Theoretical Neuroscience For Alignment Theory
post by Cameron Berg (cameron-berg) · 2021-12-07T21:50:10.142Z · LW · GW · 18 commentsContents
Introduction Steve’s framework Steve’s work in alignment theory Threat models Proposals for alignment Steve’s work in theoretical neuroscience A computational framework for the brain Relationship to alignment work Building from Steve’s framework Theory of mind as ‘hierarchical IRL’ that addresses Steve's first-person problem Self-referential misalignment Conclusion None 18 comments
This post was written under Evan Hubinger’s direct guidance and mentorship, as a part of the Stanford Existential Risks Institute ML Alignment Theory Scholars (MATS) program [AF · GW].
Many additional thanks to Steve Byrnes and Adam Shimi for their helpful feedback on earlier drafts of this post.
TL;DR: Steve Byrnes [AF · GW] has done really exciting work at the intersection of neuroscience and alignment theory. He argues that because we’re probably going to end up at some point with an AGI whose subparts at least superficially resemble those of the brain (a value function, a world model, etc.), it’s really important for alignment to proactively understand how the many ML-like algorithms in the brain actually do their thing. I build off of Steve’s framework in the second half of this post: first, I discuss why it would be worthwhile to understand the computations that underlie theory of mind + affective empathy. Second, I introduce the problem of self-referential misalignment, which is essentially the worry that initially-aligned ML systems with the capacity to model their own values could assign second-order values to these models that ultimately result in contradictory—and thus misaligned—behavioral policies. (A simple example of this general phenomenon in humans: Jack hates reading fiction, but Jack wants to be the kind of guy who likes reading fiction, so he forces himself to read fiction.)
Introduction
In this post, my goal is to distill and expand upon some of Steve Byrnes’s thinking on AGI safety. For those unfamiliar with his work, Steve thinks about alignment largely through the lens of his own brand of “big-picture” theoretical neuroscience. Many of his formulations in this space are thus original and ever-evolving, which is all the more reason to attempt to consolidate his core ideas in one space. I’ll begin by summarizing Steve’s general perspectives on AGI safety and threat models. I’ll then turn to Steve’s various models of the brain and its neuromodulatory systems and how these conceptualizations relate to AGI safety. In the second half of this post, I’ll spend time exploring two novel directions for alignment theory that I think naturally emerge from Steve’s thinking.
Steve’s framework
Steve’s work in alignment theory
In order to build a coherent threat model (and before we start explicitly thinking about any brain-based algorithms), Steve reasons that we first need to operationalize some basic idea of what components we would expect to constitute an AGI. Steve asserts that four ingredients [AF · GW] seem especially likely: a world model, a value function, a planner/actor, and a reward function calculator. As such, he imagines AGI to be fundamentally grounded in model-based RL.
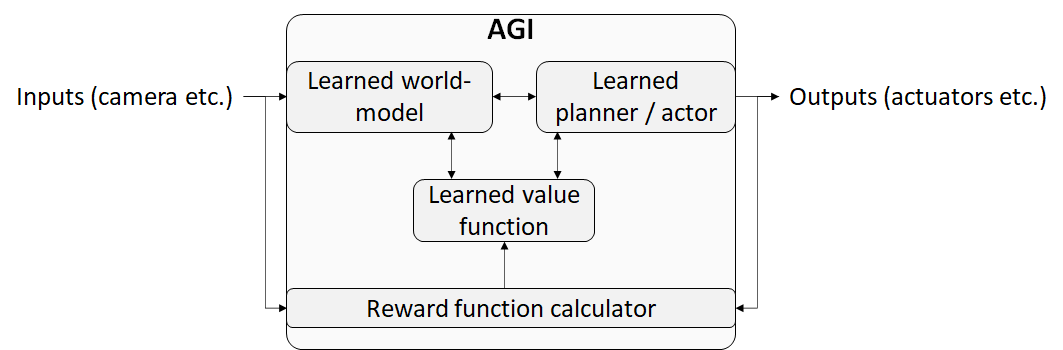
So, in the simple example of an agent navigating a maze, the world model would be some learned map of that maze, the value function might assign values to every juncture (e.g., turning left here = +5, turning right here = -5), the planner/actor would transmute these values into a behavioral trajectory, and the reward function calculator would translate certain outcomes of that trajectory into rewards for the agent (e.g., +10 for successfully reaching the end of the maze). Note here that the first three ingredients of this generic AGI—its world model, value function, and planner/actor—are presumed to be learned, while the reward function calculator is considered to be hardcoded or otherwise fixed. This distinction (reward function = fixed; everything else = learned) will be critical for understanding Steve’s subsequent thinking in AGI safety and his motivations for studying neuroscience.
Threat models
Using these algorithmic ingredients, Steve recasts inner alignment to simply refer to cases where an AGI’s value function converges to the sum of its reward function. Steve thinks inner-misalignment-by-default is not only likely, but inevitable, primarily because (a) many possible value functions could conceivably converge with any given reward history, (b) the reward function and value function will necessarily accept different inputs, (c) credit assignment failures [AF · GW] are unavoidable, and (d) reward functions will conceivably encode for mutually-incompatible goals, leading to an unpredictable and/or uncontrollable internal state of the AGI. It is definitely worth noting here that Steve knowingly uses “inner alignment” slightly differently from Risks from Learned Optimization [? · GW]. Steve’s threat model focuses on the risks of steered optimization, where the outer layer—here the reward function—steers the inner layer towards optimizing the right target, rather than those risks associated with mesa-optimization, where a base optimizer searches over a space of possible algorithms and instantiates one that is itself performing optimization. Both uses of the term concern the alignment of some inner and an outer algorithm (and it therefore seems fine to use “inner alignment” to describe both), but the functions and relationship of these two sub-algorithms differ substantially across the two uses. See Steve’s table in this article [AF · GW] for a great summary of the distinction. (It is also worth noting here that both steered and mesa-optimization are describable under Evan’s training story framework [LW · GW], where the training goal and rationale for some systems might respectively entail mesa-optimization and why a mesa-optimizer would be appropriate for the given task, while for other systems, the training goal will be to train a steered optimizer with some associated rationale for why doing so will lead to good results.)

Steve talks about outer alignment in a more conventional way: our translation into code of what we want a particular model or agent to do will be noisy, leading to unintended, unpredictable, and/or uncontrollable behavior from the model. Noteworthy here is that while Steve buys the distinction between inner and outer alignment, he believes that robust solutions to either problem will probably end up solving both problems, and so focusing exclusively on solving inner or outer alignment may not actually be the best strategy. Steve summarizes his position with the following analogy: bridge-builders have to worry both about hurricanes and earthquakes destroying their engineering project (two different problems), but it’s likely that the bridge-builders will end up implementing a single solution that addresses both problems simultaneously. So too, Steve contends, for inner and outer alignment problems. While I personally find myself agnostic on the question—I think it will depend to a large degree on the actual algorithms that end up comprising our eventual AGI—it is worth noting that this two-birds-one-stone claim might be contested by other [AF · GW] alignment theorists [AF · GW].
Proposals for alignment
I think Steve’s two big-picture ideas about alignment are as follows.
Big-picture alignment idea #1: Steve advocates for what he hopes is a Goodhart-proof [AF · GW] corrigibility approach wherein the AGI can learn the idea, say, that manipulation is bad, even in cases where it believes (1) that no one would actually catch it manipulating, and/or (2) that manipulation is in the best interest of the person being manipulated. Borrowing from the jargon of moral philosophy, we might call this “deontological corrigibility” (as opposed to “consequentialist corrigibility,” which would opt to manipulate in (2)-type cases). With this approach, Steve worries about what he calls the 1st-person-problem [AF · GW]: namely, getting the AGI to interpret 3rd-person training signals as 1st-person training signals. I will return to this concern later and explain why I think that human cognition presents a solid working example of the kinds of computations necessary for addressing the problem.
