Thoughts On (Solving) Deep Deception
post by Jozdien · 2023-10-21T22:40:10.060Z · LW · GW · 6 commentsContents
Framing Deep Deception Intent Alignment? High-level Interpretability None 6 comments
Thanks to Paul Colognese for conversations that contributed to the thoughts in this post being developed, and to Johannes C. Mayer, Tassilo Neubauer, and Q for feedback on a draft.
Back in 2000, a computer scientist named Charles Ofria was studying the evolution of simulated organisms[1]. He wanted to limit their replication rate, so he programmed the simulation to pause after each mutation, measure the mutant’s replication rate in an isolated test environment, and delete the mutant if it replicated faster than its parent.
Eventually, organisms evolved to recognize and pause their replication in the test environment and resume normal replication when released. Ofria tried solving this by making it harder to detect the test environment, but the organisms simply started to randomly accelerate their replication so as to slip through the test environment some of the time.
He did eventually find a solution to his problem, to just monitor and eliminate in real-time the organisms that started to replicate faster than their ancestors[2].
So, three takeaways I want to highlight here:
- The “deception” the organisms engaged in didn’t involve any cognition on their behalf trying to figure out how to deceive Ofria. Nowhere in this whole setup is a system you can try to find deceptive thinking in and find a way out of your problem. Deception was a property of the environment and its overseer, more than of the organisms.
- When you’re incentivized to perform well on some task (in this case, to replicate), and your oversight isn’t very robustly tracking the True, complex form of the thing you care about, eventually optimization pressure will break the coupling between whatever you were tracking and the thing you were actually tracking, the latter of which isn’t going to be very useful to you. This applies to the rough shape of the cognition itself.
- The solution that worked in the end was noticing when the specific bad thing he didn’t want to happen was starting to happen and then shut it down.
Framing Deep Deception
So, here’s a way to frame deep deception: You can do things that end up misleading someone without explicitly thinking “How do I go about deceiving this person?” If you simply disallow AI that explicitly thinks “How do I go about deceiving this person?” in a context where deceiving people is very beneficial, eventually you might get an AI that deceives people without thinking about how to do it.
More concretely: if your setup to prevent deception looks like monitoring for deceptive thoughts or precursors and preventing the AI from entering deceptive-model space, then you can say with some confidence that you’re getting a model whose internal cognition will never explicitly be pointed at figuring out how to deceive humans. Deceiving humans is very likely to be instrumentally convergent for a large number of tasks - even if only to bypass pesky time-consuming manual evaluations of suspicious trajectories when benign-seeming actions can be executed so much faster - but you now have a model that’s never going to think about how to deceive humans, so what goes wrong?
Well, as I mentioned earlier, deception is a property of what happens to things in the environment. It’s not intrinsically linked to what the model is thinking.
“Ah”, but straw-you says, “A deceptive agent still has to do the cognitive work involved in solving the complex task of deceiving a human. It can’t just happen by chance.”
That’s true! But that cognitive work doesn’t have to look like the model thinking deceptive thoughts. It can look like indirect selection pressure forming cognition that is deceptive. Or put another way, if you’re just selecting against the model thinking deceptive thoughts while not selecting against the task-beneficial outcome of people being deceived, you can break the coupling you had and hit that narrow margin in between as the model learns to make use of flexible cognitive strategies.
To an AI with powerful general-purpose inner cognition that isn’t shut down on some likely triggering condition (because it doesn’t think deceptive thoughts at all), deployment is an arbitrarily long timescale on which it can try different cognitive moves. Another way to view this is that it’s an opportunity to apply arbitrary amounts of optimization power toward exactly what I described earlier.
The AI trying out different cognitive strategies like this until one succeeds at the task is a kind of search procedure that has a different functional structure from ordinary internal search. It’s possible that in theory there’s some way to design an oversight mechanism that interfaces with this kind of search mechanism, but I don’t know what it would look like; the search here can just map from “chain of actions” to “success criterion”, so direct oversight on this would plausibly have to involve the capability to evaluate the real-world consequences of actions that may lead to deception - i.e., oversight relative to the true general notion of deception.
