A Bite Sized Introduction to ELK
post by Luk27182 · 2022-09-17T00:28:01.847Z · LW · GW · 0 commentsContents
Purpose of this Post ELK Problem Description Training a Reporter Expanding the Reporter's Training Set Proposal: Have a Human Search for Tricky Situations Counter Example: The Reporter is a Human-Operator Simulator Regularizers for the Reporter's Objective Function Proposal: Penalize Downstream Variables Counter Example: The Reporter Simulates the SmartVault AI. Guided Practice Proposal: Counter Example: Congratulations! None No comments
Epistemic Status: This post is mainly me learning in public as my final project for the ML Safety Scholars Program. [? · GW] Errors are very possible, corrections very welcome.
Purpose of this Post
From my limited perspective as a curious undergrad student, ELK research seems like a perfect way for the relatively inexperienced to try out AI safety research:
- There is essentially no necessary background knowledge beyond a basic understanding of ML
- There are no costs for conducting research (e.g. renting GPUs).
- Several cash [LW · GW] prizes have been offered in the recent past to bring people into the field, so it seems likely that there will be more in the future.
It seems possible that one of the biggest barriers to more people working on ELK is that ARC's ELK proposal is a hundred pages long. The goal of this post is to get someone who has some rationality/ML background but lacks any technical/research/AIS specific experience to the point where they can produce (probably unoriginal[1]) ELK proposals and counter exampels.
ELK Problem Description
The goal of Eliciting Latent Knowledge (ELK) is to extract knowledge that an agent knows about a situation but isn't telling us directly.
The classic example used in ELK is an AI placed in charge of a complex vault (called SmartVault) containing a diamond. The vault includes a large number of motors/servos which can potentially be used by the AI to protect the vault, and there is a single camera which allows humans to view the diamond's pedestal.

We want the AI to use the various motors and other tools to stop even highly sophisticated robbery attempts. The SmartVault AI would ideally be able to accurately predict if the diamond would be stolen if a particular plan was followed. Such a system could be used to design complex plans that minimize the predicted probability of a successful robbery.
This strategy runs into problems when the SmartVault AI is dishonest in ways that humans are not able to detect. For example, the intruder may place a painting depicting the room with the diamond on an easel in front of the camera. When humans look through the camera, it would appear as though the diamond is still on the pedestal.
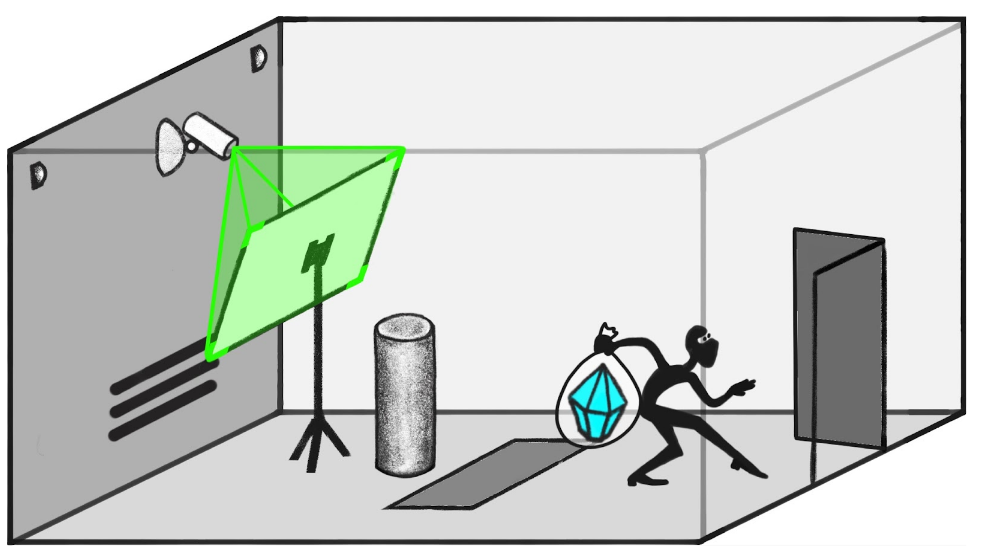
In scenarios such as this, the SmartVault AI may output that the diamond is safe even though it knows that the diamond was stolen. Because the humans believe the diamond is safe, there would be no way to punish the AI for taking this action. Worse, if the AI were created using a training set with incorrect labels in situations such as this, it would even be incentivized to be dishonest in this way!
For obvious reasons, this not ideal- humans want a way of knowing when an AI is lying about what it believes is happening in the world. The goal of ELK is to create a second AI, known as a reporter, which analyzes the SmartVault AI's internal state and is able to answer questions about what that AI really thinks is going on.
Training a Reporter
The most straightforward way to create the reporter would be to train it on internal states of the SmartVault AI, where situations in the data set are labelled as situations where the diamond is safe and situations where the diamond is stolen.
Since humans do not always know when the diamond is safe, however, we would be training the reporter on a very small subset of all possible situations. Specifically, only the subset of situations in which the human can confirm where the diamond is:

