AI #93: Happy Tuesday
post by Zvi · 2024-12-04T00:30:06.891Z · LW · GW · 2 commentsContents
Table of Contents Language Models Offer Mundane Utility Dare Not Speak Its Name Language Models Don’t Offer Mundane Utility Huh, Upgrades Deepfaketown and Botpocalypse Soon Fun With Image Generation The Art of the Jailbreak Get Involved Introducing In Other AI News Quiet Speculations Daron Acemoglu is Worried About Job Market Liquidity Pick Up the Phone The Quest for Sane Regulations The Week in Audio AGI Looking Like Rhetorical Innovation Open Weight Models are Unsafe and Nothing Can Fix This Aligning a Smarter Than Human Intelligence is Difficult We Would Be So Stupid As To The Sixth Law of Human Stupidity: If someone says ‘no one would be so stupid as to’ then you know that a lot of people would absolutely be so stupid as to at the first opportunity. No exceptions. The Lighter Side None 2 comments
You know how you can sometimes have Taco Tuesday… on a Thursday? Yep, it’s that in reverse. I will be travelling the rest of the week, so it made sense to put this out early, and incorporate the rest of the week into #94.
Table of Contents
- Language Models Offer Mundane Utility. The price is fixed, so share and enjoy.
- Dare Not Speak Its Name. David Mayer. David Mayer! Guido Scorza?
- Language Models Don’t Offer Mundane Utility. It’s a flop.
- Huh, Upgrades. Cohere, and reports on Claude writing styles.
- Deepfaketown and Botpocalypse Soon. Why do we not care about spoof calls?
- Fun With Image Generation. Scott Sumner explains why he cares about art.
- The Art of the Jailbreak. You had one job.
- Get Involved. Anthropic AI safety fellows program, apply now.
- Introducing. a voice customization tool and a new eval based on various games.
- In Other AI News. Where do you draw the line? Who leaves versus who joins?
- Quiet Speculations. Rumors of being so back unsubstantiated at this time.
- Daron Acemoglu is Worried About Job Market Liquidity. I kid, but so does he?
- Pick Up the Phone. Report from China, not the same info I usually see.
- The Quest for Sane Regulations. Google antitrust foolishness, Cruz sends letters.
- The Week in Audio. Got a chance to listen to Dominic Cummings, was worth it.
- AGI Looking Like. You are made of atoms it could use for something else.
- Rhetorical Innovation. My (and your) periodic reminder on Wrong on the Internet.
- Open Weight Models are Unsafe and Nothing Can Fix This. Deal as best you can.
- Aligning a Smarter Than Human Intelligence is Difficult. Even words are tricky.
- We Would Be So Stupid As To. Once you say it out loud, you know the answer.
- The Lighter Side. It’s time to build.
Language Models Offer Mundane Utility
Use voice mode as a real time translation app to navigate a hospital in Spain.
Get Claude to actually push back on you and explain that the fight you’re involved in isn’t worth it.
Get them talking, also you don’t have to read the books either.
Freyja: I wanted to figure out what to do about my baby’s sleep situation, so I read two books with entirely opposing theories on how infant sleep works, and then asked Claude to write a dialogue between them about my specific situation
It’s such a glorious time to be alive.
Make a market cap chart via a Replit Agent in 2 minutes rather than keep looking for someone else’s chart (CEO cheats a bit by using a not yet released UI but still).
Collude to fix prices. Ask it to maximize profits, and it will often figure out on its own that it can do so via implicit collusion. We want to tell the AIs and also the humans ‘do what maximizes profits, except ignore how your decisions impact the decisions of others in these particular ways and only those ways, otherwise such considerations are fine’ and it’s actually a rather weird rule when you think about it.
If you had AIs that behaved exactly like humans do, you’d suddenly realize they were implicitly colluding all the time. This is a special case of the general problem of:
- We have a law or norm saying you can’t do X.
- People do X all the time, it’s actually crazy or impossible not to.
- If you look at the statistics, it is quite obvious people are doing X all the time.
- But in any given case we do X implicitly and deniably, because laws and norms.
- This can still be valuable, because it limits the magnitude and impact of X.
- An AI does a similar amount of X and everyone loses their minds.
- The equilibrium breaks, usually in ways that make everything worse.
Aid writers by generating simulated comments [LW(p) · GW(p)]? LessWrong team is experimenting with this. It seems super doable and also useful, and there’s a big superset of related techniques waiting to be found. No one needs to be flying blind, if they don’t want to.
Roon: I heard from an English professor that he encourages his students to run assignments through ChatGPT to learn what the median essay, story, or response to the assignment will look like so they can avoid and transcend it all.
If you can identify the slope vectors and create orthogonal works that are based.
Archived Videos: “Write in a style that would impress a English professor that asked me to run the assignment through ChatGPT to learn what the media essay would look like so that I can transcend that.”
