The Human's Role in Mesa Optimization
post by silentbob · 2024-05-09T12:07:06.617Z · LW · GW · 0 commentsContents
No comments
When it comes to mesa optimization, there’s usually two optimizers mentioned: the “base optimizer”, such as SGD, the process used for training the model. And the “mesa optimizer”, meaning roughly “the optimizer beneath the optimizer”. One key question in this context is when and under which circumstances such mesa optimizers may occur. This question is relevant for the AI safety field and alignment research, because optimizer AIs are of particular interest: firstly, they're potentially much more capable than non-optimizing AIs, and secondly, dangerous properties such as instrumental convergence may apply to them, leading to risks of e.g. runaway optimization [LW · GW] that could escape human control.
In Risks from Learned Optimization [LW · GW], the authors explain [LW · GW]:
Conventionally, the base optimizer in a machine learning setup is some sort of gradient descent process with the goal of creating a model designed to accomplish some specific task.
Sometimes, this process will also involve some degree of meta-optimization wherein a meta-optimizer is tasked with producing a base optimizer that is itself good at optimizing systems to achieve particular goals. Specifically, we will think of a meta-optimizer as any system whose task is optimization. For example, we might design a meta-learning system to help tune our gradient descent process. Though the model found by meta-optimization can be thought of as a kind of learned optimizer, it is not the form of learned optimization that we are interested in for this sequence. Rather, we are concerned with a different form of learned optimization which we call mesa-optimization.
This sounds pretty sensible to me, but I think it’s missing an important piece: the (usually human) AI engineers who are behind the whole training process. Even if there’s no automated meta optimizer, the humans are still there, basically performing the same task: they are selecting model architectures, tweaking hyperparameters, and running all kinds of experiments, usually in order to get the emerging AI to be as capable as possible. So ultimately we (potentially) end up with this state of affairs:
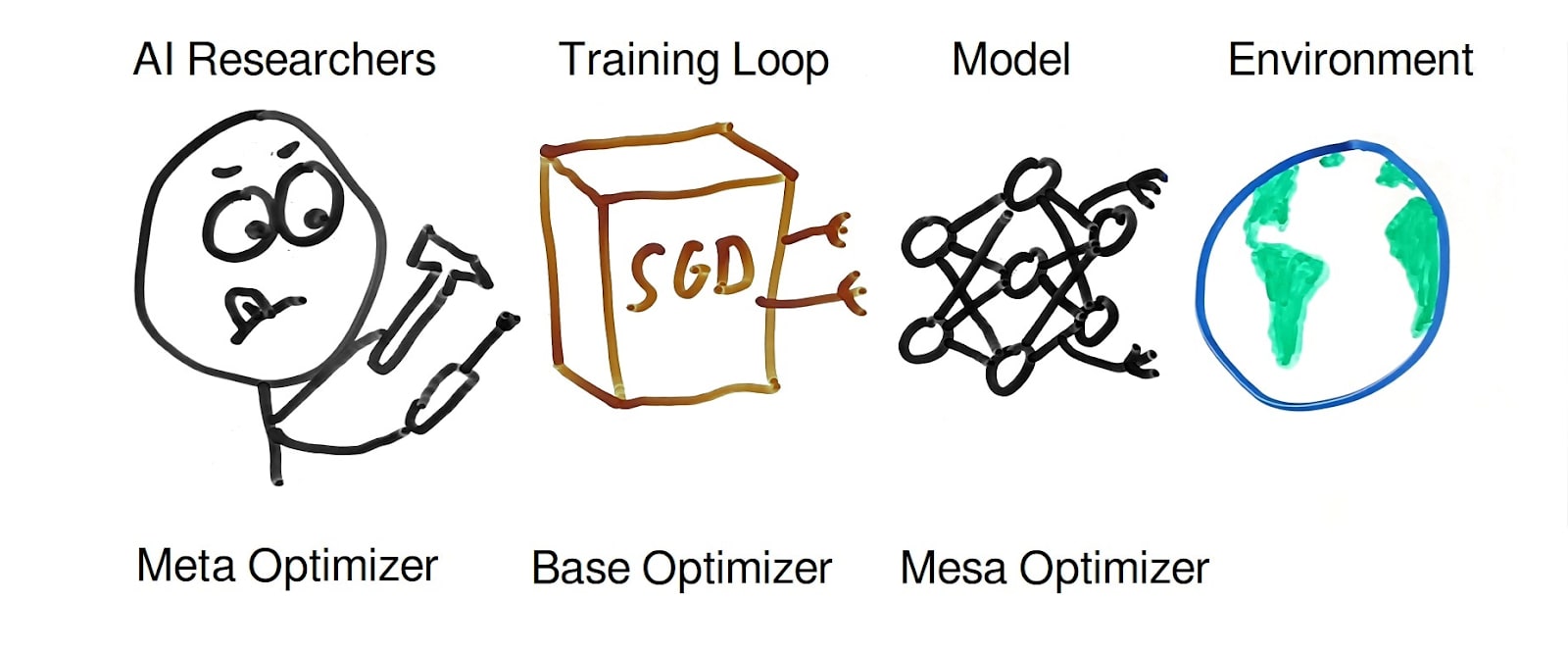
The meta optimizer (AI engineer) tweaks the base optimizer (SGD) so that it trains a mesa optimizer (model) to interact with the world once deployed.
Of course an AI engineer who highly values safety considerations may try to avoid exactly that scenario and rather tries to engineer a model that is not itself an optimizer. But a lot of AI engineers out there don’t share these concerns, and are instead especially keen on creating the most capable models possible. And the most capable models are likely to be those that are capable of optimization.
The realization that there is always this third optimizer operating in the background is important, because without it one may get to the conclusion that it’s extremely unlikely for a “stupid” process such as SGD to converge onto an AI model that is itself an optimizer[1]. Or one may think (maybe rightly so or maybe not) that current generation AI models are inherently not expressive enough to enable strong optimization[2]. But with the human optimizer in the loop, it becomes clear that this human may care a lot about building very capable AIs, and they will keep trying to find ways to get the gradient descent process to eventually find these small basins in model weight space (or, if necessary, find alternative AI architectures) that allow the AI to be unusually capable, via the means of optimization. And hence it is a mistake[3] to focus strongly on supposed fundamental limitations of current machine learning paradigms when trying to assess the longer term dangers of AI.
- ^
Maybe you believe that some optimizer-like AI would be the global optimum of the loss landscape, but it’s incredibly unlikely for gradient descent-based processes to ever find that optimum, e.g. because its attractor basin is extremely tiny (maybe even so tiny that it just exists theoretically, but cannot be stably represented by our hardware, given the inaccuracies of floating point numbers), whereas the overwhelming majority of the search space would converge towards non-optimizer models. Or maybe this optimum is surrounded by “walls” of sub-optimality all around them, making this part of the loss landscape inaccessible from anywhere else.
- ^
For instance because feed forward neural networks, as e.g. used in the transformer architecture, lack the "recursive" traits that, one could assume, are necessary for any strong optimization to occur. (I personally don’t share this view though, not least because the successive generation of multiple tokens seems close enough to such recursive traits to enable optimization)
- ^
I'm aware of course that this particular type of reasoning mistake is not one commonly made by people in the AI safety field. I still think it's valuable to make this concept very explicit and easy to remember.
0 comments
Comments sorted by top scores.