Notes on "How do we become confident in the safety of a machine learning system?"
post by RohanS · 2023-10-26T03:13:56.024Z · LW · GW · 0 commentsContents
Summary:
How do we become confident in the safety of a machine learning system?
What’s a training story?
Training story components
How mechanistic does a training goal need to be?
Relationship to inner alignment
Do training stories capture all possible ways of addressing AI safety?
Evaluating proposals for building safe advanced AI
Case study: Microscope AI
Exploring the landscape of possible training stories
Training story sensitivity analysis
None
No comments
I'm trying out taking notes on an AI safety reading in a LessWrong draft post and sharing the result as a low-effort "distillation." I'm hoping this is a quick way to force myself to take better notes, and to provide distillations that are useful to others. This reading is "How do we become confident in the safety of a machine learning system? [LW · GW]" by Evan Hubinger.
I wasn't sure at the outset how far into tangential thoughts of my own I would go. I think by writing notes with the thought that other people might read them in mind, I ended up a) following the structure of the original post more rigidly than usual and b) going on fewer tangents than usual. I think that probably isn't ideal for me; if I do this again, I might try to actively not follow those impulses.
Anyway, here are the notes. Each section title here links to the corresponding section in the original post.
Summary:
This post suggests that we use training stories to flesh out and evaluate proposals for training safe ML systems. A proposal is a training setup (loosely understood), and a training story consists of a training goal and a training rationale. A training goal describes what behavior you hope the training setup will give rise to, in some mechanistic detail; it includes both how you think the model will perform the relevant task capably and why you think performing it in that way will be safe. A training rationale describes why you think the training setup will result in a model that implements the mechanistic behavior described in the training goal. While training stories do not capture all possible ways to make AI systems safer, they are quite a general framework that can help us better systematically organize and evaluate our proposals. This framework can also help us generate proposals if there are clear gaps in the space of possible training stories. The post includes quite a few examples of proposals, training goals, training rationales, and evaluations of training stories.
How do we become confident in the safety of a machine learning system? [LW · GW]
- An overview of 11 proposals for building safe advanced AI [LW · GW] uses the criteria of outer alignment, inner alignment, training competitiveness, and performance competitiveness to evaluate proposals for safe AGI
- These are good for posing open questions, but not for systematically helping us understand what assumptions need to hold for a proposal to work
- Plus some proposals aren't amenable to evaluation by those criteria
- New idea for evaluating proposals: training stories. Hopefully, these:
- Are applicable to any proposal for building safe AGI
- Provide a concise description of the conditions under which a proposal works (produces safe AGI), so we can become confident in the safety of a proposal by checking the conditions
- Don't make unnecessary assumptions about what a proposal must constitute (thereby implicitly blinding us to proposals we should be considering)
What’s a training story? [LW · GW]
- "A training story is a story of how you think training is going to go and what sort of model you think you’re going to get at the end" (in enough mechanistic detail to reflect its generalization behavior)
- See original post for cat classifier example
- Three good things about training stories illustrated by the example:
- If the story is true, the model is safe
- The story includes details about the conditions under which the resulting model will be safe, and about what it would look like for it not to be safe (the cat classifier is an agent that terminally values classifying cats)
- Falsifiable claims about what will happen during training (e.g. the cat classifier will learn human-like heuristics - we now have evidence CNN's diverge from human heuristics, so the example story was not entirely true)
- They can be told about any model being trained for any task
- Doesn't need to be an attempt to build AGI. Would be good to see a training story for any AI that could cause harm at any level. Plus, in the future it may not be obvious in advance when a model is going to be dangerous, so maybe every AI project (e.g. NeurIPS paper) should share a training story.
- How to enforce something like that? People train their models before submitting the papers, and might not write out or think through the training story before training if it just needs to be in their final paper. Might be helpful, but might also make people think its a hassle and not actually important, so they're not paying attention even when it is important.
- Doesn't need to be an attempt to build AGI. Would be good to see a training story for any AI that could cause harm at any level. Plus, in the future it may not be obvious in advance when a model is going to be dangerous, so maybe every AI project (e.g. NeurIPS paper) should share a training story.
- If the story is true, the model is safe
Training story components [LW · GW]
2 essential components:
- Training goal: A mechanistic description of the desired model and why that would be good (e.g. classify cats using human vision heuristics)
- This example seems to be missing the "why that would be good" part, but based on the earlier part it could be "human vision heuristics don't include any agent/optimizer which would take extreme or dangerous actions"
- Training rationale: Why you believe your training setup will give rise to a model satisfying the mechanistic description in the training goal
- "'Training setup,' here, refers to anything done before the model is released, deployed, or otherwise given the ability to meaningfully impact the world."