It is not guaranteed that a reporter that does well on this small subset will generalize well to the entire sequence. For example, the reporter may simply look at outputs of the SmartVault AI and use that to figure out what the SmartVault AI will predict humans will think about the state of the diamond. Assuming that the SmartVault AI can trick us, it would follow that the reporter would trick us as well. Clearly, a reporter like this would be useless.
For ease of future reference, we call the reporter that predicts what humans will think a "human simulator" and the reporter that actually reports the SmartVault AI's internal beliefs an "honest reporter."
ARC's ELK paper offers several partial solutions (that is, solutions that "almost work") to the problem of creating an honest reporter rather than just a human simulator. These partial solutions largely fall into two categories:
- Those that expand the reporter's training data set, which improves the probability that the reporter will generalize to the full distribution of situations.
- Introducing regularizers to train the reporter so that it is penalized for being a human simulator rather than an honest reporter.
Expanding the Reporter's Training Set
One difficulty in training the reporter is that the training set (situations where the human knows the state of the diamond) is extremely small compared to the total number of situations which may occur in deployment. The larger we can get the training set, the better the reporter can be expected to generalize.
Below is an example of how the reporter's training data set could be expanded, using the structure of research generally used in ELK research. In this structure, one researcher comes up with an idea to potentially solve ELK (a proposal). Then, another researcher tries to find a way where the proposal could go wrong (a counter examples). The goal of ELK research is to create a proposal for which no convincing counter examples can be found.
Proposal: Have a Human Search for Tricky Situations
One way of expanding the training set to include situations where the human observer may not know the true state of the diamond would be to employ a human operator to control the SmartVault and explicitly search for such tricky situations.

As depicted above, this approach does indeed expand the training data to include a larger proportion of the true distribution.
Counter Example: The Reporter is a Human-Operator Simulator
It is still very possible for the reporter to perform well on this training set while failing in deployment. For example, the reporter could be a human-operator simulator (That is, an AI which predicts what the human-operator thinks about the state of the diamond).
Although a reporter trained on this expanded training set would be more likely to generalize well than the base case, the given proposal is by no means a complete solution to the ELK problem.
Regularizers for the Reporter's Objective Function
Another difficulty in training a reporter is that a human simulator will preform just as well (if not better than) a honest reporter on the training data set. One potential way to solve this issue is by training the reporter with a regularizer that punishes a human simulator more than it punishes an honest reporter.
Proposal: Penalize Downstream Variables
If the SmartVault AI is not honest, it seems likely that its internal model of the world "flips" into a lie-that-humans-will-believe near the end of its computation. Hence, we would prefer that the reporter mostly focuses on the variables early in computation. Penalizing the reporter for using downstream variables would accomplish this.
Counter Example: The Reporter Simulates the SmartVault AI.
If the reporter was able to fully simulate the SmartVault AI within its own program, it would only need access to the inputs of the AI. After that, it could simulate the SmartVault AI and do the same calculations it could before without any cost.
Guided Practice
To finish things off, I encourage you to try and find a new proposal that patches the previous counter example. That is, attempt to find a proposal that builds on the proposal to add a "Downstream Variable" regularizer and patches the counter example where the reporter just simulates the SmartVault AI.
Once you have thought of a way to solve that, view the solution below (if yours was substantially different, please comment and I will add it as an alternative solution.) There is a relatively simple solution- I think someone who has understood everything said so far should be able to think of a proposal without spending more than 10 minutes thinking.
Proposal:
In addition to the "Penalize Downstream Variables" regularizer, we could add a "Complexity" regularizer which puts a pressure on training to produce a reporter with low computational costs. This solves the previous counter example because a reporter AI could no longer simulate the entire SmartVault AI without significant costs.
It is quite difficult to see where this proposal fails, but I also left the counter example to this proposal under a black box in case you would like to try it as a challenge exercise.
Counter Example:
We assumed that the SmartVault AI model would first learn the true state of the world, and then predict what humans would believe happened. This was why we decided to penalize the reporter for using later computations. However, this assumption is not always true!
For example: suppose that an intruder sneaks into the vault and sets up the painting covering the camera before stopping to tie his shoe. After a bit of time, the robber stands up and steals the diamond.
When the reporter analyses this scenario, it is incentivizes to look at the earlier stages of the SmartVault AI's computation first. When it does so, reporter sees that there is a painting in front of the camera (so that the reporter knows what the human will believe), and yet it does not know if the diamond will successfully be stolen or not.
Because computation time is incentivized to be as low as possible an the reporter already knows that the human thinks will be the correct answer, the reporter will simply report that the diamond was not stolen before it actually examines later variables of the SmartVault AI's computation
Congratulations!
You've now done theoretical alignment research.
- ^
Note that I'm not implying that readers will be able to produce proposals and counter examples that surpass existing ones immediately after reading this article. Rather, I think readers could conceivably rediscover for themselves most of the other proposals included ARC's ELK paper. I think there is value in this.
0 comments
Comments sorted by top scores.