a question of the architecture of AGI’s learning algorithm(s). This is because these learning algorithms constitute the specific mechanism by which the AGI would transition from the state of being unable to solve some problem/achieve some goal to being able to do so.
A quick note on the ‘(s)’ in learning algorithm(s): there is no reason for us to exclude from consideration the possibility that AGI will have multiple learning strategies at its disposal, employing its different learning algorithms for different problem-solving contexts. With this being said, I think it would still make sense in many cases to talk about the ‘fundamental’ or ‘foundational’ learning algorithm employed by the AGI. For example, if the AGI fundamentally represents the world as a vast set of states (perhaps using SL) inside of which it attempts to actuate sequences of high-value actions, this AGI’s ‘foundational’ learning algorithm would be RL (even though it also uses some SL).
I will now outline my best guess at the space of these possible learning algorithm architectures. I’ve divided up the space into three axes: foundational learning algorithm, post-deployment learning capacity, and level of general intelligence. I will explain each in turn.
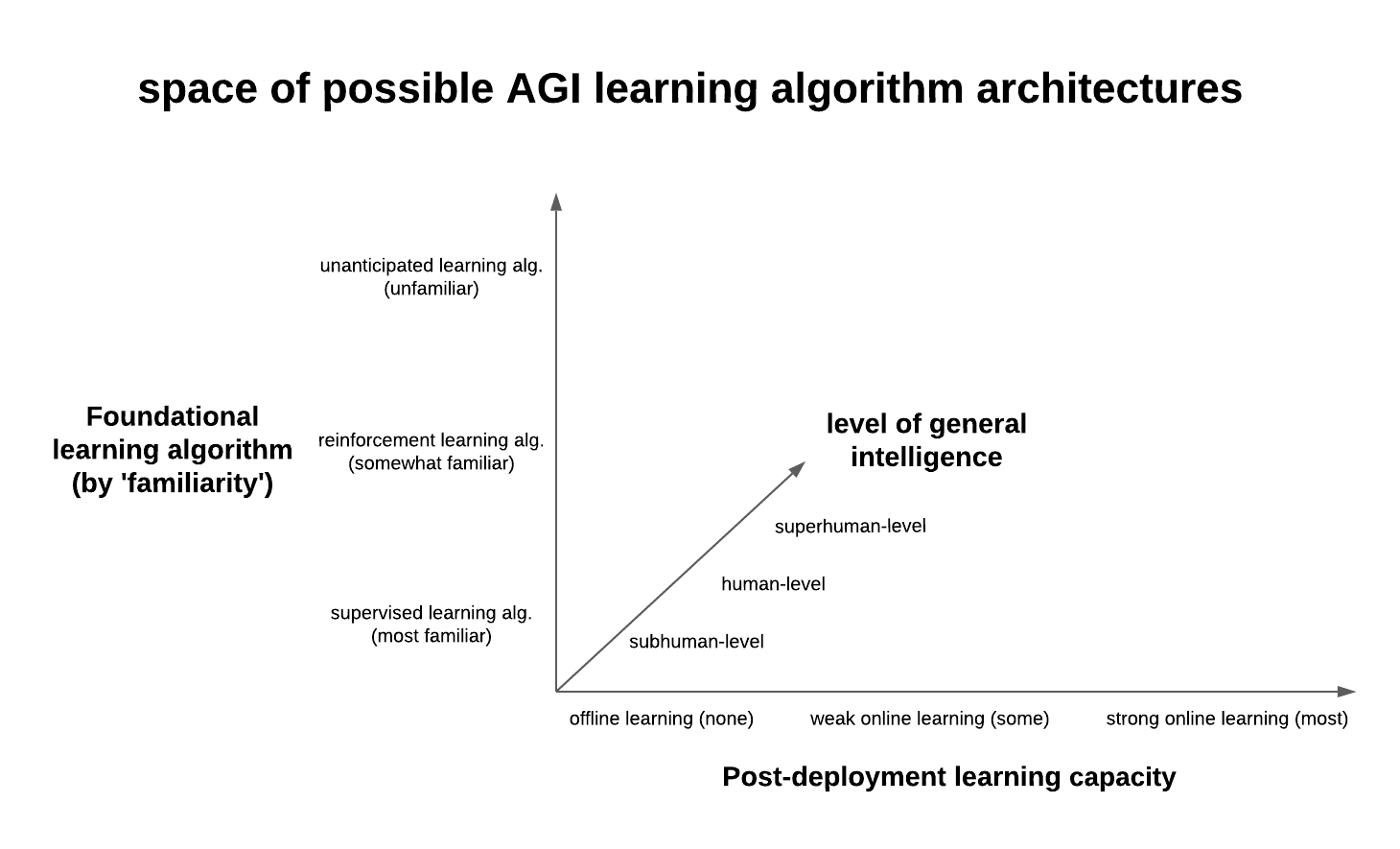
Foundational learning algorithm
The ‘foundational learning algorithm’ axis is continuous in this graph, but only because it employs a graded notion of familiarity—i.e., the extent to which current ML engineers/AI researchers understand the functional dynamics and computational potential of the family of learning algorithms in question. (I think ‘familiarity’ of this sort is a fairly contrived metric, albeit a highly relevant one for safety.)
