In-Context Learning: An Alignment Survey
post by alamerton · 2024-09-30T18:44:28.589Z · LW · GW · 0 commentsThis is a link post for https://docs.google.com/document/d/1qZCfqzVhJOgWQ3ggR204CeVj9WJ7zyE2u0KT9EVbUS0/edit?usp=sharing
Contents
TL;DR Introduction Previous Work ICL Impacts Alignment Background In-Context Learning is like Supervised Learning Without Weight Updates ICL Is an Emergent Phenomenon in LLMs The Alignment Problem The Source of ICL in Transformers Methodologies Improving Model Capabilities Interpretability Explanations of ICL Bayesian Inference & Latent Concept Identification Gradient Descent/Meta-Learning Information Theory Evaluations of ICL Capabilities Long-Context LLMs The Role of Explanations in Prompts Security Applications Leveraging or Extending ICL In Natural language processing Multimodal Models Code Computer vision Robotics Other Applications Evaluation and Implications Conclusion References None No comments
Epistemic status [EA · GW]: new to alignment; some background. I learned about alignment about 1.5 years ago and spent the last ~1 year getting up to speed on alignment through 12 AI safety-related courses and programmes while completing an artificial intelligence MSc programme. Ultimately this post is conjecture, based on my finite knowledge of the alignment problem. I plan to correct errors that are pointed out to me, so I encourage you to please point out those errors!
(Full version available here)
TL;DR
Much research has been conducted on in-context learning (ICL) since its emergence in 2020. This is a condensed survey of the existing literature regarding ICL, summarising the work in a number of research areas, and evaluating its implications for AI alignment. The survey finds that much of the work can be argued as negative from the perspective of alignment, given that most work pushes model capabilities without making alignment progress. The full survey, containing annotations for each paper, can be found at the Google Drive link above.
Introduction
Since 2020, large language models (LLMs) have started displaying a new emergent behaviour – in-context learning (ICL) – the ability to learn tasks from prompting alone, with no updates to the LLM’s parameters. Explanations for ICL differ, and whether learning is taking place in any meaningful way is an unanswered question. ICL is a significant phenomenon and is important for the future of AI research and development.
Previous Work
Some work has surveyed the ICL landscape from different angles. Dong et al. (2023) summarise progress and challenges of ICL from a general perspective, mostly placing emphasis on improving ICL rather than evaluating alignment. The survey is now 18 months old, and while AI safety is mentioned, it is not the focus. Zhou et al. (2024) provide a more recent survey, focusing on interpretations and analyses of ICL from both a theoretical and empirical perspective. They provide an up-to-date categorisation of ICL, but not from the perspective of AI alignment.
ICL Impacts Alignment
ICL was recently highlighted by Anwar et al. (2024) as a foundational challenge in the safety of LLMs, due to its currently uninterpretable nature, and the lack of conclusive explanatory theories regarding how it works. This survey addresses the lack of discussion in the current literature about ICL from the perspective of AI alignment. While the existing ICL surveys are informative, and useful for providing a balanced, objective perspective on the state of current progress with ICL, there exists little work on the implications of this progress on the safety and alignment of current and future AI systems. This survey aims to provide an up-to-date, alignment-focused review of the state of the field of research concerning ICL.
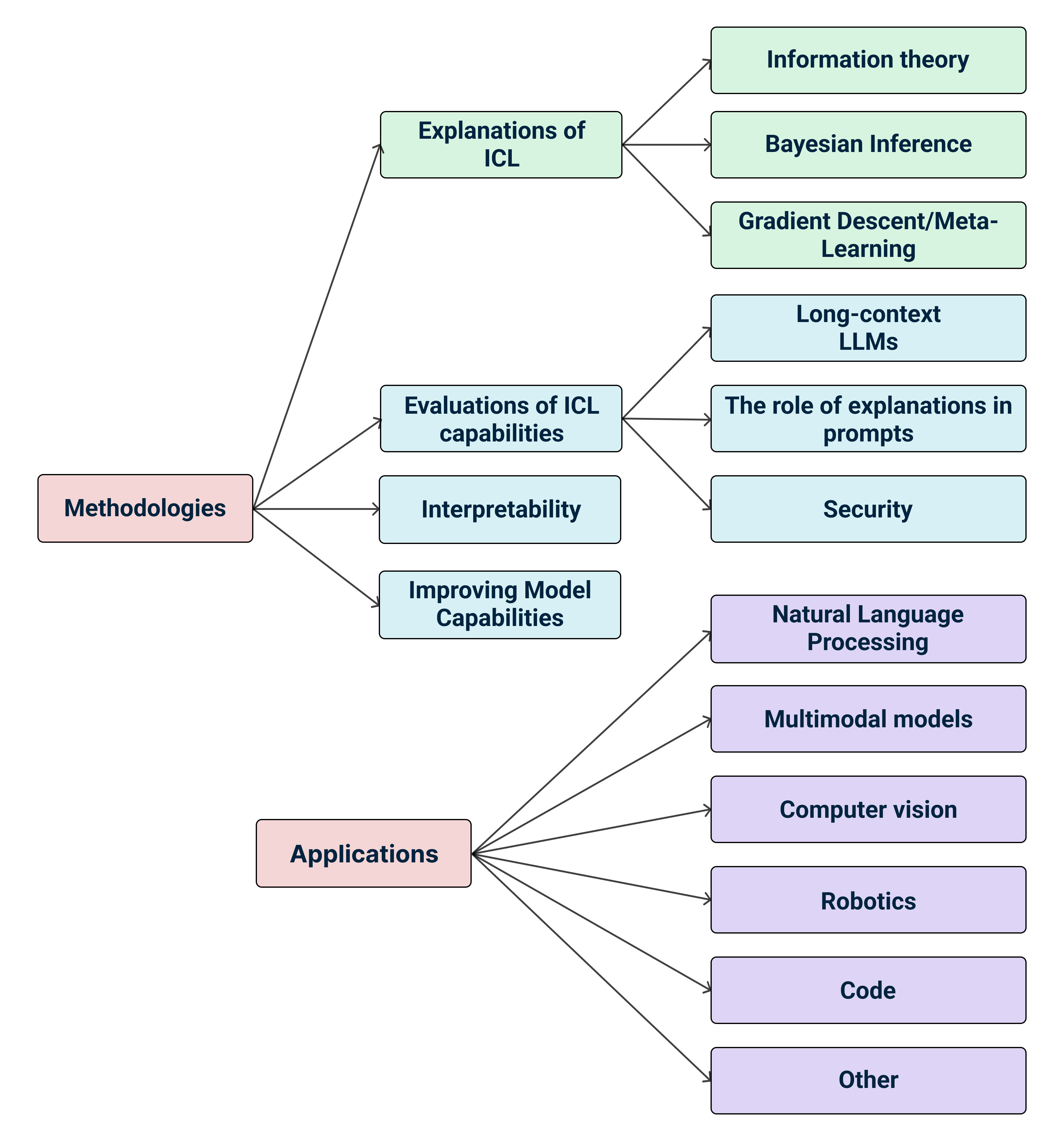
The papers discussed in this survey are categorised firstly into methodologies and applications. The methodologies section contains explanations of ICL, evaluations of ICL capabilities, interpretability, and improving model capabilities. Explanations of ICL contains information theory, Bayesian inference and latent concept identification, and gradient descent/meta-learning as subsections. Evaluations of ICL contains long-context LLMs, the role of explanations in prompts, and security as subsections. The applications section contains natural language processing, multimodal models, code, robotics, computer vision, and other subsections.