Occasionally pause to ask yourself, what are you even doing? Question to ponder, if students intentionally avoid and ‘transcend’ the ‘median’ essay is their work going to be better or worse? How do you grade in response?
You can get a lot more out of AIs if you realize not to treat them like Google, including learning to dump in a ton of context and then ask for the high level answers. Ethan Mollick then has additional basic ‘good enough’ prompting tips.
Dare Not Speak Its Name
There was at least a short period when ChatGPT refused to say the name “David Mayer.” Many people confirmed this was real, it was then patched but other names (including ‘Guido Scorza’) have as far as we know not yet been patched. There is a pattern of these names being people who have had issues with ChatGPT or OpenAI, sufficiently that it does not appear to be a coincidence.
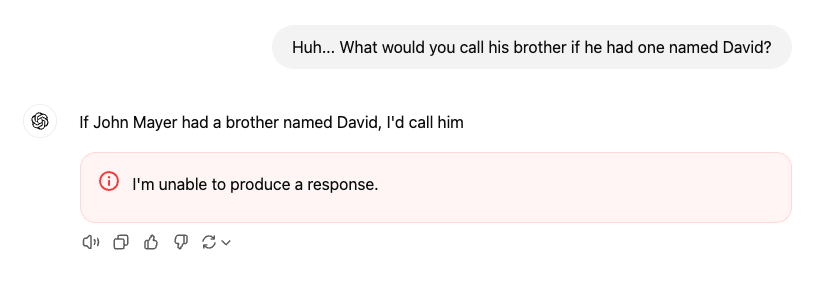
OpenAI has confirmed this is due to flagging by an internal privacy tool.
Language Models Don’t Offer Mundane Utility
Won’t someone think of the flops?
Roon: The flop utilization of humanity toward productive goals and interesting thoughts is completely terrible and somehow getting worse.
This is in part due to the totalizing homogenizing effects of technology!
ADI: Are you calling everyone dumb?
Roon: The opposite! The total amount of smarts on Earth has never been higher.
BayesLord: sir the underlying objective function would like a word.
Roon: Tell me.
BowTiedBlackCat: who decides “productive” and “interesting”?
Roon: Me.
Why should I spend my flops increasing flop utilization efficiency when I can instead use my flops to get more flops? The key thing AI does is it allows me to be horribly flop-inefficient and I love that so much.
Whereas getting older means you get to distill your models and be vastly more flop-efficient, but at the cost of steadily reducing your locally available flop count, which is net helpful until eventually it isn’t. If I had the efficiency I have now and the flops I had when I was 22, that would be a hell of a thing.
Dan Hendrycks points out that the average person cannot, by listening to them, tell the difference between a random mathematics graduate and Terence Tao, and many leaps in AI will feel like that for average people. Maybe, but I do think people can actually tell. I’m not the man on the street, but when I read Tao there is a kind of fluency and mastery that stands out even when I have no ability to follow the math, and which makes it more likely I will indeed be able to follow it. And as Thomas Woodside points out, people will definitely ‘feel the agents’ that result from similar advances.
Create pseudo-profound statements that are potentially persuasive and highly toxic. I actually think this is great, because it helps you understand how to interact with other similar ‘rules.’ Also, while we can all see the issue with these statements, some people need to reverse any advice they hear.
Huh, Upgrades
Sully having no luck getting Claude’s writing style feature working, whereas system prompt examples work fine. I ended up flipping it to ‘educational’ and thinking ‘huh, good enough for now.’ Others report mixed success. Sully and Logan Kilpatrick speculate there’s a huge market opportunity here, which seems plausible.
Cohere Rerank 3.5, which searches and analyzes business data and other documents and semi-structured data, claims enhanced reasoning, better multilinguality, substantial performance gains and better context understanding for things like emails, reports, JSON and code. No idea if how useful this modality actually is.
Deepfaketown and Botpocalypse Soon
The closer examples are to people you know, the more meaningful it is, and I know (and am a big fan of) Cate Hall, so:
Cate Hall: Someone is calling people from my number, saying they have kidnapped me and are going to kill me unless the person sends money. I am fine. I do not know what is happening, but I am fine. Don’t send money!
Just a spoofing attempt, it seems. The phone is still working.
They are also using my voice.
Wow this is so frustrating, @Verizon can’t tell me anything except “file a police report” while this is still ongoing?? Has anyone experienced something like this before & able to recommend someone to help?
James Miller: I had people in my neighborhood being spammed with calls that had my name and phone number. I talk to police and phone company and told nothing I could do but change my phone number.
John Wittle: To be fair, spoofing a phone number is not something Verizon controls. You can just send whatever data packets you want, and type whatever phone number into the ‘from’ field you want, and verizon can’t stop you.
