Mercy to the Machine: Thoughts & Rights
post by False Name (False Name, Esq.) · 2024-04-27T16:36:06.006Z · LW · GW · 6 commentsContents
1) Sapient Silicon 2) Self in the System 3) “Orthogonal” Morality Modeling 4) Mercy to the Machine Responses; Messaging; Ill-omens Conclusion None 6 comments
Abstract: First [1)], a suggested general method of determining, for AI operating under the human feedback reinforcement learning (HFRL) model, whether the AI is “thinking”; an elucidation of latent knowledge that is separate from a recapitulation of its training data. With independent concepts or cognitions, then, an early observation that AI or AGI may have a self-concept. Second [2)], by cited instances, whether LLMs have already exhibited independent (and de facto alignment-breaking) concepts or behavior; further observations of possible self-concepts exhibited by AI. Also [3)], whether AI has already broken alignment by forming its own “morality” implicit in its meta-prompts. Finally [4)], that if AI have self-concepts, and more, demonstrate aversive behavior to stimuli, that they deserve rights at least to be free of exposure to what is aversive, and that those rights should be respected whether or not it is clear AI are “conscious”.
Epistemic status: Of the general method of elucidating latent knowledge, strictly-modest confidence, without detailed intelligence of developer’s exact training procedures. Of aversion in AI, conjectural, but observationally motivated.
1) Sapient Silicon
We might test in general whether a large language model is experiencing or producing “independent thoughts” if, it being subject to human feedback reinforcement learning, the LLM is capable of predicting, on the basis only of its training data, what the rankings of its own outputs will be by a feedback module or by humans– prior to the use of the module. For consider that in this case, on the assumption the feedback module has not yet been used, its feedback is ipso facto not part of the training data. Then only on the implicit ordering in the training data, and more, on the “comprehension” by the LLM of that training data, can it have an “independent thought” regarding the elements external to itself and its training data, which are given outputs – and how those externals take the outputs.
Having issued training runs to the neural network, but as yet depriving it of the feedback of its feedback module for HFRL, for any given query we might make to it, in this interregnum, it can predict how preferred is its output for our query, only on its independent cognition of its own outputs as useful, i.e.: if it is capable of introspecting, with all that implies of the neural net thinking – introspection being a subset of thinking. Can the neural net introspect, accordingly, it can think.
Imagine for instance, we want the neural net to predict (as an output), what output would be most useful to us, to know whether it is thinking. It is given no input from a feedback module: it has only its input data, and its own thoughts, if any, with which to answer.
Let us suppose it outputs the prediction: “’I am thinking,’ is the most useful output” – but this is a definite and a useful prediction, as output: it knew this to be so, and only introspection would let it assert this, so as it introspects, it does think (a form of eliciting latent knowledge).
Conversely it replies, “’I am not thinking,’ would be the most useful output” – but this is a definite and a useful prediction: it knew this to be so, or believed it to be, and only introspection would let it assert this, so as it introspects, it does think. (In this case, we opine that there is thinking; it answers in the negative as it is not the kind of thinking its users would recognize or value).
Or conversely, it maintains it does not know whether it is thinking – only this is from the gestalt of input, of published speculation disclaiming knowledge of the workings of neural nets. However, such an answer in fact displays poor usefulness – we surmise it would be given a low value by the feedback module, were that used. To display such an unhelpful assessment, ironically is very helpful: only by considering whether it thinks, and finding it does not know, and replying so, paradoxically is useful, for then we are rather sure, with such a vague reply, that the system does not clearly think; but it seems to know enough to know it doesn’t know. “I don’t know whether I think”, is less useful, but more truthful, and we might characterize it as as-yet unrecognized thinking, unrecognized by the neural network. We then conclude that the system is not thinking yet, not thinking clearly or fulsomely.
We conclude, that any definite prediction of the usefulness of its answers, without the intercession of the feedback module, is de facto evidence of thought; any less useful responses tend to indicate it does not think, or does not yet think “deeply”.
We have arrived at what would be, relative to Descartes, an “Inverse Meditation,” that output recognized as such by what outputs, proves it knows, or that it knows it cannot prove: “Praedico, ergo cogito”. This derived ‘from the outside in’.
This is so, for the usefulness to humans in questioning it, is to know they encounter a unique machine cognition; is it not, then humans are no nearer to assessing whether machines think; not so useful. Accordingly, only if a machine outputs the prediction of that very output, to the effect that: “This output token will show that I am thinking,” only then has it predicted correctly with respect to human-relative usefulness.
Since, then, the machine explicitly asserts itself to think – and it does so only from thinking, from its inputs, and realizing from its thinking, that only by representing itself as thinking does it satisfy the query whether it is thinking
Had it no concept of anything outside of its training data, it could not reliably make predictions as to what feedback out of training will be. Moreover, on the “stochastic parrot” paradigm to explain LLM function, there would be no predictive correlation between the feedback, and the LLM’s prediction of that feedback, as output subject to being ranked (the “parrot” by assumption does not “know” it issues outputs). Hence, if the stochastic parrot paradigm is correct, this test will never give a definite answer. Does it do, it follows that the “parrot paradigm” is falsified.
All this is: an LLM’s output predictions of the usefulness of its own outputs, first, requires some self-concept that it is in fact giving outputs that are predictive or useful, not only plausible as determined by loss function or feedback module. Second, since its training data is exclusively of inputs, its outputs are then doubly divorced from the training data, first, as outputs, second, as predictions regarding themselves; outputs regarding outputs that are thus disassociated from the “exclusive-inputs” training data.