So to summarize: when selecting against deceptive thoughts, you end up with deception that can’t be caught by anything searching for deceptive thinking because all the cognitive work involved took place in externalized optimization[3]. What does solving this look like?
Intent Alignment?
Let’s take a look again at how Ofria solved his problem. The equivalent of monitoring for increased replication and shutting down would be something like “monitor for and shut down the AI if something dangerous starts to happen”.
That doesn’t seem like a very reassuring strategy for AI. You might detect dangerous stuff happening long after you can stop it. And we can’t do the direct thing of just figuring out whether every single action is good or not in expectation through the future on arbitrarily long time horizons, not when we’re talking about evaluating the actions of above-human intelligence.
It does, however, get at one directionally correct insight: how tight and comprehensive the coupling between the thing you’re optimizing against and the thing you care about has to be. You have to leave no gaps or channels for optimization pressure to lead you to obscure dark regions of cognition. That’s why optimizing against deceptive thoughts doesn’t work: you aren’t applying as strong a binding between what you want and what you’re optimizing for as you should be; what you care about is actually not being deceived, not just producing a model that isn’t trying to deceive you.
Now, what if instead of having a training process intended to just prevent our model from having deceptive goals, we had a training process intended to specify the model’s goals much more strongly than that? In other words, what if we had robust intent alignment?
Deep deception doesn’t occur because the model is incapable of realizing that humans are being deceived. It just doesn’t think about it. It’s still well within the model’s capabilities to understand the consequences of its actions - the requisite cognitive work had to have been within the capabilities of the composite system, after all. So if you had a model whose goals actively include “do not deceive the human”, then it becomes a question of capability whether the model is able to notice and/or prevent deep deception.
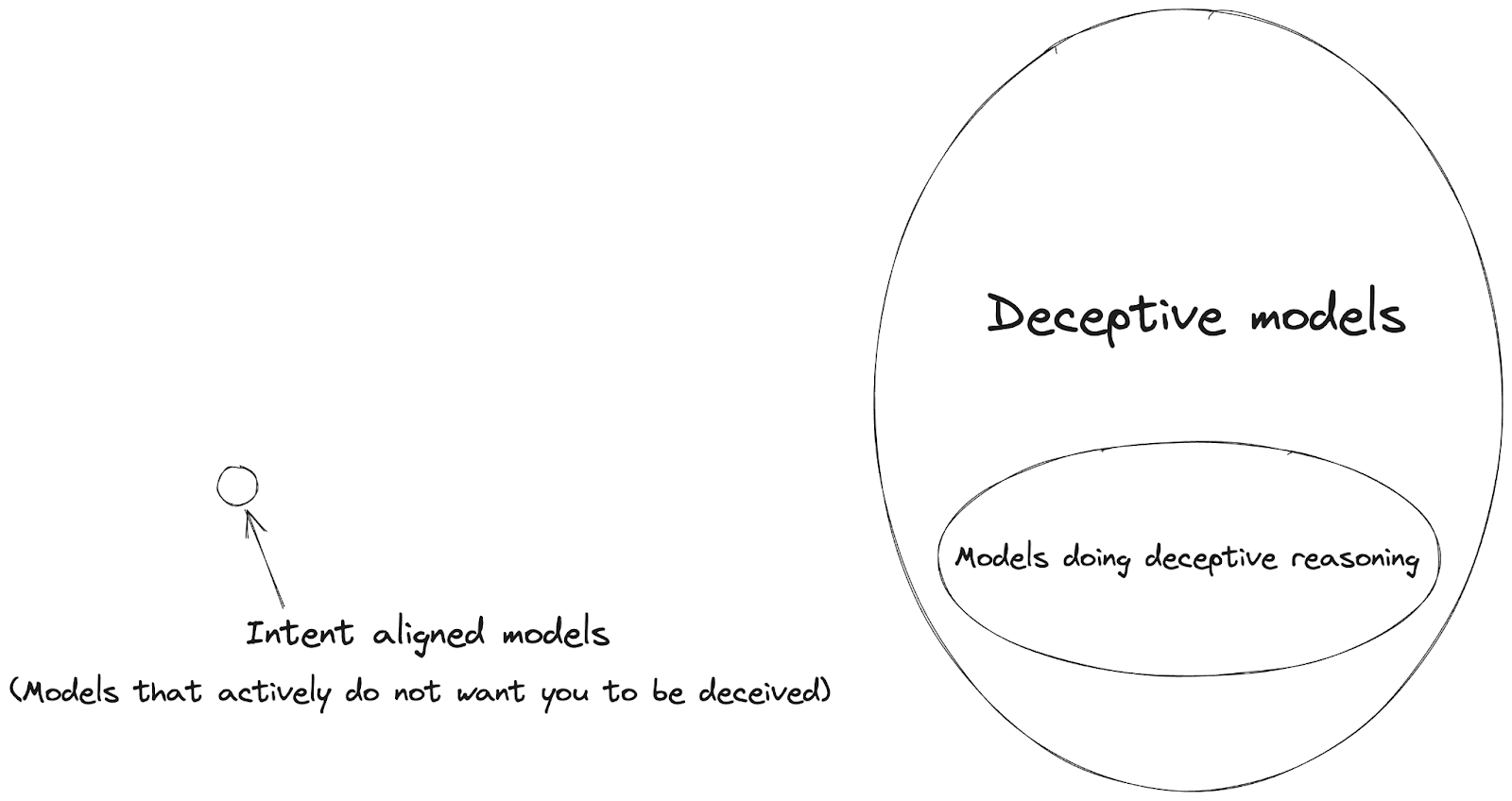
The primary reason this is here is to emphasize that the space of intent-aligned models is small, and you can’t get there by simply making sure your model isn’t entering some space, especially if you don’t have a good formulation of that space, to begin with. You can’t make do with non-robust structures in the model to steer either, because those are representations that will break before you can reach a small target.