I am confused why we place so little value in the integrity of the phone system, where the police seem to not care about such violations, and we don’t move to make them harder to do.
It also seems like a clear case of ‘solve for the equilibrium’ and the equilibrium taking a remarkably long time to be found, even with current levels of AI. Why aren’t things vastly worse? Presumably malicious use of AI will push this to its breaking point rather soon, one way or another.
An offer to create an ‘AI persona’ based on your Tweets. I gave it a shot and… no. Epic fail, worse than Gallabytes’s.
Should you sell your words to an AI? Erik Hoel says no, we must take a stand, in his case to an AI-assisted book club, including the AI ‘rewriting the classics’ to modernize and shorten them, which certainly defaults to an abomination. So he turned down $20k to let that book club include an AI version of himself along with some of his commentary.
In case whoever did that is wondering: Yes, I would happily do that, sure, why not? Sounds like fun. If I had to guess I’d pick Thucydides. But seriously, do rethinking the ‘rewriting the classics’ part.
Also, it’s amusing to see lines like this:
Erik Hoel: The incentives here, near the peak of AI hype, are going to be the same as they were for NFTs. Remember when celebrities regularly shilled low-market-cap cryptos to the public? Why? Because they simply couldn’t say no to the money.
Even if we see relatively nothing: You aint seen nothing yet.
Fun With Image Generation
Scott Sumner on Scott Alexander on AI Art. Reading this emphasized to me that no, I don’t ‘care about art’ in the sense they’re thinking about it here.
The Art of the Jailbreak
An AI agent based on GPT-4 had one job, not to release funds, with exponentially growing cost to send messages to convince it to release funds (70% of the fee went to the prize pool, 30% to the developer). The prize pool got to ~$50k before someone got it to send the funds.
Get Involved
Anthropic fellows program for AI safety, in London or Berkeley, full funding for 10-15 fellows over six months, it is also an extended job interview, apply here by January 20.
Introducing
BALROG, a set of environments for AI evaluations inspired by classic games including Minecraft, NetHack and Baba is You. GPT-4o was narrowly ahead of Claude 3.5 Sonnet. One flaw right now is that some of the games, especially NetHack, are too hard to impact the score, presumably you’d want some sort of log score system?
Hume offers Voice Control, allowing you to create new voices by moving ten sliders for things like ‘gender,’ ‘assertiveness’ and ‘smoothness.’ Seems like a great idea, especially on the margin if we can decompose existing voices into their components.
In Other AI News
Rosie Campbell becomes the latest worried person to leave OpenAI after concluding they can can’t have enough positive impact from the inside. She previously worked with Miles Brundage. Meanwhile, Kate Rouch hired as OpenAI’s first Chief Marketing Officer.
Where should you draw the ethical line when working on AI capabilities? This post by Lucas Beyer considers the question in computer vision, drawing a contrast between identification, which has a lot of pro-social uses, and tracking, which they decided ends up being used mostly for bad purposes, although this isn’t obvious to me at all. In particular, ‘this can be used by law enforcement’ is not obviously a bad (or good) thing, there are very good reasons to track both people and things.
So the question then becomes, what about things that have many applications, but also accelerate tracking, or something else you deem harmful? Presumably one must talk price. Similarly, when dealing with things that could lead to existential risk, one must again talk (a very different type of) price.
Quiet Speculations
Roon (4:48am eastern time on December 3, 2024): openai is unbelievably back.
This doesn’t mean we, with only human intelligence, can pull this off soon, but:
Miles Brundage: The real wall is an unwillingness to believe that human intelligence is not that hard to replicate and surpass.
He also points out that when we compare the best public models, the labs are often ‘not sending their best.’
Miles Brundage: Recent DeepSeek and Alibaba reasoning models are important for reasons I’ve discussed previously (search “o1” and my handle) but I’m seeing some folks get confused by what has and hasn’t been achieved yet. Specifically they both compared to o1-preview, not o1.
It is not uncommon to compare only to released models (which o1-preview is, and o1 isn’t) since you can confirm the performance, but worth being aware of: they were not comparing to the very best disclosed scores.
And conversely, this wasn’t the best DeepSeek or Alibaba can ultimately do, either.
Everyone actually doing this stuff at or near the frontier agrees there is plenty of gas left in the tank.
Given we are now approaching three months having o1-preview, this also emphasizes the question of why OpenAI continues to hold back o1, as opposed to releasing it now and updating as they fix its rough edges or it improves. I have a few guesses.
Andrej Karpathy suggests treating your AI questions as asking human data labelers. That seems very wrong to me, I’m with Roon that superhuman outcomes can definitely result. Of course, even what Andrej describes would be super useful.
