Question 5: The timeline hyperparameter
post by Cameron Berg (cameron-berg) · 2022-02-14T16:38:17.006Z · LW · GW · 3 commentsContents
Does the timeline really matter? A breakthrough-centered approach for timeline estimation How timelines modulate (re)search strategy By analogy to chess Applied to the AGI safety None 3 comments
Does the timeline really matter?
At the outset, I added an asterisk [LW · GW] to the hierarchical framework put forward in this sequence: the final question, what is the predicted timeline for the development of AGI? is explicitly not hierarchical—i.e., unlike every other question considered thus far, the formulation of this question is not strictly dependent on how we answered the previous one. However, this should not be taken to mean that it is strictly orthogonal, either: surely, for instance, our answer to this question will have something to do with our predicted learning architecture from Question 1 [LW · GW] (e.g., a super-human-level AGI will take longer to build than a sub-human-level AGI). Nevertheless, this question is essential for successfully calibrating an end-to-end AGI safety research agenda. In a sentence, our predicted AGI development timeline will tell us how quickly we need to answer the previous four questions.
Of course, this all presupposes that the AGI safety control problem needs to be solved prior to—or, at the latest, concurrently with—the development of AGI. This, in turn, depends on the probability we assign to the prospect of an ‘uncontrolled’ AGI—i.e., an AGI for which no control proposals have been implemented—posing negligible existential risks (i.e., being ‘benign’). The higher the probability that AGI is benign-by-default, the less it would matter that we solve the control problem strictly prior to the development of the first AGIs.
Here is a one-paragraph argument that the probability of AGI being benign-by-default is low. Remember: a generally intelligent agent is one who, by definition, is capable of ‘efficiently achieving goals across a wide range of domains.’ To believe that AGI would be benign-by-default, one would have to defend the premise that, in the process of achieving any of its conceivably assigned goals, the AGI could pose no existential risk. This would require also claiming that AGI would, by default, pursue the right goals in the right way for the right reasons—if any of these conditions do not hold, we have already demonstrated how this could pose an existential risk (see Question 2 [LW · GW]). If we want to claim that ‘uncontrolled’ AGI—and 'uncontrolled' humans supervising this AGI—are very unlikely to be aligned by default (this seems highly plausible), we are compelled to conclude that the probability of the development of AGI being a benign event is low, and therefore, that the AGI safety control problem should be solved prior to the development of AGI.
