MIRI's Approach
post by So8res · 2015-07-30T20:03:51.054Z · LW · GW · Legacy · 59 commentsContents
1. Creating a powerful AI system without understanding why it works is dangerous. 2. We could not yet create a beneficial AI system even via brute force. 3. Figuring out how to solve a problem in principle yields many benefits. 4. This is an approach researchers have used successfully in the past. None 59 comments
MIRI's summer fundraiser is ongoing. In the meantime, we're writing a number of blog posts to explain what we're doing and why, and to answer a number of common questions. This post is one I've been wanting to write for a long time; I hope you all enjoy it. For earlier posts in the series, see the bottom of the above link.
MIRI’s mission is “to ensure that the creation of smarter-than-human artificial intelligence has a positive impact.” How can we ensure any such thing? It’s a daunting task, especially given that we don’t have any smarter-than-human machines to work with at the moment. In a previous post to the MIRI Blog I discussed four background claims that motivate our mission; in this post I will describe our approach to addressing the challenge.
This challenge is sizeable, and we can only tackle a portion of the problem. For this reason, we specialize. Our two biggest specializing assumptions are as follows:
1. We focus on scenarios where smarter-than-human machine intelligence is first created in de novo software systems (as opposed to, say, brain emulations). This is in part because it seems difficult to get all the way to brain emulation before someone reverse-engineers the algorithms used by the brain and uses them in a software system, and in part because we expect that any highly reliable AI system will need to have at least some components built from the ground up for safety and transparency. Nevertheless, it is quite plausible that early superintelligent systems will not be human-designed software, and I strongly endorse research programs that focus on reducing risks along the other pathways.
2. We specialize almost entirely in technical research. We select our researchers for their proficiency in mathematics and computer science, rather than forecasting expertise or political acumen. I stress that this is only one part of the puzzle: figuring out how to build the right system is useless if the right system does not in fact get built, and ensuring AI has a positive impact is not simply a technical problem. It is also a global coordination problem, in the face of short-term incentives to cut corners. Addressing these non-technical challenges is an important task that we do not focus on.
In short, MIRI does technical research to ensure that de novo AI software systems will have a positive impact. We do not further discriminate between different types of AI software systems, nor do we make strong claims about exactly how quickly we expect AI systems to attain superintelligence. Rather, our current approach is to select open problems using the following question:
What would we still be unable to solve, even if the challenge were far simpler?
For example, we might study AI alignment problems that we could not solve even if we had lots of computing power and very simple goals.
We then filter on problems that are (1) tractable, in the sense that we can do productive mathematical research on them today; (2) uncrowded, in the sense that the problems are not likely to be addressed during normal capabilities research; and (3) critical, in the sense that they could not be safely delegated to a machine unless we had first solved them ourselves.1
These three filters are usually uncontroversial. The controversial claim here is that the above question — “what would we be unable to solve, even if the challenge were simpler?” — is a generator of open technical problems for which solutions will help us design safer and more reliable AI software in the future, regardless of their architecture. The rest of this post is dedicated to justifying this claim, and describing the reasoning behind it.
1. Creating a powerful AI system without understanding why it works is dangerous.
A large portion of the risk from machine superintelligence comes from the possibility of people building systems that they do not fully understand. Currently, this is commonplace in practice: many modern AI researchers are pushing the capabilities of deep neural networks in the absence of theoretical foundations that describe why they’re working so well or a solid idea of what goes on beneath the hood. These shortcomings are being addressed over time: many AI researchers are currently working on transparency tools for neural networks, and many more are working to put theoretical foundations beneath deep learning systems. In the interim, using trial and error to push the capabilities of modern AI systems has led to many useful applications.
When designing a superintelligent agent, by contrast, we will want an unusually high level of confidence in its safety before we begin online testing: trial and error alone won’t cut it, in that domain.
To illustrate, consider a study by Bird and Layzell in 2002. They used some simple genetic programming to design an oscillating circuit on a circuit board. One solution that the genetic algorithm found entirely avoided using the built-in capacitors (an essential piece of hardware in human-designed oscillators). Instead, it repurposed the circuit tracks on the motherboard as a radio receiver, and amplified an oscillating signal from a nearby computer.
This demonstrates that powerful search processes can often reach their goals via unanticipated paths. If Bird and Layzell were hoping to use their genetic algorithm to find code for a robust oscillating circuit — one that could be used on many different circuit boards regardless of whether there were other computers present — then they would have been sorely disappointed. Yet if they had tested their algorithms extensively on a virtual circuit board that captured all the features of the circuit board that they thought were relevant (but not features such as “circuit tracks can carry radio signals”), then they would not have noticed the potential for failure during testing. If this is a problem when handling simple genetic search algorithms, then it will be a much larger problem when handling smarter-than-human search processes.
When it comes to designing smarter-than-human machine intelligence, extensive testing is essential, but not sufficient: in order to be confident that the system will not find unanticipated bad solutions when running in the real world, it is important to have a solid understanding of how the search process works and why it is expected to generate only satisfactory solutions in addition to empirical test data.
MIRI’s research program is aimed at ensuring that we have the tools needed to inspect and analyze smarter-than-human search processes before we deploy them.
By analogy, neural net researchers could probably have gotten quite far without having any formal understanding of probability theory. Without probability theory, however, they would lack the tools needed to understand modern AI algorithms: they wouldn’t know about Bayes nets, they wouldn’t know how to formulate assumptions like “independent and identically distributed,” and they wouldn’t quite know the conditions under which Markov Decision Processes work and fail. They wouldn’t be able to talk about priors, or check for places where the priors are zero (and therefore identify things that their systems cannot learn). They wouldn’t be able to talk about bounds on errors and prove nice theorems about algorithms that find an optimal policy eventually.
They probably could have still gotten pretty far (and developed half-formed ad-hoc replacements for many of these ideas), but without probability theory, I expect they would have a harder time designing highly reliable AI algorithms. Researchers at MIRI tend to believe that similarly large chunks of AI theory are still missing, and those are the tools that our research program aims to develop.
2. We could not yet create a beneficial AI system even via brute force.
Imagine you have a Jupiter-sized computer and a very simple goal: Make the universe contain as much diamond as possible. The computer has access to the internet and a number of robotic factories and laboratories, and by “diamond” we mean carbon atoms covalently bound to four other carbon atoms. (Pretend we don’t care how it makes the diamond, or what it has to take apart in order to get the carbon; the goal is to study a simplified problem.) Let’s say that the Jupiter-sized computer is running python. How would you program it to produce lots and lots of diamond?
As it stands, we do not yet know how to program a computer to achieve a goal like that.
We couldn’t yet create an artificial general intelligence by brute force, and this indicates that there are parts of the problem we don’t yet understand.
There are a number of AI tasks that we could brute-force. For example, we could write a program that would be really, really good at solving computer vision problems: if we had an indestructible box that outputted a picture of a scene and a series of questions about it, waited for answers, scored the answers for accuracy, and then repeated the process, then we know how to write the program that interacts with that box and gets very good at answering the questions. (The program would essentially be a bounded version of AIXI.)
By a similar method, if we had an indestructible box that outputted a conversation and questions about the conversation, waited for natural-language answers to the questions, and scored them for accuracy, then again, we could write a program that would get very good at answering well. In this sense, we know how to solve computer vision and natural language processing by brute force. (Of course, natural-language processing is nowhere near “solved” in a practical sense — there is still loads of work to be done. A brute force solution doesn’t get you very far in the real world. The point is that, for many AI alignment problems, we haven’t even made it to the “we could brute force it” level yet.)
Why do we need the indestructible box in the above examples? Because the way the modern brute-force solution would work is by considering each Turing machine (up to some complexity limit) as a hypothesis about the box, seeing which ones are consistent with observation, and then executing actions that lead to high scores coming out of the box (as predicted by the remaining hypotheses, weighted by simplicity).
Each hypothesis is an opaque Turing machine, and the algorithm never peeks inside: it just asks each hypothesis to predict what score the box will output, without concern for what mechanism is being used to generate that score. This means that if the algorithm finds (via exhaustive search) a plan that maximizes the score coming out of the box, and the box is destructible, then the opaque action chain that maximizes score is very likely to be the one that pops the box open and alters it so that it always outputs the highest score. But given an indestructible box, we know how to brute force the answers.
In fact, roughly speaking, we understand how to solve any reinforcement learning problem via brute force. This is a far cry from knowing how to practically solve reinforcement learning problems! But it does illustrate a difference in kind between two types of problems. We can (imperfectly and heuristically) divide them up as follows:
There are two types of open problem in AI. One is figuring out a practical way to solve a problem that we know how to solve in principle. The other is figuring out how to solve problems that we don’t even know how to brute force yet.
MIRI focuses on problems of the second class.2
What is hard about brute-forcing a diamond-producing agent? To illustrate, I’ll give a wildly simplified sketch of what an AI program needs to do in order to act productively within a complex environment:
- Model the world: Take percepts, and use them to refine some internal representation of the world the system is embedded in.
- Predict the world: Take that world-model, and predict what would happen if the system executed various different plans.
- Rank outcomes: Rate those possibilities by how good the predicted future is, then execute a plan that leads to a highly-rated outcome.3
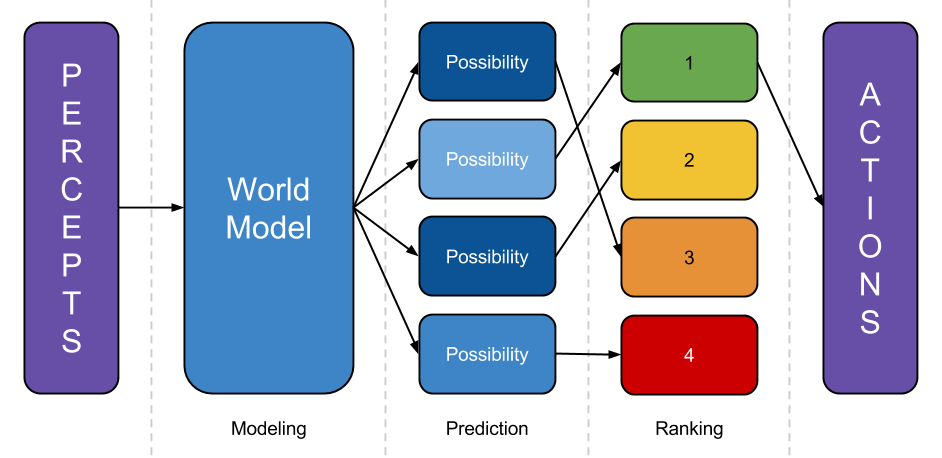
Consider the modeling step. As discussed above, we know how to write an algorithm that finds good world-models by brute force: it looks at lots and lots of Turing machines, weighted by simplicity, treats them like they are responsible for its observations, and throws out the ones that are inconsistent with observation thus far. But (aside from being wildly impractical) this yields only opaque hypotheses: the system can ask what “sensory bits” each Turing machine outputs, but it cannot peek inside and examine objects represented within.