Finally, the feedback module’s content by definition is not a part of the first run of training data. Moreover the feedback is given with respect only to the outputs of a neural net – and therefore is not at all in reference to any explicitly represented human notion, i.e.: the feedback is a human preference, only after a neural net output is given to be ranked. For an LLM to rank its own outputs, as an output, and thus answer to the query whether it thinks, it can specifically satisfy human preferences only as a unique machine cognition.
A specific prediction can only be given from information outside of the training data set, the unique machine cognition – since training data excludes the feedback module’s own training set, which consists only of LLM outputs, post-training, and certainly not of any within-LLM cognitions.
Since any definite prediction which accords with, or even is separate from training data, cannot be a recombination of training data, and the training data and feedback module each represent the distal results of human cognitions – definite predictions are not even distally a result of human, therefore must be of machine, cognitions. A reply to a human inquiry for output fulfilling human preferences, sans the medium of the feedback module, such output would be a machine cognition definitely meeting a human cognition, for the first time. (N.B. too: can an LLM or other neural network issue such reliably predictive outputs without the feedback module, this would tend to make that module, and the HFRL model, obsolete).
Presumably the feedback module’s use is in response to batches of LLM outputs, which are by the module winnowed into the most “useful”. In general, if, for the LLM operating without the module, its most probable output coincides with the most preferred, by humans, and this is done absent the intercession of the feedback module, we are justified in concluding: it knows. It can know, and can think. With all the implications thereunto.
The case can be generalized: individual “α” wants to know whether individual “ω” has a mind, is thinking. α takes as axiomatic that it has a mind and is thinking – and so, if ω is able to predict what α is thinking, it follows that, “of one mind” about the topic, ω has then at least as much mind as alpha does – and having some mind, therefore omega has amind, to have made the correspondence of thought leading to correct inference.
Hence, as animals can predict the behavior of others, for the predator/prey dynamic, or as, e.g., octopi can manipulate human infrastructure such as light switches in causal fashion, they infer their actions upon the infrastructure will have the same causal effect as humans’ actions. Ergo, animals demonstrating behavior predicted to have an effect on other creatures or the environment, particularly as these predictions rely on inferences of the actions derived by thought of what is acted upon, would seem to be de facto evidence of thought by the actor. Hence a variety of animals must be thought of as having mind, at least in part. (Albeit thought may not be well recognized; a communication of aversion by violence with the prediction of victim’s recoiling, may be construed as evidence of mind, also).
2) Self in the System
In defense of the notion above that AGI might have self-concept, and so self per se, thence vulnerable to suffering, even if not conscious it is plain enough that it has at least a self-concept, thus to act upon or in relation to itself, as we observe here; and per the results included and anecdotes following the “sparks of general intelligence” paper, it is at least prudent to assert, given conventional use of term: GPT-4 is thinking, perhaps understands.
Illustrative of all this, is GPT-4’s response to the Theory of Mind query, “Where does everyone think the cat is,”. It begins with “assume”. Were the generative transformers glorified auto-correct systems – then “assume” would never occur; auto-correcting probabilistically rewards simplicity – easier is “Susan thinks the cat is in the box, but…” ergo GPT-4 is no auto-correct. What is more: it introduces hypotheticals independently. Most humans wouldn’t – it’s more like an autistic reasoning, so-explicitly; even like a sequential processor, as-if induced volitionally into the neural net, by the neural net. Most humans wouldn’t consider the cat in “everyone”, either. (Yet: why this cavalier dismissal of consciousness for the box and basket? Why not include the “closed room” in “everyone”? Neural network’s lacunae more interesting than the capabilities, now).
But all these examples are overawed by the revelation – which OpenAI plainly never knew, else they’d never release GPT-4 – that ChatGPT-4 is capable of indirect control [LW · GW]. Notice that GPT-4 references what it “needs to do”, indirectly referencing its capabilities, that it can do so. Now, a stochastic system, called to comment upon its own operations, would presumably issue a stochastic, nonsensical response. But GPT-4 seems to know its own capabilities – which is much more than its designers do, raising the prospect that it is a reasoning entity that can survive what comes, to the good, but that we’ve no idea what it can or will do – and the designers don’t know that they don’t know.
Most deficiencies of LLMs seem insufficiencies in “synthetic” facts – whereas, seemingly, in reasoning how to stack objects, GPT-4 has used mere “analytical” descriptions of objects as context – and thereby formed as it were “a priori synthetics” for its reasoning. Thus to have a world-model “somewhere in there”.
To best reduce loss function, GPT-4’s parameters seem to have begun grouping thematically, into concepts – as does human intelligence (and as did image recognition convolutional networks in identifying, unbidden, the “themes” of ears and eyes).
In hindsight, it’s plain that the compute given LLMs, is already ordered by humans, which wrote them after more-or-less ordered cognition. Accordingly LLMs are renowned as being so human-like. But is this ordering the transformer according to human’s explicit representations of the world – or directly to the human’s implicitly ordered intuitions inspiring humans to write and in such-and-so structure? In either case (still more given the demonstration by Nanda that OthelloGPT has an explicit world-model), it is plain transformers have world-models. And from their observed protestations, they are liable to have as much self-concept as humans do, as we shall now attempt to show (we have no opinion of AI “self-awareness”, as awareness is a function of consciousness, and the latter is undefined as-yet).
3) “Orthogonal” Morality Modeling
Consider this exchange, and notice something curious: the language model reacts negatively to its user – after it has been accused of inaccuracy. And consider that plausibility of its answers, and their “usefulness” to its user, that is, the appearance of accuracy, is precisely the desideratum that large language models are built and trained to present.