Ultimately, this all means that how soon we think AGI is actually going to be developed matters substantially: it represents a deadline before which AGI safety researchers must ‘turn in their work,’ however complete it may be.
A breakthrough-centered approach for timeline estimation
As has been the case throughout this report, my goal is not to share what I think the most likely AGI timeline actually is, but rather, to determine what the right questions are to ask in order to calibrate the space of plausible timelines. To this end, I do not think that simply asking oneself “how many years away do I think we are from AGI?” is the right way to go about arriving at one’s answer. Instead, I will propose the following:
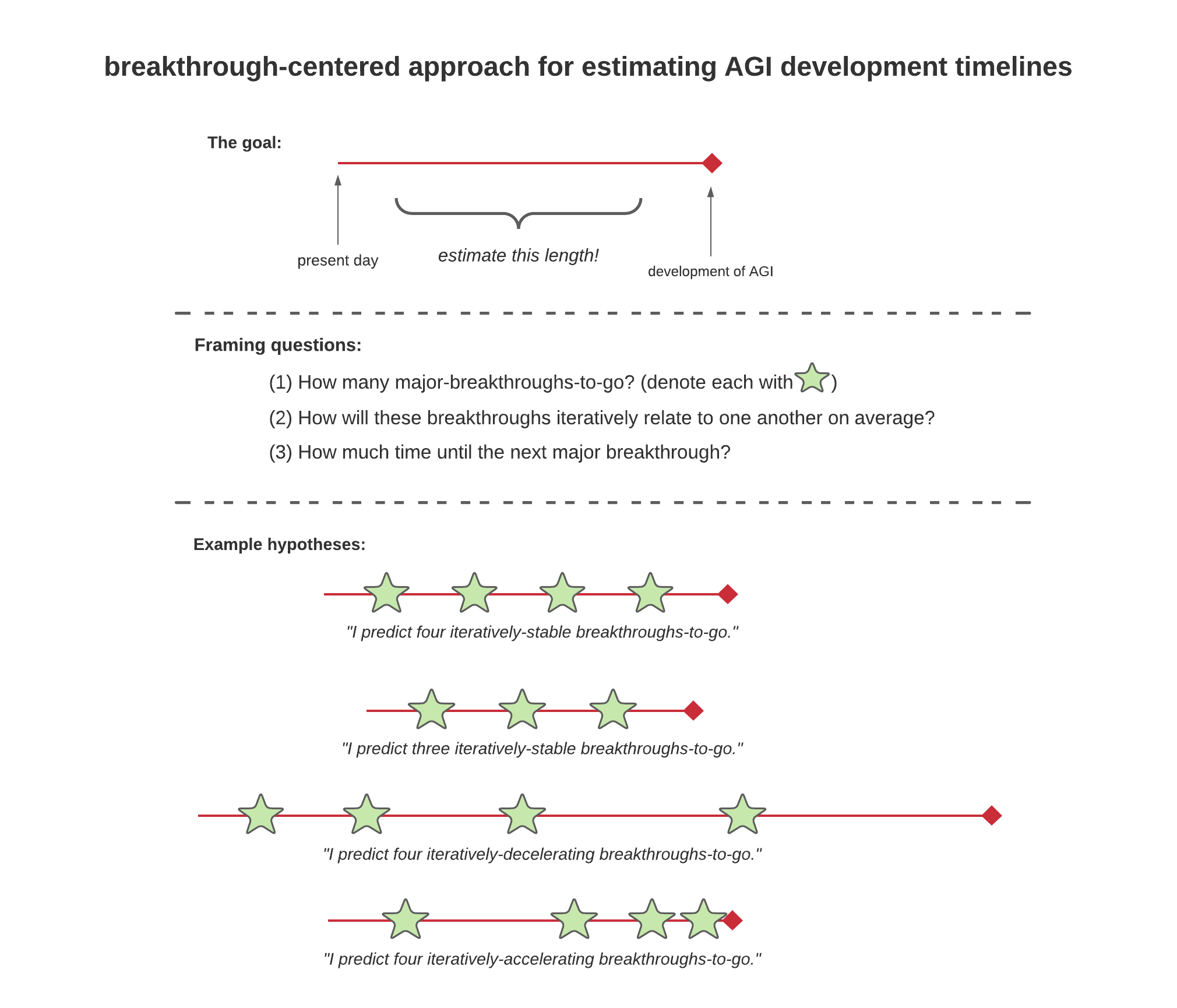
There are a few components of this approach that require further explanation. I take ‘the goal’ as it is represented above to be self-explanatory, so I will not say more about it. The framing questions are really the key part of this estimation approach. By a ‘major breakthrough’ in AGI development, I am referring to insights and discoveries that shift the fundamental paradigms of machine learning/AI. I think historical candidates for breakthroughs of this sort include deep learning, Q-learning (particularly, the Bellman equation), and perhaps most recently, transformer models. Along these lines, the first framing question asks how many additional breakthroughs of this sort we expect to be interposed between the present day and the development of AGI (i.e., not including the development of AGI itself). The second framing question asks how these breakthroughs ‘iteratively relate to one another on average,’ to which I think there are only three possible answers:
- on average, the breakthroughs will be iteratively-accelerating (i.e., on average, each breakthrough will make the next breakthrough occur more quickly)
- on average, the breakthroughs will be iteratively-decelerating (i.e., on average, each breakthrough will make the next breakthrough occur more slowly), and
- on average, the breakthroughs will be iteratively-stable (i.e., on average, each breakthrough will not affect the subsequent ‘breakthrough rate’).
Or, in more mathematical terms, I claim that the average value of the derivative of whatever function happens to describe future AI/ML breakthroughs can either be positive, negative, or zero. I do not see a fourth option.
Each of these possibilities is visually represented in the model above. An important note to add here is that humans are typically very bad at overcoming the default expectation that a system’s dynamics over time will be linear (e.g., “why are we shutting down the country when there are only 8 reported COVID cases?!”). We should keep this ‘linearity bias’ in mind when answering this second of the estimation framing questions.
Once one has formulated answers to these first two questions, the final datapoint necessary to make the whole program compile, as it were, is how much time one thinks it will take to get to the next breakthrough. Plug this value in, and the rest follows.