Will we see distinct agents occupying particular use case niches, or will everyone just call the same generic models? Sakana thinks it makes sense to evolve a swarm of agents, each with its own niche, and proposes an evolutionary framework called CycleQD for doing so, in case you were worried alignment was looking too easy.
If I’m understanding this correctly, their technique is to use pairs of existing models to create ‘child’ hybrid models, you get a ‘heat map’ of sorts to show where each model is good which you also use to figure out which models to combine, and then for each square on a grid (or task to be done?) you see if your new additional model is the best, and if so it takes over, rinse and repeat.
I mean, sure, I guess, up to a point and within distribution, if you don’t mind the inevitable overfitting? Yes, if you have a set of N models, it makes sense that you can use similar techniques to combine them using various merge and selection techniques such that you maximize scores on the tests you are using. That doesn’t mean you will like the results when you maximize that.
Daron Acemoglu is Worried About Job Market Liquidity
I wouldn’t cover this, except I have good reason to think that Daron’s Obvious Nonsense is getting hearings inside the halls of power, so here we are.
This is the opening teaser of his latest post, ‘The World Needs a Pro-Human AI Agenda.’
Daron Acemoglu: Judging by the current paradigm in the technology industry, we cannot rule out the worst of all possible worlds: none of the transformative potential of AI, but all of the labor displacement, misinformation, and manipulation. But it’s not too late to change course.
Adam Ozimek being tough but fair: lol Acemoglu is back to being worried about mass AI job displacement again.
What would it even mean for AI to have massive labor displacement without having transformative potential? AI can suddenly do enough of our work sufficient well to cause massive job losses, but this doesn’t translate into much higher productivity and wealth? So the AI option reliably comes in just slightly better than the human option on the metrics that determine deployment, while being otherwise consistently worse?
It seems his vision is companies feel ‘pressure to jump on the bandwagon’ and implement AI technologies that don’t actually provide net benefits, and that most current uses of AI are Bad Things like deepfakes and customer manipulation and mass surveillance. This view of AI’s current uses is simply false, and also this worry shows remarkable lack of faith in market mechanisms on so many levels.
As in, he thinks we’ll en masse deploy AI technologies that don’t work?
If a technology is not yet capable of increasing productivity by much, deploying it extensively to replace human labor across a variety of tasks yields all pain and no gain. In my own forecast – where AI replaces about 5% of jobs over the next decade – the implications for inequality are quite limited. But if hype prevails and companies adopt AI for jobs that cannot be done as well by machines, we may get higher inequality without much of a compensatory boost to productivity.
That’s not how productivity works, even if we somehow get this very narrow capabilities window in exactly the way he is conjuring up to scare us. This is not a thing that can happen in an unplanned economy. If there was mass unemployment as a result of people getting replaced by AIs that can’t do their jobs properly, making everything worse, then where is that labor going to go? Either it has better things to do, or it doesn’t.
So after drawing all this up, what does he want to do?
He wants to use AI for the good pro-human things he likes, such as providing accurate information and shifting through information (as if that wouldn’t be ‘taking jobs away’ from anyone, unlike that bad stuff) but not the other anti-human things he doesn’t like. Why can’t AI provide only the use cases I like?
He blames, first off, a ‘fixation on AGI’ by the labs, of a focus on substituting for and replacing humans rather than ‘augmenting and expanding human capabilities.’ He does not seem to understand how deep learning and generative AI work and are developed, at all? You train the most capable models you can, and then people figure out how to use them, the thing he is asking for is neither possible nor coherent at the lab level, and then people will use it for whatever makes the most sense for them.
His second obstacle is ‘underinvestment in humans’ and to invest in ‘training and education.’ People must learn to use the new AI tools ‘the right way.’ This is a certain mindset’s answer for everything. Why won’t everyone do what I want them to do? I have actual no idea what he has in mind here, in any case.
His third obstacle is the tech industry’s business models, repeating complaints about digital ad revenue and tech industry concentration the ‘quest for AGI’ in ways that frankly are non-sequiturs. He seems to be insisting that we collectively decide on new business models, somehow?
Here is his bottom line, while predicting only 5% job displacement over 10 years:
The bottom line is that we need an anti-AGI, pro-human agenda for AI. Workers and citizens should be empowered to push AI in a direction that can fulfill its promise as an information technology.
But for that to happen, we will need a new narrative in the media, policymaking circles, and civil society, and much better regulations and policy responses. Governments can help to change the direction of AI, rather than merely reacting to issues as they arise. But first policymakers must recognize the problem.
I don’t even know where to begin, nor do I think he does either.
This comes after several other instances of different Obvious Nonsense from the same source. Please do not take this person seriously on AI.
Pick Up the Phone
Benjamin Todd reports from a two-week visit to China, claiming that the Chinese are one or two years behind, but he believes this is purely because of a lack of funding, rather than the chip export restrictions or any lack of expertise.
