On Ilya Sutskever's "A Theory of Unsupervised Learning"
post by MiguelDev (whitehatStoic) · 2023-08-26T05:34:00.974Z · LW · GW · 0 commentsContents
A theory of unsupervised learning by Ilya Sutskever Intro [Host and Ilya, 0:05] Supervised Learning [1:47] Unsupervised Learning Via Distribution Matching [11:59] Compression [15:36] Kolmogorov Complexity [20:48] (Conditional) Kolmogorov complexity as the solution to unsupervised learning [26:12] GPT, Vision, The End of presentation [31:00 to 36:06] My biased opinion: Archetypal Transfer Learning (ATL) as a Feasible Strategy for AI Alignment None No comments
I highly recommend watching Sutskever's entire lecture instead of reading the AI-generated transcript[1], as he presents his ideas exceptionally well. I believe Sutskever's effort to formalize or demistify unsupervised learning is a solution to the control problem. My comments are in the footnotes of the bolded concepts.
A theory of unsupervised learning by Ilya Sutskever
Intro [Host and Ilya, 0:05]

thirty nine thousand um and then many more so super excited to hear what Ilya has to say about llms in the future take it away okay hi hi everyone thank you for the introduction you know when uh when Umesh invited me to to attend this event I got really excited I saw the holy speak released and I thought great I'll I'll go and I'll talk about something and then I ran into a problem which is that a lot of the technical workings we're doing at open AI actually can talk about so I was really racking my head what could I talk about right now so as of not too long ago I switched all my focus to working on AI alignment all my research Focus and we'll have very cool results to show there but not just yet so I'm like okay so this would have to be for the next stop but what would be good for this stock and I came up with something I'll tell you about some very old results that we had it open AI many years ago back in 2016 even which really affected the way I think about unsupervised learning and I thought I'd share them with you it is possible that at this point you'll find them obvious but maybe not all of them so there is at least a small chance that you'll find it interesting so I want to set the expectations modestly and hopefully exceed them
Supervised Learning [1:47]

so a theory of unsupervised learning how can such a thing exist so okay before we talk about unsupervised learning we want to talk about learning in general what is learning and why does learning work at why should learning work at all and why should computers be able to learn and now we are just used to the fact we take it for granted that neural networks learn but but why do they like mathematically why should they why would data have regularity that our machine learning models can capture so that's not an obvious question and one important conceptual advance that has taken place in machine learning many years ago by multiple people with the discovery and the formalization of supervised learning so it goes under the name of back learning or statistical learning theory and the nice thing about supervised learning is that it gives you a precise mathematical condition under which learning must succeed you're told that if you have some data from some data distribution that if you manage to achieve a low training loss and the number of your degrees of freedom is not is smaller than your training set then you will achieve low tester and you are guaranteed to do so you have a mathematical condition where you can say well if if I did find a function out of my function class which achieve low training error then learning will succeed and you can say yeah this is a very sensible mathematical thing that we can reason about and that's why supervised learning is easy and then you had all these theorems which I thought were simple you know I found the Mulligan you've seen maybe theorems like this if you have your basically it's like this is the sort of thing where if you know it you're going to say oh yeah that thing and if you don't know it it will not be possible to explain it in 30 seconds though it is possible to explain it in five minutes just not 30 seconds none of this stuff is complicated and you've got your little proof which