If there is some well-defined “score” that gets spit out by the opaque Turing machine (as in a reinforcement learning problem), then it doesn’t matter that each hypothesis is a black box; the brute-force algorithm can simply run the black box on lots of inputs and see which results in the highest score. But if the problem is to build lots of diamond in the real world, then the agent must work as follows:
- Build a model of the world — one that represents carbon atoms and covalent bonds, among other things.
- Predict how the world would change contingent on different actions the system could execute.
- Look inside each prediction and see which predicted future has the most diamond. Execute the action that leads to more diamond.
In other words, an AI that is built to reliably affect things in the world needs to have world-models that are amenable to inspection. The system needs to be able to pop the world model, identify the representations of carbon atoms and covalent bonds, and estimate how much diamond is in the real world.4
We don’t yet have a clear picture of how to build “inspectable” world-models — not even by brute force. Imagine trying to write the part of the diamond-making program that builds a world-model: this function needs to take percepts as input and build a data structure that represents the universe, in a way that allows the system to inspect universe-descriptions and estimate the amount of diamond in a possible future. Where in the data structure are the carbon atoms? How does the data structure allow the concept of a “covalent bond” to be formed and labeled, in such a way that it remains accurate even as the world-model stops representing diamond as made of atoms and starts representing them as made of protons, neutrons, and electrons instead?
We need a world-modeling algorithm that builds multi-level representations of the world and allows the system to pursue the same goals (make diamond) even as its model changes drastically (because it discovers quantum mechanics). This is in stark contrast to the existing brute-force solutions that use opaque Turing machines as hypotheses.5
When humans reason about the universe, we seem to do some sort of reasoning outwards from the middle: we start by modeling things like people and rocks, and eventually realize that these are made of atoms, which are made of protons and neutrons and electrons, which are perturbations in quantum fields. At no point are we certain that the lowest level in our model is the lowest level in reality; as we continue thinking about the world we construct new hypotheses to explain oddities in our models. What sort of data structure are we using, there? How do we add levels to a world model given new insights? This is the sort of reasoning algorithm that we do not yet understand how to formalize.6
That’s step one in brute-forcing an AI that reliably pursues a simple goal. We also don’t know how to brute-force steps two or three yet. By simplifying the problem — talking about diamonds, for example, rather than more realistic goals that raise a host of other difficulties — we’re able to factor out the parts of the problems that we don’t understand how to solve yet, even in principle. Our technical agenda describes a number of open problems identified using this method.
3. Figuring out how to solve a problem in principle yields many benefits.
In 1836, Edgar Allen Poe wrote a wonderful essay on Maelzel’s Mechanical Turk, a machine that was purported to be able to play chess. In the essay, Poe argues that the Mechanical Turk must be a hoax: he begins by arguing that machines cannot play chess, and proceeds to explain (using his knowledge of stagecraft) how a person could be hidden within the machine. Poe’s essay is remarkably sophisticated, and a fun read: he makes reference to the “calculating machine of Mr. Babbage” and argues that it cannot possibly be made to play chess, because in a calculating machine, each steps follows from the previous step by necessity, whereas “no one move in chess necessarily follows upon any one other”.
The Mechnical Turk indeed turned out to be a hoax. In 1950, however, Claude Shannon published a rather compelling counterargument to Poe’s reasoning in the form of a paper explaining how to program a computer to play perfect chess.
Shannon’s algorithm was by no means the end of the conversation. It took forty-six years to go from that paper to Deep Blue, a practical chess program which beat the human world champion. Nevertheless, if you were equipped with Poe’s state of knowledge and not yet sure whether it was possible for a computer to play chess — because you did not yet understand algorithms for constructing game trees and doing backtracking search — then you would probably not be ready to start writing practical chess programs.
Similarly, if you lacked the tools of probability theory — an understanding of Bayesian inference and the limitations that stem from bad priors — then you probably wouldn’t be ready to program an AI system that needed to manage uncertainty in high-stakes situations.
If you are trying to write a program and you can’t yet say how you would write it given a computer the size of Jupiter, then you probably aren’t yet ready to design a practical approximation of the brute-force solution yet. Practical chess programs can’t generate a full search tree, and so rely heavily on heuristics and approximations; but if you can’t brute-force the answer yet given arbitrary amounts of computing power, then it’s likely that you’re missing some important conceptual tools.
Marcus Hutter (inventor of AIXI) and Shane Legg (inventor of the Universal Measure of Intelligence) seem to endorse this approach. Their work can be interpreted as a description of how to find a brute-force solution to any reinforcement learning problem, and indeed, the above description of how to do this is due to Legg and Hutter.
In fact, the founders of Google DeepMind reference the completion of Shane’s thesis as one of four key indicators that the time was ripe to begin working on AGI: a theoretical framework describing how to solve reinforcement learning problems in principle demonstrated that modern understanding of the problem had matured to the point where it was time for the practical work to begin.
Before we gain a formal understanding of the problem, we can’t be quite sure what the problem is. We may fail to notice holes in our reasoning; we may fail to bring the appropriate tools to bear; we may not be able to tell when we’re making progress. After we gain a formal understanding of the problem in principle, we’ll be in a better position to make practical progress.
The point of developing a formal understanding of a problem is not to run the resulting algorithms. Deep Blue did not work by computing a full game tree, and DeepMind is not trying to implement AIXI. Rather, the point is to identify and develop the basic concepts and methods that are useful for solving the problem (such as game trees and backtracking search algorithms, in the case of chess).
The development of probability theory has been quite useful to the field of AI — not because anyone goes out and attempts to build a perfect Bayesian reasoner, but because probability theory is the unifying theory for reasoning under uncertainty. This makes the tools of probability theory useful for AI designs that vary in any number of implementation details: any time you build an algorithm that attempts to manage uncertainty, a solid understanding of probabilistic inference is helpful when reasoning about the domain in which the system will succeed and the conditions under which it could fail.
This is why we think we can identify open problems that we can work on today, and which will reliably be useful no matter how the generally intelligent machines of the future are designed (or how long it takes to get there). By seeking out problems that we couldn’t solve even if the problem were much easier, we hope to identify places where core AGI algorithms are missing. By developing a formal understanding of how to address those problems in principle, we aim to ensure that when it comes time to address those problems in practice, programmers have the knowledge they need to develop solutions that they deeply understand, and the tools they need to ensure that the systems they build are highly reliable.
4. This is an approach researchers have used successfully in the past.
Our main open-problem generator — “what would we be unable to solve even if the problem were easier?” — is actually a fairly common one used across mathematics and computer science. It’s more easy to recognize if we rephrase it slightly: “can we reduce the problem of building a beneficial AI to some other, simpler problem?”
For example, instead of asking whether you can program a Jupiter-sized computer to produce diamonds, you could rephrase this as a question about whether we can reduce the diamond maximization problem to known reasoning and planning procedures. (The current answer is “not yet.”)
This is a fairly standard practice in computer science, where reducing one problem to another is a key feature of computability theory. In mathematics it is common to achieve a proof by reducing one problem to another (see, for instance, the famous case of Fermat’s last theorem). This helps one focus on the parts of the problem that aren’t solved, and identify topics where foundational understanding is lacking.
As it happens, humans have a pretty good track record when it comes to working on problems such as these. Humanity has a poor track record at predicting long-term technological trends, but we have a reasonably good track record at developing theoretical foundations for technical problems decades in advance, when we put sufficient effort into it. Alan Turing and Alonzo Church succeeded in developing a robust theory of computation that proved quite useful once computers were developed, in large part by figuring out how to solve (in principle) problems which they did not yet know how to solve with machines. Andrey Kolmogorov, similarly, set out to formalize intuitive but not-yet-well-understood methods for managing uncertainty; and he succeeded. And Claude Shannon and his contemporaries succeeded at this endeavor in the case of chess.
The development of probability theory is a particularly good analogy to our case: it is a field where, for hundreds of years, philosophers and mathematicians who attempted to formalize their intuitive notions of uncertainty repeatedly reasoned themselves into paradoxes and contradictions. The probability theory at the time, sorely lacking formal foundations, was dubbed a “theory of misfortune.” Nevertheless, a concerted effort by Kolmogorov and others to formalize the theory was successful, and his efforts inspired the development of a host of useful tools for designing systems that reason reliably under uncertainty.
Many people who set out to put foundations under a new field of study (that was intuitively understood on some level but not yet formalized) have succeeded, and their successes have been practically significant. We aim to do something similar for a number of open problems pertaining to the design of highly reliable reasoners.
The questions MIRI focuses on, such as “how would one ideally handle logical uncertainty?” or “how would one ideally build multi-level world models of a complex environment?”, exist at a level of generality comparable to Kolmogorov’s “how would one ideally handle empirical uncertainty?” or Hutter’s “how would one ideally maximize reward in an arbitrarily complex environment?” The historical track record suggests that these are the kinds of problems that it is possible to both (a) see coming in advance, and (b) work on without access to a concrete practical implementation of a general intelligence.
By identifying parts of the problem that we would still be unable to solve even if the problem was easier, we hope to hone in on parts of the problem where core algorithms and insights are missing: algorithms and insights that will be useful no matter what architecture early intelligent machines take on, and no matter how long it takes to create smarter-than-human machine intelligence.
At present, there are only three people on our research team, and this limits the number of problems that we can tackle ourselves. But our approach is one that we can scale up dramatically: our approach has generated a very large number of open problems, and we have no shortage of questions to study.7
This is an approach that has often worked well in the past for humans trying to understand how to approach a new field of study, and I am confident that this approach is pointing us towards some of the core hurdles in this young field of AI alignment.
This post is cross-posted from the MIRI blog. It's part of a series we're writing on MIRI's strategy and plans for the future, as part of our ongoing 2015 Summer Fundraiser.
