Teachers: Much More Than You Wanted To Know
post by Scott Alexander (Yvain) · 2016-05-19T06:13:32.000Z · LW · GW · 3 commentsContents
I. II. III. IV. V. VI. None 3 comments
[Epistemic status: This is really complicated, this is not my field, people who have spent their entire lives studying this subject have different opinions, and I don’t claim to have done more than a very superficial survey. I welcome corrections on the many inevitable errors.]
I.
Newspapers report that having a better teacher for even a single grade (for example, a better fourth-grade teacher) can improve a child’s lifetime earning prospects by $80,000. Meanwhile, behavioral genetics studies suggest that a child’s parents have minimal (non-genetic) impact on their future earnings. So one year with your fourth-grade teacher making you learn fractions has vast effects on your prospects, but twenty-odd years with your parents shaping you at every moment doesn’t? Huh? I decided to try to figure this out by looking into the research on teacher effectiveness more closely.
First, how much do teachers matter compared to other things? To find out, researchers take a district full of kids with varying standardized test scores and try to figure out how much of the variance can be predicted by what school the kids are in, what teacher’s class the kids are in, and other demographic factors about the kids. So for example if the test scores of two kids in the same teacher’s class were on average no more similar than the test scores of two kids in two different teachers’ classes, then teachers can’t matter very much. But if we were consistently seeing things like everybody in Teacher A’s class getting A+s and everyone in Teacher B’s class getting Ds, that would suggest that good teachers are very important.
Here are the results from three teams that tried this (source, source, source):
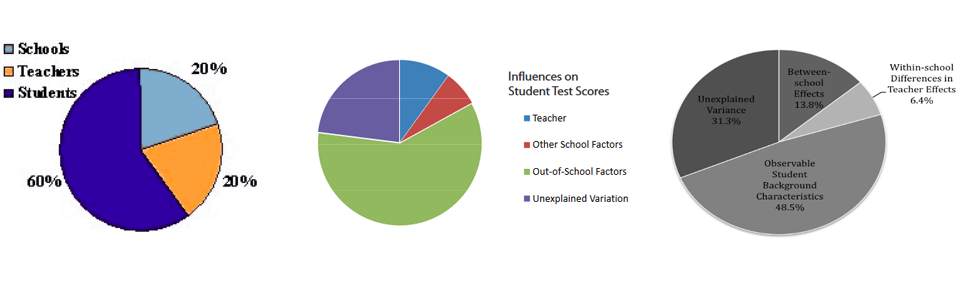
These differ a little in that the first one assumes away all noise (“unexplained variance”) and the latter two keep it in. But they all agree pretty well that individual factors are most important, followed by school and teacher factors of roughly equal size. Teacher factors explain somewhere between 5% and 20% of the variance. Other studies seem to agree, usually a little to the lower end. For example, Goldhaber, Brewer, and Anderson (1999) find teachers explain 9% of variance; Nye, Konstantopoulos, and Hedges (2004) find they explain 13% of variance for math and 7% for reading. The American Statistical Association summarizes the research as “teachers account for about 1% to 14% of the variability in test scores”, which seems about right.
So put more simply – on average, individual students’ level of ability grit is what makes the difference. Good schools and teachers may push that a little higher, and bad ones bring it a little lower, but they don’t work miracles.
(remember that right now we’re talking about same-year standardized test scores. That is, we’re talking about how much your fourth-grade history teacher affects your performance on a fourth-grade history test. If teacher effects show up anywhere, this is where it’s going to be.)
Just as it’s much easier to say “this is 40% genetic” than to identify particular genes, so it’s much easier to say “this is 10% dependent on school-level factors and 10% based on teacher-level factors” then to identify what those school-level and teacher-level factors are. The Goldhaber study above tries its best, but the only school-level variable they can pin down is that having lots of white kids in your school improves test scores. And as far as I can tell, they don’t look at socioeconomic status of the school or its neighborhood, which is probably what the white kids are serving as a proxy for. Even though these “school level effects” are supposed to be things like “the school is well-funded” or “the school has a great principal”, I worry that they’re capturing student effects by accident. That is, if you go to a school where everyone else is a rich white kid, chances are that means you’re a rich white kid yourself. Although they try to control for this, having a couple of quantifiable variables like race and income probably doesn’t entirely capture the complexities of neighborhood sorting by social class.
In terms of observable teacher-level effects, the only one they can find that makes a difference is gender (female teachers are better). Teacher certification, years of experience, certification, degrees, et cetera have no effect. This is consistent with most other research, such as Miller, McKenna, and McKenna (1998). A few studies that we’ll get to later do suggest teacher experience matters; almost nobody wants to claim certifications or degrees do much.