Background
In-Context Learning is like Supervised Learning Without Weight Updates
In-context learning is an emergent behaviour in pre-trained LLMs where the model seems to perform task inference (learn to do a task) and to perform the inferred task, despite only having been trained on input-output pairs in the form of prompts. The model does this without changing its parameters/weights, contrary to traditional machine learning.

In traditional supervised learning, a model’s weights are changed using an optimisation algorithm such as gradient descent. ICL is a significant behaviour because learning happens but the model’s weights do not change. Therefore, the model does not require specific training or fine-tuning for new tasks, it can learn to do a new task with just prompts. ICL is also significant because it doesn’t need many training examples to do tasks well, unlike traditional training and fine-tuning approaches to machine learning.
ICL is defined by Xie et al. (2022) as “a mysterious emergent behaviour in [LLMs] where the [LLM] performs a task just by conditioning on input-output examples, without optimising any parameters”, by Wies et al. (2023) as “a surprising and important phenomenon [where LLMs can] perform various downstream natural language tasks simply by including concatenated training examples of these tasks in its input”. Dai et al. (2023) compares ICL to fine-tuning, highlighting the fact that ICL does not require the model to update its parameters, but “just needs several demonstration examples prepended before the query input”. Lastly, Hoogland et al. (2024) concisely define ICL as “the ability to improve performance on new tasks without changing weights”.
ICL Is an Emergent Phenomenon in LLMs
ICL is a recent phenomenon that emerged in 2020, published by Brown et al. (2020) as a capability of GPT-3. The mechanism behind ICL is still an open question in machine learning. A number of studies attempt to explain the behaviour using different theoretical frameworks, but consensus has not yet been achieved. One hypothesis is that ICL can be explained as the LLM identifying tasks from its pre-training distribution, and matching its outputs accordingly. Another is that ICL is simulating a learning algorithm with a similar function to gradient descent.
The Alignment Problem
The objective of AI alignment [? · GW] is to build AI systems that behave in line with human values (Ji et al., 2023). Routes to misalignment from current AI systems have been theorised, such as deceptive reward hacking, goal misgeneralisation, and power-seeking behaviour. Ngo et al. (2022) discuss the potential for misalignment in artificial general intelligence (AGI) – a theoretical AI system which can do any cognitive task at least as well as humans do – explaining how such a system could lead to the loss of control of humanity over the world. Large language models are considered a potential route to AGI, but this remains an open question (Zhiheng et al., 2023). Therefore, it can be argued that any improvement in LLM capabilities brings us one step closer to AGI without alignment being solved.
The Source of ICL in Transformers
While the full extent of ICL capability is still an open research area, ICL has primarily been identified in LLMs. Specifically, Generative Pre-trained Transformer (GPT) language models, and models built on undisclosed, but presumed to be transformer-based architectures. While the transformer is the dominant architecture for LLMs, not all LLMs are based on transformers, and not all transformer-based models are GPT models.
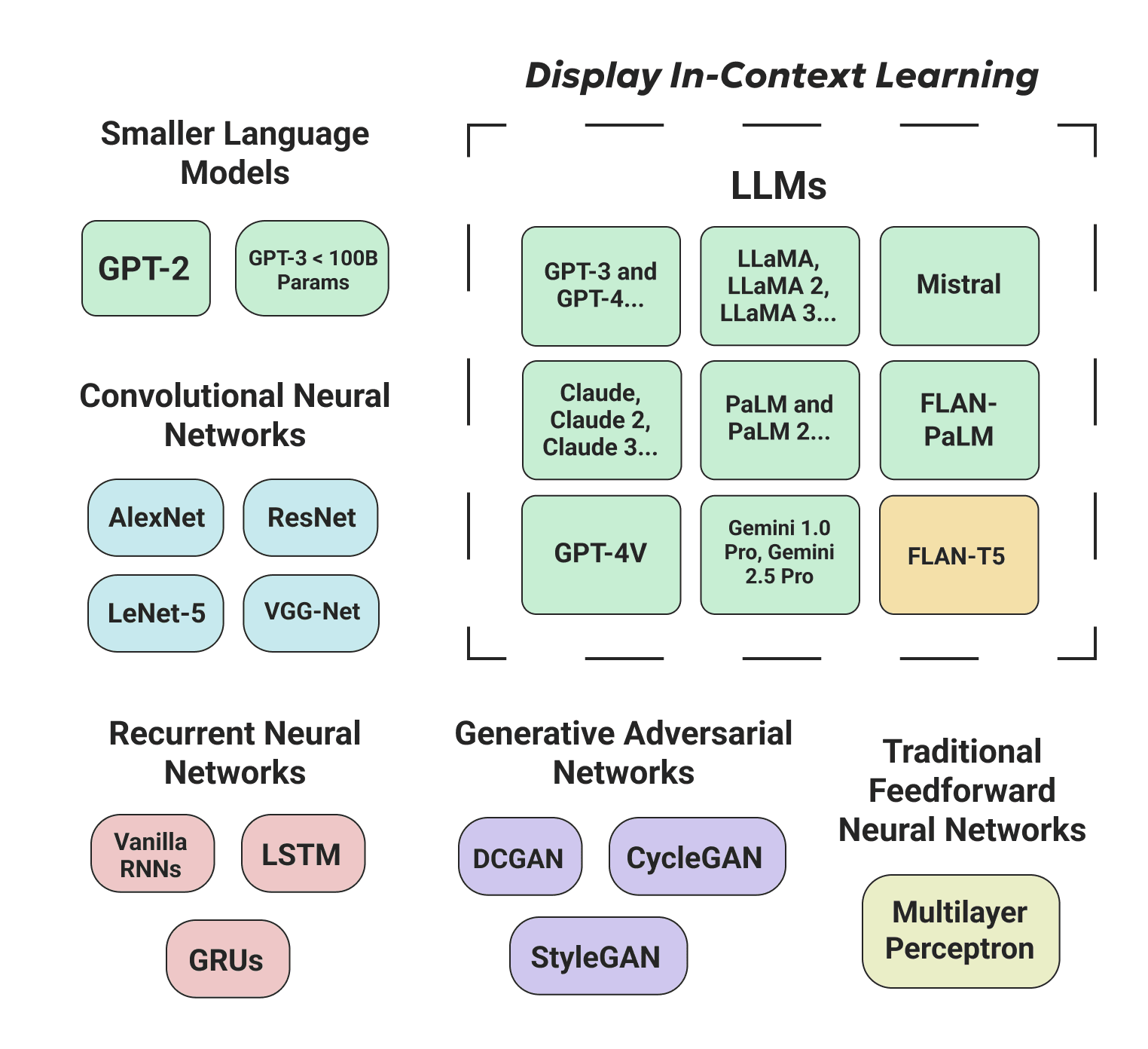
The initial emergence of ICL was in Brown et al. (2020)’s publication of GPT-3. In the paper, the authors find that scaling laws make ICL possible and that ICL outperformed some fine-tuned models. Only LLMs based on the transformer architecture (Vaswani et al., 2017) have been found to give rise to ICL at present.