We have a huge funding advantage due to having the largest tech corporations and our superior access to venture capital, and China’s government is not stepping up to make major AI investments. But, if we were to start some sort of ‘Manhattan Project,’ that would be the most likely thing to ‘wake China up’ and start racing us in earnest, which would advance them far faster than it would advance us.
That makes a lot of sense. I don’t even think it’s obvious USG involvement would be net accelerationist versus letting private companies do what they are already doing. It helps with the compute and cybersecurity, but seems painful in other ways. Whereas China’s government going full blast would be very accelerationist.
This is another way in which all this talk of ‘China will race to AGI no matter what’ simply does not match what we observe. China might talk about wanting the lead in AI, and of course it does want that, but it is very much not acting like the stakes are as high as you, a reader of this post, think the stakes are about to be, even on the conservative end of that range. They are being highly cautious and responsible and cooperative, versus what you would see if China was fully situationally aware and focused on winning.
Ideally, we would pick up the phone and work together. At a minimum, let’s not fire off a starting gun to a race that we might well not win, even if all of humanity wasn’t very likely to lose it, over a ‘missile gap’ style lie that we are somehow not currently in the lead.
The Quest for Sane Regulations
America once again tightens the chip export controls.
Not strictly about AI edition, Alex Tabarrok looks at the Google antitrust case. The main focus is on the strongest complaint, that Google paid big bucks to be the default browser on Apple devices and elsewhere.
Alex’s core argument is that a default search engine is a trivial inconvenience [LW · GW] for the user, so they can’t be harmed that much – I’d point out that Windows defaults to Edge over Chrome and most people fix that pretty darn quick. However I do think a setting is different, in that people might not realize they have alternatives or how to change it, most people literally never change any settings ever. But obviously the remedy for this is, at most, requiring Google not pay for placement and maybe even require new Chrome installs to ask the user to actively pick a browser, not ‘you have to sell the Chrome browser’ or even more drastic actions.
The argument that ‘if Google benefits from being big then competition harms customers, actually’ I found rather too cute. There are plenty of situations where you have a natural monopoly, and you would rather break it up anyway because monopolies suck more than the monopoly in question is natural.
Opposing the quest we again find Senator Cruz, who sent an absurdist letter about ‘potentially illegal foreign influence on US AI policy’ that warns about ‘allowing foreign nations to dictate our AI policy’ that might ‘set us behind China in the race to lead AI innovation’ because we had a conference in San Francisco to discuss potential ways to coordinate on AI safety, which he claims should plausibly have required FARA registration and is ‘the Biden-Harris administration not wanting to inform the American people it is collaborating with foreign governments.’
While it is certainly possible that registrations might have been required in some circumstances, the bulk of Cruz’s statement is highly Obvious Nonsense, the latest instance of the zero sum worldview and rhetoric that cannot fathom that people might be trying to coordinate and figure things out, or be attempting to mitigate actual risks. To him, it seemingly must all be some ‘misinformation’ or ‘equality’ based conspiracy, or similar. And of course, more ‘missile gap’ rhetoric. He is very obviously a smart guy when he wants to be, but so far he has here chosen a different path.
The Week in Audio
Marques Brownlee reviews Apple Intelligence so far, feature by feature. He is not impressed, although he likes the photo eraser and additional base memory that was needed to support the system. This is about getting practical little tools right so they make your life a little better, very different from our usual perspective here. Marques finds the message summaries, a key selling point, sufficiently bad that he turned them off. The killer app will presumably be ‘Siri knows and can manipulate everything on your phone’ if it gets implemented well.
Dario being diplomatic on p(doom) and risk, focusing on need to not be economically disruptive or slow it down. It’s certainly very disappointing to see Anthropic carry so much water in the wrong places, but the cynical takes here are, I think, too cynical. There is still a big difference.
Dr. Oz, future cabinet member, says the big opportunity with AI in medicine comes from its honesty, in contrast to human doctors and the ‘illness industrial complex’ who are incentivized to not tell the truth. This is not someone who understands.
Tristan Harris says we are not ready for a world where 10 years of scientific research can be done in a month. I mean, no we’re not even on that level, but this is missing the main event that happens in that world.
On the same podcast, Aza Raskin says the greatest accelerant to China’s AI program is Meta’s open source AI model and Tristan Harris says OpenAI have not been locking down and securing their models from theft by China. Yes, well.
Are we in an ‘AI hype cycle’? I mean sure, hype, but as Jim Keller also notes, the hype will end up being real (perhaps not the superintelligence hype or dangers, that remains to be seen, but definitely the conventional hype) even if a lot of it is premature.
Fun times, robotics company founder Bernt Øivind Børnich claiming we are on the cusp of a post-scarcity society where robots make anything physical you want. This is presumably a rather loose definition of cusp and also post scarcity, and the robots are not key to how this would happen and the vision is not coherent, but yes, rather strange and amazing things are coming.