One measurable variable not mentioned here does seem to have a strong ability to predict successful teachers. I’m not able to access these studies directly, but according to the site of the US Assistant Secretary of Education:
The most robust finding in the research literature is the effect of teacher verbal and cognitive ability on student achievement. Every study that has included a valid measure of teacher verbal or cognitive ability has found that it accounts for more variance in student achievement than any other measured characteristic of teachers (e.g., Greenwald, Hedges, & Lane, 1996; Ferguson & Ladd, 1996; Kain & Singleton, 1996; Ehrenberg & Brewer, 1994).
So far most of this is straightforward and uncontroversial. Teachers account for about 10% of variance in student test scores, it’s hard to predict which teachers do better by their characteristics alone, and schools account for a little more but that might be confounded. In order to say more than this we have to have a more precise way of identifying exactly which teachers are good, which is going to be more complicated.
II.
Suppose you want to figure out which teachers in a certain district are the best. You know that the only thing truly important in life is standardized test scores [citation needed], so you calculate the average test score for each teacher’s class, then crown whoever has the highest average as Teacher Of The Year. What could go wrong?
But you’ll probably just give the award to whoever teaches the gifted class. Teachers have classes with very different ability, and we already determined that innate ability grit explains more variance than teacher skill, so teachers who teach disadvantaged children will be at a big, uh, disadvantage.
So okay, back up. Instead of judging teachers by average test score, we can judge them by the average change in test score. If they start with a bunch of kids who have always scored around twentieth percentile, and they teach them so much that now the kids score at the fortieth percentile, then even though their kids are still below average they’ve clearly done some good work. Rank how many percentile points on average a teacher’s students go up or down during the year, and you should be able to identify the best teachers for real this time.
Add like fifty layers of incomprehensible statistics and this is the basic idea behind VAM (value-added modeling), the latest Exciting Educational Trend and the lynchpin of President Obama’s educational reforms. If you use VAM to find out which teachers are better than others, you can pay the good ones more to encourage them to stick around. As for the bad ones, VAM opponents are only being slightly unfair when they describe the plan as “firing your way to educational excellence”.
A claim like “VAM accurately predicts test scores” is kind of circular, since test scores are what we used to determine VAM. But I think the people in this field try to use the VAM of class c to predict the student performance of class c + 1, or other more complicated techniques, and Chetty, Rothstein, and Rivkin, Hanushek, and Kane all find that a one standard deviation increase in teacher VAM corresponds to about a 0.1 standard deviation increase in student test scores.
Let’s try putting this in English. Consider an average student with an average teacher. We expect her to score at exactly the 50th percentile on her tests. Now imagine she switched to the best teacher in the whole school. My elementary school had about forty teachers, so this is 97.5th percentile eg two standard deviations above the mean. A teacher whose VAM is two standard deviations above the mean should have students who score on average 0.2 standard deviations above the mean. Instead of scoring at the 50th percentile, now she’ll score at the 58th percentile.
Or consider the SAT, which is not the sort of standardized test involved in VAM but which at least everybody knows about. Each of its subtests is normed to a mean of 500 and an SD of 110. Our hypothetical well-taught student would go from an SAT of 500 to an SAT of 522. Meanwhile, average SAT subtest score needed to get into Harvard is still somewhere around 740. So this effect is nonzero but not very impressive.
But what happens if we compound this and give this student the best teachers many years in a row? Sanders and Rivers (also Jordan, Mendro, and Weerasinghe) argue the effects are impressive and cumulative. They compare students in Tennessee who got good teachers three years in a row to similar students who got bad teachers three years in a row (good = top quintile; bad = bottom quintile, so only 1/125 students was lucky or unlucky enough to qualify). The average bad-bad-bad student got scores in the 29th percentile; the average good-good-good student got scores in the 83rd percentile – which based on the single-teacher results looks super-additive. This is starting to sound a lot more impressive, and maybe Harvard-worthy after all. In fact, occasionally it is quoted as “four consecutive good teachers would close the black-white achievement gap” (I’m not sure whether this formulation requires also assigning whites to four consecutive bad teachers).
A RAND education report criticizes these studies as “using ad hoc methods” and argue that they’re vulnerable to double-counting student achievement. That is, we know that this teacher is the best because her students get great test scores; then later on we return and get excited over the discovery that the best teachers’ students get great test scores. Sanders and Rivers did some complicated things that ought to adjust for that; RAND runs simulations and finds that depending on the true size of teacher effects vs. student effects, those complicated things may or may not work. They conclude that “[Sanders and Rivers] provide evidence of the existence and persistence of teacher or classroom effects, but the size of the effects is likely to be somewhat overstated”.