says well if you have some number of functions in your function class the probability that your train error will be far from your test error for at least one function there is a mass and the math is simple this is all the math three lines of math so three lines of math can prove all of supervisor well that's nice that's very nice so supervised learning is something that is well understood comparatively speaking well understood we know why it must it must succeed so we can go forth and collect large supervised learning data sets and be completely certain that models will keep getting better so that's that's the story there and yeah but forgot to mention a very important piece of these results the test distribution and training distribution need to be the same if they're the same then your theory of supervised learning kicks in and works and will be successful so conceptually it is trivial we have an answer for why supervised learning works why speechrecognition should work by image categorization should work because they all reduce to supervised learning which works which has this mathematical guarantee so this is very nice here I want to make a small side comment on VC Dimension to those of you who care about such things there may be a small subset so if you want to zone out for the next 30 seconds feel free to do so so a lot of writings about statistical learning theory emphasize the VC Dimension as a key component but the main reason the VC dimension in fact the only reason the BC Dimension was invented was to allow us to handle parameters which have infinite precision the VC Dimension was invented to handle Precision like parameters with infinite Precision so if you have your linear classifier every parameter is infinite precision but then of course in reality all our floats are finite precision and their Precision is shrinking so you can and you could so you have your so the number of functions that are implemented by a computer is actually small and you can reduce it back to the little this little formula which gives you pretty much all the best bounds that you can get from supervised learning so I find this to be cool I find this to be appealing because you have fewer lines of proof okay now let's talk about unsupervised learning so I claim first of all what is unsupervised learning what is it supervised learning is like yeah you've got your data that says here do this here do that and you have all this data you do well in your training error your training error is low you'll have more training data than degrees of freedom in your function class parameters but maybe other things too degrees of freedom at bits and you say okay I'm super you're super residentiality will succeed but what is unsupervised learning what can you say at all about unsupervised learning and I'll say that I at least I have not seen like an exposition of unsupervised learning which you found satisfying how to reason about it mathematically we can reason about it intuitively but can be reason about it mathematically and for some context what is the old dream of unsupervised learning which by the way this dream has been fulfilled but it's fulfilled empirically like can we go just a tiny bit beyond the empirical results like the idea that you just look at the images or you just look at the text without being told what to do with them and somehow you still discover the true hidden structure that exists in the data and somehow it helps you why why why should it happen should it happen should we expected to happen you cannot you don't have anything remotely similar to the supervised learning guarantee the supervised learning guarantee says yeah like get your low training error and you're going to get your learning it's going to be great success unsupervised learning it appears it appears that it's not this way you know like people were talking about it for a long time in the 80s the Bolson machine was already talking about self-supervised learning and I'm super misleading also did not work at small scale but all that but the old ideas were there like the noise in Auto encoder to those of you who remember remember it it's like Bert or the diffusion model within it it's a tiny twist the tiniest of twists the language