Runaway Optimizers in Mind Space
post by silentbob · 2023-07-16T14:26:45.091Z · LW · GW · 0 commentsContents
Capable Optimizers Argument Capable optimizers can exist Humanity will be capable of building capable optimizers It’s very hard to predict in advance where in mind space a new AI will end up, and if it will have a non-zero overlap with the space of capable optimizers The most advanced AIs of the futures are likely to be capable optimizers Capable optimizers have an incentive to disempower humanity We need an aligned capable optimizer before any misaligned capable optimizer is created Counter Arguments Conclusion None No comments
This post is an attempt to make an argument more explicit that sometimes seems to be implied (or stated without deeper explanation) in AI safety discussions, but that I haven’t seen spelled out that directly or in this particular form. This post contains nothing fundamentally new, but a slightly different – and I hope more intuitive – perspective on reasoning that has been heard elsewhere. Particularly I attempt to make the argument more tangible with a visualization.
Tl;dr: When considering the case for AI as an existential risk, it may not be all that important what most AIs or the typical AI will be like. Instead there’s a particular type of AI – the ones I refer to as “capable optimizers” in this post – that may ultimately dominate the impact AIs have on the world. This is because their nature implies runaway optimizations that may lead to a trajectory of the world that humans are unable to influence.
Consider the following schematic diagram:
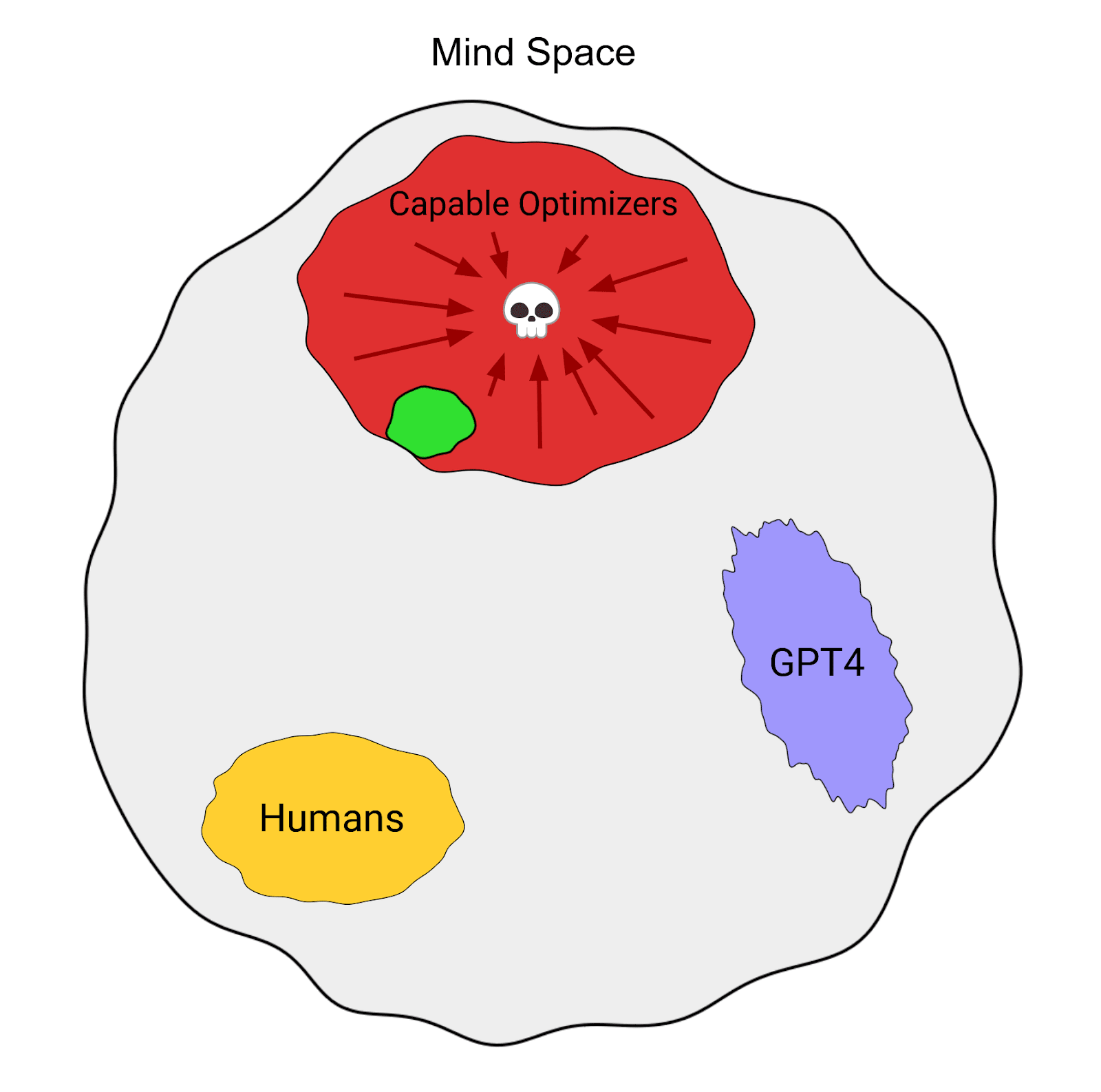
I find that using this visualization helps build an intuition for the case that building powerful AIs might lead to the disempowerment (and possibly extinction) of humanity. Let’s first look into the details of what is depicted:
- The outer, grey shape is “mind space”, i.e. some visualization of the space of possible intelligent minds. That space in reality is of course neither 2-dimensional nor necessarily bounded in any direction; still I find it helpful to visualize the space in this simplified way for the sake of the argument
- The yellow “humans” blob in the bottom left illustrates that a small subset somewhere in mind space is the space of all human minds, given our current state of evolution.
- The GPT4 blob has no direct relevance to the argument; but it’s interesting to realize that GPT4 is not a point in mind space, but rather a relatively broad set, because, based on e.g. user prompting and a conversation’s history (as well as additional system prompts), it may take on very different simulacra/personas that may behave self-consistently, but highly different from other instantiations
- Note that arguably we could make a similar case for individual humans, given that e.g. the acute distribution of neurotransmitters in their brain greatly impacts how their mind works
