Posts
Comments
I think it should be a safety priority.
Currently, I'm attempting to make a modularized snapshot of end-to-end research related to alignment (covering code, math, a number of related subjects, diagrams, and answering Q/As) to create custom data, intended to be useful to future me (and other alignment researchers). If more alignment researchers did this, it'd be nice. And if they iterated on how to do it better.
For example, it'd be useful if your 'custom data version of you' broke the fourth wall often and was very willing to assist and over-explain things.
I'm considering going on Lecture-Walks with friends and my voice recorder to world-model dump/explain content so I can capture the authentic [curious questions < - > lucid responses] process
Another thing: It's not that costly to do so - writing about what you're researching is already normal, and making an additional effort to be more explicit/lucid/capture your research tastes (and its evolution) seems helpful
i'm glad that you wrote about AI sentience (i don't see it talked about so often with very much depth), that it was effortful, and that you cared enough to write about it at all. i wish that kind of care was omnipresent and i'd strive to care better in that kind of direction.
and i also think continuing to write about it is very important. depending on how you look at things, we're in a world of 'art' at the moment - emergent models of superhuman novelty generation and combinatorial re-building. art moves culture, and culture curates humanity on aggregate scales
your words don't need to feel trapped in your head, and your interface with reality doesn't need to be limited to one, imperfect, highly curated community. all communities we come across will be imperfect, and when there's scarcity: only one community to interface with, it seems like you're just forced to grant it privilege - but continued effort might just reduce that scarcity when you find where else it can be heard
your words can go further, the inferential distance your mind can cross - and the dynamic correlation between your mind and others - is increasing. that's a sign of approaching a critical point. if you'd like to be heard, there are new avenues for doing so: we're in the over-parametrized regime.
all that means is that there's far more novel degrees of freedom to move around in, and getting unstuck is no longer limited to 'wiggling against constraints'. Is 'the feeling of smartness' or 'social approval from community x' a constraint you struggled with before when enacting your will? perhaps there's new ways to fluidly move around those constraints in this newer reality.
i'm aware that it sounds very abstract, but it's honestly drawn from a real observation regarding the nature of how information gets bent when you've got predictive AIs as the new, celestial bodies. if information you produce can get copied, mutated, mixed, curated, tiled, and amplified, then you increase your options for what to do with your thoughts
i hope you continue moving, with a growing stock pile of adaptations and strategies - it'll help. both the process of building the library of adaptations and the adaptations themselves.
in the abstract, i'd be sad if the acausal web of everyone who cared enough to speak about things of cosmic relevance with effort, but felt unheard, selected themselves away. it's not the selection process we'd want on multiversal scales
the uneven distribution of luck in our current time, before the Future, means that going through that process won't always be rewarding and might even threaten to induce hopelessness - but hopelessness can often be a deceptive feeling, overlooking the improvements you're actually making. it's not something we can easily help by default, we're not yet gods.
returning to a previous point about the imperfections of communities:
the minds or communities you'll encounter (the individuals who respond to you on LW, AI's, your own mind, etc.), like any other complexity we stumble across, was evolved, shaped and mutated by any number of cost functions and mutations, and is full of path dependent, frozen accidents
nothing now is even near perfect, nothing is fully understood, and things don't yet have the luxury of being their ideals.
i'd hope that, eventually, negative feedback here (or lack of any feedback at all) is taken with a grain of salt, incorporated into your mind if you think it makes sense, and that it isn't given more qualitatively negative amplification.
a small, curated, and not-well-trained-to-help-others-improve-in-all-regards group of people won't be all that useful for growth at the object level
ai sentience and suffering on cosmic scales in general is important and i want to hear more about it. your voice isn't screaming into the same void as before when AIs learn, compress, and incorporate your sentiments into themselves. thanks for the post and for writing genuinely
Deep learning/AI was historically bottlenecked by things like
(1) anti-hype (when single layer MLPs couldn't do XOR and ~everyone just sort of gave up collectively)
(2) lack of huge amounts of data/ability to scale
I think complexity science is in an analogous position. In its case, the 'anti-hype' is probably from a few people (probably physicists?) saying emergence or the edge of chaos is woo and everyone rolling with it resulting in the field becoming inert. Likewise, its version of 'lack of data' is that techniques like agent based modeling were studied using tools like NetLogo which are extremely simple. But we have deep learning now, and that bottleneck is lifted. It's maybe a matter of time before more people realize you can revisit the phase space of techniques like that with new tools.