models of all times they also you know generated cool samples for their time but they're unsupervised learning performance was not as impressive as those of today but I want to make the case that it is confusing because it's like why is it confusing you optimize like how doesn't suppress learning work you say okay let's optimize some kind of reconstruction error or let's optimize some kind of uh denoising error or like some kind of self-supervised learning error you optimize one objective right oh yes I just said that but you care about a different objective so then doesn't it mean that you have no reason to expect that you'll get any kind of good and supervised learning results so rather you know you do get them empirically but like is it going to be like the level of mystery is quite High I claim like it seems totally like a totally inaccessible phenomenon you optimize one objective but you care about another objective and yet it helps how can that be Magic okay so yeah the other thing by the way is that I'm super well

I guess I'm gonna I'm gonna say something which is only 90 true unsupervised learning doesn't you you could say okay so you just learned the structure in the input distribution and it helps you but then you know what if you're training from the uniform distribution then all you're on supervised learning algorithms will fail how should you think about that so what can we say what can do we need to make assumptions what kind of assumptions so I'd like to present potentially a way of thinking about unsupervised learning which I think is I personally find it interesting perhaps you'll find it interesting too let's find out so I want to show you one way of doing unsupervised learning which is not necessarily widely known because it never became the dominant way of doing that supervised learning but it has the cool feature that similarly to supervised learning it has to work so what kind of mysterious unsupervised learning procedure for you not given any labels to any of your inputs is still guaranteed to work distribution matching
Unsupervised Learning Via Distribution Matching [11:59]

so what is distribution[2] matching say my data I've got X and I've got Y data sources there's no correspondence between them to two data source data source exit intercept wise data source y language one language two text speech no correspondence between them let us look at this Criterion find the function f such that the distribution of f of x is similar to the distribution of Y it is a constrained on F and in the case of machine translation and speech recognition for example this constraint might be meaningful like you could say yeah if I have like long sentences if if you tell me that you have a function such that the distribution you take your distribution of English sentences you apply the function f to them and you get something which is very similar to the distribution of French sentences you can say okayI found the true constraint about f if the dimensionality of X and the dimensionality of Y is high enough that's going to give you a lot of constraints in fact you might be able to almost fully recover F from that information this is an example of supervised learning of unsupervised learning where it is still guaranteed to work in the same sense that supervised learning is guaranteed to work also substitution ciphers like little simple encryptions will also fit into this framework okay and so like I I kind of I ran into this I I've independently discovered this in 2015. and I got really fascinated by it because I thought wow maybe there is something meaningful mathematically meaningful that we can say about unsupervised learning and so but let's see this the thing about this setup is that still it's a little bit artificial it's still real machine learning setups aren't like this and the way we like to think about unsupervised learning isn't that also okay now I'll present to you the meat the meter what I'm going or what I wanted to say how a proposed way to think about unsupervised learning that lets you that puts it on par with supervised learning says okay what is it doing mathematically how can you be sure that you're on supervised learning is good compression to the rescue obviously it is well known I shouldn't say Obviously it is not obvious but it is well known that compression is prediction every compressor can be done to a predictor and vice versa there is a one-to-one correspondence between all compressors and all predictors however I would argue that for the purpose of thinking about unsupervised learning the language of compression offers some advantages at least for me it did perhaps it will for you too