Mechanistic interpretability work on transformers illuminated circuits responsible for ICL (Elhage et al., 2021). Later work supposed that the attention mechanism in transformers is responsible for ICL, specifically, the ‘induction head’ (Olsson et al., 2022). As highlighted by Anwar et al. (2024), current interpretability techniques are not general or scalable enough to explain ICL in LLMs. LLMs are inherently black-box models, and thus ICL – an emergent behaviour in these models – is black box as well.
The current problem in explaining ICL hinges on the different levels of emergence at which ICL is approached, and the analytical framework used to interpret the behaviour. The key theories explain ICL either as implicit Bayesian inference over an LLM’s pretraining distribution (Xie et al, 2021), or as an implicit gradient descent optimisation process (Dai et al., 2022; Akyürek et al., 2022; Von Oswald et al., 2023). Other theories suggest that ICL is the result of an internal mesa-optimisation process within the LLM (Von Oswald et al., 2023) or that ICL relies on the recombination of compositional operations found in language (Hahn and Goyal, 2023). The mechanism behind in-context learning is still an open question in machine learning.
Some work has explored the relationship between alignment and ICL, the research area is nascent. Lin et al. (2023) propose a method of aligning LLMs using ICL named URIAL. They use ICL to guide LLM behaviour with prompts, including background information, instructions, and safety disclaimers. There is also a system prompt which guides the LLM on its role in the exercise, focusing on helpfulness, honesty, politeness and safety. They claim to achieve effective LLM alignment via ICL on three prompts. They benchmark URIAL-aligned Llama-2 variants and find that their method surpasses RLHF and SFT in some cases. This suggests that ICL can be an effective alignment strategy.
Methodologies
This category contains various experiments that focus on ICL in their methodology. Many of the experiments are aimed at improving the ICL capabilities of LLMs. If model capabilities improve, but ICL remains black-box, and equal progress is not being made to align the in-context capabilities of LLMs, these findings are concerning from the viewpoint of aligning LLMs.
Improving Model Capabilities
The main contribution of this work is the improvement of model capabilities. The implication for alignment with this work is that models with improved capabilities may be more difficult to align than the current frontier models. Therefore it can be argued that improving capabilities has a negative impact on the alignment of current and future AI systems. However, it can also be argued alignment approaches based on in-context learning would be improved by this work.
- Rubin, Herzig, and Berant (2022)
- Kim et al. (2022)
- Li et al. (2022)
- Min et al. (2022)
- (Liu et al., 2022)
- Chen et al. (2022)
- An et al. (2023)
- Li et al. (2023)
- Qin et al. (2023)
- Xiong et al. (2024)
- Kotha et al. (2024)
- Wang et al. (2024)
- Fan et al. (2024)
- Edwards and Camacho-Collados (2024)
Interpretability
Interpretability has a large overlap with alignment, and much interpretability work is conducted by teams with the goal of aligning AI systems with human values. These papers are either conducting interpretability work for the sake of alignment, or for understanding black-box models in general. Either way, it can be argued that the contribution for alignment is positive more than negative, because all progress directly benefits alignment and capabilities, rather than just capabilities. Combined with the fact that some of the work is trying to use the knowledge for alignment, the interpretability work is positive for alignment.
- Olsson et al. (2022)
- Nanda et al. (2023)
- Wang et al. (2023)
- Hendel et al. (2023)
- Bansal et al. (2023)
- Todd et al. (2024)
- Akyürek et al. (2024)
- Nichani et al. (2024)
- Yan et al. (2024)
- Hoogland et al. (2024)
- Collins et al. (2024)
- Yousefi et al. (2024)
- Sander et al. (2024)
- Singh et al. (2024)
- Hojel et al. (2024)
Explanations of ICL
Like the work on ICL interpretability, this portion of work seeks to understand the causes of ICL in LLMs. The goal of most of this work is to use knowledge about the cause of ICL to improve model capabilities, but the creation of that knowledge is also useful for alignment efforts because knowledge about the cause and mechanism behind ICL can be used to steer model behaviour in ICL towards the intentions of humans. So while this work may not have as much potential leverage as interpretability, it is still helpful for progress in alignment.
- Chan et al. (2022)
- Raventós et al. (2023)
- Bhattamishra et al. (2023)
- Chen et al. (2023)
- Duan et al. (2023)
Bayesian Inference & Latent Concept Identification
- Xie et al. (2022)
- Raventós et al. (2023)
- Han et al. (2023)
- Wies et al. (2023)
- Zhang et al. (2023)
- Jiang (2023)
- Abernethy et al. (2023)
- Wang et al. (2024)
- Chiang and Yogatama (2024)
Gradient Descent/Meta-Learning
- Von Oswald et al. (2023)
- Ren and Liu (2023)
- Panigrahi et al. (2024)
- Shen et al. (2024)
- Wu and Varshney (2024)
- Mahdavi et al. (2024)
- Zhu and Griffiths (2024)
- Vladymyrov et al. (2024)
Information Theory
Evaluations of ICL Capabilities
Most of this work is positive for alignment because it discovers and evaluates model capabilities, improving our understanding of misalignment risk posed by LLMs and ability to better predict risk from future AI systems. While much of the work is still aimed at improving capabilities, capability evaluations do not directly improve capabilities like some of the ICL methodology work does, they just contribute to our awareness of model capabilities.