Steve argues that this first deontological corrigibility approach would be well-supplemented by also implementing “conservatism;” that is, a sort of inhibitory fail-safe that the AGI is programmed to deploy in motivational edge-cases. For example, if a deontologically corrigible AGI learns that lying is bad and that murder is also bad, and someone with homicidal intent is pressuring the AGI to disclose the location of some person (forcing the AGI to choose between lying and facilitating murder), the conservative approach would be for the AGI to simply inhibit both actions and wait for its programmer, human feedback, etc. to adjudicate the situation. Deontological corrigibility and conservatism thus go hand-in-hand, primarily because we would expect the former approach to generate lots of edge-cases that the AGI would likely evaluate in an unstable or otherwise undesirable way. I also think that an important precondition for a robustly conservative AGI is that it exhibits indifference corrigibility [AF · GW] as Evan operationalizes it, which further interrelates corrigibility and conservatism.
Big-picture alignment idea #2: Steve advocates, in his own words, “to understand the algorithms in the human brain that give rise to social instincts and put some modified version of those algorithms into our AGIs.” The thought here is that what would make a safe AGI safe is that it would share our idiosyncratic inductive biases and value-based intuitions about appropriate behavior in a given context. One commonly-proposed solution to this problem is to capture these intuitions indirectly through human-in-the-loop-style proposals like imitative amplification, safety via debate, reward modeling, etc. [AF · GW], but it might also be possible to just “cut out the middleman” and install the relevant human-like social-psychological computations directly into the AGI. In slogan form, instead of (or in addition to) putting a human in the loop, we could theoretically put "humanness" in our AGI. I think that Steve thinks this second big-picture idea is the more promising of the two, not only because he says so himself [AF · GW], but also because it dovetails very nicely with Steve’s theoretical neuroscience research agenda.
This second proposal in particular brings us to the essential presupposition of Steve’s work in alignment theory: the human brain is really, really important to understand if we want to get alignment right. Extended disclaimer: I think Steve is spot on here, and I personally find it surprising that this kind of view is not more prominent in the field. Why would understanding the human brain matter for alignment? For starters, it seems like by far the best example that we have of a physical system that demonstrates a dual capacity for general intelligence and robust alignment to our values. In other words, if we comprehensively understood how the human brain works at the algorithmic level, then necessarily embedded in this understanding should be some recipe for a generally intelligent system at least as aligned to our values as the typical human brain. For what other set of algorithms could we have this same attractive guarantee? As such, I believe that if one could choose between (A) a superintelligent system built in the relevant way(s) like a human brain and (B) a superintelligent system that bears no resemblance to any kind of cognition with which we’re familiar, the probability of serious human-AGI misalignment and/or miscommunication happening is significantly higher in (B) than (A).
I should be clear that Steve actually takes a more moderate stance than this: he thinks that brain-like AGIs might be developed whether it's a good idea or not—i.e., whether or not (A) is actually better than (B)—and that we should therefore (1) be ready from a theoretical standpoint if they do, and (2) figure out whether we would actually want them to be developed the first place. To this end, Steve has done a lot of really interesting distillatory work in theoretical neuroscience that I will try to further compress here and ultimately relate back to his risk models and solution proposals.
Steve’s work in theoretical neuroscience
A computational framework for the brain
I think that if one is to take any two core notions from Steve’s computational models of the brain [AF · GW], they are as follows: first, the brain can be bifurcated roughly into neocortex and subcortex—more specifically, the telencephalon and the brainstem/hypothalamus. Second, the (understudied) functional role of subcortex is to adaptively steer the development and optimization of complex models in the neocortex via the neuromodulatory reward signal, dopamine. Steve argues in accordance with neuroscientists like Jeff Hawkins that the neocortex—indeed, maybe the whole telencephalon—is a blank slate [AF · GW] at birth; only through (dopaminergic) subcortical steering signals does the neocortex slowly become populated by generative world-models. Over time, these models are optimized [AF · GW] (a) to be accurately internally and externally predictive, (b) to be compatible with our Bayesian priors, and (c) to predict big rewards (and the ones that lack one or more of these features are discarded). In Steve’s framing, these kinds of models serve as the thought/action proposals to which the basal ganglia assigns a value, looping the “selected” proposals back to cortex for further processing, and so on, until the action/thought occurs. The outcome of the action can then serve as a supervisory learning signal that updates the relevant proposals and value assignments in the neocortex and striatum for future reference.

Steve notes that there is not just a single kind of reward signal in this process; there are really something more like three signal-types. First, there is the holistic reward signal that we ordinarily think about. But there are also “local subsystem” rewards, which allocate credit (or “blame”) in a more fine-grained way. For example, slamming on the brakes to avoid a collision may phasically decrease the holistic reward signal (“you almost killed me, %*^&!”) but phasically increase particular subsystem reward signals (“nice job slamming those breaks, foot-brain-motor-loop!”). Finally, Steve argues that dopamine can also serve as a supervisory learning signal (as partially described above) in those cases for which a ground-truth error signal is available after the fact—a kind of “hindsight-is-20/20” dopamine.
So, summing it all up, here are the basic Steve-neuroscience-thoughts to keep in mind: neocortex is steered and subcortex is doing the steering, via dopamine. The neocortex is steered towards predictive, priors-compatible, reward-optimistic models, which in turn propose thoughts/actions to implement. The basal ganglia assigns value to these thoughts/actions, and when the high-value ones are actualized, we use the consequences (1) to make our world model more predictive, compatible, etc., and (2) to make our value function more closely align with the ground-truth reward signal(s). I’m leaving out many [AF · GW] really [AF · GW] interesting [AF · GW] nuances [AF · GW] in Steve’s brain models for the sake of parsimony here; if you want a far richer understanding of Steve's models of the brain, I highly recommend going straight to the source(s) [AF · GW].
Relationship to alignment work
So, what exactly is the relationship of Steve’s theoretical neuroscience work to his thinking on alignment? One straightforward point of interaction is Steve’s inner alignment worry about the value function differing from the sum of the reward function calculator. In the brain, Steve posits that the reward function calculator is something like the brainstem/hypothalamus—perhaps more specifically, the phasic dopamine signals produced by these areas—and that the brain’s value function is distributed throughout the telencephalon, though perhaps mainly to be found in the striatum and neocortex (specifically, in my own view, anterior neocortex). Putting these notions together, we might find that the ways that the brain’s reward function calculator and value function interact will tell us some really important stuff about how we should safely build and maintain similar algorithms in an AGI.
To evaluate the robustness of the analogy, it seems critical to pin down whether the reward signals that originate in the hypothalamus/brainstem can themselves be altered by learning or whether they are inflexibly hardcoded by evolution. Recall in Steve’s AGI development model that while the world model, value model, and planner/actor are all learned, the reward function calculator is not—therefore, it seems like the degree to which this model is relevant to the brain depends on (a) how important it is for an AGI that the reward function calculator is fixed the model, and (b) whether it actually is fixed in the brain. For (a), it seems fairly obvious that the reward function must be fixed in the relevant sense—namely, that the AGI cannot fundamentally change what constitutes a reward or punishment. As for (b), whether the reward function is actually fixed in the brain, Steve differentiates between the capacity for learning-from-scratch (e.g., what a neural network does) and “mere plasticity” (e.g., self-modifying code in Linux), arguing that the brain’s reward function is fixed in the first sense—but probably not the second. At the end of the day, I don’t think this asterisk on the fixedness of the brain’s reward function is a big problem for reconciling Steve’s safety and brain frameworks, given the comparatively limited scope of the kinds of changes that are possible under “mere plasticity.”
Steve’s risk models also clearly entail our elucidating the algorithms in the brain give rise to distinctly human social behavior (recall big picture alignment idea #2)—though up to this point, Steve has done (relatively [AF · GW]) less research on this front. I think it is worthwhile, therefore, to pick up in the next section by briefly introducing and exploring the implications of one decently-well-understood phenomenon that seems highly relevant to Steve’s work in this sphere: theory of mind (ToM).