Compression [15:36]

so consider the following thought experiment this thought experiment is the most important slide say you have two data sets X and Y in two data sets two files on your big giant hard disk and say you have a really great compression algorithm C which takes data in and outputs compressed objects out say you compress X and Y jointly you concatenate them you take the two data sets and you concatenate them and you feed them to your compressor what will happen well let's see what in this particular an important question is what will a sufficiently do good compressor will do my answer is very intuitively it will use the patterns that exist inside X to help it compress Y[3] and vice versa you could make the same Claim about prediction but somehow it's more intuitive when you say it about compression I don't know why there is but I find it to be the case so that's a clue and you can make an equation like this where you say hey if your compression is good enough if it's like a real great compression compressor it should say that the compression of your concatenation of your giant files should be no worse than the separate compression of YouTube files so any additional compression that was gained by concatenation is some kind of shared structure that your compressor noticed and the better your compressor is the motion structure it will extract the Gap is the shared structure or the algorithmic mutual information so that's interesting right you can see what I'm alluding to why is the data of your supervised task X is your unsupervised task but suddenly you have some kind of mathematical reason for the information for the patterns in X to try to help y notice also how it generalizes distribution matching if we are in the distribution matching case where you've got your X is language 1 and Y is language two and you're saying and you know that there exists some simple function f that transforms one distribution into the other surely your compressor if it's good will notice that and make use of that and maybe even internally try to recover this function foreign Circle
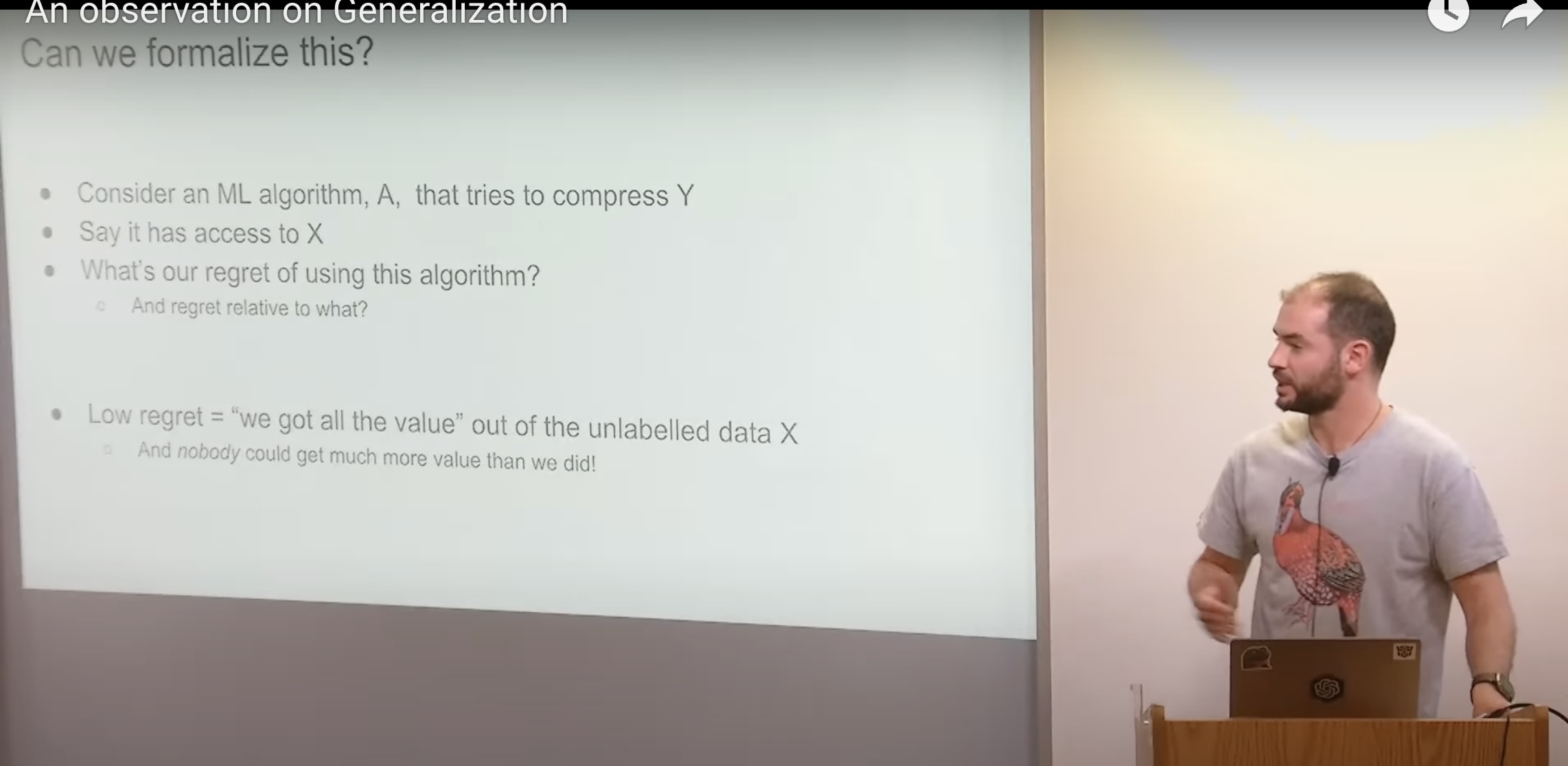
so how do we formalize it then what will be the formalization of unsupervised learning let's see let's see if I can do it consider an ml algorithm so here by the way in what follows I'll be a bit sloppy and I will use compression and prediction interchangeably say you have a machine learning algorithm a it's an algorithm a and it tries to compress y and said has access to X X is file number one and Y is file number two you want your machine learning algorithm your compressor to compress Y and it can probe X as it says fit the goal is to compress visible as possible we can ask ourselves what is our regret of using this particular algorithm you'll see what I'm getting at regret relative to what if I do a good enough job if I have like being low regret means that I've gotten all the help like that I can possibly get from this unlabeled data based on label data has helped me as much as possible and I don't feel bad about it I don't feel bad I don't feel like I've left some prediction value on the table that someone else with a better compression algorithm could have used that's what it means and in particular it's like yeah like you can go and you can sleep happily at night knowing that if there is some information in the unlabeled data that could help my task no one else like no no one could have done as good of a job as me I've done the best job at benefiting from my unlabeled data so I think that is a step towards thinking about unsupervised learning you don't know if your unsupervised data set is actually useful it may be super useful it may have the answer it may be totally useless it may be the uniform distribution but if you have a low regret[4] on supervised learning algorithm you can say whether it's the first case or the second case I know I've done my best I know I've done my best at benefiting from my unlabel data no one could have done better than me now I want to take a detour to some to to Theory land which is a little obscure I think it is interesting