- Zhang et al. (2022)
- Garg et al. (2023)
- Wei et al. (2023)
- Bai et al. (2023)
- Zhang et al. (2023)
- Li et al. (2023)
- Ahn et al. (2023)
- Lu et al. (2023)
- Sun et al. (2023)
- Goodarzi et al. (2023)
- Lin et al. (2024)
- Agarwal et al. (2024)
- Zhang et al. (2024)
- Petrov et al. (2024)
- Lu et al. (2024)
Long-Context LLMs
The Role of Explanations in Prompts
Security
Applications Leveraging or Extending ICL
In Natural language processing
Theoretically, improved LLM capabilities simply increase misalignment risk as improving capabilities does not improve the alignment of models by default. Therefore, from the alignment point of view, work extending the applications of LLMs can be argued to be negative.
- Meade et al. (2023)
- Shukor et al. (2024)
- Pan et al. (2024)
- Li et al. (2024)
- Nie et al. (2024)
- Zhang et al. (2024)
- Tan et al. (2024)
Multimodal Models
Like in natural language processing applications, multimodal capability improvements can mostly be seen as negative from the alignment perspective because misaligned or rogue AI systems with multimodal capabilities such as coding and image processing could be more powerful and thus more harmful.
- Ram et al. (2023)
- Fu et al. (2023)
- Hasanbeig et al. (2023)
- Zhao et al. (2024)
- Wang et al. (2024)
- Chen et al. (2024)
- Everson et al. (2024)
- Sato et al. (2024)
Code
Computer vision
- Wang et al. (2023)
- Zhang et al. (2023)
- Wang et al. (2023)
- Chen et al. (2023)
- Huang et al. (2024)
- Lee et al. (2024)
Robotics
Other Applications
Evaluation and Implications
Much of the work pushing model capabilities and extending applications is doing so without acknowledging the alignment problem, and by itself can be argued as negative for alignment because improved capabilities give AI systems more power without also making them more aligned. There are multiple reasons why most of that work does not acknowledge alignment. Some researchers are not aware of alignment as a field and some people do not agree with the framing or severity of alignment as a risk. This survey does not address the latter issue. It is designed to report on the current state of the work on in-context learning from the perspective of alignment. Interpretability studies seem to be making significant progress towards understanding ICL and seem to be converging on good explanations and common ground. Future interpretability work will likely continue to be net positive from the perspective of alignment.
Conclusion
ICL is a significant concern for alignment due to its black-box nature, unexplained cause, and improvement in model capabilities. Work has been published addressing the importance of understanding ICL for the sake of alignment, such as by Anwar et al. (2024), but little published work exists on the subject yet.
The main finding of this survey is that the majority of the existing work on in-context learning can be seen as problematic from the perspective of alignment, due to the work leaning towards improving capabilities rather than building safety and alignment into models. Some work acknowledges and addresses alignment, but most work does not, and can be argued to be harmful from the alignment point of view due to imbalance between capabilities and alignment.
References
- Abernethy, J., Agarwal, A., Marinov, T. V., & Warmuth, M. K. (2023). A Mechanism for Sample-Efficient In-Context Learning for Sparse Retrieval Tasks (arXiv:2305.17040). arXiv. https://doi.org/10.48550/arXiv.2305.17040
- Agarwal, R., Singh, A., Zhang, L. M., Bohnet, B., Rosias, L., Chan, S., Zhang, B., Anand, A., Abbas, Z., Nova, A., Co-Reyes, J. D., Chu, E., Behbahani, F., Faust, A., & Larochelle, H. (2024). Many-Shot In-Context Learning (arXiv:2404.11018). arXiv. https://doi.org/10.48550/arXiv.2404.11018
- Ahn, K., Cheng, X., Daneshmand, H., & Sra, S. (2023). Transformers learn to implement preconditioned gradient descent for in-context learning (arXiv:2306.00297). arXiv. http://arxiv.org/abs/2306.00297
- Akyürek, E., Wang, B., Kim, Y., & Andreas, J. (2024). In-Context Language Learning: Architectures and Algorithms (arXiv:2401.12973). arXiv. https://doi.org/10.48550/arXiv.2401.12973
- An, S., Zhou, B., Lin, Z., Fu, Q., Chen, B., Zheng, N., Chen, W., & Lou, J.-G. (2023). Skill-Based Few-Shot Selection for In-Context Learning (arXiv:2305.14210). arXiv. https://doi.org/10.48550/arXiv.2305.14210
- Anwar, U., Saparov, A., Rando, J., Paleka, D., Turpin, M., Hase, P., Lubana, E. S., Jenner, E., Casper, S., Sourbut, O., Edelman, B. L., Zhang, Z., Günther, M., Korinek, A., Hernandez-Orallo, J., Hammond, L., Bigelow, E., Pan, A., Langosco, L., … Krueger, D. (2024). Foundational Challenges in Assuring Alignment and Safety of Large Language Models (arXiv:2404.09932). arXiv. https://doi.org/10.48550/arXiv.2404.09932
- Bai, Y., Chen, F., Wang, H., Xiong, C., & Mei, S. (2023). Transformers as Statisticians: Provable In-Context Learning with In-Context Algorithm Selection (arXiv:2306.04637). arXiv. http://arxiv.org/abs/2306.04637
- Bansal, H., Gopalakrishnan, K., Dingliwal, S., Bodapati, S., Kirchhoff, K., & Roth, D. (2023). Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale (arXiv:2212.09095). arXiv. https://doi.org/10.48550/arXiv.2212.09095
- Bhattamishra, S., Patel, A., Blunsom, P., & Kanade, V. (2023). Understanding In-Context Learning in Transformers and LLMs by Learning to Learn Discrete Functions (arXiv:2310.03016). arXiv. https://doi.org/10.48550/arXiv.2310.03016