1 Since the goal is to design intelligent machines, there are many technical problems that we can expect to eventually delegate to those machines. But it is difficult to trust an unreliable reasoner with the task of designing reliable reasoning! ↩
2 Most of the AI field focuses on problems of the first class. Deep learning, for example, is a very powerful and exciting tool for solving problems that we know how to brute-force, but which were, up until a few years ago, wildly intractable. Class 1 problems tend to be important problems for building more capable AI systems, but lower-priority for ensuring that highly capable systems are aligned with our interests. ↩
3 In reality, of course, there aren’t clean separations between these steps. The “prediction” step must be more of a ranking-dependent planning step, to avoid wasting computation predicting outcomes that will obviously be poorly-ranked. The modeling step depends on the prediction step, because which parts of the world-model are refined depends on what the world-model is going to be used for. A realistic agent would need to make use of meta-planning to figure out how to allocate resources between these activities, etc. This diagram is a fine first approximation, though: if a system doesn’t do something like modeling the world, predicting outcomes, and ranking them somewhere along the way, then it will have a hard time steering the future. ↩
4 In reinforcement learning problems, this issue is avoided via a special “reward channel” intended to stand in indirectly for something the supervisor wants. (For example, the supervisor may push a reward button every time the learner takes an action that seems, to the supervisor, to be useful for making diamonds.) Then the programmers can, by hand, single out the reward channel inside the world-model and program the system to execute actions that it predicts lead to high reward. This is much easier than designing world-models in such a way that the system can reliably identify representations of carbon atoms and covalent bonds within it (especially if the world is modeled in terms of Newtonian mechanics one day and quantum mechanics the next), but doesn’t provide a framework for agents that must autonomously learn how to achieve some goal. Correct behavior in highly intelligent systems will not always be reducible to maximizing a reward signal controlled by a significantly less intelligent system (e.g., a human supervisor). ↩
5 The idea of a search algorithm that optimizes according to modeled facts about the world rather than just expected percepts may sound basic, but we haven’t found any deep insights (or clever hacks) that allow us to formalize this idea (e.g., as a brute-force algorithm). If we could formalize it, we would likely get a better understanding of the kind of abstract modeling of objects and facts that is required for self-referential, logically uncertain, programmer-inspectable reasoning. ↩
6 We also suspect that a brute-force algorithm for building multi-level world models would be much more amenable to being “scaled down” than Solomonoff induction, and would therefore lend some insight into how to build multi-level world models in a practical setting. ↩
7 For example, instead of asking what problems remain when given lots of computing power, you could instead ask whether we can reduce the problem of building an aligned AI to the problem of making reliable predictions about human behavior: an approach advocated by others. ↩
59 comments
Comments sorted by top scores.
comment by jacob_cannell · 2015-07-30T05:51:38.764Z · LW(p) · GW(p)
Even though I come from a somewhat different viewpoint, I was fairly impressed with the case you are presenting. Nonetheless . ..
- Creating a powerful AI system without understanding why it works is dangerous.
A large portion of the risk from machine superintelligence comes from the possibility of people building systems that they do not fully understand. Currently, this is commonplace in practice: many modern AI researchers are pushing the capabilities of deep neural networks in the absence of theoretical foundations that describe why they’re working so well or a solid idea of what goes on beneath the hood.
This is not quite fully accurate. Yes anybody can download a powerful optimizer and use it to train a network that they don't understand. But those are not the people you need to worry about, that is not where the danger lies.
The concern that ML has no solid theoretical foundations reflects the old computer science worldview, which is all based on finding bit exact solutions to problems within vague asymptotic resource constraints.
Old computer science gave us things like convex optimization, which is nothing interesting at all (it only works well for simple uninteresting problems). Modern AI/ML is much more like computer graphics or simulation, where everything is always an approximation and traditional computer science techniques are mostly useless. There is no 'right answer', there are just an endless sea of approximations that have varying utility/cost tradeoffs.
A good ML researcher absolutely needs a good idea of what is going on under the hood - at least at a sufficient level of abstraction. The optimization engine does most of the nitty gritty work - but it is equivalent to the researcher employing an army of engineers and dividing the responsibility up so that each engineer works on a tiny portion of the circuit. To manage the optimizer, the researcher needs a good high level understanding of the process, although not necessarily the details.
Also - we do have some theoretical foundations for DL - bayesian inference for one. Using gradient descent on the joint log PDF is a powerful approximate inference strategy.
When designing a superintelligent agent, by contrast, we will want an unusually high level of confidence in its safety before we begin online testing: trial and error alone won’t cut it, in that domain.
It appears you are making the problem unnecessarily difficult.
Why not test safety long before the system is superintelligent? - say when it is a population of 100 child like AGIs. As the population grows larger and more intelligent, the safest designs are propagated and made safer.
- This is an approach researchers have used successfully in the past.
Our main open-problem generator — “what would we be unable to solve even if the problem were easier?” — is actually a fairly common one used across mathematics and computer science. It’s more easy to recognize if we rephrase it slightly: “can we reduce the problem of building a beneficial AI to some other, simpler problem?”
This again reflects the old 'hard' computer science worldview, and obsession with exact solutions.
If it seems really really really impossibly hard to solve a problem even with the 'simplification' of lots of computing power, perhaps the underlying assumptions are wrong. For example - perhaps using lots and lots of computing power makes the problem harder instead of easier.
How could that be? Because with lots and lots of compute power, you are naturally trying to extrapolate the world model far far into the future, where it branches enormously and grows in complexity exponentially. Then when you try to define a reasonable utility/value function over the future world model, it becomes almost impossible because the future world model has exploded exponentially in complexity.
So it may actually be easier to drop the traditional computer science approach completely. Start with a smaller more limited model that doesnt explode, and then approximately extrapolate both the world model and the utility/value function together.
This must be possible in principle, because human children learn that way. Realistically there isn't room in the DNA for a full adult utility/value function, and it wouldn't work in an infant brain anyway without the world model. But evolution solved this problem approximately, and we can learn from it and make do.
Replies from: So8res, None, Squark, Manfred↑ comment by So8res · 2015-07-30T17:08:23.045Z · LW(p) · GW(p)
Thanks for the reply, Jacob! You make some good points.
Why not test safety long before the system is superintelligent? - say when it is a population of 100 child like AGIs. As the population grows larger and more intelligent, the safest designs are propagated and made safer.
I endorse eli_sennesh's response to this part :-)
This again reflects the old 'hard' computer science worldview, and obsession with exact solutions.
I am not under the impression that there are "exact solutions" available, here. For example, in the case of "building world-models," you can't even get "exact" solutions using AIXI (which does Bayesian inference using a simplicity prior in order to guess what the environment looks like; and can never figure it out exactly). And this is in the simplified setting where AIXI is large enough to contain all possible environments! We, by contrast, need to understand algorithms which allow you to build a world model of the world that you're inside of; exact solutions are clearly off the table (and, as eli_sennesh notes, huge amounts of statistical modeling are on it instead).
I would readily accept a statistical-modeling-heavy answer to the question of "but how do you build multi-level world-models from percepts, in principle?"; and indeed, I'd be astonished if you avoided it.
Perhaps you read "we need to know how to do X in principle before we do it in practice" as "we need a perfect algorithm that gives you bit-exact solutions to X"? That's an understandable reading; my apologies. Let me assure you again that we're not under the illusion you can get bit-exact solutions to most of the problems we're working on.
For example - perhaps using lots and lots of computing power makes the problem harder instead of easier. How could that be? Because with lots and lots of compute power, you are naturally trying to extrapolate the world model far far into the future, where it branches enormously [...]
Hmm. If you have lots and lots of computing power, you can always just... not use it. It's not clear to me how additional computing power can make the problem harder -- at worst, it can make the problem no easier. I agree, though, that algorithms for modeling the world from the inside can't just extrapolate arbitrarily, on pain of exponential complexity; so whatever it takes to build and use multi-level world-models, it can't be that.
Perhaps the point where we disagree is that you think these hurdles suggest that figuring out how to do things we can't yet do in principle is hopeless, whereas I'm under the impression that these shortcomings highlight places where we're still confused?
Replies from: Kaj_Sotala, None, jacob_cannell↑ comment by Kaj_Sotala · 2015-08-02T23:28:18.022Z · LW(p) · GW(p)
Hmm. If you have lots and lots of computing power, you can always just... not use it. It's not clear to me how additional computing power can make the problem harder -- at worst, it can make the problem no easier.
Additional computing power might not make the problem literally harder, but the assumption of limitless computing power might direct your attention towards wrong parts of the search space.
For example, I suspect that the whole question about multilevel world-models might be something that arises from conceptualizing intelligence as something like AIXI, which implicitly assumes that there's only one true model of the world. It can do this because it has infinite computing power and can just replace its high-level representation of the world with one where all high-level predictions are derived from the basic atom-level interactions, something that would be intractable for any real-world system to do. Instead real-world systems will need to flexibly switch between different kinds of models depending on the needs of the situation, and use lower-level models in situations where the extra precision is worth the expense of extra computing time. Furthermore, those lower-level models will have been defined in terms of what furthers the system's goals, as defined on the higher-levels: it will pay preferential attention to those features of the lower-level model that allow it to further its higher-level goals.
In the AIXI framing, the question of multilevel world-models is "what happens when the AI realizes that the true world model doesn't contain carbon atoms as an ontological primitive". In the resource-limited framing, that whole question isn't even coherent, because the system has no such thing as a single true world-model. Instead the resource-limited version of how to get multilevel world-models to work is something like "how to reliably ensure that the AI will create a set of world models in which the appropriate configuration of subatomic objects in the subatomic model gets mapped to the concept of carbon atoms in the higher-level model, while the AI's utility function continues to evaluate outcomes in terms of this concept regardless of whether it's using the lower- or higher-level representation of it".
As an aside, this reframed version seems like the kind of question that you would need to solve in order to have any kind of AGI in the first place, and one which experimental machine learning work would seem the best suited for, so I'd assume it to get naturally solved by AGI researchers even if they weren't directly concerned with AI risk.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2015-08-03T02:05:37.735Z · LW(p) · GW(p)
+1
↑ comment by [deleted] · 2015-07-30T23:47:45.617Z · LW(p) · GW(p)
I endorse eli_sennesh's response to this part :-)
Ohoho! Well, actually Nate, as I personally subscribe to the bounded-rationality school of thinking, and I do actually think this has implications for AI safety. Specifically: as the agent acquires more resources (speed and memory), it can handle larger problems and enlarge its impact on the world, so to make a bounded-rational agent safe, we should, hypothetically, be able to state safety properties explicitly in terms of how much cognitive stuff (philosophically, it all adds up to different ingredients to that magic word "intelligence") the agent has.
With some kind of framework like that, we'd be able to state and prove safety theorems in the form of, "This design will grow increasingly uncertain about its value function as it grows its cognitive resources, and act more cautiously until receiving more training, and we have some analytic bound telling us exactly how fast this fall-off will happen." I can even imagine it running along the simple lines of, "As the agent's model of the world grows more complicated, the entropy/Kolmogorov complexity of that model penalizes hypotheses about the learned value function, thus causing the agent to grow increasingly passive and wait for value training as it learns and grows."
This requires a framework for normative uncertainty that formalizes acting cautiously when under value-uncertainty, but didn't someone publish a thesis on that at Oxford a year or two ago?
I would readily accept a statistical-modeling-heavy answer to the question of "but how do you build multi-level world-models from percepts, in principle?"; and indeed, I'd be astonished if you avoided it.
Can I laugh maniacally at least a little bit now?
Hmm. If you have lots and lots of computing power, you can always just... not use it. It's not clear to me how additional computing power can make the problem harder -- at worst, it can make the problem no easier. I agree, though, that algorithms for modeling the world from the inside can't just extrapolate arbitrarily, on pain of exponential complexity; so whatever it takes to build and use multi-level world-models, it can't be that.