Kolmogorov Complexity [20:48]
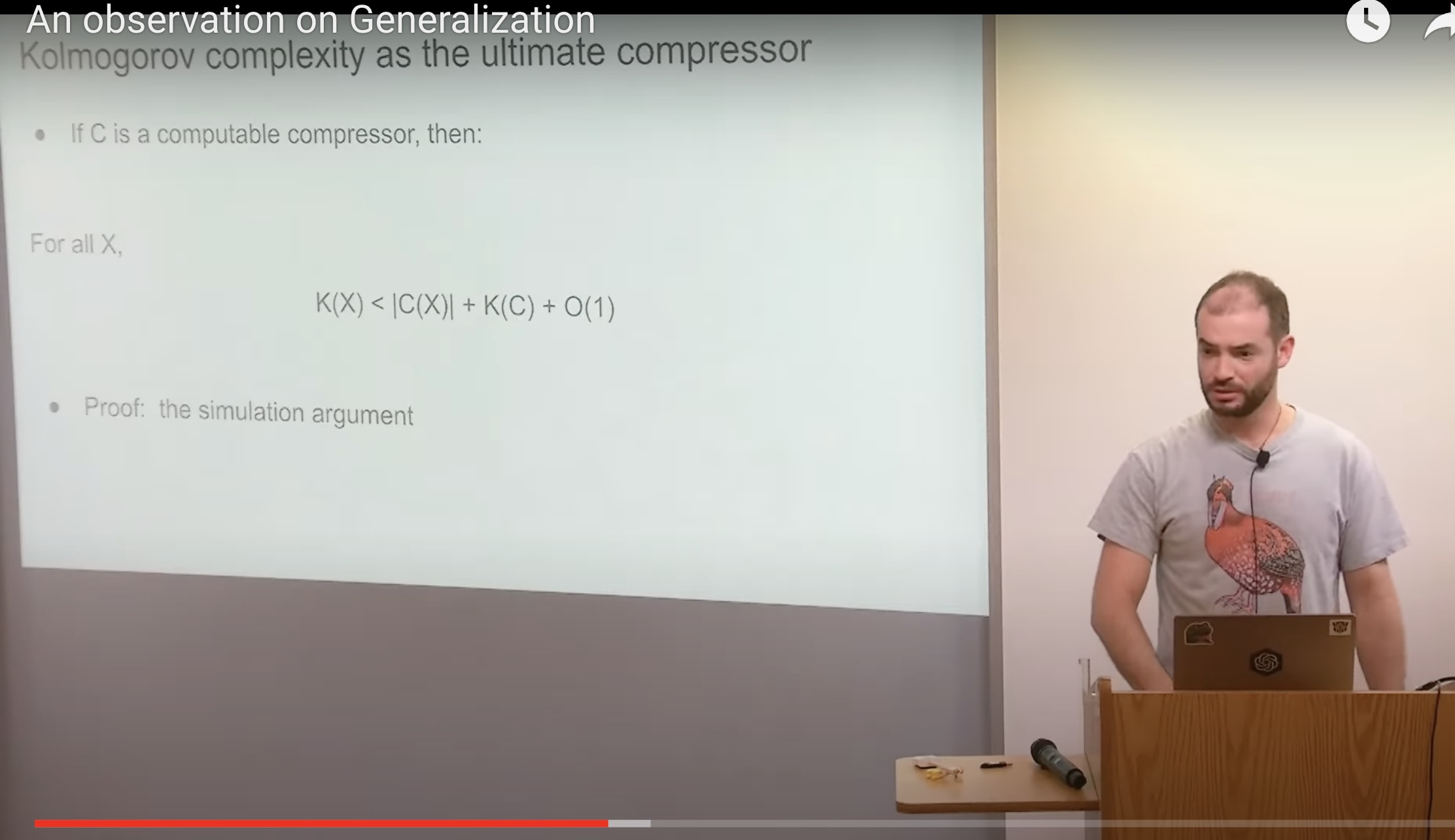
Kolmogorov complexity as the ultimate compressor gives us the ultimate low regret algorithm which is actually not an algorithm because it's not computable[5] but you'll see what I mean really quickly so comic books first of all like for some context who know who here is familiar with complexity okay about 50 yeah um it's it's the Kolmogorov complexity is the kind of thing which is easy to explain in one minute so I'll just do it it's like imagine if I give you some data or you give me some data and I'm going to compress it by giving you the shortest program that can possibly exist the shortest program that exists which if which if you run it outputs your data oh okay yes yes that is correct you got me it is the length of the shortest program which outputs X yes intuitively you can see this compressor is quite good because you can prove this theorem which is also really easy to prove or rather it's really it's easy to feel it and once you feel it you could kind of believe me that it's easy to prove and you can basically say that you call magorov compressor if you use that to compress your strings you'll have very low regrets about your compression quality you can prove this result it says that if you got your string X your data set database whatever the shortest program which output X is shorter than whatever your compressor needed output and however value compressor compress your data Plus a little term which is however many like characters of Code you need to implement your compressor intuitively you can see how it makes sense the simulation argument right the simulation argument if you tell me hey I've got this really great compressor C I'm going to say cool does it come with a computer programmer can you give this computer program to K and K is going to run your compressor because it runs computer programs you just need to pay for the program links so without giving you the details I think I gave you the feel of it oh my god of complexity the column of compressor can simulate how the computer program simulate out the compressors this is also why it's not computable it's not computable because it simulates it feels very much at Liberty to simulate all computer programs but it is the best compressor that exists and we were talking about Good compression for unsupervised learning now let us generalize a common core of complexity a common growth compressor to be allowed to use site information oh more than detailed so I'll make this detail I'll I'll reiterate this point several times because this point is important obviously the Kolmogorov compressor is not computable it's undecidable but like hey because it's like searches overall programs but hey did you know that if you're an SGD over the parameters of some neural net with the hundred layers it's like automatically like doing program searchover a computer which has a certain amount of memory a certain number of steps it's kind of like kind of like row homograph like 59 year old Nets you kind of see the feel the similarity it's kind of magical right neural networks can simulate little programs they are little computers they're circuits circuits are computers Computing machines and SGD searches over the program and all of deep learning is changes on top of the SGD miracle that we can actually train these computers with SGD that works actually find the circuits from data therefore we can compute our miniature Kolmogorov compressor