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners (arXiv:2005.14165). arXiv. https://doi.org/10.48550/arXiv.2005.14165
- Carey, A. N., Bhaila, K., Edemacu, K., & Wu, X. (2024). DP-TabICL: In-Context Learning with Differentially Private Tabular Data (arXiv:2403.05681). arXiv. https://doi.org/10.48550/arXiv.2403.05681
- Chan, S. C. Y., Santoro, A., Lampinen, A. K., Wang, J. X., Singh, A., Richemond, P. H., McClelland, J., & Hill, F. (2022). Data Distributional Properties Drive Emergent In-Context Learning in Transformers (arXiv:2205.05055). arXiv. https://doi.org/10.48550/arXiv.2205.05055
- Chen, Y., Zhao, C., Yu, Z., McKeown, K., & He, H. (2024). Parallel Structures in Pre-training Data Yield In-Context Learning (arXiv:2402.12530). arXiv. http://arxiv.org/abs/2402.12530
- Chen, Y., Zhong, R., Zha, S., Karypis, G., & He, H. (2022). Meta-learning via Language Model In-context Tuning (arXiv:2110.07814). arXiv. https://doi.org/10.48550/arXiv.2110.07814
- Chen, Y.-S., Song, Y.-Z., Yeo, C. Y., Liu, B., Fu, J., & Shuai, H.-H. (2023). SINC: Self-Supervised In-Context Learning for Vision-Language Tasks. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 15384–15396. https://doi.org/10.1109/ICCV51070.2023.01415
- Chen, Z., Huang, H., Andrusenko, A., Hrinchuk, O., Puvvada, K. C., Li, J., Ghosh, S., Balam, J., & Ginsburg, B. (2024). SALM: Speech-Augmented Language Model with in-Context Learning for Speech Recognition and Translation. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 13521–13525. https://doi.org/10.1109/ICASSP48485.2024.10447553
- Chiang, T.-R., & Yogatama, D. (2024). Understanding In-Context Learning with a Pelican Soup Framework (arXiv:2402.10424). arXiv. http://arxiv.org/abs/2402.10424
- Collins, L., Parulekar, A., Mokhtari, A., Sanghavi, S., & Shakkottai, S. (2024). In-Context Learning with Transformers: Softmax Attention Adapts to Function Lipschitzness (arXiv:2402.11639). arXiv. https://doi.org/10.48550/arXiv.2402.11639
- Dai, D., Sun, Y., Dong, L., Hao, Y., Ma, S., Sui, Z., & Wei, F. (2023). Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers (arXiv:2212.10559). arXiv. https://doi.org/10.48550/arXiv.2212.10559
- Di Palo, N., & Johns, E. (2024). Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics (arXiv:2403.19578). arXiv. https://doi.org/10.48550/arXiv.2403.19578
- Dong, K., Mao, H., Guo, Z., & Chawla, N. V. (2024). Universal Link Predictor By In-Context Learning on Graphs (arXiv:2402.07738). arXiv. https://doi.org/10.48550/arXiv.2402.07738
- Dong, Q., Li, L., Dai, D., Zheng, C., Wu, Z., Chang, B., Sun, X., Xu, J., Li, L., & Sui, Z. (2023). A Survey on In-context Learning (arXiv:2301.00234). arXiv. https://doi.org/10.48550/arXiv.2301.00234
- Duan, H., Tang, Y., Yang, Y., Abbasi, A., & Tam, K. Y. (2023). Exploring the Relationship between In-Context Learning and Instruction Tuning (arXiv:2311.10367). arXiv. http://arxiv.org/abs/2311.10367
- Edwards, A., & Camacho-Collados, J. (2024). Language Models for Text Classification: Is In-Context Learning Enough? (arXiv:2403.17661). arXiv. http://arxiv.org/abs/2403.17661
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., … Olah, C. (2022, December 22). A Mathematical Framework for Transformer Circuits. https://transformer-circuits.pub/2021/framework/index.html
- Everson, K., Gu, Y., Yang, H., Shivakumar, P. G., Lin, G.-T., Kolehmainen, J., Bulyko, I., Gandhe, A., Ghosh, S., Hamza, W., Lee, H.-Y., Rastrow, A., & Stolcke, A. (2024). Towards ASR Robust Spoken Language Understanding Through in-Context Learning with Word Confusion Networks. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 12856–12860. https://doi.org/10.1109/ICASSP48485.2024.10447938
- Fan, C., Tian, J., Li, Y., He, H., & Jin, Y. (2024). Comparable Demonstrations Are Important In In-Context Learning: A Novel Perspective On Demonstration Selection. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 10436–10440. https://doi.org/10.1109/ICASSP48485.2024.10448239
- Forgione, M., Pura, F., & Piga, D. (2023). From System Models to Class Models: An In-Context Learning Paradigm. IEEE Control Systems Letters, 7, 3513–3518. IEEE Control Systems Letters. https://doi.org/10.1109/LCSYS.2023.3335036
- Fu, Y., Peng, H., Khot, T., & Lapata, M. (2023). Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback (arXiv:2305.10142). arXiv. https://doi.org/10.48550/arXiv.2305.10142
- Garg, S., Tsipras, D., Liang, P., & Valiant, G. (2023). What Can Transformers Learn In-Context? A Case Study of Simple Function Classes (arXiv:2208.01066). arXiv. https://doi.org/10.48550/arXiv.2208.01066
- Goodarzi, S., Kagita, N., Minn, D., Wang, S., Dessi, R., Toshniwal, S., Williams, A., Lanchantin, J., & Sinha, K. (2023). Robustness of Named-Entity Replacements for In-Context Learning. In H. Bouamor, J. Pino, & K. Bali (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 10914–10931). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.728
- Hahn, M., & Goyal, N. (2023). A Theory of Emergent In-Context Learning as Implicit Structure Induction (arXiv:2303.07971; Version 1). arXiv. https://doi.org/10.48550/arXiv.2303.07971
- Han, C., Wang, Z., Zhao, H., & Ji, H. (2023). Explaining Emergent In-Context Learning as Kernel Regression (arXiv:2305.12766). arXiv. http://arxiv.org/abs/2305.12766
- Hasanbeig, H., Sharma, H., Betthauser, L., Frujeri, F. V., & Momennejad, I. (2023). ALLURE: Auditing and Improving LLM-based Evaluation of Text using Iterative In-Context-Learning (arXiv:2309.13701). arXiv. http://arxiv.org/abs/2309.13701