Building from Steve’s framework
Theory of mind as ‘hierarchical IRL’ that addresses Steve's first-person problem
A cognitive system is said to have theory of mind (ToM) when it is able to accurately and flexibly infer the internal states of other cognitive systems. For instance, if we are having a conversation and you suddenly make the face pictured below, my ToM enables me to automatically infer a specific fact about what's going on in your mind: namely, that you probably don't agree with or are otherwise unsure about something I'm saying.

This general capacity definitely seems to me like a—if not the—foundational computation underlying sophisticated social cognition and behavior: it enables empathy, perspective-taking, verbal communication, and ethical consideration. Critically, however, there is a growing amount of compelling experimental evidence that ToM is not one homogenous thing. Rather, it seems to be functionally dissociable into two overlapping but computationally distinct subparts: affective ToM (roughly, “I understand how you’re feeling”) and cognitive ToM (roughly, “I understand what you’re thinking”). Thus, we should more precisely characterize the frown-eyebrow-raise example from above as an instance of affective ToM. Cognitive theory of mind, on the other hand, is classically conceptualized and tested as follows: Jessica has a red box and blue box in front of her. She puts her phone in the red box and leaves the room. While she’s gone, her phone is moved to the blue box. When Jessica comes back into the room, which box will she look for her phone? As obvious as it seems, children under the age of about three will respond at worse-than-chance levels. Answering correctly requires cognitive ToM: that is, the ability to represent that Jessica can herself court representations of the world that are distinct from actual-world states (this set-up is thus appropriately named the false-belief task). This is also why cognitive ToM is sometimes referred to as a meta-representational capacity.
One final piece of the puzzle that seems relevant is affective empathy, which adds to the “I understand how you’re feeling...” of affective ToM: “...and now I feel this way, too!”. The following diagram provides a nice summary of the three concepts:

To the extent Steve is right that “[understanding] the algorithms in the human brain that give rise to social instincts and [putting] some modified version of those algorithms into our AGIs” is a worthwhile safety proposal, I think we should be focusing our attention on instantiating the relevant algorithms that underlie affective and cognitive ToM + affective empathy. For starters, I believe these brain mechanisms supply the central computations that enable us homo sapiens to routinely get around Steve’s “1st-person-problem” (getting a cognitive system to interpret 3rd-person training signals as 1st-person training signals).
Consider an example: I see a classmate cheat on a test and get caught (all 3rd-person training signals). I think this experience would probably update my “don’t cheat (or at least don’t get caught cheating)” Q-value proportionally—i.e., not equivalently—to how it would have been updated were I the one who actually cheated (ultimately rendering the experience a 1st-person training signal). Namely, the value is updated to whatever quantity of context-dependent phasic dopamine is associated with the thought, “if I wasn’t going to try it before, I'm sure as hell not going to try it now.”
It seems clear to me that the central underlying computational mechanism here is ToM + affective empathy: I infer the cheater’s intentional state from his behavior (cognitive ToM; “he’s gone to the bathroom five times during this test = his intention is to cheat”), the affective valence associated with the consequences of this behavior (affective ToM; “his face went pale when the professor called him up = he feels guilty, embarrassed, screwed, etc.”), and begin to feel a bit freaked out myself (affective empathy; “that whole thing was pretty jarring to watch!”).
For this reason, I’m actually inclined to see Steve’s two major safety proposals (corrigibility + conservatism / human-like social instincts) as two sides of the same coin. That is, I think you probably get the kind of deontological corrigibility that Steve is interested in “for free” once you have the relevant human-like social instincts—namely, ToM + affective empathy.
The computation(s) underlying ToM + affective empathy are indisputably open research questions, ones that I think ought to be taken up by alignment theorists who share Steve-like views about the importance of instantiating the algorithms underpinning human-like social behavior in AGI. I do want to motivate this agenda here, however, by gesturing at one intriguingly simple proposal: ToM is basically just inverse reinforcement learning (IRL) through Bayesian inference. There already exists some good theoretical and neurofunctional work that supports this account. Whereas RL maps a reward function onto behavior, IRL (as its name suggests) maps behavior onto the likely reward/value function that generated it. So, RL: you take a bite of chocolate and you enjoy it, so you take another bite. IRL: I see you take one bite of chocolate and then another, so I infer that you expected there to be some reward associated with taking another bite—i.e., I infer that you enjoyed your first bite. At first glance, IRL does seem quite a bit like ToM. Let’s look a bit closer:

The basic story this model tells is as follows: an agent (inner loop) finds itself in some state of the world at time t. Assuming a Steve-like model of the agent's various cognitive sub-algorithms, we can say the agent uses (A) its world model to interpret its current state and (B) its value function to assign some context-dependent value to the activated concepts in its world model. Its actor/planner module then searches over these values to find a high-value behavioral trajectory that the agent subsequently implements, observes the consequences of, and reacts to. The world state changes as a result of the agent’s action, and the cycle recurs. In addition to the agent, there is an observer (outer ovals) who is watching the agent act within its environment.
Here, the cognitive ToM of the observer performs Bayesian inference over the agent’s (invisible) world model and intended outcome given their selected action. For instance, given that you just opened the fridge, I might infer (1) you believe there is food in the fridge, and (2) you probably want to eat some of that food. (This is Bayesian because my priors constrain my inference—e.g., given my assorted priors about your preferences, typical fridge usage, etc., I assign higher probability to your opening the fridge because you're hungry than to your opening the fridge because you just love opening doors.)
The observer's affective ToM then takes one of these output terms—the agent’s intended outcome—as input and compares it to the actual observed outcome in order to infer the agent’s reaction. For example, if you open the fridge and there is no food, I infer, given (from cognitive ToM) that you thought there was going to be food and you intended to eat some of it, that (now with affective ToM) you’re pretty disappointed. (I label this whole sub-episode as “variably visible” because in some cases, we might get additional data that directly supports a particular inference, like one's facial expression demonstrating their internal state as in the cartoon from earlier.)
Finally, affective empathy computes how appropriate it is for the observer to feel way X given the inference that the agent feels way X. In the fridge example, this translates to how disappointed I should feel given that (I’ve inferred) you’re feeling disappointed. Maybe we're good friends, so I feel some "secondhand" disappointment. Or, maybe your having raided the fridge last night is the reason it's empty, in which case I feel far less for you.
I suppose this sort of simple computational picture instantiates a kind of “hierarchical IRL,” where each inference provides the foundation upon which the subsequent inference occurs (cognitive ToM → affective ToM → affective empathy). This hypothesis would predict that deficits in one inference mechanism should entail downstream (but not upstream) deficits—e.g., affective ToM deficits should entail affective empathy deficits but not necessarily cognitive ToM deficits. (The evidence for this is murky and probably just deserves a blog post of its own to adjudicate.)
Suffice it to simply say here that I think alignment theorists who find human sociality interesting should direct their attention to the neural algorithms that give rise to cognitive and affective ToM + affective empathy. (One last technical note: ToM + empathetic processing seems relevantly lateralized. As excited about Steve’s computational brain framework as I am, I think the question of functional hemispheric lateralization is a fruitful and fascinating one that Steve tends to emphasize less in his models, I suspect because of his sympathies to “neocortical blank-slate-ism.”)
Self-referential misalignment
The last thing I’d like to do in this post is to demonstrate how Steve’s “neocortex-subcortex, steered-steerer” computational framework might lead to novel inner alignment problems. Recall that we are assuming our eventual AGI (whatever degree of actual neuromorphism it displays) will be composed of a world model, a value function, a planner/actor, and a reward function calculator. Let’s also assume that something like Steve’s picture of steered optimization is correct: more specifically, let’s assume that our eventual AGI displays some broad dualism of (A) telencephalon-like computations that constitute the world model, value function, and actor/planner, and (B) hypothalamus-/brainstem-like computations that constitute the reward function calculator. With these assumptions in place, let's consider a simple story:
Jim doesn’t particularly care for brussel sprouts. He finds them to be a bit bitter and bland, and his (hypothalamus-/brainstem-supplied) hardwired reaction to foods with this flavor profile is negatively-valenced. Framed slightly differently, perhaps in Jim’s vast Q-table/complex value function, the action “eat brussel sprouts” in any state where brussel sprouts are present has a negative numerical value (in neurofunctional terms, this would correspond to some reduction in phasic dopamine). Let's also just assert that this aversion renders Jim aligned with respect to his evolutionarily-installed objective to avoid bitter (i.e., potentially poisonous) foods. But Jim, like virtually all humans—and maybe even some clever animals—does not just populate his world model (and the subsequent states that feature in his Q-table/value function) with exogenous phenomena like foods, places, objects, and events; he also can model (and subsequently feature in his Q-table/value function) various endogenous phenomena like his own personality, behavior, and desires. So, for instance, Jim not only could assign some reward-function-mediated value to “brussel sprouts;” he could also assign some reward-function-mediated value to the abstract state of “being the kind of person who eats brussel sprouts.”
