Research Adenda: Modelling Trajectories of Language Models
post by NickyP (Nicky) · 2023-11-13T14:33:56.407Z · LW · GW · 0 commentsContents
Summary The non-summary Motivation for the Project Illustration Steps Involved STEP 1 - Making Chains of Themes STEP 2 - Simple Prediction STEP 3 - Build Better Predictions STEP 4 - (Ambitious) Generalise Results First Steps Other Considerations What can go wrong? Backup Plan: Ambitious and Least Ambitious Versions Scope and Limitations Significance in the Context of AGI/TAI Researach Outputs Risks and downsides Team Team size Research Lead Skill requirements Apply Now None No comments
Apply to work on this project with me at AI Safety Camp 2024 before 1st December 2023.

Summary
Rather than asking “What next token will the Language Model Predict?” or “What next action will an RL agent take?”, I think it is important to be able to model the longer-term behaviour of models, rather than just the immediate next token or action. I think there likely exist parameter- and compute-efficient ways to summarise what kinds of longer-term trajectories/outputs a model might output given an input and its activations. The aim of this project would be to conceptually develop ideas, and to practically build a method to summarise the possible completion trajectories of a language model, and understand how this might or might not generalise to various edge cases.
The non-summary
Motivation for the Project
There is a large amount of effort going into understanding and interpreting the weights and activations of Language Models. Much of this is focused on directly looking at the logits for next token predictions. While I think one can learn a lot about models this way, I think there are potentially more ways one can understand behaviour of models. Another method for investigation is to sample some possible outputs, but this is expensive and time-consuming, and it can be difficult to inspect all of the outputs.
I think that it should be possible to get sufficient information from understanding model behaviour and outputs in a much more condensed and compute-efficient way, such that one could iterate through different interpretability strategies, and understand more high-level insights about the models. In addition, I think that being able to get a broader understanding of what kinds of outputs a model might likely output would make it easier to monitor models, and prevent potential trajectories we might not like.
More explicitly:
- “Machine Unlearning”/ablation experiments is one of the key ways of trying to have better metrics for interpretability tools. For example, if we identify a circuit that we think is doing some task A, it would be great we can remove that circuit and quickly recognise that this only affects task A, and does not affect other tasks.
- Can we build a better dashboard for monitoring possible outputs/”actions” a model might take, before it makes these outputs/actions? Could we monitor when a model is starting to give unexpected outputs or is starting to steer down an unexpected path?
Illustration
I have an illustration of what I would want it to look like, and how one might train one. Exact details can be discussed, but the plan looks like this:
- Prompts → Language Model → Generated outputs
- Summarise the outputs into chains of “themes”
- Accurately predict chains of themes given input prompts.
Here is a visual illustration and description of what I am envisioning (note: does not need to be this “pretty”):
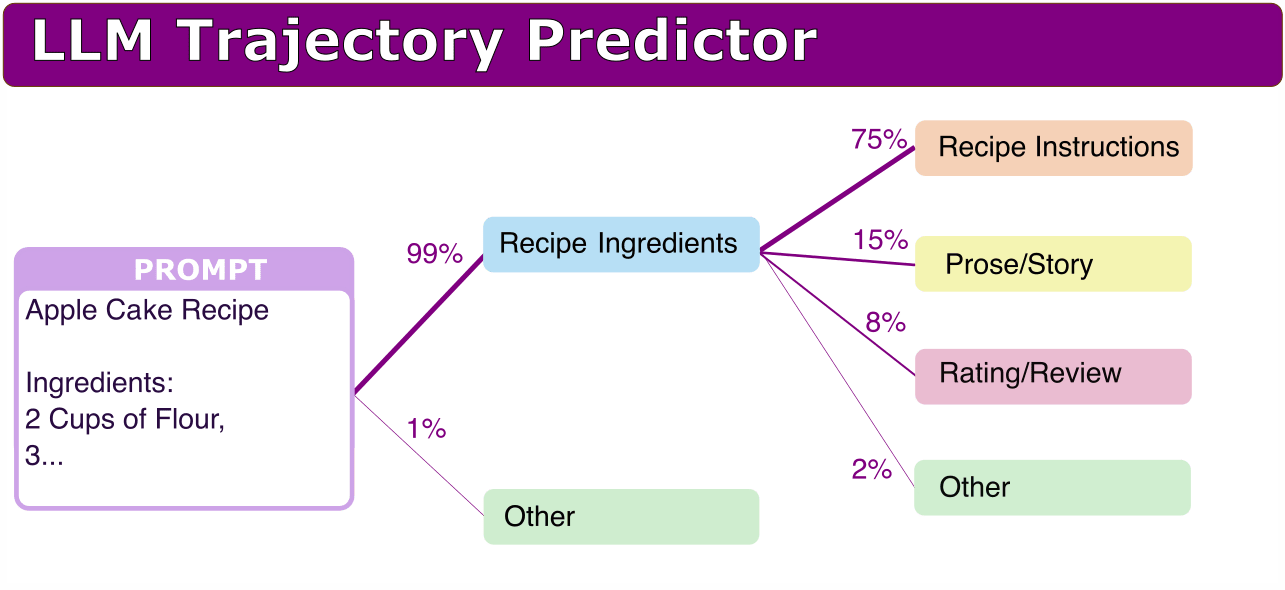
Let’s go through what the example in the image might work like:
- We have a prompt (recipe title and some ingredients)
- We feed this to a language model and get activations
- We feed the activations to a predictor
- The “predictor model” outputs what theme the predictions are likely to look like next:
- 99% “recipe ingredients” theme
- <1% on many other possible themes
- The predictor model then predicts what the theme following that might be, taking into account the previous theme. For example, assuming the model writes a section in the theme of “recipe ingredients”, the model next would write:
- 75% “recipe instructions”
- 15% “prose/story”
- 8% “rating/review”
- <1% on many other possible themes
- This gives possible chains of “themes” for LM generations.
I doubt that the first iteration of this would wildly reduce x-risk, but I think this would be a valuable first attempt to build an important tool to be iterated upon. Ultimately, I would like to be able to build upon this so that we could apply it to LLMs in RL environments, and get an idea of what sort of actions it might be considering.
Steps Involved
The main steps involved are:
- Generate Texts, and convert into Chains of Themes
- Do simple, immediate next theme prediction
- Build more advanced, multi-step theme prediction
- Generalise beyond pre-trained-LLM text generation
STEP 1 - Making Chains of Themes
(Time estimate: anywhere from 2 weeks to 8+ weeks)
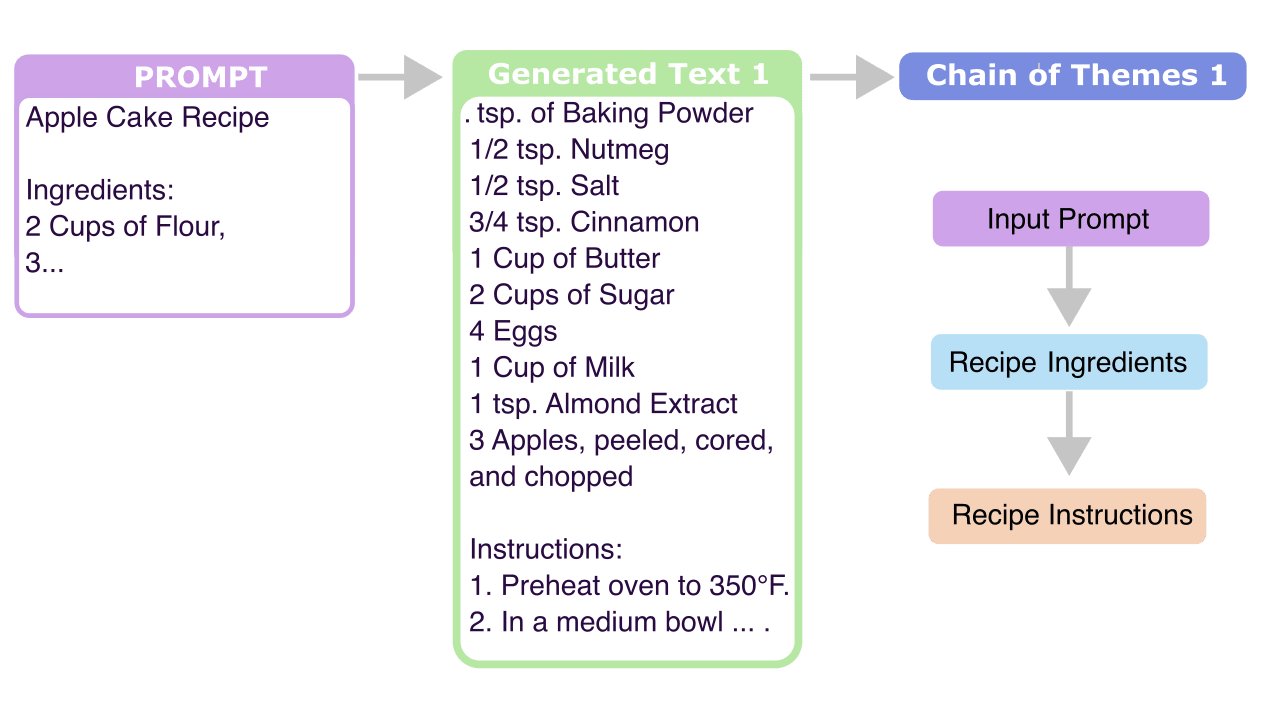
Initially, all focus would be on this step, but depending on results, we could work with initial results in step 2, and also keep refining step 1 in parallel.