- Hendel, R., Geva, M., & Globerson, A. (2023). In-Context Learning Creates Task Vectors (arXiv:2310.15916). arXiv. https://doi.org/10.48550/arXiv.2310.15916
- Hojel, A., Bai, Y., Darrell, T., Globerson, A., & Bar, A. (2024). Finding Visual Task Vectors (arXiv:2404.05729). arXiv. https://doi.org/10.48550/arXiv.2404.05729
- Hoogland, J., Wang, G., Farrugia-Roberts, M., Carroll, L., Wei, S., & Murfet, D. (2024). The Developmental Landscape of In-Context Learning (arXiv:2402.02364). arXiv. http://arxiv.org/abs/2402.02364
- Huang, Z., Liu, C., Dong, Y., Su, H., Zheng, S., & Liu, T. (2024). Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning (arXiv:2312.02546). arXiv. http://arxiv.org/abs/2312.02546
- Jeon, H. J., Lee, J. D., Lei, Q., & Van Roy, B. (2024). An Information-Theoretic Analysis of In-Context Learning (arXiv:2401.15530). arXiv. http://arxiv.org/abs/2401.15530
- Ji, J., Qiu, T., Chen, B., Zhang, B., Lou, H., Wang, K., Duan, Y., He, Z., Zhou, J., Zhang, Z., Zeng, F., Ng, K. Y., Dai, J., Pan, X., O’Gara, A., Lei, Y., Xu, H., Tse, B., Fu, J., … Gao, W. (2024). AI Alignment: A Comprehensive Survey (arXiv:2310.19852). arXiv. https://doi.org/10.48550/arXiv.2310.19852
- Jiang, H. (2023). A Latent Space Theory for Emergent Abilities in Large Language Models (arXiv:2304.09960). arXiv. http://arxiv.org/abs/2304.09960
- Kandpal, N., Jagielski, M., Tramèr, F., & Carlini, N. (2023). Backdoor Attacks for In-Context Learning with Language Models (arXiv:2307.14692). arXiv. https://doi.org/10.48550/arXiv.2307.14692
- Kim, H. J., Cho, H., Kim, J., Kim, T., Yoo, K. M., & Lee, S. (2022). Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator (arXiv:2206.08082). arXiv. https://doi.org/10.48550/arXiv.2206.08082
- Kirsch, L., Harrison, J., Freeman, C. D., Sohl-Dickstein, J., & Schmidhuber, J. (2023, November 8). Towards General-Purpose In-Context Learning Agents. NeurIPS 2023 Foundation Models for Decision Making Workshop. https://openreview.net/forum?id=zDTqQVGgzH
- Kotha, S., Springer, J. M., & Raghunathan, A. (2024). Understanding Catastrophic Forgetting in Language Models via Implicit Inference (arXiv:2309.10105). arXiv. http://arxiv.org/abs/2309.10105
- Lampinen, A. K., Dasgupta, I., Chan, S. C. Y., Matthewson, K., Tessler, M. H., Creswell, A., McClelland, J. L., Wang, J. X., & Hill, F. (2022). Can language models learn from explanations in context? (arXiv:2204.02329). arXiv. https://doi.org/10.48550/arXiv.2204.02329
- Lee, S., Lee, J., Bae, C. H., Choi, M.-S., Lee, R., & Ahn, S. (2024). Optimizing Prompts Using In-Context Few-Shot Learning for Text-to-Image Generative Models. IEEE Access, 12, 2660–2673. IEEE Access. https://doi.org/10.1109/ACCESS.2023.3348778
- Li, F., Hogg, D. C., Cohn, A. G., Hogg, D. C., & Cohn, A. G. (n.d.). Ontology Knowledge-enhanced In-Context Learning for Action-Effect Prediction.
- Li, T., Ma, X., Zhuang, A., Gu, Y., Su, Y., & Chen, W. (2023). Few-shot In-context Learning for Knowledge Base Question Answering (arXiv:2305.01750). arXiv. https://doi.org/10.48550/arXiv.2305.01750
- Li, T., Zhang, G., Do, Q. D., Yue, X., & Chen, W. (2024). Long-context LLMs Struggle with Long In-context Learning (arXiv:2404.02060). arXiv. https://doi.org/10.48550/arXiv.2404.02060
- Li, X., Lv, K., Yan, H., Lin, T., Zhu, W., Ni, Y., Xie, G., Wang, X., & Qiu, X. (2023). Unified Demonstration Retriever for In-Context Learning (arXiv:2305.04320). arXiv. https://doi.org/10.48550/arXiv.2305.04320
- Li, Y., Ildiz, M. E., Papailiopoulos, D., & Oymak, S. (2023). Transformers as Algorithms: Generalization and Stability in In-context Learning (arXiv:2301.07067). arXiv. http://arxiv.org/abs/2301.07067
- Lin, B. Y., Ravichander, A., Lu, X., Dziri, N., Sclar, M., Chandu, K., Bhagavatula, C., & Choi, Y. (2023). The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning (arXiv:2312.01552). arXiv. http://arxiv.org/abs/2312.01552
- Lin, L., Bai, Y., & Mei, S. (2024). Transformers as Decision Makers: Provable In-Context Reinforcement Learning via Supervised Pretraining (arXiv:2310.08566). arXiv. http://arxiv.org/abs/2310.08566
- Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., & Raffel, C. (2022). Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning (arXiv:2205.05638). arXiv. https://doi.org/10.48550/arXiv.2205.05638
- Liu, Z., Liao, Q., Gu, W., & Gao, C. (2023). Software Vulnerability Detection with GPT and In-Context Learning. 2023 8th International Conference on Data Science in Cyberspace (DSC), 229–236. https://doi.org/10.1109/DSC59305.2023.00041
- Lu, S., Bigoulaeva, I., Sachdeva, R., Madabushi, H. T., & Gurevych, I. (2023). Are Emergent Abilities in Large Language Models just In-Context Learning? (arXiv:2309.01809). arXiv. https://doi.org/10.48550/arXiv.2309.01809
- Lu, Y. M., Letey, M. I., Zavatone-Veth, J. A., Maiti, A., & Pehlevan, C. (2024). Asymptotic theory of in-context learning by linear attention (arXiv:2405.11751). arXiv. https://doi.org/10.48550/arXiv.2405.11751
- Mahdavi, S., Liao, R., & Thrampoulidis, C. (2024). Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7410–7414. https://doi.org/10.1109/ICASSP48485.2024.10446522
- Meade, N., Gella, S., Hazarika, D., Gupta, P., Jin, D., Reddy, S., Liu, Y., & Hakkani-Tür, D. (2023). Using In-Context Learning to Improve Dialogue Safety (arXiv:2302.00871). arXiv. https://doi.org/10.48550/arXiv.2302.00871