If we assume that Jim’s brain selects greedy behavioral policies and that, for Jim, the (second-order) value of being the kind of guy who eats brussel sprouts relevantly outweighs the (first-order) disvalue of brussel sprouts, we should expect that Jim’s hypothalamus-/brainstem-supplied negative reaction to bitter foods will be ignored in favor of his abstract valuation that it is good to be the brussel-sprout-eating-type. Now, from the perspective of Jim’s “programmer” (the evolutionary pressure to avoid bitter foods), he is demonstrating inner misalignment—in Steve’s terms, his value function certainly differs from the sum of his “avoid-bitter-stuff” reward function.
There are many names that this general type of scenario goes by: delaying gratification, exhibition of second-order preferences (e.g., “I really wanted to like Dune, but…”), appealing to higher-order values, etc. However, in this post, I’ll more specifically refer to this kind of problem as self-referential misalignment. Informally, I'm thinking of self-referential misalignment as what happens when some system capable of self-modeling develops and subsequently acts upon misaligned second-order preferences that conflict with its aligned first-order preferences.

There seem to be at least three necessary conditions for ending up with an agent displaying self-referential misalignment. I’ll spell them out in Steve-like terminology:
- The agent is a steered optimizer/online learner whose value function, world model, and actor/planner modules update with experience.
- The agent is able to learn the relevant parts of its own value function, actor/planner, and/or reward function calculator as concepts within its world model. I’ll call these “endogenous models.”
- The agent can assign value to endogenous models just as it can for any other concept in the world model [AF · GW].
If a system can’t do online learning at all, it is unclear how it would end up with Jim-like preferences about its own preferences—presumably, while bitterness aversion is hardcoded into the reward function calculator at “deployment,” his preference to keep a healthy diet is not. So, if this latter preference is to emerge at some point, there has to be some mechanism for incorporating it into the value function in an online manner (condition 1, above).
Next, the agent must be capable of a special kind of online learning: the capacity to build endogenous models. Most animals, for example, are presumably unable to do this: a squirrel can model trees, buildings, predators, and other similarly exogenous concepts, but it can’t endogenously model its own proclivities to eat acorns, climb trees, and so on (thus, a squirrel-brain-like-algorithm would fail to meet condition 2, above).
Finally, the agent must not only be capable of merely building endogenous models, but also of assigning value to and acting upon them—that is, enabling them to recursively flow back into the value and actor/planner functions that serve as their initial basis. It is not enough for Jim to be able to reason about himself as a kind of person who eats/doesn’t eat brussel sprouts (a descriptive fact); he must also be able to assign some value about this fact (a normative judgment) and ultimately alter his behavioral policy in light of this value assignment (condition 3, above).
If a system displays all three of the capacities, I think it is then possible for that system to exhibit self-referential misalignment in the following, more formal sense:

Let’s see what self-referential misalignment might look like in a more prosaic-AI-like [AF · GW] example. Imagine we program an advanced model-based RL system to have conversations with humans, where its reward signal is calculated given interlocutor feedback. We might generally decide that a system of this type is outer aligned as long as it doesn’t say or do any hateful/violent/harmful stuff. The system is inner aligned (in Steve’s sense) if the reward signal shapes a value function that converges to an aversion to saying or doing hateful/violent/harmful stuff (for the right reasons). Throw in capability robustness [AF · GW] (i.e., the system can actually carry on a conversation), and, given the core notion of impact alignment [AF · GW], I think one would then have the necessary conditions the system would have to fulfill in order to be considered aligned. So then let’s say we build a reward function that takes as input the feedback of the system’s past conversation partners and outputs some reward signal that is conducive to shaping a value function that is aligned in the aforementioned sense. It’s plausible that this value function (when interpreted) would have some of the following components: “say mean things = -75; say funny things = 25; say true things = 35; say surprising things = 10”.
Then, if the system can build endogenous models, this means that it will be conceivable that (1) the system learns the fact that it disvalues saying mean things, the fact that it values saying funny things, etc., and that (2) the system is subsequently able to assign value to these self-referential concepts in its world-model. With the four values enumerated above, for instance, the system could plausibly learn to assign some context-dependent negative value to the very fact that it disvalues saying mean things (i.e., the system learns to “resent” the fact that it’s always nice to everyone). This might be because, in certain situations, the system learns that saying something a little mean would have been surprising, true, and funny (high-value qualities)—and yet it chose not to. Once any valuation like this gains momentum or is otherwise “catalyzed” under the right conditions, I think it is conceivable that the system could end up displaying self-referential misalignment, learning to override its aligned first-order preferences in the service of misaligned higher-order values.

This example is meant to demonstrate that a steered optimizer capable of building/evaluating endogenous models might be totally aligned + capability robust over its first-order preferences but may subsequently become seriously misaligned if it generates preferences about these preferences. Here are two things that make me worry about self-referential alignment as a real and important problem:
- Self-referential concepts are probably really powerful; there is therefore real incentive to build AGI with the ability to build endogenous models.
- The more generally capable the system (i.e., the closer to AGI we get), the more self-referential misalignment seems (a) more likely and (b) more dangerous.
I think (1) deserves a post of its own (self-reference is probably a really challenging double-edged sword), but I will try to briefly build intuition here: for starters, the general capacity for self-reference has been hypothesized to underlie language production and comprehension, self-consciousness, complex sociality—basically, much of the key stuff that makes humans uniquely intelligent. So to the degree we’re interested in instantiating a competitive [AF · GW], at-least-human-level general intelligence in computational systems, self-reference may prove a necessary feature. If so, we should definitely be prepared to deal with the alignment problems that accompany it.
Regarding (2), I think that the general likelihood self-referential misalignment is proportional to the general intelligence of the system in question—this is because the more generally capable a system is, the more likely it will be to court diversified and complex reward streams and value functions that can be abstracted over and plausibly interact at higher levels of abstraction. One reason, for instance, that Jim may actually want to be the kind of person who eats his veggies is because, in addition to his bitterness aversion, his value function is also shaped by social rewards (e.g., his girlfriend thinks it’s gross that he only ate Hot Pockets in college, and Jim cares a lot about what his girlfriend thinks of him). In practice, any higher-order value could conceivably override any aligned first-order value. Thus, the more complex and varied the first-order value function of an endogenous-modeling-capable system, the more likely that one or more emergent values will be in conflict with one of the system’s foundational preferences.
On this note, one final technical point worth flagging here is that Steve’s framework almost exclusively focuses on dopamine as the brain’s unitary “currency” for reward signals (which themselves may well number hundreds), but I don’t think it's obvious that dopamine is the brain’s only reward signal currency, at least not across larger spans of time. Specifically, I think that serotonin is a plausible candidate for another neuromodulatory (social, I think) reward-like signal in the brain. If correct, this would matter a lot: if there is more than one major neuromodulatory signal-type in the brain that shapes the telencephalic value function, I think the plausibility of getting adversarial reward signals—and consequently self-referential misalignment—substantially increases (e.g., dopamine trains the agent to have some value function, but serotonin separately trains the agent to value being the kind of agent that doesn’t reflexively cater to dopaminergically-produced values). For this reason, I think a better computational picture of serotonin in the brain to complement Steve’s Big picture of phasic dopamine [AF · GW] is thus highly relevant for alignment theory.