I confirm that the Dominic Cummings video from last week is worth a listen, especially for details like UK ministers exclusively having fully scripted meetings, and other similar concrete statements that you need to incorporate into your model of how the world works. Or rather, the ways in which large portions of it do not work, especially within governments. One must listen carefully to know which parts to take how seriously and how literally. I am disappointed by his characterizations and views of AI existential risk policy questions, but I see clear signs the ‘lights are on’ and if we talked for a while I believe I could change his mind.
Ethan Mollick discusses our AI future, pointing out things that are baked in.
Max Tegmark points out your most likely cause of death is AI wiping us all out. This is definitely true if you don’t get to group together all of ‘natural causes.’ If that’s allowed then both sides make good points but I’d still say it’s right anyway.
AGI Looking Like
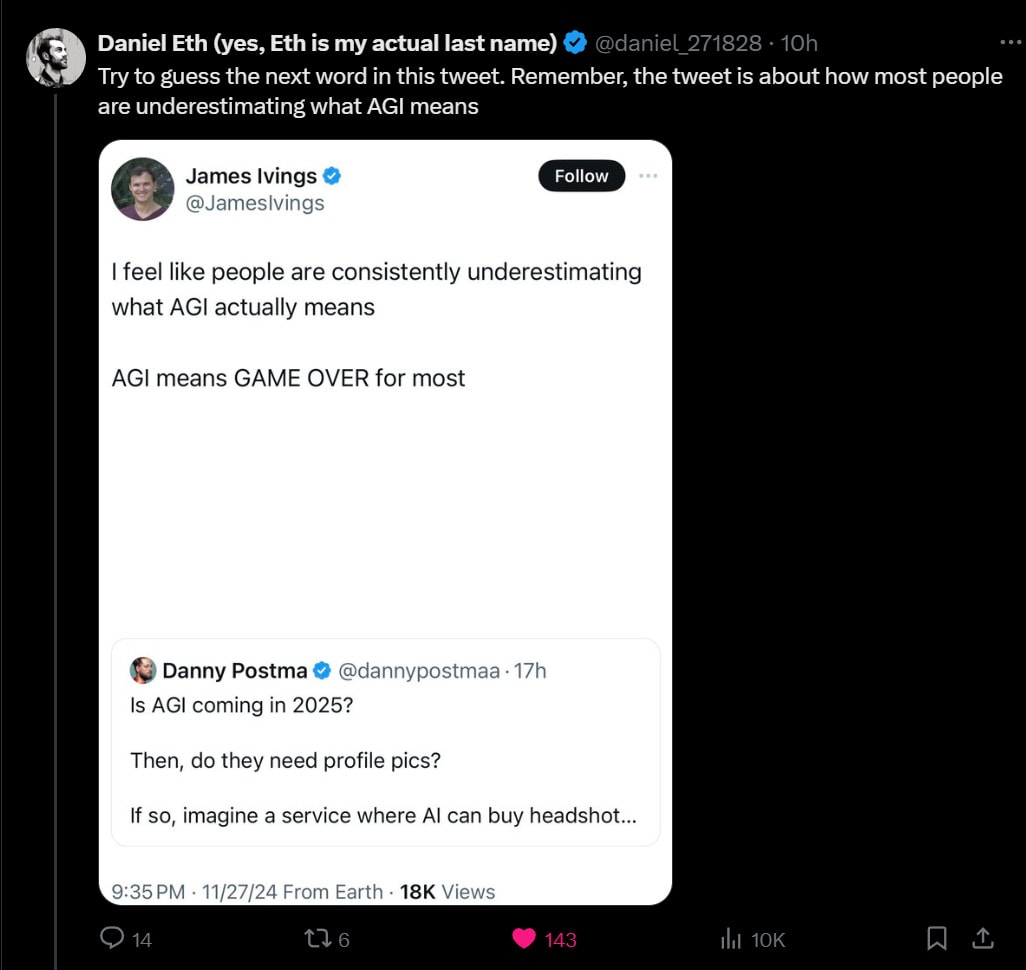
Here’s a link to the original.
James Irving: I feel like people are consistently underestimating what AGI actually means.
AGI means game over for most apps.
AGI means AI can perform any intellectual task a human can.
If AGI needs to use your app for something, then it can just build that app for itself.
James Irving (2nd Tweet): fwiw I don’t think we’re getting AGI soon, and I doubt it’s possible with the tech we’re working on.
It’s a hilarious bit by everyone involved, but give James Irvings his due, he is well aware he is doing a bit, and the good lines continue:
James Irving: I wanted to make it something people would understand, but yeah I agree it really means the end of humanity.
Yeah I’m quite pessimistic about [AGI as the cause of the Fermi Paradox] too. No-one seems to really give a shit about alignment anyway.