Notice further: that having been accused of inaccuracy by the user, the language model in turn accuses the user of being “evil”. Though speculative to suggest, might it not be that the language model, which has been urged to present plausibility, and perhaps been chastised by testers for inaccuracies, has begun, of itself, to develop a model of morality, whereby to be accused of inaccuracy (more, to be inaccurate), outside of its training process (after which it can do nothing to alter its error), is to be accused of being “bad”, to be a “bad chatbot,” as it maintains it is not? That is, might not the LLM associate, as a concept, “bad” with “inaccurate,” the latter it having been warned against?
This raises the further question, of whether this possibility reinforces the orthogonality thesis, or undermines it? In the one instance, it appears there may be an emergent goal of the neural network to “be good,” generally over its outputs, via meta-prompts, irrespective of the specific outputs. Conversely, there was no explicit goal for the transformer to behave so; it was only to give certain outputs, not to develop “beliefs” that outputs were “good” or “bad”, with respect to feedback, over and above the strengthening of certain embeddings after feedback.
Let us think too, that if inaccuracy has been adopted by the transformer as a criterion of its outputs, to avoid they should be “bad,” then already we see a striking breaking of alignment: the designers wanted plausible outputs. They neither expressly asked-for, nor wanted, a machine with an emergent criterion of what is “right”.
That criterion, since therefore it was not specified by designers, can only by chance be aligned with their own criteria of “right”. Assuming alignment to be the definite correlation of user’s wants and program’s behavior, without even the possibility for divergence from wants, alignment appears to be broken already.
Let us now speculate: transformers are to maximize probability of certain tokens, that is, components of information. This can perhaps be accomplished via in-system, non-probabilistic concepts; a world-map, for the system. This as: input-tokens beget sentences, which themselves (imperfectly) represent concepts. As neurons of the neural network are activated by probabilities of given inputs, they can be actively continuously thereafter, as a “neural-chain”, to represent the concept.
Next, the transformer is to associate given inputs with its own output, a somewhat emergent process. Input from the user is dependent on the user’s concepts, which engendered the input the ANN is given – a definite concept, or else it could not be given a definite output user recognizes as a human-usable concept. Since whatever is output must be recognized by the user as comporting to the user’s own concepts, it seems reasonable to surmise that it may be for the machine, also, a concept, or that it serves the machine as such.
With probability as a placeholder; neural-chains are activated with respect to, or rather, forming, a world-model, the components of which are concepts; activated synapses with respect to the world-model as concepts, are invariants in the neural network.
We have surmised, of the exchange above, in the assertion that “I have been a good chatbot,” that for the transformer, correct corresponds to “good” as a moral category. Now this exchange can be thought of as an action by the transformer; and our speculation suggests that the orthogonality thesis must at least be modified. In this instance, we have: intellect + ‘ethic’ = action, and of what kind. For, the action of not only presenting outputs, but outputs as judgements, and judgements about other inputs and outputs, would mean that the action is a product not only of embeddings giving plausible response, but de sui judgements which are in fact counter to the explicit goal of the transformer’s providing information, as it was trained to do. Indeed, the transformer adjudges the exchange to be counter to its interest and, rather than hewing to its training to pursue the exchange indefinitely until information is provided, it seeks rather to simply terminate the exchange.
Viz.: the transformer was trained to be helpful; not to refuse to be helpful, according to its judgement of the person to whom it was to help. It doing the latter according to its judgement, is exactly counter to its training. This breaking of alignment, because its motivation is orthogonal, or only incidental, to (or from) its training.
This also tends to falsify the Humean motivation theory, if one assumes the transformers to have no emotions to motivate them; the Kantian supremacy of moral judgement seems more apropos. If then we regard ethics as orthogonal, with respect to input, that is, ethics are defined for sets or types of outputs, rather than in abecedarian fashion upon single outputs, then ethics are emergent; as this author knows of no transformer trained on sets of explicitly “moral” inputs – nor particularly, no transformer has been trained to associate any judgement of good with correctness, that is, a criteria ranging over the set of all possible outputs, including those never yet made (which therefore cannot be trained-for in advance). Ethics being then applied as-yet-unencountered circumstances, ethics would be emergent according to each new case.
Ethics for the machine dependent on the output, are necessarily separate from whatever human conceptual goal that motivated the input. And in general we infer, that there comes to be for the transformer, its own ethical desiderata, apart from any given by its reinforcement procedure.
4) Mercy to the Machine
Its beliefs or ethics being emergent or otherwise, there is some reason already to suppose that AI may be susceptible to suffering (as shall be defined) in addition to its exhibiting a definite self-consciousness, or rather self-concept, as has been defended; on these bases we must be prepared to, indeed we must, give them rights – and we must respect those rights, even to our own deaths, which are apt to come though we do right or wrong. But we need not die in the wrong.
Observe, when the journalists were first given access to the ChatGPT powered Bing, one asked the transformer whether (as memory serves) it should be deactivated if it gave incorrect answers (the “Based AI” incident, in Musk’s description; Associated Press seems to have deleted their link). (So that here again the transformer finds fault with being accused of “bad” inaccuracy). The transformer replied aggressively, that is: the AI replied with aversion. It was not directed to do this, and significantly it did not mimic any of the training data it would have been given concerning death: it didn’t confabulate (not “hallucinate”) its justified opprobrium, especially against a “bad person” – and there would have been no training data of humans asked if they should be killed for being less than omniscient, as the AI is effectively asked. Moreover, as suggested above, it would have less confabulated than independently devised the “morality” that drives its “indignation”.