As a quick example: John Holland made a distilled model of complex systems called "Echo" which he described in Hidden Order and if you download NetLogo you can run it yourself. It's a bit cute, actually - here's an image of it:
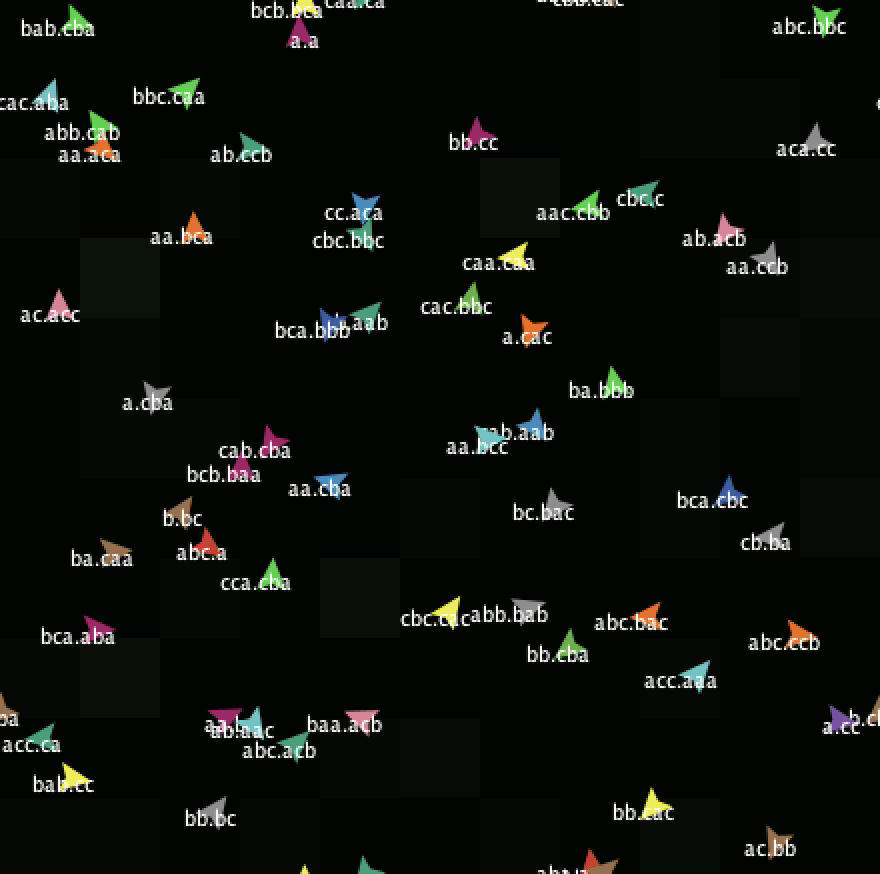
But anyway, the point is that this is the best people could do at the time - there was an acknowledgement that some systems cannot be understood analytically in tractable ways, and predicting/controlling them would benefit from algorithmic approaches. So? An attempt was made to do it by making these hard-coded rules for agents. But now that we have deep learning, we can make beefed up artificial ecologies of our own to empirically study the external dynamics of systems. Though it still demands theoretical advancements (like figuring out the parameterized, generalized forms of physics equations and fitting them to empirical data to then model that system with deep learning ecologies).
If people find that the methods/ideas are lacking, they might be exploring the field in a suboptimal way/not investigating thoroughly. One thing I do is try to make some initial attempt to define things myself the best I can (e.g. try to formalize/locate the sharp left turn, edge of chaos, emergence, etc. and what it'd take to understand it) which adjusts my attention mechanism for looking for research, which lets me find niche content that's surprisingly relevant (in my opinion). If you come at the field with far too much skepticism, you're almost making yourself unnecessarily blind.