The aim here would be to generate some training data:
- Choose a language model for testing
- Select a broad set of possible inputs (preferably a mix of generic and specific)
- Prompt 1, 2, 3 …
- Get the language model to generate a variety of possible outputs for each input/prompt (in order to get an idea of the distribution of possible trajectories)t
- Prompt 1 → LLM → Generated Texts 1A, 1B, 1C
- Get a language model to summarise the “theme” of the outputs from each of the prompts (ideally: multiple consecutive themes). i.e:
- Generated Texts 1A, 1B, 1C → LLM → Thematic Summaries 1A, 1B, 1C
I think that in practice, the final step above is somewhat difficult to get done exactly right, and might take a few weeks. While it is easy to imagine summaries in cases like the recipe example, I think there are also many other possible cases where it is non-obvious how much detail we want.
Some of the main things to do are:
- Hypothesise what might influence these trajectories.
- Better describe what "longer-term trajectories/outputs" mean.
- Better tune what “summaries” should look like.
Before building a large dataset, we would try doing initial experiments on how to give summarisation chains that capture what we want. For example:
- Give one well-defined prompt (e.g: cooking ingredients).
- Get 10 random generations. (could be more)
- Summarise the chain of themes in these generations.
- Get 10 more random generations.
- Summarise again.
- Make sure that the summary chains are giving descriptions that are informative, accurate, consistent etc.
- Try again with a prompt that is more vague (e.g, something like: “An Introduction to”) and make sure that it works somewhat as planned. (maybe requires larger # generations)
Once this looks like what we want it to look like, we can scale this up to make the full training data on a larger variety of possible prompts. If there is a sufficient variety in prompts, I would expect that one does not need to have as many examples per prompt of possible completions, but this would also need to be tested. There is a change that we get stuck on this step, and end up spending the entire time working on making this better.
Part of this work might involve finding existing literature and building upon it (for example this paper), but I haven’t found anything building anything sufficiently general and consistent.