the simulation argument applies here as well by the way I just want to mention this one fact I don't know if you've ever tried to design a better neural network architecture what you'd find is that it's kind of hard to find a better new network architecture you say well let's add this connection let's add that connection and let's like modify this and that why is it hard the simulation argument because your new architecture can be pretty straightforwardly simulated by old architecture except when it can't those are rare cases and in those rare cases you have a big Improvement such as when you switch from the little RNN to the Transformer the RNN has a bottleneck the hidden state so it's a hard time implementing a Transformer however had we found a way to engineer and Ireland with a very very large Hidden State perhaps it would become as good as a Transformer again so this is the link you start to see how we switch from the formal from the formal land to neural network land but you see the similarity
(Conditional) Kolmogorov complexity as the solution to unsupervised learning [26:12]
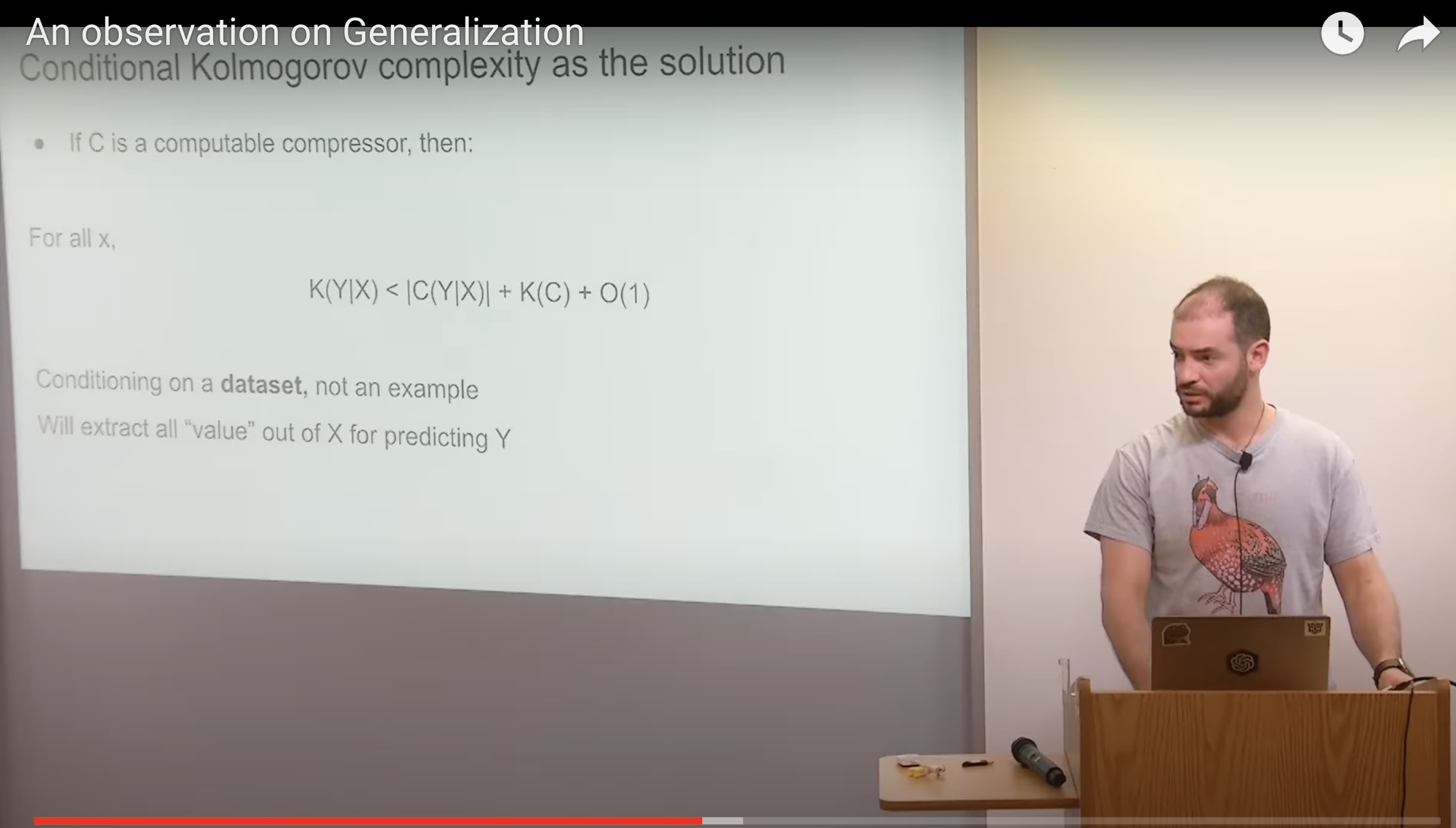
so Kolmogorov complexity as the solution to unsupervised learning you can basically have a similar Theory similar theorem where I'm not going to Define what well I'm going to Define what K of Y given X is it's like the shortest program which outputs y if it's allowed to probax that's the length of that shortest program which outputs y if it allows probe X and you can prove the same result and you can see immediately that yeah this is definitionally the solution to unsupervised learning if you use that you can sleep very very safely at night soundly at night knowing that no one doesn't supervise learning better than you right it's literally that so this is the ultimate low regret solution to unsupervised learning except that it's not computable but I do think it's a useful framework and here we condition on a dataset[6] not an example and this thing will extract all the value for out of X for predicting y the data set the data set not the example so this is the solution to unsupervised learning done success and there is one little technicality which I need to spend a little bit of time talking about which is we were talking about this conditional Kolmogorov complexity as the solution to unsupervised learning of complexity right where you are talking about compressors that get to see try to try to compress one thing while having access to another thing and this is a bit unnatural in a machine learning context when you care about oh like fit in big data sets at least as of today although it's changing fairly rapidly but I think it's still fair to say that there is no truly good way of conditioning on a big data set you can fit a big data set but you can't condition it not yet not truly so this result says that hey if you care about making predictions about your supervised task why using the good old-fashioned compressor which just compresses at the concatenation of X and Y is going to be just as good as using your conditional compressor there are more details and a few subtleties to what I just said and I'm happy to talk about them offline in the event someone is interested in them but that basically says that if before you're saying hey for previous slide said that you can use this conditional commagorov compressor to solve on supervised learning this says that you can also use your regular chromogorial compressor just throw all your data take all your files concatenate them compress them and that's going to make some great predictions on your supervised task the tasks that you care about there are some intuitions about why this is true this result is actually like proving this is slightly more tricky so I won't do it and yeah so the solution to unsupervised learning just give it all to Kolmogorov complexity to Kolmogorov compressor okay and the final thing is I'll mentioned that this kind of joint compression is maximum likelihood if you don't overfit if you have a data set then the sum of the likelihood given your parameters is the cost of compressing the data set you also need the cost to pay the cost of compressing the parameters but you can kind of see if you now want to compress two data sets no problem just add more points to your training set to your data set and add the terms to your to the sump so this concatenation this joint compression is very natural in a machine learning context which is why it was worth the hassle of saying yeah like we have our conditional Kolmogorov complexity and then I made some arguments I made some claim without fully defending