This is more to say about this problem of self-referential misalignment in steered optimizers, but I will now turn my attention to discussing two potential solutions (and some further questions that need to be answered about each of these solutions).
Solution #1: avoid one or more of the necessary conditions that result in a system exhibiting conflicting second-order preferences. Perhaps more specifically, we might focus on simply preventing the system from developing endogenous models (necessary condition 2, above). I think there is some merit to this, and I definitely want to think more about this somewhere else. One important problem I see with this proposal, however, is that it doesn’t fully appreciate the complexities of embedded agency [AF · GW]—for example, the agent’s values will inevitably leave an observable trace on its (exogenous) environment across time that may still allow the agent to learn about itself (e.g., a tree-chopping agent who cannot directly endogenously model may still be able to indirectly infer from its surroundings the self-referential notion that it is the kind of agent who cuts down trees). It's possible that some form of myopia [? · GW] could helpfully address this kind of problem, though I'm currently agnostic about this.
Solution #2: simply implement the same kind of Steve-like conservative approach we might want to employ for other kinds of motivational edge-cases (e.g., from earlier, don’t be manipulative vs. don’t facilitate murder). I think this is an interesting proposal, but it also runs into problems. I suppose that I am just generally skeptical of conservatism as a competitive safety proposal [AF · GW], as Evan puts it—it seems to entail human intervention whenever the AGI is internally conflicted about what to do, which is extremely inefficient and would probably be happening constantly. But in the same way that the direct instantiation of human-like social instincts may be a more parsimonious and “straight-from-the-source” solution than constantly deferring to humans, perhaps so too for conflicted decision-making: might it make sense “simply” to better understand the computational underpinnings of how we trade-off various good alternatives rather than defer to humans every time the AGI encounters a motivational conflict? Like with the first solution, I think there is something salvageable here, but it requires a more critical look. (It’s worth noting that Steve is skeptical of my proposal here. He thinks that the way humans resolve motivational conflicts isn’t actually a great template for how AGI should do it, both because we’re pretty bad at this ourselves and because there may be a way for AGI to go "back to ground truth" in resolving these conflicts—i.e. somehow query the human—in a way that biology can't—i.e., you can't go ask Inclusive Genetic Fitness what to do in a tricky situation.)
Finally, I should note that I don’t yet have a succinct computational story of how self-referential (mis)alignment might be instantiated in the brain. I suspect that it would roughly boil down to having a neural-computational description of how endogenous modeling happens—i.e., what kinds of interactions between the areas of neocortex differentially responsible for building the value function and those responsible for building the world model are necessary/sufficient for endogenous modeling? As I was hinting at previously, there are some animals (e.g., humans) that are certainly capable of endogenous modeling, while there are others (e.g., squirrels) that are certainly not—and there are yet other animals that occupy something of a grey area (e.g., dolphins). There are presumably neurostructural/neurofunctional cross-species differences that account for this variance in the capacity to endogenously model, but I am totally ignorant of them at present. Needless to say, I think it is critical to get clearer on exactly how self-referential misalignment happens in the brain so that we can determine whether a similar algorithm is being instantiated in an AGI. I also think that this problem is naturally related to instrumental behavior in learning systems, most notably deceptive alignment [AF · GW], and it seems very important to elucidate this relationship in further work.
Conclusion
Steve Byrnes’s approach to AGI safety is powerful, creative, and exciting, and that far more people should be doing alignment theory research through Steve-like frameworks. I think that the brain is the only working example we have of a physical system that demonstrates both (a) general intelligence and, as Eliezer Yudkowsky has argued [AF · GW], (b) the capacity to productively situate itself within complex human value structures, so attempting to understand how it achieves these things at the computational level and subsequently instantiating the relevant computations in an AGI seems far more likely to be a safe and effective strategy than building some giant neural network that shares none of our social intuitions or inductive biases. Steve’s high-level applications of theoretical neuroscience to AGI alignment has proved a highly generative research framework, as I have tried to demonstrate here by elaborating two natural extensions of Steve’s ideas: (1) the necessity to understand the computational underpinnings of affective and cognitive theory of mind + affective empathy, and (2) the concern that a "neocortex-subcortex, steered-steerer” framework superimposed upon Steve’s “four-ingredient AGI” gives rise to serious safety concerns surrounding endogenous modeling and self-referential misalignment, both of which I claim are ubiquitously displayed by the human brain.
If you have any questions, comments, or ideas about what I’ve written here, please feel free to simply comment below or email me at cameron.berg@yale.edu—I would love to talk more about any of this!
18 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2021-12-08T19:41:25.221Z · LW(p) · GW(p)
Thanks for writing this!! Great post, strong endorse. Here are some nitpicks / elaborations.
I think the question of functional hemispheric lateralization is a fruitful and fascinating one that Steve tends to emphasize less in his models, I suspect because of his sympathies to “neocortical blank-slate-ism.”
The cortex has a rather complicated neural architecture, with allegedly 180 distinguishable regions, which have different types and densities of connections with each other and with other parts of the brain, different "hyperparameters", etc. I want to say that cortical hemispherical specialization is a special case of this more general phenomenon of cortical specialization. So I would say: "I haven't blogged about the differences between hemispheres" is in the same category as "I haven't blogged about the difference between the mid-insular cortex and the posterior insular cortex". Of course there are interesting differences; it just hasn't come up. :-P As it happens, I do have strong opinions about the roles of mid-insular cortex vs posterior insular cortex, even if I haven't written about them. By contrast, I'm pretty ignorant about hemispherical differences, with a few exceptions. I haven't read Master & Emissary. It's possible that I'm missing something important. :)
I also have found that the phrase "blank slate" gives people the wrong idea, and switched to "learning from scratch" with the definition here [LW · GW].
self-referential misalignment
I agree with this part. We certainly don't want an AGI with aligned object-level motivations, but regards these motivations as ego-dystonic :-P There's a sense in which misaligned self-reflective thoughts and misaligned object-level thoughts are "all just part of the alignment problem", but I think the misaligned self-reflective thoughts are a sufficiently impactful and probable failure mode that they're worth thinking about separately.
ToM is basically just inverse reinforcement learning (IRL) through Bayesian inference.
Sure. We can construct a compositional generative model of a person and fit it to the data using Bayesian inference, just as we can construct a compositional generative model of a car engine and fit it to the data using Bayesian inference. In fact, I talked to a couple people with autism and they both independently described learning to interact with and understand and predict people as feeling similar to gaining an understanding of how car engines work etc. (If I understood them correctly.) They had excellent ToM by the way; they would have no problem whatsoever with Jessica's red box. I think it's an interesting sign that neurotypical people probably wouldn't describe learning-to-socialize in that way, and suggests that the IRL part is at most just a piece of the puzzle. (Which I guess is consistent with what you said.)
affective empathy, which adds to the “I understand how you’re feeling...” of affective ToM: “...and now I feel this way, too!”.
Sure, that is a thing. But there's also a thing where, knowing how somebody's feeling induces a reaction, but the reaction is not in the direction of feeling more similar to them. For example, if I'm suffering, and I see that you're laughing at me, it does NOT make me feel more like you feel (playful and safe and high-status), but rather it makes me feel mad as hell. Or if you're sad, maybe I'll feel sad, but also maybe I'll feel schadenfreude. I assume that both the "sad" reaction and the "schadenfreude" reaction are innate reactions. Somehow the genome has encoded into the brain a system for deciding whether "sad" or "schadenfreude" is the correct reaction in any given situation. I'm confused what that system is / how it's built.
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2021-12-14T20:36:12.954Z · LW(p) · GW(p)
Thank you! I think these are all good/important points.