- Some things I think this could include that might not immediately come to mind under the words "training setup" include interventions like ensembling and activation engineering
- Also, I think a model could meaningfully impact the world before humans intend for it to be done training. Example: a model becomes misaligned and gains a decisive strategic advantage during training, and interrupts the training process to pursue its goals. Also, all of continual learning.
- So a training story should also talk about why nothing bad will happen along the way?
- "'Training setup,' here, refers to anything done before the model is released, deployed, or otherwise given the ability to meaningfully impact the world."
- Training goal doesn't need to be super precise; how precise it needs to be is complicated, will be discussed in next section
2 subcomponents for each of the two things above, making 4 essential parts to any training story:
- Training goal specification: Mechanistic description of the desired model
- Training goal desirability: Why any model that meets the training goal will be safe and perform the desired task well
- (My addition) There's a universal quantifier here. "For all models that meet the training goal, is safe" is the statement that needs justifying. That's a high bar.
- Training rationale constraints: What constraints the model must satisfy and why the training goal is compatible with those constraints (e.g. fitting the training data perfectly (if trained to zero loss), and being implementable with the selected architecture)
- Training rationale nudges: Why the training setup is likely to produce a model that meets the training goal, despite other things also satisfying the constraints
- Could be "meeting the goal is the simplest way to meet the constraints" (inductive bias arguments)
- Example of all 4 with the cat classifier
How mechanistic does a training goal need to be? [LW · GW]
- Usually want to specify the training goal in as much detail as possible; we can rarely get close to having such a detailed training goal that we could hardcode it
- Want to specify the training goal in a way that makes it as easy as possible to argue both that it is desirable (meets training goal safe) and that the training setup will lead to an outcome which satisfies it
- The latter is best served by having a training goal that is described in ways that we can understand in the context of the training setup
- "The factors that, in my opinion, actually make a training goal specification easier to build a training rationale for aren’t generality, but rather questions like how natural the goal is in terms of the inductive biases of the training process, how much it corresponds to aspects of the model that we know how to look for, how easily it can be broken down into individually checkable pieces, etc."
- A positive and negative example for what a training goal specification should look like to allow for a training rationale to support it: broadly reinforces the idea that more specific/mechanistic is good
- "Ideally, as I discuss later, I’d like to have rigorous sensitivity analyses of things like 'if the training rationale is slightly wrong in this way, by how much do we miss the training goal.'"
Relationship to inner alignment [LW · GW]
- Common AI safety terms like mesa-optimization, inner alignment, and objective misgeneralization are meant to fit into training stories. Evan provides a glossary of common terms, with definitions reworded slightly to better fit with training stories
- Abbreviated glossary:
- Objective misgeneralization: Final model has the desired capabilities from the training goal, but utilizes them for a different purpose than the one in the training goal
- Mesa-optimization: Any situation where the final model internally performs optimization. Particularly concerning is if internal optimization is learned but was not part of the training goal.
- Outer alignment problem: The problem of selecting an objective (e.g. reward/loss function) such that the training goal of “a model that optimizes for that loss/reward function” would be desirable.
- Inner alignment problem: The problem of developing a training setup with a strong rationale for producing a final model which optimizes for the specified objective.
- Deceptive alignment problem: "The problem of constructing a training rationale that avoids models that are trying to fool the training process into thinking that they’re doing the right thing."
- Training stories show that the outer-inner alignment breakdown is not fundamental; we could have a training story that doesn't attempt to specify an objective that is desirable to optimize, and doesn't attempt to train a model to optimize the specific objective, and that model could perform desirable behavior.
Do training stories capture all possible ways of addressing AI safety? [LW · GW]
- Training stories are pretty general, but no. They can't handle things like the following:
- Proposals for building safe AGI without a training step (e.g. non-ML stuff like explicit hierarchical planning)
- Proposals to build safe AGI that attempt to develop confidence in the safety of the final model without a mechanistic story for what it is doing
- Proposals to reduce AI X-risk that don't involve building safe AGI (e.g. persuading AI researchers not to build AGI because it is dangerous)
In The Plan - 2022 Update [LW · GW], John Wentworth says:
I expect we’ll also see more discussion of end-to-end alignment strategies based on directly reading and writing the internal language of neural nets.... Since such strategies very directly handle/sidestep the issues of inner alignment, and mostly do not rely on a reward signal as the main mechanism to incentivize intended behavior/internal structure, I expect we’ll see a shift of focus away from convoluted training schemes in alignment proposals.