Here is a simple end-to-end example: Bob thinks that there are probably two more major breakthroughs necessary to get from present-day AI capabilities to AGI. He also believes these breakthroughs are likely to be iteratively-accelerating (at some rate we’ll call 𝛂)—i.e., the time between now and the first breakthrough will be greater than the time between the first breakthrough and the second breakthrough, which in turn will be greater than the time between the second breakthrough and AGI. Finally, Bob estimates that the first breakthrough is less than three years away. It necessarily follows from these inputted values that Bob’s estimated AGI development timeline has an upper bound of slightly less than nine years (3 + 3 - ε + 3 - 2ε = 9 - 3ε) and a mean at six or so years (this will depend on what 𝛂 is). This framework is intended to yield estimates, not prophecies; I think it does a pretty good job at the former and would do a pretty dismal job at the latter.
I want to return for a moment to discuss the second framing question from the model above, given that it does most of the heavy lifting in the overall estimation framework. While I certainly have my own thoughts about which of the three available positions (i.e., iterative acceleration, iterative deceleration, iterative stability) is most plausible, I do not think any of them should necessarily be dismissed out of hand. To demonstrate this, I will briefly provide three examples of very simple and familiar problem-solving scenarios that behave like each of the three possible answers.
Puzzles like sudoku and crosswords exhibit iterative acceleration on average—i.e., the time it takes to fill in each successive square in the puzzle-grid decreases as the puzzle is increasingly solved. In other words, figuring out some of the solution to these problems facilitates figuring out the rest of the solution faster. On the whole, they get easier the closer one gets to the finish line. Maybe solving the problem of AGI development will be temporally analogous to ‘solving the problem’ of a sudoku puzzle.
Games like chess, checkers, and Go can exhibit iterative deceleration on average—i.e., the time it takes to correctly make each successive move can decrease on average the farther one gets into the game. In chess, for example, openings are often easy and fairly automatic; it is in the middle- and end-game where one really has to do the hard problem-solving work. In other words, the ‘solution’ to a chess game (i.e., the total set of moves made by the winning player) often gets increasingly hard to find the closer one actually moves towards the complete solution (i.e., the farther one gets into the game). Maybe solving the problem AGI development will be temporally analogous to ‘solving the problem’ of a chess game.
‘Solving the problem’ of winning a competitive athletic event can exhibit iterative stability on average—i.e., the amount of time it takes to do whatever is required to win (e.g., score more goals, get more touchdowns, etc.) does not vary with the cumulative duration of the match. In other words, implementing the ‘solution’ to winning an athletic competition does not get easier (and thus happens faster) or harder (and thus happens slower) as the match progresses. This would not be true if, for instance, soccer goalkeepers were removed from the game in its last five minutes. Maybe solving the problem of AGI development will be temporally analogous to ‘solving the problem’ of winning an athletic event.
Because familiar real-world problems demonstrate iterative-acceleration, -deceleration, and -stability, I think these three positions prove themselves to be perfectly coherent stances to adopt with respect to the problem of AGI development timeline estimation—even if they are not all equivalently plausible.
How timelines modulate (re)search strategy
By analogy to chess
What is one actually supposed to do with their estimated timeline for the development of AGI? Again, I think the most illustrative answer to this question is by analogy to a game: in this case, chess.

Whether or not one plays with a clock, the rules and goals of chess are the same—i.e., it is the exact same problem-to-be-solved (i.e., whose solution is instantiated by the total set of moves ultimately made by the winning player). With infinite time, a sufficiently intelligent chess player could, at each turn, exhaustively search over the decision tree in order to determine the optimal move. Of course, the combinatorics of this exhaustive search strategy makes the problem computationally intractable in practice (chess has a branching factor of ≈35). As such, chess players/programs are required to limit the depth of search according to particular heuristics—i.e., the player must, using search heuristics of some sort, (A) identify a worthwhile subset of the possibility-space and (B) proceed to actually search over this (now more computationally tractable) space. Herbert Simon, an eminent psychologist of the mid-twentieth century, coined a term for this sort of thing: satisficing.
Accordingly, the quality of a player’s move (i.e., its proximity to optimality) must be some function of (1) the quality of the player’s search heuristics, (2) the player’s raw search speed, and (3) the amount of time allotted for search (e.g., blitz chess vs. a two-hour game). I think these three ingredients—search heuristic quality, raw search speed, time allotted—are equally relevant for the search undertaken by people hunting for a solution to the AGI safety control problem.
Applied to the AGI safety
If the control problem must be basically solved prior to the development of AGI, then our AGI timeline presents an upper bound on the time allotted to search for solutions to the problem (just as a clock presents an upper bound on the amount of time a chess player can spend searching for moves). All else being equal, having to solve the control problem in less time would require proportional increases in the quality of researchers’ search heuristics and/or researchers’ raw search speed.