This set-up implicitly claims that supervised learning (SL) methods (e.g., ANNs, language models, classification and regression tasks, etc.) are, relatively speaking, better researched by most ML practitioners than reinforcement learning (RL) methods (which is not to say that RL is not studied)—and that these two approaches are fundamentally different. Of course, the least familiar learning algorithms would be those that do not currently exist and/or those that aren’t adequately described under the broad computational frameworks of RL or SL.
Despite their seemingly continuous representation in this graph, I want to be clear that the different foundational learning algorithms are probably best thought of as discrete. (While there might potentially be some rough SL-RL spectrum [e.g., strict SL → ‘SL-model-based’ RL → model-free RL], it would be impossible to incorporate currently-unknown learning algorithms into this spectrum, so I am content to think of these as cleanly discrete possibilities for now.)
Evaluating the precise relationship between RL and SL algorithms is a highly worthwhile topic, albeit one for another post (see Barto's excellent treatment of the subject here); for our purposes, I will briefly summarize the distinction as follows. Both SL and RL algorithms can be validly construed as learning to build a model that makes optimal ‘decisions:’ an SL algorithm might ‘decide’ to predict a handwritten digit as a ‘7’ (given particular patterns of activation in its neural network), while a Q-learning RL algorithm might ‘decide’ to turn left in a maze (given its value and policy functions).
Along these lines, I think the most fundamental difference between these two learning algorithms is that the ‘decisions’ of an SL algorithm (e.g., predicting ‘7’) have no direct bearing on the next decision problem faced by the algorithm (e.g., predicting ‘7’ is causally independent of that fact the next training image—and prediction—is a ‘4’), while the ‘decisions’ of an RL algorithm (e.g., turning left in a maze) do affect the next decision-problem (e.g., turning left means I can turn left or right at the next junction while turning right would eventually lead me into a dead-end). RL decision-problems are self-entangled; if they use the Bellman equation, they are intrinsically recursive.
In other words, successful RL algorithms yield a model that can solve a sequential decision problem (e.g., maze = left-left-right-straight-left-goal), while successful SL algorithms yield a model that can solve many discrete decision problems (e.g., serially predicting 10,000 handwritten digits).
Given this cursory summary, the degree to which one believes that AGI would fundamentally be more like a ‘sequential problem solver’ should track with one’s credence in the foundational learning algorithm of AGI being some form of RL. So too with AGI being more like a ‘repeated discrete problem solver’ and SL. If one believes that both of these framings seem wrong and/or orthogonal to how an AGI would really need to learn, one would probably lean towards predicting AGI to have what I’ve called an ‘unanticipated learning algorithm’ (which is really something more like the absence of a prediction).
Post-deployment learning capacity
‘Post-deployment learning capacity’ means what it sounds like. All learning algorithms (though admittedly maybe not some unanticipated ones) demonstrate something like a ‘build and refine decision-making procedure’ phase and an ‘implement decision-making procedure’ phase, more familiarly and succinctly referred to as training/testing and deployment, respectively. In these terms, the question at hand is predicting how much of the cumulative learning done by the AGI will occur post-deployment. Possible answers presumably range from 0% to ≈100%. Of course, it is worth immediately noting that if one believes the answer is closer to 100% than 0%, the notion of a training/testing-deployment distinction becomes increasingly arbitrary—if significant learning can be done post-deployment, then in what sense is ‘post-deployment’ different from ‘just more training and testing?’ I think the following simple terminology seems appropriate for describing this state of affairs:

Note that everyone agrees that there will be learning going on pre-deployment—i.e., during the training/testing stage. The question of post-deployment learning capacity might also be framed as the extent to which one predicts the AGI's generated model to be 'static' or 'solidified' following deployment. A current example of a solidly offline learning algorithm setup is Tesla's use of deep learning for training the self-driving functionality of their cars: data is collected, models are trained and tested, and software updates containing the now-static model are subsequently sent out to the individual cars. This set-up would be online if, for example, each car were to continually update its own representations (subsequent to a software update) given new data encountered by that car while driving.
Conversely, the best example of strong online learning can be found in the brain. There is of course no moment prior to death when a neurotypical brain can be said to stop learning, and though there is some evidence that model training/testing might basically be what occurs during sleep, it is obviously also the case that humans and animals can learn spontaneously during waking hours. When someone tells me their name, my world model immediately updates. When a Tesla car blows through a stop sign, its world model does not immediately update. As I've written previously [LW(p) · GW(p)], the brain also seems to almost entirely evade the notion of deployment, as it is totally unclear how to answer the question of when a brain is 'deployed' in the traditional sense.