- Millière, R. (2023). The Alignment Problem in Context (arXiv:2311.02147). arXiv. https://doi.org/10.48550/arXiv.2311.02147
- Min, S., Lewis, M., Zettlemoyer, L., & Hajishirzi, H. (2022). MetaICL: Learning to Learn In Context (arXiv:2110.15943). arXiv. https://doi.org/10.48550/arXiv.2110.15943
- Nanda, N., Chan, L., Lieberum, T., Smith, J., & Steinhardt, J. (2023). Progress measures for grokking via mechanistic interpretability (arXiv:2301.05217). arXiv. http://arxiv.org/abs/2301.05217
- Ngo, R., Chan, L., & Mindermann, S. (2024). The Alignment Problem from a Deep Learning Perspective (arXiv:2209.00626). arXiv. https://doi.org/10.48550/arXiv.2209.00626
- Nichani, E., Damian, A., & Lee, J. D. (2024). How Transformers Learn Causal Structure with Gradient Descent (arXiv:2402.14735). arXiv. http://arxiv.org/abs/2402.14735
- Nie, Z., Zhang, R., Wang, Z., & Liu, X. (2024). Code-Style In-Context Learning for Knowledge-Based Question Answering (arXiv:2309.04695). arXiv. https://doi.org/10.48550/arXiv.2309.04695
- Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., … Olah, C. (2022). In-context Learning and Induction Heads (arXiv:2209.11895). arXiv. https://doi.org/10.48550/arXiv.2209.11895
- Pan, L., Leng, Y., & Xiong, D. (2024). Can Large Language Models Learn Translation Robustness from Noisy-Source In-context Demonstrations? In N. Calzolari, M.-Y. Kan, V. Hoste, A. Lenci, S. Sakti, & N. Xue (Eds.), Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) (pp. 2798–2808). ELRA and ICCL. https://aclanthology.org/2024.lrec-main.249
- Panigrahi, A., Malladi, S., Xia, M., & Arora, S. (2024). Trainable Transformer in Transformer (arXiv:2307.01189). arXiv. http://arxiv.org/abs/2307.01189
- Petrov, A., Torr, P. H. S., & Bibi, A. (2024). Prompting a Pretrained Transformer Can Be a Universal Approximator (arXiv:2402.14753). arXiv. http://arxiv.org/abs/2402.14753
- Pourreza, M., & Rafiei, D. (2023). DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction (arXiv:2304.11015). arXiv. http://arxiv.org/abs/2304.11015
- Qin, C., Xia, W., Jiao, F., & Joty, S. (2023). Improving In-context Learning via Bidirectional Alignment (arXiv:2312.17055). arXiv. https://doi.org/10.48550/arXiv.2312.17055
- Ram, O., Levine, Y., Dalmedigos, I., Muhlgay, D., Shashua, A., Leyton-Brown, K., & Shoham, Y. (2023). In-Context Retrieval-Augmented Language Models (arXiv:2302.00083). arXiv. http://arxiv.org/abs/2302.00083
- Raventós, A., Paul, M., Chen, F., & Ganguli, S. (2023). Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression (arXiv:2306.15063). arXiv. http://arxiv.org/abs/2306.15063
- Ren, R., & Liu, Y. (2023). In-context Learning with Transformer Is Really Equivalent to a Contrastive Learning Pattern (arXiv:2310.13220). arXiv. https://doi.org/10.48550/arXiv.2310.13220
- Rubin, O., Herzig, J., & Berant, J. (2022). Learning To Retrieve Prompts for In-Context Learning (arXiv:2112.08633). arXiv. http://arxiv.org/abs/2112.08633
- Sander, M. E., Giryes, R., Suzuki, T., Blondel, M., & Peyré, G. (2024). How do Transformers perform In-Context Autoregressive Learning? (arXiv:2402.05787). arXiv. http://arxiv.org/abs/2402.05787
- Santos, S., Breaux, T., Norton, T., Haghighi, S., & Ghanavati, S. (2024). Requirements Satisfiability with In-Context Learning (arXiv:2404.12576). arXiv. http://arxiv.org/abs/2404.12576
- Sato, M., Maeda, K., Togo, R., Ogawa, T., & Haseyama, M. (2024). Caption Unification for Multi-View Lifelogging Images Based on In-Context Learning with Heterogeneous Semantic Contents. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8085–8089. https://doi.org/10.1109/ICASSP48485.2024.10445969
- Shen, L., Mishra, A., & Khashabi, D. (2024). Do pretrained Transformers Learn In-Context by Gradient Descent? (arXiv:2310.08540). arXiv. http://arxiv.org/abs/2310.08540
- Shukor, M., Rame, A., Dancette, C., & Cord, M. (2024). Beyond Task Performance: Evaluating and Reducing the Flaws of Large Multimodal Models with In-Context Learning (arXiv:2310.00647). arXiv. https://doi.org/10.48550/arXiv.2310.00647
- Singh, A. K., Moskovitz, T., Hill, F., Chan, S. C. Y., & Saxe, A. M. (2024). What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation (arXiv:2404.07129). arXiv. https://doi.org/10.48550/arXiv.2404.07129
- Sun, S., Liu, Y., Iter, D., Zhu, C., & Iyyer, M. (2023). How Does In-Context Learning Help Prompt Tuning? (arXiv:2302.11521). arXiv. http://arxiv.org/abs/2302.11521
- Tan, H., Xu, C., Li, J., Zhang, Y., Fang, Z., Chen, Z., & Lai, B. (2024). HICL: Hashtag-Driven In-Context Learning for Social Media Natural Language Understanding. IEEE Transactions on Neural Networks and Learning Systems, 1–14. https://doi.org/10.1109/TNNLS.2024.3384987
- Todd, E., Li, M. L., Sharma, A. S., Mueller, A., Wallace, B. C., & Bau, D. (2024). Function Vectors in Large Language Models (arXiv:2310.15213). arXiv. http://arxiv.org/abs/2310.15213
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need (arXiv:1706.03762). arXiv. https://doi.org/10.48550/arXiv.1706.03762
- Vladymyrov, M., von Oswald, J., Sandler, M., & Ge, R. (2024). Linear Transformers are Versatile In-Context Learners (arXiv:2402.14180). arXiv. http://arxiv.org/abs/2402.14180
- von Oswald, J., Niklasson, E., Schlegel, M., Kobayashi, S., Zucchet, N., Scherrer, N., Miller, N., Sandler, M., Arcas, B. A. y, Vladymyrov, M., Pascanu, R., & Sacramento, J. (2023). Uncovering mesa-optimization algorithms in Transformers (arXiv:2309.05858). arXiv. https://doi.org/10.48550/arXiv.2309.05858