- Also note that combining GPT4 with other tools and technologies may shift it to different areas in mind space, a possible example being AutoGPT
- Most notably, there’s the big “Capable optimizers” blob at the top, which most of the rest of this post is about
- The green part inside it is that of “aligned” capable optimizers
- The red part represents “misaligned” capable optimizers, who’s optimization would likely eventually lead to humanity’s demise in one form or another – represented by the depicted convergence to a skull
- It may seem that a third category, something like “neutral” capable optimizers is missing. I would argue though that the most relevant distinction is that between misaligned and aligned ones, and the existence of “neutral” capable optimizers just doesn’t impact this post’s argument much, so I decided to keep the post focused on these two classes. I’d be happy if further discussion brought more nuance to this area though.
Capable Optimizers
The term “capable optimizers” here describes a particular subset of mind space. Namely I mean minds meeting the following constraints:
- Capable: They are much more capable than humans in many meaningful ways (such as planning, prediction, general reasoning, communication, deception…)
- Optimizers: They pursue some kind of goal, and make use of their capability to achieve it. Notably this does not just mean that they behave in ways that happen to bring the world closer to a state where that goal is fulfilled. Instead they, on some level, know the goal, and pursue active steps to optimizing towards it
In my understanding, many of the thought experiments about how future AGIs may behave, such as by Bostrom and Yudkowsky, seem to rely on some version of such “capable optimizers”, even though they are often referred to just as AI, artificial general intelligence, or superintelligence.
It may be worth noting that the majority of AIs that humans will build over the next decades may well not be capable optimizers. Arguably none of today’s AIs would qualify as generally capable in the sense described above (although it’s conceivable we simply haven’t unlocked their full potential yet), and only few of them could even be described as optimizers at all[1]. Instead, the “optimizing” part often happens outside of the AI itself, during training, but the AI is not necessarily itself optimizing in any way, but is rather the outcome of the optimization that happened during training. This seems unlikely to remain that way indefinitely however, for two reasons: Firstly, the outer optimization process might ultimately benefit from producing an AI that is also itself an optimizer (i.e. a mesa optimizer [? · GW]). And secondly, even if that first point somehow doesn’t come true, e.g. because the (supposed) global optimum of an inner optimizer isn’t easily reachable through gradient descent for the outer optimization process, it still seems plausible that humans have an interest to build generally intelligent optimizers, since they’re likely to be more useful.