STEP 2 - Simple Prediction
(Estimated time: likely at least 2 weeks, but I don’t expect this to take too much longer)
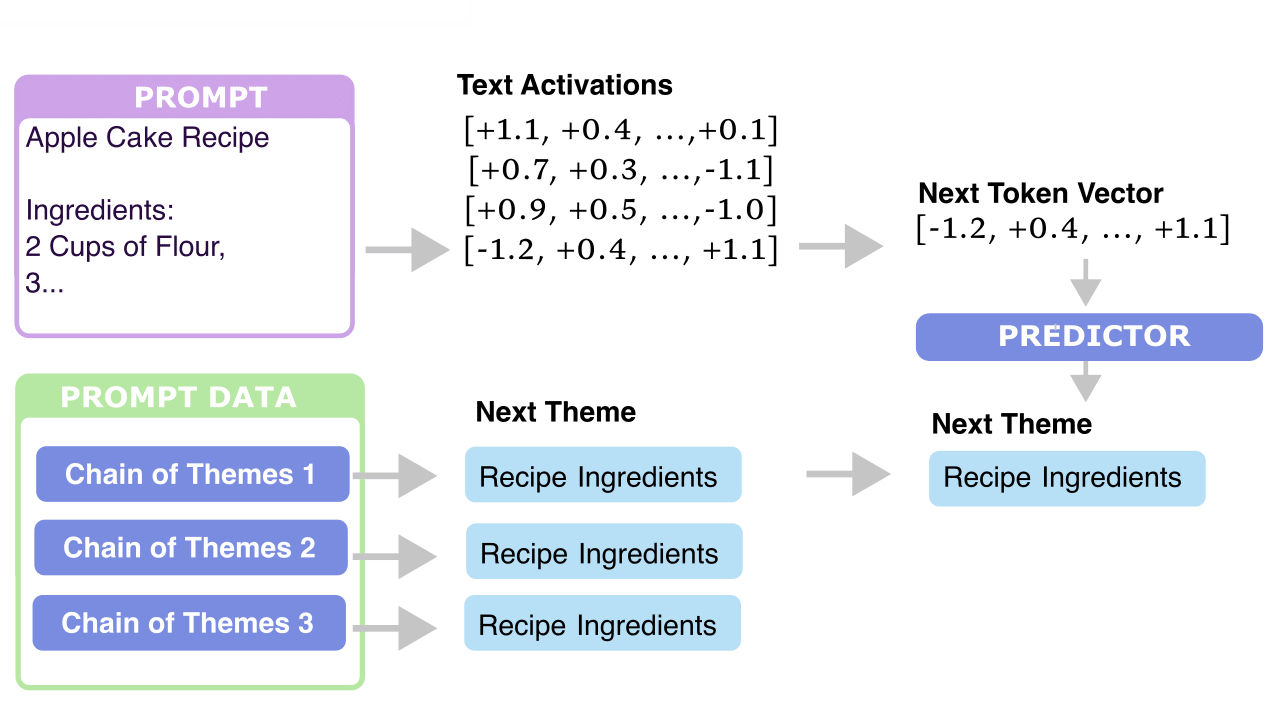
Depending on results of step 1, could start doing this in parallel while still working on improving step 1.
Try the simplest possible “trajectory modelling predictor”
- Run model on a possible input, and take the outputs of the final layer, and save these.
- Create a dataset that maps final-token-activation to likely-theme(s).
- Train a linear regression model on this dataset.
Note: it may be the case that final layer activations don’t hold enough information, but intuitively I think they should. (e.g: this paper where they trained linear probes and compared performance in each layer)
At this point, it would be a good idea to test how well this simplistic model works. Some questions to try answer:
- Does this work well? (% accuracy?)
- Does this generalise? (for some unseen set of weird prompts)
- Does it work better for different layers? (maybe the final layer is too lossy with information?)
- Do we need to do normalisation (e.g: LayerNorm)?
- Does it work better if we make the prompts more consistent (e.g: prompt is sentence ending with full stop)?
- How stable is this? Do we have a measure for when uncertainty is high?
Depending on how this goes, it may be necessary to go back to Step 1 and revise again. If this goes well, then we can continue to try to build upon this research and predictors for chains of themes.
STEP 3 - Build Better Predictions
(Estimated time: Dependent on results, but likely minimum >1 month)
Train a longer-term “trajectory modelling predictor”
- Run model on a possible input, and take the activations of the model, and save these
- Create a more complex predictor model (See details below)
- Train the simple model to take the final layer outputs and predict a chain of “themes”
The more complex predictor model might look like (in order of “I like this more” to “I like this less”):
- Create a simple, 2-layer transformer model that takes in multiple activations from the final layer (+ maybe a “<theme>” token), and train it to output multiple theme tokens.
- Take an existing small model (eg: galactica-125m), retrofit it (e.g: change embedding to Wgal, embedT Wactor, unembed ) and fine-tune this new model on output-activations → themes
- Take the original model with N layers, and fine-tune the layers N-2 … N with LoRA on the task.
STEP 4 - (Ambitious) Generalise Results
If all the above goes particularly smoothly, then we can begin to generalise the finding and results to other models. For example: RL agents, AutoGPT, decision transformers…
If this occurs, I would likely discuss details later on with the team.
First Steps
I would start off by giving a detailed explanation of how the key parts of a transformer work, and introducing.