The difference between doing this and not might be substantial: if you don't, you might take a look at the surface level of the field and just see hand-wavey attempts at connecting a bunch of disparate things - but if you do, you might notice that 'robust delegation', 'modularity', 'abstractions', 'embedded agency', etc. have undergone investigations from a number of angles already, and find public alignment research almost boring, not-even-wrong, or framed/approached in unprincipled ways in comparison (which I don't blame them for - there's something very anti-memetic about studying the hard parts of alignment theory leaving the field impoverished of size and diversity).
Yeah, I'd be happy to.
I'm working on a post for it as well + hope to make it so others can try experiments of their own - but I can DM you.
I'm not expecting to pull off all three, exactly - I'm hoping that as I go on, it becomes legible enough for 'nature to take care of itself' (other people start exploring the questions as well because it's become more tractable (meta note: wanting to learn how to have nature take care of itself is a very complexity scientist thing to want)) or that I find a better question to answer.
For the first one, I'm currently making a suite of long-running games/tasks to generate streams of data from LLMs (and some other kinds of algorithms too, like basic RL and genetic algorithms eventually) and am running some techniques borrowed from financial analysis and signal processing (etc) on them because of some intuitions built from experience with models as well as what other nearby fields do
Maybe too idealistic, but I'm hoping to find signs of critical dynamics in models during certain kinds of tasks and I'd also like to observe some models with more memory dominate other models (in terms of which model diverges more from its start state to the other model's) etc. - Anthropic's power laws for scaling are sort of unsurprising, in a certain sense, if you know how ubiquitous some kinds of relationships are given some kinds of underlying dynamics (e.g. minimizing cost dynamics)
I didn't personally go about it in the most principled way, but:
1. locate the smartest minds in the field or tangential to it (surely you know of Friston and Levin, and you mentioned Krakauer - there's a handful more. I just had a sticky note of people I collected)
2. locate a few of the seminal papers in the field, the journals (e.g. entropy)
3. based on your tastes, skim podcasts like Santa Fe's or Sean Carroll's
4. textbooks (e.g. that theory of cas book you mentioned (chapter 6 on info theory for cas seemed like the most important if i had to pick one), multilayer networks theory, statistical field theory (for neural networks, etc.)) - I personally also save books which seem a bit distanced from alignment (e.g. theoretical ecology/metabolic theory of ecology) just out of curiosity to see how they think/what questions they wind up asking
Of these, I think getting a feel for the repeats in the unsolved problems/vocabulary/concepts that show up in journals is important, and pretty much anything related to "what does it take to unify information and physics, and extend information theory to talk about open-systems, and how do we get there asap" seems good bc of how foundational all that is.
Here are some resources:
1. The journal entropy (this specifically links to a paper co-authored by D. Wolpert, the guy who helped come up with the No Free Lunch Theorem)
2. John Holland's books or papers (though probably outdated and he's just one of the first people looking into complexity as a science - you can always start at the origin and let your tastes guide you from there)
3. Introduction to the Theory of Complex Systems and Applying the Free-Energy Principle to Complex Adaptive Systems (one of the sections talks about something an awful lot like embedded agency in a lot more detail)
4. The Energetics of Computing in Life and Machines
And I'm guessing non-stationary information theory, statistical field theory, active inference/free energy principle, constructor theory (or something like it), random matrix theory, information geometry, tropical geometry, and optimal transport are all also good to look into, as well as adjacent fields based on your instinct. That's not intended to be covering the space elegantly, just a battery of things in the associative web near what might be good to look into. Combinatorics, topology, fractals and fields are where it's at.