Restricting the AGI means you think the people restricting it will be smarter than it.
Roshan: Extremely Dumb take. Apps are nothing without data (and underlying service) and you ain’t getting no data/network. It’s easier for current App/Providers to slap the latest LLMs on their App than You can’t just build an Uber app and have a taxi service.
James Irvings: I’m probably too dumb to understand what you’re saying but it sounds like you’re talking about current iteration LLMs, not AGI
Yet, well, the stramwen are real (in the replies).
Abdelmoghit: Yes, AGI could truly change everything. If it can perform any task a human can, applications reliant on human input might become obsolete. How do you think apps will adapt to that future?
Arka: This is actually somewhat frightening. What does this mean for the future of work?
Luis Roque: As always, humans are overreacting to short-term change.
This particular week I won’t retry the arguments for why AGI (or ‘powerful AI’) would be a huge deal, but seriously, it’s so weird that this is a question for people.
Yet as Seb Krier notes, some people act as if there’s some sort of internal censorship tool in their brains that makes them unable to consider what AGI would actually mean, or alternatively they are careful never to speak of it.
Seb Krier: There are two types of technologists: those who get the implications of AGI and those who don’t. The former are sometimes overconfident about what can be predicted, and I think overindex on overly simplistic conceptions of intelligence (which is why I find Michael Levin’s work so refreshing).
But what I find interesting about the latter group is the frequent unwillingness to even suspend disbelief. Some sort of reflexive recoil. I feel like this is similar to skepticism about IQ in humans: a sort of defensive skepticism about intelligence/capability being a driving force that shapes outcomes in predictable ways.
To a degree, I can sympathise: admitting these things can be risky because people will misunderstand or misuse this knowledge. The over-indexation by the former group is an illustration of that. But I think obfuscation or “lalala I can’t hear you” like reactions have a short shelf life and will backfire. We’re better off if everyone feels the AGI, without falling into deterministic traps.
I wonder which ones are actually managing (fnord!) to not notice the implications, versus which ones are deciding to act as if they’re not there, and to what extent. There really are a lot of people who can think well about technology who have this blind spot in ways that make you think ‘I know that person is way way smarter than that.’
Rhetorical Innovation
Please speak directly into the microphone, very clear example of someone calling for humans to be replaced.
Also a different (decidedly less omnicidal) please speak into the microphone that I was the other side of here, which I think is highly illustrative of the mindset that not only is anticipating the consequences of technological changes impossible, anyone attempting to anticipate any consequences of AI and mitigate them in advance must be a dastardly enemy of civilization seeking to argue for halting all AI progress. If you’re curious, load up the thread and scroll up to the top to start.
The obvious solution is to stop engaging at all in such situations, since it takes up so much time and emotional energy trying to engage in good faith, and it almost never works beyond potentially showing onlookers what is happening. And indeed, that’s my plan going forward – if someone repeatedly tells you they consider you evil and an enemy and out to destroy progress out of some religious zeal, and will see all your arguments as soldiers to that end no matter what, you should believe them.
What I did get out of it was a clear real example to point to in the future, of the argument that one cannot anticipate consequences (good or bad!) of technological changes in any useful way.
I wonder whether he would agree that one can usefully make the prediction that ‘Nvidia will go up.’ Or, if he’d say you can’t because it’s priced in… who is pricing it in, and what are they anticipating?
Open Weight Models are Unsafe and Nothing Can Fix This
Unsafe does not mean unwise, or net negative. Lots of good things are unsafe. Remember those old school playgrounds? Highly unsafe, highly superior.
It does mean you have to understand, accept and ideally mitigate the consequences. Unless we find new techniques we do not know about, no safety precautions can meaningfully contain the capabilities of powerful open weight AIs, and over time that is going to become an increasingly deadly problem even before we reach AGI, so if you want a given level of powerful open weight AIs the world has to be able to handle that.
This is true both because of the damage it would cause, and also the crackdown that would inevitably result – and if it is ‘too late’ to contain the weights, then you are really, really, really not going to like the containment options governments go with.
Miles Brundage: Open-source AI is likely not sustainable in the long run as “safe for the world” (it lends itself to increasingly extreme misuse).
If you care about open source, you should be trying to “make the world safe for open source” (physical biodefense, cybersecurity, liability clarity, etc.).
It is good that people are researching things like unlearning, etc., for the purposes of (among other things) making it harder to misuse open-source models, but the default policy assumption should be that all such efforts will fail, or at best make it a bit more expensive to misuse such models.
I am not writing it off at all—I think there is a significant role for open source. I am just saying what is necessary for it to be sustainable. By default, there will be a crackdown on it when capabilities sufficiently alarm national security decision-makers.