Gary Rubinstein thinks he’s debunked Sanders and Rivers style studies. I strongly disagree with his methods – he seems to be saying that the correlation between good teaching and good test scores isn’t exactly one and therefore doesn’t matter – but he offers some useful data. Just by eyeballing and playing around with it, it looks like most of the gain from these “three consecutive great teachers” actually comes from the last great teacher. So the superadditivity might not be quite right, and Sanders and Rivers might just be genuinely finding bigger teacher effects than anybody else.
At what rate do these gains from good teachers decay?
They decay pretty fast. Jacob, Lefgren and Sims find that only 25% of gains carry on to the next year, and only 15% to the year after that. That is, if you had a great fourth grade teacher who raised your test scores by x points, in fifth grade your test scores will be 0.25x higher than they would otherwise have been. Kane and Rothstein find much the same. A RAND report suggests 20% persistence after one year and 10% persistence after two. Jacob, Lefgren, and Sims find that only 25% of gains remain after one year, and about 13% after two years, after which it drops off much more slowly. All of this contradicts Sanders and Rivers pretty badly.
None of these studies can tell us whether the gains go all the way to zero after a long enough time. Chetty does these calculations and finds that they stabilize at 25% of their original value. But this number is higher than the two-year number for most of the other studies, plus Chetty is famous for getting results that are much more spectacular and convenient than anybody else’s. I am really skeptical here. I remember a lot more things about last year than I do about twenty years ago, and even though I am pretty sure that my sixth grade teacher (for some weird reason) taught our class line dancing, I can’t remember a single dance step. And remember Louis Benezet’s early 20th century experiments with not teaching kids any math at all until middle school – after a year or two they were just as good as anyone else, suggesting a dim view of how useful elementary school math teachers must be. And even Chetty doesn’t really seem to want to argue the point, saying that his results “[align] with existing evidence that improvements in education raise contemporaneous scores, then fade out in later scores”.
In summary, I think there’s pretty strong evidence that a +1 SD increase in teacher VAM can increase same-year test scores by + 0.1 SD, but that 50% – 75% of this effect decays in the first two years. I’m less certain how much these numbers change when one gets multiple good or bad teachers in a row, or how fully they decay after the first two years.
III.
When I started looking for evidence about how teachers affected children, I expected teachers’ groups and education specialists to be pushing all the positive results. After all, what could be better for them than solid statistical proof that good teachers are super valuable?
In fact, these groups are the strongest opponents of the above studies – not because they doubt good teachers have an effect, but because in order to prove that effect you have to concede that good teaching is easy to measure, which tends to turn into proposals to use VAM to measure teacher performance and then fire underperformers. They argue that VAM is biased and likely to unfairly pull down teachers who get assigned less intelligent lower-grit kids.
It’s always fun to watch rancorous academic dramas from the outside, and the drama around VAM is really a level above anything else I’ve seen. A typical example is the blog VAMboozled! with its oddly hypnotic logo and a steady stream of posts like Kane Is At It Again: “Statistically Significant” Claims Exaggerated To Influence Policy. Historian/researcher Diane Ravitch doesn’t have quite as cute an aesthetic, but she writes things like:
VAM is Junk Science. Looking at children as machine-made widgets and looking at learning solely as standardized test scores may thrill some econometricians, but it has nothing to do with the real world of children, learning, and teaching. It is a grand theory that might net its authors a Nobel Prize for its grandiosity, but it is both meaningless in relation to any genuine concept of education and harmful in its mechanistic and reductive view of humanity.
But tell us how you really feel.
I was originally skeptical of this, but after reading enough of these sites I think they have some good points about how VAM isn’t always a good measure.
First, it seems to depend a lot on student characteristics; for example, it’s harder to get a high VAM in a class full of English as a Second Language students. It makes perfect sense that ESL students would get low test scores, but since VAM controls for prior achievement you might expect them to get the same VAM anyway. They don’t. Also, a lot of VAM models control for student race, gender, socioeconomic status, et cetera. I guess this is better than not doing this, but it seems to show a lack of confidence – if controlling for prior achievement was enough, you wouldn’t need to control for these other things. But apparently people do feel the need to control for this stuff, and at that point I bring up my usual objection that you can never control for confounders enough, and also all to some degree these things are probably just lossy proxies for genetics which you definitely can’t control for enough.
Maybe because of this, there’s a lot of noise in VAM estimates. Goldhaber & Hansen (2013) finds that a teacher’s VAM in year t is correlated at about 0.3 with their VAM in year t + 1. A Gates Foundation study also found reliabilities from 0.19 to 0.4, averaging about 0.3. Newton et al get slightly higher numbers from 0.4 to 0.6; Bessolo a wider range from 0.2 to 0.6. But these are all in the same ballpark, and Goldhaber and Hanson snarkily note that standardized tests aimed to assess students usually need correlations of 0.8 to 0.9 to be considered valid (the SAT, for example, is around 0.87). Although this suggests there’s some component of VAM which is stable, it can’t be considered to be “assessing” teachers in the same way normal tests assess students.