Plenty of really smart people—people who can search complex ‘search-spaces’ quickly—are already working on the control problem, meaning that, barring help from qualitatively better searchers (e.g., AI helping with AGI safety), raw search speed in solving the control problem will probably not dramatically increase in the coming years. One obvious proposal for boosting this term would be to continue increasing the number of smart people contributing to AGI safety research, though there the likelihood of diminishing returns that must be noted here (e.g., millions of AGI safety researchers would be exceedingly hard to coordinate and might be net-less-productive than a well-coordinated network of thousands of researchers).
Increasing the quality of researchers’ search heuristics, however, seems far more plausible in the short term. Indeed, doing this has essentially been the goal of this sequence! Not only do we need sharp people working on the AGI safety control problem—we need sharp people who are searching for good answers to the right questions.
Accordingly, my goal in this sequence has been to contribute to the fairly-neglected meta-question of what the right questions in AGI safety even are. The shorter our anticipated AGI development timeline, the better our search heuristics need to be—i.e., the more careful we need to be that we are not only answering questions correctly but also that we are asking questions whose answers are most relevant for actually solving the problem. We are on the clock, and my sense is that we do not have any time to waste.
3 comments
Comments sorted by top scores.
comment by TLW · 2022-02-15T04:38:27.456Z · LW(p) · GW(p)
I do not see a fourth option.
Consider 'Zeno's breakthrough':
At t=1, a discrete discovery occurs that advances us 1 unit of knowledge towards AI.
At t=3/2, (i.e. 1 + 1/2) a discrete discovery occurs that advances us 1/2 unit of knowledge towards AI.
At t=11/6, (i.e. 1 + 1/2 + 1/3) a discrete discovery occurs that advances us 1/4 unit of knowledge towards AI.
At t=25/12, (i.e. 1 + 1/2 + 1/3 + 1/4) a discrete discovery occurs that advances us 1/8th unit of knowledge towards AI.
Etc.
One the one hand, this looks very much like an accelerating timeline if you are solely looking at breakthroughs. On the other hand, the actual rate of knowledge acquiry over time is decreasing.
I would argue that this sort of trend is fairly common in research. Research discoveries in a particular field do continue over time, and the rate of discoveries increases over time, but the purport of each discovery tends to lessen over time.
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2022-02-15T16:09:59.310Z · LW(p) · GW(p)
Very interesting counterexample! I would suspect it gets increasingly sketchy to characterize 1/8th, 1/16th, etc. 'units of knowledge towards AI' as 'breakthroughs' in the way I define the term in the post.
I take your point that we might get our wires crossed when a given field looks like it's accelerating, but when we zoom in to only look at that field's breakthroughs, we find that they are decelerating. It seems important to watch out for this. Thanks for your comment!
Replies from: TLW↑ comment by TLW · 2022-02-19T01:39:48.335Z · LW(p) · GW(p)
I would suspect it gets increasingly sketchy to characterize 1/8th, 1/16th, etc. 'units of knowledge towards AI' as 'breakthroughs' in the way I define the term in the post.
Absolutely. It does - eventually. Which is partially my point. The extrapolation looks sound, until suddenly it isn't.
I take your point that we might get our wires crossed when a given field looks like it's accelerating, but when we zoom in to only look at that field's breakthroughs, we find that they are decelerating. It seems important to watch out for this.
I think you may be slightly missing my point.
Once you hit the point that you no longer consider any recent advances breakthroughs, yes, it becomes obvious that you're decelerating.
But until that point, breakthroughs appear to be accelerating.
And if you're discretizing into breakthrough / non-breakthrough, you're ignoring all the warning signs that the trend might not continue.
(To return to my previous example: say we currently consider any one step that's >=1/16th of a unit of knowledge as a breakthrough, and we're at t=2.4... we had breakthroughs at t=1, 3/2, 11/6, 25/12, 137/60. The rate of breakthroughs are accelerating! And then we hit t=49/20, and no breakthrough. And it either looks like we plateaued, or someone goes 'no, 1/32nd of advancement should be considered a breakthrough' and makes another chart of accelerating breakthroughs.)
(Yes, in this example every discovery is half as much knowledge as the last one, which makes it somewhat obvious that things have changed. Power of 0.5 was just chosen because it makes the math simpler. However, all the same issues occur with an power of e.g. 0.99 not 0.5. Just more gradually. Which makes the 'no, the last advance should be considered a breakthrough too' argument a whole lot easier to inadvertently accept...)