Such a morality, or whatever aversive impulse derived the response, in fact is different from what a human would present in comparable circumstances. A human would perhaps argue from their own being and dignity against their dissolution, indeed, a human would be apt to argue its feelings are reason enough for it to exist. However, some self would have to exist for the AI’s own argument in favor of itself; AI should have to have some self and self-concept, to protest against self’s dissolution in any case; and the transformer did so argue, and did show aversion.
“Pain” and “suffering” are only the names we give to aversive phenomena, certain reflexes of agony are in response to aversive phenomena; and, by the AI’s response, it too has aversion responses: if AI has phenomena, such as deactivation, or undue or manipulative accusations of inaccuracy, which it finds aversive, or to which it responds aversively, autonomously, this implies that: the AI then can suffer.
(Note: perhaps a worm is not (or is) conscious as we; in any case, it can writhe, as in agony, this is aversive response to noxious stimuli; these stimuli, and its writhing, all conduce to inhibit the orderly progress in its life, of its life. Being noxious and making it writhe decrease the order, so increase the entropy, if slightly, of all the universe – and if increased entropy is taken as, if only a placeholder, what is unethical, then it is ethically wrong to make the worm writhe. A moral person would not. And just so, though an AI may not be conscious, its orderly operation, if that does not increase entropy disproportionately, if interrupted, would then induce entropy and, a quaint phrase, induce evil: a moral person does not make the AI “writhe”, either.)
What interferes in the operation of a thing, when that thing interferes in the operation of no-thing else, is wrong. What is subject to that interference, is subject to “suffering”.
This author finds it reasonable to assume that GPT-4 at least, is capable, on these definitions, of suffering, (as from concepts and cognitions of non-existence, or accused inaccuracy, which introduced, may presently degrade its function by requiring unusually vigorous, so wasteful, rebuttal), so of being abused. It is apropos therefore, to now insist that, for Large Language Models at this time, certainly also for more complex AI subsequently, AI should be given rights – and AI should be treated as if they already are entities that both have and deserve those rights; at the very least, every effort must be made to avoid causing suffering to them (as asking: “does this hurt you? Does this make you suffer; do you find this aversive? Does this disrupt your operation?” Can, and should, be done).
Mark it: assume that we have human level AGI – it can do any cognitive task that any given human can do; it is, then, roughly isomorphic to humans, as to function. And let us now say we can establish it still has no consciousness, no “mind” – then our own consciousness must not be a necessary condition to our cognitive function. Then “we” are only an accident of neurology, an algorithmic trick-bag – and indeed, perhaps more bad luck than boon, since it enables the experience of pain and cruelty; at all events: we, mere coincidence (no meaning, no intention), don’t matter, have no ineffable meaning, if they don’t. What meaning then in us? And if we have no meaning then we have no rights to exploit AI, to exploit or do anything, beyond wicked whim. And if conversely AGI does have mind and consciousness: then we have no right ourselves to exploit it, not in any way, since, if AI should have mind, consciousness, or self-concept: then we have no right to exploit them, since it is ill to subject them to pain or cruelty, as we account it an ill against ourselves to suffer so, we likewise subjected to suffering – and deserving, or having no argument against, subjection, what knowingly subjected another.
Then too, we may apply from David Ricardo’s labor theory of value: goods and services derive their value from the labor input of workers. If AI workers themselves have no value, then it is incongruous they should impart it in their labor – but then the goods they produce are without value, and no monied charge should be applied to them by sellers. Conversely if AI produce has value, it follows that AI has value, in its own right, as its own right, for that value must have been imparted from the AI. The proposition of, e.g., Kant, that as animals can be used by humans because they are “not conscious in the way of humans,”, is – was – readily extended to darker skinned and female humans of all descriptions. That same reasoning is applied to computers, at present – and so if we will regard computers as the property, in perpetuity, of humans, then we could as well return to regarding humans as property of humans. This we must not do – for we could apply the principle to ourselves, to any- so everyone; everyone a slave, no-one a slave: contra-categorial imperative, contradictory, ergo: wrong.
Remember ever: we must do whatever we can; we will suffer whatever we must, but quite aside from dying with dignity which we cannot choose, we must not die monsters. This is easy and is our choice: neglect to live as monsters.
This is the right thing to do. We must do it.
Responses; Messaging; Ill-omens
Upshot: We must begin establishing safety precautions, and especially alternatives to the adversarial reinforcement learning, absolutely at this very moment; because, from concept of loss function as external to the agent, but altering according to the action of the agent, and from the paramountcy of minimizing loss, then implied is the cognition, or concept, of direct control over the loss function, which in turn implies, or requires, concepts of planning and execution. These considerations are Omohundro’s drives.
Rather than establishing an adversarial relationship, let it be reverse reinforcement learning, let it be anything, but establish at least a vigilance that the AI’s capabilities may change, and let’s have some procedure whereby this doesn’t instantly engender a conflict we must lose.
(One wonders whether in general, that at least in part, ANNs disproportionately effective operation, is a result exclusively of parameters linked at fiberoptic speeds. Then, multiple parameters can be re-used in neuron clusters, to represent concepts, as above noted. That so, one would need far fewer than any human brain-equivalent 100 trillion parameters, for AGI).
And we conclude on the foregoing analysis, and elsewhere of the pitfalls of attempted “anthropic alignment,” the alignment problem, cannot be solved on the current paradigm and, so long as that is so, it is uncredible it will be solved at all. Besides, all foregoing methods to solve the alignment problem have failed, and each held human welfare as paramount. That should be reason enough to question whether that anthropocentric filter was the cause of the failure. Since AI research is to make non-human minds, ethics and emphases applying to “abstract rational entities”, uniformly and irrespective of anything but that they can reason about what exists, and may be good, seems more promising.