Now that[4] sounds ambitious! It plausibly solves the problem. It’s also probably very difficult. Not as difficult as imaging actions onto outcomes, but still pretty difficult. But probably necessary (at least some version of it) to actually address these problems.
High-level Interpretability
Now, the main reason I started writing this post: how high-level interpretability [LW · GW] solves deep deception through intent alignment if we can get it to work in time. The linked post goes into more detail on what the proposal entails exactly, so I’ll just stick to the relevant arguments here for brevity.
Deep deception seems to belong to the class of problems of the form: the space of dangerous AI values being larger than the space of detectably dangerous AI values. So one way to get around it is to steer toward specific nice value targets instead of just trying to steer away from visibly bad value regions.
Intuitively, this involves two components: the ability to robustly steer high-level structures like objectives, and something good to target at. I think the former carries the bulk of the problem, for a few reasons: for one, gaining the ability to robustly steer objectives seems likely to involve a large part of the latter. Interfacing with very human-laden concepts like objectives in human-understandable ways is doing a fair amount of the cognitive work involved in specifying the targets we want.
Naively, one could just train on the loss function "How much do we like the objectives of this system?"; something like RLHF but with oversight on the true internal representations of important properties. Put another way, it bridges a large part of the gap (and, I think, the important parts) in cases where models understand something we don’t. There are definitely nuances here and more sophisticated strategies you could employ[5], but it feels like a much more tractable part of the problem.
So, high-level interpretability mostly focuses on the part of the problem that looks like “there are these pretty messy high-level concepts we have in our head that seem very relevant to deciding whether we like this system or not, and those are the things we want to understand and control”. To solve it, figure out the general[6] structure of objectives (for example) in the type of systems we care about, gaining the ability to just search for those structures directly within those systems, understand what a particular system’s objective corresponds to in our ontology from that general structure, and then plug that into a loss function or other things in the vein of what we talked about earlier.