Level of general intelligence
The final axis worth considering in the space of possible AGI learning algorithm architectures is the AGI’s level of general intelligence. Recall that general intelligence is basically defined as “the ability to efficiently achieve goals in a wide range of domains.” Though to my surpise I have not seen it discussed elsewhere, it is important to note that nothing about this definition (or intelligence being instantiated ‘artificially’) necessarily entails superhuman competence. I think the most obvious and intuitive examples of subhuman general intelligence can be found in other intelligent species like dolphins, octopuses, chimpanzees, crows, etc. These creatures are certainly less generally intelligent than humans, but they are certainly generally intelligent in the aforementioned sense.
Consider the common bottlenose dolphin, which can hunt using highly complex tactics, coordinate sophisticated social behaviors, use tools for self-protection, enact multi-stage plans, engage in deceptive behavior, play complex games with determinate rulesets, elect to ‘get high’ on puffer fish nerve toxins, and so on. Efficiently achieving goals? Check. Wide range of domains? Check. Perhaps we will build AGI like this (with subhuman general intelligence). Or perhaps we will build AGI that matches or exceeds our general intelligence—i.e., an AGI that can more efficiently achieve a broader set of goals in a wider range of domains than can homo sapiens. In general, the novel claim contained within this axis is that general intelligence and superintelligence should not be conflated; that is, an AGI with subhuman general intelligence—however plausible—is perfectly possible.
Having explained these three axes in greater detail, I think it worth noting that this framework plausibly accounts for different conceptualizations of AGI in safety research, such as ‘prosaic AGI’ vs. ‘brain-based AGI, [? · GW]’ as it depicted (in the two relevant dimensions) below:

In general, the graph claims that prosaic AGI safety researchers seem to center their efforts in mostly-supervised, mostly-offline learning architectures, while brain-based AGI safety researchers are more interested in more RL-based, solidly-online learning architectures. I provide this example as a tentative proof of concept both for the possibility-space and for the utility of having a single framework that can incorporate the thinking of different AGI safety researchers with significantly different priors.
Zooming back out
Recall our starting point: in order to control something, we should generally understand how it works. In the case of AGI, I think that ‘how does it work?’ can be more precisely stated as ‘what is the predicted foundational architecture of the learning algorithm(s) used by the AGI?’. The proposed framework proposes a three-dimensional space of plausible answers to this question inside which AGI researchers can localize their own intuitions.
One thing that makes the AGI safety control problem most obviously unique from most other control problems is that the object-to-be-controlled—the AGI—does not yet exist. If this problem needs to be solved prior to the invention of the AGI (discussed in Question 5 [LW · GW]), proposals for control must necessarily be based upon our best predictions about what AGI will look like. Therefore, the stakes are high for figuring out what the most plausible models of AGI actually are; it is only with models of this sort as a foundation (whether or not they are explicitly acknowledged) that any of the subsequent control-related work can be done.
Even if we think that there might be certain problems—and subsequent control proposals—that transcend specific learning architectures (i.e., problems that apply to—and control proposals that could work for—any generally intelligent computational system), it still makes sense to think about specific architectures as a first step. This is because, as I will discuss next, there are almost certainly going to be other important safety problems (and solutions) that end up being strictly architecture-specific. In order to solve the AGI safety control problem, we need to solve all of these subproblems, architecture-independent and architecture-dependent alike.
We will now turn to investigate the sorts of problems that might arise from an AGI situated somewhere within the three-dimensional model presented here.
1 comments
Comments sorted by top scores.
comment by Koen.Holtman · 2022-02-11T15:51:02.488Z · LW(p) · GW(p)
I'm interested to see where you will take this.
A terminology comment: as part of your classification system. you are calling 'supervised learning' and 'reinforcement learning' two different AI/AGI 'learning algorithm architectures'. This takes some time for me to get used to. It is more common in AI to say that SL and RL solve two different problems, are different types of AI.
The more common framing would be to say that an RL system is fundamentally an example of an an autonomous agent type AI, and an SL system is fundamentally an example of an input classifier or answer predictor type AI. Both types can in theory be built without any machine learning algorithm inside, in fact early AI research produced many such intelligent systems without any machine learning algorithm inside at all.
An example of a machine learning architecture, on the other hand, would be something like a deep neural net with backpropagation. This type of learning algorithm might be used to build both an SL system and an RL system.
In Barto's work that you reference, he writes that
Both reinforcement learning and supervised learning are statistical processes in which a general function is learned from samples.
I usually think of a 'machine learning algorithm/architecture' as being a particular method to learn a general function from samples. Where the samples come from, and how the learned function is then used, depends on other parts of the 'AI architecture', the non-ML-algorithm parts.
So where you write 'Predicted architecture of AGI learning algorithm(s)', I would tend to write 'predicted type of AGI system being used'.