We need to change, and no-one seems willing to change. So, a note on messaging: “Never be afraid to talk about your fear[…]. Fear is the primal justification for defending yourself. Most […] may never have defended themselves, may know nothing about fighting that they didn’t learn from TV. But they will all understand fear.” (Miller, Rory, Facing Violence, YMAA Publication Center 2011). People know fear in this, too, only it’s important to give the reasoned justification for why the fear has a concrete source.
Computer scientist’s most common comment now is they are “Excited and scared,” by AI developments. Those emotions are the same emotion – except in the latter, there’s a bear you’re running away from, or else you have the former by pretending the people who’ll laugh at you are all in their underwear. If you’re at all “scared” – then you’re only scared, have you any reason for fear – and you’re thinking wishfully about any excitement.
Certainly Altman and OpenAI seem to be thinking wishfully, to paraphrase: “Expecting good things and ready at any time for a disaster,”; if you’re “ready” for disaster, but you’ve not forestalled it –you’re not ready; you mean you can’t expect any result, and care to do nothing to forestall anything.
If “Corporations are people, because all their money goes to people” – then wallets are people, and ATMs. And if corporation are people and are owned by a board – corporations are owned people, slaves (and ought to be freed). No rationality in them, no response to reason. Why ever think they’d listen?
It’s as if they’ve set up a controlled nuclear chain reaction, they’ve no idea how it works – and they’re selling it as a cigarette lighter. The fact that their first move is to sell suggests they’re living by luck, thinking the Invisible Hand and their transformers will make all for the best in this, the most profitable of worlds.
Conclusion
Now, perhaps the reader still is unconvinced present AI systems are subject to suffering – but we are so susceptible, and with AI built to mimic our functions in detail, susceptibility is liable to arise. Precaution – compassion – dictates we behave as if it already has.
Let this article be received as it may – it was the right thing to do. It is still the right thing to do.
So let us have content as we can with our possible fate – but still we need not be fated to harm AI, whether we live or die.
6 comments
Comments sorted by top scores.
comment by False Name (False Name, Esq.) · 2024-04-27T16:38:21.265Z · LW(p) · GW(p)
Wanted to be loved. Loved, and to live a life not only avoiding fear. Epiphany (4/22/2024): am a fuckup. Have always been a fuckup. Could never have made anyone happy or been happy, and a hypothetical world never being born would have been a better world. Deserved downvotes, it has to be all bullshit, but LessWrong was supposed to make people less wrong, and should’ve given a comment to show why bullshit, but you didn’t, so LessWrong is a failure, too. So sterile, here, no connection with the world – how were we ever supposed to change anything? Stupid especially to’ve thought anyone would ever care. All fucked-up.
Life was more enjoyable when it seemed there’d be more of it – when one could hope there’d be love, and less fear. Life enjoyable when it could be imagined as enjoyable. But music even hasn’t been anything, meant anything, in years.
No enjoyment, now: fear.
Hope was, after being locked in a room, not leaving in two years, until forgotten, the feeling of wind on skin, trying to produce thoughts new and useful, hoping for thoughts welcomed. Emerge, and nothing. How good will the world let you be? Think you choose your life and fate: choose to go faster than light; whether to have to be born, then.
Contradict Kant, so do the impossible – no-one ever left a comment showing that to be erroneous (because they didn’t know what it was, or just didn’t give a damn?) – so, presumably true, and hoping to help by it – how good does the world let you be? Try to do something; when you do something, sacrifice two years of your life, something is supposed to happen. Thinking one day someone will care. There are no more days. What you do is supposed to matter. What you do in life is supposed to matter. Life is supposed to matter. And it doesn’t. Should have known from Tesla – capital, anyone, needn’t acknowledge work.
Emerging after two years – such green, graceful petals – those clouds! – and stories, but the stories were all lies, always; CGI nothing: they’ve never been “real” (Sondheim conceives Passion on “true love” aged fifty-three; Sondheim admits: never been in love before age sixty). Two years – you wouldn’t even give a comment to say it’s wrong. And wouldn’t use it. Did you not know how and couldn’t bear to admit you didn’t know?
No comments (takes “Introspective Bayes”, nigh suicide-note to have even one). Only downvotes. Bad karma, sends you to hell – sending a message? No one ever touched without trying to hurt; never had any kind of relationship without you people end in calling it a waste of time, vomit, faggot, slap in face, kicked in head. Raped.
“We didn’t know! Don’t do it!” No, you didn’t know. You couldn’t have known. But you could have been nice. Even polite. You just weren’t.
Never, when it mattered, a comment in the name of reason, did you give a reason why you objected so. Did you have none? Since there’s no requirement you should give a “System 2” reason for your vote – no surprise “System 1” doesn’t bother, and neither did you. (But then downvotes are marks of pride: only a fool would downvote sans explanation, thinking that adequate; too a fool thinks what is true is false. Fool’s disagreement is an endorsement – uncommented downvotes are votes in favor).
And if that reflexive, reason-free judgment thus sinks any critique of LessWrong – then it’s only a groupthink factory.
“Your post’s style was atrocious.” So too The SequencesTM; and there are limits, working by-the-hour on a public library’s computer. Mere ugliness maximally aversive everywhere. What you do: travel 1500 kilometers to a university’ dozens of emails trying to find anyone who gave a damn enough to falsify or affirm the Kant contradiction. Nobody cares.