Even if VAM is a very noisy estimate, can’t the noise be toned down by averaging it out over many years? I think the answer is yes, and I think the most careful advocates of VAM want to do this, but President Obama wants to improve education now and a lot of teachers don’t have ten years worth of VAM estimates.
Also, some teachers complain that even averaging it out wouldn’t work if there are consistent differences in student assignment. For example, if Ms. Andrews always got the best students, and Mr. Brown always got the worst students, then averaging ten years is just going to average ten years of biased data. Proponents argue that aside from a few obvious cases (the teacher of the gifted class, the teacher of the ESL class) this shouldn’t happen. They can add school-fixed effects into their models (eg control for average performance of students at a particular school), leaving behind only teacher effects. And, they argue, which student in a school gets assigned which teacher ought to be random. Opponents argue that it might not be, and cite Paufler and Amrein-Beardsley‘s survey of principals, in which the principals all admit they don’t assign students to classes randomly. But if you look at the study, the principals say that they’re trying to be super-random – ie deliberately make sure that all classes are as balanced as possible. Even if they don’t 100% achieve this goal, shouldn’t the remaining differences be pretty minimal?
Maybe not. Rothstein (2009) tries to “predict” students’ fourth-grade test scores using their fifth-grade teacher’s VAM and finds that this totally works. Either schools are defying the laws of time and space, or for some reason the kids who do well in fourth-grade are getting the best fifth-grade teachers. Briggs and Domingue not only replicate these effects, but find that a fifth-grade teacher’s “effects” on her students in fourth-grade is just as big as her effect on her students when she is actually teaching them, which would suggest that 100% of VAM is bias. Goldhaber has an argument for why there are statistical reasons this might not be so damning, which I unfortunately don’t have enough understanding grit to evaluate.
Genetics might also play a role in explaining these results (h/t Spotted Toad’s excellent post on the subject). A twin study by Robert Plomin does the classical behavioral genetics thing to VAM and finds that individual students’ nth grade VAM is about 40% to 50% heritable. That is, the change in your test scores between third to fourth grade will probably be more like the change in your identical twin’s test scores than like the change in your fraternal twin’s test scores.
At first glance, this doesn’t make sense – since VAM controls for past performance, shouldn’t it be a pretty pure measure of your teacher’s effectiveness? Toad argues otherwise. One of those Ten Replicated Findings From Behavioral Genetics is that IQ is more shared environmental in younger kids and more genetic in older kids. In other words, when you’re really young, how smart you are depends on how enriched your environment is; as you grow older, it becomes more genetically determined.
So suppose that your environment is predisposing you to an IQ of 100, but your genes are predisposing you to an IQ of 120. And suppose (pardon the oversimplification) that at age 5 your IQ is 100, at age 15 it’s 120, and change between those ages is linear. Then every year you could expect to gain 2 IQ points. Now suppose there’s another kid whose environment is predisposing her to an IQ of 130, but whose genes are predisposing her to an IQ of 90. At age 5 her IQ is 130, at age 15 it’s 90, and so every year she is losing 4 IQ points. And finally, suppose that your score on standardized tests is exactly 100% predicted by your IQ. Since you gain two points every year, in fifth grade you’ll gain two points on your test, and your teacher will look pretty good. She’ll get a good VAM, a raise, and a promotion. Since your friend loses four points every year, in fifth grade she’ll lose four points on her test, and her teacher will look incompetent and be assigned remedial training.
This critique meshes nicely with the Rothstein test. Since you’re gaining 2 points every year, Prof. Rothstein can use your 5th grade gains of +2 points to accurately predict your fourth grade gain of +2 points. Then he can use your friend’s 5th grade loss of -4 points to accurately predict her fourth grade loss of -4 points.
This is a very neat explanation. My only concern is that it doesn’t explain decay effects very well. If a fifth grade teacher’s time-bending effect on students in fourth grade is exactly the same as her non-time-bending effect on students in fifth grade, how come her effect on her students once they graduate to sixth grade will only be 25% as large as her fifth grade effects? How come her seventh-grade effects will be smaller still? Somebody here has to be really wrong.
It would be nice to be able to draw all of this together by saying that teachers have almost no persistent effects, and the genetic component identified by Plomin and pointed at by Rothstein represents the 15 – 25% “permanent” gain identified by Chetty and others which so contradicts my lack of line dancing memories. But that would be just throwing out Briggs and Domingue’s finding that the Rothstein effect explains 100% of identified VAM.