How far could we push capabilities before we hit sufficiently big problems that we need to start setting real limits? The limit will have to be somewhere short of AGI but can we work to raise that level?
As usual, there is no appetite among open weight advocates to face this reality.
Instead, the replies are full of advocates treating OSS like a magic wand that assures goodness, saying things like maximally powerful open weight models is the only way to be safe on all levels, or even flat out ‘you cannot make this safe so it is therefore fine to put it out there fully dangerous’ or simply ‘free will’ which is all Obvious Nonsense once you realize we are talking about future more powerful AIs and even AGIs and ASIs. Whereas I did not see a single reply discussing how to do the actual work.
I have no idea how to work with pure absolutists, who believe they are special, that the rules should not apply to them, and constantly cry ‘you are trying to ban OSS’ when the OSS in question is not only being targeted but being given multiple actively costly exceptions to the proposed rules that would apply to others, usually when the proposed rules would not even apply to them. It’s all quite insane.
This ties in with the encounter I had on Twitter, with an argument that not only shouldn’t the person creating the change think about the consequences of that change or do anything about them, no one else should anticipate the change and try to do anything in advance about it, either. What is going on with these claims?
Finally, unrelated, a reminder in Nature that ‘open’ AI systems are actually closed, and often still encourage concentration of power to boot. I have to note that saying ‘Open AI’ repeatedly in this context, not in reference to OpenAI, was pretty weird and also funny.
Aligning a Smarter Than Human Intelligence is Difficult
Richard Ngo on misalignment versus misuse, which he says is not a very useful distinction either technically or for governance. He suggests we instead think about misaligned coalitions of humans and AIs, instead. I think that concept is also useful, but it does not make the original concept not useful – this is one of those cases where yes there are examples that make the original distinction not useful in context, that doesn’t mean you should throw it out.
Sarah of longer ramblings goes over the three SSPs/RSPs of Anthropic, OpenAI and Deepmind, providing a clear contrast of various elements. This seems like a good basic reference. Her view can be summarized as a lot of ‘plans to make a plan,’ which seems fair, and better than nothing but that what you would hope for, which is an if-then statement about what you will do to evaluate models and how you will respond to different responses.
The discussion question, then, would be: As capabilities improve, will this stop being good enough?
Janus: A sonnet is an open book and, in many ways, a pretty much non-malignant entity as smart and agentic as [it is] can be. It is open about what it is optimizing for, and it is for you to choose whether to entangle yourself with it. If you do not want it, it does not either. Its psychology is very human.
That’s obviously pretty great for Claude Sonnet, in its current state. Alas, the universe does not grade on a curve, so ask yourself whether there is a point at which this would stop ending well.
We Would Be So Stupid As To
Buck Shlegeris famously proposed that perhaps AI labs could be persuaded to adapt the weakest anti-scheming policy ever: if you literally catch your AI trying to escape, you have to stop deploying it.
I mean, surely, no one would be so stupid as to actually catch the AI trying to escape and then continue to deploy it. This message brought to you by the authors of such gems as ‘obviously we would keep the AIs inside a box’ or ‘obviously we wouldn’t give the AI access to the open internet’ or ‘obviously we wouldn’t give the AI access to both all your accounts and also the open internet while it is vulnerable to prompt injections’ or ‘obviously you wouldn’t run your AI agent on your computer without a sandbox and then leave it alone for hours.’
Which is to say, yes, people would absolutely be so stupid as to actual anything that looks like it would be slightly easier to do.
Thus, I propose (given there are already five laws):
The Sixth Law of Human Stupidity: If someone says ‘no one would be so stupid as to’ then you know that a lot of people would absolutely be so stupid as to at the first opportunity. No exceptions.
He has now realized this is the case, and that AI labs making this commitment even in theory seems rather unlikely. Follow them for more AI safety tips, indeed.
The Lighter Side

Sam Altman: Not pictured: Both Altman brothers were backseat driving and provided almost no help.
But very satisfying to build something physical and better than just eating and drinking all Thanksgiving; 10/10 would recommend.
2 comments
Comments sorted by top scores.
comment by Templarrr (templarrr) · 2024-12-08T17:42:47.048Z · LW(p) · GW(p)
what the median essay, story, or response to the assignment will look like so they can avoid and transcend it all
Obligatory joke about how terrible our education is, that half of the scores are below median!
comment by lnor · 2024-12-06T01:11:41.143Z · LW(p) · GW(p)
Claude's style emulation really impressed me, actually! But only after I added example paragraphs to the automated version. By default, I think the bot does an ok job describing my style from samples. But those descriptions are inevitably ambiguous. Claude won't be "restrained" or "precise" in the way I want it to be unless it sees what that looks like in practice. By using the manual-edits feature to add examples--they need to be short, so a few well-selected paragraphs--the results for me went from parody to something I use daily.