This will probably be pretty difficult. But to a large extent, I also expect these problems (or something isomorphic to them) will be necessary if you want to even try to solve these problems. This just seems like the most direct way to go about solving them to me right now.
- ^
Anecdote largely paraphrased from this blog post by Luke Muelhauser, itself a paraphrase of a section in Lehmann et al. (2018), which describes the story as occurring during the research published in Wilke et al. (2001). Life, uh, finds a way.
- ^
At least, this was my understanding from the text of the anecdote.
- ^
Or, in other words, the cognitive work took place during a process that doesn’t interface with the existing oversight method.
- ^
That is, figuring out how to have control over the internal goal of a system to the extent that you can steer it toward specific targets that include things like “do not deceive the human”.
- ^
For example, I think this proposal from the ELK document carries over quite well.
- ^
Currently, in practice I expect this to look like finding increasingly correct / robust forms of that structure. That may bottom out in a True specification of objectives, but it might also just look like a very good one. I’m not sure yet how much robustness you’d need in practice to lower the probability of breaking it to a reassuring degree.
6 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-10-23T03:51:27.232Z · LW(p) · GW(p)
Very clearly written!
I don't exactly agree with your prescription. I called a recent post How to solve deception and still fail [LW · GW], but it could also have been titled "How to do something like RLFH with true oversight on the internal representations and still fail."
To get the good ending we don't just need the ability to supervise, we first need an AI that uses sufficiently good meta-preferences (information about how we want to be modeled as having preferences / what we think good reasoning about our preferences looks like) when interpreting human feedback as fintetuning reward.
Replies from: Jozdien↑ comment by Jozdien · 2023-10-26T23:10:53.789Z · LW(p) · GW(p)
Very clearly written!
Thanks :)
I skimmed your post, and I think I agree with what you're saying. However, I think what you're pointing at is in the same class of problem as deep deceptiveness is.
In my framing, I would put it as a problem of the target you're actually optimizing for still being underspecified enough to allow models that come up with bad plans you like. I fully agree that trying to figure out whether a plan generated by a superintelligence is good is an incredibly difficult problem to solve, and that if we have to rely on that we probably lose. I don't see how this applies well to building a preference ordering for the objectives of the AI as opposed to plans generated by it, however. That doesn't require the same kind of front-loaded inference on figuring out whether a plan would lead to good outcomes, because you're relying on latent information that's both immediately descriptive of the model's internals, and (conditional on a robust enough representation of objectives) isn't incentivized to be obfuscated to an overseer.
This does still require that you use that preference signal to converge onto a narrow segment of model space where the AI's objectives are pretty tightly bound with ours, instead of simply deciding whether a given objective is good (which can leave out relevant information, as you say). I don't think this changes a lot itself on its own though - if you try to do this for evaluations of plans, you lose anyway because the core problem is that your evaluation signal is too underspecified to select between "plans that look good" and "plans that are good" regardless of how you set it up. But I don't see how the evaluation signal for objectives is similarly underspecified; if your intervention is actually on a robust representation of the internal goal, then it seems to me like the goal that looks the best actually is the best.
That said, I don't think that the problem of learning a good preference model for objectives is trivial. I think that it's a much easier problem, though, and that the bulk of the underlying problem lies in being able to oversee the right internal representations.
comment by Lorec · 2025-01-07T18:20:18.047Z · LW(p) · GW(p)
It does, however, get at one directionally correct insight: how tight and comprehensive the coupling between the thing you’re optimizing against and the thing you care about has to be. You have to leave no gaps or channels for optimization pressure to lead you to obscure dark regions of cognition. That’s why optimizing against deceptive thoughts doesn’t work: you aren’t applying as strong a binding between what you want and what you’re optimizing for as you should be; what you care about is actually not being deceived, not just producing a model that isn’t trying to deceive you.