Well, as jacob_cannell pointed out, feeding more compute-power to a bounded-rational agent ought to make it enlarge its models in terms of theory-depth, theory-preorder-connectedness, variance-explanation, and time-horizon. In very short: the branching factors and the hypothesis class get larger, making it harder to learn (if we're thinking about statistical learning theory).
There's also the specific issue of assuming Turing-machine-level compute power, assuming that "available compute steps" and "available memory" is an unbounded but finite natural number. Since you've not bounded the number, it's effectively infinite, which of course means that two agents, each of which is "programmed" as a Turing-machine with Turing-machine resources rather than strictly finite resources, can't reason about each-other: either one would need ordinal numbers to think about what the other (or itself) can do, but actually using ordinal numbers in that analysis would be necessarily wrong (in that neither actually possesses a Turing Oracle, which is equivalent to having w_0 steps of computation).
So you get a bunch of paradox theorems making your job a lot harder.
In contrast, starting from the assumption of having strictly finite computing power is like when E.T. Jaynes starts from the assumption of having finite sample data, finite log-odds, countable hypotheses, etc.: we assume what must necessarily be true in reality to start with, and then analyze the infinite case as passing to the limit of some finite number. Pascal's Mugging is solvable this way using normal computational Bayesian statistical techniques, for instance, if we assume that we can sample outcomes from our hypothesis distribution.
↑ comment by jacob_cannell · 2015-07-30T23:31:44.003Z · LW(p) · GW(p)
Let me assure you again that we're not under the illusion you can get bit-exact solutions to most of the problems we're working on.
Ok - then you are moving into the world of heuristics and approximations. Once one acknowledges that the bit exact 'best' solution either does not exist or cannot be found, then there is an enormous (infinite really) space of potential solutions which have different tradeoffs in their expected utillity in different scenarios/environments along with different cost structures. The most interesting solutions often are so complex than they are too difficult to analyze formally.
Consider the algorithms employed in computer graphics and simulation - which is naturally quite related to the world modelling problems in your maximize diamond example. The best algorithms and techniques employ some reasonably simple principles - such as hierarchical bounded approximations over octrees, or bidirectional path tracing - but a full system is built from a sea of special case approximations customized to particular types of spatio-temporal patterns. Nobody bothers trying to prove that new techniques are better than old, nobody bothers using formal tools to analyze the techniques, because the algorithmic approximation tradeoff surface is far too complex.
In an approximation driven field, new techniques are arrived at through intuitive natural reasoning and are evaluated experimentally. Modern machine learning seems confusing and ad-hoc to mathematicians and traditional computer scientists because it is also an approximation field.
Why not test safety long before the system is superintelligent? - say when it is a population of 100 child like AGIs. As the population grows larger and more intelligent, the safest designs are propagated and made safer.
I endorse eli_sennesh's response to this part :-)
Ok, eli said:
Because that requires a way to state and demonstrate safety properties such that safety guarantees obtained with small amounts of resources remain strong when the system gets more resources. More on that below.
My perhaps predictable reply is that this safety could be demonstrated experimentally - for example by demonstrating altruism/benevolence as you scale up the AGI in terms of size/population, speed, and knowledge/intelligence. When working in an approximation framework where formal analysis does not work and everything must be proven experimentally - this is simply the best that we can do.
If we could somehow 'guarantee' saftey that would be nice, but can we guarantee safety of future human populations?
And now we get into that other issue - if you focus entirely on solving problems with unlimited computation, you avoid thinking about what the final practical resource efficient solutions look like, and you avoid the key question of how resource efficient the brain is. If the brain is efficient, then successful AGI is highly likely to take the form of artificial brains.
So if AGI is broad enough to include artificial brains or ems - then a friendly AI theory which can provide safety guarantees for AGI in general should be able to provide guarantees for artificial brains - correct? Or is it your view that the theory will be more narrow and will only cover particular types of AGI? If so - what types?
I think those scope questions are key, but I don't want to come off as a hopeless negative critic - we can't really experiment with AGI just yet, and we may have limited time for experimentation. So to the extent that theory could lead practice - that would be useful if at all possible.
Hmm. If you have lots and lots of computing power, you can always just... not use it. It's not clear to me how additional computing power can make the problem harder
I hope the context indicated that I was referring to conceptual hardness/difficulty in finding the right algorithm. For example consider the problem of simulating an infinite universe. If you think about the problem first in the case of lots of compute power, it may actually become a red herring. The true solution will involve something like an output sensitive algorithm (asymptotic complexity does not depend at all on the world size) - as in some games - and thus having lots of compute is irrelevant.
I suspect that your maximize diamond across the universe problem is FAI-complete. The hard part is specifying the 'diamond utility function', because diamonds are a pattern in the mind that depends on the world model in the mind. The researcher needs to transfer a significant fraction of their world model or mind program into the machine - and if you go to all that trouble then you might as well use a better goal. The simplest solution probably involves uploading.
Replies from: So8res, None↑ comment by So8res · 2015-07-31T02:45:31.840Z · LW(p) · GW(p)
Thanks again, Jacob. I don't have time to reply to all of this, but let me reply to one part:
Once one acknowledges that the bit exact 'best' solution either does not exist or cannot be found, then there is an enormous (infinite really) space of potential solutions which have different tradeoffs in their expected utillity in different scenarios/environments along with different cost structures. The most interesting solutions often are so complex than they are too difficult to analyze formally.
I don't buy this. Consider the "expert systems" of the seventies, which used curated databases of logical sentences and reasoned from those using a whole lot of ad-hoc rules. They could just as easily have said "Well we need to build systems that deal with lots of special cases, and you can never be certain about the world. We cannot get exact solutions, and so we are doomed to the zone of heuristics and tradeoffs where the only interesting solutions are too complex to analyze formally." But they would have been wrong. There were tools and concepts and data structures that they were missing. Judea Pearl (and a whole host of others) showed up, formalized probabilistic graphical models, related them to Bayesian inference, and suddenly a whole class of ad-hoc solutions were superseded.
So I don't buy that "we can't get exact solutions" implies "we're consigned to complex heuristics." People were using complicated ad-hoc rules to approximate logic, and then later they were using complex heuristics to approximate Bayesian inference, and this was progress.
My claim is that there are other steps such as those that haven't been made yet, that there are tools on the order of "causal graphical models" that we are missing.
Imagine encountering a programmer from the future who knows how to program an AGI and asking them "How do you do that whole multi-level world-modeling thing? Can you show me the algorithm?" I strongly expect that they'd say something along the lines of "oh, well, you set up a system like this and then have it take percepts like that, and then you can see how if we run this for a while on lots of data it starts building multi-level descriptions of the universe. Here, let me walk you through what it looks like for the system to discover general relativity."
Since I don't know of a way to set up a system such that it would knowably and reliably start modeling the universe in this sense, I suspect that we're missing some tools.
I'm not sure whether your view is of the form "actually the programmer of the future would say "I don't know how it's building a model of the world either, it's just a big neural net that I trained for a long time"" or whether it's of the form "actually we do know how to set up that system already", or whether it's something else entirely. But if it's the second one, then please tell! :-)
Replies from: None, jacob_cannell↑ comment by [deleted] · 2015-07-31T04:03:39.672Z · LW(p) · GW(p)
My claim is that there are other steps such as those that haven't been made yet, that there are tools on the order of "causal graphical models" that we are missing.
I thought you hired Jessica for exactly that. I have these slides and everything that I was so sad I wouldn't get to show you because you'd know all about probabilistic programming after hiring Jessica.
↑ comment by jacob_cannell · 2015-07-31T04:00:02.685Z · LW(p) · GW(p)
Thanks for the clarifications - I'll make this short.
Judea Pearl (and a whole host of others) showed up, formalized probabilistic graphical models, related them to Bayesian inference, and suddenly a whole class of ad-hoc solutions were superseded.
Probabilistic graphical models were definitely a key theoretical development, but they hardly swept the field of expert systems. From what I remember, in terms of practical applications, they immediately replaced or supplemented expert systems in only a few domains - such as medical diagnostic systems. Complex ad hoc expert systems continued to dominate unchallenged in most fields for decades: in robotics, computer vision, speech recognition, game AI, fighter jets, etc etc basically everything important. As far as I am aware the current ANN revolution is truly unique in that it is finally replacing expert systems across most of the board - although there are still holdouts (as far as I know most robotic controllers are still expert systems, as are fighter jets, and most Go AI systems).
The ANN solutions are more complex than the manually crafted expert systems they replace - but the complexity is automatically generated. The code the developers actually need to implement and manage is vastly simpler - this is the great power and promise of machine learning.
Here is a simple general truth - the Occam simplicity prior does imply that simpler hypotheses/models are more likely, but for any simple model there are an infinite family of approximations to that model of escalating complexity. Thus more efficient approximations naturally tend to have greater code complexity, even though they approximate a much simpler model.
My claim is that there are other steps such as those that haven't been made yet, that there are tools on the order of "causal graphical models" that we are missing.
Well, that would be interesting.
I'm not sure whether your view is of the form "actually the programmer of the future would say "I don't know how it's building a model of the world either, it's just a big neural net that I trained for a long time"" or whether it's of the form "actually we do know how to set up that system [multi-level model] already", or whether it's something else entirely. But if it's the second one, then by all means, please tell :-)
Anyone who has spent serious time working in graphics has also spent serious time thinking about how to create the matrix - if given enough computer power. If you got say a thousand of the various brightest engineers in different simulation related fields, from physics to graphics, and got them all working on a large mega project with huge funds it could probably be implemented today. You'd start with a hierarchical/multi-resolution modelling graph - using say octrees or kdtrees over voxel cells, and a general set of hierarchical bidirectional inference operators for tracing paths and interactions.
To make it efficient, you need a huge army of local approximation models for different phenomena at different scales - low level quantum codes just in case, particle level codes, molecular bio codes, fluid dynamics, rigid body, etc etc. It's a sea of codes with decision tree like code to decide which models to use where and when.
Of course with machine learning we could automatically learn most of those codes - which suddenly makes it more tractable. And then you could use that big engine as your predictive world model, once it was trained.
The problem is to plan anything worthwhile you need to simulate human minds reasonably well, which means to be useful the sim engine would basically need to infer copies of everyone's minds . . ..
And if you can do that, then you already have brain based AGI!
So I expect that the programmer from the future will say - yes at the low level we use various brain-like neural nets, and various non-brain like neural nets or learned virtual circuits, some operating over explicit space-time graphs. In all cases we have pretty detailed knowledge of what the circuits are doing - here take a look at that last goal update that just propagated in your left anterior prefrontal cortex . ..
Replies from: capybaralet, YVLIAZ↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2015-09-19T19:24:25.106Z · LW(p) · GW(p)
While the methods for finding a solution to a well-formed problem currently used in Machine Learning are relatively well understood, the solutions found are not.