One thing I kept seeing in the best papers on this was an acknowledgement that instead of arguing “VAMs are biased!” versus “VAMs are great!”, people should probably just agree that VAMs are biased, just like everything else, and start figuring out ways to measure exactly how biased they are, then use that number to determine what purposes they are or aren’t appropriate for. But I haven’t seen anybody doing this in a way I can understand.
In summary, there are many reasons to be skeptical of VAM. But some of these reasons contradict each other, and it’s not clear that we should be infinitely skeptical. A big part of VAM is bias, but there might also be some signal within the noise, especially when it’s averaged out over many years.
IV.
So let’s go back to that study that says that a good fourth grade teacher can earn you $89,000. The study itself is Chetty, Friedman, and Rockoff (part 1, part 2). You may recognize Chetty as a name that keeps coming up, usually attached to findings about as unbelievable as these ones.
Bloomberg said that “a truly great” teacher could improve a child’s earnings by $80,000, but I think this is mostly extrapolation. The number I see in the paper is a claim that a 1 SD better fourth-grade teacher can improve lifetime earnings by $39,000, so let’s stick with that.
This sounds impressive, but imagine the average kid works 40 years. That means it’s improving yearly earnings by about $1,000. Of note, the study didn’t find this. They found that such teachers improved yearly earnings by about $300, but their study population was mostly in their late twenties and not making very much, and they extrapolated that if good teachers could increase the earnings of entry-level workers by $300, eventually they could increase the earnings of workers with a little more experience by $1000. The authors use a lot of statistics to justify this assumption which I’m not qualified to assess. But really, who cares? The fact that having a good fourth grade teacher can improve your adult earnings any measurable amount is the weird claim here. Once I accept that, I might as well accept $300, $1,000, or $500,000.
And here’s the other weird thing. Everyone else has found that teacher effects on test scores decay very quickly over time. Chetty has sort of found that up to 25% of them persist, but he doesn’t really seem interested in defending that claim and agrees that probably test scores just fade away. Yet as he himself admits, good teachers’ impact on earnings works as if there were zero fadeout of teacher effects. He and his co-authors write:
Our conclusion that teachers have long-lasting impacts may be surprising given evidence that teachers’ impacts on test scores “fade out” very rapidly in subsequent grades (Rothstein 2010, Carrell and West 2010, Jacob, Lefgren, and Sims 2010). We confirm this rapid fade-out in our data, but find that teachers’ impacts on earnings are similar to what one would predict based on the cross-sectional correlation between earnings and contemporaneous test score gains.
They later go on to call this a “pattern of fade-out and re-emergence”, but this is a little misleading. The VAM never re-emerges on test scores. It only shows up in the earnings numbers.
All of this is really dubious, and it seems like Section III gives us an easy way out. There’s probably a component of year-to-year stable bias in VAM, such that it captures something about student quality, maybe even innate ability, rather than just teacher quality. It sounds very easy to just say that this is the component producing Chetty’s finding of income gains at age 28; students who have higher innate ability in fourth grade will probably still have it in their twenties.
Chetty is aware of this argument and tries to close it off. He conducts a quasi-experiment which he thinks replicates and confirms his original point: what happens when new teachers enter the school?
The thing we’re most worried about is bias in student selection to teachers. If we take an entire grade of a school (for example, if a certain school has three fifth-grade teachers, we take all three of them as a unit) this should be immune to such effects. So Chetty looks at entire grades as old teachers retire and new teachers enter. In particular, he looks at such grades when a new teacher transfers from a different school. That new transfer teacher already has a VAM which we know from his work at the other school, which will be either higher or lower than the average VAM of his new school. If it’s higher and VAM is real, we should expect the average VAM of that grade of his new school to go up a proportionate amount. If it’s lower and VAM is real, we should expect the average VAM of that grade of his new school to go down a proportionate amount. Chetty investigates this with all of the transfer teachers in his data, finds this is in fact what happens, and finds that if he estimates VAM from these transfers he gets the same number (+ $1000 in earnings) that he got from the normal data. This is impressive. Maybe even too impressive. Really? The same number? So there’s no bias in the normal data? I thought there was a lot of evidence that most of it was bias?
Rothstein is able to replicate Chetty’s findings using data from a different district, but then he goes on to do the same thing on Chetty’s quasi-experiment as he did on the normal VAMs, with the same results. That is, you can use the amount a school improves when a great new fifth-grade teacher transfers in to predict that teacher’s students’ fourth-grade performance. Not perfectly. But a little. For some reason, teacher transfers are having the same freaky time-bending effects as other VAM. Rothstein mostly explains this by saying that Chetty incorrectly excluded certain classes and teachers from his sample, although I don’t fully understand this argument. He also gives one other example of when this might happen: suppose that a neighborhood is gentrifying. The new teachers who transfer in after the original teachers retire will probably be a better class of professional lured in by the improving neighborhood. And the school’s student body will also probably be more genetically and socioeconomically advantaged. So better transfer teachers will be correlated with higher-achieving kids, but they won’t have caused such high achievement.