Argument
With these definitions out of the way, here is the basic, broken-down argument of this post:
- Capable optimizers can exist
- Humanity will be capable of building capable optimizers
- It’s very hard to predict in advance where in mind space a new AI will end up, and if it will have a non-zero overlap with the space of capable optimizers
- The most advanced AIs of the futures are likely to be capable optimizers
- Capable optimizers have an incentive to disempower humanity (instrumental convergence)
- We need an aligned capable optimizer before any misaligned capable optimizer is created
In the following sections, I’ll address the individual six parts of the above argument one by one. But first, here are some conclusions and further thoughts based on the argument:
- Critics of instrumental convergence or the orthogonality thesis sometimes seem to think that these two concepts may only apply to very few possible AIs / paradigms, and hence don’t play a big role for our future. However, given that instrumental convergence implies runaway self optimization, AIs of that type are most likely to end up being the most capable ones. Orthogonality on top of that would imply the risk of this runaway self optimization to move in harmful directions. In other words, if there are at least some possible AIs (or paradigms) that are affected by both instrumental convergence and orthogonality, then these are also among the most likely to end up being the most capable and most harmful AIs of the future, because they have a strong motivation to be power-seeking, resource acquiring and self-improving.
- If a capable optimizer (of sufficient capability) were built today, there would probably be little we could do to stop the optimization process. Depending on the capability difference between it and humanity, there may possibly be a period where humanity could still find ways to overpower it, but this period may be short and require fast insight and coordination.
- It seems very likely to me that most “runaway optimizations” lead to states of the world that we would consider undesirable (e.g. due to going extinct); Human values are messy, often inconsistent, and just not very compatible with strong optimization. And even if optimizations exist that humanity could at least partially agree on as ones that would lead to acceptable outcomes – it’s a whole other question if and how we get a capable optimizer to optimize for that exact thing, rather than for something that is subtly different
- Another implication of this model is that a difference in the ratio of AIs built and deployed that are definitely not capable optimizers doesn’t so much affect the probability of a catastrophic outcome, but rather its timing. If the most relevant uncertainty is the question of whether the very first capable optimizer will be aligned or misaligned, then it just doesn’t matter that much how many non-capable-optimizer AIs have been built prior to that[2]. If 99% of AIs we build are non-optimizers, this doesn't imply a 99% chance of safety. Our safety still depends to a great extent on what the first capable optimizer will look like.
Capable optimizers can exist
Mind space is vast, and you could imagine almost any type of mind. If you can predict on a high level how such a mind would behave (and it doesn’t violate physical laws), that’s a pretty good reason to assume it can exist in principle. After all, imagining a mind isn’t that far away from simulating it, and a simulated mind is in my book sufficiently close to “existing” that the initial claim is true. The question then boils down to whether such levels of capability are possible in principle.
A possible counter argument would be the assumption that humanity may happen to be so intelligent that there just isn’t much room to become significantly more capable. Then even the most advanced AI would not be able to overpower humans. Hence any being being “capable” according to this post’s definition would be very unlikely / impossible. However, given the many known constraints and limitations of human minds (such as biases & fallacies, size & speed limitations, lack of scalability, very limited & imperfect memory, etc.), this would be very surprising to me.
Humanity will be capable of building capable optimizers
Another formulation of this point is that, given the subset of mind space where current AIs reside, humanity will be able to trace a path from that area into the space of capable optimizers (left figure), be it by scaling up with current paradigms, identifying new breakthroughs, or simply connecting and utilizing existing AIs and methodologies in new ways – or any mixture of the three.
To me, it wasn’t obvious ahead of time that something like AutoGPT would not end up being a capable optimizer (although it surely seemed unlikely). And this will get less and less obvious with every further model that is being deployed. One way to be safe (from capable optimizers) would be for humanity to just never build a single capable optimizer to begin with. But this seems hardly realistic[3]. To believe this, you would need to believe there’s some quite fundamental reason for the path to capable optimizers in mind space being “blocked off” (right figure).