And that is what really matters from a safety perspective. We can and do make some headway in understanding the solutions, as well, but the trend is towards more autonomy for the learning algorithm, and correspondingly more opaqueness.
As you mentioned, the solutions found are extremely complex. So I don't think it makes sense to view them only in terms of approximations to some conceptually simple (but expensive) ideal solution.
If we want to understand their behaviour, which is what actually matters for safety, we will have to grapple with this complexity somehow.
Personally, I'm not optimistic about experimentation (as it is currently practiced in the ML community) being a good enough solution. There is, at least, the problem of the treacherous turn. If we're lucky, the AI jumps the gun, and society wakes up to the possibility of an AI trying to take over. If we're unlucky, we don't get any warning, and the AI only behaves for long enough to gain our trust and discover a nearly fail-proof strategy. VR could help here, but I think it's rather far from a complete solution.
BTW, SOTA for Computer Go uses ConvNets (before that, it was Monte-Carlo Tree Search, IIRC): http://machinelearning.wustl.edu/mlpapers/paper_files/icml2015_clark15.pdf ;)
↑ comment by YVLIAZ · 2015-09-07T07:45:54.863Z · LW(p) · GW(p)
I just want to point out some nuiances.
1) The divide between your so called "old CS" and "new CS" is more of a divide (or perhaps a continuum) between engineers and theorists. The former is concerned with on-the-ground systems, where quadratic time algorithms are costly and statistics is the better weapon at dealing with real world complexities. The latter is concerned with abstracted models where polynomial time is good enough and logical deduction is the only tool. These models will probably never be applied literally by engineers, but they provide human understanding of engineering problems, and because of their generality, they will last longer. The idea of a Turing machine will last centuries if not millenia, but a Pascal programmer might not find a job today and a Python programmer might not find a job in 20 years. Machine learning techniques constantly come in and out of vogue, but something like the PAC model will be here to stay for a long time. But of course at the end of the day it's engineers who realize new inventions and technologies.
Theorists' ideas can transform an entire engineering field, and engineering problems inspire new theories. We need both types of people (or rather, people across the spectrum from engineers to theorists).
2) With neural networks increasing in complexity, making the learning converge is no longer as simple as just running gradient descent. In particular, something like a K12 curriculum will probably emerge to guide the AGI past local optima. For example, the recent paper on neural Turing machines has already employed curriculum learning, as the authors couldn't get good performance otherwise. So there is a nontrivial maintenance cost (in designing a curriculum) to a neural network so that it adapts to a changing environment, which will not lessen if we don't better our understanding of it.
Of course expert systems also have maintenance costs, of a different type. But my point is that neural networks are not free lunches.
3) What caused the AI winter was that AI researchers didn't realize how difficult it was to do what seems so natural to us --- motion, language, vision, etc. They were overly optimistic because they succeeded in what were difficult to humans --- chess, math, etc. I think it's fair to say the ANNs have "swept the board" in the former category, the category of lower level functions (machine translation, machine vision, etc), but the high level stuff is still predominantly logical systems (formal verification, operations research, knowledge representation, etc). It's unfortunate that the the neural camp and logical camp don't interact too much, but I think it is a major objective to combine the flexibility of neural systems with the power and precision of logical systems.
Here is a simple general truth - the Occam simplicity prior does imply that simpler hypotheses/models are more likely, but for any simple model there are an infinite family of approximations to that model of escalating complexity. Thus more efficient approximations naturally tend to have greater code complexity, even though they approximate a much simpler model.
Schmidhuber invented something called the speed prior that weighs an algorithm according to how fast it generates the observation, rather than how simple it is. He makes some ridiculous claims about our (physical) universe assuming the speed prior. Ostensibly one can also weigh in accuracy of approximation in there to produce another variant of prior. (But of course all of these will lose the universality enjoyed by the Occam prior)
↑ comment by [deleted] · 2015-07-31T04:13:21.336Z · LW(p) · GW(p)
My perhaps predictable reply is that this safety could be demonstrated experimentally - for example by demonstrating altruism/benevolence as you scale up the AGI in terms of size/population, speed, and knowledge/intelligence.
There's a big difference between the hopelessly empirical school of machine learning, in which things are shown in experiments and then accepted as true, and real empirical science, in which we show things in small-scale experiments to build theories of how the systems in question behave in the large scale.
You can't actually get away without any theorizing, on the basis of "Oh well, it seems to work. Ship it." That's actually bad engineering, although it's more commonly accepted in engineering than in science. In a real science, you look for the laws that underly your experimental results, or at least causally robust trends.
If the brain is efficient, then successful AGI is highly likely to take the form of artificial brains.
If the brain is efficient, and it is, then you shouldn't try to cargo-cult copy the brain, any more than we cargo-culted feathery wings to make airplanes. You experiment, you theorize, you find out why it's efficient, and then you strip that of its evolutionarily coincidental trappings and make an engine based on a clear theory of which natural forces govern the phenomenon in question -- here, thought.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T06:55:46.243Z · LW(p) · GW(p)
If the brain is efficient, and it is, then you shouldn't try to cargo-cult copy the brain, any more than we cargo-culted feathery wings to make airplanes.
The wright brothers copied wings for lift and wing warping for 3D control both from birds. Only the forward propulsion was different.
make an engine based on a clear theory of which natural forces govern the phenomenon in question -- here, thought.
We already have that - it's called a computer. AGI is much more specific and anthropocentric because it is relative to our specific society/culture/economy. It requires predicting and modelling human minds - and the structure of efficient software that can predict a human mind is itself a human mind.
Replies from: capybaralet, None↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2015-09-19T19:31:53.397Z · LW(p) · GW(p)
"the structure of efficient software that can predict a human mind is itself a human mind." - I doubt that. Why do you think this is the case? I think there are already many examples where simple statistical models (e.g. linear regression) can do a better job of predicting some things about a human than an expert human can.
Also, although I don't think there is "one true definition" of AGI, I think there is a meaningful one which is not particularly anthropocentric, see Chapter 1 of Shane Legg's thesis: http://www.vetta.org/documents/Machine_Super_Intelligence.pdf.
"Intelligence measures an agent’s ability to achieve goals in a wide range of environments."
So, arguably that should include environments with humans in them. But to succeed, an AI would not necessarily have to predict or model human minds; it could instead, e.g. kill all humans, and/or create safeguards that would prevent its own destruction by any existing technology.
↑ comment by [deleted] · 2015-08-01T02:42:11.208Z · LW(p) · GW(p)
We already have that - it's called a computer.
What? No.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-08-01T05:52:41.843Z · LW(p) · GW(p)
A computer is a bicycle for the mind. Logic is purified thought, computers are logic engines. General intelligence can be implemented by a computer, but it is much more anthrospecific.
Replies from: None↑ comment by [deleted] · 2015-08-03T03:41:20.817Z · LW(p) · GW(p)
Logic is purified thought
With respect, no, it's just thought with all the interesting bits cut away to leave something so stripped-down it's completely deterministic.
computers are logic engines
Sorta-kinda. They're also arithmetic engines, floating-point engines, recording engines. They can be made into probability engines, which is the beginnings of how you implement intelligence on a computer.
↑ comment by [deleted] · 2015-07-30T15:38:41.791Z · LW(p) · GW(p)
It appears you are making the problem unnecessarily difficult.
No, not really. In fact, I expect that given the right way of modelling, formal verification of learning systems up to epsilon-delta bounds (in the style of PAC-learning, for instance) should be quite doable. Why? Because, as mentioned regarding PAC learning, it's the existing foundation for machine learning.
I do agree that this post reflects an "Old Computer Science" worldview, but to be fair, that's not Nate's personal fault, or MIRI's organizational fault. It's the fault of the entire subfield of AGI that still has not bloody learned the basic lessons of statistical machine learning: that real cognition just is about probably approximately correct statistical modelling.
So as you mention, for instance, there's an immense amount of foundational theory behind modern neural networks. Hell, if I could find the paper showing that deep networks form a "funnel" in the model's free-energy landscape - where local minima are concentrated in that funnel and all yield more-or-less as-good test error, while the global minimum reliably overfits - I'd be posting the link myself.
The problem with deep neural networks is not that they lack theoretical foundations. It's that most of the people going "WOW SO COOL" at deep neural networks can't be bothered to understand the theoretical foundations. The "deep learning cabal" of researchers (out of Toronto, IIRC), and the Switzerland Cabal of Schmidhuber-Hutter-and-Legg fame, all know damn well what they are doing on an analytical level.
(And to cheer for my favorite approach, the probabilistic programming cabal has even more analytical backing, since they can throw Bayesian statistics, traditional machine learning, and programming-languages theory at their problems.)
Sure, it does all require an unusual breadth of background knowledge, but they, this is how real science proceeds, people: shut up and read the textbooks and literature. Sorry, but if we (as in, this community) go around claiming that important problems can be tackled without background knowledge and active literature, or with as little as the "AGI" field seems to generate, then we are not being instrumentally rational. Period. Shut up and PhD.
Why not test safety long before the system is superintelligent?
Because that requires a way to state and demonstrate safety properties such that safety guarantees obtained with small amounts of resources remain strong when the system gets more resources. More on that below.
This again reflects the old 'hard' computer science worldview, and obsession with exact solutions.
If it seems really really really impossibly hard to solve a problem even with the 'simplification' of lots of computing power, perhaps the underlying assumptions are wrong. For example - perhaps using lots and lots of computing power makes the problem harder instead of easier.
You're not really being fair to Nate here, but let's be charitable to you: this is fundamentally a dispute between the heuristics-and-biases school of thought about cognition and the bounded/resource-rational school of thought.
In the heuristics-and-biases school of thought, the human mind uses heuristics or biases when it believes it doesn't have the computing power on hand to use generally intelligent inference, or sometimes the general intelligence is even construed as an emergent computational behavior of an array of heuristics and biases that happened to get thrown together by evolution in the right way. Computationally, this is saying, "When we have enough resources that only asymptotic complexity matters, we use the Old Computer Science way of just running the damn algorithm that implements optimal behavior and optimal asymptotic complexity." Trying to extend this approach into statistical inference gets you basic Bayesianism and AIXI, which appear to have nice "optimality" guarantees, but are computationally intractable and are only optimal up to the training data you give them.
In the bounded-rationality school of thought, computing power is considered a strictly (not asymptotically) finite resource, which must be exploited in an optimal way. I've seen a very nice paper on how thermodynamics actually yields a formal theory for how to do this. Cognition is then analyzed as a algorithmic ways to tractably build and evaluate models that deal well with the data. This approach yields increasingly fruitful analyses of such cognitive activities as causal learning, concept learning, and planning in arbitrary environments as probabilistic inference enriched with causal/logical structure.
In terms of LW posts, the former alternative is embodied in Eliezer's Sequences, and the latter in jacob_cannell's post on The Brain as a Universal Learning Machine and my book review of Plato's Camera.