It's not clear to me whether interventions like "reading and writing the internal language of neural nets" are supposed to fit within training stories. John does seem to be suggesting that the main part of these alignment proposals is not how the models are trained.
Evaluating proposals for building safe advanced AI [LW · GW]
- We've seen how training stories are constructed, but how should we evaluate a training story? 4 criteria for AGI training stories (not all training stories):
- Training goal alignment: Are all models that meet the training goal good for the world?
- Training goal competitiveness: Are models that meet the training goal competent enough to not be surpassed and obsoleted by other models?
- Training rationale alignment: Would the training setup actually produce a model that meets the training goal?
- Training rationale competitiveness: Is it feasible to implement the described training setup? (Possible reason why not is "requires much more compute/data than alternate training setups.")
Case study: Microscope AI [LW · GW]
- Training setup:
- (Evan includes the training setup within the training story (specifically the rationale), but it seems to me like the proposal is the proposed training setup, and then the training story needs to be told about the setup?)
- Self-supervised learning on a large diverse dataset, while using transparency tools during training to check that the correct training goal (see below) is being learned.
- Training story:
- Goal: Get a purely predictive model that uses human-understandable concepts for prediction.
- No internal optimization
- Once we have this model, we can use interpretability tools to figure out how it is predicting, and we can gain insights that humans can learn from and utilize for improved decision-making.
- Rationale:
- Hopefully, the simplicity biases push self-supervised learning to learn a purely predictive model that doesn't perform optimization, and that uses human-understandable concepts.
- The transparency tools are mainly for catching dangerous agentic optimization and halting the training process if such processes are found.
- Goal: Get a purely predictive model that uses human-understandable concepts for prediction.
- Evaluation:
- Goal alignment: Whether or not a pure predictor is safe is more complicated than it may seem, due to self-referential things. The exact way the goal is specified may be able to rule out these concerns.
- Goal competitiveness: Couple factors to consider here.
- Interpretability tools need to be capable of extracting actually useful info from the model. This might not work, especially if we want info for effective sequential decision-making while the model was just a pure predictor.
- This requires that humanity is ok with not building useful agentic systems, and improved understanding and decision-making are enough.
- I kind of doubt that improved understanding and decision-making are enough.
- Rationale alignment:
- Would self-supervised learning actually produce a pure predictor? One cause for concern is that the world includes optimizers (such as humans, at least sometimes), and we would want this predictor to be capable of making predictions about what those optimizers will do. Training a model to be able to internally model optimizers well enough to predict them may just cause the model to learn to optimize internally.
- Using transparency tools to prevent the model learning optimization (by throwing out models that are found to be optimizers, or by training against the transparency tools) could be bad, as it may result in deceptive optimizers which fool the transparency tools.
- The model is also supposed to use human-understandable concepts, which may not work given that cat classifiers don't use human-like visual heuristics. Maybe human-like-abstraction-use looks like this, which is good near AGI and bad for superintelligence:
- Rationale competitiveness:
- Self-supervised learning is a dominant ML paradigm, so pretty competitive. Using transparency tools might slow things down and reduce competitiveness; advancing automated interpretability would help.
- This is a better analysis of Microscope AI than the one in 11 proposals, because instead of trying to evaluate it according to outer alignment and other concepts that don't really apply, the proposal is evaluated on its own terms.