After this came an increasingly complicated exchange between Rothstein and Chetty that I wasn’t able to follow. Chetty, Friedman, and Rockoff wrote a 52 page Response To Rothstein where they argued that Rothstein’s methodology would find retro-causal effects even in a fair experiment where none should exist. According to a 538 article on the debate, a couple of smart people (albeit smart people who already support VAMs and might be biased) think that Chetty’s response makes sense, and even Rothstein agrees it “could be” true. 538 definitely thought the advantage in this exchange went to Chetty. But Rothstein responded with a re-replication of his results that he says addresses Chetty’s criticisms but still finds the retro-causal effects indicating bias; as far as I know Chetty has not responded and nobody has weighed in to give me an expert opinion on whether or not it’s right.
My temptation would usually be to say – here are some really weird results that can’t possibly be true which we want to explain away, here’s a widely-respected Berkeley professor of economics who says he’s explained them away, great, let’s forget about the whole thing. But there’s one more experiment which I can’t dismiss so easily.
V.
Project STAR (Student Teacher Achievement Ratio) was a big educational experiment in the 80s and 90s to see whether or not smaller class size improved student performance. That’s a whole different can of worms, but the point is that in order to do this experiment for a while they randomized children to kindergarten classes within schools across 79 different schools. Since one of the biggest possible sources of bias for these last few studies has been possible nonrandom assignment of students to teachers, these Tennessee schools were an opportunity to get much better data than were available anywhere else.
So Chetty, Friedman, Higer, Saez, Schanzenbach, and Yagan analyzed the STAR data. They tried to do a lot of things with predicting earnings based on teacher experience, teacher credentials, and other characteristics, and it’s a bit controversial whether they succeeded or not – see Bryan Caplan’s analysis (1, 2) for more. Caplan is skeptical of a lot of the study, but one part he didn’t address – and which I find most convincing – is based on something a lot like VAM.
Because of the random assignment, Chetty et al don’t have to do full VAM here. It looks like their measure of kindergarten teacher quality is just the average of all their students’ test scores (wait, kindergarteners are taking standardized tests now? I guess so.) When they’re using teacher quality to predict the success of specific students, they use the average of all the test scores except that of the student being predicted, in order to keep it fair.
They find that the average test score of all the other students in your class, compared against the average score of all the students in other randomly assigned classes in your school, predicts your own test score. “A one percentile increase in entry-year class quality is estimated to raise own test scores by 0.68 percentiles, confirming that test scores are highly correlated across students within a classroom”. This fades to approximately zero by fourth grade, confirming that the test-score-related benefits of having a good teacher are transient and decay quickly. But, students assigned to a one-percentile-higher class have average earnings that are 0.4% higher at age 25-27! And they say that this relationship is linear! So for example, the best kindergarten teacher in their dataset caused her class to perform at the 70th percentile on average, and these students earned about $17000 on average (remember, these are young entry-level workers in Tennessee) compared to the $15500 or so of their more average-kindergarten-teacher-having peers. Just their kindergarten teacher, totally apart from any other teacher in their life history, increased their average income 10%. Really, Chetty et al? Really?
But as crazy as it is, this study is hard to poke holes in. Even in arguing against it, Caplan notes that “it’s an extremely impressive piece” that “the authors are very careful”, and that it’s “one of the most impressive empirical papers ever written”. The experimental randomization means we can’t apply most of the usual anti-VAM measures to it. I don’t know, man. I just don’t know.
Okay, fine. I have one really long-shot possibility. Chetty et al derive their measure for teacher quality from the performance of all of the students in a class, excluding each student in turn as they try to predict his or her results. But this is only exogenous if the student doesn’t affect his or her peers’ test scores. But it’s possible some students do affect their peers’ test scores. If a student is a behavioral problem, they can screw up the whole rest of their class. Carrell finds that “exposure to a disruptive peer in classes of 25 during elementary school reduces earnings at age 26 by 3 to 4 percent”. Now, this in itself is a crazy, hard-to-believe study. But if we accept this second crazy hard-to-believe study, it might provide us with a way of attacking the first crazy hard-to-believe study. Suppose we have a really screwed-up student who is always misbehaving in class and disrupting the lesson. This lowers all his peers’ test scores and makes the teacher look low-quality. Then that kid grows up and remains screwed-up and misbehaving and doesn’t get as good a job. If this is a big factor in the differences in performances between classes, then so-called “teacher quality” might be conflated with a measure of how many children in their classes are behavioral problems, and apparent effects of teacher quality on earnings might just represent that misbehaving kids tend to become low-earning adults. I’m not sure if the magnitude of this effect checks out, but it might be a possibility.