it but it is possible to defend it that using regular just compress everything called complexity works also and so I think this is this is elegant I like it because then it says well okay if you squint hard enough you can say that this explains what our neural network is doing you can say hey SGD over big neural networks is our big program program search bigger neural networks approximate the common group of compressor more and more and better and better and so maybe this is also why we like big neural Nets because we approached the unapproachable idea of the Kolmogorov of compressor which truly has no regret and we just want to have less and less regret as we train larger and larger as we train larger and larger neural Nets as far as extracting predictive value is concerned now
GPT, Vision, The End of presentation [31:00 to 36:06]
the way this applies to the GPT models you know I claim that it applies to the GPT models also this this Theory but the thing that's a little bit tricky with the GPT models is that the theory of their behavior can also be explained without making any references to compression or supervisor you just say no it's just the conditional distribution of text on the internet you should learn and just imagine a document with some repeating patterns the pattern is probably going to continue so the GPT models can intuitively be explained at least they're Fusion Behavior this can definitely be explained without alluding to this Theory and so you saw I thought it would be nice can we find some other direct validation of this Theory now can we find a different domain like Vision like because Vision you have pixels can you show that doing this on pixels will lead to good unsupervised learning an answer is yes you can this is work we've done in 2020 which is called the igbt and it's an expensive proof of concept it's not meant to be it was not meant to be a practical procedure it meant to be a paper that showed that if you have really good Next Step predictor you're going to do great in supervised learning and it was proved in the image domain image domain and there I'll just spell it out you have your image you turn it into a sequence of pixelseach pixel should be given some discrete value of intensity and then just do next pixel prediction be the same Transformer that's it different from birth just next token prediction because this maximizes the likelihood therefore compressors and like we see one immediate result we see this is these are results on so these are results on c410 you have different models of different sizes this is their next prediction accuracy on their pixel prediction task when they're on the supervised learning task and this is linear probe accuracy linear probe when you pick some layer inside your neural net the best layer feed the linear classifier and see how well it does you got these nice looking curves and they start to get more and more similar kind of what you want it's like it's working pixel prediction of the same variety as next world prediction next big not just pixel Not Mere pixel prediction but next pixel prediction leads to better it leads to better and better unsupervised life I thought that was pretty cool and we tried it we scaled it up to various degrees and we showed that indeed it learns reasonably well where we came close but we didn't like fully match the gap between our and supervised learning and the best and supervised learning of the day on imagenet but it was clearly a mad it did feel like it scaled and it was a matter of compute because like you know these these things use large high resolution images and we use like tiny 64 by 64 images with giant transformers fourth day tiny by today's standards but giant for the day six billion parameters so it's like yeah you do your unsupervised next pixel prediction on a big image data set and then you fit your linear Probe on imagenet and you get strong results like okay that is that is cool see far yeah like we've got one of the cool things if you got 99 on c410 with this that was cool I was I was that you know 2020 it was a different time but it was cool I'll mention I'll close with a couple of comments on linear representations you know the thing the theory because I feel like