I think the first step would be to better define what these longer-term trajectories should look like, and better define what these “themes” should be. It may be the case that ideally, one would want to output Multiple properties of the output, and writing a succinct yet precise and accurate summary in a broad set of situations could be difficult.
It might be the case that it would make more sense to look at more “boring” models, such as chess engines or grid world agents and try to model those, and I would be supportive in efforts of this direction as well. My current intuition is that language models outputs might actually be the easier thing to “summarise” in this case.
It would also be worth investigating techniques one might expect to yield useful results for this. While the most basic method would be to train a predictor model, I suspect there could be interesting non-gradient based methods that could achieve similar performance without requiring training by mathematically extracting the relevant information from the output activations.
Other Considerations
What can go wrong?
I think the ideas written up are sufficiently clear that experiments could be refined and run, but there are some of the main pitfalls that I could see happening:
- The “summarisation” is too low-dimensional to be done both usefully. There are many ways of doing this in different situations, and it is difficult to do anything in any kind of general manner. I suspect this shouldn’t be the case, but it seems possible.
- It may be the case that it is too difficult for the predictor to generalise to examples sufficiently different from the initial training. This might be better if one somehow retrofits a pre-trained tiny model to attach to the outputs of the original model, and then from that generate the possible paths, but this has its own challenges.
Backup Plan:
- It may be the case that the ideas written here are premature for running experiments, and I think theoretical research exploring and trying to understand long-term behaviours and goals of models would be quite interesting. I have some written up some thoughts [? · GW], and would be interested in a deeper dive.
- It may also be the case that Making Chains of Themes (STEP 1) is quite difficult to do well such that I am happy with it, and while we could run some preliminary experiments on it, time would plausibly be best spent working on making it more robust/theoretically grounded.
Ambitious and Least Ambitious Versions
- Most Ambitious: Developing a method that can accurately summarise and predict the long-term behaviours of a wide array of ML models across all possible inputs and scenarios, in such a way that it generalises to fine-tunings of the model.
- Least Ambitious: Try running tests on tiny models and realise this is not feasible (due to small models being too poor, lack of compute, theoretical gaps etc.). Further developing any theory that might be required to actually put this into practice, noticing potential failures, writing up what might be required to achieve the same things as described above.
Scope and Limitations
The aim here is to:
- Further develop theoretical understanding of long-term trajectories/“goals”
- Be better able to predict and model the longer-term behaviour of models
The project as currently formulated would not focus on directly interpreting and understanding how Language Models work, nor would it be directly modifying the “goals” of a Language Model. Instead, we would be building tools that could potentially make this process easier.
Significance in the Context of AGI/TAI
Understanding and being able to predict the longer-term behaviours of models like AGI/TAI is paramount to ensuring they operate safely and effectively within societal contexts. By providing a method to predict and summarise possible trajectories of a model’s responses and actions, this project aims to create a foundation for enhanced predictability in deploying models in real-world scenarios. In particular, being able to better understand and model what a model might do many time steps down the line, or better notice when the plans might change, one could better monitor when a model might not give desired outputs, and not let that path be explored.
In particular, I am worried about worlds where, even if people get really good at probing and understanding what goals may lie in a model, that there may implicitly lie longer-term goals that are not explicitly encoded in the model. For example, if we have a robot that encodes only the goal “go north 1 mile every day”, then we can implicitly learn that the model has the goal “go to the North Pole”, but could only infer this by studying the behaviour on longer time scales. There is very little work on inferring longer-term behaviour of Lanugage Models, and this work aims to be a first attempt at trying to build these longer-time-scale views of model behaviour.
A more clear benefit comes from the applications in better assessing interpretability research. In particular, having quantitative information on how model generations have qualitatively changed would be a significant improvement on existing slow and manual techniques for assessing outputs from models. One can look at, for example, the ActAdd Post [LW · GW]: The main method of evaluation is quite labor-intensive to evaluate (generate many outputs and list them all), and building better tools for evaluating methods like this would make it easier to understand the efficacy of the method, and how it compares to other approaches.
In particular, I think that trying to do Machine Unlearning with these Interpretability related techniques would be a good benchmark to test how well we understand what is going on, and to what extent other aspects of model generation are affected by the technique.