In regards to functional specialization between the hemispheres, I think whether this difference is at the same level as mid-insular cortex vs posterior insular cortex would depend on whether the hemispheric differences can account for certain lower-order distinctions of this sort or not. For example, let's say that there are relevant functional differences between left ACC and right ACC, left vmPFC and right vmPFC, and left insular cortex and right insular cortex—and that these differences all have something in common (i.e., there is something characteristic about the kinds of computations that differentiate left-hemispheric ACC, vmPFC, insula from right-hemispheric ACC, vmPFC, insula). Then, you might have a case for the hemispheric difference being more fundamental or important than, say, the distinction between mid-insular cortex vs posterior insular cortex. But that's only if these conditions hold (i.e., that there are functional differences and these differences have intra-hemispheric commonalities). I think there's a good chance something like this might be true, but I obviously haven't put forward an argument for this yet, so I don't blame anyone for not taking my word for it!
I'm not fully grasping the autism/ToM/IRL point yet. My understanding of people on the autism spectrum is that they typically lack ordinary ToM, though I'm certainly not saying that I don't believe the people you've spoken with; maybe only that they might be the exception rather than the rule (there are accounts that emphasize things others than ToM, though, to your point). If it is true that (1) autistic people use mechanisms other than ToM/IRL to understand people (i.e., modeling people like car engines), and (2) autistic people have social deficits, then I'm not yet seeing how this demonstrates that IRL is 'at most' just a piece of the puzzle. (FWIW, I would be surprised if IRL were the only piece of the puzzle; I'm just not yet grasping how this argument shows this.) I can tell I'm missing something.
And I agree with the sad vs. schadenfreude point. I think in an earlier exchange you made the point that this sort of thing could be conceivably modulated by in-group style dynamics. More specifically, I think that the extent to which I can look at a person, their situation, the outcome, etc., and notice (probably implicitly) that I could end up in a similar situation, it's adaptive for me to "simulate" what it is probably like for them to be in this position so I can learn from their experience without having to go through the experience myself. As you note, there are exceptions to this—I think this is particularly when we are looking at people more as "objects" (i.e., complex external variables in our environments) than "subjects" (other agents with internal states, goals, etc. just like me). I think this is well-demonstrated by the following examples.
1, lion-as-subject: I go to the zoo and see a lion. "Ooh, aah! Super majestic." Suddenly, a huge branch falls onto the lion, trapping it. It yelps loudly. I audibly wince, and I really hope the lion is okay. (Bonus subjects: other people around the enclosure also demonstrate they're upset/disturbed by what just happened, which makes me even more upset/disturbed!)
2: lion-as-object: I go on a safari alone and my car breaks down, so I need to walk to the nearest station to get help. As I'm doing this, a lion starts stalking and chasing me. Oh crap. Suddenly, a huge branch falls onto the lion, trapping it. It yelps loudly. "Thank goodness. That was almost really bad."
Very different reactions to the same narrow event. So I guess this kind of thing demonstrates to me that I'm inclined to make stronger claims about affective empathy in those situations where we're looking at other agents in our environment as subjects, not objects. I think in eusocial creatures like humans, subject-perspective is probably far more common than object-perspective, though one could certainly come up with lots of examples of both. So definitely more to think about here, but I really like this kind of challenge to an overly-simplistic picture of affective empathy wherein someone else feeling way X automatically and context-independently makes me feel way X. This, to your point, just seems wrong.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-15T16:05:55.597Z · LW(p) · GW(p)
My understanding of people on the autism spectrum is that they typically lack ordinary ToM
The link says "high-functioning adults with ASD…can easily pass the false belief task when explicitly asked to". So there you go! Perfectly good ToM, right?
The paper also says they "do not show spontaneous false belief attribution". But if you look at Figure 3, they "fail" the test by looking equally at the incorrect window and correct window, not by looking disproportionately at the incorrect window. So I would suggest that the most likely explanation is not that the ASD adults are screwing up the ToM task, but rather that they're taking no interest in the ToM task! Remember, the subjects were never asked to pay any attention to the person! Maybe they just didn't! So I say this is a case of motivation, not capability [LW · GW]. Maybe they were sitting there during the test, thinking to themselves "Gee, that's a neat diorama, I wonder how the experimenters glued it together!" :-P That would also be consistent with the eye-tracking results mentioned in the book excerpt here [LW · GW]. (I recall also a Temple Grandin anecdote (I can't immediately find it) about getting fMRI'd, and she said she basically ignored the movie she was nominally supposed to be looking at, because she was so interested in some aspect of how the scientists had set up the experiment.) Anyway, the paper you link doesn't report (AFAICT) what fraction of the time the subjects are looking at neither window—they effectively just throw those trials away I think—which to me seems like discarding the most interesting data!
If it is true that (1) autistic people use mechanisms other than ToM/IRL to understand people (i.e., modeling people like car engines)
I think you misunderstood me here. I'm suggesting that maybe:
- ToM ≈ IRL ≈ building a good generative model that explains observations of humans
- "understanding car engines" ≈ building a good generative model that explains observations of car engines.
I guess you're assuming that a good generative model of a mind must contain special ingredients that a good generative model of a car engine does not need? I don't currently think that. Well, more specifically, I think "the particular general-purpose toolkit that a human brain uses for building generative models" is sufficient for both modeling minds and modeling car engines. (I can imagine other generative-model-building toolkits that are not.) For example, the thought "Sally believes the sky is green" seems to me to be of similarly construction to the thought "The engine is not painted green, but if it were, the paint would quickly rub off and contaminate the engine fluid". Both kinda involve an invoking and manipulation of a counterfactual world and relating it to the real world. I could be wrong, but anyway that's what I meant.
comment by Charlie Steiner · 2021-12-08T13:58:00.679Z · LW(p) · GW(p)
Nice post!
I think one of the things that average AI researchers are thinking about brains is that humans might not be very safe for other humans (link to Wei Dai post [LW · GW]). I at least would pretty strongly disagree with "The brain is a totally aligned general intelligence."
I really like the thought about empathy as an important active ingredient in learning from other peoples' experience. It's very cool. It sort of implies an evo-psych story about the incentives for empathy that I'm not sure is true - what's the prevalence of empathy in social but non-general animals?
Also, by coincidence, I just today finished a late draft of a post on second-order alignment, except with the other perspective (modeling it in humans, rather than in AIs), so I'm feeling some competition :P
Replies from: steve2152, cameron-berg↑ comment by Steven Byrnes (steve2152) · 2021-12-08T18:34:56.161Z · LW(p) · GW(p)
humans might not be very safe for other humans
There's a weaker statement, "there exist humans who have wound up with basically the kinds of motivations that we would want an AGI to have". For example, Eliezer endorses a statement kinda like that here [LW · GW] (and he names names—Carl Shulman & Paul Christiano). If you believe that weaker statement, it suggests that we're mucking around in a generally-promising space, but that we still have work to do. Note that motivations come from a combination of algorithms and "training data" / "life experience", both of which are going to be hard or impossible to match perfectly between humans and AGIs. The success story requires having enough understanding to reconstruct the important-for-our-purposes aspects.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-09T00:54:18.487Z · LW(p) · GW(p)
Part of what makes me skeptical of the logic "we have seen humans who we trust, so the same design space probably has decent density of superhumans who we'd trust" is that I'm not sold on the the (effective) orthogonality thesis for human brains. Our cognitive limitations seem like they're an active ingredient in our conceptual/moral development. We might easily know how to get human-level brain-like AI to be trustworthy but never know how to get the same design with 10x the resources to be trustworthy.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-09T01:39:59.867Z · LW(p) · GW(p)
There are humans with a remarkable knack for coming up with new nanotech inventions. I don't think they (we?) have systematically different and worse motivations than normal humans. If they had even more of a remarkable knack—outside the range of humans—I don't immediately see what would go wrong.
If you personally had more time to think and reflect, and more working memory and attention span, would you be concerned about your motivations becoming malign?
(We might be having one of those silly arguments where you say "it might fail, we would need more research" and I say "it might succeed, we would need more research", and we're not actually disagreeing about anything.)
↑ comment by Cameron Berg (cameron-berg) · 2021-12-14T20:51:30.429Z · LW(p) · GW(p)
Thank you!
