Self-assessment in expert AI predictions
post by Stuart_Armstrong · 2013-02-26T16:30:10.903Z · LW · GW · Legacy · 9 commentsContents
9 comments
This brief post is written on behalf of Kaj Sotala, due to deadline issues.
The results of our prior analysis suggested that there was little difference between experts and non-experts in terms of predictive accuracy. There were suggestions, though, that predictions published by self-selected experts would be different from those elicited from less selected groups, e.g. surveys at conferences.
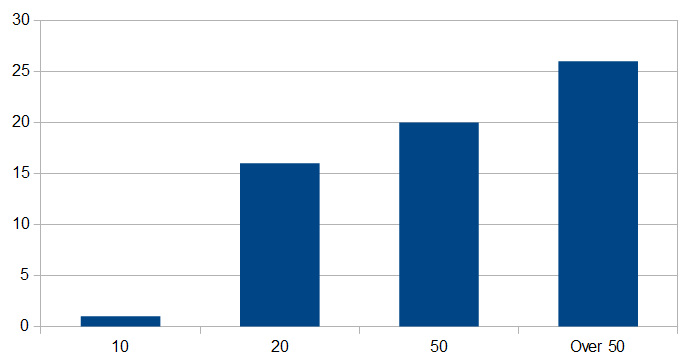
We have no real data to confirm this, but a single datapoint suggests the idea might be worth taking seriously. Michie conducted an opinion poll of experts working in or around AI in 1973. The various experts predicted adult-level human AI in:
- 5 years: 0 experts
- 10 years: 1 expert
- 20 years: 16 experts
- 50 years: 20 experts
- More than 50 years: 26 experts
On a quick visual inspection, these results look quite different from the distribution in the rest of the database giving a much more pessimistic prediction than the more self-selected experts:
But that could be an artifact from the way that the graph on page 12 breaks the predictions down to 5 year intervals while Michie breaks them down into intervals of 10, 20, 50, and 50+ years. Yet there seems to remain a clear difference once we group the predictions in a similar way [1]:
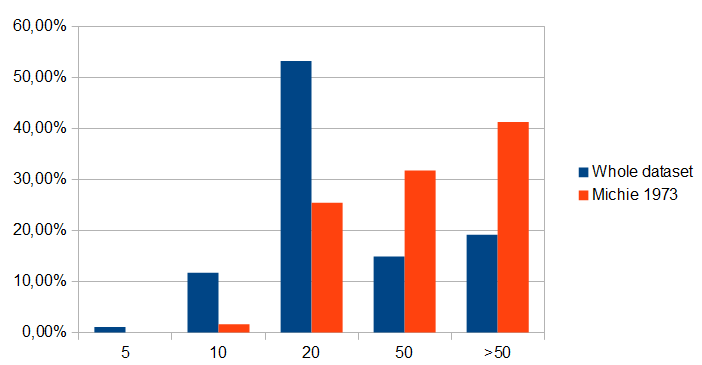
This provides some support for the argument that "the mainstream of expert opinion is reliably more pessimistic than the self-selected predictions that we keep hearing about".
[1] Assigning each prediction to the closest category, so predictions of <7½ get assigned to 5, 7½<=X<15 get assigned to 10, 15<=X<35 get assigned to 20, 35<=X<50 get assigned to 50, and 50< get assigned to over fifty.
9 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2013-02-26T18:48:50.704Z · LW(p) · GW(p)
Thanks for making the post, Stuart.
In case anyone's wondering, this post doesn't mention the surveys from AGI conferences because anyone participating in those will be extremely self-selected. XiXiDu's interview series is somewhat better, in that he also contacted names in mainstream AI, but he also spoke to a number of folks who were specifically chosen for working in the field of AGI so that's not a representative sample either.
Replies from: KatjaGrace↑ comment by KatjaGrace · 2014-06-14T20:41:42.203Z · LW(p) · GW(p)
Do you mean the people at AGI conferences are extremely self-selected in the sense of them choosing to be in AGI or to attend the conference, or do you mean that within the conference, there is strong selection regarding who chooses to do the surveys?
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2014-06-15T07:38:39.231Z · LW(p) · GW(p)
The former.
comment by Vladimir_Nesov · 2013-02-26T16:42:58.240Z · LW(p) · GW(p)
The images don't load for me. (In general, it's better to use LW's inbuilt hosting, so that the images are maintained in the same archive and don't disappear later.)
Edit: Fixed now, thanks!
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-26T16:49:21.849Z · LW(p) · GW(p)
Edited that. Is it better now?
comment by Mitchell_Porter · 2013-02-26T16:42:23.071Z · LW(p) · GW(p)
From the title, I thought this might be about an AI's "self-assessment" and the role this would play in predictions involving itself (e.g. perhaps predictions of how it would think and act after a particular modification).
comment by TrE · 2013-02-26T16:32:08.822Z · LW(p) · GW(p)
More than 50 years: 26 years
*experts
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-26T16:32:41.063Z · LW(p) · GW(p)
Thanks!