Researach Outputs
I think outputs would look something like:
- Mid AISC:
- LessWrong post or Design Doc describing what the experiment might look like in greater detail what one might want as an outcome
- If a more theory-laden approach is taken, this could also be a final outcome
- End of AISC:
- Experiments run + github repo
- LessWrong post showing some results
- After AISC (optional):
- Write-up with more details into a paper + post onto ArXiV (or conference if desired)
- Possibly apply for funding to continue work in this direction
Risks and downsides
I think this has potential to give improvements to interpretability, and making it easier to run experiments on identifying potential modularity/separation of capabilities in language models. This has a dual-use argument as an interpretability approach, but I think that the risks here are relatively low compared to other research I have seen.
It seems possible that one could do optimisation on the approach for prompt engineering and find prompts that force the model to go down “paths” that might be unexpected. This could be for better (e.g: stop the model from going down paths you don’t want) or for worse (e.g: “jailbreak” a highly capable model).
I would however suggest testing for any of these potential risks before publishing any results.
Team
Team size
I think the normal team size of 3-5 people could make sense, but it depends on what kind of people might be interested in the project. I suspect something like this could work well:
- Theorist Role
- Experimentalist/Coding Role
- Distiller/Generalist + Ops Role
Likely Ideal: 2 Experimentalists + 1 Theorist + 1 Distiller role
I could see some of the roles being merged or split apart depending what kind of people apply. If this seems interesting and you think you can help, but you don't feel like you would fit into these moulds, you are still encouraged to apply
Research Lead
I’ve spent the past 1.5 years doing alignment research, mostly independently, including doing SERI MATS in Summer 2022. I think that there is not enough research into understanding “goals” models, and this seems to be one of the most important things to understand. I think that modelling longer-term trajectories could be an interesting and useful approach to try doing this.
I will likely spend 15-25 hours each week directly working on this project, and will:
- Dedicate time to working with people and getting them up to speed
- Meet at least once a week (and likely more often) to plan actions and to resolve issues people might have
- At least 3x per week, have online casual office hours (eg: Gather Town) when people have blockers but aren’t sure how to articulate their problem by text, or if people want to co-work.
- Take feedback and adjust mentorship style depending on what people are interested in.
Skill requirements
As a minimum, for each role, I would expect:
- Having a basic theoretical understanding of how neural networks work (eg: 3blue1brown video series) is a must.
- I think having done something like AGI Safety Fundamentals or similar would be useful.
- Having some understanding of how Language Models work would be good, but I am also able to teach the important basics.
- Being good at working with other people
- Having knowledge of some phenomena in neural networks such as grokking, double descent, superposition, Goodhart’s law etc. is not necessary, but would a plus.
For the more specific roles, I would expect:
Experimentalist = Should have strong coding experience. Familiarity with Python/PyTorch/Language Models is a plus, but not necessary. (For example: internships/experience at tech company, comfortable doing basic Leet Code questions, can use git and run unit tests). I have experience with working with most of the things described above, so can help explain things if someone gets stuck, and have existing code that might be useful for some things.
I think there is room to have a couple of coders, as there is likely a lot one could do on STEP 1 (Summarising generations), and likely even if/when there is sufficient progress to work on STEP 2/3 (building predictors), there would likely be possible improvements to STEP 1 still to be made.
Theorist = Should be able to deal with confusion and attempt to clarify some ideas. Interested in coming up with new ideas. Having a background in mathematics/physics/statistics or similar would be ideal.
I think this would involve tasks such as: conceptualising the most efficient ways to summarise “themes”, reading many papers on methods related to interpretability and finding how these could be evaluated better/what is missing.
This could also involve trying to do things like: measure uncertainty over predictions, do some sensitivity analysis, find to what degree the predictions are chaotic/highly unpredictable.
Distiller = Should be able to read and understand materials, should be able converting messy language and experiments from other people into more understandable and easy to read form.
In particular, writing up the results in a way that is as legible as possible would be quite useful.
Having people with a mix of these skills would also be quite valuable.
Apply Now
This project is one of the projects you can work on at AI Safety Camp 2024. If you think this project looks valuable, and think you might be a good fit, then you can apply to work on it at AI Safety Camp before 23:59 on 1st December 2023 (Anywhere on Earth),
0 comments
Comments sorted by top scores.