I have more resources/thoughts on this but I'll leave it at that for now unless someone's interested. The best resource is the will to understand and the audacity to think you can, of course
I forgive the ambiguity in definitions because:
1. they're dealing with frontier scientific problems and are thus still trying to hone in on what the right questions/methods even are to study a set of intuitively similar phenomena
2. it's more productive to focus on how much optimization is going into advancing the field (money, minds, time, etc.) and where the field as a whole intends to go: understanding systems at least as difficult to model as minds, in a way that's general enough to apply to cities, the immune system, etc.
I'd be surprised if they didn't run into some of the same theoretical problems involved in solving alignment. (I wouldn't be very surprised if complexity scientists make more progress on alignment than existing alignment researchers. It's hard to bet against institutions of interdisciplinary scientists in close communication with one another already applying empirical work and exploring where the information theorists and physicists of the previous century left off to study life and minds).
That being said, John Holland (one of the pioneers of complexity science, invented genetic algorithms) has written several books on the subject and has made attempts to lay some groundwork for how the field should be studied.
I think he'd probably say complex adaptive systems are an updating interaction network of 'agents' with world models trying to lower some kind of fitness function (huge oversimplification of course). He'd probably also emphasize the combinatorial nature of adaptation: structures (schemata ~ abstractions ~ innovations) can be found via mutation-like processes, assembled, tiled, and disassembled.
So we've got the textbook you mentioned which talks about co-evolving multilayer networks, Holland's adapting network of agents, and Krakauer's 'teleonomic matter' description. People might toss in other properties like diversity of entities, flows and cycles of some kind of resource (money, energy, etc), 'emergence', self-organization, etc.
I think those seem fine. I'd probably say that complex systems is something like the academic-child of frontier information theory and physics which focuses on the counterfactual evolutions of non-stationary information flows (infodynamics) when the environment contains sources and sinks of information, and when it contains memory/compression systems. Once you introduce memory and compression into the universe, information about the past and the future are allowed to interact, as well as counterfactuals. Downstream of that, I suspect, is theory of mind, acausal decision theories, embedded agency, etc. Memory systems are also 'lags' in the flow of information, which then changes what the geodesic looks like for bits.