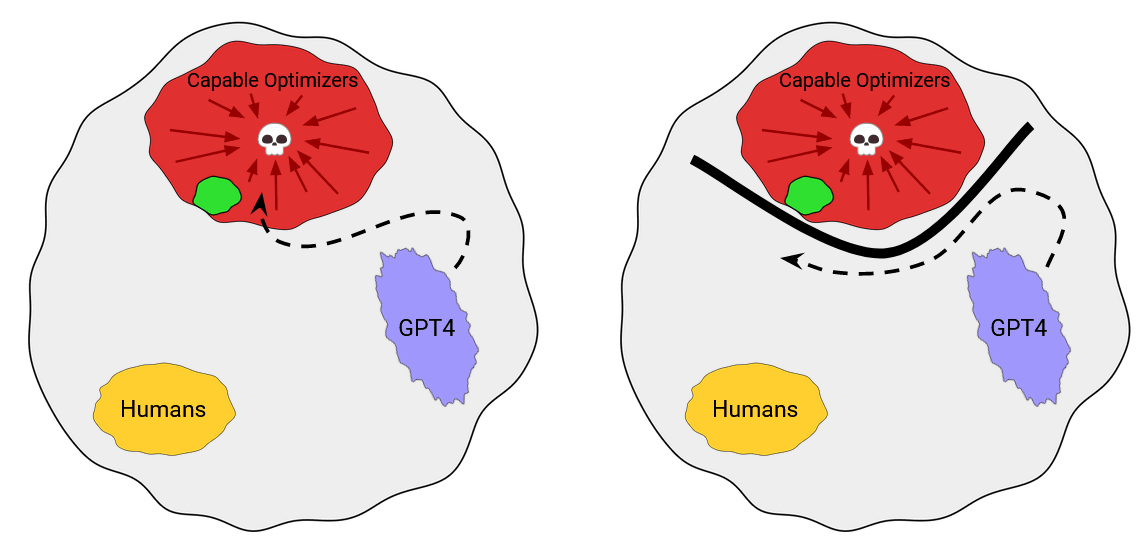
Alternatively, it’s possible that humanity will be capable of building capable optimizers, but refrain from doing so, e.g. through careful regulation or stigmatization [LW · GW]. This would be one of several options of how we may delay or prevent disempowerment scenarios. But if states, organizations or even individuals are at some point capable of building capable optimizers, then we better make very sure that this capability isn’t acted on even once.
It’s very hard to predict in advance where in mind space a new AI will end up, and if it will have a non-zero overlap with the space of capable optimizers
One reason to believe this is the realization that scaled up LLMs, to name one example, tend to develop new “emergent” capabilities that seem impossible to predict reliably. Generally it is practically inherent to Deep Learning that we don’t know to any satisfying degree ahead of time what type of AI we’ll get. One thing we know with a decent degree of certainty is that a trained model will probably be able to substantially reduce the loss function’s overall loss with regards to the training data – but we typically can’t predict how the AI will behave out-of-distribution, and neither can we predict how exactly the model will manage to fit the training data itself.
Technically, we can’t even be sure if GPT4 – an LLM that has been publicly available for 4 months as of writing this post – has any overlap with the space of capable optimizers (if prompted or chained up in just the “right” way). It seems that so far nobody found such an instantiation of GPT4, but it’s difficult to be fully certain that it’ll stay that way.
Lastly, we just lack the understanding of mind space itself, to make fully reliably predictions about where exactly a particular mind ends up. Also the two concepts used here, capability and optimization, are quite high level and vague, which makes it difficult to assess ahead of time whether any given mind fully matches these criteria.
The most advanced AIs of the futures are likely to be capable optimizers
The reasoning behind this claim basically comes down to selection effects: If you have 99 AIs that are “static” and just do whatever they’re built to do, and 1 AI that has an interest in self optimization and resource acquisition and is also capable enough to follow up on that interest successfully, then the latter has probably the best shot of eventually becoming the most capable AI out of the 100. If you select for “capability”, and some subset of AIs have a non-negligible way of increasing their own capability, then these will eventually dominate your selection.[4]
A similar pattern can be observed in the context of evolution: the most capable beings it produced[5] were not those with the best “base capability”, but rather those with the ability to enhance their own basic capabilities via tool use and general intelligence. It’s not the case that evolution caused even remotely all species to be able to enhance their capabilities, or even a few percent of them, but for humans in particular that happened to happen, and caused us to out-compete practically all other animal species. Similarly, it’s not the case that all AIs will be capable optimizers, but if >0 of those will exist, then those will be the most likely to be the most capable, and hence have a very significant and growing impact on the trajectory of the world.