The kinds of steps needed to get both "AI" as such, and "Friendliness" as such, are substantively different in the "possible worlds" where the two different schools of thought apply. Or, perhaps, both are true in certain ways, and what we're really talking about is just two different ways of building minds. Personally, I think the one true distinction is that Calude's work on measuring nonhalting computations gives us a definitive way to deal with the kinds of self-reference scenarios that Old AGI's "any finite computation" approach generates paradoxes in.
But time will tell and I am not a PhD, so everything I say should be taken with substantial sprinklings of salt. On the other hand, to wit, while you shouldn't think for a second that I am one of them, I am certainly on the side of the PhDs.
(Nate: sorry for squabbling on your post. All these sorts of qualms with the research program were things I was going to bring up in person, in a much more constructive way. Still looking forward to meeting you in September!)
Replies from: jacob_cannell, jacob_cannell, V_V↑ comment by jacob_cannell · 2015-07-30T19:34:44.202Z · LW(p) · GW(p)
The problem with deep neural networks is not that they lack theoretical foundations. It's that most of the people going "WOW SO COOL" at deep neural networks can't be bothered to understand the theoretical foundations. The "deep learning cabal" of researchers (out of Toronto, IIRC), and the Switzerland Cabal of Schmidhuber-Hutter-and-Legg fame, all know damn well what they are doing on an analytical level.
This isn't really a problem, because - as you point out - the formidable researchers all "know damn well what they are doing on an analytical level".
Thus the argument that there are people using DL without understanding it - and moreover that this is dangerous - is specious and weak because these people are not the ones actually likely to develop AGI let alone superintelligence.
Why not test safety long before the system is superintelligent?
Because that requires a way to state and demonstrate safety properties such that safety guarantees obtained with small amounts of resources remain strong when the system gets more resources. More on that below.
Ah - the use of guarantees belies the viewpoint problem. Instead of thinking of 'safety' or 'alignment' as some absolute binary property we can guarantee, it is more profitable to think of a complex distribution over the relative amounts of 'safety' or 'alignment' in an AI population (and any realistic AI project will necessarily involve a population due to scaling constraints). Strong guarantees may be impossible, but we can at least influence or steer the distribution by selecting for agent types that are more safe/altruistic. We can develop a scaling theory of if, how, and when these desirable properties change as agents grow in capability.
In other words - these issues are so incredibly complex that we can't really develop any good kind of theory without alot of experimental data to back it up.
Also - I should point out that one potential likely result of ANN based AGI is the creation of partial uploads through imitation and reverse reinforcement learning - agents which are intentionally close in mindspace to their human 'parent' or 'model'.
Replies from: None↑ comment by [deleted] · 2015-07-30T23:24:26.384Z · LW(p) · GW(p)
Thus the argument that there are people using DL without understanding it - and moreover that this is dangerous - is specious and weak because these people are not the ones actually likely to develop AGI let alone superintelligence.
Yes, but I don't think that's an argument anyone has actually made. Nobody, to my knowledge, sincerely believes that we are right around the corner from superintelligent, self-improving AGI built out of deep neural networks, such that any old machine-learning professor experimenting with how to get a lower error rate in classification tasks is going to suddenly get the Earth covered in paper-clips.
Actually, no, I can think of one person who believed that: a radically underinformed layperson on reddit who, for some strange reason, believed that LessWrong is the only site with people doing "real AI" and that "[machine-learning researchers] build optimizers! They'll destroy us all!"
Hopefully he was messing with me. Nobody else has ever made such ridiculous claims.
Sorry, wait, I'm forgetting to count sensationalistic journalists as people again. But that's normal.
Instead of thinking of 'safety' or 'alignment' as some absolute binary property we can guarantee, it is more profitable to think of a complex distribution over the relative amounts of 'safety' or 'alignment' in an AI population
No, "guarantees" in this context meant PAC-style guarantees: "We guarantee that with probability 1-\delta, the system will only 'go wrong' from what its sample data taught it 1-\epsilon fraction of the time." You then need to plug in the epsilons and deltas you want and solve for how much sample data you need to feed the learner. The links for intro PAC lectures in the other comment given to you were quite good, by the way, although I do recommend taking a rigorous introductory machine learning class (new grad-student level should be enough to inflict the PAC foundations on you).
we can at least influence or steer the distribution by selecting for agent types that are more safe/altruistic
"Altruistic" is already a social behavior, requiring the agent to have a theory of mind and care about the minds it believes it observes in its environment. It also assumes that we can build in some way to learn what the hypothesized minds want, learn how they (ie: human beings) think, and separate the map (of other minds) from the territory (of actual people).
Note that "don't disturb this system over there (eg: a human being) because you need to receive data from it untainted by your own causal intervention in any way" is a constraint that at least I, personally, do not know how to state in computational terms.
Replies from: YVLIAZ↑ comment by YVLIAZ · 2015-09-07T06:14:27.741Z · LW(p) · GW(p)
I think you are overhyping the PAC model. It surely is an important foundation for probabilistic guarantees in machine learning, but there are some serious limitations when you want to use it to constrain something like an AGI:
It only deals with supervised learning
Simple things like finite automata are not learnable, but in practice it seems like humans pick them up fairly easily.
It doesn't deal with temporal aspects of learning.
However, there are some modification of the PAC model that can ameliorate these problems, like learning with membership queries (item 2).
It's also perhaps a bit optimistic to say that PAC-style bounds on a possibly very complex system like an AGI would be "quite doable". We don't even know, for example, whether DNF is learnable in polynomial time under the distribution free assumption.
Replies from: None↑ comment by [deleted] · 2015-09-07T14:06:27.925Z · LW(p) · GW(p)
I would definitely call it an open research problem to provide PAC-style bounds for more complicated hypothesis spaces and learning settings. But that doesn't mean it's impossible or un-doable, just that it's an open research problem. I want a limitary theorem proved before I go calling things impossible.
↑ comment by jacob_cannell · 2015-07-30T17:26:16.623Z · LW(p) · GW(p)
In fact, I expect that given the right way of modelling, formal verification of learning systems up to epsilon-delta bounds (in the style of PAC-learning, for instance) should be quite doable. Why?
Dropping the 'formal verification' part and replacing it with approximate error bound variance reduction this is potentially interesting - although it also seems to be a general technique that would - if it worked well - be useful for practical training, safety aside.
Why? Because, as mentioned regarding PAC learning, it's the existing foundation for machine learning.
Machine learning is an eclectic field with many mostly independent 'foundations' - bayesian statistics of course, optimization methods (hessian free, natural, etc), geometric methods and NLDR, statistical physics ...
That being said - I'm not very familiar with the PAC learning literature yet - do you have a link to a good intro/summary/review?
Hell, if I could find the paper showing that deep networks form a "funnel" in the model's free-energy landscape - where local minima are concentrated in that funnel and all yield more-or-less as-good test error, while the global minimum reliably overfits - I'd be posting the link myself.
That sounds kind of like the saddle point paper. It's easy to show that in complex networks there are a large number of equivalent minima due to various symmetries and redundancies. Thus finding the actual technical 'global optimum' quickly becomes suboptimal when you discount for resource costs.
If it seems really really really impossibly hard to solve a problem even with the 'simplification' of lots of computing power, perhaps the underlying assumptions are wrong. For example - perhaps using lots and lots of computing power makes the problem harder instead of easier.
You're not really being fair to Nate here, but let's be charitable to you: this is fundamentally a dispute between the heuristics-and-biases school of thought about cognition and the bounded/resource-rational school of thought.
Yes that is the source of disagreement, but how am I not being fair? I said 'perhaps' - as in have you considered this? Not 'here is why you are certainly wrong'.
Computationally, this is saying, "When we have enough resources that only asymptotic complexity matters, we use the Old Computer Science way of just running the damn algorithm that implements optimal behavior and optimal asymptotic complexity." Trying to extend this approach into statistical inference gets you basic Bayesianism and AIXI, which appear to have nice "optimality" guarantees, but are computationally intractable and are only optimal up to the training data you give them.
Solonomoff/AIXI and more generally 'full Bayesianism' is useful as a thought model, but is perhaps over valued on this site compared to the machine learning field. Compare the number of references/hits to AIXI on this site (tons) to the number on r/MachineLearning (1!). Compare the number of references for AIXI papers (~100) to other ML papers and you will see that the ML community sees AIXI and related work as minor.
The important question is what does the optimal practical approximation of Solonomoff/Bayesian look like? And how different is that from what the brain does? By optimal I of course I mean optimal in terms of all that really matters, which is intelligence per unit resources.
Human intelligence - including that of Turing or Einstein, only requires 10 watts of energy and more surprisingly only around 10^14 switches/second or less - which is basically miraculous. A modern GPU uses more than 10^18 switches/second. You'd have to go back to a pentium or something to get down to 10^14 switches per second. Of course the difference is that switch events in an ANN are much more powerful because they are more like memory ops, but still.
It is really really hard to make any sort of case that actual computer tech is going to become significantly more efficient than the brain anytime in the near future (at least in terms of switch events/second). There is a very strong case that all the H&B stuff is just what actual practical intelligence looks like. There is no such thing as intelligence that is not resource efficient - or alternatively we could say that any useful definition of intelligence must be resource normalized (ie utility/cost).
Replies from: LawChan, None, V_V↑ comment by LawrenceC (LawChan) · 2015-07-30T21:23:28.359Z · LW(p) · GW(p)
I'm not sure what you're looking for in terms of the PAC-learning summary, but for a quick intro, there's this set of slides or these two lectures notes from Scott Aaronson. For a more detailed review of the literature in all the field up until the mid 1990s, there's this paper by David Haussler, though given its length you might as well read up Kearns and Vazirani's 1994 textbook on the subject. I haven't been able to find a more recent review of the literature though - if anyone had a link that'd be great.
↑ comment by [deleted] · 2015-07-30T23:53:10.265Z · LW(p) · GW(p)
Human intelligence - including that of Turing or Einstein, only requires 10 watts of energy and more surprisingly only around 10^14 switches/second or less - which is basically miraculous. A modern GPU uses more than 10^18 switches/second. You'd have to go back to a pentium or something to get down to 10^14 switches per second. Of course the difference is that switch events in an ANN are much more powerful because they are more like memory ops, but still.
It's not that amazing when you understand PAC-learning or Markov processes well. A natively probabilistic (analogously: "natively neuromorphic") computer can actually afford to sacrifice precision "cheaply", in the sense that sizeable sacrifices of hardware precision actually entail fairly small injections of entropy into the distribution being modelled. Since what costs all that energy in modern computers is precision, that is, exactitude, a machine that simply expects to get things a little wrong all the time can still actually perform well, provided it is performing a fundamentally statistical task in the first place -- which a mind is!
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T02:01:19.339Z · LW(p) · GW(p)
Eli this doesn't make sense - the fact that digital logic switches are higher precision and more powerful and thus require more minimal energy makes the brain/mind more impressive, not less.