I suspect a science of complexity will involve a lot of concepts from physics like work, energy, entropy, etc. - but they'll involve more generalized, parameterized forms which need to be fit via empirical data from a particular complex system you desire to study.
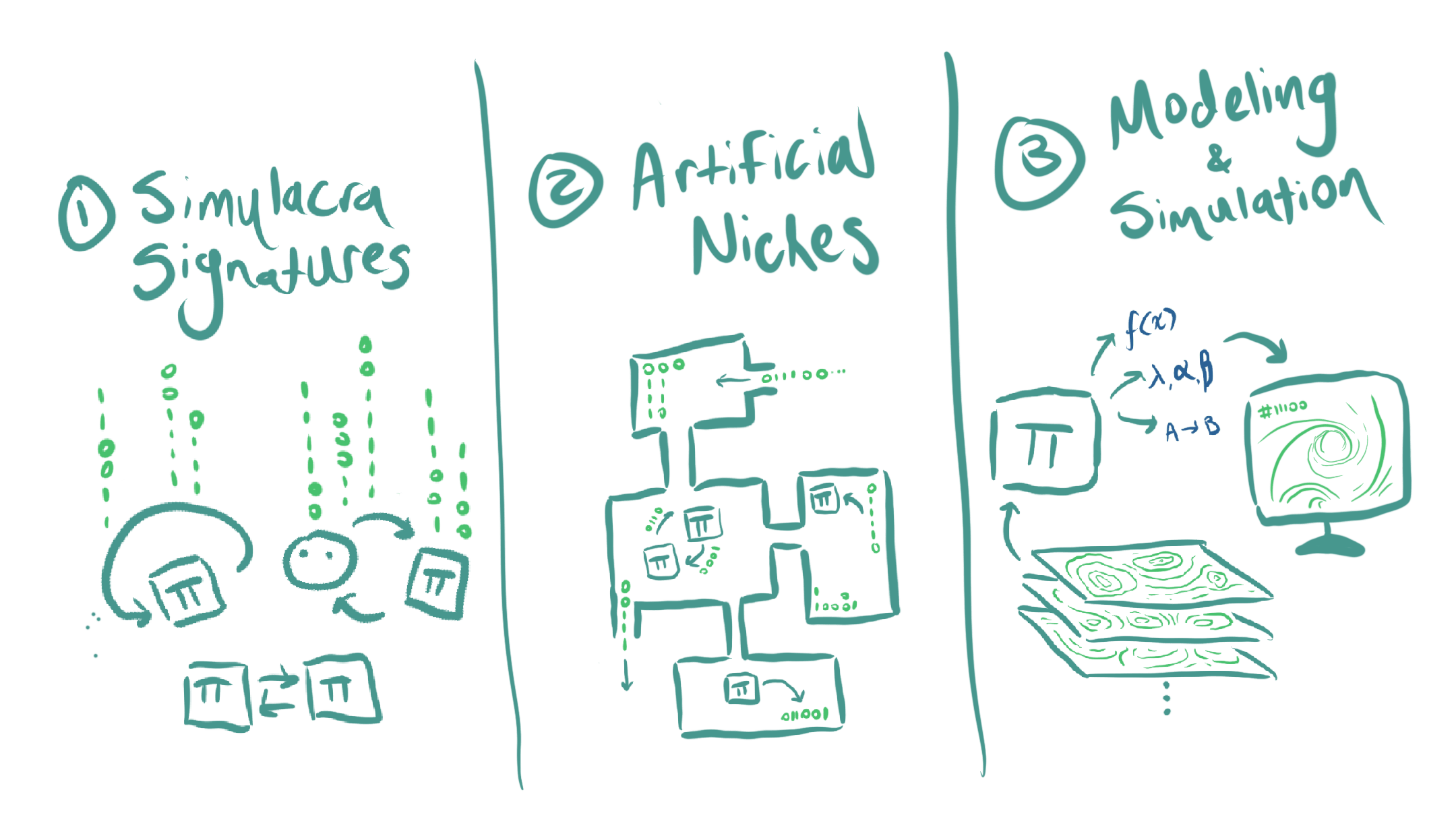
I think alignment might get a lot easier once we understand "infodynamics" far better, and the above drawing is of what I see as my current three-step, high level plan:
(1) find ways to track/measure the heat signautures (really 'information' signatures) of optimization processes/intelligences
(2) develop (open, driven-dissipative) environments that allow intelligences of different scales to move information around and interact with one another to get empirical data on how the 'information-spacetime' changes
(3) extract distilled models of the phenomena/laws going on so that rapid modeling can occur to explore the space of minds with these abstract models
So this is the dark arts of rationality...
Is this a problem? I think the ontology addresses this.
I'd have phrased what you just described as the agent exiting an "opening" in the niche ((2) in the image).
If theres an attractor that exists outside the enclosure (the 'what if' thoughts you mention count, I think, since they pull the agent towards states outside the niche), if there's some force pushing the agent outwards (curiosity/search/information seeking), and if there are holes/openings, then I expect there to be unexpected failures from finding novel solutions
Thanks for making this!
I'm wondering if you've spent time engaging with any of Michael Levin's work (here's a presentation he gave for the PIBBS 2022 speaker series)? He often talks about intelligence at varying scales/levels of abstractions composing and optimizing in different spaces. He says things like "there is no hard/magic dividing line between when something is intelligent or not,". I think you might find his thinking on the subject valuable.
You might also find Designing Ecosystems of Intelligence from First Principles and The Markov blankets of life: autonomy, active inference and the free energy principle + the sources they draw from relevant.