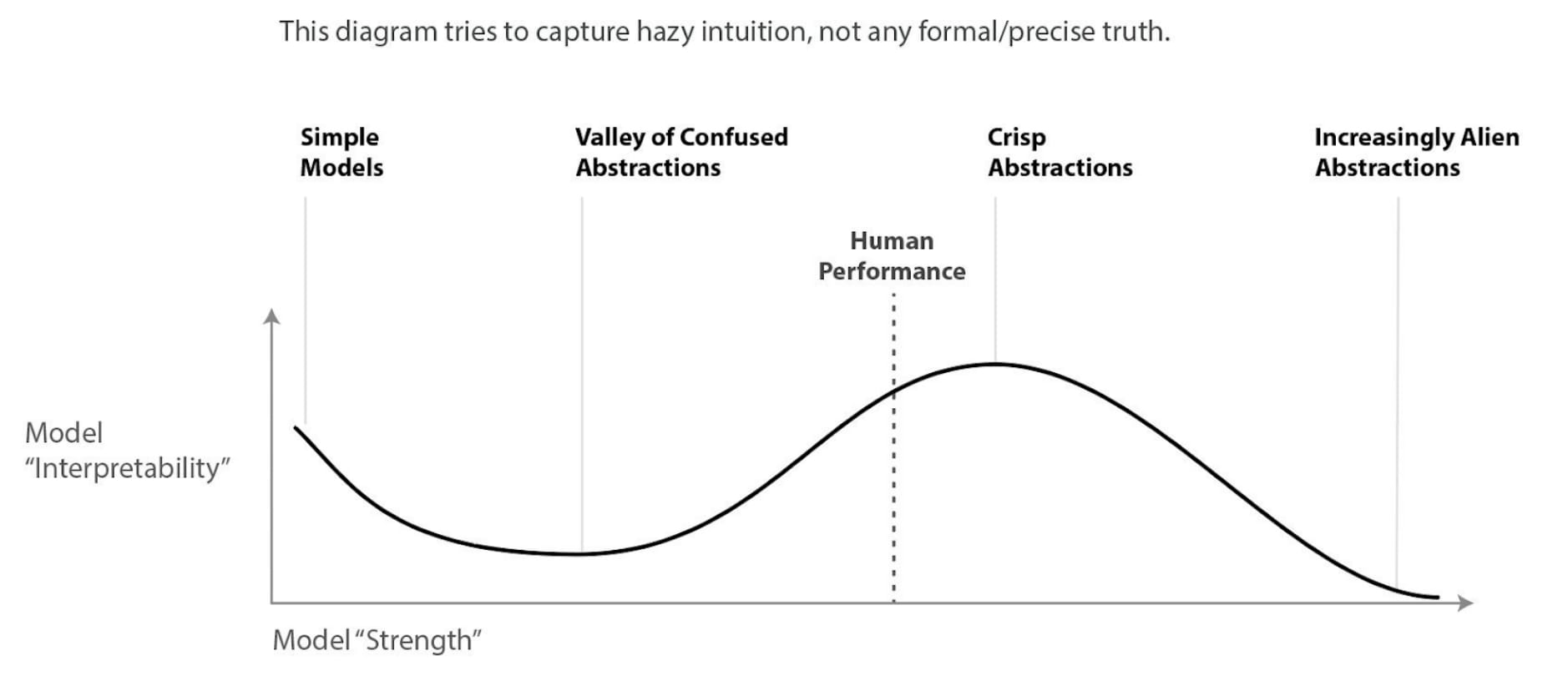
Exploring the landscape of possible training stories [LW · GW]
- This section is a non-exhaustive exploration of broad categories that training goals and training rationales could fall into. There may be many broad categories that the field of AI safety has yet to discover.
First, some training goals. (This part reminds me of John Wentworth's discussion of possible alignment targets here [LW · GW], which I liked quite a bit. That post came out later, but I read it first.)
- Loss-minimizing models: A possible training goal, for people who are very confident they've specified a truly desirable objective, is to get a model that internally optimizes for that objective (e.g. loss function). This can be bad, due to classic outer alignment concerns.
- Fully aligned agents: An agent that cares about everything humans care about and acts to achieve those goals. E.g. ambitious value learning [LW · GW]. But this is a very difficult target, that most people think isn't worth focusing on in our first shot at aligning advanced AI. Instead, we can do something else more achievable to get useful and safe human+ level AI, and then use those to help us get to fully aligned superintelligence later. (Or sacrifice the fully aligned superintelligence goal because we think we'll never get it.)
- I personally think "human values" aren't well-defined, and in my mind fully aligned agents would do something along the lines of "solve morality and act accordingly," which probably works out to "maximize the well-being of conscious creatures." What, did I say something controversial?
- Corrigible agents: We may want AI systems that let themselves be turned off or modified, or help us figure out when it would be good for us to turn them off or modify them. Consider approval-directed agents (though there are ways this could fail to be corrigible).
- Robust instruction-following agents may also fit here?
- Myopic agents: AI agents that preform limited optimization only, such as only optimizing the immediate effect of their next action, rather than having long-term, large-scale goals.