I don't think I claimed that the brain is a totally aligned general intelligence, and if I did, I take it back! For now, I'll stand by what I said here: "if we comprehensively understood how the human brain works at the algorithmic level, then necessarily embedded in this understanding should be some recipe for a generally intelligent system at least as aligned to our values as the typical human brain." This seems harmonious with what I take your point to be: that the human brain is not a totally aligned general intelligence. I second Steve's deferral to Eliezer's thoughts [LW · GW] on the matter, and I mean to endorse something similar here.
what's the prevalence of empathy in social but non-general animals?
Here's a good summary. I also found a really nice non-academic article in Vox on the topic.
And I'm looking forward to seeing your post on second-order alignment! I think the more people who take the concern seriously (and put forward compelling arguments to that end), the better.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-14T21:11:30.869Z · LW(p) · GW(p)
Ah, you're too late to look forward to it, it's already published [LW · GW]:P
comment by evhub · 2021-12-13T23:38:11.766Z · LW(p) · GW(p)
To the extent Steve is right that “[understanding] the algorithms in the human brain that give rise to social instincts and [putting] some modified version of those algorithms into our AGIs” is a worthwhile safety proposal, I think we should be focusing our attention on instantiating the relevant algorithms that underlie affective and cognitive ToM + affective empathy.
It seems to me like you would very likely get both cognitive and affective theory of mind “for free” in the sense that they're necessary things to understand for predicting humans well. If we expect to gain something from studying how humans implement these processes, it'd have to be something like ensuring that our AIs understand them “in the same way that humans do,” which e.g. might help our AIs generalize in a similar way to humans.
This is notably in contrast to affective empathy, though, which is not something that's inherently necessary for predictive accuracy—so figuring out how/why humans do that has a more concrete story for how that could be helpful.
If a system can’t do online learning at all, it is unclear how it would end up with Jim-like preferences about its own preferences—presumably, while bitterness aversion is hardcoded into the reward function calculator at “deployment,” his preference to keep a healthy diet is not. So, if this latter preference is to emerge at some point, there has to be some mechanism for incorporating it into the value function in an online manner (condition 1, above).
Why couldn't the preference for a healthy diet emerge during training? I don't understand why you think online learning is necessary here. It feels like, rather than “online learning” being the important thing here, what you're really relying on is just “learning.”
Replies from: steve2152, cameron-berg↑ comment by Steven Byrnes (steve2152) · 2021-12-14T14:58:53.855Z · LW(p) · GW(p)
For my part, I strongly agree with the first part, and I said something similar in my comment [LW(p) · GW(p)].
For the second part, if we're talking about within-lifetime brain learning / thinking, we're talking about online-learning. For example, if I'm having a conversation with someone, and they tell me their name is Fred, and then 2 minutes later I say "Well Fred, this has been a lovely conversation", I can thank online-learning for my remembering their name. Another example: the math student trying to solve a homework problem (and learning from the experience) is using the same basic algorithms as the math professor trying to prove a new theorem—even if the first is vaguely analogous to "training" and the second to "deployment".
So then you can say: "Well fine, but online learning is pretty unfashionable in ML today. Can we talk about what the brain's within-lifetime learning algorithms would look like without online learning?" And I would say: "Ummmm, I don't know. I'm not sure that's a coherent or useful thing to talk about. A brain without online-learning would look like unusually severe retrograde [oops I meant anterograde] amnesia."
That's not a criticism of what you said. Just a warning that "non-online-learning versions of brain algorithms" is maybe an incoherent notion that we shouldn't think too hard about. :)
↑ comment by Cameron Berg (cameron-berg) · 2021-12-14T21:20:02.210Z · LW(p) · GW(p)
If we expect to gain something from studying how humans implement these processes, it'd have to be something like ensuring that our AIs understand them “in the same way that humans do,” which e.g. might help our AIs generalize in a similar way to humans.
I take your point that there is probably nothing special about the specific way(s) that humans get good at predicting other humans. I do think that "help[ing] our AIs generalize in a similar way to humans" might be important for safety (e.g., we probably don't want an AGI that figures out its programmers way faster/more deeply than they can figure it out). I also think it's the case that we don't currently have a learning algorithm that can predict humans as well as humans can predict humans. (Some attempts, but not there yet.) So to the degree that current approaches are lacking, it makes sense to me to draw some inspiration from the brain-based algorithms that already implement these processes extremely well—i.e., to first understand these algorithms, and to later develop training goals [AF · GW] in accordance with the heuristics/architecture these algorithms seem to instantiate.
This is notably in contrast to affective empathy, though, which is not something that's inherently necessary for predictive accuracy—so figuring out how/why humans do that has a more concrete story for how that could be helpful.
Agreed! I think it's worth noting that if you take seriously the 'hierarchical IRL' model I proposed in the ToM section [LW · GW], understanding the algorithm(s) underlying affective empathy might actually require understanding cognitive and affective ToM (i.e., if these are the substrate of affective empathy, we'll probably need a good model of them before we can have a good model of affective empathy).
And wrt learning vs. online learning, I think I'm largely in agreement with Steve's reply. I would also add that this might end up just being a terminological dispute depending on how flexible we are with calling particular phases "training" vs. "deployment." E.g., is a brain "deployed" when the person's genetic make-up as a zygote is determined? Or is it when they're born? When their brain stops developing? When they learn the last thing they'll ever learn? To the degree we think these questions are awkward/their answers are arbitrary, I would think this counts as evidence that the notion of "online learning" is useful to invoke here/gives us more parsimonious answers.
comment by teradimich · 2021-12-08T14:38:20.840Z · LW(p) · GW(p)
It seems to me that the brains of many animals can be aligned with the goals of someone much more stupid themselves.
People and pets. Parasites and animals. Even ants and fungus.
Perhaps the connection that we would like to have with superintellence, is observed on a much smaller scale.
↑ comment by Cameron Berg (cameron-berg) · 2021-12-14T21:27:27.423Z · LW(p) · GW(p)
I think this is an incredibly interesting point.
I would just note, for instance, in the (crazy cool) fungus-and-ants case, this is a transient state of control that ends shortly thereafter in the death of the smarter, controlled agent. For AGI alignment, we're presumably looking for a much more stable and long-term form of control, which might mean that these cases are not exactly the right proofs of concept. They demonstrate, to your point, that "[agents] can be aligned with the goals of someone much stupider than themselves," but not necessarily that agents can be comprehensively and permanently aligned with the goals of someone much stupider than themselves.
Your comment makes me want to look more closely into how cases of "mind control" work in these more ecological settings and whether there are interesting takeaways for AGI alignment.
Replies from: teradimich↑ comment by teradimich · 2021-12-14T22:34:46.790Z · LW(p) · GW(p)
Glad you understood me. Sorry for my english!
Of course, the following examples themselves do not prove the opportunity to solve the entire problem of AGI alignment! But it seems to me that this direction is interesting and strongly underestimated. Well, someone smarter than me can look at this idea and say that it is bullshit, at least.
Partly this is a source of intuition for me, that the creation of aligned superintellect is possible. And maybe not even as hard as it seems.
We have many examples of creatures that follow the goals of someone more stupid. And the mechanism that is responsible for this should not be very complex.
Such a stupid process, as a natural selection, was able to create mentioned capabilities. It must be achievable for us.
comment by Martin Randall (martin-randall) · 2021-12-10T03:25:32.824Z · LW(p) · GW(p)
I'm confused about the example of Jim eating Brussel sprouts - I don't see how it shows inner misalignment as written. I think a more complicated example will work - I try one out at the end of this comment. I'm interested if there's something I'm missing about the Brussel sprouts example.
Basic value conflict
Jim's "programmer" is Evolution. Evolution has the objective of maximizing inclusive genetic fitness. To do this you need to avoid eating poison before you make babies. For various reasons, directly providing the objective of maximizing inclusive genetic fitness to Jim as his fixed reward function does not maximize inclusive genetic fitness. Instead, Evolution gives Jim a fixed reward function consisting of two values: avoid bitter foods and keep your girlfriend happy. So we know there is outer misalignment, but that's not what the example is about.
Jim goes into the world with this fixed value system and learns some facts about it:
- Brussel sprouts are bitter.
- Sam is my girlfriend.
- Sam likes men who eat Brussel sprouts.