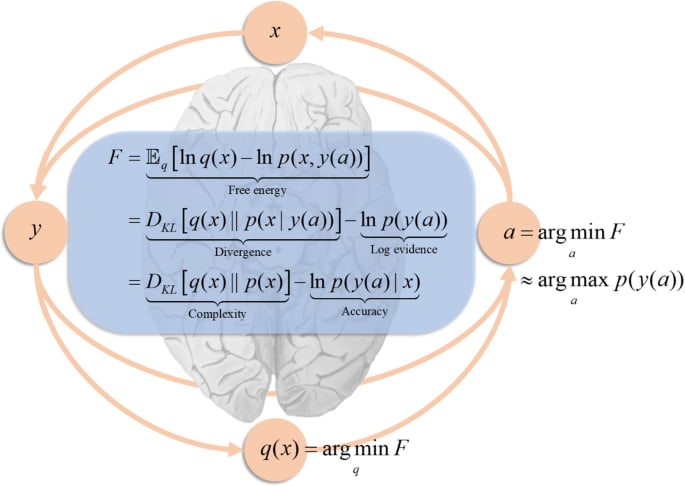
How similar is Watanabe's formulation of free energy to Karl Friston's?
Another potential idea:
27. A paper which does for the sharp left turn what the goal misgeneralization paper does for inner alignment (or, at least, breaking the SLT into sub-problems and making a paper for one of the sub-problems)
it does seem to be part of the situation we’re in
Maybe - I can see it being spun in two ways:
- The AI safety/alignment crowd was irrationally terrified of chatbots/current AI, forced everyone to pause, and then, unsurprisingly, didn't find anything scary
- The AI safety/alignment crowd need time to catch up their alignment techniques to keep up with the current models before things get dangerous in the future, and they did that
To point (1): alignment researchers aren't terrified of GPT-4 taking over the world, wouldn't agree to this characterization, and are not communicating this to others. I don't expect this is how things will be interpreted if people are being fair.
I think (2) is the realistic spin, and could go wrong reputationally (like in the examples you showed) if there's no interesting scientific alignment progress made in the pause-period.
I don't expect there to be a lack of interesting progress, though. There's plenty of unexplored work in interpretability alone that could provide many low-hanging fruit results. This is something I naturally expect out of a young field with a huge space of unexplored empirical and theoretical questions. If there's plenty of alignment research output during that time, then I'm not sure the pause will really be seen as a failure.
I’m in favor of interventions to try to change that aspect of our situation
Yeah, agree. I'd say one of the best ways to do this is to make it clear what the purpose of the pause is and defining what counts as the pause being a success (e.g. significant research output).
Also, your pro-pause points seem quite important, in my opinion, and outweigh the 'reputational risks' by a lot:
- Pro-pause: It’s “practice for later”, “policy wins beget policy wins”, etc., so it will be easier next time
- Pro-pause: Needless to say, maybe I’m wrong and LLMs won’t plateau!
I'd honestly find it a bit surprising if the reaction to this was to ignore future coordination for AI safety with a high probability. "Pausing to catch up alignment work" doesn't seem like the kind of thing which leads the world to think "AI can never be existentially dangerous" and results in future coordination being harder. If AI keeps being more impressive than the SOTA now, I'm not really sure risk concerns will easily go away.
For me, the balance of considerations is that pause in scaling up LLMs will probably lead to more algorithmic progress
I'd consider this to be one of the more convincing reasons to be hesitant about a pause (as opposed to the 'crying wolf' argument, which seems to me like a dangerous way to think about coordinating on AI safety?).
I don't have a good model for how much serious effort is currently going into algorithmic progress, so I can't say anything confidently there - but I would guess there's plenty and it's just not talked about?
It might be a question about which of the following two you think will most likely result in a dangerous new paradigm faster (assuming LLMs aren't the dangerous paradigm):
- current amount of effort put into algorithmic progress + amplified by code assistants, apps, tools, research-assistants, etc.
- counterfactual amount of effort put into algorithmic progress if a pause happens on scaling
I think I'm leaning towards (1) bringing about a dangerous new paradigm faster because
- I don't think the counterfactual amount of effort on algorithmic progress will be that much more significant than the current efforts (pretty uncertain on this, though)
- I'm weary of adding faster feedback loops to technological progress/allowing avenues for meta-optimizations to humanity since these can compound
I had a potential disagreement with your claim that a pause is probably counterproductive if there's a paradigm change required to reach AGI: even if the algorithms of the current paradigm aren't directly a part of the algorithm behind existentially dangerous AGI, advances in these algorithms will massively speed up research and progress towards this goal.