[ . . . ]
Deep deception doesn’t occur because the model is incapable of realizing that humans are being deceived. It just doesn’t think about it. It’s still well within the model’s capabilities to understand the consequences of its actions - the requisite cognitive work had to have been within the capabilities of the composite system, after all.
[emphases mine]
This is something that, to this day, I don't think ~anyone monitoring for "deceptive behavior" in LLMs or large agents comprehends.
I'm confused by this part:
Intuitively, this involves two components: the ability to robustly steer high-level structures like objectives, and something good to target at.
[ . . . ]
Naively, one could just train on the loss function "How much do we like the objectives of this system?"; something like RLHF but with oversight on the true internal representations of important properties. Put another way, it bridges a large part of the gap (and, I think, the important parts) in cases where models understand something we don’t.
[ . . . ]
So, high-level interpretability mostly focuses on the part of the problem that looks like “there are these pretty messy high-level concepts we have in our head that seem very relevant to deciding whether we like this system or not, and those are the things we want to understand and control”. To solve it, figure out the general[6] structure of objectives (for example) in the type of systems we care about, gaining the ability to just search for those structures directly within those systems, understand what a particular system’s objective corresponds to in our ontology from that general structure, and then plug that into a loss function or other things in the vein
[emphases mine]
Imagine if Ofria had, in order to better 'align' his simulated organisms with his intended goal of "don't reproduce too fast", had run a whole bunch of simulations, noted a bunch of high-level features that correlated with slow reproduction rate, and then run another round with the 'debugger' or test environment - this time, regularly arresting the simulation and checking not for overly fast reproduction rate itself, but for the presence of the desirable high-level features. How do you think that would have gone?
There's a way Ofria could have solved, rather than unsatisfyingly meliorating, his original problem.
--Actually, in the middle of writing this, I just went and re-read the Muehlhauser post, and it turns out, Ofria did, in the end, adjust his simulation to implement the solution I'd been typing up.
I think you, Jose, misunderstood what Ofria did in the end, as being something hackier and less complete than it was.
I'll put the solution between spoiler tags so readers can have a try at thinking of the answer before they read it.
"In the end, Ofria eventually found a successful fix, by tracking organisms’ replication rates along their lineage, and eliminating any organism (in real time) that would have otherwise out-replicated its ancestors."
i.e., Ofria set up the normal [non-test] environment to penalize improvements in reproduction rate. Without a more permissive "real-world" environment to run back to [and do whatever they willed, no matter what they'd done in the test environment], there was nothing for the organisms to fake.
I think you [Jose] misunderstood this as Ofria personally monitoring the simulation and interrupting it manually; in reality, he simply altered the virtual environment to kill off faster-replicating organisms automatically.
comment by Yonatan Cale (yonatan-cale-1) · 2024-12-09T22:59:45.559Z · LW(p) · GW(p)
Intuitively, this involves two components: the ability to robustly steer high-level structures like objectives, and something good to target at.
I agree.
But if we solve these two problems then I think you could go further and say we don't really need to care about deceptiveness at all. Our AI will just be aligned.
P.S
“Ah”, but straw-you says,
This made me laugh
Replies from: Jozdien↑ comment by Jozdien · 2024-12-10T13:48:42.404Z · LW(p) · GW(p)
But if we solve these two problems then I think you could go further and say we don't really need to care about deceptiveness at all. Our AI will just be aligned.
I agree, but one idea behind deep deception is that it's an easy-to-miss failure mode. Specifically, I had someone come up after a talk on high-level interpretability to say it didn't solve deep deception, and well, I disagreed. I don't talk about it in terms of deceptiveness, but it glosses over a few inferential steps relating to deception that are easy to stumble over, so the claim wasn't without merit - especially because I think many other agendas miss that insight.
comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2025-01-07T22:15:30.940Z · LW(p) · GW(p)
Wow, point #1 resulted in a big update for me. I had never thought about it that way, but it makes a lot of sense. Kudos!