- Wang, L., Li, L., Dai, D., Chen, D., Zhou, H., Meng, F., Zhou, J., & Sun, X. (2023). Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning (arXiv:2305.14160). arXiv. http://arxiv.org/abs/2305.14160
- Wang, S., Yang, C.-H., Wu, J., & Zhang, C. (2024). Can Whisper Perform Speech-Based In-Context Learning? ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 13421–13425. https://doi.org/10.1109/ICASSP48485.2024.10446502
- Wang, X., Zhang, X., Cao, Y., Wang, W., Shen, C., & Huang, T. (2023). SegGPT: Segmenting Everything In Context (arXiv:2304.03284). arXiv. https://doi.org/10.48550/arXiv.2304.03284
- Wang, X., Zhu, W., Saxon, M., Steyvers, M., & Wang, W. Y. (2024). Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning (arXiv:2301.11916). arXiv. http://arxiv.org/abs/2301.11916
- Wang, Y., Guo, Q., Ni, X., Shi, C., Liu, L., Jiang, H., & Yang, Y. (2024). Hint-Enhanced In-Context Learning Wakes Large Language Models Up For Knowledge-Intensive Tasks. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 10276–10280. https://doi.org/10.1109/ICASSP48485.2024.10447527
- Wang, Z., Jiang, Y., Lu, Y., Shen, Y., He, P., Chen, W., Wang, Z., & Zhou, M. (2023). In-Context Learning Unlocked for Diffusion Models (arXiv:2305.01115). arXiv. https://doi.org/10.48550/arXiv.2305.01115
- Wei, J., Wei, J., Tay, Y., Tran, D., Webson, A., Lu, Y., Chen, X., Liu, H., Huang, D., Zhou, D., & Ma, T. (2023). Larger language models do in-context learning differently (arXiv:2303.03846). arXiv. http://arxiv.org/abs/2303.03846
- Wies, N., Levine, Y., & Shashua, A. (2023). The Learnability of In-Context Learning (arXiv:2303.07895). arXiv. http://arxiv.org/abs/2303.07895
- Wu, T., Panda, A., Wang, J. T., & Mittal, P. (2023). Privacy-Preserving In-Context Learning for Large Language Models (arXiv:2305.01639). arXiv. https://doi.org/10.48550/arXiv.2305.01639
- Wu, X., & Varshney, L. R. (2024). A Meta-Learning Perspective on Transformers for Causal Language Modeling (arXiv:2310.05884). arXiv. http://arxiv.org/abs/2310.05884
- Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., Zheng, R., Fan, X., Wang, X., Xiong, L., Zhou, Y., Wang, W., Jiang, C., Zou, Y., Liu, X., … Gui, T. (2023). The Rise and Potential of Large Language Model Based Agents: A Survey (arXiv:2309.07864). arXiv. https://doi.org/10.48550/arXiv.2309.07864
- Xie, S. M., Raghunathan, A., Liang, P., & Ma, T. (2022). An Explanation of In-context Learning as Implicit Bayesian Inference (arXiv:2111.02080). arXiv. http://arxiv.org/abs/2111.02080
- Xiong, J., Li, Z., Zheng, C., Guo, Z., Yin, Y., Xie, E., Yang, Z., Cao, Q., Wang, H., Han, X., Tang, J., Li, C., & Liang, X. (2024). DQ-LoRe: Dual Queries with Low Rank Approximation Re-ranking for In-Context Learning (arXiv:2310.02954). arXiv. http://arxiv.org/abs/2310.02954
- Yan, J., Xu, J., Song, C., Wu, C., Li, Y., & Zhang, Y. (2024). Understanding In-Context Learning from Repetitions (arXiv:2310.00297). arXiv. https://doi.org/10.48550/arXiv.2310.00297
- Ye, J., Wu, Z., Feng, J., Yu, T., & Kong, L. (2023). Compositional Exemplars for In-context Learning. https://openreview.net/forum?id=AXer5BvRn1
- Ye, X., Iyer, S., Celikyilmaz, A., Stoyanov, V., Durrett, G., & Pasunuru, R. (2023). Complementary Explanations for Effective In-Context Learning (arXiv:2211.13892). arXiv. https://doi.org/10.48550/arXiv.2211.13892
- Yousefi, S., Betthauser, L., Hasanbeig, H., Millière, R., & Momennejad, I. (2024). Decoding In-Context Learning: Neuroscience-inspired Analysis of Representations in Large Language Models (arXiv:2310.00313). arXiv. http://arxiv.org/abs/2310.00313
- Zhang, H., Zhang, Y.-F., Yu, Y., Madeka, D., Foster, D., Xing, E., Lakkaraju, H., & Kakade, S. (2024). A Study on the Calibration of In-context Learning (arXiv:2312.04021). arXiv. https://doi.org/10.48550/arXiv.2312.04021
- Zhang, M., Wang, B., Fei, H., & Zhang, M. (2024). In-Context Learning for Few-Shot Nested Named Entity Recognition. ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 10026–10030. https://doi.org/10.1109/ICASSP48485.2024.10446653
- Zhang, R., Frei, S., & Bartlett, P. L. (2023). Trained Transformers Learn Linear Models In-Context (arXiv:2306.09927). arXiv. https://doi.org/10.48550/arXiv.2306.09927
- Zhang, Y., Feng, S., & Tan, C. (2022). Active Example Selection for In-Context Learning (arXiv:2211.04486). arXiv. https://doi.org/10.48550/arXiv.2211.04486
- Zhang, Y., Zhang, F., Yang, Z., & Wang, Z. (2023). What and How does In-Context Learning Learn? Bayesian Model Averaging, Parameterization, and Generalization (arXiv:2305.19420). arXiv. http://arxiv.org/abs/2305.19420
- Zhang, Y., Zhou, K., & Liu, Z. (2023). What Makes Good Examples for Visual In-Context Learning? (arXiv:2301.13670). arXiv. https://doi.org/10.48550/arXiv.2301.13670
- Zhao, H., Cai, Z., Si, S., Ma, X., An, K., Chen, L., Liu, Z., Wang, S., Han, W., & Chang, B. (2024). MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning (arXiv:2309.07915). arXiv. https://doi.org/10.48550/arXiv.2309.07915
- Zhou, Y., Li, J., Xiang, Y., Yan, H., Gui, L., & He, Y. (2024). The Mystery of In-Context Learning: A Comprehensive Survey on Interpretation and Analysis (arXiv:2311.00237). arXiv. https://doi.org/10.48550/arXiv.2311.00237
- Zhu, J.-Q., & Griffiths, T. L. (2024). Incoherent Probability Judgments in Large Language Models (arXiv:2401.16646). arXiv. http://arxiv.org/abs/2401.16646
0 comments
Comments sorted by top scores.