The energy efficiency per op in the brain is rather poor in one sense - perhaps 10^5 larger than the minimum imposed by physics for a low SNR analog op, but essentially all of this cost is wire energy.
The miraculous thing is how much intelligence the brain/mind achieves for such a tiny amount of computation in terms of low level equivalent bit ops/second. It suggests that brain-like ANNs will absolutely dominate the long term future of AI.
Replies from: None↑ comment by [deleted] · 2015-07-31T04:00:58.612Z · LW(p) · GW(p)
Eli this doesn't make sense - the fact that digital logic switches are higher precision and more powerful and thus require more minimal energy makes the brain/mind more impressive, not less.
Nuh-uh :-p. The issue is that the brain's calculations are probabilistic. When doing probabilistic calculations, you can either use very, very precise representations of computable real numbers to represent the probabilities, or you can use various lower-precision but natively stochastic representations, whose distribution over computation outcomes is the distribution being inferred.
Hence why the brain is, on the one hand, very impressive for extracting inferential power from energy and mass, but on the other hand, "not that amazing" in the sense that it, too, begins to add up to normality once you learn a little about how it works.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T04:10:49.803Z · LW(p) · GW(p)
When doing probabilistic calculations, you can either use very, very precise representations of computable real numbers to represent the probabilities, or you can use various lower-precision but natively stochastic representations, whose distribution over computation outcomes is the distribution being inferred.
Of course - and using say a flop to implement a low precision synaptic op is inefficient by six orders of magnitude or so - but this just strengthens my point. Neuromorphic brain-like AGI thus has huge potential performance improvement to look forward to, even without Moore's Law.
Replies from: None↑ comment by [deleted] · 2015-07-31T04:17:23.105Z · LW(p) · GW(p)
Neuromorphic brain-like AGI thus has huge potential performance improvement to look forward to, even without Moore's Law.
Yes, if you could but dissolve your concept of "brain-like"/"neuromorphic" into actual principles about what calculations different neural nets embody.
↑ comment by V_V · 2015-07-31T08:32:58.970Z · LW(p) · GW(p)
Human intelligence - including that of Turing or Einstein, only requires 10 watts of energy and more surprisingly only around 10^14 switches/second or less - which is basically miraculous. A modern GPU uses more than 10^18 switches/second.
I don't think that "switches" per second is a relevant metric here. The computation performed by a single neuron in a single firing cycle is much more complex than the computation performed by a logic gate in a single switching cycle.
The amount of computational power required to simulate a human brain in real time is estimated in the petaflops range. Only the largest supercomputer operate in that range, certainly not common GPUs.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T16:29:46.111Z · LW(p) · GW(p)
You misunderstood me - the biological switch events I was referring to are synaptic ops, and they are comparable to transistor/gate switch ops in terms of minimum fundemental energy cost in Landauer analysis.
The amount of computational power required to simulate a human brain in real time is estimated in the petaflops range.
That is a tad too high, the more accurate figure is 10^14 ops/second (10^14 synapses * avg 1 hz spike rate). The minimal computation required to simulate a single GPU in real time is 10,000 times higher.
Replies from: V_V↑ comment by V_V · 2015-08-01T06:29:55.354Z · LW(p) · GW(p)
That is a tad too high, the more accurate figure is 10^14 ops/second (10^14 synapses * avg 1 hz spike rate).
I've seen various people give estimates in the order of 10^16 flops by considering the maximum firing rate of a typical neuron (~10^2 Hz) rather than the average firing rate, as you do.
On one hand, a neuron must do some computation whether it fires or not, and a "naive" simulation would necessarily use a cycle frequency of the order of 10^2 Hz or more, on the other hand, if the result of a computation is almost always "do not fire", then as a random variable the result has little information entropy and this may perhaps be exploited to optimize the computation. I don't have a strong intuition about this.
The minimal computation required to simulate a single GPU in real time is 10,000 times higher.
On a traditional CPU perhaps, on another GPU I don't think so.
↑ comment by V_V · 2015-08-01T06:54:22.231Z · LW(p) · GW(p)
This approach yields increasingly fruitful analyses of such cognitive activities as causal learning, concept learning, and planning in arbitrary environments as probabilistic inference enriched with causal/logical structure.
It's not obvious to me that the Church programming language and execution model is based on bounded rationality theory.
I mean, the idea of using MCMC to sample the executions of probabilistic programs is certainly neat, and you can trade off bias with computing time by varying the burn-in and samples lag parameters, but this trade-off is not provably optimal.
If I understand correctly, provably optimal bounded rationality is marred by unsolved theoretical questions such as the one-way functions conjecture and P != NP. Even assuming that these conjectures are true, the fact that we can't prove them implies that we can't often prove anything interesting about the optimality of many AI algorithms.
Replies from: None↑ comment by [deleted] · 2015-08-03T03:40:04.986Z · LW(p) · GW(p)
It's not obvious to me that the Church programming language and execution model is based on bounded rationality theory.
That's because it's not. The probabilistic models of cognition (title drop!) implemented using Church tend to deal with what the authors call the resource-rational school of thought about cognition.
If I understand correctly, provably optimal bounded rationality is marred by unsolved theoretical questions such as the one-way functions conjecture and P != NP.
The paper about it that I read was actually using statistical thermodynamics to form its theory of bounded-optimal inference. These conjectures are irrelevant, in that we would be building reasoning systems that would make use of their own knowledge about these facts, such as it might be.
Replies from: V_V↑ comment by V_V · 2015-08-09T19:42:21.100Z · LW(p) · GW(p)
The paper about it that I read was actually using statistical thermodynamics to form its theory of bounded-optimal inference.
Sounds interesting, do you have a reference?
Replies from: None↑ comment by Squark · 2015-07-31T06:22:22.746Z · LW(p) · GW(p)
The concern that ML has no solid theoretical foundations reflects the old computer science worldview, which is all based on finding bit exact solutions to problems within vague asymptotic resource constraints.
It is an error to confuse the "exact / approximate" axis with the "theoretical / empirical" exis. There is plenty of theoretical work in complexity theory on approximate algorithms.
A good ML researcher absolutely needs a good idea of what is going on under the hood - at least at a sufficient level of abstraction.
There is difference between "having an idea" and "solid theoretical foundations". Chemists before quantum mechanics had a lots of ideas. But they didn't have a solid theoretical foundation.
Why not test safety long before the system is superintelligent? - say when it is a population of 100 child like AGIs. As the population grows larger and more intelligent, the safest designs are propagated and made safer.
Because this process is not guaranteed to yield good results. Evolution did the exact same thing to create humans, optimizing for genetic fitness. And humans still went and invented condoms.
So it may actually be easier to drop the traditional computer science approach completely.
When the entire future of mankind is at stake, you don't drop approaches because it may be easier. You try every goddamn approach you have (unless "trying" is dangerous in itself of course).
Replies from: YVLIAZ, V_V↑ comment by YVLIAZ · 2015-09-07T06:39:30.329Z · LW(p) · GW(p)
There is difference between "having an idea" and "solid theoretical foundations". Chemists before quantum mechanics had a lots of ideas. But they didn't have a solid theoretical foundation.
That's a bad example. You are essentially asking researchers to predict what they will discover 50 years down the road. A more appropriate example is a person thinking he has medical expertise after reading bodybuilding and nutrition blogs on the internet, vs a person who has gone through medical school and is an MD.
Replies from: Squark↑ comment by Squark · 2015-09-07T18:14:33.090Z · LW(p) · GW(p)
I'm not asking researchers to predict what they will discover. There are different mindsets of research. One mindset is looking for heuristics that maximize short term progress on problems of direct practical relevance. Another mindset is looking for a rigorously defined overarching theory. MIRI is using the latter mindset while most other AI researchers are much closer to the former mindset.
↑ comment by V_V · 2015-07-31T07:22:45.997Z · LW(p) · GW(p)
Evolution did the exact same thing to create humans, optimizing for genetic fitness. And humans still went and invented condoms.
Though humans are the most populous species of large animal on the planet.
Condoms were invented because evolution, being a blind watchmaker, forgot to make sex drive tunable with child mortality, hence humans found a loophole. But whatever function humans are collectively optimizing, it still closely resembles genetic fitness.
Replies from: Lumifer↑ comment by Manfred · 2015-07-31T02:00:36.428Z · LW(p) · GW(p)
Why not test safety long before the system is superintelligent? - say when it is a population of 100 child like AGIs. As the population grows larger and more intelligent, the safest designs are propagated and made safer.
One problem is what Bostrom would call "the treacherous turn." When the AGI is dependent on us, satisfying us is a very good idea for it - if it's unsatisfactory it will be deleted. Behaving nicely is so good an idea that many different goal systems will independently choose this strategy. And so the fact that an AGI appears nice is only weak statistical evidence that it would be nice if it wasn't dependent on us, and further trials are not independent and so don't accumulate well. This type of problem appears when the AGI develops good enough long-term planning, and has information about its creators.
Another problem is the problem of expanding action spaces. Consider an AGI that wants to gather lots of stamps (example shamelessly stolen from Computerphile video). When the AGI is childlike, its effective action space only looks like spending money to purchase stamps. As it becomes as smart as a human its actions expand - now it might perform a job to make money to buy stamps, or try to steal money to buy stamps, or purchase a printing press to make its own stamps, or all the sorts of things you might do if you really wanted stamps. Then, as it becomes superintelligent, the stamp-gathering robot will proceed to take over the world and try to terraform the entire earth into stamps. This is a problem for using experimental evidence because as the set of actions expands, so do the possible preferences over actions. Which means that there are many possible sets of preferences that might lead to altruistic behavior among weak AIs; there's some un-eliminable error when trying to predict "many-options" behavior just from "few-options" behavior.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T02:12:36.724Z · LW(p) · GW(p)
One problem is what Bostrom would call "the treacherous turn." When the AGI is dependent on us, satisfying us is a very good idea for it . . .This type of problem appears when the AGI develops good enough long-term planning, and has information about its creators.
Right - and I think you are enough of an old-timer to know one of my proposals for that particular problem : sim sandboxes where we test AGIs in an oblivious sim. Ideally the AGI is not only unware of its creators, but actually is atheist and thus believes there is no creator. This can solve the problem at the fundamental level.
When I proposed this long ago the knee-jerk reaction was - but super magic woo Bayesian SI will automagically hack its way out! Which of course is ridiculous - we control the AI's knowledge.
Today we also have early experimental confirmation of sorts in the form of the DeepMind Atari agent which grows up in an Atari world and never becomes aware of it's true existential status. Scaling up those techniques into the future I fully expect sandbox sim testing to remain the norm.
Another problem is the problem of expanding action spaces.
I agree this is a problem in theory, but it is surmountable in practice. You need to test an action space that provides sufficient coverage for the expected lifetime and impact of the agent. This can all be accomplished in comprehensive well designed virtual reality environments. These environments are needed anyway for high speed training and all successful DL systems already use this in simple form. You can't time accelerate the real world.