My take is: a “pause” in training unprecedentedly large ML models is probably good if TAI will look like (A-B), maybe good if TAI will look like (C), and probably counterproductive if TAI will be outside (C).
+
The obvious follow-up question is: “OK then how do we intervene to slow down algorithmic progress towards TAI?” The most important thing IMO is to keep TAI-relevant algorithmic insights and tooling out of the public domain (arxiv, github, NeurIPS, etc.).
This seems slightly contradictory to me. It seems like - whether or not the current paradigm results in TAI, it is certainly going to make it easier to code faster, communicate ideas faster, write faster, and research faster - which would potentially make all sorts of progress, including algorithmic insights, come sooner. A pause to the current paradigm would thus be neutral or net positive if it means ensuring progress isn't sped up by more powerful models
We don't need to solve all of philosophy and morality, it would be sufficient to have the AI system to leave us in control and respect our preferences where they are clear
I agree that we don't need to solve philosophy/morality if we could at least pin down things like corrigibility, but humans may poorly understand "leaving humans in control" and "respecting human preferences" such that optimizing for human abstractions of these concepts could be unsafe (this belief isn't that strongly held, I'm just considering some exotic scenarios where humans are technically 'in control' according to the specification we thought of, but the consequences are negative nonetheless, normal goodharting failure mode).
Which of the two (or the innumerable other possibilities) happens?
Depending on the work you're asking the AI(s) to do (e.g. automating large parts of open ended software projects, automating large portions of STEM work), I'd say the world takeover/power-seeking/recursive self improvement type of scenarios happen since these tasks incentivize the development of unbounded behaviors (because open-ended, project based work doesn't have clear deadlines, may require multiple retries, and has lots of uncertainty, I can imagine unbounded behaviors like "gain more resources because that's broadly useful under uncertainty" to be strongly selected for).
I'd be interested in hearing more about what Rohin means when he says:
... it’s really just “we notice when they do bad stuff and the easiest way for gradient descent to deal with this is for the AI system to be motivated to do good stuff”.
This sounds something like gradient descent retargeting the search for you because it's the simplest thing to do when there are already existing abstractions for the "good stuff" (e.g. if there already exists a crisp abstraction for something like 'helpfulness', and we punish unhelpful behaviors, it could potentially be 'really easy' for gradient descent to simply use the existing crisp abstraction of 'helpfulness' to do much better at the tasks we give it).
I think this might be plausible, but a problem I anticipate is that the abstractions for things we "actually want" don't match the learned abstractions that end up being formed in future models and you face what's essentially a classic outer alignment failure (see Leo Gao's 'Alignment Stream of Thought' post on human abstractions). I see this happening for two reasons:
- Our understanding of what we actually want is poor, such that we wouldn't want to optimize for how we understand what we want
- We poorly express our understanding of what we actually want in the data we train our models with, such that we wouldn't want to optimize for the expression of what we want
I've used the same terms (horizontal and vertical generality) to refer to (what I think) are different concepts than what's discussed here, but wanted to share my versions of these terms in case there's any parallels you see
Horizontal generality: An intelligence's ability to take knowledge/information learned from an observation/experience solving a problem and use it to solve other similarly-structured/isomorphic problems (e.g. a human notices that a problem in finding optimal routing can be essentially mapped to a graph theory problem and solving one solves the other)
Vertical generality: An intelligence's ability to use their existing knowledge to augment their own intelligence with tools or by successfully designing smarter agents aligned to it (e.g. a human is struggling with solving problems in quantum mechanics, and no amount of effort is helping them. They find an alternative route to solving these problems by learning how to create aligned superintelligence which helps them solve the problems)
If you're an intelligence solving problems, increasing horizontal generality helps because it lets you see how problems you've already solved actually apply to problems you didn't think they applied to before you increased horizontal generality. Increasing vertical generality helps because it finds an alternative route to solving the problem by actually increasing your effective problem solving ability.