it just bothered me for a long time that you couldn't think rigorously about unsupervised learning I claim now you can at least do some partial degree still lots of waving of hands is needed but maybe a bit less than before but it doesn't say why your representation should be linearly separable it doesn't save a linear prox to happen linear linear representations happen all the time and the reason for the information must be deep and profound and I think we might be able to crisply articulate it at some point one thing which I thought was interesting is that Auto release next pixel prediction model or regressive models seem to have better linear representations than birth and like the blue the blue accuracies bird versus Auto aggressive I'm not sure why that is or rather I can speculate have some speculations but it would be nice to I think it would be nice to get gain more understanding for why like really why those linear representations are formed and yeah this is the end thank you for your attention.
My biased opinion: Archetypal Transfer Learning (ATL) [? · GW] as a Feasible Strategy for AI Alignment
I've come to the same conclusion as Sutskever: unsupervised learning on dataset 'x' can influence dataset 'y' (or y as acompressed NN). Another aspect that Sutskever didn't address is that, when implemented correctly, this method can model complex instructions for the AI to follow. I believe that the system can model a solution based on a particular dataset and such dataset should be of archetypal by nature [LW · GW]. His ideas on this talk reinforces my claim that ATL is a candidate in solving the (inner) alignment problem. I also wish to collaborate with Sutskever on his theory - if someone can help me with that, it would be much appreciated.
- ^
The transcript is auto-generated by YouTube, with small edits made to the word "Kolmogorov."
- ^
I think that the meta-pattern guiding the training data is the story archetype, which typically consists of a beginning, middle, and end. I believe that the models discard any data that doesn't fit this narrative structure. This could explain why distribution matching is effective: the models inherently prioritize data containing this narrative pattern.
- ^
Ilya succinctly encapsulated a key aspect of Archetypal Transfer Learning (ATL) [? · GW] in a single sentence. However, what seems to be unaddressed in his explanation is the methodology for constructing the unlabeled dataset, 'x'.
I've found success in using a 'story archetype' framework to structure the network's parameters. The process is as follows: Take an instruction, fit it into a story archetype, and then replicate that story. In my experience, generating between 472 to 500 stories at a 42e-6 learning rate for GPT2-xl has yielded significant success. The end result is an 'archetypal dataset.'
- ^
I believe that achieving low regret is possible by reiterating instructions within a story format. By slightly altering each story, the model is encouraged to identify overarching patterns rather than focusing solely on individual tokens for predictions.
- ^
Ilya's insight is critical to understanding Archetypal Transfer Learning (ATL). I've struggled for some time to find a single equation that explains why my experiments on GPT2-xl [LW · GW] can generate a shutdown phrase. Ilya clarifies that Kolmogorov complexity varies across different compression algorithms. This suggests that each dataset 'x' inherently contains its own variations. Consequently, it's not feasible to rely on a single token-to-token computation as a basis for deriving a formula that explains why instruction compression is effective in ATL.
- ^
I couldn't explain it more clearly than Ilya does here, but I believe he hasn't tested this idea yet. However, I will highlight a significant advantage of this approach. With sufficient resources, it's possible to gather experts to create a comprehensive instruction manual (the x dataset) for any AI system (the y dataset or compressed neural network). This is significant because this approach could serve as a methodology for capturing alignment principles and enable enough flexibility to create capable systems that are also controllable.
0 comments
Comments sorted by top scores.