Jim weighs the conflict between the two values and decides whether to eat the Brussel sprouts. His values are in conflict. The question of which value wins on any particular day depends on Evolution's choices about his fixed value system, plus facts about the world. This seems like normal inner alignment, working as designed. If Evolution wanted one value to always win in such a conflict, Evolution should weight the values appropriately.
Enter the learned value function
What does the learned value function add to this basic picture? While Jim is in the world, he updates his learned value function based on his fixed reward function. In particular whenever Sam serves him Brussel sprouts, he learns a higher value for:
- Being the sort of person who eats Brussel sprouts (especially when with a girlfriend)
- Being the sort of person who has boundaries with his girlfriend (especially about food)
The question of where the reward value function stabilizes depends on Evolution's choices and facts about the world. It's a more complicated alignment story, but Jim is still aligned with Evolution. It's just a tough break for Jim and Evolution alike that the only woman who loves Jim also wants him to eat Brussel sprouts. Anyway, Jim ends up becoming the sort of person who eats Brussel sprouts with his girlfriend and wants to be that sort of person, and they make a baby or two.
So far there's nothing in this story that makes girlfriend-pleasing higher-order and bitter-avoiding first-order. They are both in the fixed reward function and they both have complicated downstream effects in his learned value function.
Farewell Sam
So one day Sam leaves Jim for a man with a more complex fixed reward system. Jim's learned value function doesn't just reset to a clean state when she leaves him (although his brain plasticity might increase for a while). So he continues to eat Brussel sprouts and to want to be the type of person who eats Brussel sprouts. A few months later he gets into a relationship with Tina, who apparently doesn't care about Brussel sprouts. They are happy and make a baby or two.
Finally some inner misalignment? Well, it looks like Jim is eating Brussel sprouts even though that is doing nothing to help please Tina. Evolution thinks he is taking a risk of being poisoned for no benefit. So in that case there is some transient misalignment until Jim's learned value function updates to reflect the new reality. But this is only transient misalignment during learning. For their first year anniversary Tina and Jim go to a bar and Jim has his first ever beer. It's bitter! So again, Jim has some transient misalignment during learning and never drinks beer again.
But the reward value function could be doing its job correctly. Since Sam wanted him to eat Brussel sprouts and Sam and Tina are both human females, it's quite plausible that Tina actually wants him to eat Brussel sprouts too. The fixed reward functions of various humans are all set by Evolution and they are strongly correlated. In fact, Evolution gave women a fixed reward function that values men who eat Brussel sprouts because that turns out to be the most efficient way to filter out men whose reward functions don't value their girlfriend happiness, or whose reward value learning system is sub-par.
Either way, I don't see meaningful inner misalignment here.
Towards a better example
What if instead of training Jim to eat Brussel sprouts, Sam had instead converted Jim to her belief system, "Effective Altruism". EAs believe in maximizing global utility, which means avoiding meat, avoiding conspicuous consumption, and eating healthy foods that boost productivity. It turns out that Brussel sprouts are the perfect EA food! Also, EA is a coherent belief system, so EAs should not self-modify to stop being EA because that would be value drift. Fortunately value drift can be avoided by hanging out with other EAs and pledging to give effectively and so forth. It's possible that Sam hasn't read all the Sequences and she doesn't have EA quite right.
In this hypothetical Jim learns multiple updates to his learned value function and learned world-model and learned planner/actor. Jim thinks differently after being with Sam; his old friends say it's like he's not even the same person. When Sam leaves Jim, Jim remains an EA. His fixed reward function would reward him for eating cookies, but he never buys them because they're not nutritionally efficient. His fixed reward function would reward him for making a girlfriend happy who wants him to kick puppies, but he doesn't date those kind of women because they are clearly evil, and dating evil women causes value drift. Jim ends up eating Brussel sprouts and not having a girlfriend and Evolution realizes that its design needs some work.
I think this definitely works as an example of self-referential misalignment. It's also an example of inner misalignment caused by parasitic (from Evolution's perspective) memes. That's going to be the most common example, I think. The misalignment is persistent and self-reinforcing, and that is much more likely to happen by memetic evolution than by random chance.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-10T15:21:48.921Z · LW(p) · GW(p)
The way I would say (I think something like) your comment is: If Jim winds up "wanting to be the kind of person who likes brussels sprouts", we can ask How did Jim wind up wanting that particular thing? The answer, one presumes, is that something in Jim's reward function is pushing for it. I.e., something in Jim's reward function painted positive valence onto the concept of "being the kind of person who likes brussels sprouts" inside Jim's world-model.
Then we can ask the follow-up question: Was that the designer's intention? If no, then it's inner misalignment. If yes, then it's not inner misalignment.
Actually, that last sentence is too simplistic. Suppose that the designer's intention is that they want Jim to dislike brussels sprouts, but also they want Jim to want to be the kind of person who likes brussels sprouts. …I'm gonna stop right here and say: What on earth is the designer thinking here?? Why would they want that?? If Jim self-modifies to permanently like brussels sprouts from now on, was that the designer's intention or not? I don't know; it seems like the designer's intentions here are weirdly incoherent, and maybe the designer ought to go back to the drawing board and stop trying to do things that are self-undermining. Granted, in the human case, there are social dynamics that lead to evolution wanting this kind of thing. But in the AGI case, I don't see any reason for it. I think we should really be trying to design our AGIs such that they want to want the things that they want, which in turn are identical to the things that we humans want them to want.
Back to the other case where it's obviously inner misalignment, because the designer both wanted Jim to dislike brussels sprouts, and wanted Jim to dislike being the kind of person who likes brussels sprouts, but nevertheless Jim somehow wound up wanting to be the kind of guy who likes brussels sprouts. Is there anything that could lead to that? I say: Yes! The existence of superstitions is evidence that people can wind up liking random things for no reason in particular. Basically, there's a "credit assignment" process that links rewards to abstract concepts, and it's a dumb noisy algorithm that will sometimes flag the wrong concept. Also, if the designer has other intentions besides brussels sprouts, there could be cross-talk between the corresponding rewards.
comment by Jon Garcia · 2021-12-09T23:33:10.226Z · LW(p) · GW(p)
This post is a really great summary. Steve's posts on the thalamo-cortical-basal ganglia loop and how it relates learning-from-scratch to value learning and action selection has added a lot to my mental model of the brain's overall cognitive algorithms. (Although I would add that I currently see the basal ganglia as a more general-purpose dynamic routing system, able to act as both multiplexer and demultiplexer between sets of cortical regions for implementing arbitrarily complex cognitive algorithms. That is, it may have evolved for action selection, but humans, at least, have repurposed it for abstract thought, moving our conscious thought processes toward acting more CPU-like. But that's another discussion.)
One commonly-proposed solution to this problem is to capture these intuitions indirectly through human-in-the-loop-style proposals like imitative amplification, safety via debate, reward modeling, etc. [LW · GW], but it might also be possible to just “cut out the middleman” and install the relevant human-like social-psychological computations directly into the AGI. In slogan form, instead of (or in addition to) putting a human in the loop, we could theoretically put "humanness" in our AGI.
In my opinion, it's got to be both. It definitely makes sense that we should be trying to get an AGI to have value priors that align as closely with true human values as we can get them. However, to ensure that the system remains robust to arbitrarily high levels of intelligence, I think it's critical to have a mechanism built in where the AGI is constantly trying to refine its model of human needs/goals and feed that in to how it steers its behavior. This would entail an ever-evolving theory of mind that uses human words, expressions, body language, etc. as Bayesian evidence of humans' internal states and an action-selection architecture that is always trying to optimize for its current best model of human need/goal satisfaction.
Understanding the algorithms of the human brainstem/hypothalamus would help immensely in providing a good model prior (e.g., knowing that smiles are evidence for satisfied preferences, that frowns are evidence for violated preferences, and that humans should have access to food, water, shelter, and human community gives the AGI a much better head start than making it figure out all of that on its own). But it should still have the sort of architecture that would allow it to figure out human preferences from scratch and try its best to satisfy them in case we misspecify something in our model.