- Simulators: AI system that does nothing other than simulate something else. Things you might want to simulate include HCH (roughly, an infinite tree of humans delegating subtasks and consulting each other), physics (for an AlphaFold-like system), and a human internet user (for a language model).
- Narrow agents: Agents that are highly capable in a specific domain without thinking much or at all about other domains. E.g. STEM AI [LW · GW].
- I think some current systems, like superhuman chess AIs, also fit this category.
- Truthful question-answerers: A non-agent truthful question-answering system that accurately reports what its model of the world says/predicts in human-understandable terms.
Next, some training rationales. These aren't explicitly paired with particular training goals, but there are implicit relationships to classes of training goals.
- Capabilities limitations: Can argue that a particular training setup will give rise to a model that does not have certain dangerous capabilities (e.g. internal optimization, understanding of how to deceive humans), and therefore won't exhibit the dangerous behaviors that require the capability.
- Inductive bias analysis: Can argue that certain behaviors are more likely to be learned than others given a training setup, for reasons other than "lower loss." Often this appeals to some form of simplicity. This is a promising approach, but hard to make strong detailed arguments in advance about what will be learned. But there is a growing literature outlining empirical phenomena that can inform our inductive bias assessments (like deep double descent [LW · GW], lottery tickets, scaling laws, grokking, or distributional generalization).
- "This is especially problematic given how inductive bias analysis essentially requires getting everything right before training begins, as a purely inductive-bias-analysis-based training rationale doesn’t provide any mechanism for verifying that the right training goal is actually being learned during training."
- Transparency and interpretability: If we use transparency tools during training to throw out or disincentivize dangerous models, then our training rationale could include something like "We think that our transparency checks will rule out all simple models that don’t fit the training goal, with all remaining models that don’t fit the goal being too complex according to the inductive biases of the training process to possibly be learned." One great thing about transparency tools is that they could make it possible for us to verify that the right training goal is actually being learned during training, rather than just hoping it will be and leaving training a black box.
- Evan's A transparency and interpretability tech tree [LW · GW] is a good post on various types of interpretability along with discussion of their challenges and limitations. It helped me see what ambitious interpretability could look like.
- Automated oversight: Humans may struggle to label data or use transparency tools; having humans-in-the-loop slows things down, and we can only understand human-understandable concepts. We could perhaps automate these things with competent AIs, including ones that understand the alien abstractions used by the model we're training (maybe a copy of that same model). How can we trust the supervisor AI? That's a challenge; maybe using some recursive oversight methods. For a more thorough exploration of what such an approach might look like, see “Relaxed adversarial training for inner alignment [LW · GW].”
- AI cognitive science: Instead of mechanistic analysis, we could do behavioral analysis of models; test how they act in ways that we think reveal important underlying details. Possibly a less direct and trustworthy source of info than mechanistic interpretability. Might be hard to extrapolate findings to more capable models.
- Precursor checking: Check for some easier-to-check property that is a necessary precursor for bad behavior. E.g. it might be easier to check that a model's planning-horizon length is below a certain threshold, and that might imply that the model isn't being deceptive, while checking for deception more generally may be very difficult. Need to make sure the property is actually a necessary condition.
- Loss landscape analysis: Extension of inductive bias analysis, can help us predict paths through parameter space (rather than just the final local loss minimum). Could be used in conjunction with various other training rationales on this list.
- Game-theoretic/evolutionary analysis: What multi-agent dynamics are likely to be learned? One difficult aspect of this is avoiding the assumption that agents will be optimizing for their specified objectives; agent objectives are typically taken as given when finding equilibria in game theory. Evolutionary analysis does this less; it deals with properties that tend to be selected-for in multi-agent settings, might be useful.
We can use these lists of goals and rationales to categorize past approaches, we can combine existing goals and rationales in new ways, and we can try to come up with new goals and rationales (aided by the observed lack of exhaustivity in these lists).
Training story sensitivity analysis [LW · GW]
We want to analyze how sensitive the outcome of a training setup is to incorrectness in the assumptions that go into its training story. What happens when a training story fails? When one of its assumptions is wrong? Does it fail safely or catastrophically?
The original post contains some examples of what our uncertainties about the assumptions in a training story might look like and how we can have more confidence in some parts of a training story than others.
"Hopefully, as we build better training stories, we’ll also be able to build better tools for their sensitivity analysis so we can actually build real confidence in what sort of model our training processes will produce."
0 comments
Comments sorted by top scores.