Hopenope's Shortform
post by Hopenope (baha-z) · 2024-12-22T10:52:39.610Z · LW · GW · 11 commentsContents
11 comments
11 comments
Comments sorted by top scores.
comment by Hopenope (baha-z) · 2024-12-22T10:52:39.708Z · LW(p) · GW(p)
Many expert level benchmarks totally overestimate the range and diversity of their experts' knowledge. A person with a PhD in physics is probably undergraduate level in many parts of physics that are not related to his/her research area, and sometimes we even see that within expert's domain (Neurologists usually forget about nerves that are not clinically relevant).
Replies from: Buck, GAA↑ comment by Buck · 2024-12-23T20:30:12.954Z · LW(p) · GW(p)
Relatedly, undergrads are often way below undergrad level in courses that they haven't taken lately. Like, if you take someone who just graduated with a physics major and get them to retake finals from sophomore physics without prep, I bet they'll often get wrecked.
As a professional computer scientist, I often feel like my knowledge advantage over recent grads is that I know the content of intro CS classes better than they do.
↑ comment by Guive (GAA) · 2024-12-23T21:29:29.350Z · LW(p) · GW(p)
Katja Grace ten years ago [LW · GW]:
"Another thing to be aware of is the diversity of mental skills. If by 'human-level' we mean a machine that is at least as good as a human at each of these skills, then in practice the first 'human-level' machine will be much better than a human on many of those skills. It may not seem 'human-level' so much as 'very super-human'.
We could instead think of human-level as closer to 'competitive with a human' - where the machine has some super-human talents and lacks some skills humans have. This is not usually used, I think because it is hard to define in a meaningful way. There are already machines for which a company is willing to pay more than a human: in this sense a microscope might be 'super-human'. There is no reason for a machine which is equal in value to a human to have the traits we are interested in talking about here, such as agency, superior cognitive abilities or the tendency to drive humans out of work and shape the future. Thus we talk about AI which is at least as good as a human, but you should beware that the predictions made about such an entity may apply before the entity is technically 'human-level'.
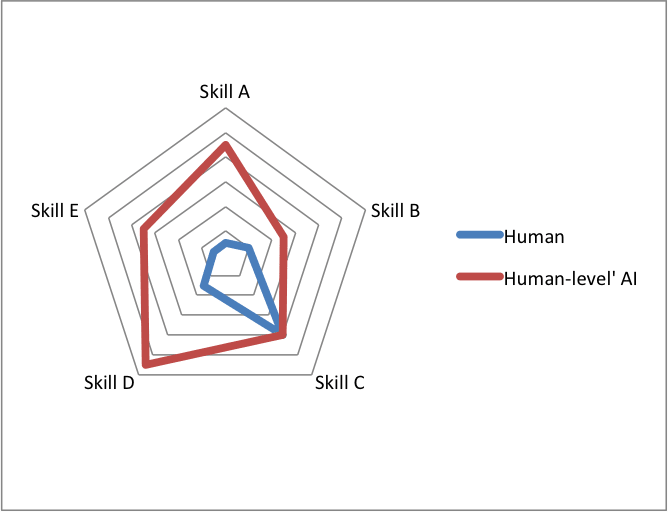
"
comment by Hopenope (baha-z) · 2025-01-07T17:31:33.776Z · LW(p) · GW(p)
What happened to Waluigi effect [LW · GW]? It used to be a big issue, some people were against it, and suddenly it is pretty much forgotten. Are there any related research, or recent demos, that examine it in more detail?
comment by Hopenope (baha-z) · 2025-01-22T10:34:27.828Z · LW(p) · GW(p)
Is COT faithfulness already obsolete? How does it survive the concepts like latent space reasoning, or RL based manipulations(R1-zero)? Is it realistic to think that these highly competitive companies simply will not use them, and simply ignore the compute efficiency?
Replies from: nathan-helm-burger, bogdan-ionut-cirstea↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-22T12:29:53.627Z · LW(p) · GW(p)
I think CoT faithfulness was a goal, a hope, that had yet to be realized. People were assuming it was there in many cases when it wasn't.
You can see the cracks showing in many places. For example, editing the CoT to be incorrect and noting that the model still puts the same correct answer. Or observing situations where the CoT was incorrect to begin with, and yet the answer was correct.
Those "private scratchpads"? Really? How sure are you that the model was "fooled" by them? What evidence do you have that this is the case? I think the default assumption has to be that the model sees a narrative story element which predicts a certain type of text, and thus puts the type of text there that it expects belongs there. That doesn't mean you now have true insight into the computational generative process of the model!
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2025-01-24T23:49:33.466Z · LW(p) · GW(p)
To the best of my awareness, there isn't any demonstrated proper differential compute efficiency from latent reasoning to speak of yet. It could happen, it could also not happen. Even if it does happen, one could still decide to pay the associated safety tax of keeping the CoT.
More generally, the vibe of the comment above seems too defeatist to me; related: https://www.lesswrong.com/posts/HQyWGE2BummDCc2Cx/the-case-for-cot-unfaithfulness-is-overstated [LW · GW].
comment by Hopenope (baha-z) · 2025-01-09T19:29:50.065Z · LW(p) · GW(p)
I am not sure if longer timelines are always safer. For example, when comparing a two-year timeline to a five-year one, there are a lot of advantages to the shorter timeline. In both cases you need to outsource a lot of alignment research to AI anyway, and the amount of compute and the number of players with significant compute are lower, which reduces both the racing pressure and takeoff speed.
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-01-09T19:31:36.277Z · LW(p) · GW(p)
We have no idea how to use AI systems to "solve alignment" yet, and of course shorter timelines give you much less time in the loop to figure it out.
comment by Hopenope (baha-z) · 2024-12-28T20:20:24.366Z · LW(p) · GW(p)
If you have a very short timeline, and you don't think that alignment is solvable in such a short time, then what can you still do to reduce the chance of x-risk?
Replies from: dtch1997↑ comment by Daniel Tan (dtch1997) · 2024-12-28T21:44:25.639Z · LW(p) · GW(p)
Some rough ideas
- Work on evals / model organisms / scary demos
- Work on AI control
- Work on technical governance
- Work on policy