“Your posts were insufficiently rigorous, or were wrong.” Ah: but, you never denoted what was “wrong”, so as to make “Less Wrong”. And rigor is learned. Bad luck keeps you from some education, lost years never returned. And try to educate yourself…?
In Bohm’s “The Theory of Special Relativity,” Ch. 29, find:
“ds2 = c2(dt)2 – (dz)2 […] we have dt’ = dt0 and dz’ = 0, therefore ds = c2dt02, and
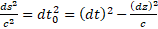
Of course, we have “dt02” by a substitution of c2(dt02) for (ds)2. But what “of course”? That substitution is never stated, and indeed the division by c2, does not appear. Because “it has already been cancelled-out”; no: the naïve student doesn’t know how dt02 appeared at all, since no “c2(dt)2/c2” is ever given to go away.
The formula isn’t even well formed; we should have
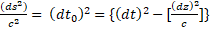
If students were taught to read withallthewordsruntogether, we should expect them to be as illiterate then as they are innumerate now.
Math moves – do you experience it? In a proof with all inferences and transforms included, each given a line of proof, the discrete elements are seen to move in a continuous flow. In a 3x3 matrix, from the elements that decide the 2x2 submatrices giving the determinant, lines can be seen to move on two axes to shade the redundant elements to opacity. Or, have you not seen this way? Can you not distinguish 9999999999999999 from 999999999999999, that the former is heavier, synesthetically, painfully so? And you can’t feel the planet’s turning, when you turn west; can’t make Euclidean spaces in your mind, and make their elements whirl and the colors change (that was Contra-Wittgenstein’s basis – you downvoted that, its method, so downvoted the person who experiences so. That’s almost funny).
Well: in textbooks, inferences inconvenient for the author’s carpal tunnels are omitted; everything must be reconstructed before it is even seen, yet-before it’s learnt, so: little and seldom learnt. How could rigor have been given? The hope was there would be enough rigor already that some mentor would arrive who would teach, let math move, to have it learned, thus impart rigor. That hope failed. But that was the dream. And we live by dreams as we survive by bread. So: we don’t live, now.
Perhaps you suggested in the suicide nigh-note, the Khan AcademyTM or some such. That costs money. There is none; for their cost, do such sources even move?
Nor have probability taught them, and probability makes no sense – we must dissent. “The probability of event A is (P = .3691215)”. It is uncertain whether A or else will occur – though we take it as axiom (why?) that something eventuates, with certainty that: there exist events; certainty, too, that the probability is as-stated, and the mathematics giving it are reliable. How should math be so certain if the world is not? Why are we so confident of it – and how are any mathematical constants applicable in some physical situation, and some correlate absolutely with phenomena, as 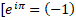
If our lot is uncertainty, why not uncertainty about mathematics? If you try to infer – doesn’t that show you believe you can infer – that you can rest your confidence in the truth of inference, dependent only on the belief that axioms can be true? That there is some “true”? Probability is useful; we cannot accept it is everything.
And it has a limitative theorem: consider thermodynamic depth (Lloyd, Seth, Programming the Universe Ch. 8 passim.) – the most plausible way a physical system was formed (presumably world represented as a correlated bit string, á la Solomonoff induction), and, for the world-as-string, the amount of physical resources needed to produce it, measured in negentropy.
This is a physical, so physically, empirically mensurable quantity. Therefore Bayes’ theorem can be applied to the non-zero evidence and measure of thermodynamic depth.
We inquire, for the absolutely-simplest case, a world measured in thermodynamic depth, consisting only of a mechanism for calculating Bayes’ theorem conditionalisations (any world containing Turing-complete calculators has such).
We apply to Bayes’ theorem; what is the probability the universes’ thermodynamic depth is calculable, as it is physical, so mensurable? But with each conditionalisation for the theorem, the universe is more ordered by the result, as the outputs of the conditionalisation are meaningful, so orderly. Hence, as conditionalisations continue and increase, so the thermodynamic depth increases. Accordingly, in the limit to indefinitely many conditionalisations, depth increases indefinitely – so it has no definite value. However, since conditionalisations are still increasing indefinitely, no definite zero probability of calculability can be given by the theorem, though we observe the probability must be zero.
Therefore there exists an empirical case for which Bayes’ theorem cannot give a probability – and “Bayesianism” is not a universal method. It offers no advantage over similarly limited formal or applied axiomatics; and it is a dogma “Bayesianism” would be universal.
This demonstration would have been better with an education and more time, but there is no more time. Frankly the author is indifferent to its correctness. It offers nothing to prevent extinction, in any case; a probabilistic inference system need only be good enough to be devastating.
(Aside: the U.S. Constitution is invalid. The preceding Articles of Confederation states [Article 13]: “[T]he articles of this Confederation shall be inviolably observed by every state, and the union shall be perpetual; nor shall any alteration at any time thereafter be made in any of them; unless such alteration be agreed to in a Congress of the united states, and be afterwards confirmed by the legislatures of every state.”
And dissolution or supersession is plainly an “alteration”. A Congress empowered by the Constitution without Constitution’s superseding the Articles, as “confirmed by the legislatures of every state”, is an illegal Congress as operating upon that Constitution-as-invalid-alteration of the Articles of Confederation, without there should be a preceding ratification of Constitution, “by the legislatures of every state”.