But if we can’t make that work, we’re stuck believing that good kindergarten teachers can increase your yearly earnings by thousands of dollars. What do we make of that?
Again, everybody finds that test score gains do not last nearly that long. So it can’t be that kindergarten teachers provide you with a useful fund of knowledge which you build upon later. It can’t even be that kindergarten teachers stimulate and enrich you which raises your IQ or makes you love learning or anything like that. It has to be something orthogonal to test scores and measurable intellectual ability.
Chetty et al’s explanation is that teachers also teach “non-cognitive skills”. I can’t understand the regressions they use, but they say that although a one percentile increase in kindergarten class quality has a statistically insignificant increase (+ 0.05 percentiles) on 8th grade test scores, it has a statistically significant increase (+0.15 percentiles) on 8th grade non-cognitive scores (“non-cognitive scores” in this case are a survey where 8th grade teachers answer questions like “does this student annoy others?”) They then proceed to demonstrate that the persistence of these non-cognitive effects do a better job of predicting the earning gains than the test scores do. They try to break these non-cognitive effects into four categories: “effort”, “initiative”, “engagement” and “whether the student values school”, but the results are pretty boring and about equally loaded on all of them.
This does go together really well with my “behavioral problem” theory of the kindergarten class-earnings effect. The “quality” of a student’s kindergarten class, which might have more to do with the number of students who were behavioral problems in it than anything else, doesn’t correlate with future test scores but does correlate with future behavioral problems. It also seems to match Plomin’s point about how very early test scores are determined by environment, but later test scores are determined by genetics. A poor learning environment might be a really big deal in kindergarten, but stop mattering as much later on.
But this also goes together with some other studies that have found the same. The test scores gains from pre-K are notorious for vanishing after a couple of years, but a few really big preschool studies like the Perry Preschool Program found that such programs do not boost IQ but may have other effects (though to complicate matters, apparently Perry did boost later-life standardized test scores, just not IQ scores, and to further complicate matters, other studies find children who went to pre-K have worse behavior). This also sort of reminds me of some of the very preliminary research I’ve been linking to recently suggesting that excessively early school starting ages seem to produce an ADHD-like pattern of bad behavior and later-life bad effects, which I was vaguely willing to attribute to overchallenging kids’ brains too early while they’re still developing. If I wanted to be very mean (and I do!) I could even say that all kindergarten is a neurological insult that destroys later life prospects because of forcing students to overclock their young brains concentrating on boring things, but good teachers can make this less bad than it might otherwise be by making their classes a little more enjoyable.
But even if this is true, it loops back to the question I started with: there’s strong evidence that parents have relatively little non-genetic impact on their childrens’ life outcomes, but now we’re saying that even a kindergarten teacher they only see for a year does have such an impact? And what’s more, it’s not even in the kindergarten teacher’s unique area of comparative advantage (teaching academic subjects), but in the domain of behavioral problems, something that parents have like one zillion times more exposure to and power over?
I don’t know. I still find these studies unbelievable, but don’t have the sort of knock-down evidence to dismiss them that I’d like. I’m really impressed with everybody participating in this debate, with the quality of the data, and with the ability to avoid a lot of the usual failure modes. It’s just not enough to convince me of anything yet.
VI.
In summary: teacher quality probably explains 10% of the variation in same-year test scores. A +1 SD better teacher might cause a +0.1 SD year-on-year improvement in test scores. This decays quickly with time and is probably disappears entirely after four or five years, though there may also be small lingering effects. It’s hard to rule out the possibility that other factors, like endogenous sorting of students, or students’ genetic potential, contributes to this as an artifact, and most people agree that these sorts of scores combine some signal with a lot of noise. For some reason, even though teachers’ effects on test scores decay very quickly, studies have shown that they have significant impact on earning as much as 20 or 25 years later, so much so that kindergarten teacher quality can predict thousands of dollars of difference in adult income. This seemingly unbelievable finding has been replicated in quasi-experiments and even in real experiments and is difficult to banish. Since it does not happen through standardized test scores, the most likely explanation is that it involves non-cognitive factors like behavior. I really don’t know whether to believe this and right now I say 50-50 odds that this is a real effect or not – mostly based on low priors rather than on any weakness of the studies themselves. I don’t understand this field very well and place low confidence in anything I have to say about it.