Capable optimizers have an incentive to disempower humanity
The instrumental convergence thesis claims that there are certain goals that are instrumentally useful for a wide variety of terminal goals, and that sufficiently advanced AIs will thus be incentivized to act on these instrumental goals. More or less whatever any given individual optimizes for, certain goals are generally very likely to be helpful for that. These instrumental goals are typically said to include self-preservation, resource-acquisition and goal stability. “You can’t fetch the coffee if you’re dead”.
I used to be somewhat skeptical of the idea of instrumental convergence, but by now realized that this was mostly because it clearly isn’t relevant to all AIs. The thesis seems to make a bunch of assumptions about how a given AI works – e.g. that it has “goals” to begin with. This doesn’t seem to apply to GPT4 for instance. It just does things. It’s not trying to do anything and it’s not optimizing for anything. As far as I can tell, it’s just going through the motions of predicting next tokens without “caring” about which tokens it gets as input, without preferring any particular state of the world that it could optimize for.
This however is still only an argument about GPT4 (or even less - about the ChatGPT version of GPT 4; it’s harder to make such an argument about variations such as AutoGPT). It says nothing about capable optimizers though. And for those, instrumental convergence seems much more probable. So we end up with the situation that if we ever get a capable optimizer, then it will most probably be affected by instrumental convergence, even if the vast majority of all other AIs may not be. And that’s a problem, because capable optimizers are the types of AIs that we should eventually care the most about.
We need an aligned capable optimizer before any misaligned capable optimizer is created
Once a misaligned capable optimizer (red zone) is created, a potentially disastrous runaway optimization begins. At that point the future of humanity depends on whether this process can be stopped before it gets out of hand. This may in principle be possible through human coordination without interference of any further AIs – but given the potentially vast differential in capabilities between the capable optimizer and humanity on the one hand, and the difficulty of large-scale human coordination on the other hand, this is not something we should bet on.
Arguably a better approach would be to have an aligned capable optimizer (green zone) in place first[6] which is able to either prevent misaligned capable optimizers from being created at all (e.g. through a “pivotal act”), or alternatively is able to reliably keep them in check if they are created.
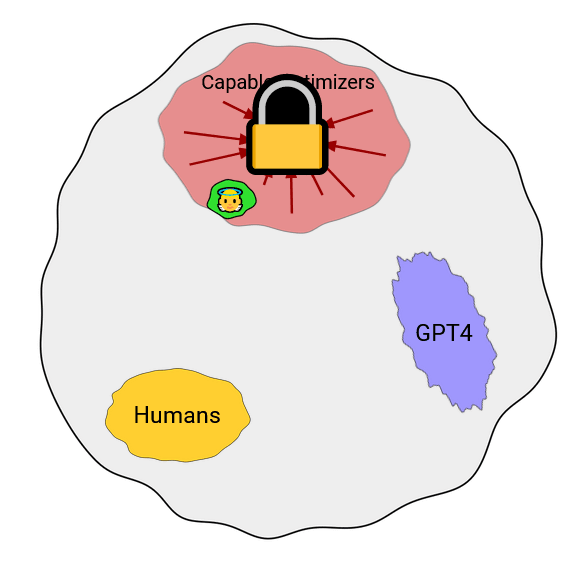
If this post’s schematic diagram is roughly correct in that the space of aligned capable optimizers is much smaller (or to be more precise: is much harder to hit[7]) than the space of misaligned capable optimizers, then this poses a potentially huge problem. Note though that this is not a fundamental assumption of this post, and the general argument still applies, albeit less strongly, if the space of aligned capable optimizers is larger relative to misaligned ones.
Counter Arguments
I’m personally uncertain about the probabilities of all these claims. All I can say at this point is that the risk of AI permanently disempowering humanity seems substantial enough to be taken seriously, and I’ve developed an understanding of why some people might even think it’s overwhelmingly likely (even though I currently don’t share this view).
In this post I’ve primarily focused on the reasons why fear of AI x-risk seems justified. But the underlying model leaves room for a number of cruxes or counter arguments, some of which I’ve listed below.
- Improving intelligence may be very hard, and the “runaway optimization” process might just tend to fizzle out, or run into dead ends, or require vastly more additional resources (such as energy) than the AI is able to generate at any given stage in its existence
- Humanity for some reason won’t be able to create an AI that is capable enough of improving itself (or in any other way triggering a runaway optimization)
- Humanity for some reason won’t be able to create optimizers at all
- Maybe the green zone is in reality much larger than the red one, e.g. because advanced capabilities tend to cause AIs to reliably adopt certain goals; or in other words, the orthogonality thesis is wrong. More specifically, it is wrong in a way that is beneficial to us.