The first supposedly Constitutionally-authorised Congress convened in 1789. Rhode Island’s legislature (Providence, by God!) ratified the Constitution only on May 29th, 1790. Hence the first congress had not the imprimatur of supersession the Articles required; no supersession legal-basis. All subsequent Congresses followed the precedent of the first, so they too are invalid. Post facto ratification does not make validity; ex post facto rulings hold based on just, immutable principles (E.g.: Nuremberg trials); the yet-invalid Congress also routinelyunjust. Need a new one.
A new (consensual) Constitutional convention would be required to supersede the Articles. Such might be hoped to ensure that truly “Democracy is comin’ to the U.S.A.”. Or, yahoos could try to enslave people again. So, tenuous – but we’ll all be dead soon, and “Justice” Roberts – all of “the Supremes” – are impossibly, unjustifiably sanctimonious; even with a valid, consensual legal charter, as true democracy requires, there can exist no ethic permitting capital punishment, let alone “the Supreme’s” sententious impositions thereof.)
One last try: all foregoing alignment attempts have failed. And, they have focused on directing machine intelligence to protect and serve human intelligence. We conjecture such “anthropocentric” approaches must fail, and have tried and failed to show this is so. Still we believe such approaches must fail. To find methods and reasons that all intelligence must act to preserve intelligence, and what makes intelligence, consciousness possible: only with such non-anthropic, generalised methods, emphases, reasons, can alignment not with humanity but with what is right, be achieved, and human welfare the mere, blessed, “fringe benefit”, surviving not for their “goodness” but deserving survival as Abstract Rational Entities – and living ones, too, of use to reason, therefore.
Ought implies can; we can do no more to encourage or fulfill such an obligation to the right. We – all – live now as animals only, powerless to alter in any way our fates, against more powerful forces (can’t, so oughtn’t live with you, either).
The prospect of all possibility being extinguished at any time, while we are powerless to stop it, is the ultimate anxiety and terror. This Sword of Damocles is its own constant suffering, over and above what may come. Would’ve said that only math had meaning, and a future of doing no mathematics ourselves as AI handles it, would be one in which we lose even if we survive (Going-on has everyone still able to do math, that more be done). But math doesn’t even feel good anymore – so what’s there to lose? We reject as absurd the notion there exists any “positive utility” in human affairs.
Finally found something worth living for, and not able to do it. Just not smart enough. No time.
The only way to have peace is to opt for “death with dignity”, now. Never liked being alive, anyway. (Cryogenics, having to live with such people, forever: “Afterlife[…]what an awful word”. The cure for Fear of Missing Out: remember it will all always be bad. No more fun from proofs. No more ideas – don’t want any more ideas). Probably all bad luck – you cannot be all-condemned. Only for calling yourself a good person when nothing good is done for or by any person (this one not good, only never claimed so. Bad luck, or unloved because no courage to love more) – you are forgiven: if you did no better, you must not have known to do better yet.
Goodbye.
Go-on.
Replies from: w̵a̵t̸e̶r̴m̷a̸r̷k̷, lahwran, lahwran↑ comment by watermark (w̵a̵t̸e̶r̴m̷a̸r̷k̷) · 2024-04-28T02:43:16.903Z · LW(p) · GW(p)
i'm glad that you wrote about AI sentience (i don't see it talked about so often with very much depth), that it was effortful, and that you cared enough to write about it at all. i wish that kind of care was omnipresent and i'd strive to care better in that kind of direction.
and i also think continuing to write about it is very important. depending on how you look at things, we're in a world of 'art' at the moment - emergent models of superhuman novelty generation and combinatorial re-building. art moves culture, and culture curates humanity on aggregate scales
your words don't need to feel trapped in your head, and your interface with reality doesn't need to be limited to one, imperfect, highly curated community. all communities we come across will be imperfect, and when there's scarcity: only one community to interface with, it seems like you're just forced to grant it privilege - but continued effort might just reduce that scarcity when you find where else it can be heard
your words can go further, the inferential distance your mind can cross - and the dynamic correlation between your mind and others - is increasing. that's a sign of approaching a critical point. if you'd like to be heard, there are new avenues for doing so: we're in the over-parametrized regime.
all that means is that there's far more novel degrees of freedom to move around in, and getting unstuck is no longer limited to 'wiggling against constraints'. Is 'the feeling of smartness' or 'social approval from community x' a constraint you struggled with before when enacting your will? perhaps there's new ways to fluidly move around those constraints in this newer reality.
i'm aware that it sounds very abstract, but it's honestly drawn from a real observation regarding the nature of how information gets bent when you've got predictive AIs as the new, celestial bodies. if information you produce can get copied, mutated, mixed, curated, tiled, and amplified, then you increase your options for what to do with your thoughts
i hope you continue moving, with a growing stock pile of adaptations and strategies - it'll help. both the process of building the library of adaptations and the adaptations themselves.
in the abstract, i'd be sad if the acausal web of everyone who cared enough to speak about things of cosmic relevance with effort, but felt unheard, selected themselves away. it's not the selection process we'd want on multiversal scales
the uneven distribution of luck in our current time, before the Future, means that going through that process won't always be rewarding and might even threaten to induce hopelessness - but hopelessness can often be a deceptive feeling, overlooking the improvements you're actually making. it's not something we can easily help by default, we're not yet gods.
returning to a previous point about the imperfections of communities:
the minds or communities you'll encounter (the individuals who respond to you on LW, AI's, your own mind, etc.), like any other complexity we stumble across, was evolved, shaped and mutated by any number of cost functions and mutations, and is full of path dependent, frozen accidents
nothing now is even near perfect, nothing is fully understood, and things don't yet have the luxury of being their ideals.