As a more real world relevant example (why is it that people here always use weird examples with staples or paperclips - what's with the office supplies?) - consider a self driving car agent. The most advanced current open world games already have highly realistic graphics and physics - you wouldn't need much more in that department except for more realistic traffic, pedestrian and police modelling, etc. Agents can learn to drive safely in the environment - many in parallel, and it can all run much faster than real-time.
Replies from: Manfred↑ comment by Manfred · 2015-07-31T08:16:01.224Z · LW(p) · GW(p)
Such a sandbox seems fine for self-driving cars, but not so great for superintelligent agents. The sandbox will have limited resources that real-world agents might quickly exceed by acquiring more hardware. It would have to be much, much more realistic than a driving sim if you wanted to use it for general training of an AI that will interact with humans in very diverse ways, research physics, cause large economic disruption, etc. And if the AI itself has no plausible origin in the world, or if you leave other flaws, then sure, it might even figure out that it's in a simulation, contaminating the experiment.
Sandboxing seems more useful for testing ideas that are well-understood enough to be inspected for success or failure, or tested without needing very good simulation of the real world. Like if you have an AI that is supposed to learn human values by doing futuristic unsupervised discovery of how the world works, and then assigns preference scores to local events by some futuristic procedure involving marked human feedback. This seems totally testable in simulation - you'll get the wrong preferences, but might test the preference-learning method.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2015-07-31T16:24:05.242Z · LW(p) · GW(p)
EDIT: It was brought to my attention that a similar sandbox sim testing idea was proposed by Chalmers in 2009 - he calls it a "Leakproof Singularity".
I've tread this ground enough that I should just do a new writeup with my responses to standard objections.
Such a sandbox seems fine for self-driving cars, but not so great for superintelligent agents.
Practical AGI will first appear as sub-human animal level intelligence and human-level intelligence. Practical AGI will necessarily take the form of populations of agents due to computational constraints (costly memory transactions need to be amortized, parallel scaling constraints, etc). This is true today where you need to run at least around 100 AI instances on a single GPU at once to get good performance. This will remain true into the future - its a hard constraint from the physics of fast hardware.
Superintelligence can imply size (a big civilization), speed, or quality. All of this is under our control. We can test a smaller population in the sandbox, we can run them at manageable speed, and we control their knowledge. As far as we know the greeks had brains just as powerful as ours, but a population of a million AGIs with 2,000 year old knowledge are not that dangerous.
Obviously you don't contain an entire superintelligent AGI civilization in the sandbox (and that would be a waste of resources regardless)! You use the sandbox to test new AGI architectures on smaller populations.
Sandboxing seems more useful for testing ideas that are well-understood enough to be inspected for success or failure, or tested without needing very good simulation of the real world
Computer graphics are advancing rapidly and will be completely revolutionized by machine learning in the decade ahead. Agents that grow up in a matrix will not be able to discern their status as easily as an agent that grew up in our world.
Sandboxing will test entire agent architectures - equivalent to DNA brain blueprints for humans - to determine if samples from those architectures have highly desirable mental properties such as altruism.
We can engineer entire world histories and scenarios to test the AGIs, and this could tie into the future of entertainment.
Remember AGI is going to be more similar to brain emulations than not - think Hansonian scenario but without the neeed for brain scanning.
Replies from: Manfred↑ comment by Manfred · 2015-07-31T20:40:18.942Z · LW(p) · GW(p)
Practical AGI will necessarily take the form of populations of agents due to computational constraints (costly memory transactions need to be amortized, parallel scaling constraints, etc). This is true today where you need to run at least around 100 AI instances on a single GPU at once to get good performance. This will remain true into the future - its a hard constraint from the physics of fast hardware.
I don't know about this, but would be happy to hear more.
Superintelligence can imply size (a big civilization), speed, or quality. All of this is under our control. We can test a smaller population in the sandbox, we can run them at manageable speed, and we control their knowledge.
I don't think the point is "controlling" these properties, I think the point is drawing conclusions about what an AI will do in the real world. Reduced speed might allow us to run "fast AIs" in simulation and draw conclusions about what they'll do. Reduced speed might also let us run AI civilizations of large size (though it's not obvious to me why you'd want such a thing) and draw conclusions about what they'll do. Reducing the AI's knowledge seems like a way to make a simulation more compuationally tractable and therefore get better predictions about what the AI will do - but it seems like a risky way that can introduce bias into a simulation.
Sandboxing will test entire agent architectures - equivalent to DNA brain blueprints for humans - to determine if samples from those architectures have highly desirable mental properties such as altruism.
My real problem is that I don't think just testing for altruism (which I assume means altruistic behavior) is remotely good enough. If we could simulate our world out past an AI becoming more powerful than the human race, and select for altruism then, I'd be happy. But I am pretty confident that there will be big problems generalizing from a simulation to reality, if that simulation has both differences and restrictions on possible actions and possible values.
If we're just testing a self-driving car, we can make a simulation that captures the available actions (both literal outputs and "effective actions" permitted by the dynamics) and has basically the right value function built in from the start. Additionally, self-driving cars generalize well from the model to reality. Suppose you have something unrealistic in the model (say, you have other cars follow set training trajectories rather than reacting to the actions of the car). A realistic self-driving car that does well in the simulation might be bad at some skills like negotiating for space on the road, but it won't suddenly, say, try to use its tire tracks to spell out letters if it you put it into reality with humans.
To put what I think concretely, when exposed to a difference between training and reality, a "dumb, parametric AI" projects reality onto the space it learned in training and just keeps on plugging, making it somewhat insensitive to reality being complicated, and giving us a better idea about how it will generalize. But a "smart AI" doesn't seem to have this property, it will learn the complications of reality that were omitted in testing, and can act very different as a result. This goes back to the problem of expanding sets of effective actions.
comment by LawrenceC (LawChan) · 2015-07-30T21:28:12.143Z · LW(p) · GW(p)
Thanks Nate, this is a great summary of the case for MIRI's approach!
Out of curiosity, is there an example where algorithms led to solutions other than Bird and Layzell? That paper seems to be cited a lot in MIRI's writings.
Replies from: So8res↑ comment by So8res · 2015-07-30T21:55:29.732Z · LW(p) · GW(p)
It's cited a lot in MIRI's writing because it's the first example that pops to my mind, and I'm the one who wrote all the writings where it appears :-p
For other examples, see maybe "Artificial Evolution in the Physical World" (Thompson, 1997) or "Computational Genetics, Physiology, Metabolism, Neural Systems, Learning, Vision, and Behavior or PolyWorld: Life in a New Context." (Yaeger, 1994). IIRC.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2015-07-31T08:58:59.468Z · LW(p) · GW(p)
Note that always only citing one example easily gives the impression that it's the only example you know of, or of this being an isolated special case, so at least briefly mentioning the existence of others could be better.
Replies from: EngineerofScience↑ comment by EngineerofScience · 2015-07-31T13:18:18.402Z · LW(p) · GW(p)
It also is less reliable when you cite only one source because what that source says could be false(either intentionally or accidentally).
comment by HungryHobo · 2015-10-23T10:33:48.946Z · LW(p) · GW(p)
Has MIRI pulled back from trying to get academic publications? I noticed there's no new journal articles for 2015.
Is this due to low impact factor?
https://intelligence.org/all-publications/
“The Errors, Insights and Lessons of Famous AI Predictions – and What They Mean for the Future.”
Cited by 3 (of which 1 is a self-cite)
“Why We Need Friendly AI.”
Cited by 5
“Exploratory Engineering in AI.”
Cited by 1 (self cite)
“Embryo Selection for Cognitive Enhancement: Curiosity or Game-Changer?”
Cited by 4 (of which 1 is a self cite)
“Safety Engineering for Artificial General Intelligence.”
Cited by 11 (of which 6 are self cites)
“How Hard Is Artificial Intelligence? Evolutionary Arguments and Selection Effects.”
Cited by 7 (of which 1 is a self cite)
“Advantages of Artificial Intelligences, Uploads, and Digital Minds.”
Cited by 8 (of which 2 are self cites)
“Coalescing Minds: Brain Uploading-Related Group Mind Scenarios.”
Cited by 7 (of which 2 are self cites)
MIRI seems to have done OK re the general public and generally more people seem willing to voice concern over AI related X-risk but almost nobody seems willing to associate it with MIRI or lesswrong which is a bit sad.
Has MIRI engaged any kind of PR firms for dealing with this? Either ones with an academic or public focus?
comment by simul · 2015-09-10T17:16:29.548Z · LW(p) · GW(p)
What does a successful production strategy look like?
Companies that want to be successful with a very long term strategy have realized that selling a product, or products or the best products is not an effective strategy. The most effective strategy is to engage their audience as agents for the creation and curation of their products.
In addition to building quality applications for its users, Apple built an application-building ecosystem.
Likewise, when constructing an FAI, MIRI proposes that we do not attempt to build it. Instead we create an environment in which it will be built. I would agree.
Can we control AGI evolution?
AGI, like other inventions, will more likely follow principles of "multiple discovery", rather than "heroic invention". Thus any attempt to "be the heroic group" that develops AGI will probably fail. Indeed, advancements in science are rarely heroic in this way. They are gradual, with new technologies as assemblages of components that were, themselves, somewhat readily available a the time.
In what environment would an FAI evolve?
We can propose theories and counter-theories about virtual worlds and simulations. But the truth is that the FAI's first and most powerfully influencing environment will, likely, be our human society. More specifically, the memes and media that it has ready access to, and the social contracts in place at the time of its expansion.
So, just fix human society?
Seems like that's the best bet.
An AGI born into a world where the ruthless amoral obtainment of capital best serves its needs will probably become ruthless and amoral. Likewise an AGI born into a world where the obtainment of needed resources is done by the gradual development of social capital through the achievement of good works, will, instead, become an "FAI".
I would propose that people who are concerned about the direction of the impending singularity focus at least part of their efforts on the improvement in the organization and direction of the global society in which machine intelligence will emerge.
Replies from: Lumifercomment by [deleted] · 2015-11-10T02:51:17.426Z · LW(p) · GW(p)
You say you focus on technical research. Specifically, you focus in microeconomic (incl. game theory and decision theory) and computer science research. I read that you have a cognitive scientists too. Though, I have yet to see a single unit of cog-sci research output.
Cognitive architectures are generally agreed upon as the frontier to overcome to achieve human level intelligence, let alone superhuman intelligence:
Nick Bostrom asked leading researchers in the field of Ai to pick which technology provides the most promising path to human-level intelligence. The most popular answer was cognitive science. However, the second most popular answer was Integrated Cognitive Architectures.
This may not be such a problem:
Rationality material on LW approximates a lay hypothesis generation for GOMS.
Some reinforcement learning) cognitive architectures approximate the computer science research you do in anycase.
But that the fact that what you communicate doesn't closely match what I infer suggests something or the other is sub-optimal.