- Maybe the Lebowski theorem saves the day, and at some level of capability, AIs just stop caring about the real world and instead start hacking their reward function. (although this too would need to be true for basically all AIs, or at least all capable optimizers, and not just some or most of them, in order to work as a counter argument)
- Some people might insist that today’s AIs are not actually “intelligent” and that it doesn’t make sense to see them as part of “mind space” at all. While I strongly disagree with the view that e.g. GPT4 is not actually intelligent, merely because it is “just statistics” as is often pointed out, I just don’t think this is very relevant to this post as long as humanity will eventually be able to create capable optimizers.
- One could argue that the same style of argument as the one from this post should apply to e.g. evolution as well, and clearly evolution has not produced any capable optimizers so far. Which maybe we should interpret as evidence against the argument. Note though that this line of reasoning seems to rely rather heavily on survivorship bias, and all we know with some certainty is that evolution didn't produce any capable optimizers yet.
I’d like to stress though that none of these counter arguments strike me as particularly convincing, or probable enough that they would be able to defeat this post’s main argument. Counter arguments 1 and 2 seem conceivable to me, but more in the “there may be hope” range than in the “worrying about AI risk is a waste of time” range.
Conclusion
Many skeptics of AI x-risk tend to argue about why worst case scenarios are unlikely based on plausible sounding claims about what AIs are or are not going to be like. With this post I tried to highlight that AI security is actually a very bold claim: for AI to be secure by default (without solving technical AI alignment as well as the coordination challenges about which AIs can be developed and deployed), we would need to be sure that no single AI ever created ends up being a misaligned capable optimizer. Training and deploying new AIs is somewhat like throwing darts into mind space, aiming closer and closer to the space of capable optimizers over time. This seems like a very dangerous process to me, because eventually we might succeed, and if we do, chances are we’re ending up with the wrong kind of capable optimizer, which may be an irreversible mistake.
For the future to be secure, we need to make sure that this never happens. Either by prior to the creation of any misaligned capable optimizer, installing an AI that is able to either prevent or control all possible future misaligned capable optimizers. Or by putting regulations and incentives in place that reliably prevent the creation of even a single capable optimizer. These seem like very hard problems.
Thanks a lot to Leonard Dung and Leon Lang [LW · GW] for their valuable feedback during the creation of this post.
- ^
This also begs the question if humans could be considered to be optimizers. My take is that this is generally not the case, or at least not fully, because most humans appear to have very fuzzy and unstable goals. Optimization takes time, and if the goal that is optimized for is in constant flux, the optimization (particularly given our capability levels) doesn’t get very far. It might be the case though that some humans, given enough capability for e.g. self modification, could be considered “accidental optimizers”, in the sense that their self modifications might inadvertently change their values and cause a sort of runaway feedback loop on its own, one with no clearly predefined goal – but that’s way out of scope for this post.
- ^
A caveat to this being that “longer timelines” means there’s more time available to solve the alignment problem, so it would still be helpful. Also, a larger number aligned non-capable-optimizers could turn out to be helpful in confining the potential of misaligned capable optimizers.
- ^
Note: in this post I generally leave out the question of timelines. Maybe some people agree with the general arguments, but think that they don’t really affect us yet because the existence of capable optimizers may still be centuries away. I would not agree with that view, but consider this a separate discussion.
- ^
Of course this particular argument rests on the assumption that capable optimizers will exist at some point; if we manage to reliably and sustainably prevent this, then the most advanced AIs will naturally not be capable optimizers, and, luckily for us, the whole argument collapses.
- ^
This is of course implying that the most capable beings evolution produced are in fact humans. If you happen to disagree with this, then the argument should still make sense when limited to the evolution of, say, mammals, rather than all living beings.
- ^
or alternatively build a capable enough aligned non-optimizer
- ^
In principle the size of the two sets (aligned and misaligned capable optimizers) on the one hand, and which one is easier to hit on the other hand, are two quite different questions. But for the sake of simplicity of this post I’ll assume that the size of the areas in the diagram corresponds roughly with how easy it is to reach them for humans in the foreseeable future.
0 comments
Comments sorted by top scores.