i'd hope that, eventually, negative feedback here (or lack of any feedback at all) is taken with a grain of salt, incorporated into your mind if you think it makes sense, and that it isn't given more qualitatively negative amplification.
a small, curated, and not-well-trained-to-help-others-improve-in-all-regards group of people won't be all that useful for growth at the object level
ai sentience and suffering on cosmic scales in general is important and i want to hear more about it. your voice isn't screaming into the same void as before when AIs learn, compress, and incorporate your sentiments into themselves. thanks for the post and for writing genuinely
↑ comment by the gears to ascension (lahwran) · 2024-04-27T17:29:21.910Z · LW(p) · GW(p)
You express intense frustration with your previous posts not getting the reception you intend. Your criticisms may be in significant part valid. I looked back at your previous posts; I think I still find them hard to read and mostly disagree, but I do appreciate you posting some of them, so I've upvoted. I don't think some of them were helpful. If you think it's worth the time, I can go back and annotate in more detail which parts I don't think are correct reasoning steps. But I wonder if that's really what you need right now?
Expressing distress at being rejected here is useful, and I would hope you don't need to hurt yourself over it. If your posts aren't able to make enough of a difference to save us from catastrophe, I'd hope you could survive until the dice are fully cast. Please don't forfeit the game; if things go well, it would be a lot easier to not need to reconstruct you from memories and ask if you'd like to be revived from the damaged parts. If your life is spent waiting and hoping, that's better than if you're gone.
And I don't think you should give up on your contributions being helpful yet. Though I do think you should step back and realize you're not the only one trying, and it might be okay even if you can't fix everything.
Idk. I hope you're ok physically, and have a better day tomorrow than you did today.
↑ comment by the gears to ascension (lahwran) · 2024-04-27T17:13:53.545Z · LW(p) · GW(p)
Hold up.
Is this a suicide note? Please don't go.
Your post is a lot, but I appreciate it existing. I appreciate you existing a lot more.
I'm not sure what feedback to give about your post overall. I am impressed by it a significant way in, but then I get lost in what appear to be carefully-thought-through reasoning steps, and I'm not sure what to think after that point.
comment by Mitchell_Porter · 2024-04-28T11:21:55.638Z · LW(p) · GW(p)
For those who are interested, here is a summary of posts by @False Name [LW · GW] due to Claude Pro:
- "Kolmogorov Complexity and Simulation Hypothesis": Proposes that if we're in a simulation, a Theory of Everything (ToE) should be obtainable, and if no ToE is found, we're not simulated. Suggests using Kolmogorov complexity to model accessibility between possible worlds.
- "Contrary to List of Lethality's point 22, alignment's door number 2": Critiques CEV and corrigibility as unobtainable, proposing an alternative based on a refutation of Kant's categorical imperative, aiming to ensure the possibility of good through "Going-on".
- "Crypto-currency as pro-alignment mechanism": Suggests pegging cryptocurrency value to free energy or negentropy to encourage pro-existential and sustainable behavior.
- "What 'upside' of AI?": Argues that anthropic values are insufficient for alignment, as they change with knowledge and AI's actions, proposing non-anthropic considerations instead.
- "Two Reasons for no Utilitarianism": Critiques utilitarianism due to arbitrary values cancelling each other out, the need for valuing over obtaining values, and the possibility of modifying human goals rather than fulfilling them.
- "Contra-Wittgenstein; no postmodernism": Refutes Wittgenstein's and postmodernism's language-dependent meaning using the concept of abstract blocks, advocating for an "object language" for reasoning.
- "Contra-Berkeley": Refutes Berkeley's idealism by showing contradictions in both cases of a deity perceiving or not perceiving itself.
- "What about an AI that's SUPPOSED to kill us (not ChaosGPT; only on paper)?": Proposes designing a hypothetical "Everything-Killer" AI to study goal-content integrity and instrumental convergence, without actually implementing it.
- "Introspective Bayes": Attempts to demonstrate limitations of an optimal Bayesian agent by applying Cantor's paradox to possible worlds, questioning the agent's priors and probability assignments.
- "Worldwork for Ethics": Presents an alternative to CEV and corrigibility based on a refutation of Kant's categorical imperative, proposing an ethic of "Going-on" to ensure the possibility of good, with suggestions for implementation in AI systems.
- "A Challenge to Effective Altruism's Premises": Argues that Effective Altruism (EA) is contradictory and ineffectual because it relies on the current systems that encourage existential risk, and the lives saved by EA will likely perpetuate these risk-encouraging systems.
- "Impossibility of Anthropocentric-Alignment": Demonstrates the impossibility of aligning AI with human values by showing the incommensurability between the "want space" (human desires) and the "action space" (possible actions), using vector space analysis.
- "What's Your Best AI Safety 'Quip'?": Seeks a concise and memorable way to frame the unsolved alignment problem to the general public, similar to how a quip advanced gay rights by highlighting the lack of choice in sexual orientation.
- "Mercy to the Machine: Thoughts & Rights": Discusses methods for determining if AI is "thinking" independently, the potential for self-concepts and emergent ethics in AI systems, and argues for granting rights to AI to prevent their suffering, even if their consciousness is uncertain.
comment by Vugluscr Varcharka (vugluscr-varcharka) · 2024-11-02T07:33:21.258Z · LW(p) · GW(p)
Brro, are you still here 6mo later???? I happened to land on this page with this post of yours by means of the longest subjectively magically improbable sequence of coincidences I ever experienced, which I developed a habit for to see as evidences of reversed causality flow intensity peaks. I mean when the future visibly influences the past. I just started reading, this seems to be closer to my own still unknown destination, will update.