Further reading: Institute of Education Science summary, Edward Haertel’s summary, TTI report, Adler’s critique of Chetty, American Statistical Society’s critique of Chetty/VAM, Chetty’s response, Ballou’s critique of Chetty
3 comments
Comments sorted by top scores.
comment by Jason Hise (jason-hise) · 2018-01-25T19:14:50.706Z · LW(p) · GW(p)
It strikes me as a completely reasonable hypothesis that effect on income is based on the behavior students learn to adopt in a classroom rather than on what is learned. This fits well with how the value of a college degree is often less about the specific material which is learned and quickly forgotten, and more about signaling that you have the capacity to be productive and do the tasks you are assigned over multiple years to achieve a goal.
The classroom is a much better proxy for a future work environment than life at home... you have peers/co-workers being given tasks by an authority figure, and developing the skills for navigating that political environment successfully is likely to transfer later in life. If you have a teacher or classroom environment that can successfully teach you how to ‘play the game’ (part of which will be learning how to get good test scores even if the knowledge isn’t retained), you will probably grow up better able to convince your future employer to hire you, or to convince them that you are valuable and worth paying more.
comment by Ben (ben-lang) · 2023-02-02T19:06:36.382Z · LW(p) · GW(p)
All very interesting.
The behavioural problems idea theory could be tested by looking not at the average (mean) earning in later life but the median for each class.
So in a class of 15, one child has very poor behaviour. All of them have slightly lower test scores that year. 20 years later the other 14 get ordinary jobs for the area/cohort, but that adult who was a naughty child is maybe unemployed, in prison or employed in a job that pays less than normal for the area/cohort. They bring the mean down. But, are the other 14 still where they would be? If they are unmoved then the median will not have shifted much.
In a wider sense. The people doing these studies are (it sounds like) all doing proper and careful statistics. Unfortunately the great majority of school administrators/principles etc. are not native statisticians, and work in quite a politically charged environment. This means that even well-researched, careful studies of thing like "VAM" can be damaging to teachers careers (even good teachers) and damaging to the education system at large.
Here in the UK the government decided that during COVID they would ask teachers to predict the exam results students would have got had the exams not been cancelled. The predictions were (on average) higher than the previous year, so they programmed a computer to change the grades until the statistical distribution was the same as the year before on a school by school basis. The most extreme case flagged was a small language school where only one student would have done an exam. They were awarded something like a D, because the only exam ever previously sat at that school had been a D result. I have a friend who is a teacher who was ordered to set up an internal test of about 5 physics students (special needs school. Small classes). Then the computer (and computer like administrators) were all very unhappy. She was warned by one system that 0% failure was way way way too low, while another freaked out about the one test with a 20% failure rate. She claims none of these people seemed to realise that 10% of 5 was not possible - even when it was explained.
Long-winded way of saying that even if VAM is completely accurate, with no artefacts, then it is still probably a bad idea to hire/fire teachers based off of it. Just because the people doing that process are not equipped with the statistical knowledge to implement the process correctly.
comment by Emiya (andrea-mulazzani) · 2021-01-15T15:01:01.334Z · LW(p) · GW(p)
And here’s the other weird thing. Everyone else has found that teacher effects on test scores decay very quickly over time. Chetty has sort of found that up to 25% of them persist, but he doesn’t really seem interested in defending that claim and agrees that probably test scores just fade away. Yet as he himself admits, good teachers’ impact on earnings works as if there were zero fadeout of teacher effects.
Students are pretty short-sighted and high school seems to be designed everywhere to have them worry only about the next test rather than their education as a whole.
I'm speaking from personal experience, but when I think back to a subject I studied in high school I remember nearly only what I learned with good teachers, and nothing of what I learned with bad ones.
A single good teacher makes me now remember a subject with some amount of interest, if I had none it's significantly harder to feel something like that.
I had to study a second time nearly all of the high school knowledge I needed to use in my university, so I think the attitude toward a subject (or the experience of learning) lasts a lot more than the notions you needed to fork out for a test.
When you are in high school, you have no say in what you have to study and get graded all the time, so I guess a new teacher can make you dislike a subject you liked the year before pretty fast.
More generally, it feels to me like, from these findings, lots and lots of stuff that happens in your education affects by a lot your income. Basically we'd expect to see that the possible income values are all over the place. I'd suspect that this means that whatever control were put in place for these studies weren't enough, and that a many factors that cause probabilistic income shifts and the possible stuff that might happen in a single year of preschool/high-school education weren't adequately controlled for and there's something subtle that's screwing up everyone's results.
In fact, these groups are the strongest opponents of the above studies – not because they doubt good teachers have an effect, but because in order to prove that effect you have to concede that good teaching is easy to measure, which tends to turn into proposals to use VAM to measure teacher performance and then fire underperformers.
I guess that this isn't the main point of the post, but I still feel it's worth to point out this way you'll select to have only teachers that spend all their time preparing their classes to game the evaluation system. From what I understood about the USA educational system It's already a serious problem, I can't even imagine how badly things would turn when a test score would determine the chance people kept their job...